初步了解预训练语言模型BERT

本文字数::4024字
预计阅读时间:12分钟
BERT是由Google提出的预训练语言模型,它基于transformer架构,被广泛应用于自然语言处理领域,是当前自然语言处理领域最流行的预训练模型之一。而了解BERT需要先了解注意力机制与Transformers。
注意力机制
注意力机制(Attention Mechanism)是一种在机器学习和自然语言处理中广泛使用的技术,它可以帮助模型在处理输入数据时集中关注其中最重要的部分,从而提高模型的准确性。
原理
注意力机制最初是从认知神经科学中引入到机器学习领域的,19世纪90年代的威廉·詹姆斯发现人类注意力焦点受到非自主性提示和自主性提示有选择地引导[7]。简单来说,非自主性提示是一种无意注意,例如人会先看到最显眼的物品,而自主性提示是一种有意注意,例如人会根据自己的需要先关注到自己需要到物品。非自主性提示与自主性提示会导致人类神经网络选择性地加强或减弱一些特定的神经元的活动。
在机器学习中,注意力机制模拟了人类的这种认知行为,采用的方式主要是通过查询向量query模拟自主提示,键值向量key模拟非自主提示,二者交互形成注意力焦点,从而有选择的聚合了值向量value(模拟感官输入)最终形成输出[8]。具体的计算过程可以用下图表示:
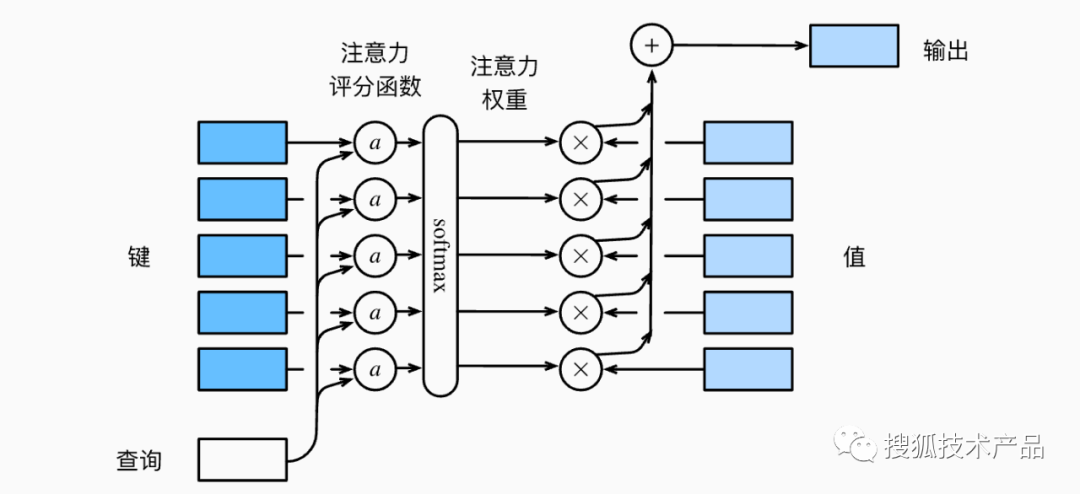
图1 注意力得分计算示意图
假设有一个查询向量q∈Rq和m个“键—值”对(k1,v1),...,(km,vm),其中ki∈Rk,vi∈Rv。在计算注意力得分时,首先通过注意力评分函数a将查询向量q和键向量ki映射成标量,不同的注意力评分函数可以产生不同的注意力汇聚效果,常见的有缩放点积注意力评分函数(公式1)
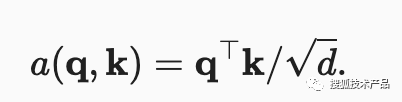
公式1
再经过softmax运算,得到注意力权重α(公式2),
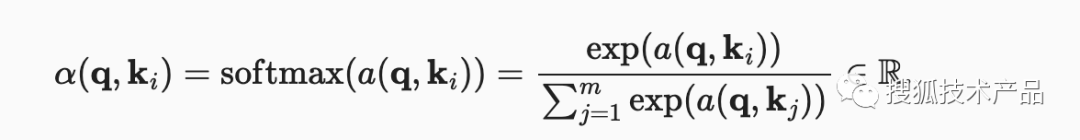
公式2
而最终的输出也就是注意力权重与值向量的加权和:
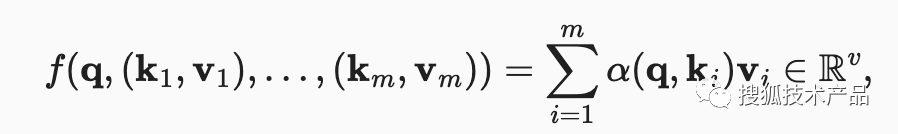
公式3
在实际应用中,通常将同一组词源输入到注意力池化中,以便同一组词元同时充当query、key和value。具体来说,每个query都会关注所有的key-value对并产生一个注意力输出。由于query、key和value来自同一组输入,因此被称为自注意力(self-attention)。
Transformer
transformers是继MLP,RNN,CNN(第四大类模型架构),最早被google research团队 Ashish Vaswani 等人提出,是一种完全基于注意力机制的encoder-decoder架构,最早应用于机器翻译这个任务。在transformer之前,主要采用依赖神经网络的注意力模型,但是RNN、CNN等传统神经网络在处理长序列数据时效率较低,而自注意力机制同时具有并行计算和最大路径长度两个优势,而完全基于注意力机制的transformer模型解决了传统神经网络的问题。
Transformer的核心思想是使用注意力机制来实现序列中的信息交互,它将输入序列和输出序列中的每一个元素连接起来,同时对它们进行加权计算,以决定对于当前元素的关注程度。这种机制将整个输入序列通过Encoders编码成一个编码向量,再通过Decoders将之解码为输出序列,从而实现了序列到序列的转换,可以用来完成机器翻译、文本生成等任务。在实际应用中,encoders和decoders可以单独使用。简单的模型如下图所示(图2),Encoders是由6个结构相同encoder组成,但是每个encoder参数不相同;Decoders是由6个结构相同decoder组成,但是每个decoder参数不相同;
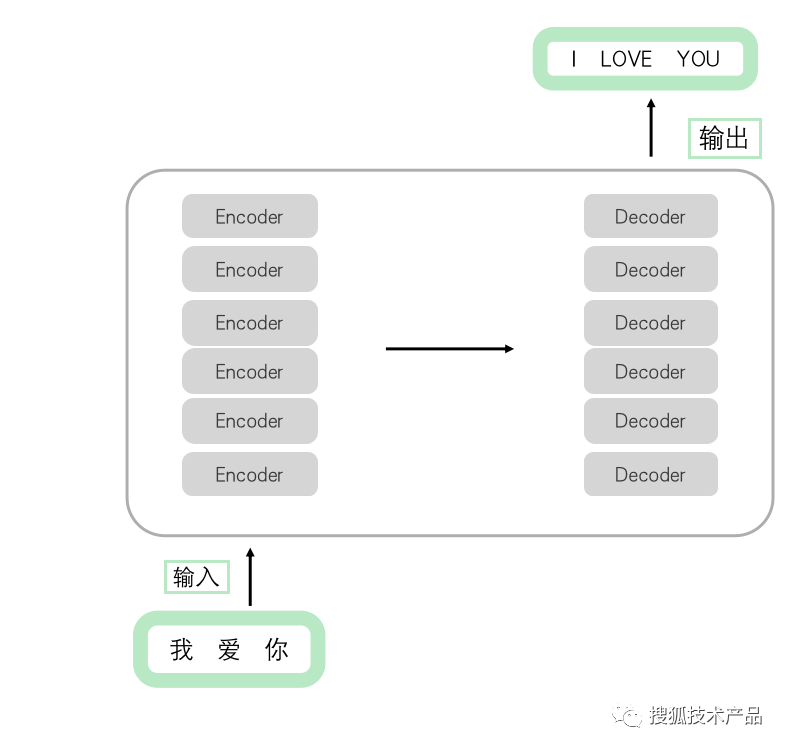 图2 注意力模型结构图
图2 注意力模型结构图
Transformer的整体网络架构中的encoder和decoder都采用多层堆叠的自注意力机制。encoder将输入序列转换成隐藏表示,decoder将隐藏表示转换成输出序列。其整体架构图如下图3所示,其中左边是encoder,右边是decoder,下面我将结合下图详细介绍encoder和decoder的内部实现。
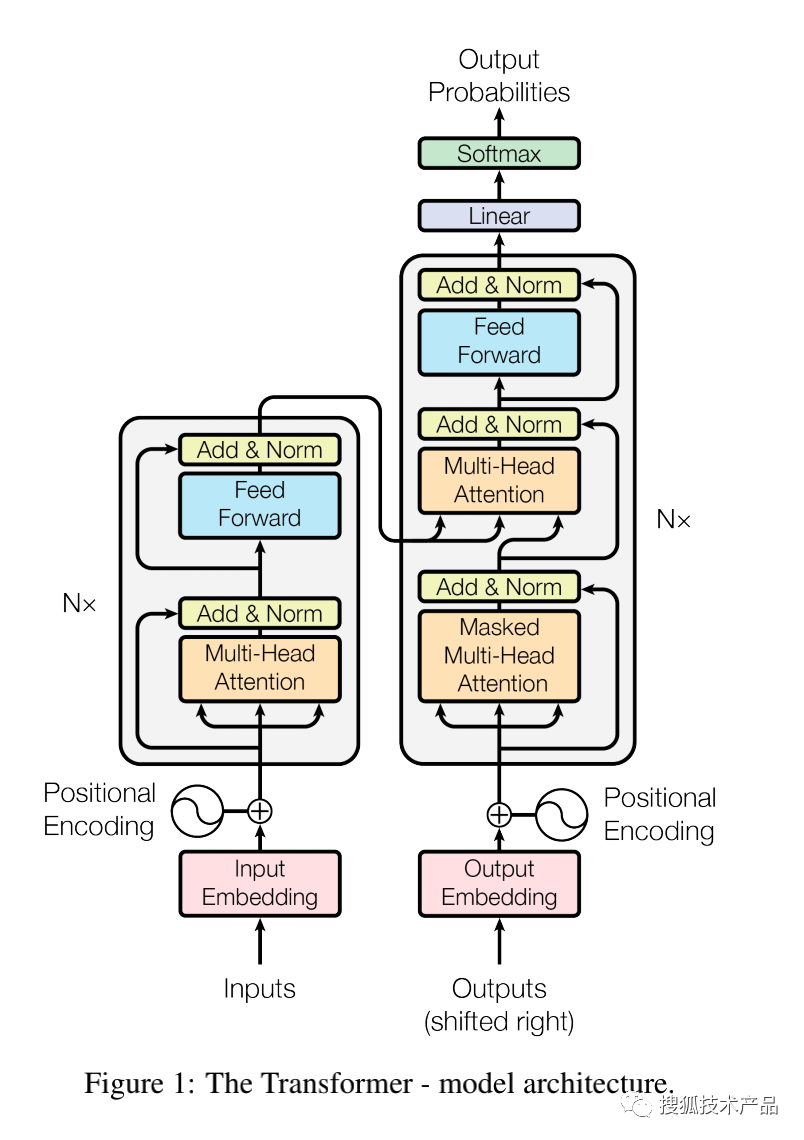
encoder
对于encoder,输入数据首先通过一个嵌入层(embedding layer)将每个单词转化为一个向量表示,由于注意力机制不是顺序读取码元的,所以在输入中会加上位置编码信息(positional encoding),位置编码加上输入向量就构成了注意力机制的输入。如上图所示,输入向量会分为查询向量(query,下文简写为q)、键向量(key,下文简写为k)、值向量(value,下文简写为v)三个向量输入到多头注意力(Muiti-Head Attention)中,其中由输入向量得到q、k、v的过程如下图所示。
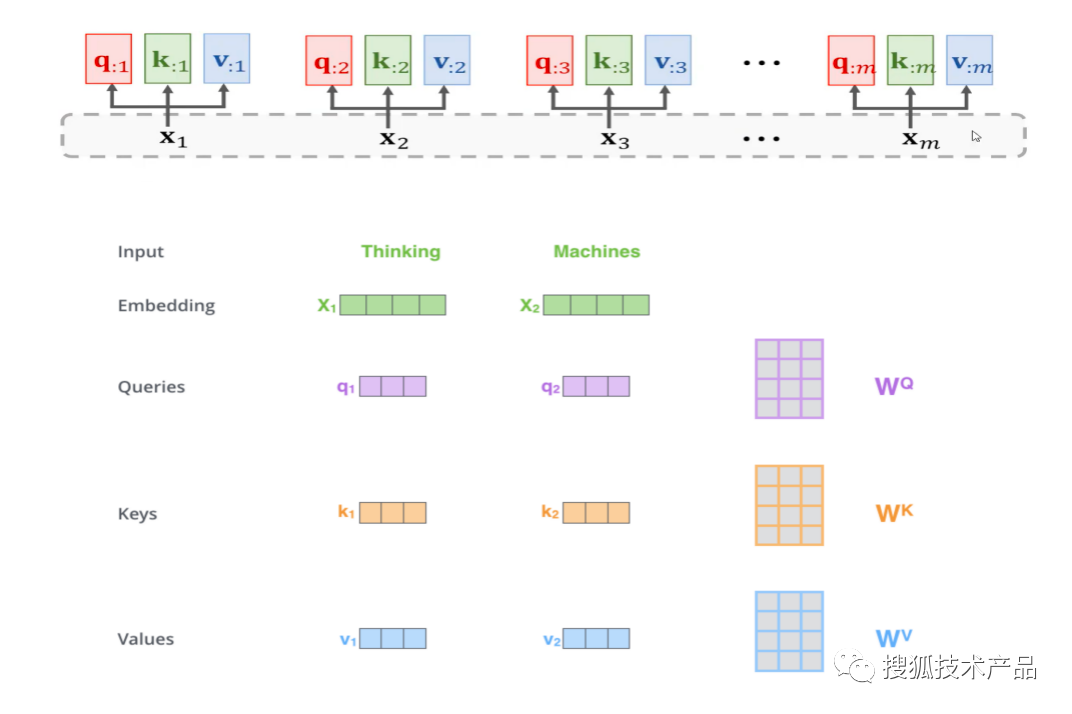
q、k、v是通过每一个输入向量x分别投影到WQ、 WK、WV矩阵得到的,而其中WQ、 WK、WV最初是随机初始化得到,然后不断学习更新。在多头注意力机制中,就是通过多套WQ、 WK、WV不同的参数矩阵实现的,具体实现方式是将q、k、v投影到低维度矩阵,投影h次,也就是h头注意力。使用多头注意力的好处就是可以通过多角度学习输入的信息,从而提升学习的效果。
得到q、k、v向量后,就可以根据上文介绍的注意力机制在Muiti-Head Attention中得到注意力的输出。这里的注意力公式如下所示(公式5),该公式可由上文的2-1公式推演得出。
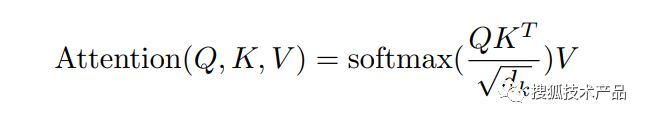
其中q、k、v这三个参数由上文介绍的过程投影得出的矩阵,dk表示向量长度。这里是k和q做内积,每个词的q与所有的词k(包括本身)做内积,得到每个向量的相似度,可以理解为当前词与整句话里所有词的相似度。每个词都要做一遍上述计算,然后softmax之后输出注意力权重,得到的一套注意力权重和所有的字v做加权和(相乘再相加) ,就是当前词最后的输出。在多头注意力中,就是经过多次注意力函数,然后将输出拼接在一起,在经过高维度矩阵投影回来,得到多头注意力的输出。
在多头注意力层外,每个子层都采用了残差连接和层规范化机制,也就是上图2-3中的Add&Norm,这两者是构成深度架构的关键,可以有效地避免梯度消失或爆炸问题,提升模型性能。残差连接是指在每个子层之后都加入了一个直接连接,将输出与未经过注意力机制的输入进行相加,使得模型可以直接学习到残差信息。层规范化则是对于每个子层的输出进行标准化处理,避免了输入项的数值不同而导致的训练过程中的不稳定性。
最后,每个子层后接一个前馈神经网络(feed-forward neural network),作为最后一步转换。前馈神经网络采用门控线性单元(gated linear unit, GLU)的形式,这样做的目的是为了实现语义空间的转换,有效的使用序列信息,将已经抓取出来的序列信息映射到更想要的那个语义空间,增加模型的拟合能力。经过多层堆叠的encoder会生成一个编码向量,作为decoder的输入。
decoder
对于decoder,可以看作是encoder的逆过程。从上图3中可以看出encoder和decoder的不同之处主要在于decoder有两个注意力机制,第一个是mask-attention,第二个是与encoder部分相同的多头注意力机制。decoder的第一个mask-attention是为了防止后面信息参与计算,将后面的词mask掉,被mask掉的词就不参与计算,从而保留自回归属性。decoder第二个多头注意力,q、k、v维度是一样的,其中k、q来自上一层encoder的输出,然后作用于value上,这一层的作用可以理解为encoder的输出汇聚出想要的信息。与encoder相同,在经过注意力机制后输出的作为前馈神经网络的输入,实现语义空间的转换,同样decoder中的子层也被残差连接和紧随的层规范化围绕。
BERT
BERT全称Bidirectional Encoder Representations from Transformers,是Google于2018年提出的一种基于Transformer模型的预训练模型。BERT基于Transformer模型,通过多任务学习的方式,在大规模无标注的语料库上进行预训练,并对各种下游自然语言处理任务进行微调,取得了极好的成绩。
BERT的核心原理是通过多层双向Transformer编码器,将输入文本表示成高维语义空间中的向量,使得语义相近的词或句子在向量空间内彼此接近。与传统基于语言学规则或统计方法的自然语言处理技术相比,BERT可以从大规模的无标注文本中学习到更全局、更复杂的语义信息,取得了更好的效果。
在BERT中,与原始Transformer模型不同的是,通过双向Transformer编码器,BERT能够更好地捕捉上下文的相关性,在单词或句子级别上对文本进行建模。此外,BERT采用了掩码语言建模和下一句预测等多种预训练任务,进一步提高了模型的泛化能力。
具体来说,BERT通过多层堆叠的Transformer 编码器来对输入文本进行建模,并采用掩码技术,让编码器只能看见输入序列中一部分的信息,从而使得编码器具有非常强的泛化能力。此外,BERT还利用了两个新的预训练任务,即掩码语言建模和下一句预测,来增强模型对上下文的理解。
在掩码语言建模任务中,采用了一种类似于“完形填空”的思路构建掩码模型。BERT随机掩盖句子中的一些单词具体方式是随机把一句话中15%的token(字)替换成以下内容:
(1)这些token有80%的几率被替换成[MASK]
(2)有10%的几率被替换成任意一个其它的token
(3)有10%的几率原封不动。完成掩码后,再用模型预测这些掩盖掉的单词。
在下一句预测任务中,BERT输入一对句子,模型判断这两个句子对是连续的还是随机采样两个句子放在一起的。这些任务都是基于无标注文本的,通过预训练让BERT学习理解语言的能力,从而可以在下游任务中取得更好的效果。
BERT模型的输入主要包括三个部分:token embedding、segment embedding和position embedding。其中,token embedding表示为每个输入词汇对应的向量表示;而segment embedding和position embedding则分别表示为每个句子对应的标识符和每个词在序列中的位置信息。具体来说,对于输入句子中的每个词汇,BERT模型都会将其转化为一个向量表示,这个向量表示是该词汇在BERT模型的预训练过程中学习得到的。同时,BERT模型还会在输入的每个句子之前加上一个特殊的标记[CLS],在每个句子之后加上另一个标记[SEP],以便模型学习句子之间的关系。
在输入数据的基础上,BERT模型还需要进行构造数据的处理。具体来说,BERT模型会把输入的文本序列按照一定的规则组合起来,构造成一段首尾各有一个特殊标记的文本序列。在这个文本序列中,对于两个句子之间的分界点,BERT模型会用一个特殊的segment embedding进行区分。同时,对于每个词在序列中的位置信息,BERT模型也会使用一个特殊的position embedding进行标记。
通过对输入数据的处理,BERT模型可以将文本序列转换成一个高维向量表示,这个高维向量通常被称为上下文向量。BERT模型的输出则主要包括上下文向量和[CLS]标记对应的向量。其中,上下文向量可以用来进行各种下游任务的特征提取和计算,而[CLS]标记对应的向量则通常被用作整个文本序列的汇总表示,它可以用来进行文本分类、语义相似度计算等任务。在语意相似度计算任务中,得到的语义向量会作为特征输入给一个线性分类器,如逻辑回归或支持向量机等,在此基础上进行二分类或多分类的任务,从而实现语意相似度的计算。
在BERT模型中,由于使用了横向和纵向的自注意力机制,可以充分地考虑和利用不同位置和不同上下文的信息,但也导致了模型对于不同维度和方向的信息处理能力不同,此外,自注意力机制无法处理一些长序列的依赖关系问题,因此在计算时会将过长的文本或序列截断,这也会导致模型对于长序列中不同方向和不同偏移量的编码能力存在差异,这都会导致各项异性的问题,从而进一步影响结果的准确性。
相关文章:
初步了解预训练语言模型BERT
本文字数::4024字 预计阅读时间:12分钟 BERT是由Google提出的预训练语言模型,它基于transformer架构,被广泛应用于自然语言处理领域,是当前自然语言处理领域最流行的预训练模型之一。而了解BERT需要先了解注…...

Android Hook系统 Handler 消息实现
前言 主线程的Handler 主要依赖于 ActivityThread,Android是消息驱动,比如view的刷新,activity的创建等,如果能打印系统层Handler消息日志,就需要对于系统层的Handler 进行Hook 原理 ActivityThread中 mH对象主要负责…...

R语言从入门到精通之【R语言的使用】
系列文章目录 1.R语言从入门到精通之【R语言介绍】 2.R语言从入门到精通之【R语言下载与安装】 3.R语言从入门到精通之【R语言的使用】 文章目录 系列文章目录一、新手上路1.R语句构成2.获取帮助3.工作空间二、包1.包的安装2.实践应用总结一、新手上路 1.R语句构成 R语句由函…...

WPF实战学习笔记29-登录数据绑定,编写登录服务
添加登录绑定字段、命令、方法 修改对象:Mytodo.ViewModels.ViewModels using Mytodo.Service; using Prism.Commands; using Prism.Events; using Prism.Mvvm; using Prism.Services.Dialogs; using System; using System.CodeDom.Compiler; using System.Collec…...

c++函数式编程:统计文件字符串,文件流
头文件 #include <iostream> #include <fstream> #include <string> #include <sstream> #include <algorithm> #include <vector>统计方法 int count_lines(const std::string &filename) {std::ifstream in{filename};return std:…...

scp命令----跨服务器传输文件
scp命令 Linux scp 命令用于 Linux 之间复制文件和目录。 scp 是 secure copy 的缩写, scp 是 linux 系统下基于 ssh 登陆进行安全的远程文件拷贝命令。 scp 是加密的,rcp 是不加密的,scp 是 rcp 的加强版。 一、Linux scp 命令 以下是scp命令常用的…...
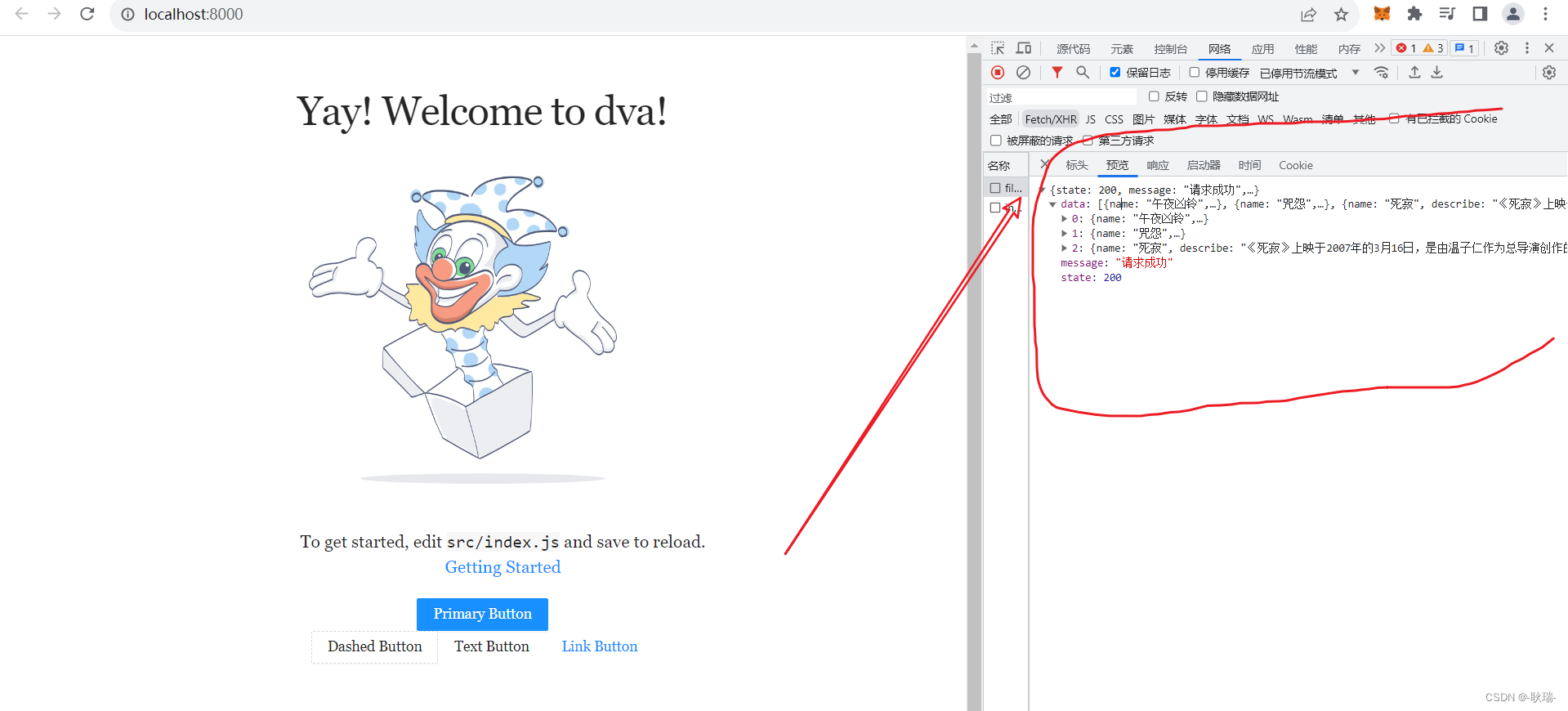
React Dva项目中模仿网络请求数据方法
我们都已经选择react了 那么自然是一个前后端分离的开发形式 至少我在公司中 大部分时候是前后端同时开发的 一般你在开发界面没有接口直接给你 但你可以和后端约定数据格式 然后在前端模拟数据 我们在自己的Dva项目中 在根目录下的 mock 目录下创建一个js文件 我这里叫 filmDa…...
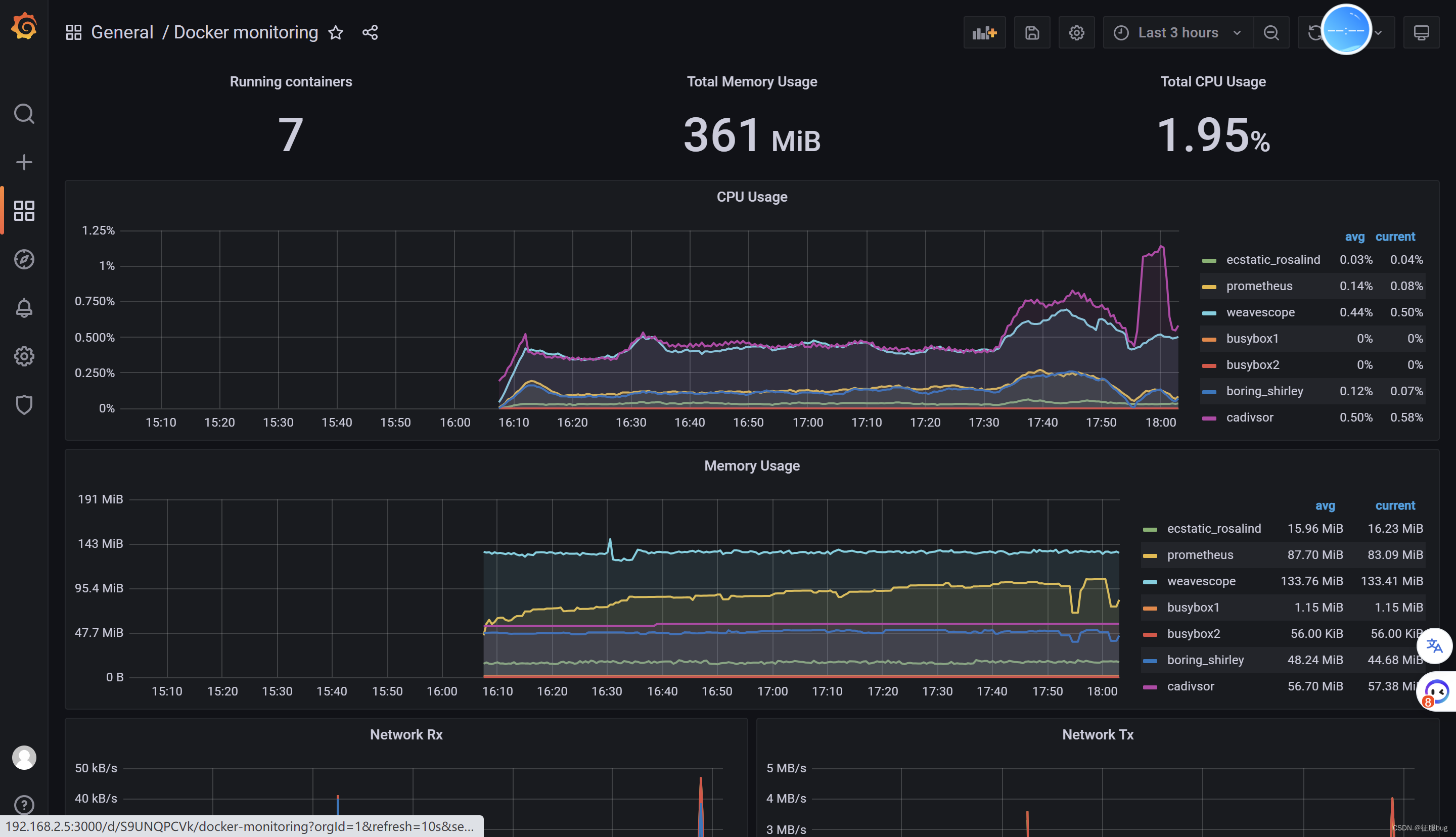
【云原生】Docker容器命令监控+Prometheus监控平台
目录 1.常用命令监控 docker ps docker top docker stats 2.weave scope 1.下载 2.安装 3.访问查询即可 3.Prometheus监控平台 1.部署数据收集器cadvisor 2.部署Prometheus 3.部署可视化平台Gragana 4.进入后台控制台 1.常用命令监控 docker ps [rootlocalhost ~…...

DBA 职责及日常工作职责
DBA 职责及日常工作职责: 1.安装和升级数据库服务器,以及应用程序工具构建和配置网络环境. 2.熟悉数据库系统的存储结构预测未来的存储需求,制订数据库的存储方案. 3.根据开发人员设计的应用系统需求创建数据库存储结构. 4.根据开发人员设计的应用系统需求创建数据库对象 5…...

如何利用量化接口进行数据分析和计算?
量化交易作为一种利用数据和算法进行投资的方式,数据分析和计算是量化交易的核心。量化接口作为连接量化交易者和交易所的桥梁,提供了获取市场数据和执行交易指令的功能,为量化交易的数据分析和计算提供了基础。 一、数据获取: 市…...
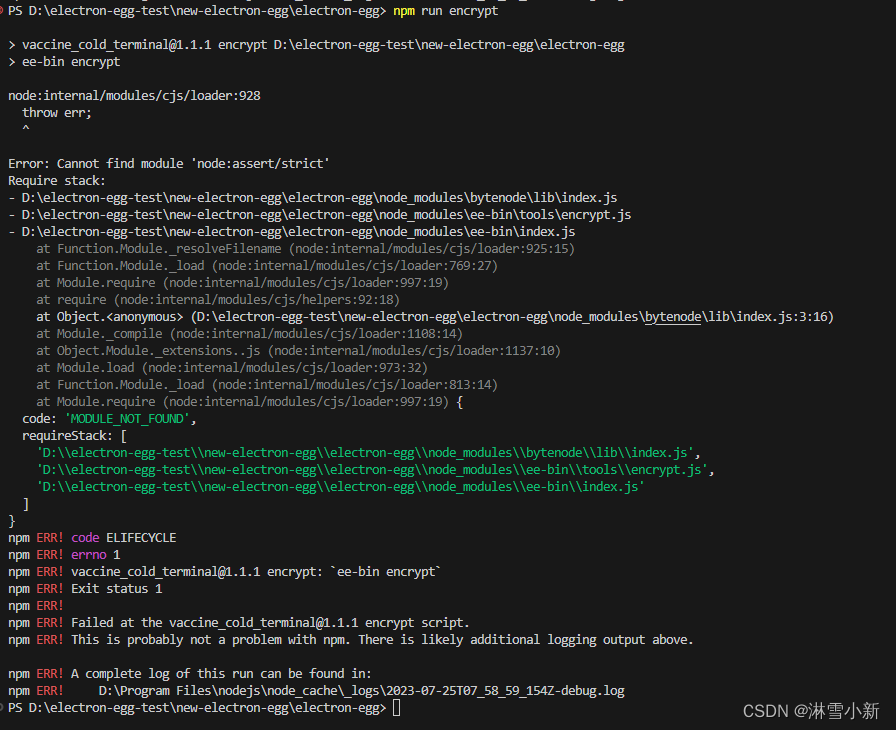
electron-egg 加密报错
electron框架:electron-egg 解决方式 npm uninstall bytenode npm install bytenode1.3.6node:internal/modules/cjs/loader:928 throw err; ^ Error: Cannot find module ‘node:assert/strict’ Require stack: D:\electron-egg-test\new-electron-egg\electr…...
)
循环队列的基本操作(3种处理方式,2种实现方式)
为区分队空队满有3种处理方式: ①牺牲一个单元 ②增设表示元素个数的数据成员 ③增设tag数据成员 1.front->队头元素,rear->队尾元素下一位置 1.1牺牲一个单元 1.1.1定义 #define MaxSize 50 typedef struct {ElemType data[MaxSize];int fron…...

react的特点
React的特点包括以下几个方面: 组件化:React将用户界面分解成小而独立的组件,每个组件都有自己的状态和属性。通过组合这些组件,可以构建复杂而灵活的用户界面。 虚拟DOM:React使用虚拟DOM(Virtual DOM&am…...
)
MATLAB实现图像处理:图像识别、去雨、去雾、去噪、去模糊等等(附上20个完整仿真源码)
图像处理是计算机视觉领域的重要研究方向,MATLAB是一种功能强大的数学计算软件,可以用于图像处理和分析。下面是一些简单的MATLAB图像处理代码示例,包括图像增强、边缘检测、形态学处理、特征提取等。 文章目录 1. 图像增强2. 边缘检测3. 形态…...

cmake stm32 模板
文件结构 ├─.vscode ├─build ├─cmake ├─Drivers │ ├─CMSIS │ │ ├─Device │ │ │ └─ST │ │ │ └─STM32F1xx │ │ │ ├─Include │ │ │ └─Source │ │ │ └─Templates │ │ └─Include │ └─STM32F1xx_HAL_Driver │ ├─Inc │ │ └─Leg…...
STM32 UDS Bootloader开发-上位机篇-CANoe制作(2)
文章目录 前言CANoe增加NodeCAPL脚本获取GUI中的参数刷写过程诊断仪在线接收回调函数发送函数总结前言 在上一篇文章中,介绍了UDS Bootloadaer上位机软件基于CANoe的界面设计。本文继续介绍CAPL脚本的编写以实现刷写过程。 CANoe增加Node 在开始编写CAPL之前,需要在Simula…...

实例026 随机更换主界面背景
实例说明 如果开发的软件用户使用频率非常高,可以为程序设计随机更换背景的程序。这样不但可以使用户心情愉快,也增加了软件的人性化设计。下面的界面就是一个随机更换主界面的例子,效果如图1.26所示。 技术要点 随机更换主界面背景使用了…...
PostgreSQL 简洁、使用、正排索引与倒排索引、空间搜索、用户与角色
PostgreSQL使用 PostgreSQL 是一个免费的对象-关系数据库服务器(ORDBMS),在灵活的BSD许可证下发行。PostgreSQL 9.0 :支持64位windows系统,异步流数据复制、Hot Standby;生产环境主流的版本是PostgreSQL 12 BSD协议 与 GPL协议 …...
“, j,i)->property(“Value“)读不到数据问题)
querySubObject(“Cells(int,int)“, j,i)->property(“Value“)读不到数据问题
在使用qt读取Excel文件内容的时候,使用下列方式: worksheet->querySubObject("Cells(int,int)", j,i)->property("Value").toString(); 不会报错,但读取不到数据。多次尝试发现应该将property改为dynamicCall 下…...
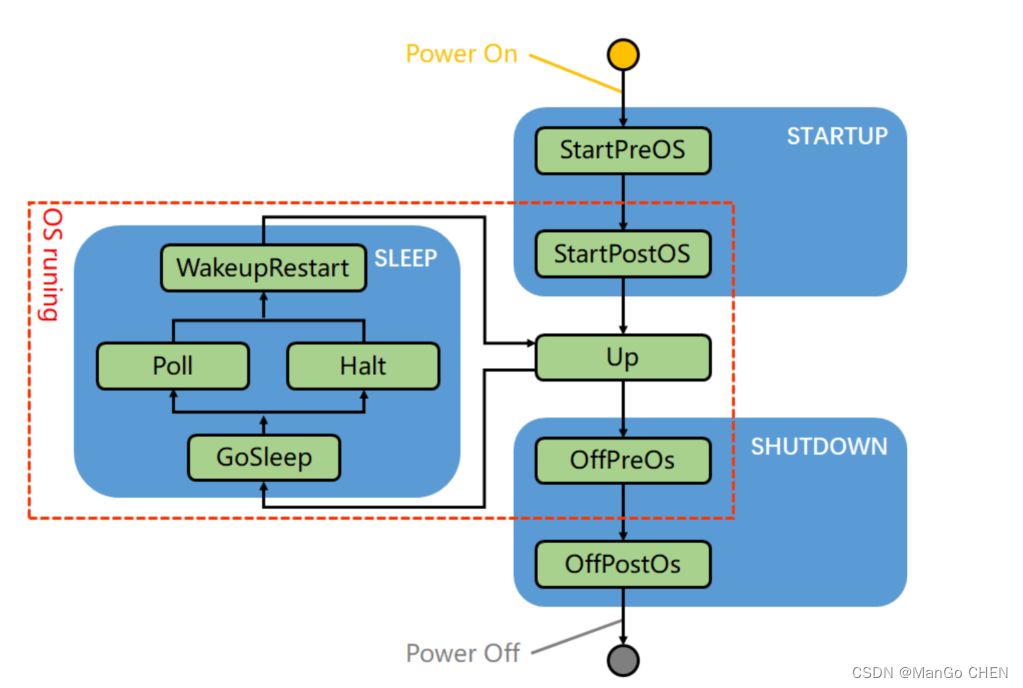
AutoSAR系列讲解(实践篇)10.2-EcuM的上下电流程
目录 一、上电(StartUp) 二、下电(Shutdown) 三、睡眠(Sleep) 上下电,说白了就是给Ecu上下电后,Ecu的代码执行顺序。这里还讲到了大家可能经常会用到的Sleep流程,主要就是可以归纳为以下这张图,大家 掌握这张图就基本掌握了EcuM的上下电流程了。这张图的具体内容博…...

2026爆火!5款AI写作辅助平台实测,治愈文献焦虑,初稿撰写快人一步
对于学生、科研工作者而言,论文写作往往伴随着诸多困扰:文献资料筛选耗时费力、格式排版反复调整、查重率难以达标、逻辑结构不够清晰,这些问题严重制约了写作效率与研究成果的呈现质量。随着AI技术在2026年的持续突破,各类AI论文…...
)
AI视频生成工具“免费额度”背后的算法剥削:我们逆向拆解11家平台的Token计费黑箱(含实测换算表)
更多请点击: https://codechina.net 第一章:AI视频生成工具收费价格对比 当前主流AI视频生成工具在定价策略上呈现显著差异,涵盖免费试用、按分钟计费、订阅制及企业定制等多种模式。用户在选型时需综合考量生成质量、输出分辨率、商用授权范…...

5分钟免费上手:AI换脸终极指南,用roop-unleashed创作专业级视频
5分钟免费上手:AI换脸终极指南,用roop-unleashed创作专业级视频 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要零基础制作电影…...
)
GitHub星标超50k的开源AI工具,为何大厂仍每年豪掷千万采购商业套件?(20年AI基建老兵深度复盘)
更多请点击: https://intelliparadigm.com 第一章:GitHub星标超50k的开源AI工具,为何大厂仍每年豪掷千万采购商业套件?(20年AI基建老兵深度复盘) 开源AI工具如LangChain、LlamaIndex、Ollama和Hugging Fac…...
)
DeepSeek模型越狱攻击实录与反制(2024最新0day漏洞封堵手册)
更多请点击: https://kaifayun.com 第一章:DeepSeek模型安全加固概述 DeepSeek系列大语言模型在开源生态中广泛应用,但其默认部署配置存在若干潜在安全风险,包括未授权API访问、提示注入攻击面暴露、敏感信息泄露通道及权重文件未…...

AI Agent在DevOps中的应用:自主监控、根因分析与故障修复
AI Agent在DevOps中的应用:自主监控、根因分析与故障修复 引言 痛点引入:现代DevOps团队的“三座大山” 想象一个场景:周五晚上23:58,你正准备关掉电脑奔赴周末的露营烧烤局,手机突然弹出数十条Prometheus、ELK Sta…...

如何构建高效笔记系统:解锁OneNote智能编辑新体验
如何构建高效笔记系统:解锁OneNote智能编辑新体验 【免费下载链接】NoteWidget Markdown add-in for Microsoft Office OneNote 项目地址: https://gitcode.com/gh_mirrors/no/NoteWidget 在数字时代,高效的知识管理已成为专业人士的核心竞争力。…...

初次在Taotoken模型广场切换不同模型进行文本生成的体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次在Taotoken模型广场切换不同模型进行文本生成的体验 作为一名开发者,初次接触大模型聚合平台时,最关心…...

Taotoken提供的官方价折扣与活动价在长期使用中的成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken提供的官方价折扣与活动价在长期使用中的成本优势感知 1. 成本可预测性的起点:透明的按Token计费 对于需要长…...
)
跟着 MDN 学CSS day_13 :(深入理解CSS中的元素尺寸调整)
在网页布局的世界里,尺寸控制是一切视觉呈现的基础。一个元素到底应该占据多大的空间,是由内容决定还是由我们手动设定,在不同的设备和视口下又该如何自适应,这些问题贯穿于每一个 CSS 开发者的日常工作。MDN 的"在 CSS 中调…...