【Python】数据分析+数据挖掘——探索Pandas中的索引与数据组织
前言
在数据科学和数据分析领域,Pandas是一个备受喜爱的Python库。它提供了丰富的数据结构和灵活的工具,帮助我们高效地处理和分析数据。其中,索引在Pandas中扮演着关键角色,它是一种强大的数据组织和访问机制,使我们能够更好地理解和操作数据。
本博客将探讨Pandas中与索引相关的核心知识点和常用操作。我们将了解如何设置和重置索引,通过索引来选择和过滤数据,以及如何利用多级索引来处理复杂的层次结构数据。
索引
当涉及Python或Pandas库中的索引时,通常指的是Pandas库中的DataFrame和Series对象的索引。这里只简单介绍一下索引,索引的具体用法均在其他操作中
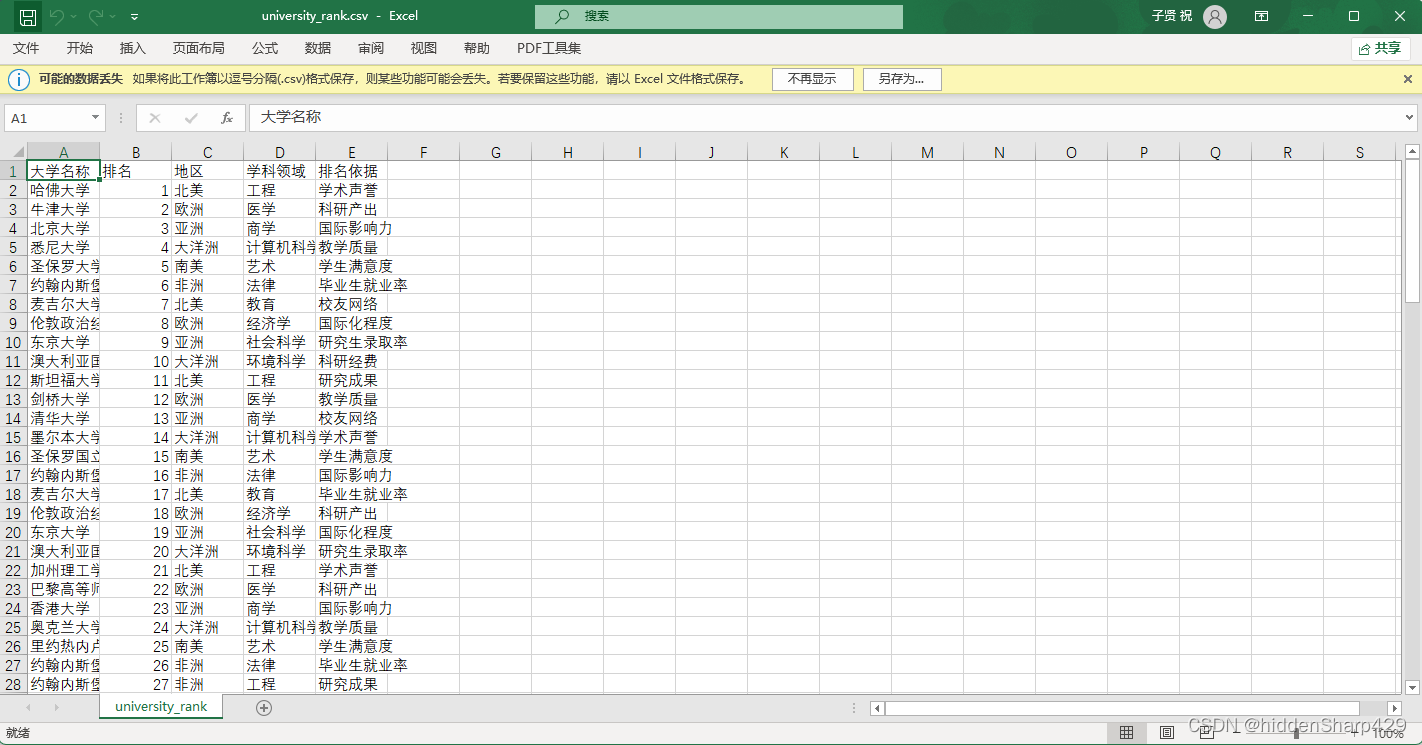
案例数据表university_rank.csv
索引的设置
我们可以在读入数据的时候就通过pd.read_csv相关属性来设置索引列,可以是单列也可以是多列,需要用列表来表达
读取时设置索引
pd.read_csv(# 设置索引列index_col = [].........
)
In[0]:
df = pd.read_csv("university_rank.csv", index_col=["大学名称"])
df
out[0]:
| 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|
| 大学名称 | ||||
| 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... |
| 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 4 columns
如果我想要设置多个变量列作为索引呢?
In[1]:
df = pd.read_csv("university_rank.csv", index_col=["地区", "学科领域"]) # 设置多个变量列作为索引
df
out[1]:
| 大学名称 | 排名 | 排名依据 | ||
|---|---|---|---|---|
| 地区 | 学科领域 | |||
| 北美 | 工程 | 哈佛大学 | 1 | 学术声誉 |
| 欧洲 | 医学 | 牛津大学 | 2 | 科研产出 |
| 亚洲 | 商学 | 北京大学 | 3 | 国际影响力 |
| 大洋洲 | 计算机科学 | 悉尼大学 | 4 | 教学质量 |
| 南美 | 艺术 | 圣保罗大学 | 5 | 学生满意度 |
| ... | ... | ... | ... | |
| 计算机科学 | 圣保罗国立大学 | 96 | 研究生录取率 | |
| 非洲 | 环境科学 | 约翰内斯堡大学 | 97 | 学术声誉 |
| 北美 | 艺术 | 麦吉尔大学 | 98 | 学生满意度 |
| 欧洲 | 法律 | 伦敦政治经济学院 | 99 | 国际影响力 |
| 亚洲 | 教育 | 东京大学 | 100 | 毕业生就业率 |
100 rows × 3 columns
DataFrame.set_index方法设置索引
除此之外也可以使用DataFrame类型数据自带的df.set_index方法
df.set_index(# 索引列名,需要使用list类型key# 建立索引后是否删除该列drop = True# 是否在原索引上添加索引append = False# 是否直接修改原dfinplace = False# 默认为False,如果为True,则检查新的索引是否唯一,如果有重复则会抛出ValueErrorverify_integrity = False
)
In[2]:
df = pd.read_csv("university_rank.csv")
df.set_index(keys=["排名"], append=True, inplace=True)
print(type(df)) # 查看df类型
df
out[2]:
<class 'pandas.core.frame.DataFrame'>
| 大学名称 | 地区 | 学科领域 | 排名依据 | ||
|---|---|---|---|---|---|
| 排名 | |||||
| 0 | 1 | 哈佛大学 | 北美 | 工程 | 学术声誉 |
| 1 | 2 | 牛津大学 | 欧洲 | 医学 | 科研产出 |
| 2 | 3 | 北京大学 | 亚洲 | 商学 | 国际影响力 |
| 3 | 4 | 悉尼大学 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 5 | 圣保罗大学 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 96 | 圣保罗国立大学 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 97 | 约翰内斯堡大学 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 98 | 麦吉尔大学 | 北美 | 艺术 | 学生满意度 |
| 98 | 99 | 伦敦政治经济学院 | 欧洲 | 法律 | 国际影响力 |
| 99 | 100 | 东京大学 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 4 columns
上面这个例子就很明显的看出来append参数的作用,本来该DataFrame就有一个流水索引,后面又添加了一个排名索引并且append参数为True
但是我们发现打印出来是100 row * 4 columns,所以排名变成索引后就不在作为一个列来存在了,我们可以使用drop参数来改变它
In[3]:
df = pd.read_csv("university_rank.csv")
df.set_index(keys=["排名"], append=True, inplace=True, drop=False) # 调整drop参数
df
out[3]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | ||
|---|---|---|---|---|---|---|
| 排名 | ||||||
| 0 | 1 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 1 | 2 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 2 | 3 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 3 | 4 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 5 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... | ... |
| 95 | 96 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 97 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 98 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 98 | 99 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 99 | 100 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 5 columns
取消set_index索引设置
那么我们该如何还原呢,答案就是使用df.reset_index
df.reset_index()是Pandas DataFrame对象的一个方法,它用于重置(恢复)DataFrame的索引,将整数序列作为新的行索引,并将原来的行索引(可能是整数、字符串或其他类型)转换为DataFrame的列。
df.reset_index(# 是否将索引列删除,而不还原drop = Flase# 是否修改原dfinplace = False# 可选参数,用于指定要重置的索引级别。如果不指定,则会重置所有的索引级别level# 如果DataFrame具有多级列索引,该参数用于指定要重置的列级别。默认为0,即第一级col_level# 如果指定了col_level,则可以使用该参数为重置的列索引命名col_fill
)
In[4]:
df.reset_index(drop=True, inplace=True)
df
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 5 columns
DataFrame.index.name修改索引名称
此外我们也可以使用df.index.names来修改索引的名称
In[5]:
df.index.names = ["ID"] # df是案例数据表,设置索引名称为ID
df
out[5]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| ID | |||||
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 5 columns
索引的排序
建立完索引后我们可以根据索引来进行排序,具体使用的方法是df.sort_index()
DataFrame.sort_index索引排序
df.sort_index()是Pandas DataFrame对象的一个方法,用于按照索引(行标签)对DataFrame进行排序。它可以根据行索引的标签值进行升序或降序排序。
df.sort_index(# 多重索引时的优先级level# 是否为升序ascending = True# 是否在原df修改inplace = False# 缺失值的排列顺序,可选值有 'first' 和 'last',默认为 'last',表示NaN在排序后放在最后。na_position = 'last'# 是否按索引排序后丢弃索引,默认为False,如果为True,则在排序后重置行索引为从0开始的连续整数索引ignore_index = False# 默认为0,表示按照行索引排序。如果设置为1,则按列索引排序(对于多级索引的DataFrame)axis = 0# 排序算法的种类。可选值有 'quicksort'、'mergesort'、'heapsort',默认为 'quicksort'kind = 'quicksort'# 默认为True,如果在排序时有未指定的级别或索引,则对其进行排序。如果设置为False,则保持原样sort_remaining = True# 1.1.0新增属性,可以对索引值进行函数修改key
)
In[6]:
df = pd.read_csv("university_rank.csv", index_col=["学科领域", "地区"])
df
out[6]:
| 大学名称 | 排名 | 排名依据 | ||
|---|---|---|---|---|
| 学科领域 | 地区 | |||
| 工程 | 北美 | 哈佛大学 | 1 | 学术声誉 |
| 医学 | 欧洲 | 牛津大学 | 2 | 科研产出 |
| 商学 | 亚洲 | 北京大学 | 3 | 国际影响力 |
| 计算机科学 | 大洋洲 | 悉尼大学 | 4 | 教学质量 |
| 艺术 | 南美 | 圣保罗大学 | 5 | 学生满意度 |
| ... | ... | ... | ... | ... |
| 计算机科学 | 南美 | 圣保罗国立大学 | 96 | 研究生录取率 |
| 环境科学 | 非洲 | 约翰内斯堡大学 | 97 | 学术声誉 |
| 艺术 | 北美 | 麦吉尔大学 | 98 | 学生满意度 |
| 法律 | 欧洲 | 伦敦政治经济学院 | 99 | 国际影响力 |
| 教育 | 亚洲 | 东京大学 | 100 | 毕业生就业率 |
100 rows × 3 columns
In[7]:
df.sort_index()
out[7]:
| 大学名称 | 排名 | 排名依据 | ||
|---|---|---|---|---|
| 学科领域 | 地区 | |||
| 医学 | 亚洲 | 清华大学 | 34 | 学术声誉 |
| 亚洲 | 清华大学 | 54 | 教学质量 | |
| 亚洲 | 清华大学 | 74 | 教学质量 | |
| 亚洲 | 清华大学 | 94 | 教学质量 | |
| 北美 | 麦吉尔大学 | 28 | 教学质量 | |
| ... | ... | ... | ... | ... |
| 计算机科学 | 南美 | 里约热内卢大学 | 86 | 研究生录取率 |
| 南美 | 圣保罗国立大学 | 96 | 研究生录取率 | |
| 大洋洲 | 悉尼大学 | 4 | 教学质量 | |
| 大洋洲 | 墨尔本大学 | 14 | 学术声誉 | |
| 大洋洲 | 奥克兰大学 | 24 | 教学质量 |
100 rows × 3 columns
In[8]:
df.sort_index(level="地区")
out[8]:
| 大学名称 | 排名 | 排名依据 | ||
|---|---|---|---|---|
| 学科领域 | 地区 | |||
| 医学 | 亚洲 | 清华大学 | 34 | 学术声誉 |
| 亚洲 | 清华大学 | 54 | 教学质量 | |
| 亚洲 | 清华大学 | 74 | 教学质量 | |
| 亚洲 | 清华大学 | 94 | 教学质量 | |
| 商学 | 亚洲 | 北京大学 | 3 | 国际影响力 |
| ... | ... | ... | ... | ... |
| 环境科学 | 非洲 | 约翰内斯堡大学 | 57 | 学术声誉 |
| 非洲 | 约翰内斯堡大学 | 67 | 学术声誉 | |
| 非洲 | 约翰内斯堡大学 | 77 | 学术声誉 | |
| 非洲 | 约翰内斯堡大学 | 87 | 学术声誉 | |
| 非洲 | 约翰内斯堡大学 | 97 | 学术声誉 |
100 rows × 3 columns
In[9]:
df.sort_index(level="地区", ignore_index=True)
out[9]:
| 大学名称 | 排名 | 排名依据 | |
|---|---|---|---|
| 0 | 清华大学 | 34 | 学术声誉 |
| 1 | 清华大学 | 54 | 教学质量 |
| 2 | 清华大学 | 74 | 教学质量 |
| 3 | 清华大学 | 94 | 教学质量 |
| 4 | 北京大学 | 3 | 国际影响力 |
| ... | ... | ... | ... |
| 95 | 约翰内斯堡大学 | 57 | 学术声誉 |
| 96 | 约翰内斯堡大学 | 67 | 学术声誉 |
| 97 | 约翰内斯堡大学 | 77 | 学术声誉 |
| 98 | 约翰内斯堡大学 | 87 | 学术声誉 |
| 99 | 约翰内斯堡大学 | 97 | 学术声誉 |
100 rows × 3 columns
DataFrame.sort_values变量列排序
如果我想要按照变量来排序呢,而不是索引?df.sort_values可以帮到你
df.sort_values(# 用于指定排序的列名或列名列表。可以传入单个列名的字符串,也可以传入一个包含多个列名的列表,表示按照这些列的值进行排序by# 默认为0,表示按照行进行排序。如果设置为1,则按列进行排序axis = 0# 默认为True,表示升序排序。如果设置为False,表示降序排序ascending = True# 默认为False,是否在原df上修改inplace = False# 指定缺失值(NaN)在排序后的位置。可选值有 'first' 和 'last',默认为 'last',表示NaN在排序后放在最后na_position = 'last'# 默认为False,如果为True,则在排序后重置行索引为从0开始的连续整数索引ignore_index = False
)
In[10]:
data = {'ID': [4, 2, 1, 3],'Name': ['David', 'Bob', 'Alice', 'Charlie'],'Age': [40, 30, 25, 35]
}df = pd.DataFrame(data)
print(df)
out[10]:
ID Name Age
2 1 Alice 25
1 2 Bob 30
3 3 Charlie 35
0 4 David 40现在,我们按照’Age’列进行升序排序
In[11]:
df_sorted = df.sort_values(by='Age')
print(df_sorted)
out[11]:
ID Name Age
2 1 Alice 25
1 2 Bob 30
3 3 Charlie 35
0 4 David 40
结束语
如果有疑问欢迎大家留言讨论,你如果觉得这篇文章对你有帮助可以给我一个免费的赞吗?我们之间的交流是我最大的动力!
相关文章:
【Python】数据分析+数据挖掘——探索Pandas中的索引与数据组织
前言 在数据科学和数据分析领域,Pandas是一个备受喜爱的Python库。它提供了丰富的数据结构和灵活的工具,帮助我们高效地处理和分析数据。其中,索引在Pandas中扮演着关键角色,它是一种强大的数据组织和访问机制,使我们…...

matlab进阶:求解在约束条件下的多元目标函数最值(fmincon函数详解)
🌅*🔹** φ(゜▽゜*)♪ **🔹*🌅 欢迎来到馒头侠的博客,该类目主要讲数学建模的知识,大家一起学习,联系最后的横幅! 喜欢的朋友可以关注下,私信下次更新不迷路࿰…...
Kotlin知识点
Kotlin 是 Google 推荐的用于创建新 Android 应用的语言。使用 Kotlin,可以花更短的时间编写出更好的 Android 应用。 基础 Kotlin 程序必须具有主函数,这是 Kotlin 编译器在代码中开始编译的特定位置。主函数是程序的入口点,或者说是起点。…...
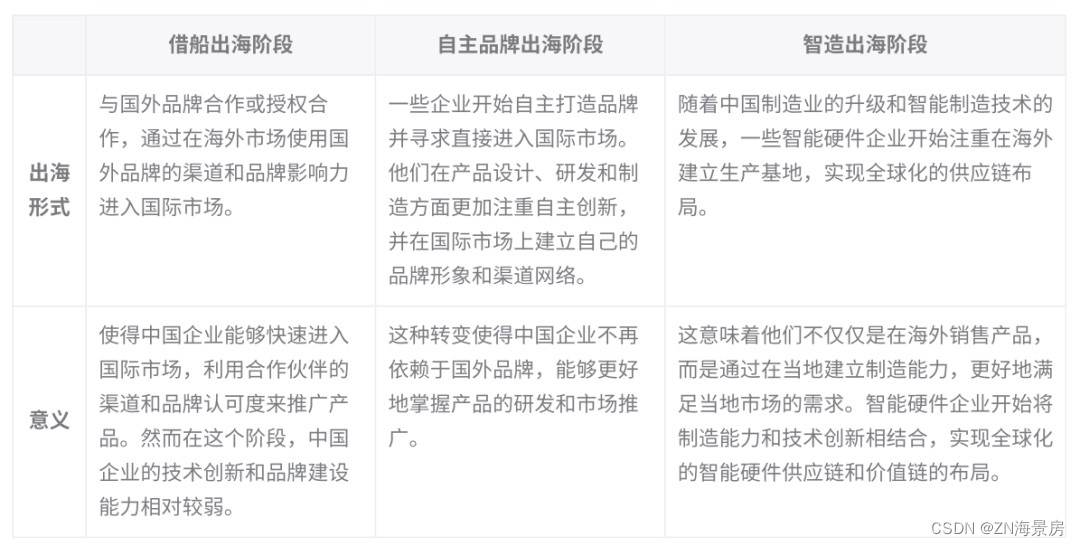
亚马逊云科技联合霞光社发布《2013~2023中国企业全球化发展报告》
中国企业正处于全球聚光灯下。当企业全球化成为时代发展下的必然趋势,出海也从“可选项”变为“必选项”。中国急速扩大的经济规模,不断升级的研发和制造能力,都在推动中国企业不断拓宽在全球各行业的疆域。 过去十年,是中国企业…...
【解析excel】利用easyexcel解析excel
【解析excel】利用easyexcel解析excel POM监听类工具类测试类部分测试结果备注其他 EasyExcel Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题&…...

JQuery操作单选按钮Radio和复选框checkbox
获取选中值: $(input:radio:checked).val();$("input[typeradio]:checked").val();$("input[namerd]:checked").val();$("input[idrand_question]:checked").val();设置第一个Radio为选中值: $(input:radio:…...
7.28 作业 QT
手动完成服务器的实现,并具体程序要注释清楚: widget.h: #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTcpServer> //服务器类 #include <QTcpSocket> //客户端类 #include <QMessageBox> //对话框类 #include …...

HTML <pre> 标签
定义和用法 pre 元素可定义预格式化的文本。被包围在 pre 元素中的文本通常会保留空格和换行符。而文本也会呈现为等宽字体。 <pre> 标签的一个常见应用就是用来表示计算机的源代码。 可以导致段落断开的标签(例如标题、"><p> 和 标签"><a…...

查询结果元数据-MetaData对象、数据库工具类的封装、通过反射实现数据查询的封装
六、查询结果元数据-MetaData对象 七、数据库工具类的封装 1、PropertieUtil类 2、DbUtil类 3、DBHepler类 查询: 4、TestDb测试类: 更新: 1)插入: 2)修改: 3)删除: 查…...
【Minio中间件】上传图片并Vue回显
流程: 目录 1.文件服务器Minio的安装 1.1 下载Minio安装后,新建1个data文件夹。并在该安装目录cmd 敲命令。注意不要进错目录。依次输入 1.2 登录Minio网页端 1.3 先建1个桶(buckets),点击create a bucket 2. Spr…...
Jmeter配置不同业务请求比例,应对综合场景压测
需求: 每次向服务器发出请求时,先生成一个随机数,我们对随机数的取值划分若干个范围(对应若干个业务请求),然后对随机数进行判断,当随机数落在某个范围内,就可以执行对应的请求。比…...

数学分析:流形的线性代数回顾
因为是线性的,所以可以把所有的系数都提取出去。这也是多重线性代数的性质。可以看成基本的各项自变量的乘法。 这里可以看到两个不同基向量下,他们的坐标转化关系。 引出了张量积,也就是前面提到的内容。 对偶空间的例子总是比较美好。 因为…...

前端请求后端接口返回错误码
1、如果 HTTP Code 是 2xx 范围内的,那通常表明请求已经成功处理,并且可以根据具体的 HTTP Code 进一步判断请求的处理结果。比如: HTTP Code 200 表明请求成功,并返回了请求资源;HTTP Code 204 表明请求成功…...

【Java Web】Nacos 介绍和安装教程
文章目录 1. Nacos 介绍1.1 Nacos 的定义1.2 Nacos 的主要功能1.2.1 服务注册与发现1.2.2 配置管理1.2.3 动态 DNS 服务1.2.4 服务和元数据管理 1.3 Nacos 的适用场景1.3.1 微服务架构1.3.2 动态配置管理1.3.3 多环境部署1.3.4 云原生应用 2. Nacos 的核心组件2.1 服务注册与发…...

web漏洞-java安全(41)
这个重点是讲关于java的代码审计,看这些漏洞是怎么在java代码里面产生的。 #Javaweb 代码分析-目录遍历安全问题 这个漏洞原因前面文章有,这次我们看看这个漏洞如何在代码中产生的,打开靶场 解题思路就是通过文件上传,上传文件…...
用CSS和HTML写一个水果库存静态页面
HTML代码: <!DOCTYPE html> <html> <head><link rel"stylesheet" type"text/css" href"styles.css"> </head> <body><header><h1>水果库存</h1></header><table>…...

【回眸】备考PMP考点汇总 三(距离考试还有20天)
目录 前言 【回眸】备考PMP考点汇总 三(距离考试还有20天) 29、管理质量 30、获取资源 31、建设团队 32、管理团队 33、管理沟通 34、实施风险应对 35、实施采购 36、管理相关方参与 37、监控项目工作(10%) 38、实施整…...

新房的收房验房注意事项
文章目录 流程注意事项准备检查材料手续整体结构验收水电检测门窗结构地面工程墙面工程顶面工程阳台厨房卫生间户外设施 流程注意事项 只要发现问题,不管大小,都要在相关文件或表格中记录下来,而不管开发商以及陪同的收房人员如何花言巧语。…...
ARM裸机-5
1、可编程器件的编程原理 1.1、电子器件的发展方向 模拟器件-->数字器件 ASIC-->可编程器件 1.2、可编程器件的特点 CPU在固定频率的时钟控制下节奏运行。 CPU可以通过总线读取外部存储设备中的二进制指令集,然后解码执行。 这些可以被CPU解码执行的二进制指…...
——分布式搜索ElasticSeach场景使用)
SpringCloud学习路线(11)——分布式搜索ElasticSeach场景使用
一、DSL查询文档 (一)DSL查询分类 ES提供了基于JSON的DSL来定义查询。 1、常见查询类型: 查询所有: 查询出所有的数据,例如,match_all全文检索(full text)查询: 利用…...

鸿蒙同城兴趣圈页面构建:附近社群与兴趣标签模块详解
鸿蒙同城兴趣圈页面构建:附近社群与兴趣标签模块详解 前言 在 HarmonyOS 6.0 应用开发中,社交类页面的核心挑战在于如何高效展示附近社群、兴趣标签和活动信息。本文将以“同城兴趣圈”应用的主页面为例,深入解析如何在鸿蒙平台上构建社交发现…...

别再走弯路!2026亲测靠谱的AI论文写作工具|安心版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

【ChatGPT】锂电卷绕机深度拆解、信息图、爆炸图、C++代码框架
深度拆解信息图...

7 年评测经验博主发布扫地机器人挑选指南,邀你探讨机器人革命!
评测多款扫地机器人,Matic 脱颖而出博主发布了关于挑选最佳扫地机器人的指南,近期评测了戴森的 Spot & Scrub、鲨客的 Power Detect 以及 Matic。在其 7 年的扫地机器人评测生涯中,Matic 是最有意思的新型扫地机器人。拨开营销迷雾&#…...
)
摆脱论文困扰!高效论文写作全流程AI论文工具推荐(2026 最新)
论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,2026年AI论文工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖免费/付费、通用/垂直场景。一…...
)
良心盘点!2026AI写作辅助软件榜单(覆盖 99% 毕业论文需求)
本文精选13 款2026 年实测 AI 论文工具,按全流程全能型、垂直领域专精型、润色降重专家、文献管理助手四大类别排序,覆盖从选题到定稿全链路,适配本科 / 硕博 / 期刊全场景,附选型速查表与避坑指南,帮你快速找到最佳拍…...

平均 CPU 利用率指标为何该摒弃?多个案例揭示真相!
1. 作者信息与文章背景Jeremy Theocharis 是《平凡即卓越》作者、UMH 联合创始人兼首席技术官。文章基于其在 2026 年 4 月云原生亚琛聚会上的演讲,探讨为何应摒弃平均 CPU 利用率指标。2. 应用程序问题引出我们应用程序中的一个 Go 函数在生产环境总是被取消执行。…...
)
DeepSeek服务网格选型决策树(Istio vs. eBPF轻量方案深度对比:延迟压降42%、资源开销降低68%实测数据)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek微服务架构建议 在构建面向大语言模型推理与训练任务的微服务系统时,DeepSeek系列模型对计算密集型服务、高吞吐API网关及弹性资源编排提出了明确要求。推荐采用分层解耦、异步协同…...
)
NotebookLM效应量计算合规性危机:FDA/EMA/NMPA最新AI辅助研究指南对效应量报告的强制性要求(附自查清单V2.3)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM效应量计算合规性危机的定义与背景 NotebookLM 效应量计算合规性危机,是指当研究者在使用 Google NotebookLM(一款基于 LLM 的文档理解与推理工具)辅助开展…...

asnumpy - 让昇腾NPU和NumPy无缝对接
刚学深度学习那会,最顺手的是 NumPy。各种矩阵运算、广播机制、索引操作,闭着眼睛都能写。 后来跑昇腾NPU,发现 NumPy 代码没法直接跑——torch.tensor 和 np.ndarray 不能混用,数据要手动转来转去,烦死了。 直到我发…...