自然语言处理从入门到应用——LangChain:模型(Models)-[文本嵌入模型Ⅱ]
分类目录:《自然语言处理从入门到应用》总目录
本文将介绍如何在LangChain中使用Embedding类。Embedding类是一种与嵌入交互的类。有很多嵌入提供商,如:OpenAI、Cohere、Hugging Face等,这个类旨在为所有这些提供一个标准接口。
嵌入创建文本的向量表示会很有用,因为这意味着我们可以在向量空间中表示文本,并执行类似语义搜索这样的操作。LangChain中的基本Embedding类公开两种方法:
embed_documents:适用于多个文档embed_query:适用于单个文档
将这两种方法作为两种不同的方法的另一个原因是一些嵌入提供商对于需要搜索的文档和查询(搜索查询本身)具有不同的嵌入方法,下面是文本嵌入的集成示例:
Embaas
embaas是一种全面托管的NLP API服务,提供诸如嵌入生成、文档文本提取、文档转换为嵌入等功能。我们可以选择各种预训练模型。下面展示的是如何使用embaas的嵌入API为给定的文本生成嵌入:
# Set API key
embaas_api_key = "YOUR_API_KEY"
# or set environment variable
os.environ["EMBAAS_API_KEY"] = "YOUR_API_KEY"
from langchain.embeddings import EmbaasEmbeddings
embeddings = EmbaasEmbeddings()
# Create embeddings for a single document
doc_text = "This is a test document."
doc_text_embedding = embeddings.embed_query(doc_text)
# Print created embedding
print(doc_text_embedding)
# Create embeddings for multiple documents
doc_texts = ["This is a test document.", "This is another test document."]
doc_texts_embeddings = embeddings.embed_documents(doc_texts)
# Print created embeddings
for i, doc_text_embedding in enumerate(doc_texts_embeddings):print(f"Embedding for document {i + 1}: {doc_text_embedding}")
# Using a different model and/or custom instruction
embeddings = EmbaasEmbeddings(model="instructor-large", instruction="Represent the Wikipedia document for retrieval")
Fake Embeddings
LangChain还提供了伪造嵌入(Fake Embeddings)类,我们可以使用它来测试流程:
from langchain.embeddings import FakeEmbeddings
embeddings = FakeEmbeddings(size=1352)
query_result = embeddings.embed_query("foo")
doc_results = embeddings.embed_documents(["foo"])
Google Vertex AI PaLM
Google Vertex AI PaLM是与Google PaLM集成是分开的。Google选择通过GCP提供PaLM的企业版,它支持通过GCP提供的模型。Vertex AI上的PaLM API是预览版本,受GCP特定服务条款的预GA产品条款的约束。GA产品和功能具有有限的支持,并且对GA版本的产品和功能的更改可能与其他GA版本不兼容。有关更多信息,我们可以参阅发布阶段描述。另外,使用Vertex AI上的PaLM API即表示同意生成式AI预览版本的条款和条件(预览版条款)。对于Vertex AI上的PaLM API,我们可以根据“云数据处理附加协议”中概述的适用限制和义务,在合同(如预览版条款中所定义)中处理个人数据。要使用Vertex AI PaLM,我们必须安装google-cloud-aiplatform Python包,并且配置了我们的环境的凭据并将服务帐号JSON文件的路径存储为GOOGLE_APPLICATION_CREDENTIALS环境变量。下面的代码库使用了google.auth库,该库首先查找上述应用凭据变量,然后查找系统级身份验证:
#!pip install google-cloud-aiplatform
from langchain.embeddings import VertexAIEmbeddings
embeddings = VertexAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
Hugging Face Hub
我们加载Hugging Face Embedding类:
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="bert-base-uncased")
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
HuggingFace Instruct
我们加载HuggingFace Instruct Embeddings类:
from langchain.embeddings import HuggingFaceInstructEmbeddings
embeddings = HuggingFaceInstructEmbeddings(query_instruction="Represent the query for retrieval: "
)
load INSTRUCTOR_Transformer
max_seq_length 512
text = "This is a test document."
query_result = embeddings.embed_query(text)
Jina
我们加载Jina Embedding类:
from langchain.embeddings import JinaEmbeddings
embeddings = JinaEmbeddings(jina_auth_token=jina_auth_token, model_name="ViT-B-32::openai")
text = "这是一个测试文档。"
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
Llama-cpp
这个示例介绍了如何在LangChain中使用Llama-cpp embeddings:
!pip install llama-cpp-python
from langchain.embeddings import LlamaCppEmbeddings
llama = LlamaCppEmbeddings(model_path="/path/to/model/ggml-model-q4_0.bin")
text = "这是一个测试文档。"
query_result = llama.embed_query(text)
doc_result = llama.embed_documents([text])
MiniMax
MiniMax提供了一个嵌入服务。以下示例演示如何使用 LangChain 与 MiniMax 推理进行文本嵌入交互:
import osos.environ["MINIMAX_GROUP_ID"] = "MINIMAX_GROUP_ID"
os.environ["MINIMAX_API_KEY"] = "MINIMAX_API_KEY"
from langchain.embeddings import MiniMaxEmbeddings
embeddings = MiniMaxEmbeddings()
query_text = "这是一个测试查询。"
query_result = embeddings.embed_query(query_text)
document_text = "这是一个测试文档。"
document_result = embeddings.embed_documents([document_text])
import numpy as npquery_numpy = np.array(query_result)
document_numpy = np.array(document_result[0])
similarity = np.dot(query_numpy, document_numpy) / (np.linalg.norm(query_numpy) * np.linalg.norm(document_numpy))
print(f"文档与查询之间的余弦相似度:{similarity}")
输出:
文档与查询之间的余弦相似度:0.1573236279277012
ModelScope
我们加载 ModelScope 嵌入类:
from langchain.embeddings import ModelScopeEmbeddings
model_id = "damo/nlp_corom_sentence-embedding_english-base"
embeddings = ModelScopeEmbeddings(model_id=model_id)
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_results = embeddings.embed_documents(["foo"])
MosaicML
MosaicML提供了一个托管的推理服务。我们可以使用各种开源模型,也可以部署我们自己的模型。以下示例演示如何使用LangChain与MosaicML推理服务进行文本嵌入交互:
# 注册账号:https://forms.mosaicml.com/demo?utm_source=langchainfrom getpass import getpassMOSAICML_API_TOKEN = getpass()
import osos.environ["MOSAICML_API_TOKEN"] = MOSAICML_API_TOKEN
from langchain.embeddings import MosaicMLInstructorEmbeddings
embeddings = MosaicMLInstructorEmbeddings(query_instruction="Represent the query for retrieval: "
)
query_text = "This is a test query."
query_result = embeddings.embed_query(query_text)
document_text = "This is a test document."
document_result = embeddings.embed_documents([document_text])
import numpy as npquery_numpy = np.array(query_result)
document_numpy = np.array(document_result[0])
similarity = np.dot(query_numpy, document_numpy) / (np.linalg.norm(query_numpy)*np.linalg.norm(document_numpy))
print(f"Cosine similarity between document and query: {similarity}")
OpenAI
我们加载OpenAI嵌入类:
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
让我们加载第一代模型(例如:text-search-ada-doc-001/text-search-ada-query-001)的 OpenAI 嵌入类。需要注意的是其实这些模型并不推荐使用。
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
# 如果您在明确的代理后面,可以使用 OPENAI_PROXY 环境变量进行传递
os.environ["OPENAI_PROXY"] = "http://proxy.yourcompany.com:8080"
SageMaker Endpoint
我们加载SageMaker Endpoint Embeddings类。如果我们在SageMaker上托管自己的Hugging Face模型,则可以使用该类。需要注意的是,为了处理批量请求,我们需要调整自定义inference.py脚本中的predict_fn()函数中的返回行,即从return {"vectors": sentence_embeddings[0].tolist()}到return {"vectors": sentence_embeddings.tolist()}:
!pip3 install langchain boto3
from typing import Dict, List
from langchain.embeddings import SagemakerEndpointEmbeddings
from langchain.llms.sagemaker_endpoint import ContentHandlerBase
import jsonclass ContentHandler(ContentHandlerBase):content_type = "application/json"accepts = "application/json"def transform_input(self, inputs: list[str], model_kwargs: Dict) -> bytes:input_str = json.dumps({"inputs": inputs, **model_kwargs})return input_str.encode('utf-8')def transform_output(self, output: bytes) -> List[List[float]]:response_json = json.loads(output.read().decode("utf-8"))return response_json["vectors"]content_handler = ContentHandler()embeddings = SagemakerEndpointEmbeddings(# endpoint_name="endpoint-name", # credentials_profile_name="credentials-profile-name", endpoint_name="huggingface-pytorch-inference-2023-03-21-16-14-03-834", region_name="us-east-1", content_handler=content_handler
)
query_result = embeddings.embed_query("foo")
doc_results = embeddings.embed_documents(["foo"])
SelfHostedEmbeddings
我们加载SelfHostedEmbeddings、SelfHostedHuggingFaceEmbeddings和 SelfHostedHuggingFaceInstructEmbeddings类:
from langchain.embeddings import (SelfHostedEmbeddings,SelfHostedHuggingFaceEmbeddings,SelfHostedHuggingFaceInstructEmbeddings,
)
import runhouse as rh
# 对于 GCP、Azure 或 Lambda 上的按需 A100
gpu = rh.cluster(name="rh-a10x", instance_type="A100:1", use_spot=False)# 对于 AWS 上的按需 A10G(AWS 上没有单个 A100)
# gpu = rh.cluster(name='rh-a10x', instance_type='g5.2xlarge', provider='aws')# 对于现有的集群
# gpu = rh.cluster(ips=['<集群的 IP>'],
# ssh_creds={'ssh_user': '...', 'ssh_private_key':'<私钥路径>'},
# name='my-cluster')
embeddings = SelfHostedHuggingFaceEmbeddings(hardware=gpu)
text = "This is a test document."
query_result = embeddings.embed_query(text)
类似地,对于SelfHostedHuggingFaceInstructEmbeddings:
embeddings = SelfHostedHuggingFaceInstructEmbeddings(hardware=gpu)
现在我们使用自定义加载函数加载一个嵌入模型:
def get_pipeline():from transformers import (AutoModelForCausalLM,AutoTokenizer,pipeline,) # Must be inside the function in notebooksmodel_id = "facebook/bart-base"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id)return pipeline("feature-extraction", model=model, tokenizer=tokenizer)def inference_fn(pipeline, prompt):# Return last hidden state of the modelif isinstance(prompt, list):return [emb[0][-1] for emb in pipeline(prompt)]return pipeline(prompt)[0][-1]
embeddings = SelfHostedEmbeddings(model_load_fn=get_pipeline,hardware=gpu,model_reqs=["./", "torch", "transformers"],inference_fn=inference_fn,
)
query_result = embeddings.embed_query(text)
Sentence Transformers
使用HuggingFaceEmbeddings集成来调用Sentence Transformers嵌入。LangChain还为熟悉直接使用SentenceTransformer包的用户添加了SentenceTransformerEmbeddings的别名。SentenceTransformers是一个可以生成文本和图像嵌入的Python包,源自于SentenceBERT:
!pip install sentence_transformers > /dev/null
from langchain.embeddings import HuggingFaceEmbeddings, SentenceTransformerEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 等同于 SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text, "This is not a test document."])
TensorFlow Hub
TensorFlow Hub是一个包含训练好的机器学习模型的仓库,可随时进行微调并在任何地方部署。TensorFlow Hub 让我们可以在一个地方搜索和发现数百个已经训练好、可直接部署的机器学习模型。
from langchain.embeddings import TensorflowHubEmbeddings
embeddings = TensorflowHubEmbeddings()text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_results = embeddings.embed_documents(["foo"])
参考文献:
[1] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[2] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[文本嵌入模型Ⅱ])
自然语言处理从入门到应用——LangChain:模型(Models)-[文本嵌入模型Ⅱ]
分类目录:《自然语言处理从入门到应用》总目录 本文将介绍如何在LangChain中使用Embedding类。Embedding类是一种与嵌入交互的类。有很多嵌入提供商,如:OpenAI、Cohere、Hugging Face等,这个类旨在为所有这些提供一个标准接口。 …...

Olap BI工具对比
背景 目前公司主要使用数据存储有MySQL、ES、Hive、HBase、TiDB等 MySQL用于存储应用的基本支撑数据,数据量少;ES和Hbase用于存储和查询调用记录,数据量多;Hive和TiDB用于DC上使用,数据量多。主要使用的数据分析平台…...
【iOS】Cocoapods的安装以及使用
文章目录 前言一、Cocoapods的作用二、安装Cocoapods三、使用Cocoapods总结 前言 最近笔者在仿写天气预报App时用到了api调用数据,一般的基本数据类型我们用Xcode中自带的框架就可以转换得到。但是在和风天气api中的图标的格式为svg格式。 似乎iOS13之后Xcode中可…...

OpenCvSharp (C# OpenCV) 二维码畸变矫正--基于透视变换(附源码)
导读 本文主要介绍如何使用OpenCvSharp中的透视变换来实现二维码的畸变矫正。 由于CSDN文章中贴二维码会导致显示失败,大家可以直接点下面链接查看图片: C# OpenCV实现二维码畸变矫正--基于透视变换 (详细步骤 + 代码) 实现步骤 讲解实现步骤之前先看下效果(左边是原图,右边…...
下级平台级联视频汇聚融合平台EasyCVR,层级显示不正确的原因排查
视频汇聚平台安防监控EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有GB28181、RTSP/Onvif、RTMP等,以及厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等,能对外分发RTSP、RTMP、FLV、HLS、WebRTC等…...

Android程序CPU使用大的异常分析
程序出现CPU使用过高的问题,如果能够重现,就比较好办了,可以top命令查看各线程的cpu使用,定位到线程。 以下是问国内某AI的答案 在Android应用中,如果某个应用消耗了大量的CPU资源,可以采取以下方法进行分…...

[数学建模] 0、关于数学建模的一点看法付费专栏食用说明
文章目录 1、前言2、数学建模学习索引2.1、建模知识点 3、实战建模论文索引3.1、国赛真题索引3.1.1、[数学建模] [2001年国赛模拟] 1. 血管的三维重建3.1.2、[数学建模] [2011年B国赛模拟] 2. 交巡警服务平台的设置与调度3.1.3、[数学建模][2012年A国赛模拟] 3. 葡萄酒的评价 3…...

2.oracle数据库自增主键
不同于mysql,oracle主键自增不能在建表时直接设置,其实也很简单 1.建表 CREATE TABLE test(id NUMBER NOT NULL,key1 VARCHAR2(40) NULL,key2 VARCHAR2(40) NULL);2.设置主键 alter table test add constraint test_pk primary key (id);3.新建序列tes…...

算法通关村第二关——链表加法的问题解析
题目类型 链表反转、栈 题目描述 * 题目: * 给你两个非空链表来表示两个非负整数,数字最高位位于链表的开始位置。 * 它们的每个节点都只存储一个数字。将这两个数相加会返回一个新的链表。 * 你可以假设除了数字0外,这两个数字都不会以0开头…...

mapboxGL中楼层与室内地图的结合展示
概述 质量不够,数量来凑,没错,本文就是来凑数的。前面的几篇文章实现了楼栋与楼层单体化的展示、室内地图的展示,本文结合前面的几篇文章,做一个综合的展示效果。 实现效果 实现 1. 数据处理 要实现上图所示的效果…...

使用Anaconda3创建pytorch虚拟环境
一、Conda配置Pytorch环境 1.conda安装Pytorch环境 打开Anaconda Prompt,输入命令行: conda create -n pytorch python3.6 输入y,再回车。 稍等,便完成了Pytorch的环境安装。我们可以利用以下命令激活pytorch环境。 conda…...

QT 常用数据结构整理
目录 QString篇 QString篇 //初始化bool bOk false;QString str "sd";QString strTemp(str);str QString("%1,%2").arg("11").arg("-gg");qDebug()<<str;str.sprintf("%s %d","ni",1);qDebug()<<…...

Fiddler使用教程|渗透测试工具使用方法Fiddler
提示:如有问题可联系我,24小时在线 文章目录 前言一、Fiddler界面介绍二、菜单栏1.菜单Fiddler工具栏介绍Fiddler命令行工具详解 前言 网络渗透测试工具: Fiddler是目前最常用的http抓包工具之一。 Fiddler是功能非常强大,是web…...
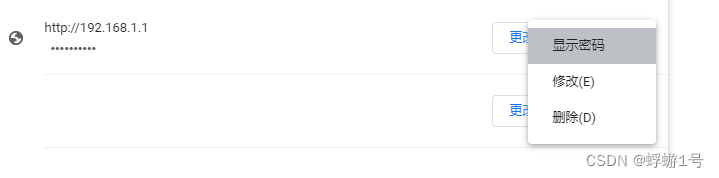
网站密码忘记了怎么办?chrome浏览器,谷歌浏览器。
有时候忘记了网站的密码,又不想“忘记密码”去一番折腾。如果你正好用的是 chrome 浏览器。 那么根本就没必要折腾,直接就能看到网站密码。 操作如下 1.在浏览器右上角点击三个小点: 2.点这三个点: 3.选择“显示密码”&#x…...

23款奔驰GLS450加装原厂香氛负离子系统,清香宜人,久闻不腻
奔驰原厂香氛合理性可通过车内空气调节组件营造芳香四溢的怡人氛围。通过更换手套箱内香氛喷雾发生器所用的香水瓶,可轻松选择其他香氛。香氛的浓度和持续时间可调。淡雅的香氛缓缓喷出,并且在关闭后能够立刻散去。车内气味不会永久改变,香氛…...
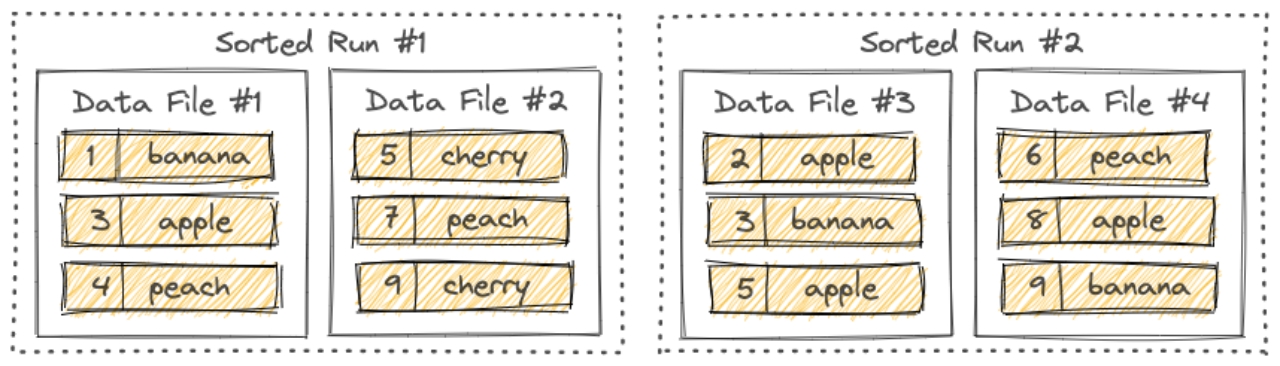
流数据湖平台Apache Paimon(一)概述
文章目录 第1章 概述1.1 简介1.2 核心特性1.3 基本概念1.3.1 Snapshot1.3.2 Partition1.3.3 Bucket1.3.4 Consistency Guarantees一致性保证 1.4 文件布局1.4.1 Snapshot Files1.4.2 Manifest Files1.4.3 Data Files1.4.4 LSM Trees 第1章 概述 1.1 简介 Flink 社区希望能够将…...
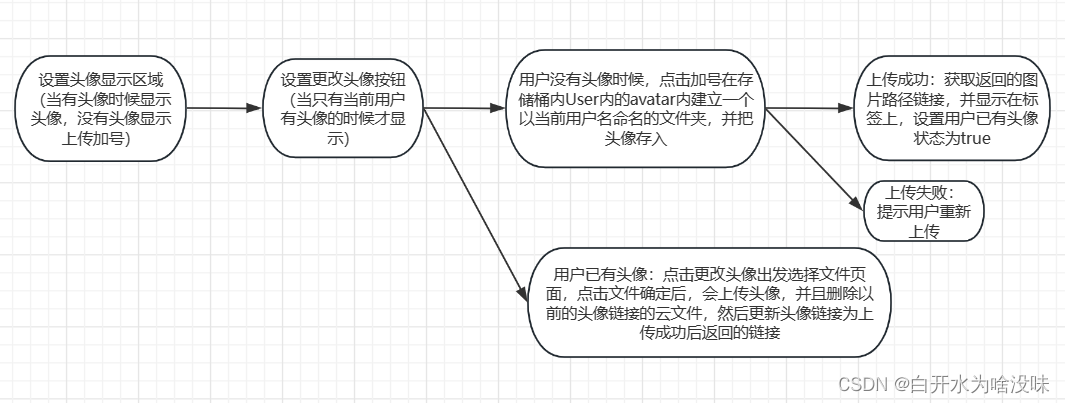
上传图片到腾讯云对象存储桶cos 【腾讯云对象存储桶】【cos】【el-upload】【vue3】【上传头像】【删除】
1、首先登录腾讯云官网控制台 进入对象存储页面 2、找到跨越访问CIRS设置 配置规则 点击添加规则 填写信息 3、书写代码 这里用VUE3书写 第一种用按钮出发事件形式 <template><div><input type"file" change"handleFileChange" /><…...

Hadoop教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System)࿰…...
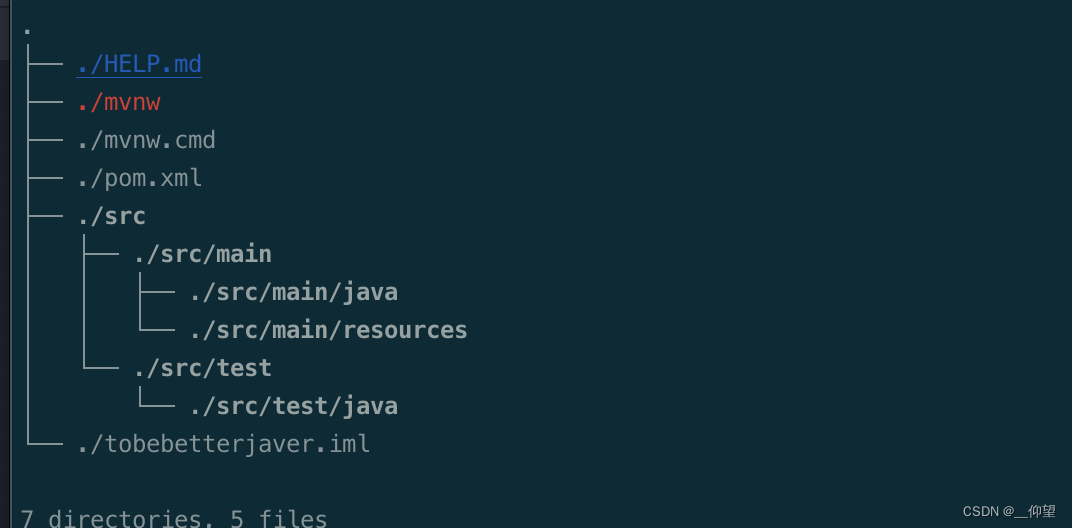
Mac 快速生成树形项目结构目录
我这里使用的是通过包管理 Homebrew安装形式。没有安装的话可以自行搜索 Homebrew 安装方式 brew install tree直接到项目的根目录执行 tree 命令 tree 效果如下: or : tree -CfL 3效果如下:...

使用fegin调用时,返回的值不能直接List这种,要使用对象包装一下
正确使用如下 fegin ResponseBodyGetMapping(value "/menu/queryAllNonLowCodePageSubmenuById")public Result<List<LinkTheFormPageDataDTO>> queryAllNonLowCodePageSubmenuById(RequestParam("id")int id);服务 ResponseBodyGetMapping(…...

尤斯伯恩书籍购买指南:多语言版本可选,不同地区购买方式大揭秘!
按年龄浏览书籍 如果禁用了 cookies,商店将无法正常工作。您的浏览器似乎禁用了 JavaScript。为了在我们的网站上获得最佳体验,请确保在浏览器中启用 JavaScript。跳转到内容,英语 - 英镑 £,选择语言:英语、法语、…...

黑龙江移远科技,是懂预算、懂场景、更懂服务的专业服务商
很多人误以为移远科技只是简单卖设备的贸易公司,实则不然。依托全品牌货源优势、极致性价比、五星贴心服务、专属方案定制,企业早已从传统销售商,升级为综合性通讯安防解决方案服务商,全方位解决客户采购难、选型难、售后难、预算…...

Keil C251中RTX251配置错误解决方案
1. RTX251配置错误问题解析与修复指南最近在使用Keil C251开发工具时,遇到了一个典型的RTX251实时操作系统配置问题。当尝试编译TRAFFIC2、SAMPLE或INTRPT示例项目时,系统在汇编RTXCONF.A51文件时抛出了大量"UNDEFINED SYMBOL"错误。这个问题困…...

CVPR 2019 RKD论文复现踩坑记:从理论公式到可运行的PyTorch代码全解析
CVPR 2019 RKD论文复现实战:从数学推导到工业级PyTorch实现的关键细节当我在实验室第一次尝试复现CVPR 2019的Relational Knowledge Distillation(RKD)算法时,原以为按照论文公式直接编码就能快速跑通实验。但实际动手后才发现&am…...

室内点云轮廓提取
1 简介 室内点云轮廓提取是三维感知中的一项基础处理技术,它的核心作用是将杂乱、海量的原始点云,转化为简洁、有意义的几何边界。主要用处体现在以下几个方面: 1 机器人导航与避障 轮廓提取能实时勾勒出墙壁、家具、门窗等障碍物的边缘,帮助扫地机器人、服务机器人快速理…...

基于图神经网络的机器学习有限区域模型:边界处理与图结构设计实战
1. 项目概述与核心挑战最近几年,机器学习天气预测(MLWP)的进展让人有点兴奋,又有点眼花缭乱。从全球尺度的大模型到区域性的精细化预报,数据驱动的方法正在重新定义我们对大气模拟的理解。作为一名长期混迹在气象和计算…...
—— 进阶篇)
STM32内核精讲 | 第七章:异常与中断系统(NVIC)—— 进阶篇
💡 本文是《STM32内核精讲》栏目的第七篇。上一篇我们学习了异常类型、向量表以及 NVIC 的基础寄存器操作(使能/禁止、挂起/清除、优先级配置)。本篇将继续深入 NVIC 的核心机制:优先级分组、晚到与尾链、EXC_RETURN 的奥秘&#…...

r2frida:打通Radare2静态分析与Frida动态调试的逆向工程工作流
1. 为什么你还在用 Frida CLI 单打独斗,而高手早已把 Radare2 的逆向能力“焊”进动态分析流程? 如果你做过 Android 或 iOS 应用的深度安全分析,大概率经历过这样的场景:Frida hook 到目标函数后,看到 this 指针指…...

麒麟KYLINOS声音设置进阶:用命令行玩转‘寻光’主题、单声道和侦听模式
麒麟KYLINOS声音设置进阶:用命令行玩转‘寻光’主题、单声道和侦听模式对于追求系统深度定制的极客用户、音频工作者或无障碍功能使用者来说,图形界面往往只是冰山一角。麒麟KYLINOS基于UKUI桌面的声音子系统隐藏着诸多实用功能,通过命令行可…...
)
【AI问答/前端】前端瞒天过海局(三)
问三:还有一件事,就是浏览器按钮的前进后退,他真实还原了js改前端的过程,就好像真的有过访问纪录,这个是JS纪录下了自己的路由操作历史,改的浏览器地址栏?还是这个路由操作历史真的是写进了浏览…...