如何保证集合是线程安全的 ConcurrentHashMap如何实现高效地线程安全?
第10讲 | 如何保证集合是线程安全的? ConcurrentHashMap如何实现高效地线程安全?

我在之前两讲介绍了 Java 集合框架的典型容器类,它们绝大部分都不是线程安全的,仅有的线程安全实现,比如 Vector、Stack,在性能方面也远不尽如人意。幸好 Java 语言提供了并发包(java.util.concurrent),为高度并发需求提供了更加全面的工具支持。
今天我要问你的问题是,如何保证容器是线程安全的?ConcurrentHashMap 如何实现高效地线程安全?
典型回答
Java 提供了不同层面的线程安全支持。在传统集合框架内部,除了 Hashtable 等同步容器,还提供了所谓的同步包装器(Synchronized Wrapper),我们可以调用 Collections 工具类提供的包装方法,来获取一个同步的包装容器(如 Collections.synchronizedMap),但是它们都是利用非常粗粒度的同步方式,在高并发情况下,性能比较低下。
另外,更加普遍的选择是利用并发包提供的线程安全容器类,它提供了:
各种并发容器,比如 ConcurrentHashMap、CopyOnWriteArrayList。
各种线程安全队列(Queue/Deque),如 ArrayBlockingQueue、SynchronousQueue。
各种有序容器的线程安全版本等。
具体保证线程安全的方式,包括有从简单的 synchronize 方式,到基于更加精细化的,比如基于分离锁实现的 ConcurrentHashMap 等并发实现等。具体选择要看开发的场景需求,总体来说,并发包内提供的容器通用场景,远优于早期的简单同步实现。
考点分析
谈到线程安全和并发,可以说是 Java 面试中必考的考点,我上面给出的回答是一个相对宽泛的总结,而且 ConcurrentHashMap 等并发容器实现也在不断演进,不能一概而论。
如果要深入思考并回答这个问题及其扩展方面,至少需要:
理解基本的线程安全工具。
理解传统集合框架并发编程中 Map 存在的问题,清楚简单同步方式的不足。
梳理并发包内,尤其是 ConcurrentHashMap 采取了哪些方法来提高并发表现。
最好能够掌握 ConcurrentHashMap 自身的演进,目前的很多分析资料还是基于其早期版本。
今天我主要是延续专栏之前两讲的内容,重点解读经常被同时考察的 HashMap 和 ConcurrentHashMap。今天这一讲并不是对并发方面的全面梳理,毕竟这也不是专栏一讲可以介绍完整的,算是个开胃菜吧,类似 CAS 等更加底层的机制,后面会在 Java 进阶模块中的并发主题有更加系统的介绍。
知识扩展
- 为什么需要 ConcurrentHashMap?
Hashtable 本身比较低效,因为它的实现基本就是将 put、get、size 等各种方法加上“synchronized”。简单来说,这就导致了所有并发操作都要竞争同一把锁,一个线程在进行同步操作时,其他线程只能等待,大大降低了并发操作的效率。
前面已经提过 HashMap 不是线程安全的,并发情况会导致类似 CPU 占用 100% 等一些问题,那么能不能利用 Collections 提供的同步包装器来解决问题呢?
看看下面的代码片段,我们发现同步包装器只是利用输入 Map 构造了另一个同步版本,所有操作虽然不再声明成为 synchronized 方法,但是还是利用了“this”作为互斥的 mutex,没有真正意义上的改进!
private static class SynchronizedMap<K,V>implements Map<K,V>, Serializable {private final Map<K,V> m; // Backing Mapfinal Object mutex; // Object on which to synchronize// …public int size() {synchronized (mutex) {return m.size();}}// …
}所以,Hashtable 或者同步包装版本,都只是适合在非高度并发的场景下。
2.ConcurrentHashMap 分析
我们再来看看 ConcurrentHashMap 是如何设计实现的,为什么它能大大提高并发效率。
首先,我这里强调,ConcurrentHashMap 的设计实现其实一直在演化,比如在 Java 8 中就发生了非常大的变化(Java 7 其实也有不少更新),所以,我这里将比较分析结构、实现机制等方面,对比不同版本的主要区别。
早期 ConcurrentHashMap,其实现是基于:
分离锁,也就是将内部进行分段(Segment),里面则是 HashEntry 的数组,和 HashMap 类似,哈希相同的条目也是以链表形式存放。
HashEntry 内部使用 volatile 的 value 字段来保证可见性,也利用了不可变对象的机制以改进利用 Unsafe 提供的底层能力,比如 volatile access,去直接完成部分操作,以最优化性能,毕竟 Unsafe 中的很多操作都是 JVM intrinsic 优化过的。
你可以参考下面这个早期 ConcurrentHashMap 内部结构的示意图,其核心是利用分段设计,在进行并发操作的时候,只需要锁定相应段,这样就有效避免了类似 Hashtable 整体同步的问题,大大提高了性能。

在构造的时候,Segment 的数量由所谓的 concurrencyLevel 决定,默认是 16,也可以在相应构造函数直接指定。注意,Java 需要它是 2 的幂数值,如果输入是类似 15 这种非幂值,会被自动调整到 16 之类 2 的幂数值。
具体情况,我们一起看看一些 Map 基本操作的源码,这是 JDK 7 比较新的 get 代码。针对具体的优化部分,为方便理解,我直接注释在代码段里,get 操作需要保证的是可见性,所以并没有什么同步逻辑。
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;int h = hash(key.hashCode());//利用位操作替换普通数学运算long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;// 以Segment为单位,进行定位// 利用Unsafe直接进行volatile accessif ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {//省略}return null;}
而对于 put 操作,首先是通过二次哈希避免哈希冲突,然后以 Unsafe 调用方式,直接获取相应的 Segment,然后进行线程安全的 put 操作:
public V put(K key, V value) {Segment<K,V> s;if (value == null)throw new NullPointerException();// 二次哈希,以保证数据的分散性,避免哈希冲突int hash = hash(key.hashCode());int j = (hash >>> segmentShift) & segmentMask;if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);return s.put(key, hash, value, false);}其核心逻辑实现在下面的内部方法中:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {// scanAndLockForPut会去查找是否有key相同Node// 无论如何,确保获取锁HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);V oldValue;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {if (e != null) {K k;// 更新已有value...}else {// 放置HashEntry到特定位置,如果超过阈值,进行rehash// ...}}} finally {unlock();}return oldValue;}所以,从上面的源码清晰的看出,在进行并发写操作时:
ConcurrentHashMap 会获取再入锁,以保证数据一致性,Segment 本身就是基于 ReentrantLock 的扩展实现,所以,在并发修改期间,相应 Segment 是被锁定的。
在最初阶段,进行重复性的扫描,以确定相应 key 值是否已经在数组里面,进而决定是更新还是放置操作,你可以在代码里看到相应的注释。重复扫描、检测冲突是 ConcurrentHashMap 的常见技巧。
我在专栏上一讲介绍 HashMap 时,提到了可能发生的扩容问题,在 ConcurrentHashMap 中同样存在。不过有一个明显区别,就是它进行的不是整体的扩容,而是单独对 Segment 进行扩容,细节就不介绍了。
另外一个 Map 的 size 方法同样需要关注,它的实现涉及分离锁的一个副作用。
试想,如果不进行同步,简单的计算所有 Segment 的总值,可能会因为并发 put,导致结果不准确,但是直接锁定所有 Segment 进行计算,就会变得非常昂贵。其实,分离锁也限制了 Map 的初始化等操作。
所以,ConcurrentHashMap 的实现是通过重试机制(RETRIES_BEFORE_LOCK,指定重试次数 2),来试图获得可靠值。如果没有监控到发生变化(通过对比 Segment.modCount),就直接返回,否则获取锁进行操作。
下面我来对比一下,在 Java 8 和之后的版本中,ConcurrentHashMap 发生了哪些变化呢?
总体结构上,它的内部存储变得和我在专栏上一讲介绍的 HashMap 结构非常相似,同样是大的桶(bucket)数组,然后内部也是一个个所谓的链表结构(bin),同步的粒度要更细致一些。
其内部仍然有 Segment 定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构上的用处。
因为不再使用 Segment,初始化操作大大简化,修改为 lazy-load 形式,这样可以有效避免初始开销,解决了老版本很多人抱怨的这一点。
数据存储利用 volatile 来保证可见性。
使用 CAS 等操作,在特定场景进行无锁并发操作。
使用 Unsafe、LongAdder 之类底层手段,进行极端情况的优化。
先看看现在的数据存储内部实现,我们可以发现 Key 是 final 的,因为在生命周期中,一个条目的 Key 发生变化是不可能的;与此同时 val,则声明为 volatile,以保证可见性。
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;// … }
我这里就不再介绍 get 方法和构造函数了,相对比较简单,直接看并发的 put 是如何实现的。
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh; K fk; V fv;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 利用CAS去进行无锁线程安全操作,如果bin是空的if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break; }else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else if (onlyIfAbsent // 不加锁,进行检查&& fh == hash&& ((fk = f.key) == key || (fk != null && key.equals(fk)))&& (fv = f.val) != null)return fv;else {V oldVal = null;synchronized (f) {// 细粒度的同步修改操作... }}// Bin超过阈值,进行树化if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;
}初始化操作实现在 initTable 里面,这是一个典型的 CAS 使用场景,利用 volatile 的 sizeCtl 作为互斥手段:如果发现竞争性的初始化,就 spin 在那里,等待条件恢复;否则利用 CAS 设置排他标志。如果成功则进行初始化;否则重试。
请参考下面代码:
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {// 如果发现冲突,进行spin等待if ((sc = sizeCtl) < 0)Thread.yield(); // CAS成功返回true,则进入真正的初始化逻辑else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {try {if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;sc = n - (n >>> 2);}} finally {sizeCtl = sc;}break;}}return tab;
}当 bin 为空时,同样是没有必要锁定,也是以 CAS 操作去放置。
你有没有注意到,在同步逻辑上,它使用的是 synchronized,而不是通常建议的 ReentrantLock 之类,这是为什么呢?现代 JDK 中,synchronized 已经被不断优化,可以不再过分担心性能差异,另外,相比于 ReentrantLock,它可以减少内存消耗,这是个非常大的优势。
与此同时,更多细节实现通过使用 Unsafe 进行了优化,例如 tabAt 就是直接利用 getObjectAcquire,避免间接调用的开销。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getObjectAcquire(tab, ((long)i << ASHIFT) + ABASE);
}再看看,现在是如何实现 size 操作的。阅读代码你会发现(http://hg.openjdk.java.net/jdk/jdk/file/12fc7bf488ec/src/java.base/share/classes/java/util/concurrent/ConcurrentHashMap.java),真正的逻辑是在 sumCount 方法中, 那么 sumCount 做了什么呢?
final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}
我们发现,虽然思路仍然和以前类似,都是分而治之的进行计数,然后求和处理,但实现却基于一个奇怪的 CounterCell。 难道它的数值,就更加准确吗?数据一致性是怎么保证的?
static final class CounterCell {volatile long value;CounterCell(long x) { value = x; }
}
其实,对于 CounterCell 的操作,是基于 java.util.concurrent.atomic.LongAdder 进行的,是一种 JVM 利用空间换取更高效率的方法,利用了Striped64内部的复杂逻辑。这个东西非常小众,大多数情况下,建议还是使用 AtomicLong,足以满足绝大部分应用的性能需求。
今天我从线程安全问题开始,概念性的总结了基本容器工具,分析了早期同步容器的问题,进而分析了 Java 7 和 Java 8 中 ConcurrentHashMap 是如何设计实现的,希望 ConcurrentHashMap 的并发技巧对你在日常开发可以有所帮助。
一课一练
关于今天我们讨论的题目你做到心中有数了吗?留一个道思考题给你,在产品代码中,有没有典型的场景需要使用类似 ConcurrentHashMap 这样的并发容器呢?
请你在留言区写写你对这个问题的思考,我会选出经过认真思考的留言,送给你一份学习鼓励金,欢迎你与我一起讨论。
c.LongAdder 进行的,是一种 JVM 利用空间换取更高效率的方法,利用了Striped64内部的复杂逻辑。这个东西非常小众,大多数情况下,建议还是使用 AtomicLong,足以满足绝大部分应用的性能需求。
今天我从线程安全问题开始,概念性的总结了基本容器工具,分析了早期同步容器的问题,进而分析了 Java 7 和 Java 8 中 ConcurrentHashMap 是如何设计实现的,希望 ConcurrentHashMap 的并发技巧对你在日常开发可以有所帮助。
一课一练
关于今天我们讨论的题目你做到心中有数了吗?留一个道思考题给你,在产品代码中,有没有典型的场景需要使用类似 ConcurrentHashMap 这样的并发容器呢?
请你在留言区写写你对这个问题的思考,我会选出经过认真思考的留言,送给你一份学习鼓励金,欢迎你与我一起讨论。
你的朋友是不是也在准备面试呢?你可以“请朋友读”,把今天的题目分享给好友,或许你能帮到他。
相关文章:
如何保证集合是线程安全的 ConcurrentHashMap如何实现高效地线程安全?
第10讲 | 如何保证集合是线程安全的? ConcurrentHashMap如何实现高效地线程安全? 我在之前两讲介绍了 Java 集合框架的典型容器类,它们绝大部分都不是线程安全的,仅有的线程安全实现,比如 Vector、Stack,在性能方面也…...

C++对象模型和this指针
成员变量和成员函数分开存储:基本概念:在C中,类内的成员变量和成员函数分开存储只有非静态成员变量才属于类的对象上每个空对象都会有一个独一无二的内存地址,所以,空对象占用内存空间的大小为1代码实现:#i…...
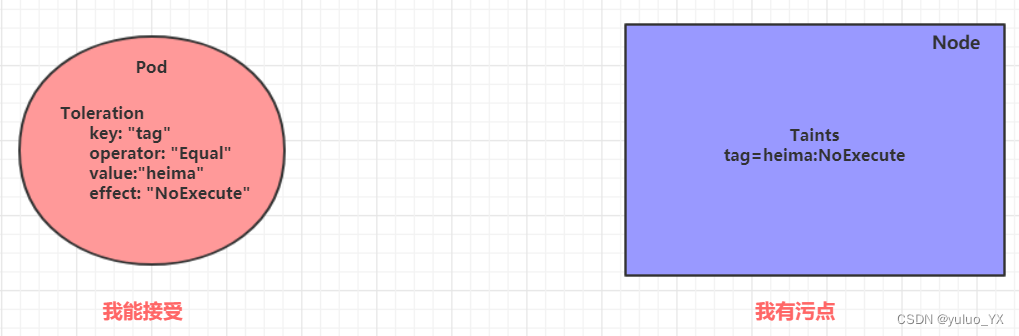
kubernetes教程 --Pod调度
Pod调度 在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某…...

功率放大器科普知识(晶体管功率放大器的注意事项)
虽然功率放大器是电子实验室的常用仪器,但是很多人对于它却没有清晰的认识,下面就让安泰电子来为大家介绍功率放大器的科普内容以及使用注意事项,希望大家可以对功率放大器有清晰的认识。功率放大器可以把输入信号的功率放大,以满…...
CentOS 7转化系统为阿里龙蜥Anolis OS 7
转载:原社区CentOS 7迁移Anolis OS 7迁移手册 一、注意事项 Anolis OS 7生态上和依赖管理上保持跟CentOS7.x兼容,一键式迁移脚本centos2anolis.py,实现CentOS7.x到Anolis OS 7的平滑迁移。 使用迁移脚本前需要注意如下事项: 迁…...
【快速复习】一文看懂 Mysql 核心存储 隔离级别 锁 MVCC 机制
一文看懂 Mysql 核心存储 & 隔离级别 & 锁 & MVCC 机制 Mysql InnoDB 引擎下核心存储 数据&索引存储 IBD 文件 mysql 实际存储采用 B 树结构。 B 树是一种多路搜索树,其搜索性能高于 B 树 所有叶节点在同一深度,保证搜索效率仅叶节…...
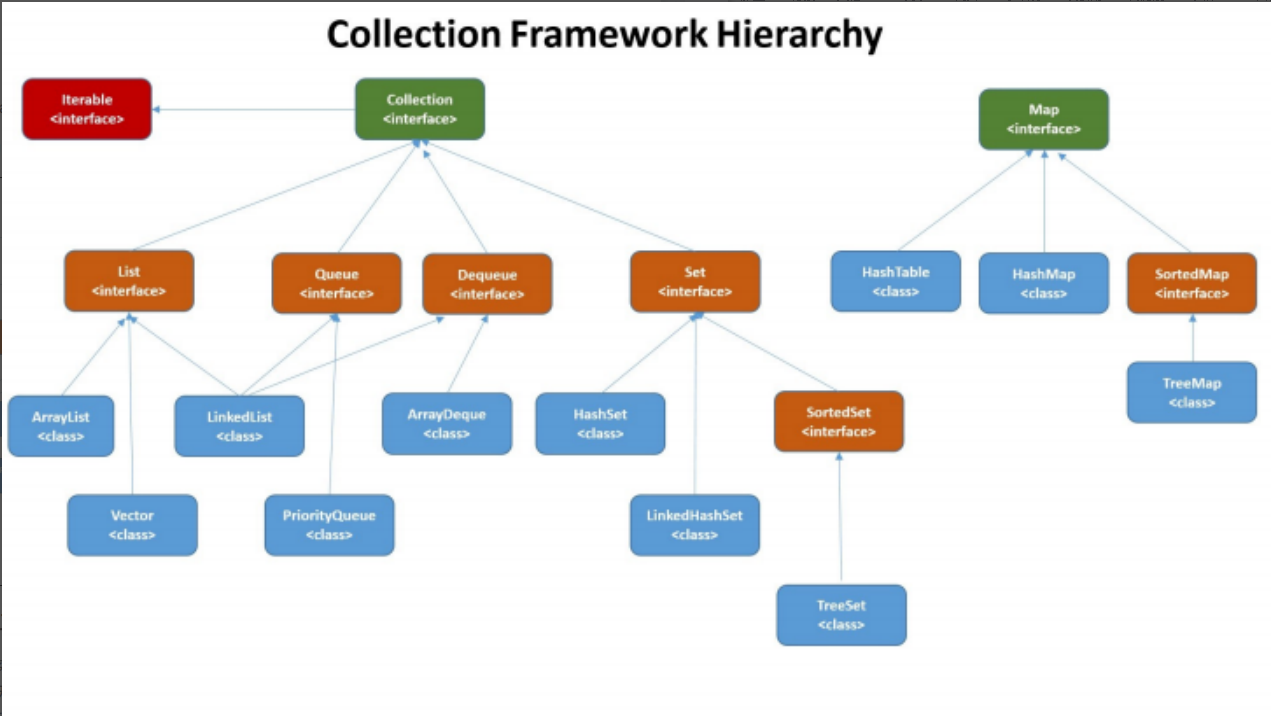
面试题----集合
概述 从上图可以看出,在Java 中除了以 Map 结尾的类之外, 其他类都实现了 Collection 接⼝。 并且,以 Map 结尾的类都实现了 Map 接⼝List,Set,Map List (对付顺序的好帮⼿): 存储的元素是有序的、可重复的。 Set (注重独⼀⽆⼆…...
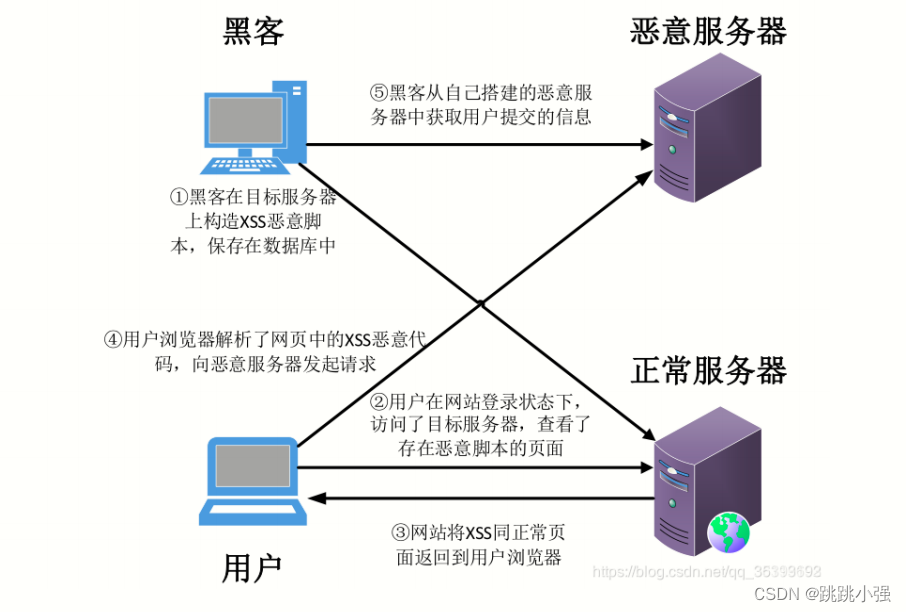
XSS注入基础入门篇
XSS注入基础入门篇1.XSS基础概念2. XSS的分类以及示例2.1 反射型XSS2.1.1 示例1:dvwa low 级别的反射型XSS2.1.2 攻击流程2.2 DOM型XSS2.2.1 示例2:DOM型XSS注入1.环境部署2.基础版本3.进阶绕过2.3 存储型XSS2.3.1 示例1:dvwa low示例2.3.2 攻…...
链表)
刷题 - 数据结构(二)链表
1. 链表 1.1 题目:合并两个有序链表 链表的建立与插入:关键在于留出头部,创建迭代指针。 ListNode* head new ListNode; // 通过new 创建了一个数据类型为ListNode的数据 并把该数据的地址赋值给ListNodeListNode* p 0; // 再创建一个数据…...

用于隔离PWM的光耦合器选择和使用
光耦合器(或光隔离器)是一种将电路电隔离的器件,不仅在隔离方面非常出色,而且允许您连接到具有不同接地层或在不同电压电平下工作的电路。光耦合器具有“故障安全”功能,因为如果受到高于最大额定值的电压,…...
面试完阿里,字节,腾讯的测试岗,复盘以及面试总结
前段时间由于某些原因辞职了,最近一直在面试。面试这段时间,经历过不同业务类型的公司(电商、酒店出行、金融、新能源、银行),也遇到了很多不同类型的面试官。 参加完三家大厂的面试聊聊我对面试的一些看法࿰…...

分享一个外贸客户案例
春节期间一个外贸人收到了客户的回复,但因为自己的处理方式造成了一个又一个问题,我们可以从中学到一些技巧和知识。“上次意大利的客人询价后,一直没回复(中间有打过电话,对方说口语不行,我写过邮件跟进过…...
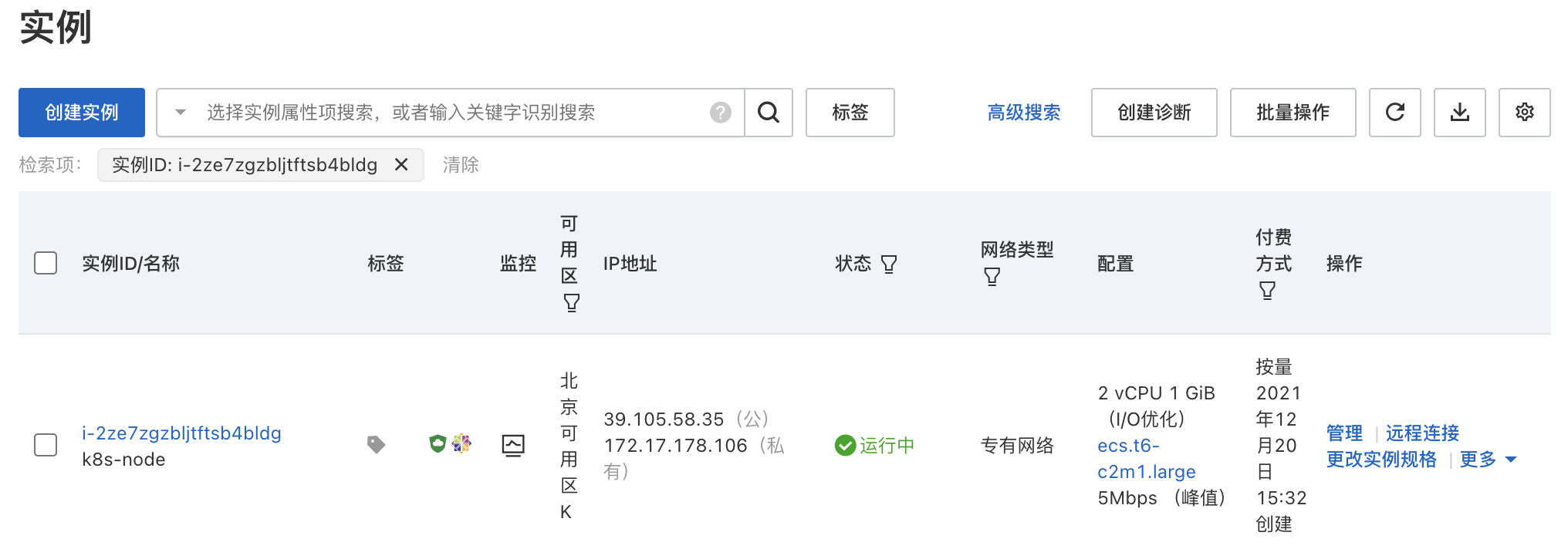
【Kubernetes】第二篇 - 购买阿里云 ECS 实例
一,前言 上一篇,简单介绍了 CI/CD 的概念以及 ECS 服务规划,搭建整套服务需要三台服务器,配置如下: ECS 配置启动服务说明2核4GJenkins Nexus Dockerci-server2核4GDocker Kubernetesk8s-master1核1GDocker Kube…...

数影周报:据传国内45亿条快递数据泄露,聆心智能完成Pre-A轮融资
本周看点:据传国内45亿条快递数据泄露;消息称微软解雇150 名云服务销售;消息称TikTok计划在欧洲再开两个数据中心;衣服长时间放购物车被淘宝客服嘲讽;聆心智能完成Pre-A轮融资......数据安全那些事据传国内45亿条快递数…...
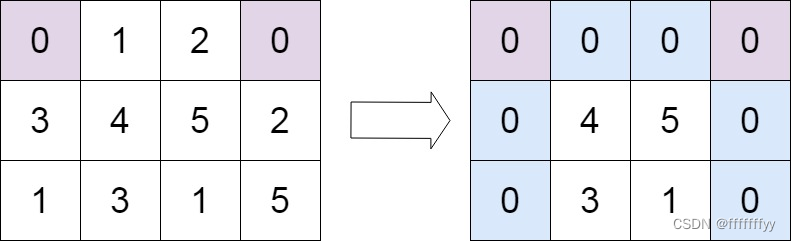
Leetcode力扣秋招刷题路-0073
从0开始的秋招刷题路,记录下所刷每道题的题解,帮助自己回顾总结 73. 矩阵置零 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:mat…...

遥感数字图像处理
遥感数字图像处理 来源:慕课北京师范大学朱文泉老师的课程 遥感应用:遥感制图、信息提取 短期内了解知识结构–>有选择的剖析经典算法原理–>系统化知识结构、并尝试实践应用 跳出算法(尤其是数学公式) 关注原理及解决问…...
深度学习常用的python函数(一)
由于我只简单的学过python和pytorch,其中有很多函数的操作都还是一知半解的,其中有些函数经常见到,所以就打算记录下来。 1.zip zip(*a):针对单个可迭代对象压缩成n个元组,元组数量n等于min(a中元素的最小长度) a [(1, 2), (3…...
2023年美国大学生数学建模A题:受干旱影响的植物群落建模详解+模型代码(一)
目录 前言 一、题目理解 背景 解析: 要求 二、建模 1.相关性分析 2.相关特征权重 只希望各位以后遇到建模比赛可以艾特认识一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路&…...
PPS文件如何转换成PPT?附两种方法
在工作中,PPS文件的使用还是很广泛的,因为作为幻灯片放映文件,点击后就能直接播放,十分方便。但如果想要修改PPS里的内容,PPS是无法编辑的,我们需要把文件转换成PPT,再进行修改。 那PPS文件如何…...
ParallelsDesktop安装【亲测可行】
我这边安装的是macos最新系统 (Ventura13.2) 本文参考这篇文章安装,但是你完全按照这篇文章会报错,具体可行操作记录如下 一、下载软件和补丁 1、点这里去下载补丁18.0.1 2、点这里去下载对应版本的ParallelsDesktop18.0.1,安装上到试用这里…...

计算机视觉工程师必须掌握的颜色空间选型指南
1. 项目概述:为什么计算机视觉工程师必须懂颜色理论你有没有遇到过这样的情况:模型在训练集上准确率98%,一到测试集就掉到72%?调试半天发现,不是数据标注错了,也不是网络结构有问题,而是训练图像…...

统一内存引擎:异构计算时代的内存管理革命
1. 项目概述:统一内存引擎的诞生背景与核心价值最近在分布式系统和数据库领域,一个名为chenxi-lee/unified-memory-engine的项目引起了我的注意。乍一看这个标题,可能会觉得它又是一个内存池或者缓存组件,但深入研究后你会发现&am…...

MarkFlowy:基于智能感知的Markdown写作流工具设计与实现
1. 项目概述:一个为Markdown而生的高效写作流工具 如果你和我一样,每天的工作都离不开Markdown——写技术文档、整理项目笔记、构思博客文章,那你一定体会过那种在“专注写作”和“格式调整”之间反复横跳的痛苦。刚进入心流状态,…...
终极配置指南:5步打造专业级网络视频传输系统)
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 你是否曾为OBS Stud…...

3PEAK思瑞浦 TP2262-SR SOP8 运算放大器
特性 供电电压:3V至36V 低供电电流:每通道700uA 轨到轨输出 带宽:4MHz 斜率:15V/us 优异的EMI抑制性能 偏移电压:最大3毫伏 偏移电压温度漂移:2V/C 低噪声:1kHz时30nV/vHz 工作温度范围:-40C至125C...

Java开发者收藏 | 你的经验不是负担,而是转型AI应用开发的加速器!
本文为Java开发者提供了清晰的AI应用开发转型路径。强调Java后端经验在AI领域是宝贵财富而非负担,并介绍了拥抱AI的优势。文章提出了分阶段学习路线,涵盖基础概念、框架选型(Spring AI、LangChain4j、Spring AI Alibaba)、可视化工…...

光纤偏振测量:从琼斯矢量到庞加莱球,六种工具深度解析与工程实践
1. 从一道周五小测题说起:光纤测量中的偏振态表征上周五,我在整理旧资料时,翻到了EE Times在2015年发布的一篇“周五小测”文章,主题是光纤光学测量。其中第一道题就很有意思,它问的是:“以下哪种工具不能用…...
)
Watercolor风格在MJ中被严重低估的3个底层能力:纸基模拟、颜料扩散建模、干湿叠加逻辑(Adobe资深插画师联合验证)
更多请点击: https://intelliparadigm.com 第一章:Watercolor风格在MJ中被严重低估的3个底层能力:纸基模拟、颜料扩散建模、干湿叠加逻辑(Adobe资深插画师联合验证) 纸基模拟:不只是纹理,而是…...

STM32CubeMX LL库配置外部中断,从按键消抖到中断嵌套的实战避坑指南
STM32CubeMX LL库外部中断深度优化:从硬件消抖到中断嵌套的工程实践 当你的嵌入式系统需要实时响应外部事件时,外部中断(EXTI)往往是最高效的选择。但在实际项目中,简单配置EXTI只是开始——按键抖动导致的误触发、中断优先级冲突引发的死锁、…...

AI工具搭建自动化视频生成NVENC
最近在折腾视频生成这块,发现AI工具搭配NVENC(NVIDIA的硬件编码器)做自动化视频生成,其实是个挺有意思的组合。很多人以为写个脚本调用FFmpeg就能搞定,但真正要把NVENC用透,背后的门道还是挺多的。不如从几…...