极速查找(3)-算法分析
篇前小言
本篇文章是对查找(2)的续讲
二叉排序树
二叉排序树(Binary Search Tree,BST),又称为二叉查找树,是一种特殊的二叉树。
性质:
左子树的节点值小于根节点的值,右子树的节点值大于根节点的值:这是二叉排序树最基本的性质。对
于任意节点N,其左子树中的所有节点的值都小于N的值,而右子树中的所有节点的值都大于N的值。这
个性质决定了二叉排序树的有序性,使得我们可以通过比较节点值进行快速的插入、删除和查找操作。中序遍历的结果是按序排列的序列:由于二叉排序树的左子树中的节点值都小于根节点的值,而右子树
中的节点值都大于根节点的值,所以中序遍历的结果是一个按序排列的序列。这使得二叉排序树可以实
现排序功能,将节点按值的大小进行有序存储。对于任意节点,左子树和右子树也是二叉排序树:这个性质是递归地应用于每个节点的子树。由于左子
树中的节点值都小于根节点的值,右子树中的节点值都大于根节点的值,并且左子树和右子树都是二叉
排序树,因此这个性质得以满足。不存在相同值的节点:在二叉排序树中,每个节点的值是唯一的。这是为了确保树的每个节点都可以通
过值进行唯一的标识和比较。平均查找时间复杂度为O(log n):由于二叉排序树的有序性质,当树是平衡的时候,即左右子树的高
度相差不大时,平均查找时间复杂度可以达到O(log n)。这是因为每次查找都是通过二分法来进行的,
每次可以将问题规模减半。但是如果二叉排序树是不平衡的,即左右子树的高度相差较大,可能会导致
查找性能下降,退化为线性查找(O(n)时间复杂度)。可以支持插入、删除和查找操作:二叉排序树的性质使得它可以高效地支持插入、删除和查找操作。插
入操作按照节点值的大小,在合适的位置插入新节点。删除操作涉及到对不同情况进行处理,包括删除
叶子节点、删除只有一个子节点的节点以及删除有两个子节点的节点。查找操作可以通过比较给定值和
当前节点值的大小,递归地向左子树或右子树查找目标值。
特点
有序性:二叉排序树是一种有序的二叉树结构,它的左子树中的节点值都小于根节点的值,而右子树中
的节点值都大于根节点的值。这种有序性质使得二叉排序树在存储、查找和排序数据时具有很高的效率。中序遍历有序:二叉排序树的中序遍历结果是一个按序排列的序列。即按照"左子树-根节点-右子树"的
顺序遍历二叉排序树的节点,可以得到一个按节点值升序排列的序列。这种特点使得二叉排序树可以用
于实现排序功能。可以进行高效的插入、删除和查找操作:由于二叉排序树的有序性,插入、删除和查找操作可以在平均
情况下以O(log n)的时间复杂度完成。在插入操作中,根据节点值的大小,递归地插入新节点到合适的
位置。在删除操作中,根据节点值的大小,递归地删除指定节点。在查找操作中,根据节点值的大小,
递归地向左或向右查找目标节点。不允许重复值:二叉排序树中的节点值是唯一的,不存在相同值的节点。这是为了确保树的每个节点都
可以通过值进行唯一的标识和比较。可以支持快速的最小值和最大值查询:由于二叉排序树的有序性质,可以很快地找到最小值和最大值。
最小值位于树的最左边(最左子节点),而最大值位于树的最右边(最右子节点)。
优点
有序存储和排序功能:二叉排序树的节点存储是有序的,左子树中的节点值都小于根节点的值,而右子
树中的节点值都大于根节点的值。这使得二叉排序树可以通过中序遍历得到一个按节点值升序排列的序
列,实现了快速的排序功能。高效的插入、删除和查找操作:由于二叉排序树的有序性,插入、删除和查找操作可以在平均情况下以
O(log n)的时间复杂度完成。在插入操作中,根据节点值的大小,在合适的位置递归地插入新节点。在
删除操作中,根据节点值的大小,在合适的位置递归地删除节点。在查找操作中,根据节点值的大小,
在合适的位置递归地查找目标节点。这使得二叉排序树非常适合存储和操作有序的数据集合。快速的最小和最大值查询:由于二叉排序树的有序性特点,可以快速地找到最小值和最大值。最小值位
于树的最左边(最左子节点),而最大值位于树的最右边(最右子节点)。这对于需要频繁查找最小和
最大值的场景很有帮助。灵活性:二叉排序树的节点结构简单且灵活,可以根据实际需求进行扩展,如增加额外的属性或方法。
这使得二叉排序树可以支持更复杂的操作和算法,满足不同场景的需求。内存利用率高:二叉排序树在存储数据时,只需要存储节点的值和左右子树的指针,相较于其他数据结
构,它的内存占用较小。而且,由于平均查找时间复杂度为O(log n),数据量越大,二叉排序树的优势
更加明显。
缺点
对于随机插入的数据,可能会导致树的不平衡:二叉排序树的性能高度依赖于树的平衡性。如果在插入
过程中不平衡地插入节点,可能会导致树的不平衡,使得树的深度增加,进而降低了效率。不平衡的树
可能会导致查找、插入和删除操作的时间复杂度由原来的O(log n)退化为O(n),变成线性操作,降低
了性能。效率受数据分布的影响:二叉排序树的效率受到数据分布的影响。如果数据按照有序的方式插入二叉排
序树中,比如按照升序或降序的顺序,可能会导致树的不平衡,进而降低效率。为了克服这个问题,可
以使用某些技术,如随机化插入或平衡二叉搜索树,来解决数据分布对效率的影响。需要额外的内存空间:除了存储节点的值和左右子树的指针,二叉排序树还需要额外的内存空间来存储
节点的额外信息,如父指针。而一些其他数据结构,如数组,只需要连续的内存空间即可存储数据,没
有额外的空间开销。不支持高效的范围查询:尽管二叉排序树可以快速找到最小值和最大值,并且支持单个元素的查找,但
对于范围查询(如查找在给定范围内的值)来说,并不是最优的数据结构。范围查询可能需要遍历的节
点数与树中元素的数量成比例,而不仅仅是与树的高度有关。如果需要高效地支持范围查询,可以考虑
使用其他数据结构,如平衡二叉搜索树的变种(如红黑树)或B树等。难以处理重复值:二叉排序树的每个节点值是唯一的,不允许重复值的存在。如果需要支持重复值的存
储和操作,必须引入一些额外的机制,如在节点中存储计数信息,或者在节点左右子树中维护重复值的
集合。这会增加复杂性和实现难度。
实际应用
数据库索引:在关系型数据库中,二叉排序树经常被用作索引结构,以加快数据的查找速度。数据库表
中的某一列可以作为二叉排序树的键,通过构建二叉排序树来加速对表的查询操作。字典和查找表:二叉排序树可以用于实现字典和查找表功能,其中关键字作为树的节点值,便于快速的
插入、删除和查找操作。这在文本编辑器、拼写检查器、自动补全功能等应用中非常有用。文件系统和目录结构:文件系统和目录结构可以用二叉排序树来组织和管理文件和目录。文件名或目录
名作为树的节点值,通过二叉排序树可以快速地进行文件查找、插入和删除操作。动态排名和统计:二叉排序树可以用于实现动态排名和统计功能。通过对节点进行适当的标记或调整,
可以快速找到某个节点的排名,或者统计某个范围内有多少个节点,方便计算和分析。范围查询和区间搜索:尽管二叉排序树不是最优的数据结构来支持范围查询,但在某些情况下它仍然可
以用于处理范围查询和区间搜索。可以通过递归遍历树的方式,找到满足指定范围条件的节点。数值集合操作:二叉排序树可以用于实现对数值集合进行操作,如合并集合、交集、差集等。树的节点
值可以表示数值,通过对树的遍历和操作,可以实现集合操作。
平衡二叉树
性质:
平衡性:平衡二叉树的平衡性是指树中任意节点的左子树和右子树的高度差不超过1。这意味着对于每个节点,其左子树的高度和右子树的高度之差的绝对值不大于1。平衡性是保持树的高度相对较低,从而确保树的操作性能高效的关键特性。高度的上界和下界:对于一个具有n个节点的平衡二叉树,其高度h满足以下条件:h <= log2(n+1)h >= log2(n)这意味着平衡二叉树的高度上界是O(log n),下界是O(log n)。自平衡操作:平衡二叉树通过自平衡操作来维持其平衡性。插入或删除节点时,如果导致某个节点的平衡因子大于1或小于-1,就需要通过旋转或其他操作来调整树的结构。一般来说,平衡二叉树的自平衡操作包括左旋、右旋、双旋等,以保持树的平衡状态。查找操作:平衡二叉树支持高效的查找操作。由于平衡二叉树的节点值有序排列,可以使用二分查找的方式在O(log n)时间复杂度内完成查找。插入和删除操作:插入和删除操作的平均时间复杂度为O(log n)。添加一个节点时,树可能需要进行自平衡操作来保持平衡性。删除一个节点时,也可能需要进行自平衡操作。删除操作可能需要找到一个适当的替代节点来替代被删除的节点。局部性原理的优化:
平衡二叉树利用局部性原理进行优化,即通过在内存中存储相邻节点,减少磁盘I/O的次数,提高查询
性能。
特点
平衡性:
平衡二叉树的定义是指对于树中的每个节点,其左右子树的高度差(平衡因子)不超过1。
平衡因子定义为节点的左子树高度减去右子树的高度,平衡因子的绝对值不大于1。
通过保持平衡性,平衡二叉树可以避免出现树的高度差过大的情况,提供较好的平均查找性能。快速的插入、删除和查找操作:
平衡二叉树的插入、删除和查找操作的平均时间复杂度为O(log n),其中n为树中节点的数量。
平衡二叉树通过自平衡操作来维持平衡性,在插入或删除节点后,通过旋转操作恢复平衡。
自平衡操作的时间复杂度为O(1),使得平衡二叉树的插入、删除和查找操作具有较好的性能。自适应动态数据结构:
平衡二叉树适用于动态的数据集合,即在频繁插入和删除节点的情况下能够保持树的平衡性。
平衡二叉树通过自平衡操作,能够自动调整树的结构,使得树的高度保持相对较低,适应不断变化的数
据集合。有序性操作支持:
平衡二叉树的节点按照某种顺序排列,一般是左子树节点值小于根节点,右子树节点值大于根节点的方
式。
这使得平衡二叉树可以支持快速的有序性操作,如范围查询、查找最小值和最大值等。
有序性操作在某些应用场景中非常重要,平衡二叉树提供了高效的实现方式。自平衡的数据结构:
平衡二叉树是一种自平衡的数据结构,通过特定的自平衡操作来保持树的平衡性。
在插入和删除节点时,平衡二叉树可以通过旋转和调整操作保持树的平衡状态。
自平衡的特性使得平衡二叉树相对于非平衡的二叉搜索树,如普通二叉搜索树,更加稳定和可靠。
优点
快速的插入、删除和查找操作:
平衡二叉树的插入、删除和查找操作的平均时间复杂度为O(log n),其中n为树中节点的数量。
平衡二叉树通过自平衡操作来维持平衡性,使得树的高度保持较低,从而提供快速的操作性能。
自平衡操作的时间复杂度为O(1),因此,无论树的大小如何,插入、删除和查找操作的时间复杂度都保
持在对数级别。自适应动态数据结构:
平衡二叉树适用于频繁插入和删除节点的动态数据集合。它可以在数据集合大小改变时自动调整树的结
构,维持平衡性。
自适应动态的特性使得平衡二叉树适用于场景中数据频繁变化的情况,如动态存储、实时数据处理等。有序性操作支持:
平衡二叉树的节点按照某种顺序排列,一般是左子树节点值小于根节点,右子树节点值大于根节点的方
式。
有序性的排列使得平衡二叉树支持快速的有序性操作,如范围查询、查找最小值和最大值等。
有序性操作在某些应用场景中非常重要,平衡二叉树提供了高效的实现方式。自平衡的数据结构:
平衡二叉树是一种自平衡的数据结构,通过特定的自平衡操作来保持树的平衡性。
自平衡的特性使得平衡二叉树相对于非平衡的二叉搜索树,如普通二叉搜索树,更加稳定和可靠。
在插入和删除节点时,平衡二叉树可以通过旋转和调整操作保持树的平衡状态,避免出现树的高度差过
大的情况。高效的存储和查询:
平衡二叉树可以使用相对较少的额外存储空间来存储平衡因子,使得空间占用更低。
在平衡二叉树中,节点按照有序性排列,使得查询操作可以利用二分查找的方式,在较短时间内完成。
缺点
内存空间需求较大:
平衡二叉树需要在每个节点中保存额外的平衡因子信息,以及链接指向左子树和右子树的指针。
这样的额外信息和指针会占用更多的内存空间,相对于普通的二叉搜索树,平衡二叉树需要更大的存储
空间。自平衡操作的复杂性:
平衡二叉树的自平衡操作需要在插入和删除节点时进行,以保持树的平衡性。
这些自平衡操作的实现可能较为复杂,需要额外的计算和判断,增加了代码的复杂性。自适应调整的开销:
平衡二叉树在插入和删除节点时需要进行自平衡操作,以维持树的平衡性。
这些自平衡操作可能涉及到多次旋转、调整和重新连接节点,引入了一定的开销。
尽管自平衡操作的时间复杂度为O(1),但实际上可能需要花费相对较长的时间执行。不适合频繁修改的场景:
平衡二叉树适用于频繁的查询操作,但对于频繁的插入和删除操作,可能不是最佳选择。
在频繁修改的场景中,由于每次操作都需要进行自平衡操作,可能导致频繁的树结构调整,影响效率。不适合大规模数据:
随着数据量的增加,平衡二叉树的自平衡操作会变得更加耗时,可能导致性能下降。
对于大规模数据集合,可能需要更高级的平衡二叉树变种,如B树、红黑树等。
实际应用
数据库索引结构:平衡二叉树被广泛应用于数据库中的索引结构,如B+树和红黑树。
数据库中的索引用于快速查找和访问数据,平衡二叉树的有序性和快速的插入、删除、查询操作使其成
为理想的索引结构。文件系统:
平衡二叉树经常用于文件系统中的目录结构,确保文件和目录的快速查找和访问。
文件系统中的目录和文件具有层次结构,平衡二叉树能够有效地组织和管理这种层次结构,提供高效的
文件访问。编程语言中的集合和映射:
许多编程语言的标准库或第三方库中提供了平衡二叉树的实现,用于集合和映射等数据结构。
这些实现通常提供快速的插入、删除和查找操作,以及有序性的支持,满足了许多编程任务中的需求,
如排序、搜索等。游戏开发:
平衡二叉树在游戏开发中有许多应用,如实现碰撞检测、空间划分、排序等。
平衡二叉树可以存储游戏中的对象,并支持高效的查找和更新操作,提供了快速的游戏性能。排序和搜索算法:
平衡二叉树作为搜索和排序算法的基础结构,可以用于实现各种搜索和排序算法,如二分查找、中序遍
历等。
平衡二叉树的有序性和快速的插入、删除操作使其成为实现这些算法的有效选择。
相关文章:
-算法分析)
极速查找(3)-算法分析
篇前小言 本篇文章是对查找(2)的续讲二叉排序树 二叉排序树(Binary Search Tree,BST),又称为二叉查找树,是一种特殊的二叉树。性质: 左子树的节点值小于根节点的值,右…...

http 常见的响应状态码 ?
100——客户必须继续发出请求101——客户要求服务器根据请求转换HTTP协议版本200——交易成功201——提示知道新文件的URL202——接受和处理、但处理未完成203——返回信息不确定或不完整204——请求收到,但返回信息为空205——服务器完成了请求,用户代理…...
机器学习笔记之优化算法(四)线搜索方法(步长角度;非精确搜索)
机器学习笔记之优化算法——线搜索方法[步长角度,非精确搜索] 引言回顾:精确搜索步长及其弊端非精确搜索近似求解最优步长的条件反例论述 引言 上一节介绍了从精确搜索的步长角度观察了线搜索方法,本节将从非精确搜索的步长角度重新观察线搜…...
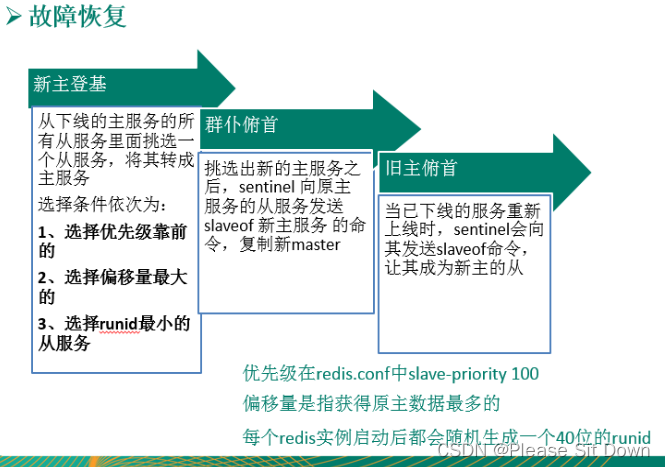
Redis 哨兵 (sentinel)
是什么 官网理论:https://redis.io/docs/management/sentinel/ 吹哨人巡查监控后台 master 主机是否故障,如果故障了根据投票数自动将某一个从库转换为新主库,继续对外服务。 作用:无人值守运维 哨兵的作用: 1…...

统计2021年10月每个退货率不大于0.5的商品各项指标
统计2021年10月每个退货率不大于0.5的商品各项指标_牛客题霸_牛客网s mysql(ifnull): select product_id, format(ifnull(sum(if_click)/nullif(count(*),0),0),3) as ctr, format(ifnull(sum(if_cart)/nullif(sum(if_click),0),0),3) as c…...
【小波尺度谱】从分段离散小波变换计算小波尺度谱研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
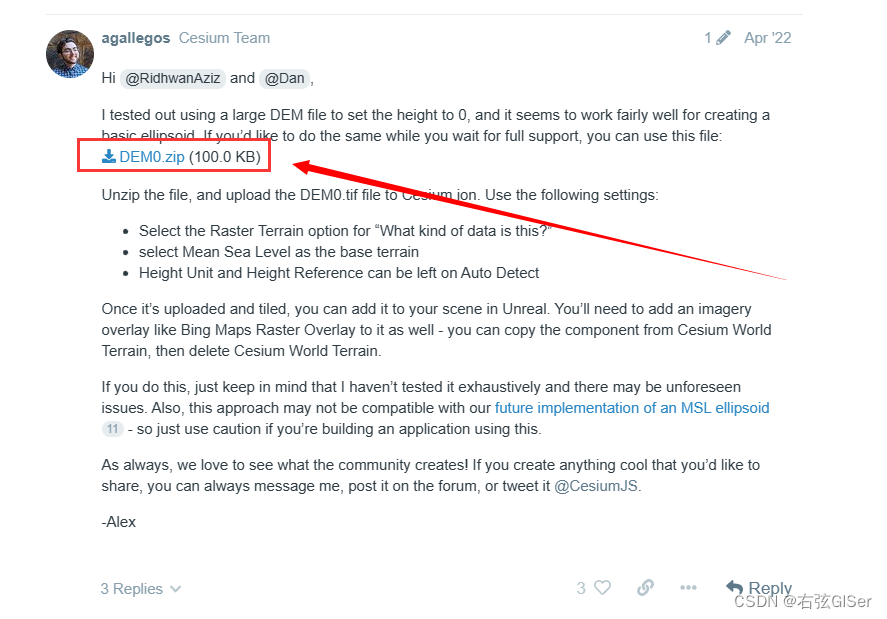
UE5、CesiumForUnreal加载无高度地形
文章目录 1.实现目标2.实现过程3.参考资料1.实现目标 在UE5中,CesiumForUnreal插件默认的地形都是带高度的,这里加载没有高度的地形,即大地高程为0,GIF动图如下: 2.实现过程 参考官方的教程,下载无高度的DEM,再切片加载到UE中。 (1)下载无高度地形DEM0。 在官方帖子…...

关于Spring中的@Configuration中的proxyBeanMethods属性
Configuration的proxyBeanMethods属性 在Configuration注解中,有两个属性: value配置Bean名称proxyBeanMethos,默认是true 这个proxyBeanMethods的默认属性是true。 直接说:当Configuration注解的proxyBeanMeathods属性是true…...

dp1,ACM暑期培训
D - 摆花 P1077 [NOIP2012 普及组] 摆花 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) Description 小明的花店新开张,为了吸引顾客,他想在花店的门口摆上一排花,共 m 盆。通过调查顾客的喜好,小明列出了顾客最喜欢的 n 种花&…...

大厂程序员的水平比非大厂高很多嘛?
最近一个月,筛选了一百多份简历,前前后后面试了二三十人,基本上都是有大厂经历的人。同时,也录用了几个有大厂经历的。但整体而言,打破了对大厂出来的都是优质人才的幻觉。看到的实际情况与想象中的落差还是比较大的。…...
Java开发工具MyEclipse发布v2023.1.2,今年第二个修复版!
MyEclipse一次性提供了巨量的Eclipse插件库,无需学习任何新的开发语言和工具,便可在一体化的IDE下进行Java EE、Web和PhoneGap移动应用的开发;强大的智能代码补齐功能,让企业开发化繁为简。 MyEclipse v2023.1.2官方正式版下载 …...
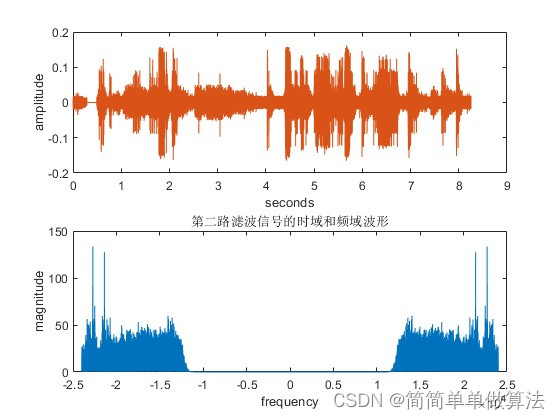
基于正交滤波器组的语音DPCM编解码算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ...........................................................g0zeros(1,lenH); g1zeros(1,l…...
VS2022和QT混合编程打包发布程序
1.在开始菜单输入 CMD 找到 Qt5.15.2(MSVC 64-bit) 2.输入windeployqt exe所在路径 3.运行完毕后,双击打开exe文件,可能会报错,缺少相关的dll,找到缺少的dll拷贝到运行文件夹下即可。...

Filebeat学习笔记
Filebeat基本概念 简介 Filebeat是一种轻量级日志采集器,内置有多种模块(auditd、Apache、Nginx、System、MySQL等),针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。之所以能实现这一点&#…...
 —— React17+React Hook+TS4 最佳实践,仿 Jira 企业级项目(十六))
【实战】 九、深入React 状态管理与Redux机制(一) —— React17+React Hook+TS4 最佳实践,仿 Jira 企业级项目(十六)
文章目录 一、项目起航:项目初始化与配置二、React 与 Hook 应用:实现项目列表三、TS 应用:JS神助攻 - 强类型四、JWT、用户认证与异步请求五、CSS 其实很简单 - 用 CSS-in-JS 添加样式六、用户体验优化 - 加载中和错误状态处理七、Hook&…...

第九十五回 如何使用dio的转换器
文章目录 概念介绍使用方法使用默认的转换器自定义转换器 示例代码经验分享 我们在上一章回中介绍了"如何打造一个网络框架"相关的内容,本章回中将介绍 如何使用dio的转换器.闲话休提,让我们一起Talk Flutter吧。 概念介绍 转换器主要用来转…...

Python深度学习“四大名著”之一【赠书活动|第二期《Python机器学习:基于PyTorch和Scikit-Learn》】
近年来,机器学习方法凭借其理解海量数据和自主决策的能力,已在医疗保健、 机器人、生物学、物理学、大众消费和互联网服务等行业得到了广泛的应用。自从AlexNet模型在2012年ImageNet大赛被提出以来,机器学习和深度学习迅猛发展,取…...
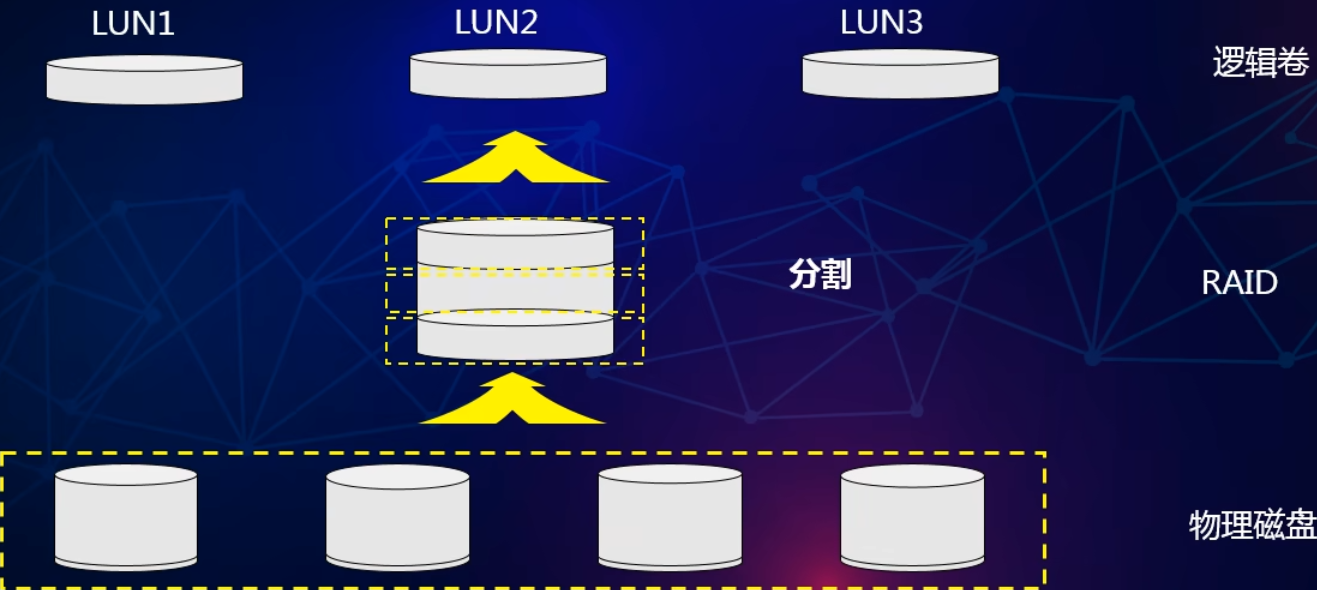
RAID相关知识
简介 RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,通常简称为磁盘阵列。RAID技术将多个单独的物理硬盘以不同的方式组合成一个逻辑磁盘,从而提高硬盘的读写性能和数据安全性。 数据组织形式 分块&#x…...
DataStructure--Basic
程序设计数据结构算法 只谈数据结构不谈算法就跟去话剧院看梁山伯与祝英台结果只有梁山伯在演,祝英台生病了没来一样。 本文的所有内容都出自《大话数据结构》这本书中的代码实现部分,建议看书,书中比我本文写的全。 数据结构,直…...
Intellij IDEA 双击启动报错ClassNotFoundException: com.licel.b.z@
项目场景: 新从官网下载了ideaIU-2023.2.win.zip ,安装后双击启动报错, 无法运行idea, 提示信息如下 问题描述 Internal error. Please refer to https://jb.gg/ide/critical-startup-errorsjava.lang.ExceptionInInitializerErrorat java…...

终极指南:如何用OpenCore Legacy Patcher让旧Mac焕发新生,完美运行最新macOS
终极指南:如何用OpenCore Legacy Patcher让旧Mac焕发新生,完美运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥…...

ICA与NMF算法详解:从盲源分离到矩阵分解的数学原理与工程实践
1. 项目概述:从数据噪音中“听”出独立的声音在信号处理、神经科学、金融数据分析等领域,我们常常会遇到一个经典的“鸡尾酒会问题”:在一个嘈杂的房间里,多个声源(比如不同人的谈话、背景音乐)的声音混合在…...
)
别再死记硬背了!用Python手把手拆解卡尔曼滤波的5个核心公式(附filterpy/OpenCV两种实现)
别再死记硬背了!用Python手把手拆解卡尔曼滤波的5个核心公式(附filterpy/OpenCV两种实现)卡尔曼滤波就像一位隐形的数据调酒师,它能将嘈杂的观测数据与不完美的预测模型混合,调制出一杯接近真实状态的"鸡尾酒&quo…...
和Windows上彻底卸载AWS CLI v2)
告别混乱:如何在不同Linux发行版(openEuler/Ubuntu)和Windows上彻底卸载AWS CLI v2
彻底卸载AWS CLI v2:跨平台深度清理指南当AWS CLI v2出现版本冲突、配置混乱或需要重新安装时,简单的删除操作往往无法彻底清除所有痕迹。本文将深入探讨如何在Windows、Ubuntu和openEuler系统上执行外科手术式卸载,确保不留任何残留文件。1.…...

基于Hugging Face与Gradio的智能问答系统构建实战
1. 项目概述:从零构建一个可交互的智能问答系统 如果你对自然语言处理(NLP)感兴趣,并且一直想亲手搭建一个能“读懂”文章并回答问题的智能系统,那么这篇文章就是为你准备的。过去几年,基于Transformer架构…...

物理信息机器学习在声场估计中的应用:原理、实践与前沿
1. 物理信息机器学习:当声学物理遇上数据智能 如果你在声学、音频信号处理或者空间音频领域工作,那么“声场估计”这个词对你来说一定不陌生。简单来说,它就像是用有限的几个“耳朵”(传声器)去“猜”出整个空间里每一…...

机器学习赋能非结构网格CFD:GNN、PINN与降阶建模实战
1. 项目概述:机器学习如何重塑非结构网格CFD 在计算流体力学(CFD)领域,非结构网格是处理复杂几何形状的“瑞士军刀”。与规则排列的结构化网格不同,非结构网格由不规则分布的节点和单元(如三角形、四面体&a…...

新手避坑指南:在Ubuntu 22.04上从零搭建Plexe-SUMO自动驾驶仿真环境
新手避坑指南:在Ubuntu 22.04上从零搭建Plexe-SUMO自动驾驶仿真环境自动驾驶仿真技术已成为学术界和工业界验证算法有效性的重要手段。对于刚接触该领域的研究者而言,环境搭建往往是第一个"拦路虎"。本文将手把手带你完成Plexe-SUMO环境的完整…...

C# AR应用性能优化三大硬核策略
1. 这不是“加个特效”就能解决的问题:AR应用卡顿背后的真实战场C# AR应用优化实战——这七个字,我盯着看了三分钟。不是因为难懂,而是因为太熟悉了。过去三年,我带过7个AR项目,从工业设备远程巡检到博物馆文物交互导览…...

别再只跑代码了!用泰坦尼克号数据集,手把手教你从EDA到模型调优的完整数据分析实战
从数据洞察到模型优化:泰坦尼克号生存预测的深度实践指南 如果你已经能够熟练运行数据分析代码,却依然对项目全流程缺乏系统性认知,这篇文章将带你超越基础操作,深入理解数据分析的完整闭环。我们将以经典的泰坦尼克号数据集为例&…...