PostgreSQL 简洁、使用、正排索引与倒排索引、空间搜索、用户与角色
PostgreSQL使用
- PostgreSQL 是一个免费的对象-关系数据库服务器(ORDBMS),在灵活的BSD许可证下发行。
- PostgreSQL 9.0 :支持64位windows系统,异步流数据复制、Hot Standby;
- 生产环境主流的版本是PostgreSQL 12
BSD协议 与 GPL协议
BSD协议:可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。
GPL协议:某软件使用了GPL软件,那么该软件也需要开源,如果不开源,就不能使用GPL软件。MySQL被Oracle所控制,MySQL使用了GPL
PostgreSQL与MySQL的比较
- PG的索引类型比MySQL种类多;
- PG的主备复制属于物理复制,相对于MySQL基于binlog的逻辑复制
- PostgreSQL完全免费,而且是BSD协议, MySQL是GPL协议,被Oracle控制;
- PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
总结来说, PostgreSQL适合严格的企业场景, MySQL更加适合业务逻辑相对简单、数据可靠性要求较低的互联网场景(比如google、facebook、alibaba)
Windows下的PostgreSQL的下载
下载地址:PostgreSQL下载
-
点击exe文件,弹出

-
可以修改安装路径
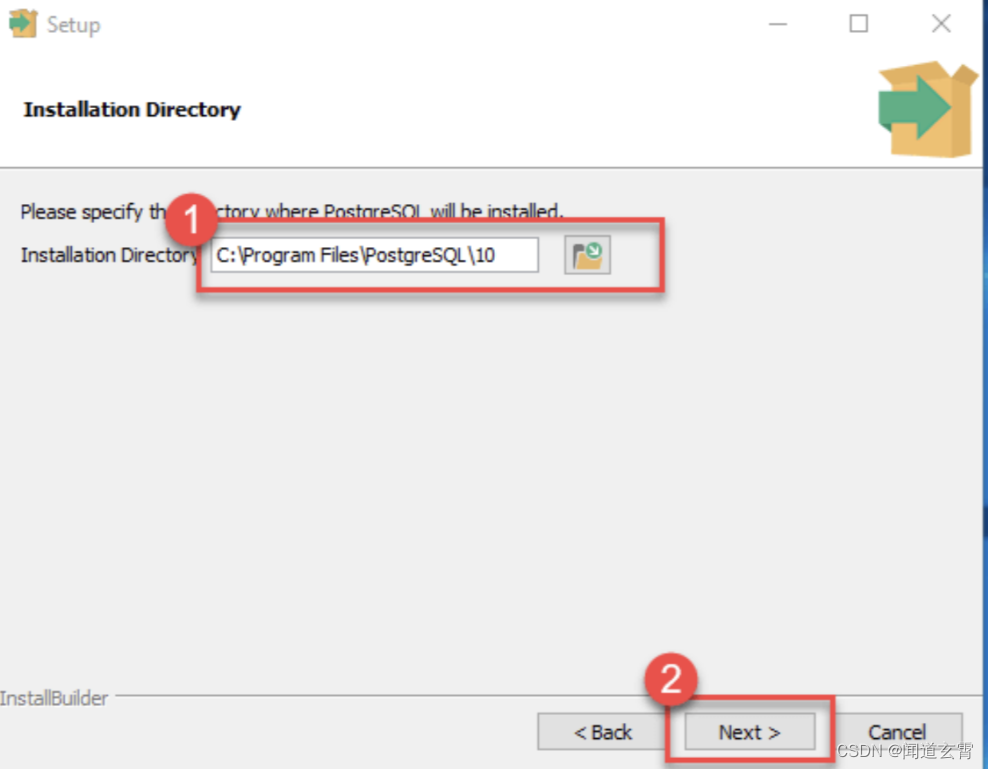
-
选择安装组件,不懂的选就是全部勾上:
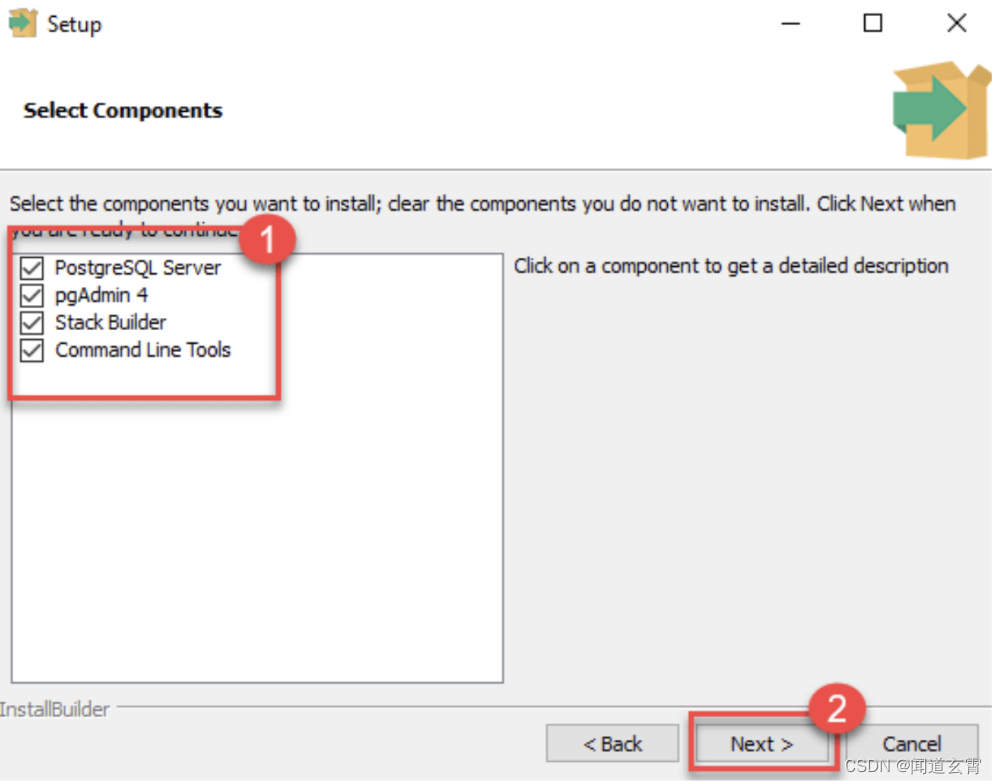
-
设置数据库的数据路径‘
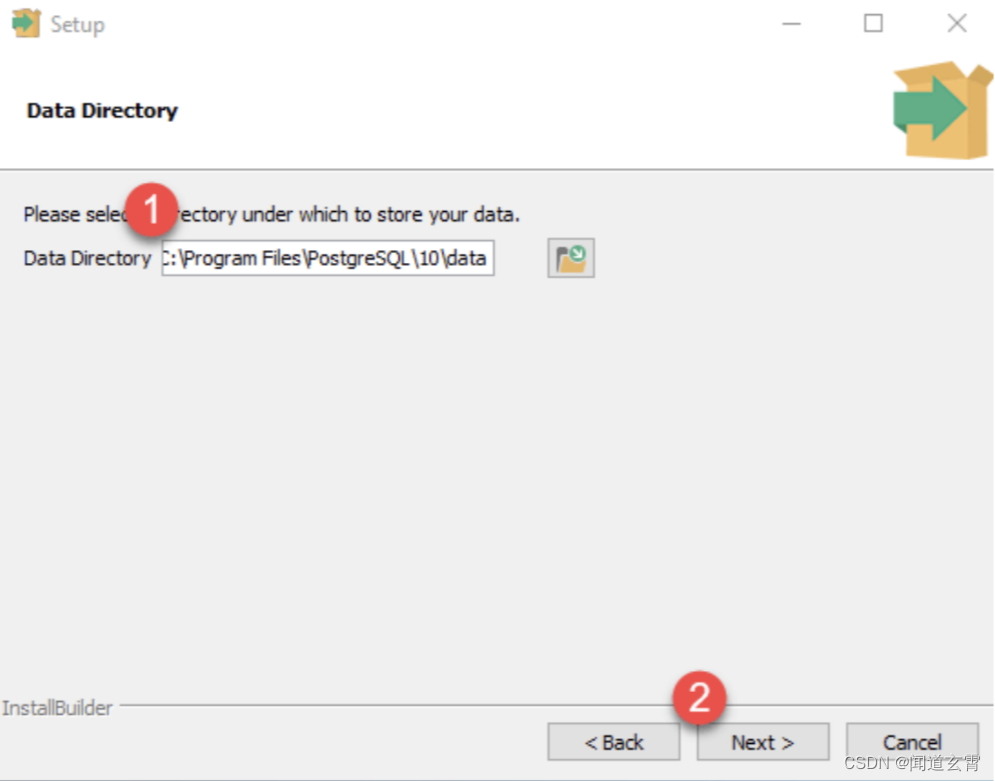
-
设置超级用户的密码
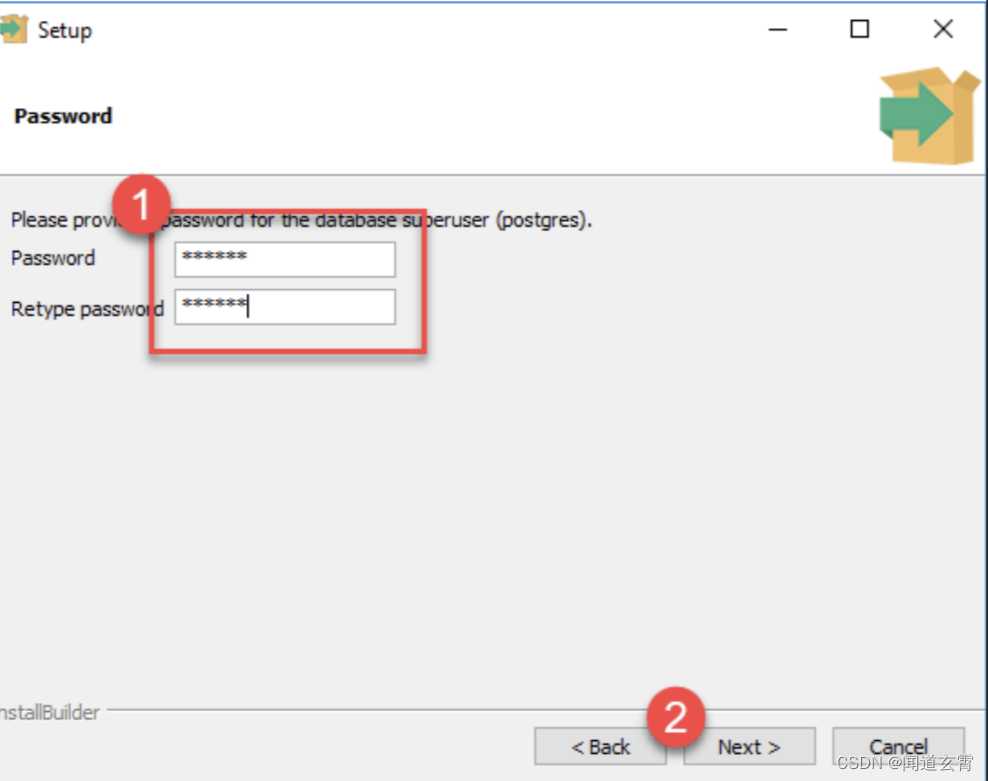
6.设置端口号,可以直接用默认就行
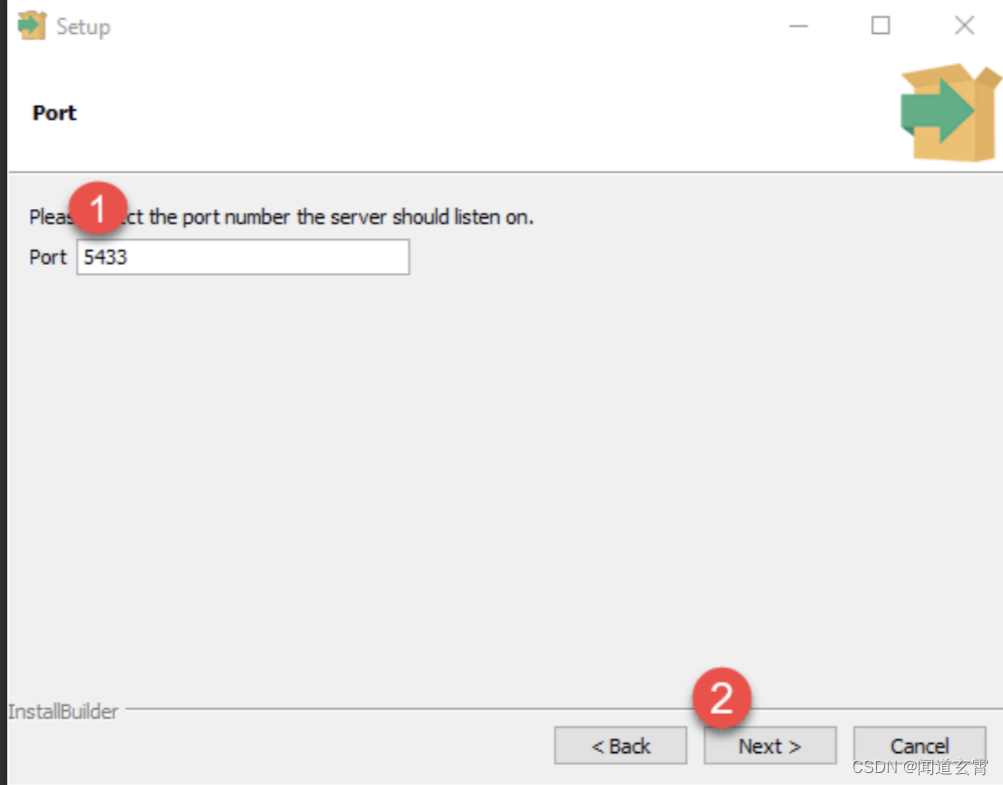
6. 直接点 Next,直到以下图,取消勾选;
- 打开 pgAdmin 4
- 点击左侧的 Servers > Postgre SQL 10
输入密码,点击 OK 即可
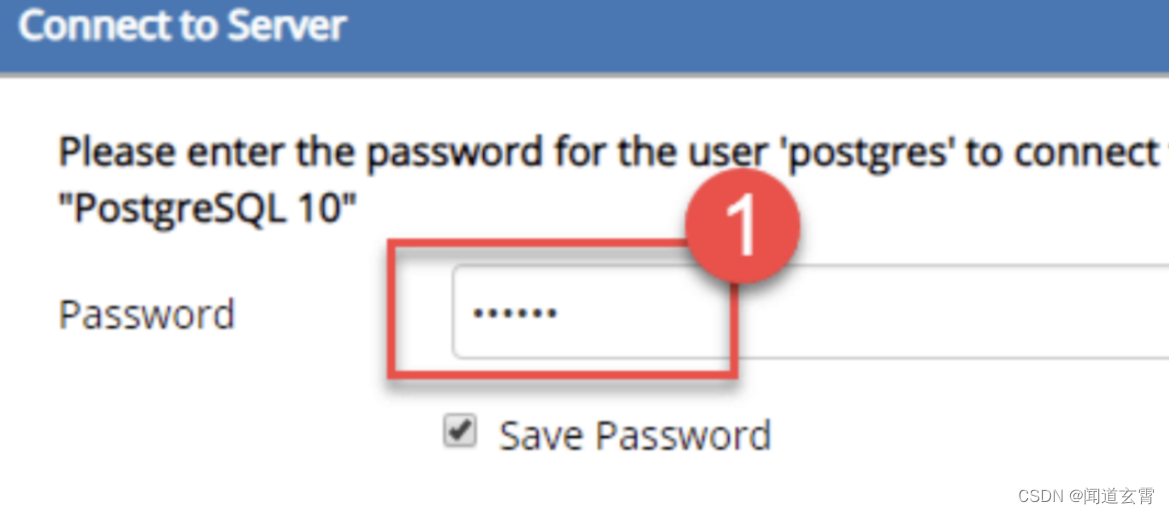
9. 打开 SQL Shell(psql)

PostgreSQL远程访问
-
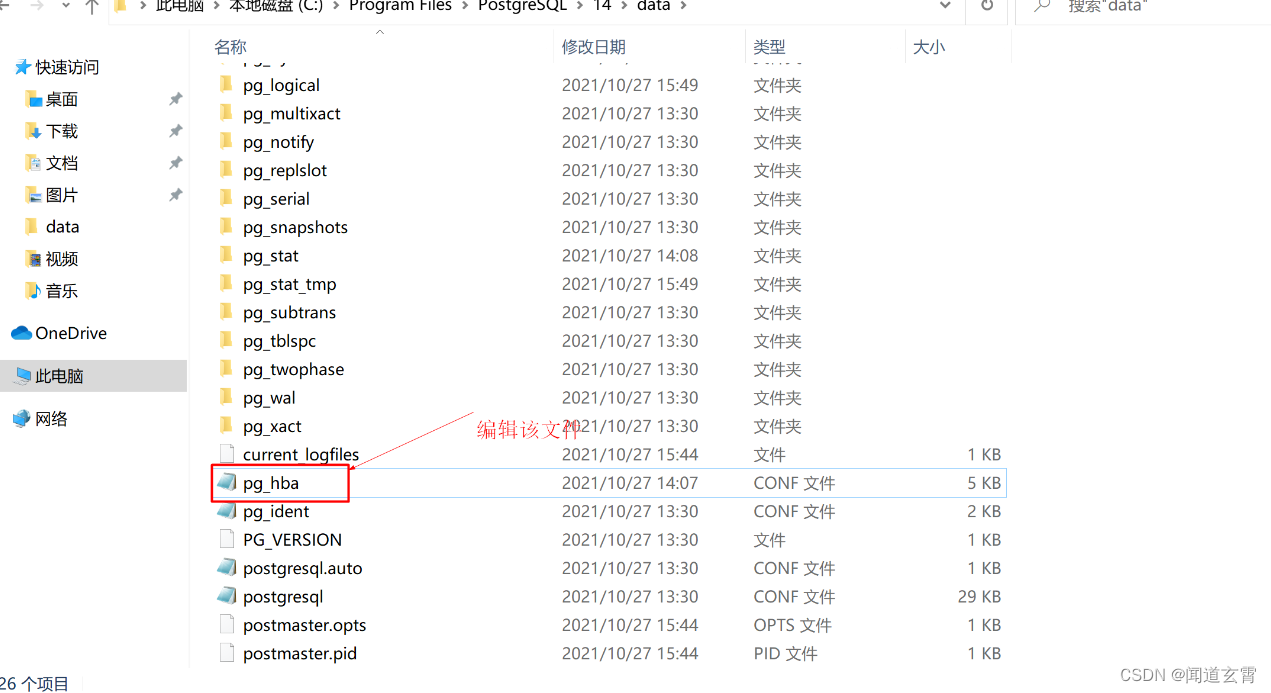
打开postgresql安装目录的data子目录
-
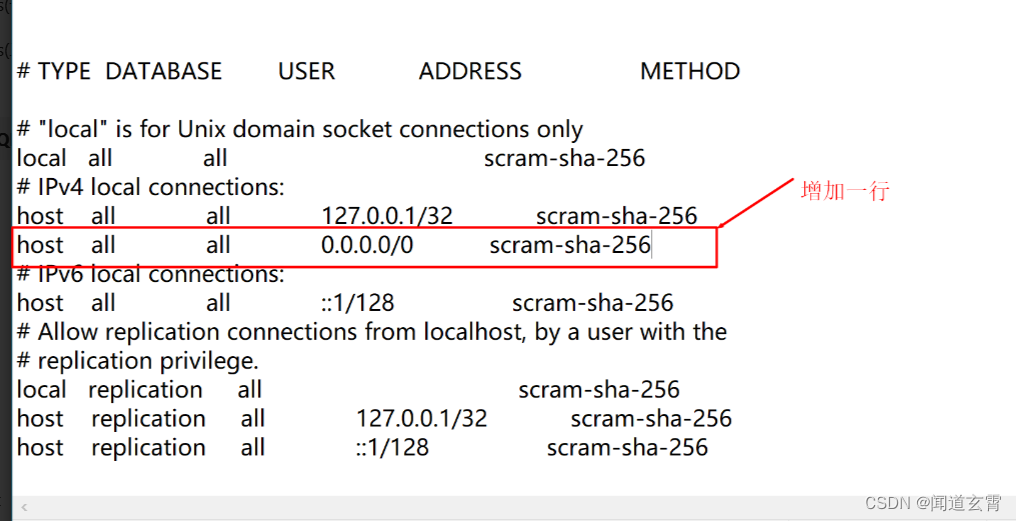
修改pg_hba.conf文件:在IPV4部分添加新的一行:host all all 0.0.0.0/0 md5
-
控制面板–>系统与安全–>Windows防火墙,关闭防火墙,重启服务;
- 业务开发中,大部分还是通过客户端连接工具操作PostgreSQL,通过命令行操作的方式还是很少, 我用的是navicat。
- 远程访问连接问题可能会有多种,大部分百度都可以解决;
PostgreSQL的基本使用
登录
业务中,我们用navicat连接居多,很少会用命令行连接;
psql -U dbuser -d exampledb -h 127.0.0.1 -p 5432
数据库操作
#创建数据库
CREATE DATABASE mydb;#查看所有数据库
\l#切换当前数据库
\c mydb#删除数据库
drop database <dbname>
数据库表操作
表字段类型
- 整数型
- smallint :2 字节, 小范围整数,范围-32768 到 +32767
- integer:4 字节,常用的整数,范围 -2147483648 到 +2147483647
- bigint:8 字节 大范围整数,范围-9223372036854775808 到 +9223372036854775807
- decimal :可变长 用户指定的精度,精确 小数点前 131072 位;小数点后 16383 位
- numeric 可变长 用户指定的精度,精确 小数点前 131072 位;小数点后 16383 位
- double:8 字节 可变精度,不精确 15 位十进制数字精度
业务中一般不用double, 最好用decimal,避免出现精度误差问题;
- 字符型
- char(size),character(size):固定长度字符串,size 规定了需存储的字符数,由右边的空格补齐
- varchar(size),character varying(size):可变长度字符串,size 规定了需存储的字符数;
- text:可变长度字符串。
- 时间型
- timestamp:日期和时间;
- date:日期,无时间;
- time:时间;
主要就是这几种,还有几何,布尔类型等,常见是以上三种;
表操作
业务中,创建表的操作,应该是通过可视化客户端工具创建;
#创建表
CREATE TABLE test(id int,body varchar(100));#在表中插入数据
insert into test(id,body) values(1,'hello,postgresql');#查看当前数据库下所有表
\d#查看表结构,相当于desc
\d test
主键相关:PostgreSQL 使用序列来标识字段的自增长,数据类型有 smallserial、serial 和 bigserial 。这些属性类似于 MySQL 数据库支持的 AUTO_INCREMENT 属性。
- SMALLSERIAL : 2字节,范围:1到 32767
- SERIAL: 4字节,范围:1 到 2,147,483,647
- BIGSERIAL: 8字节,范围1 到 922,337,2036,854,775,807
#创建表
CREATE TABLE COMPANY(ID SERIAL PRIMARY KEY,NAME TEXT NOT NULL,AGE INT NOT NULL,ADDRESS CHAR(50),SALARY REAL
);#插入数据
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Paul', 32, 'California', 20000.00 );INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Allen', 25, 'Texas', 15000.00 );
#查询SQL
SELECT * FROM COMPANY where id = 1;
# 更新SQL
UPDATE COMPANY SET age = 33 where id = 1;
PostgreSQL的语法基本和MySQL差不多, 业务开发中,一般都是写curd, 而建表等操作,通过可视化工具执行效率更高效;
Schema
PostgreSQL 模式(SCHEMA)可以看着是一个表的集合。
一个模式可以包含视图、索引、数据类型、函数和操作符等。
相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表。
使用模式的优势:
● 允许多个用户使用一个数据库并且不会互相干扰。
● 将数据库对象组织成逻辑组以便更容易管理。
● 第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
模式类似于操作系统层的目录,但是模式不能嵌套。
#创建schema:
create schema myschema;create table myschema.company(ID INT NOT NULL,NAME VARCHAR (20) NOT NULL,AGE INT NOT NULL,ADDRESS CHAR (25),SALARY DECIMAL (18, 2),PRIMARY KEY (ID)
);#删除schema:
drop schema myschema;#删除一个模式以及其中包含的所有对象:
DROP SCHEMA myschema CASCADE;
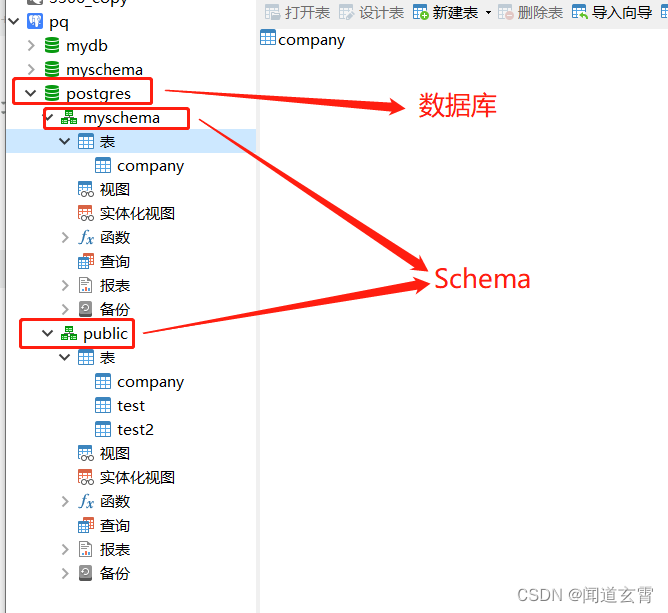
结构如上,创建了schema之后,可以在两个schema中创建同名的表, 类似库中库的感觉;
数据表的索引
唯一索引 与 普通索引
CREATE UNIQUE INDEX "idx_dev_id_user_id" ON "myschema"."device" USING btree ("deviceid","userid"
)
psql普通索引:
CREATE INDEX "id_dev_id" ON "myschema"."device" USING btree ("deviceid"
)
索引底层使用的是Btree结构, 是排好序的结构,通过树的遍历快速找到目标结果,大大减少IO次数;
若不使用索引,则进行全表扫描;
树结构如图所示:
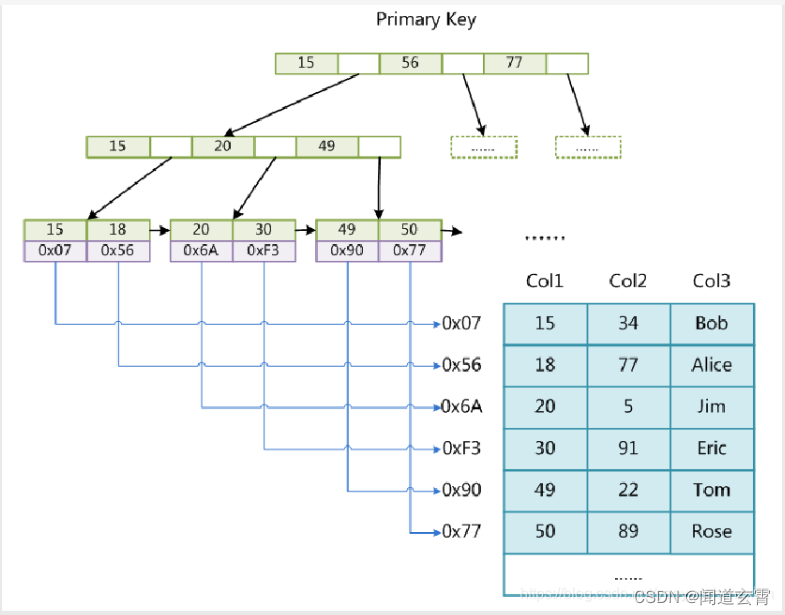
哈希索引
通过哈希表结构存储数据, 存储数据时, 对查询条件进行hash,得到哈希码后,再从哈希表中拿到目标值,缺点是只能支持 =, in查询, 不支持范围查询;
CREATE INDEX "idx_name" ON "myschema"."person" USING hash ("name"
)

业务开发中,基本不会使用到这个索引,业务中很多场景都需要进行模糊搜索,范围搜索,而哈希索引是支持不了的;
倒排索引
- Generalized Inverted Index, 简称gin;
- 它处理的数据类型的值不是原子的,而是由元素组成的。
- GIN索引由元素的B树组成,TID的B树或平面列表链接到该B树的叶行。
- 使用于全文搜索场景,解决全文搜索性能低问题;
- 可解决like “%xxx%” 索引失效问题;
- 增加pg_trgm拓展
CREATE EXTENSION pg_trgm;
- 给字段建立索引
CREATE INDEX "idx_addres" ON "myschema"."person" USING gin ("address"
)
正排索引
整个key是索引, value是整行记录;
例如 搜索name为"zhangsan", value为“zhangsan”整条记录;
正排索引的key是 “zhangsan”, value保存整条记录;
对应ID主键索引,普通索引,唯一索引,是正排索引;
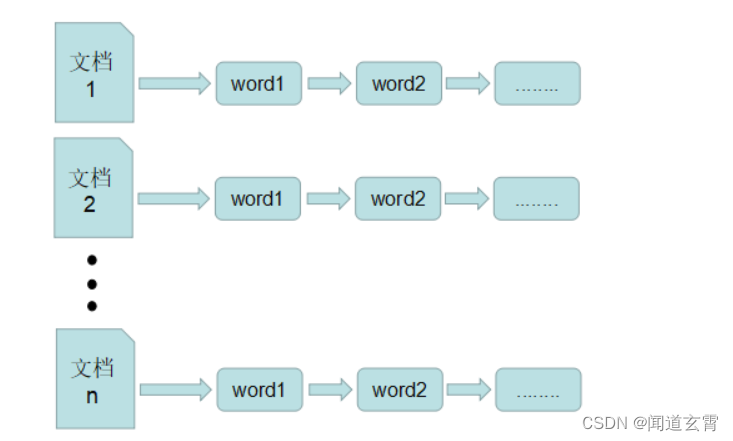
倒排索引
-
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
-
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。
-
在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
-
倒排表的结构图如下图

-
GIN(Generalized Inverted Index, 通用倒排索引)是一个存储对(key, posting list)集合的索引结构,其中key是一个键值,而posting list 是一组出现过key的位置。如(‘hello’, ’14:2 23:4’)中,表示hello在14:2和23:4这两个位置出现过,在PG中这些位置实际上就是元组的tid。
-
在表中的每一个属性,在建立索引时,都可能会被解析为多个键值,所以同一个元组的tid可能会出现在多个key的posting list中。
-
通过这种索引结构可以快速的查找到包含指定关键字的元组,因此GIN索引特别适用于支持全文搜索,而PG的GIN索引模块也就是为了支持全文搜索而开发的。
psql gist索引
- Gist(Generalized Search Tree),即通用搜索树。和btree一样,也是平衡的搜索树
- Btree用于等值、范围搜索;
- 生活部分场景中,需要存储多维数据,例如地理位置、空间位置、图像数据等,经常要判断是否在 某个位置, 某个点的数据,我即判断地理位置的"包含"那么我们就可以使用gist索引了
使用场景
- 几何类型,支持位置搜索,按距离排序。
- 范围类型,支持位置搜索。
- 空间类型(PostGIS),支持位置搜索,按距离排序。
其场景暂时没想到;
简单使用
1.创建一张测试表:
create table company(id int, location point); 
2. 给location设置索引
CREATE INDEX "idx_location" ON "myschema"."company " USING gist ("location"
)
- 添加随机插入10万条数据
insert into company select generate_series(1,100000), point(round((random()*1000)::numeric, 2), round((random()*1000)::numeric, 2));
- 查询
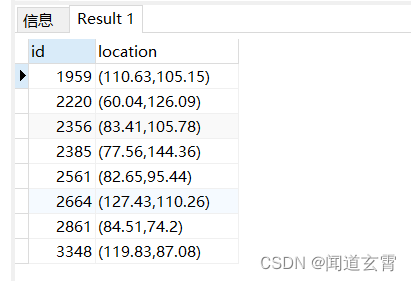
select * from company where circle '((100,100) 50)' @> location;
把坐标(100,100) 上下50范围内的数据全找出来, 结果如下,
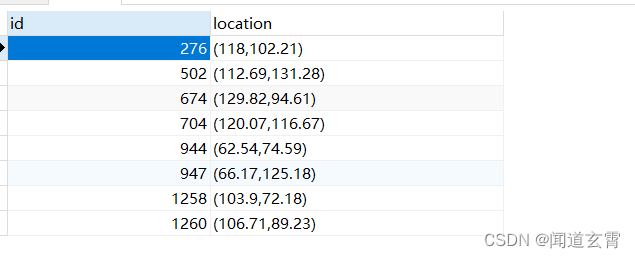
使用explain查看执行计划:
explain (analyze,verbose,timing,costs,buffers) select * from company where circle '((100,100) 50)' @> location;

再查看分页的执行计划;
explain (analyze,verbose,timing,costs,buffers) select * from company where circle '((100,100) 50)' @> location ORDER BY id limit 10 OFFSET 11;
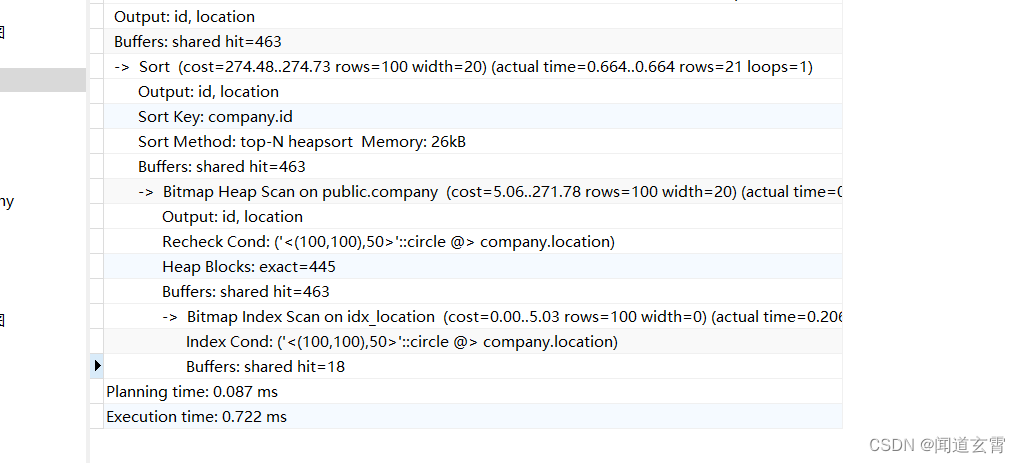
出现了Bitmap index scan, Bitmap heap scan, sort三种;
分页搜索场景
业务开发中,搜索经常会涉及到分页操作,而PostgreSQL和MySQL不太一致, 不是使用limit xxx, xxx, 而是使用了limit xx offset xx;
例如一页10条数据, 搜索第一页:
select * from company where circle '((100,100) 50)' @> location ORDER BY id limit 10 OFFSET 1;
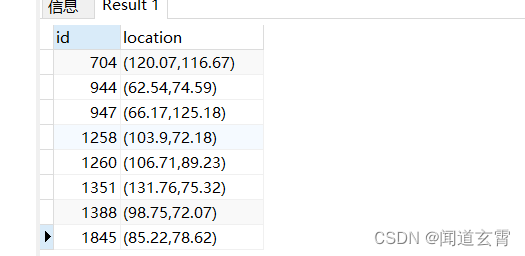
第二页则是 第11条值20条
select * from company where circle '((100,100) 50)' @> location ORDER BY id limit 10 OFFSET 11;
用户操作
#创建用户并设置密码
CREATE USER 'username' WITH PASSWORD 'password';
CREATE USER test WITH PASSWORD 'test';#修改用户密码
$ ALTER USER 'username' WITH PASSWORD 'password';#数据库授权,赋予指定账户指定数据库所有权限
$ GRANT ALL PRIVILEGES ON DATABASE 'dbname' TO 'username';
#将数据库 mydb 权限授权于 test
GRANT ALL PRIVILEGES ON DATABASE mydb TO test;
#但此时用户还是没有读写权限,需要继续授权表
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO xxx;
#注意,该sql语句必须在所要操作的数据库里执行#移除指定账户指定数据库所有权限
REVOKE ALL PRIVILEGES ON DATABASE mydb from test#删除用户
drop user test# 查看用户
\dupg_hba.conf配置中的第一项设置的意思是:本地用户通过unix socket登陆时,使用peer方式认证。
# "local" is for Unix domain socket connections only
local all all peer
- peer是用PostgreSQL所在的操作系统上的用户登陆。
peer方式中,client必须和PostgreSQL在同一台机器上。只要当前系统用户和要登陆到PostgreSQL的用户名相同,就可以登陆。
在刚部署PostgreSQL之后,切换到系统的postgres用户后,直接执行psql就能进入PostgreSQL就是这个原因(当前系统用户为名postgre,PostgreSQL中的用户名也是postgre)。
PostgreSQL 角色管理
在PostgreSQL 里没有区分用户和角色的概念,“CREATE USER” 为 “CREATE ROLE” 的别名,这两个命令几乎是完全相同的,唯一的区别是"CREATE USER" 命令创建的用户默认带有LOGIN属性,而"CREATE ROLE" 命令创建的用户默认不带LOGIN属性
postgres=# CREATE ROLE david; //默认不带LOGIN属性
CREATE ROLE
postgres=# CREATE USER sandy; //默认具有LOGIN属性
CREATE ROLE
postgres=# \duList of rolesRole name | Attributes | Member of
-----------+------------------------------------------------+-----------david | Cannot login | {}postgres | Superuser, Create role, Create DB, Replication | {}sandy | | {}postgres=#
postgres=# SELECT rolname from pg_roles ;rolname
----------postgresdavidsandy
(3 rows)postgres=# SELECT usename from pg_user; //角色david 创建时没有分配login权限,所以没有创建用户usename
----------postgressandy
(2 rows)postgres=#
更新权限;
postgres=# ALTER ROLE bella WITH LOGIN;
ALTER ROLE
postgres=# \duList of rolesRole name | Attributes | Member of
-----------+------------------------------------------------+-----------bella | Create DB | {}david | | {}postgres | Superuser, Create role, Create DB, Replication | {}renee | Create DB | {}sandy | | {}postgres=#
角色属性
- login:只有具有 LOGIN 属性的角色可以用做数据库连接的初始角色名。
- superuser: 数据库超级用户
- createdb: 创建数据库权限
- createrole: 允许其创建或删除其他普通的用户角色(超级用户除外)
- password: 在登录时要求指定密码时才会起作用,比如md5或者password模式,跟客户端的连接认证方式有关
- replication: 做流复制的时候用到的一个用户属性,一般单独设定。
命令行模式下的常用命令
\password命令(设置密码)
\q命令(退出)
\h:查看SQL命令的解释,比如\h select。
\?:查看psql命令列表。
\l:列出所有数据库。
\c [database_name]:连接其他数据库。
\d:列出当前数据库的所有表格。
\d [table_name]:列出某一张表格的结构。
\du:列出所有用户。
总结
- PostgreSQL 功能比MySQL强大一些, 语法上接近, crud学起来很快;
- 同样拥有唯一索引,普通索引,哈希索引, 另外多了GIN,GIST索引的新特性, 业务场景更加广泛了;
- oracle是要钱的, PostgreSQL是免费的, 未来严格的企业场景中,Oracle占比会越来越少,逐渐被PostgreSQL替代;
- Mysql + PostgreSQL 以后是潮流,开发者必须要懂这两块;
- 以后还有进阶内容,需要不断学习;
相关文章:
PostgreSQL 简洁、使用、正排索引与倒排索引、空间搜索、用户与角色
PostgreSQL使用 PostgreSQL 是一个免费的对象-关系数据库服务器(ORDBMS),在灵活的BSD许可证下发行。PostgreSQL 9.0 :支持64位windows系统,异步流数据复制、Hot Standby;生产环境主流的版本是PostgreSQL 12 BSD协议 与 GPL协议 …...
“, j,i)->property(“Value“)读不到数据问题)
querySubObject(“Cells(int,int)“, j,i)->property(“Value“)读不到数据问题
在使用qt读取Excel文件内容的时候,使用下列方式: worksheet->querySubObject("Cells(int,int)", j,i)->property("Value").toString(); 不会报错,但读取不到数据。多次尝试发现应该将property改为dynamicCall 下…...
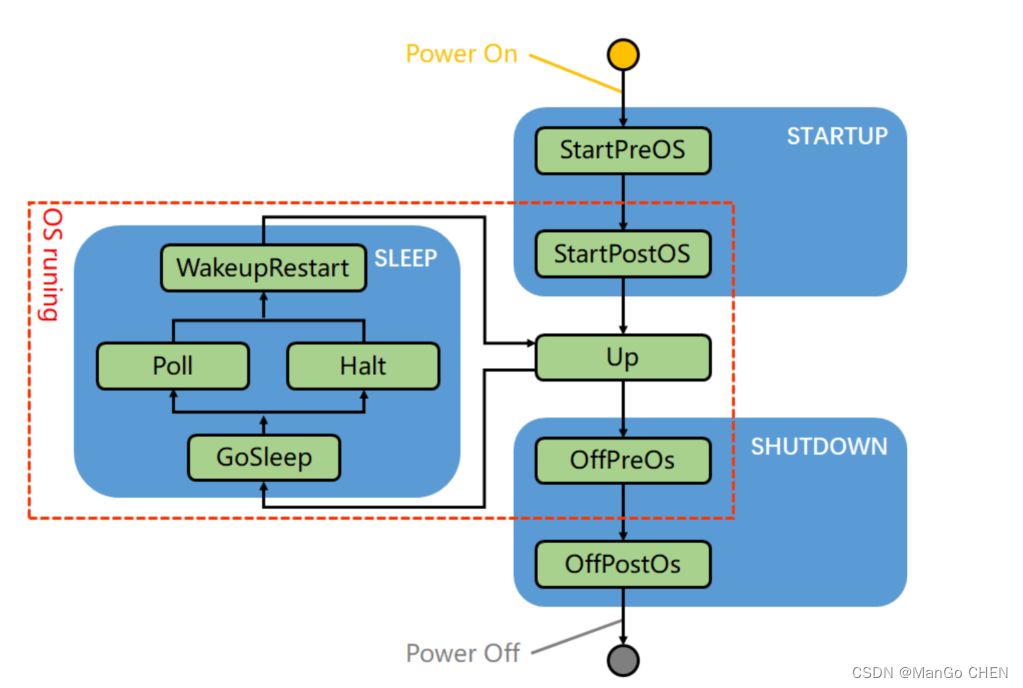
AutoSAR系列讲解(实践篇)10.2-EcuM的上下电流程
目录 一、上电(StartUp) 二、下电(Shutdown) 三、睡眠(Sleep) 上下电,说白了就是给Ecu上下电后,Ecu的代码执行顺序。这里还讲到了大家可能经常会用到的Sleep流程,主要就是可以归纳为以下这张图,大家 掌握这张图就基本掌握了EcuM的上下电流程了。这张图的具体内容博…...
科研院所用泛微搭建信创办公平台,统一办公,业务融合,安全便捷
国家全面推动重要领域的信创改造工作,要求到2027年底,对综合办公、经营管理、生产运营等系统实现“应替尽替、能替则替”。 科研机构作为智力、知识密集型机构,承载着大量数据、信息资产,数字化程度高,业务系统多样&a…...

基于LoRA进行Stable Diffusion的微调
文章目录 基于LoRA进行Stable Diffusion的微调数据集模型下载环境配置微调过程 推理WebUI部署 基于LoRA进行Stable Diffusion的微调 数据集 本次微调使用的数据集为: LambdaLabs的Pokemon数据集 使用git clone命令下载数据集 git clone https://huggingface.co/…...

C++STL序列式容器——list容器及其常用操作(详解)
纵有疾风起,人生不言弃。本文篇幅较长,如有错误请不吝赐教,感谢支持。 💬文章目录 一.list容器基本概念二.list容器的常用操作list构造函数list迭代器获取list特性操作list元素操作list赋值操作list的交换、反转、排序、归并操作…...

【雕爷学编程】MicroPython动手做(15)——掌控板之AB按键2
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...
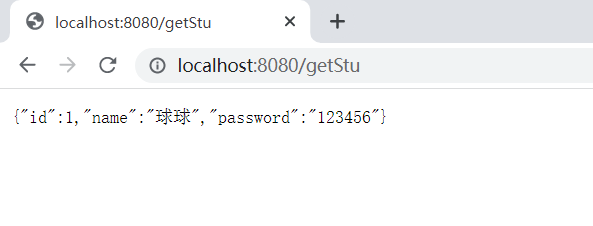
Spring Boot中整合MyBatis(基于xml方式基于注解实现方式)
一、前提准备 在Spring Boot中整合MyBatis时,你需要导入JDBC(不需要手动添加)和Druid的相关依赖。 JDBC依赖:在Spring Boot中整合MyBatis时,并不需要显式地添加JDBC的包依赖。这是因为,当你添加mybatis-sp…...
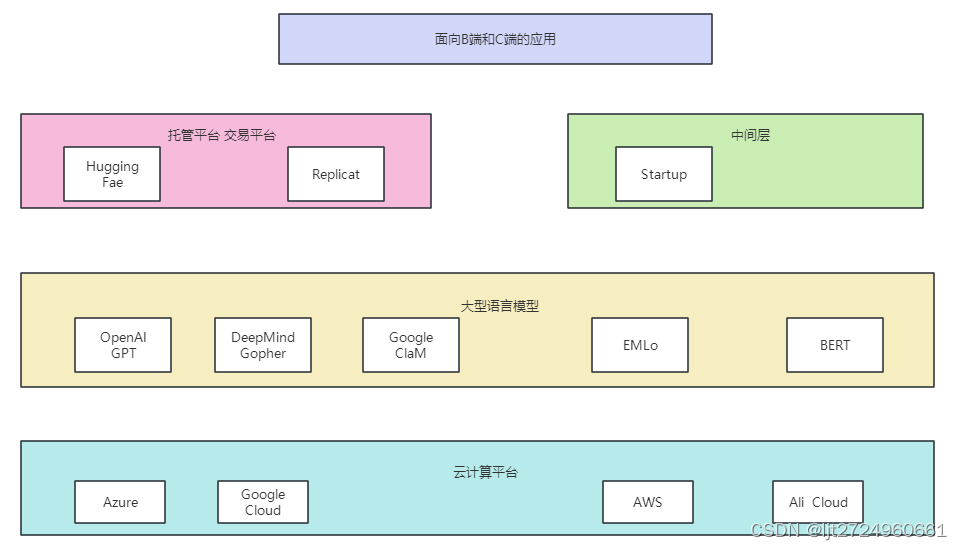
ChatGPT漫谈(三)
AIGC(AI Generated Content)指的是使用人工智能技术生成的内容,包括文字、图像、视频等多种形式。通过机器学习、深度学习等技术,AI系统可以学习和模仿人类的创作风格和思维模式,自动生成大量高质量的内容。AIGC被视为继用户生成内容(UGC)和专业生成内容(PGC)之后的下…...

树、二叉树(C语言版)详解
🍕博客主页:️自信不孤单 🍬文章专栏:数据结构与算法 🍚代码仓库:破浪晓梦 🍭欢迎关注:欢迎大家点赞收藏关注 文章目录 🍊树的概念及结构1. 树的概念2. 树的相关概念3.树…...
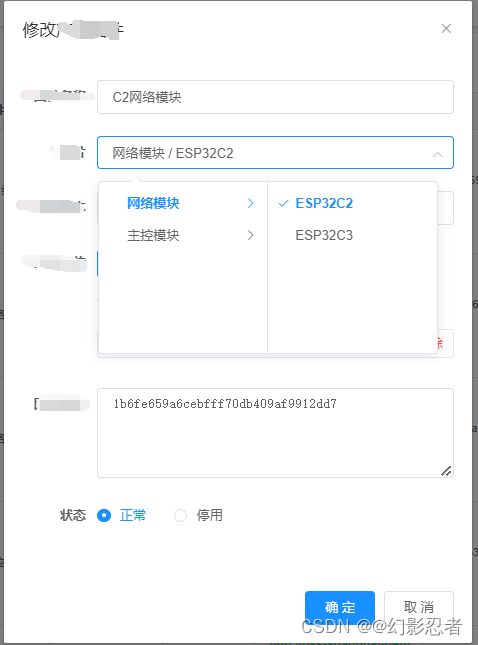
vue中Cascader 级联选择器实现-修改实现
vue 的cascader研究了好长时间,看了官网给的示例,上网查找了好多信息,才解决修改时回显的问题,现将方法总结如下: vue代码: <el-form-item label"芯片" prop"firmware"> <…...

C语言实现三子棋游戏
test.c源文件 - 三子棋游戏测试 game.h头文件 - 三子棋游戏函数的声明 game.c源文件 - 三子棋游戏函数的实现 主函数源文件: #define _CRT_SECURE_NO_WARNINGS 1#include"game.h" //自己定义的用"" void menu() {printf("*************…...
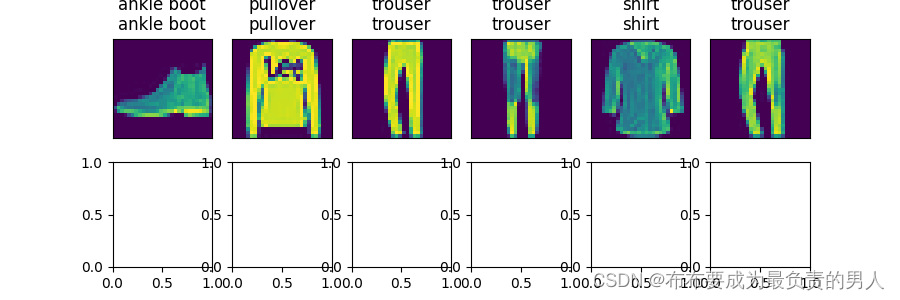
机器学习深度学习——softmax回归从零开始实现
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——向量求导问题 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 …...

Windows如何安装Django及如何创建项目
目录 1、Windows安装Django--pip命令行 2、创建项目 2.1、终端创建项目 2.2、在Pycharm中创建项目 2.3、二者创建的项目有何不同 2.4、项目目录说明 1、Windows安装Django--pip命令行 安装Django有两种方式: pip命令行【推荐--简单】手动安装【稍微复杂一丢丢…...
)
在CSDN学Golang云原生(监控解决方案Prometheus)
一,记录规则配置 在golang云原生中,通常使用日志库记录应用程序的日志。其中比较常见的有logrus、zap等日志库。这些库一般支持自定义的输出格式和级别,可以根据需要进行配置。 对于云原生应用程序,我们通常会采用容器化技术将其…...
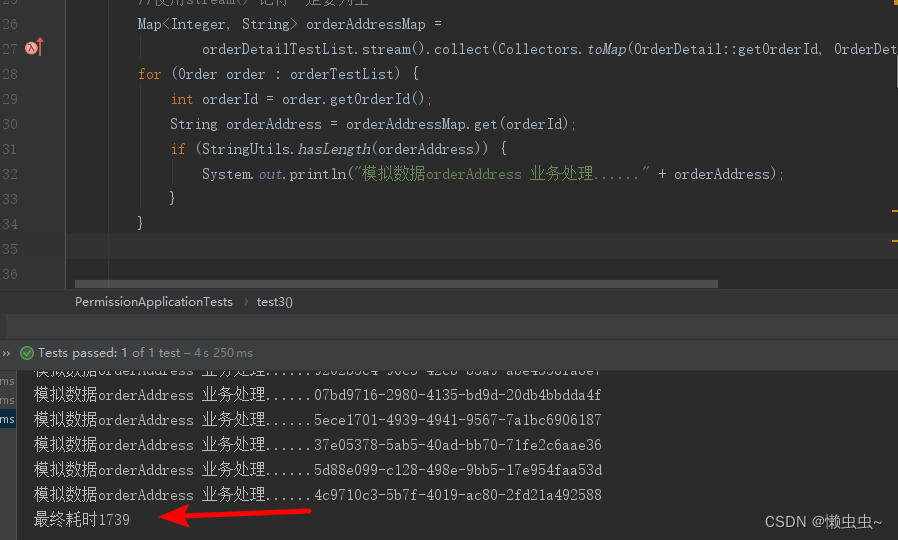
双重for循环优化
项目中有段代码逻辑是个双重for循环,发现数据量大的时候,直接导致数据接口响应超时,这里记录下不断优化的过程,算是抛砖引玉吧~ Talk is cheap,show me your code! 双重for循环优化 1、数据准备2、原始双重for循环3、…...
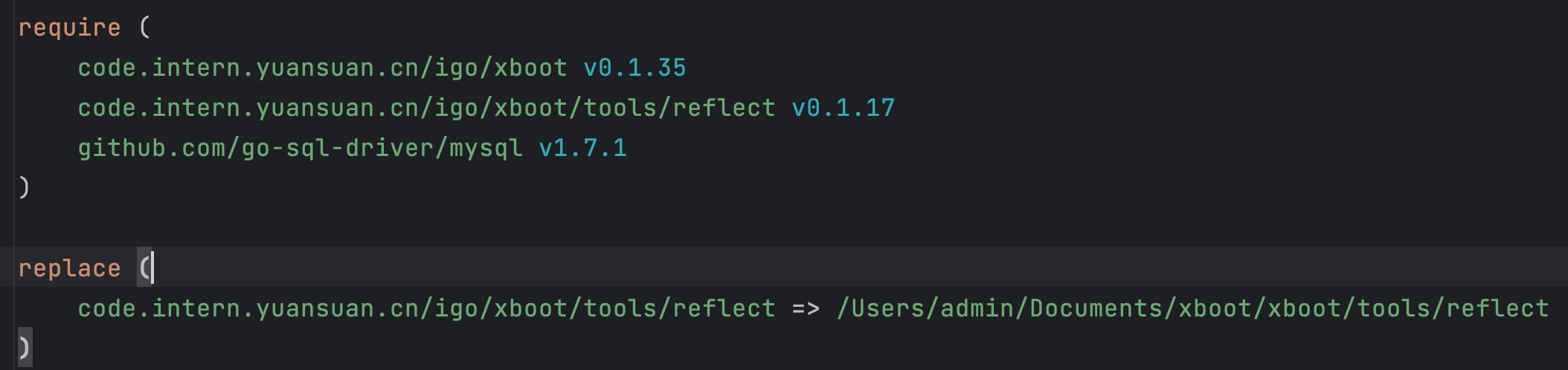
golang利用go mod巧妙替换使用本地项目的包
问题 拉了两个项目下来,其中一个项目依赖另一个项目,因为改动了被依赖的项目,想重新导入测试一下。 解决办法 go.mod文件的require中想要被代替的包名在replace中进行一个替换,注意:用来替换的需要用绝对路径…...

使用 docker 一键部署 MySQL
目录 1. 前期准备 2. 导入镜像 3. 创建部署脚本文件 4. MySQL 服务器配置文件模板 5. 执行脚本创建容器 6. 后续工作 7. 基本维护 1. 前期准备 新部署前可以从仓库(repository)下载 MySQL 镜像,或者从已有部署中的镜像生成文件&#x…...

MyBatis-Plus 查询PostgreSQL数据库jsonb类型保持原格式
文章目录 前言数据库问题背景后端返回实体对象前端 实现后端返回List<Map<String, Object>>前端 前言 在这篇文章,我们保存了数据库的jsonb类型:MyBatis-Plus 实现PostgreSQL数据库jsonb类型的保存与查询 这篇文章介绍了模糊查询json/json…...

Linux操作系统1-命令篇
不同领域的主流操作系统 桌面操作系统 Windos Mac os Linux服务器操作系统 Unix Linux(免费、稳定、占有率高) Windows Server移动设备操作系统 Android(基于Linux,开源) ios嵌入式操作系统 Linux(机顶盒、路由器、交换机) Linux 特点:免费、开源、多用户、多任务…...

2026年10款降AI率软件亲测:最高AI率100%直降至0.12%
2026年全球学术界对AIGC内容的监管持续收紧,多所高校及科研机构相继升级论文检测标准,AI痕迹识别技术进入全新阶段。随着知网、Turnitin等主流查重平台全面接入深度学习型AIGC检测系统,学术论文中AI生成内容的识别精度大幅提升,传…...

CSS背景效果完全指南
CSS背景效果完全指南 引言 CSS背景效果是美化网页的重要手段,通过合理使用背景属性,可以创造出丰富的视觉效果。本文将深入探讨CSS背景的各种属性和高级技巧。 一、背景基础 1.1 background-color .element {background-color: #4CAF50;background-color…...

林志玲退文策院聘书,台湾大骂“中国玲”
林志玲到底咋了?这几天林志玲拒绝文策院董事的消息,在网上炸开了锅。可谁能想到,这个“拒绝”本身,反倒把她架在火上烤了一遍。先看岛内那边。一听说这事,一些极端网友直接炸毛,翻出她以前为祖国做的事儿&a…...

【避坑指南】Midscene.js 常见报错解析:Timeout、模型幻觉与跨域问题的终极解法
开篇:当AI自动化“翻车”时,你在想什么? 凌晨两点,你的CI/CD流水线又红了。点开日志一看——TimeoutError: AI model request timed out。改了timeout参数重新跑,这次倒是没超时,但AI模型信誓旦旦地点了一个根本不存在的按钮。第三次,脚本直接抛出403,提示跨域被拦截。…...

摆脱论文困扰!盘点2026年断层领先的的降AI率平台
轻松降低论文AI率在2026年已不再是天方夜谭。最新推出的2026年降AI率平台,实测提速效果惊人,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,真正实现高效降AI率,助你轻松应对论文挑战。 一、全流程王者&…...

网站内容创作团队如何利用多模型聚合平台提升效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 网站内容创作团队如何利用多模型聚合平台提升效率 对于网站内容运营或编辑团队而言,持续产出高质量、多样化的内容是一…...

Unity Android启动卡在Waiting For Debugger原因与三套解决方案
1. 这个“Waiting For Debugger”到底在等谁?——从Unity启动流程看问题本质你刚在Android设备上点开调试中的Unity App,屏幕却卡在黑屏或白屏,Logcat里反复刷出一行红色日志:Waiting For Debugger。你反复检查USB调试开关、ADB权…...

初次在Taotoken模型广场切换不同模型进行文本生成的体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次在Taotoken模型广场切换不同模型进行文本生成的体验 作为一名开发者,初次接触大模型聚合平台时,最关心…...

终极鸣潮自动化工具:5个技巧让你的游戏时间效率提升500%
终极鸣潮自动化工具:5个技巧让你的游戏时间效率提升500% 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves 你是否曾经为《…...

量子机器学习:首次光子实验实现明确量子优势,开启超低功耗AI新范式
1. 量子机器学习:从理论到实验的首次明确优势量子计算和人工智能,这两个听起来都充满未来感的领域,在过去几年里各自都取得了令人瞩目的进展。但一个核心问题始终悬而未决:量子力学那些“反直觉”的特性,比如叠加和纠缠…...