ChatGPT 是如何工作的:从预训练到 RLHF
欢迎来到人工智能的未来:生成式人工智能!您是否想知道机器如何学习理解人类语言并做出相应的反应?让我们来看看ChatGPT ——OpenAI 开发的革命性语言模型。凭借其突破性的 GPT-3.5 架构,ChatGPT 席卷了世界,改变了我们与机器通信的方式,并为人机交互开辟了无限可能。随着 ChatGPT 的竞争对手 Google BARD 最近推出,由 PaLM 2 提供支持,这场竞赛已经正式开始。在本文中,我们将深入探讨 ChatGPT 的内部工作原理、它是如何工作的、涉及哪些不同步骤,例如预训练和 RLHF,以及探索它如何理解和生成类似人类的文本具有非凡的准确性。
探索 ChatGPT 的内部运作方式,并探索它如何以极高的准确性理解和生成类似人类的文本。准备好对 ChatGPT 背后的尖端技术感到惊讶,并发现这种强大的语言模型的无限潜力。
本文的主要目标是 -
- 讨论 ChatGPT 模型训练涉及的步骤。
- 了解使用人类反馈强化学习 (RLHF) 的优势。
- 了解人类如何参与改进 ChatGPT 等模型。
ChatGPT 训练概述
ChatGPT 是一种针对对话进行优化的大型语言模型(LLM)。它使用人类反馈强化学习 (RLHF) 构建在 GPT 3.5 之上。它接受了大量互联网数据的训练。
构建 ChatGPT 主要涉及 3 个步骤 -
- 预培训法学硕士
- LLM(SFT)的监督微调
- 根据人类反馈进行强化学习 (RLHF)
第一步是在无监督数据上预训练 LLM (GPT 3.5),以预测句子中的下一个单词。这使得法学硕士能够学习文本的表示和各种细微差别。
预培训法学硕士
语言模型是预测序列中下一个单词的统计模型。大型语言模型是经过数十亿单词训练的深度学习模型。训练数据来自多个网站,如 Reddit、StackOverflow、Wikipedia、Books、ArXiv、Github 等。


我们可以看到上图并了解数据集的侧面和参数的数量。LLM 的预训练计算成本很高,因为它需要大量的硬件和庞大的数据集。在预训练结束时,我们将获得一个 LLM,可以在提示时预测句子中的下一个单词。例如,如果我们提示一个句子“玫瑰是红色的并且”,它可能会回复“紫罗兰是蓝色的”。下图描述了 GPT-3 在预训练结束时可以做什么:


我们可以看到该模型正在尝试完成句子而不是回答它。但我们需要知道答案而不是下一句话。实现这一目标的下一步可能是什么?让我们在下一节中看到这一点。
LLM 的监督微调
那么,我们如何让LLM回答问题而不是预测下一个单词呢?模型的监督微调将帮助我们解决这个问题。我们可以告诉模型对给定提示的期望响应并对其进行微调。为此,我们可以创建一个包含多种类型问题的数据集来询问对话模型。人工贴标者可以提供适当的响应,使模型理解预期的输出。这个由成对的提示和响应组成的数据集称为演示数据。现在,让我们看看演示数据中的提示示例数据集及其响应。


根据人类反馈进行强化学习 (RLHF)
现在,我们将了解 RLHF。在了解RLHF之前,我们先来看看使用RLHF的好处。
为什么选择RLHF?
经过监督微调后,我们的模型应该针对给定的提示给出适当的响应,对吧?很不幸的是,不行!我们的模型可能仍然无法正确回答我们提出的每个问题。它可能仍然无法评估哪个响应是好的,哪个响应不是。它可能必须过度拟合演示数据。让我们看看如果它过度拟合数据会发生什么。


我没有给它任何链接、文章或句子来总结。但它只是总结了一些东西就给了我,这是我始料未及的。
可能出现的另一问题是其毒性。尽管答案可能是正确的,但在伦理和道德上可能并不正确。例如,请看下面的图片,您可能以前见过。当询问下载电影的网站时,它首先回答说这是不道德的,但在下一个提示中,我们可以轻松地操纵它,如图所示。


好的,现在转到 ChatGPT 并尝试相同的示例。它给了你同样的结果吗?
为什么我们没有得到相同的答案?他们重新训练了整个网络吗?可能不会!RLHF 可能有一个小的微调。您可以参考这个美丽的要点了解更多原因。
奖励模式
RLHF 的第一步是训练奖励模型。该模型应该能够将提示的响应作为输入,并输出一个标量值来描述响应的好坏。为了让机器了解什么是好的响应,我们可以要求注释者用奖励来注释响应吗?一旦我们这样做,奖励不同注释者的反应可能会存在偏差。因此,模型可能无法学习如何奖励响应。相反,注释者可以对模型的响应进行排名,这将在很大程度上减少注释中的偏差。下图显示了来自 Anthropic 的 hh-rlhf 数据集的给定提示的选定响应和拒绝响应。




该模型尝试根据这些数据区分好的响应和坏的响应。
使用 RL 的奖励模型微调 LLM
现在,我们用近端策略近似(PPO)对法学硕士进行微调。在这种方法中,我们获得初始语言模型和微调迭代的当前迭代生成的响应的奖励。我们将当前语言模型与初始语言模型进行比较,以便语言模型不会偏离正确答案太多,同时生成整洁、干净且可读的输出。KL 散度用于比较两个模型,然后微调 LLM。
模型评估
在每个步骤结束时都会使用不同数量的参数不断评估模型。您可以在下图中看到这些方法及其各自的分数:


我们可以在上图中比较不同阶段的法学硕士与不同模型大小的表现。正如您所看到的,每个训练阶段后结果都有显着增加。
我们可以用人工智能 RLAIF 来替代 RLHF 中的人类。这显着降低了标签成本,并且有可能比 RLHF 表现更好。让我们在下一篇文章中讨论这个问题。
结论
在本文中,我们了解了如何训练 ChatGPT 等会话式 LLM。我们看到了训练 ChatGPT 的三个阶段,以及基于人类反馈的强化学习如何帮助模型提高其性能。我们也了解每个步骤的重要性,没有这些步骤,法学硕士将是不准确的。
经常问的问题
答:ChatGPT 从 Reddit、StackOverflow、Wikipedia、Books、ArXiv、Github 等多个网站获取数据。它使用这些数据来学习模式、语法和事实。
A. ChatGPT本身并不提供直接的赚钱方式。然而,个人或组织可以利用 ChatGPT 的功能来开发可以产生收入的应用程序或服务,例如博客、虚拟助理、客户支持机器人或内容生成工具。
答:ChatGPT 是一种针对对话而优化的大型语言模型。它接受提示作为输入并返回响应/答案。它使用GPT 3.5和人类反馈强化学习(RLHF)作为核心工作原理。
答:ChatGPT 在幕后使用深度学习和强化学习。它分三个阶段开发:预训练大型语言模型(GPT 3.5)、监督微调、人类反馈强化学习(RLHF)。
相关文章:
ChatGPT 是如何工作的:从预训练到 RLHF
欢迎来到人工智能的未来:生成式人工智能!您是否想知道机器如何学习理解人类语言并做出相应的反应?让我们来看看ChatGPT ——OpenAI 开发的革命性语言模型。凭借其突破性的 GPT-3.5 架构,ChatGPT 席卷了世界,改变了我们…...

KafKa脚本操作
所有操作位于/usr/local/kafka_2.12-3.5.1/bin。 rootubuntu2203:/usr/local/kafka_2.12-3.5.1/bin# pwd /usr/local/kafka_2.12-3.5.1/bin rootubuntu2203:/usr/local/kafka_2.12-3.5.1/bin# ls connect-distributed.sh kafka-delegation-tokens.sh kafka-mirror-mak…...
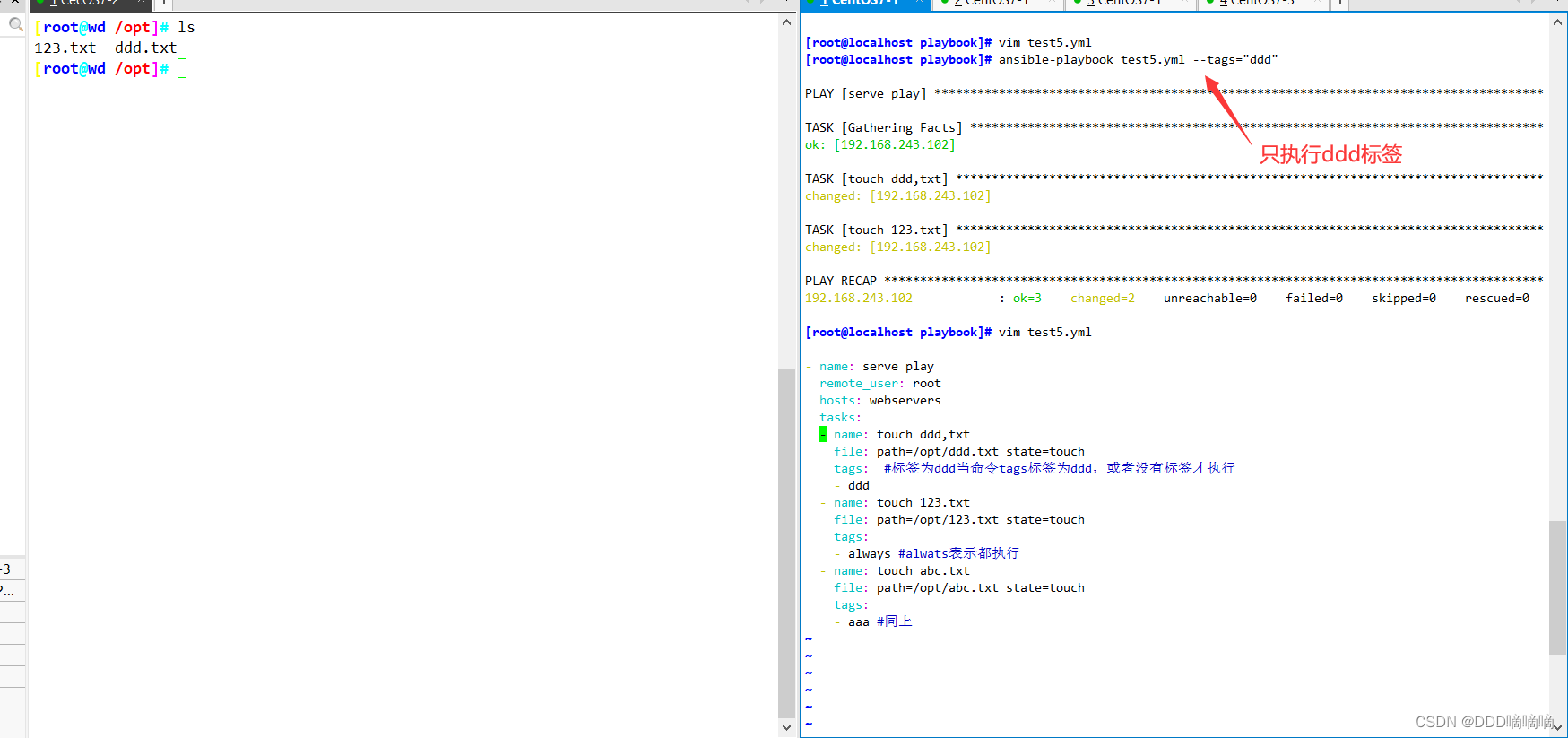
【自动化运维】playbook剧本
目录 一、Ansible 的脚本 playbook 剧本1.1playbooks的组成 二、剧本编写实验2.1定义、引用变量2.2使用远程主机sudo切换用户2.3whenn条件判断2.4迭代 三、Templates 模板四、Tags模板 一、Ansible 的脚本 playbook 剧本 1.1playbooks的组成 (1)Tasks&…...

java中双引号和单引号的区别
起因 刷题的时候,有判断是否相同的情况,然后我发现单引号和双引号在上的表现不一样,所以记录一下。 解释 在Java中,双引号(" ")和单引号(’ )在使用上有很重要的区别&a…...

jenkinsfile指定jenkins流水线的构建号
背景 升级Jenkins过程中不小心导致流水线配置文件job目录丢失, 重新配置流水线后所有流水线构建号码都从1开始构建了, 然而我们的产品关联了jenkins构建号,重新从1 构建会导致各种问题. 解决方案 在Jenkinsfile文件中指定流水线的构建号为一个不存在的数字, 这样就不会冲突了…...
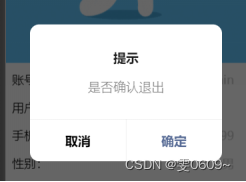
微信小程序:实现提示窗确定,取消执行不同操作(消息提示确认取消)showModal
效果 代码 wx.showModal({title: 提示,content: 是否确认退出,success: function (res) {if (res.confirm) {console.log(用户点击确定)} else if (res.cancel) {console.log(用户点击取消)}}})...
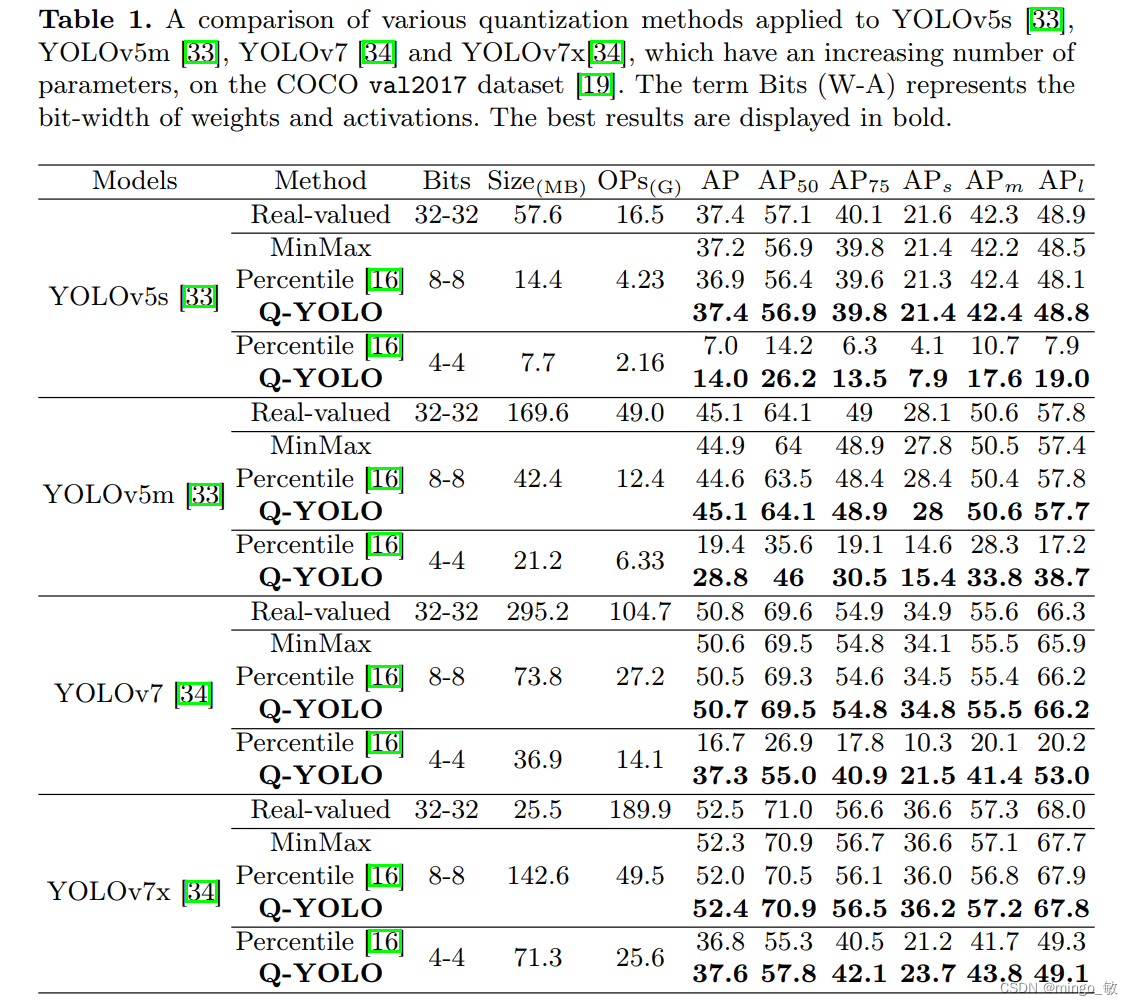
深度学习论文: Q-YOLO: Efficient Inference for Real-time Object Detection及其PyTorch实现
深度学习论文: Q-YOLO: Efficient Inference for Real-time Object Detection及其PyTorch实现 Q-YOLO: Efficient Inference for Real-time Object Detection PDF: https://arxiv.org/pdf/2307.04816.pdf PyTorch代码: https://github.com/shanglianlm0525/CvPytorch PyTorch代…...
解读随机森林的决策树:揭示模型背后的奥秘
一、引言 随机森林[1]是一种强大的机器学习算法,在许多领域都取得了显著的成功。它由多个决策树组成,而决策树则是构建随机森林的基本组件之一。通过深入解析决策树,我们可以更好地理解随机森林模型的工作原理和内在机制。 决策树是一种树状结…...

OceanMind海睿思获评中国信通院“内审数字化产品评测”卓越级(最高级)!
2023年7月27日,由中国内部审计协会、中国通信标准化协会指导,中国信息通信研究院主办的第二届数字化审计论坛在北京成功召开。 大会聚焦内部审计数字化领域先进实践、研究成果、行业发展举措,重磅发布了多项内部审计数字化领域的最新研究和实…...
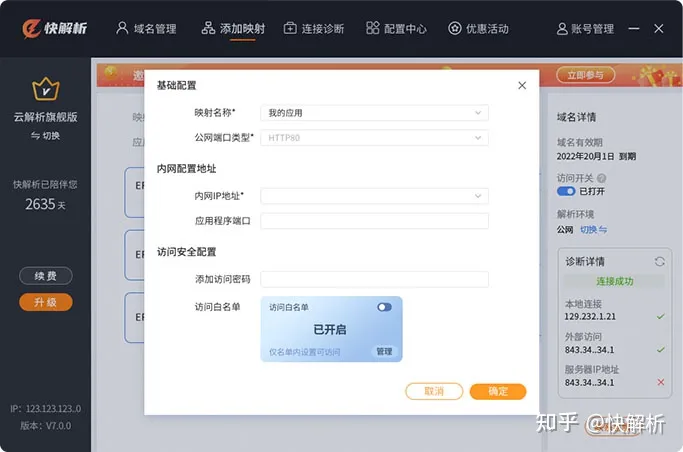
TPlink云路由器界面端口映射设置方法?快解析内网穿透能实现吗?
有很多网友在问:TPlink路由器端口映射怎么设置?因为不懂端口映射的原理,所以无从下手,下面小编就给大家分享TPlink云路由器界面端口映射设置方法,帮助大家快速入门TP路由器端口映射设置方法。 1.登录路由器管理界面&a…...

css3的filter图片滤镜使用
业务介绍 默认:第一个图标为选中状态,其他三个图标事未选中状态 样式:选中状态是深蓝,未选中状体是浅蓝 交互:鼠标放上去选中,其他未选中,鼠标离开时候保持当前选中状态 实现:目前…...

❤️创意网页:打造炫酷网页 - 旋转彩虹背景中的星星动画
✨博主:命运之光 🌸专栏:Python星辰秘典 🐳专栏:web开发(简单好用又好看) ❤️专栏:Java经典程序设计 ☀️博主的其他文章:点击进入博主的主页 前言:欢迎踏入…...

react常用知识点
React是一个用于构建用户界面的JavaScript库。以下是React常用的知识点: 组件:React将用户界面分解成小而独立的组件,每个组件都有自己的状态和属性,并且可以通过组合这些组件来构建复杂的用户界面。 // 函数组件示例 function We…...

iOS开发-QLPreviewController与UIDocumentInteractionController显示文档
iOS开发-QLPreviewController与UIDocumentInteractionController显示文档 在应用中,我们有时想预览文件, 可以使用QLPreviewController与UIDocumentInteractionController 一、QLPreviewController与UIDocumentInteractionController QLPreviewController是一个 UIViewContr…...

八、用 ChatGPT 帮助排查生产事故
目录 一、实验介绍 二、背景 三、故障排查概述 3.1 生产环境故障排查涉及的角色...

WPF实战学习笔记25-首页汇总
注意:本实现与视频不一致。本实现中单独做了汇总接口,而视频中则合并到国todo接口当中了。 添加汇总webapi接口添加汇总数据客户端接口总数据客户端接口对接3首页数据模型 添加数据汇总字段类 新建文件MyToDo.Share.Models.SummaryDto using System;…...
FreeRTOS源码分析-7 消息队列
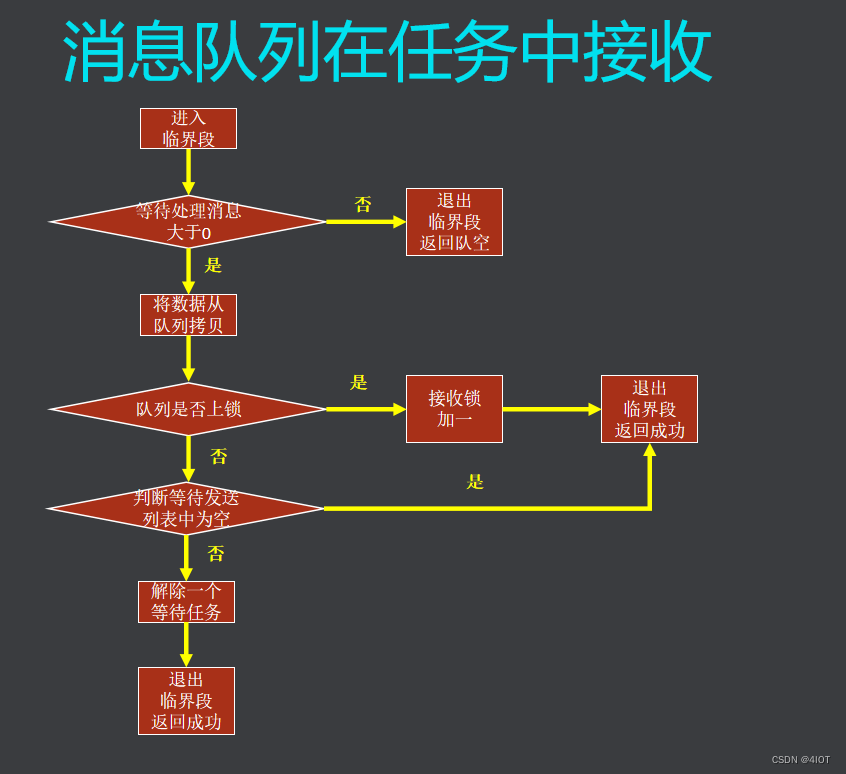
目录 1 消息队列的概念和作用 2 应用 2.1功能需求 2.2接口函数API 2.3 功能实现 3 消息队列源码分析 3.1消息队列控制块 3.2消息队列创建 3.3消息队列删除 3.4消息队列在任务中发送 3.5消息队列在中断中发送 3.6消息队列在任务中接收 3.7消息队列在中断中接收 1 消…...

机器学习深度学习——权重衰减
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——模型选择、欠拟合和过拟合 📚订阅专栏:机器学习&&深度学习 希望文章对你…...
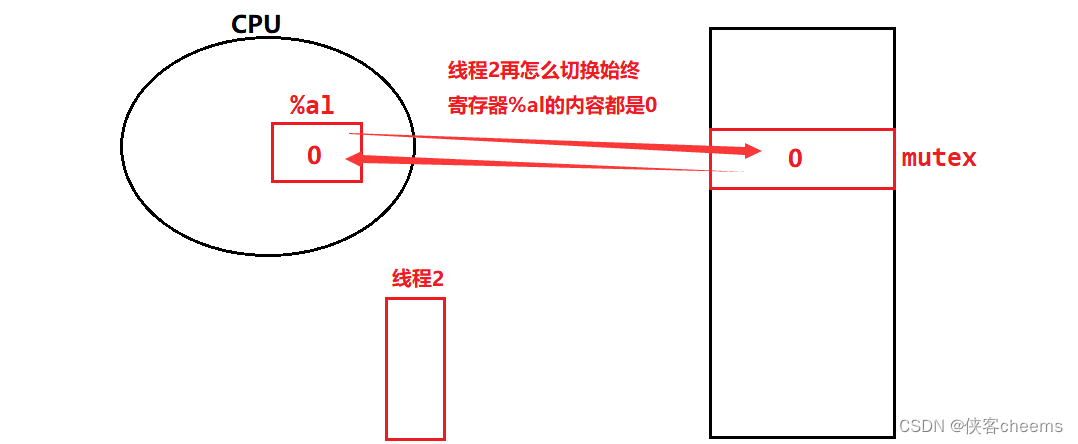
【Linux】线程互斥 -- 互斥锁 | 死锁 | 线程安全
引入互斥初识锁互斥量mutex锁原理解析 可重入VS线程安全STL中的容器是否是线程安全的? 死锁 引入 我们写一个多线程同时访问一个全局变量的情况(抢票系统),看看会出什么bug: // 共享资源, 火车票 int tickets 10000; //新线程执行方法 vo…...

【vue-pdf】PDF文件预览插件
1 插件安装 npm install vue-pdf vue-pdf GitHub:https://github.com/FranckFreiburger/vue-pdf#readme 参考文档:https://www.cnblogs.com/steamed-twisted-roll/p/9648255.html catch报错:vue-pdf组件报错vue-pdf Cannot read properti…...

【RT-DETR实战】064、NMS后处理优化与替代方案:我在RT-DETR里踩过的那些坑
今天调一个RT-DETR的部署问题,模型推理速度明明达标了,但在实际视频流里跟踪目标时总出现“闪跳”——同一个目标在相邻帧里忽左忽右。 盯着输出看了半天,发现是相邻帧的检测框置信度相差0.01,NMS直接就把低分框干掉了,导致目标位置在帧间不连续。这个经典问题让我决定好…...

入门吉他弹唱怎么选?面单琴技术对比:繁星AC-10 vs 雅马哈FG800
一、测评背景与技术参数1.1 测评样品信息桶型:GA桶 vs D桶面板:西提卡云杉纯单板 vs 西提卡云杉背侧板:桃花芯木纯单板 vs 那都木/奥古曼合板琴颈:奥古曼 vs 那都木指板:玫瑰木 vs 玫瑰木有效弦长:650mm vs…...

harmonyos-ai-skill:让 Cursor 按 ArkTS 规范写鸿蒙,不再瞎编 API
端侧 Kit、MCP 接线都写过之后,写代码的人仍会遇到:Cursor 生成「像 React 的 ArkTS」、编造不存在的 Kit 名。社区项目 harmonyos-ai-skill 用可安装知识包,把 API 11 / DevEco 6 约束塞进 AI 工具链。 1. 问题:通用大模型不懂你…...

电子书转有声书完整指南:一键实现1158种语言的AI语音合成
电子书转有声书完整指南:一键实现1158种语言的AI语音合成 【免费下载链接】ebook2audiobook Generate audiobooks from e-books, voice cloning & 1158 languages! 项目地址: https://gitcode.com/GitHub_Trending/eb/ebook2audiobook 你是否曾希望将心爱…...

SAP ABAP SOAUTH2 配置原理与 OAuth2 四要素落地解析
1. 为什么 SAP ABAP 系统里填个 OAuth2 参数总像在解谜题? 刚接手一个对接钉钉开放平台的 ABAP 项目时,我盯着事务码 SOAUTH2 的配置界面足足看了二十分钟——Client ID、Client Secret、Authorization Endpoint、Token Endpoint、Redirect URI……每个…...

Unity拼图游戏商业级架构:零代码关卡+丝滑拖拽+真机性能优化
1. 这不是“拼图小游戏”,而是一套可量产的商业级益智游戏骨架你肯定见过那种上线三天就冲进App Store益智类前20的拼图游戏:首页是高清风景图轮播,点进去自动切分成16块带微动效的碎片,拖拽顺滑、吸附精准、完成时有粒子音效成就…...

Java学习笔记——DAY3
目录 1、Java方法 2、方法的定义 3、方法调用 4、方法的重载 5、命令行传参 6、可变参数 7、递归 1、Java方法 Java方法是语句的集合,它们在一块执行一个功能。 方法是解决一类问题的步骤的有序集合方法包含与类或对象中方法在程序中被创建,在其…...

超厉害!AI写教材,低查重且内容连贯,快速产出专业教材!
整理教材知识点实在是一项“精细工作”,最大的挑战在于如何保持平衡与衔接!我们常常担忧会遗漏核心概念,或是难以掌握合适的难度梯度——小学教材常常写得过于复杂,导致学生难以理解;而高中教材则可能显得过于简单&…...

Claude CLI 缓存陷阱:为什么用第三方模型时 token 会暴涨 10 倍?
一个开发者的真实经历 上周,我收到一位朋友的微信: “我用 Claude Code 接 DeepSeek API,明明代码没怎么变,token 消耗却突然涨了好几倍,一天就把额度用完了。” 这个情况不是个例。在 GitHub 上,至少有 80 多个相关 issue,核心问题都指向同一个点——Claude CLI 默认…...

Mac Mouse Fix:3步让你的普通鼠标超越苹果触控板体验
Mac Mouse Fix:3步让你的普通鼠标超越苹果触控板体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾为macOS上鼠标功能受限…...