【mysql学习篇】Order by与Group by优化以及排序算法详解
一、Order by与Group by优化
Case1:

分析: 利用最左前缀法则:中间字段不能断,因此查询用到了name索引,从key_len=74也能看出,age索引列用在排序过程中,因为Extra字段里没有using filesort
注意: order by age 虽然用到了索引,但是不会在key_len列体现
Case 2:

分析: 从explain的执行结果来看:key_len=74,查询使用了name索引,由于用了position进行排序,跳过了age,出现了Using filesort。
注意: 这里跳过了age,这里position是无序的,所以不会走索引
Case 3:

分析: 查找只用到索引name,age和position用于排序,无Using filesort。
Case 4:

分析: 和Case 3中explain的执行结果一样,但是出现了Using filesort,因为索引的创建顺序为name,age,position,但是排序的时候age和position颠倒位置了。
重点注意: 这边颠倒age和position,mysql不会像前面提到的where后面一样优化最左前缀
Case 5:

分析: 与Case 4对比,在Extra中并未出现Using filesort,因为age为 常量,在排序中被优化,所以索引未颠倒,不会出现Using filesort。
Case 6:

分析: 虽然排序的字段列与索引顺序一样,且order by默认升序,这里position desc变成了降序,导致与索引的排序方式不同,从而产生Using filesort。Mysql8以上版本有降序索引可以支持该种查询方式。
Case 7:

分析: 对于排序来说,多个相等条件也是范围查询
Case 8:

可以用覆盖索引优化

二、Using filesort 文件排序原理详解
filesort文件排序方式
在使用explain分析查询的时候,利用有序索引获取有序数据显示Using index。如果MySQL在排序的时候没有使用到索引那么就会输出using filesort,即使用文件排序。
文件排序是通过相应的排序算法,将取得的数据在内存中进行排序:
- MySQL需要将数据在内存中进行排序,所使用的内存区域也就是我们通过sort_buffer_size系统变量所设置的sort buffer(排序区)。
- 这个sort buffer是每个Thread独享的,所以说可能在同一时刻在MySQL中可能存在多个sort buffer内存区域。
1. 双路排序(又叫回表排序模式)
- 首先根据相应的条件取出相应的
排序字段和可以直接定位行数据的行 ID - 然后在 sort buffer (内存排序)中进行排序,排序完后需要再次取回其它需要的字段;
- 用trace工具可以看到sort_mode信息里显示< sort_key, rowid >
第一遍扫描出需要排序的字段,然后进行排序后,根据排序结果,第二遍再扫描一下需要select的列数据。这样会引起大量的随机IO,效率不高,但是节约内存。排序使用quick sort,但是如果内存不够则会按照 block 进行排序,将排序结果写入磁盘文件,然后再将结果合并。
2. 单路排序
- 一次性取出满足条件行的
所有字段,然后在sort buffer内存中进行排序; - 用trace工具可以看到sort_mode信息里显示< sort_key, additional_fields >或者< sort_key, packed_additional_fields >
- 不需要回表获取其他字段效率高,但将所有字段取出,在sort buffer中排序,占用内存
如何选择文件排序方式
MySQL 通过比较系统变量 max_length_for_sort_data(默认1024字节) 的大小和需要查询的字段总大小来判断使用哪种排序模式。
- 如果 字段的总长度小于max_length_for_sort_data ,那么使用 单路排序模式
- 如果 字段的总长度大于max_length_for_sort_data ,那么使用 双路排序模式
示例验证下各种排序方式:

查看下这条sql对应trace结果如下(只展示排序部分):
mysql> set session optimizer_trace="enabled=on",end_markers_in_json=on; --开启trace
mysql> select * from employees where name = 'zhuge' order by position;
mysql> select * from information_schema.OPTIMIZER_TRACE;trace排序部分结果:
"join_execution": { --Sql执行阶段"select#": 1,"steps": [{"filesort_information": [{"direction": "asc","table": "`employees`","field": "position"}] /* filesort_information */,"filesort_priority_queue_optimization": {"usable": false,"cause": "not applicable (no LIMIT)"} /* filesort_priority_queue_optimization */,"filesort_execution": [] /* filesort_execution */,"filesort_summary": { --文件排序信息"rows": 10000, --预计扫描行数"examined_rows": 10000, --参与排序的行"number_of_tmp_files": 3, --使用临时文件的个数,这个值如果为0代表全部使用的sort_buffer内存排序,否则使用的磁盘文件排序"sort_buffer_size": 262056, --排序缓存的大小,单位Byte"sort_mode": "<sort_key, packed_additional_fields>" --排序方式,这里用的单路排序} /* filesort_summary */}] /* steps */} /* join_execution */mysql> set max_length_for_sort_data = 10; --employees表所有字段长度总和肯定大于10字节
mysql> select * from employees where name = 'zhuge' order by position;
mysql> select * from information_schema.OPTIMIZER_TRACE;trace排序部分结果:
"join_execution": {"select#": 1,"steps": [{"filesort_information": [{"direction": "asc","table": "`employees`","field": "position"}] /* filesort_information */,"filesort_priority_queue_optimization": {"usable": false,"cause": "not applicable (no LIMIT)"} /* filesort_priority_queue_optimization */,"filesort_execution": [] /* filesort_execution */,"filesort_summary": {"rows": 10000,"examined_rows": 10000,"number_of_tmp_files": 2,"sort_buffer_size": 262136, "sort_mode": "<sort_key, rowid>" --排序方式,这里用的双路排序} /* filesort_summary */}] /* steps */} /* join_execution */mysql> set session optimizer_trace="enabled=off"; --关闭trace
我们先看单路排序的详细过程:
- 从索引name找到第一个满足 name = ‘zhuge’ 条件的主键 id
- 根据主键 id 取出整行,取出所有字段的值,存入 sort_buffer 中
- 从索引name找到下一个满足 name = ‘zhuge’ 条件的主键 id
- 重复步骤 2、3 直到不满足 name = ‘zhuge’
- 对 sort_buffer 中的数据按照字段 position 进行排序
- 返回结果给客户端
我们再看下双路排序的详细过程:
- 从索引 name 找到第一个满足 name = ‘zhuge’ 的主键id
- 根据主键 id 取出整行,把排序字段 position 和主键 id 这两个字段放到 sort buffer 中
- 从索引 name 取下一个满足 name = ‘zhuge’ 记录的主键 id
- 重复 3、4 直到不满足 name = ‘zhuge’
- 对 sort_buffer 中的字段 position 和主键 id 按照字段 position 进行排序
- 遍历排序好的 id 和字段 position,按照 id 的值回到原表中取出 所有字段的值返回给客户端
三、总结
-
其实对比两个排序模式,单路排序会把所有需要查询的字段都放到 sort buffer 中,而双路排序只会把主键和需要排序的字段放到 sort buffer 中进行排序,然后再通过主键回到原表查询需要的字段。
-
如果 MySQL 排序内存 sort_buffer 配置的比较小并且没有条件继续增加了,可以适当把 max_length_for_sort_data 配置小点,让优化器选择使用双路排序算法,可以在sort_buffer 中一次排序更多的行,只是需要再根据主键回到原表取数据。
-
如果 MySQL 排序内存有条件可以配置比较大,可以适当增大 max_length_for_sort_data 的值,让优化器优先选择全字段排序(单路排序),把需要的字段放到 sort_buffer 中,这样排序后就会直接从内存里返回查询结果了。
-
所以,MySQL通过 max_length_for_sort_data 这个参数来控制排序,在不同场景使用不同的排序模式,从而提升排序效率。
注意: 如果全部使用sort_buffer内存排序一般情况下效率会高于磁盘文件排序,但不能因为这个就随便增大sort_buffer(默认1M),mysql很多参数设置都是做过优化的,不要轻易调整。
相关文章:
【mysql学习篇】Order by与Group by优化以及排序算法详解
一、Order by与Group by优化 Case1: 分析: 利用最左前缀法则:中间字段不能断,因此查询用到了name索引,从key_len74也能看出,age索引列用在排序过程中,因为Extra字段里没有using filesort 注意…...
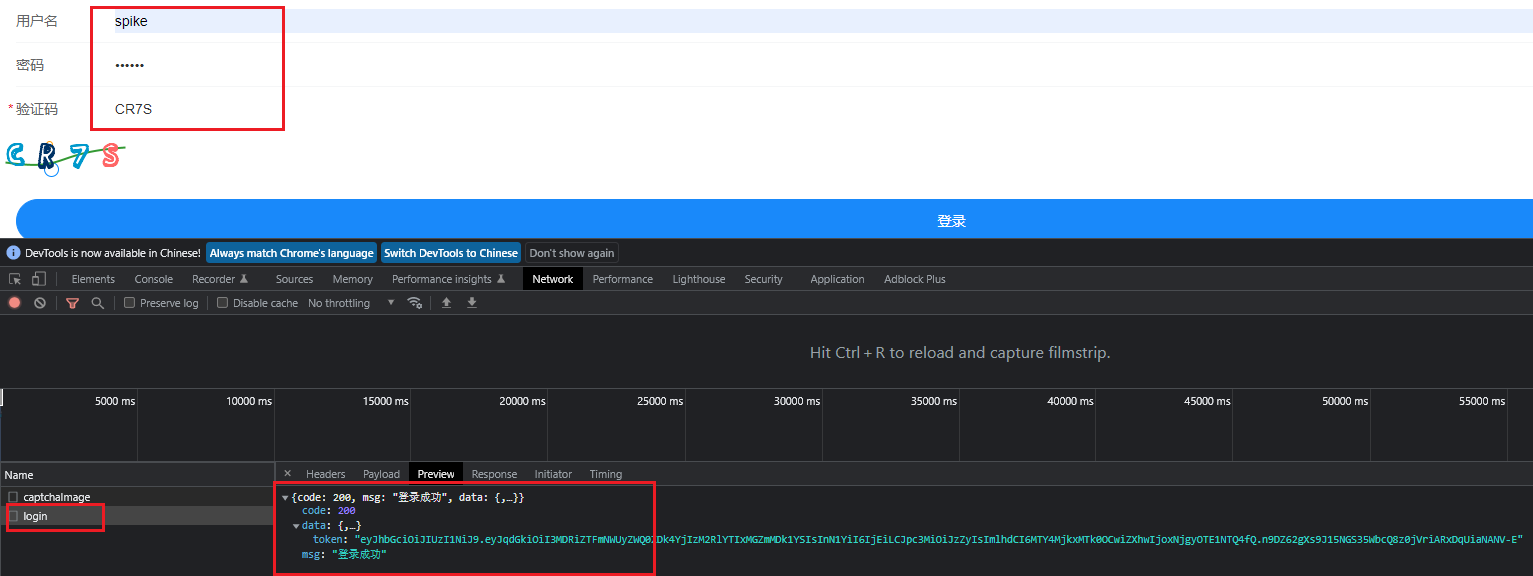
【业务功能篇60】Springboot + Spring Security 权限管理 【终篇】
4.4.7 权限校验扩展 4.4.7.1 PreAuthorize注解中的其他方法 hasAuthority:检查调用者是否具有指定的权限; RequestMapping("/hello")PreAuthorize("hasAuthority(system:user:list)")public String hello(){return "hello Sp…...
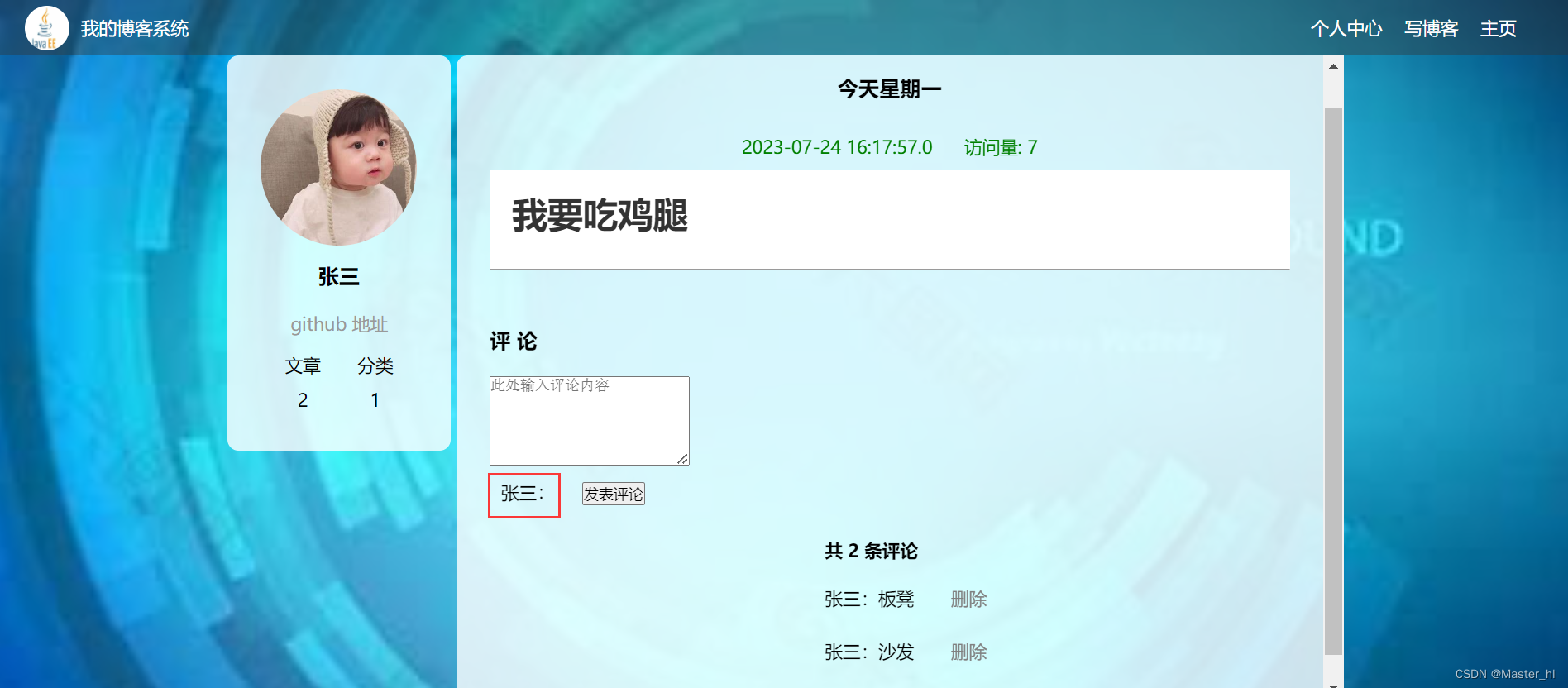
文章详情页 - 评论功能的实现
目录 1. 准备工作 1.1 创建评论表 1.2 创建评论实体类 1.3 创建 mapper 层评论接口和对应的 xml 实现 1.4 准备评论的 service 层 1.5 准备评论的 controller 层 2. 总的初始化详情页 2.1 加载评论列表 2.1.1 实现前端代码 2.1.2 实现后端代码 2.2 查询当前登录用户的…...
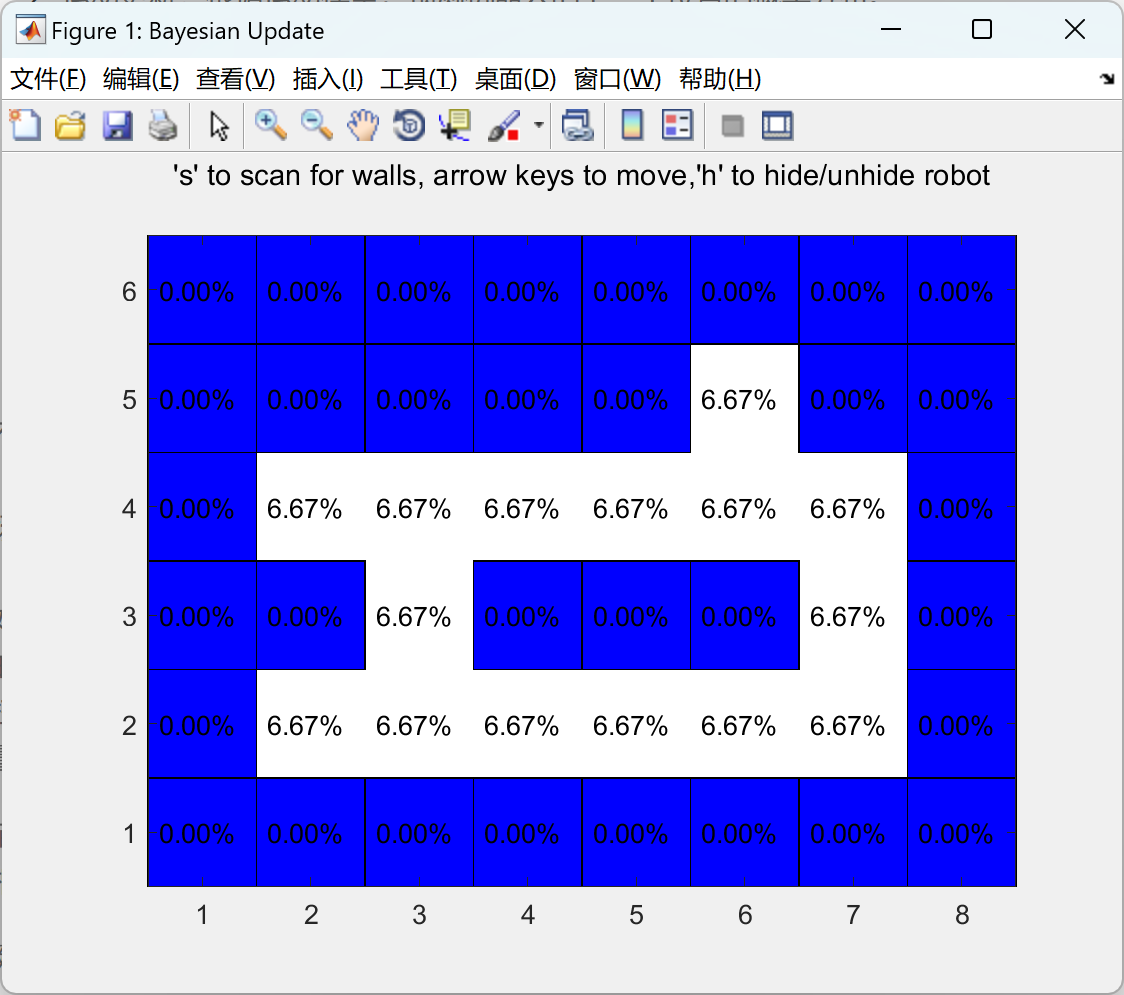
使用贝叶斯滤波器通过运动模型和嘈杂的墙壁传感器定位机器人研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
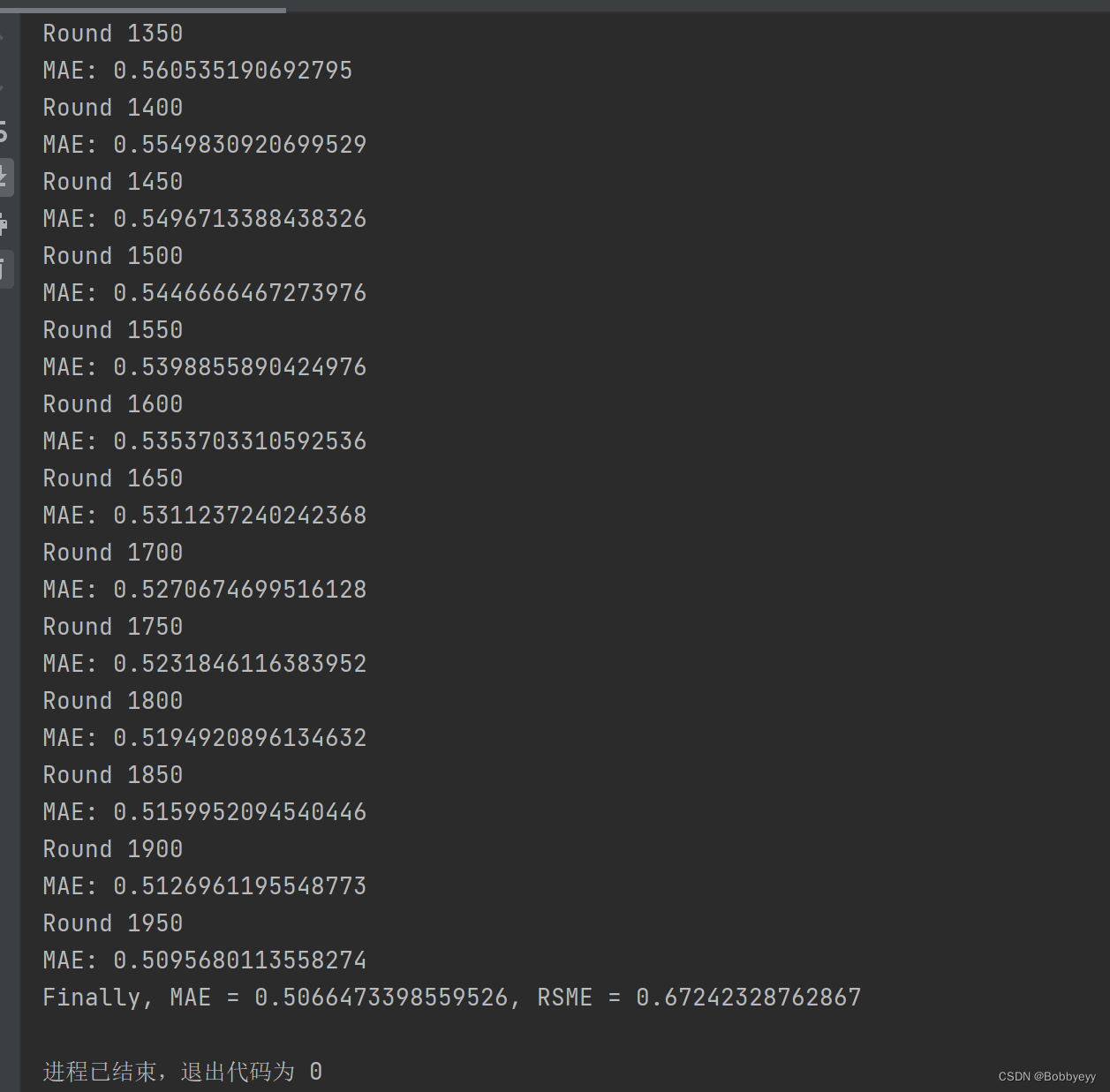
Day 69-70:矩阵分解
代码: package dl;import java.io.*; import java.util.Random;/** Matrix factorization for recommender systems.*/public class MatrixFactorization {/*** Used to generate random numbers.*/Random rand new Random();/*** Number of users.*/int numUsers…...

数据结构:树的存储结构
学习树之前,我们已经了解了二叉树的顺序存储和链式存储,哪么我们如何来存储普通型的树结构的数据?如下图1: 如图1所示,这是一颗普通的树,我们要如何来存储呢?通常,存储这种树结构的数…...
Vue前端渲染blob二进制对象图片的方法
近期做开发,联调接口。接口返回的是一张图片,是对二进制图片处理并渲染,特此记录一下。 本文章是转载文章,原文章:Vue前端处理blob二进制对象图片的方法 接口response是下图 显然,获取到的是一堆乱码&…...
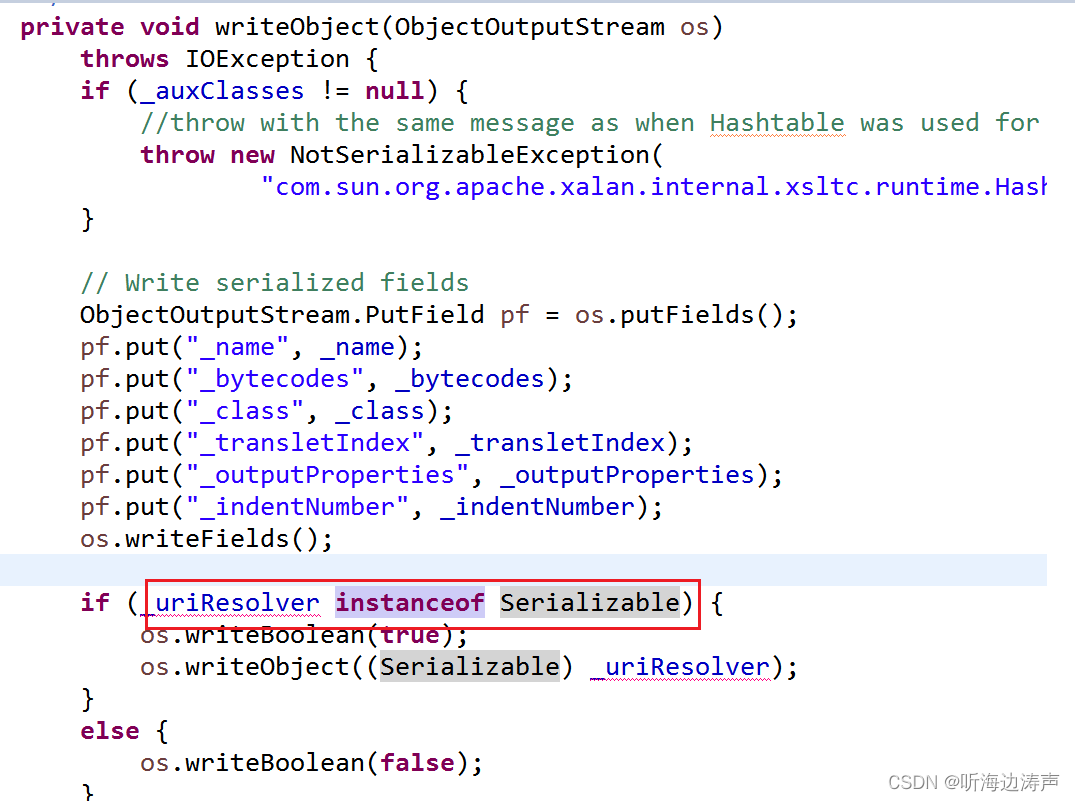
Java的标记接口(Marker Interface)
Java中的标记接口(Marker Interface)是一个空接口,接口内什么也没有定义。它标识了一种能力,标识继承自该接口的接口、实现了此接口的类具有某种能力。 例如,jdk的com.sun.org.apache.xalan.internal.xsltc.trax.Temp…...
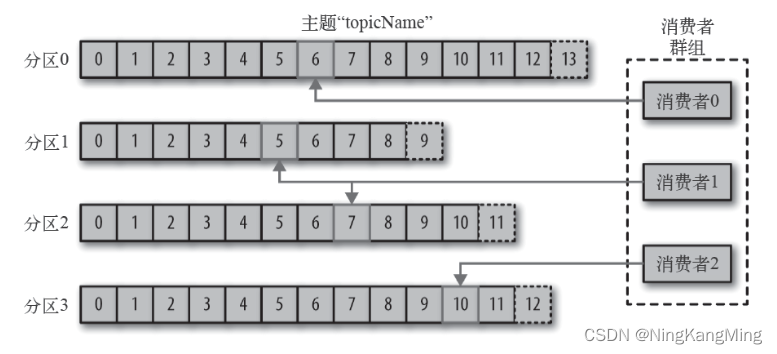
Kafka基础架构与核心概念
Kafka简介 Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。架构特点是分区、多副本、多生产者、多订阅者,性能特点主要是…...
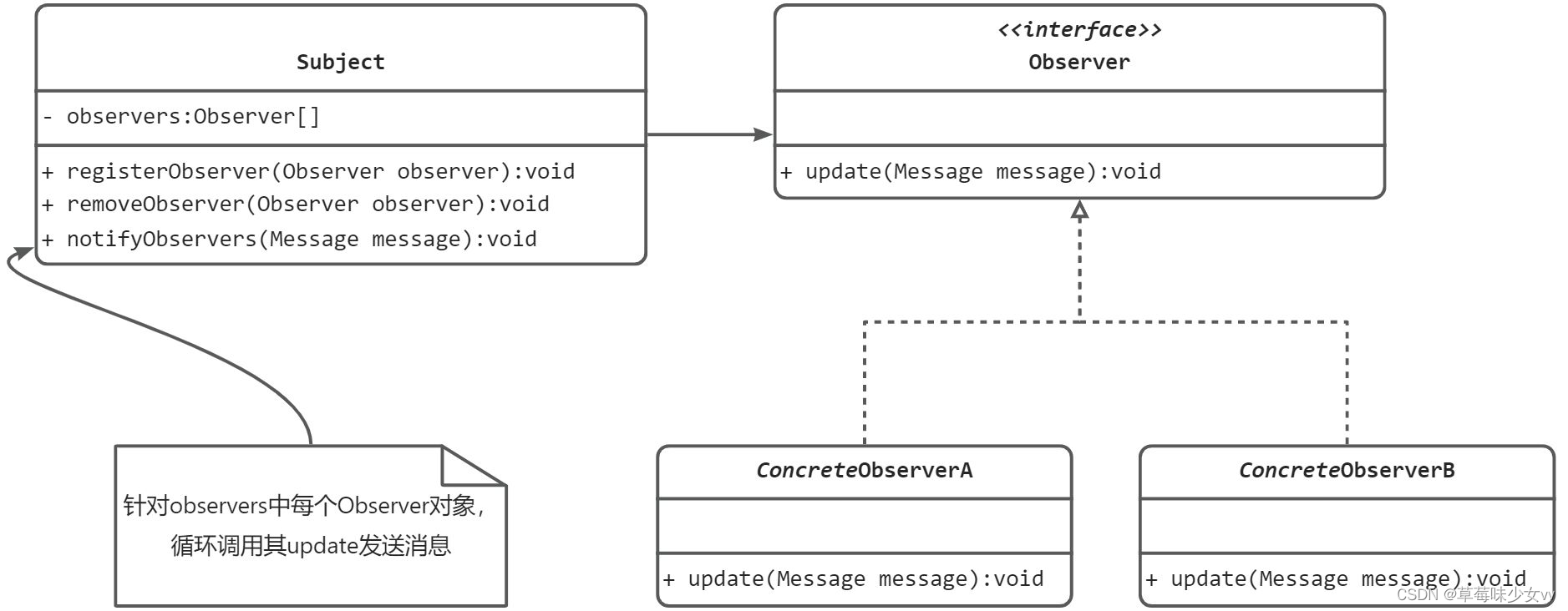
观察者模式与观察者模式实例EventBus
什么是观察者模式 顾名思义,观察者模式就是在多个对象之间,定义一个一对多的依赖,当一个对象状态改变时,所有依赖这个对象的对象都会自动收到通知。 观察者模式也称为发布订阅模式(Publish-Subscribe Design Pattern)࿰…...

科普 | OSI模型
本文简要地介绍 OSI 模型 1’ 2’ 3。 更新:2023 / 7 / 23 科普 | OSI模型 术语节点链路协议网络拓扑 概念作用结构应用层表示层会话层传输层网络层数据链路层物理层 数据如何流动OSI 和TCP/IP 的对应关系和协议参考链接 术语 节点 节点( Node &#…...

redis相关异常之RedisConnectionExceptionRedisCommandTimeoutException
本文只是分析Letture类型的Redis 池化连接出现的连接超时异常、读超时异常问题。 1.RedisConnectionException 默认是10秒。 通过如下可以配置: public class MyLettuceClientConfigurationBuilderCustomizer implements LettuceClientConfigurationBuilderCusto…...

Merge the squares! 2023牛客暑期多校训练营4-H
登录—专业IT笔试面试备考平台_牛客网 题目大意:有n*n个边长为1的小正方形摆放在边长为n的大正方形中,每次可以选择不超过50个正方形,将其合并为一个更大的正方形,求一种可行的操作使所有小正方形都被合并成一个n*n的大正方形 1…...
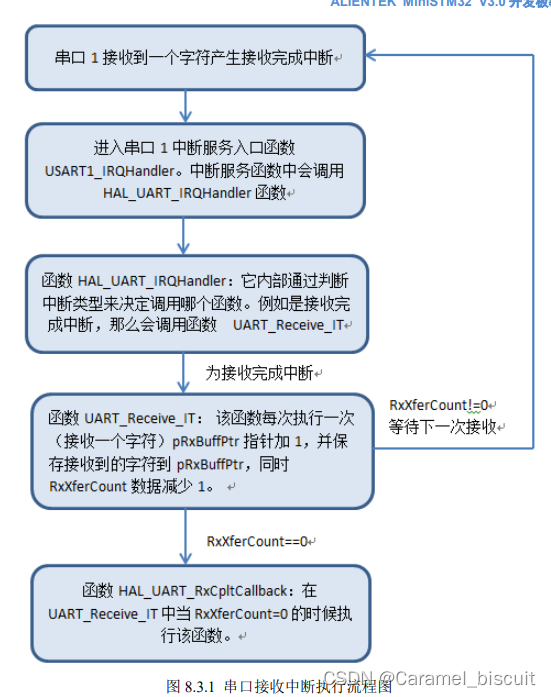
STM32 串口学习(二)
要用跳线帽将PA9与RXD相连,PA10与TXD相连。 软件设计 void uart_init(u32 baud) {//UART 初始化设置UART1_Handler.InstanceUSART1; //USART1UART1_Handler.Init.BaudRatebound; //波特率UART1_Handler.Init.WordLengthUART_WORDLENGTH_8B; //字长为 8 位数据格式U…...
点大商城V2_2.5.0 全开源版 商家自营+多商户入驻 百度+支付宝+QQ+头条+小程序端+unipp开源前端安装测试教程
安装测试环境:Nginx 1.20PHP7.2MySQL 5.6 修复了无法上传开放平台问题 安装说明: 1、上传后端目录至网站 2、导入提供的数据库文件 3、修改数据库配置文件根目录下config.php,增加数据库用户名和密码 4、网站后台直接访问网址ÿ…...

“深入理解SpringBoot:从入门到精通“
标题:深入理解Spring Boot:从入门到精通 摘要:本文将介绍Spring Boot的基本概念和核心特性,并通过示例代码演示如何使用Spring Boot构建一个简单的Web应用程序。 1. 简介 Spring Boot是一个开源的Java框架,旨在简化基…...

PCB绘制时踩的坑 - SOT-223封装
SOT-223封装并不是同一的,细分的话可以分为两种常用的封装。尤其是tab脚的属性很容易搞错。如果你想着用tab脚连接有属性的铺铜,来提高散热效率,那么你一定要注意你购买的器件tab脚的属性。 第一种如下图,第1脚为GND,第…...
Go语法入门 + 项目实战
👂 Take me Hand Acoustic - Ccile Corbel - 单曲 - 网易云音乐 第3个小项目有问题,不能在Windows下跑,懒得去搜Linux上怎么跑了,已经落下进度了.... 目录 😳前言 🍉Go两小时 🔑小项目实战 …...
QT控件通过qss设置子控件的对齐方式、大小自适应等
一些复杂控件,是有子控件的,每个子控件,都可以通过qss的双冒号选择器来选中,进行独特的样式定义。很多控件都有子控件,太多了,后面单独写一篇文章来介绍各个控件的子控件。这里就随便来几个例子 例如下拉列…...

基于java在线收银系统设计与实现
摘要 科技的力量总是在关键的地方改变着人们的生活,不仅如此,我们的生活也是离不开这样或者那样的科技改变,有的消费者没有时间去商场购物,那么电商和快递的结合让端口到消费者的距离不再遥远;有的房客因地域或者工作的…...

WarcraftHelper终极指南:3大模块彻底解决魔兽争霸3兼容性问题
WarcraftHelper终极指南:3大模块彻底解决魔兽争霸3兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3在Win…...

3个步骤掌握BilibiliDown:零基础也能轻松下载B站视频
3个步骤掌握BilibiliDown:零基础也能轻松下载B站视频 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi…...

终极免费方案:如何5分钟搞定Axure RP全界面中文汉化
终极免费方案:如何5分钟搞定Axure RP全界面中文汉化 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的…...

终极iOS设备激活解锁解决方案:Applera1n完全指南
终极iOS设备激活解锁解决方案:Applera1n完全指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾经遇到过二手iPhone或iPad无法激活的困境?当你满怀期待地拿到一台设备…...

【ChatGPT商业计划书写作避坑手册】:基于216份真实BP评审数据,揭示投资人3秒淘汰BP的底层逻辑
更多请点击: https://kaifayun.com 第一章:ChatGPT商业计划书的核心价值定位 ChatGPT商业计划书并非通用技术方案说明书,而是面向特定商业场景的价值契约——它精准锚定AI能力与企业增长杠杆之间的耦合点,将大语言模型的泛化智能…...

Win11Debloat:Windows系统终极清理与优化完全指南
Win11Debloat:Windows系统终极清理与优化完全指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

BiliBiliCCSubtitle架构解析:C++实现的B站CC字幕高效下载与转换技术方案
BiliBiliCCSubtitle架构解析:C实现的B站CC字幕高效下载与转换技术方案 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle BiliBiliCCSubtitle是一款基于C…...

布里渊散射与机器学习势场协同表征MOF力学性能
1. 项目概述:当布里渊散射遇见机器学习势场在材料科学的前沿探索中,我们常常面临一个核心挑战:如何精确、无损地获取复杂材料的本征力学性能,尤其是那些结构精巧但晶体尺寸微小的新材料。金属有机框架(MOFs)…...

告别重装!用Systemback在Ubuntu 20.04上打造你的专属系统‘时光机’
用Systemback为Ubuntu打造专属系统时光机每次系统崩溃都要重装?开发环境配置浪费半天时间?实验室电脑和个人笔记本环境不一致?这些问题对于频繁折腾系统的开发者来说简直是噩梦。Systemback就像给Ubuntu系统装上了"时光机"…...

昇腾CANN ops-blas Batched GEMM:多头注意力的小矩阵乘批处理实战
Transformer 的 Multi-Head Attention 有 H 个注意力头——每个头独立做矩阵乘(QhKh^T、AttnVh)。H32 时,一个 BatchNorm 后面紧跟着 32 个小矩阵乘(每个头独立)。单独启动 32 次 GEMM 会有 32 次 launch 开销…...