使用DataX实现mysql与hive数据互相导入导出
一、概论
1.1 什么是DataX
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
1.2 DataX 的设计
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。
1.3 框架设计

- Reader:数据采集模块,负责采集数据源的数据,将数据发给Framework。
- Wiriter: 数据写入模块,负责不断向Framwork取数据,并将数据写入到目的端。
- Framework:用于连接read和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
运行原理
- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
1.4 Datax所支持的渠道
| 类型 | 数据源 | 读者 | 作家(写) | 文件 |
|---|---|---|---|---|
| RDBMS关系型数据库 | MySQL | √ | √ | 读,写 |
| 甲骨文 | √ | √ | 读,写 | |
| SQL服务器 | √ | √ | 读,写 | |
| PostgreSQL的 | √ | √ | 读,写 | |
| DRDS | √ | √ | 读,写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读,写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读,写 |
| 美国存托凭证 | √ | 写 | ||
| 开源软件 | √ | √ | 读,写 | |
| OCS | √ | √ | 读,写 | |
| NoSQL数据存储 | OTS | √ | √ | 读,写 |
| Hbase0.94 | √ | √ | 读,写 | |
| Hbase1.1 | √ | √ | 读,写 | |
| 凤凰4.x | √ | √ | 读,写 | |
| 凤凰5.x | √ | √ | 读,写 | |
| MongoDB | √ | √ | 读,写 | |
| 蜂巢 | √ | √ | 读,写 | |
| 卡桑德拉 | √ | √ | 读,写 | |
| 无结构化数据存储 | 文本文件 | √ | √ | 读,写 |
| 的FTP | √ | √ | 读,写 | |
| HDFS | √ | √ | 读,写 | |
| 弹性搜索 | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| 技术开发局 | √ | √ | 读,写 |
二、快速入门
2.1 环境搭建
下载地址: http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
源码地址: https://github.com/alibaba/DataX
配置要求:
- Linux
- JDK(1.8以上 建议1.8) 下载
- Python(推荐 Python2.6.X)下载
安装:
1) 将下载好的datax.tar.gz上传到服务器的任意节点,我这里上传到node01上的/exprot/soft
2)解压到/export/servers/
[root@node01 soft]# tar -zxvf datax.tar.gz -C ../servers/3)运行自检脚本
出现以下结果说明你得环境没有问题
[/opt/module/datax/plugin/reader/._hbase094xreader/plugin.json]不存在. 请检查您的配置文件.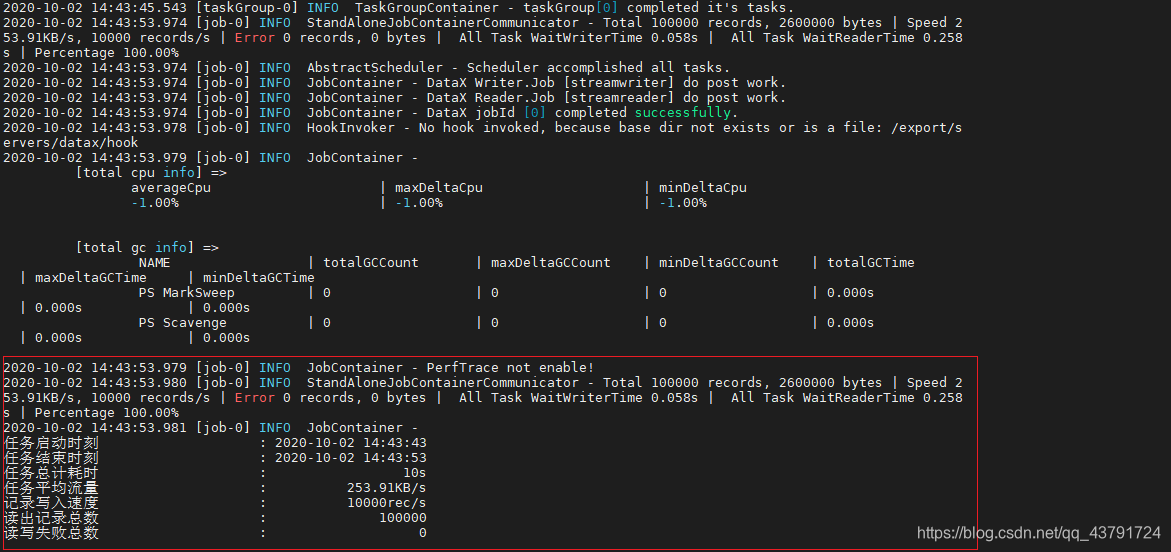
2.2搭建环境注意事项
[/opt/module/datax/plugin/reader/._hbase094xreader/plugin.json]不存在. 请检查您的配置文件.
参考:
find ./* -type f -name ".*er" | xargs rm -rf
find: paths must precede expression: |
Usage: find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression]find /datax/plugin/reader/ -type f -name "._*er" | xargs rm -rf
find /datax/plugin/writer/ -type f -name "._*er" | xargs rm -rf这里的/datax/plugin/writer/要改为你自己的目录
原文链接:https://blog.csdn.net/dz77dz/article/details/127055299
2.3读取Mysql中的数据写入到HDFS
准备
创建数据库和表并加载测试数据
create database test;
use test;
create table c_s(id varchar(100) null,c_id int null,s_id varchar(20) null
);
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 1, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 2, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 3, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 5, '201967');
INSERT INTO test.c_s (id, c_id, s_id) VALUES ('123', 6, '201967');查看官方提供的模板
[root@node01 datax]# bin/datax.py -r mysqlreader -w hdfswriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the mysqlreader document:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.mdPlease refer to the hdfswriter document:https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.mdPlease save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": [],"connection": [{"jdbcUrl": [],"table": []}],"password": "","username": "","where": ""}},"writer": {"name": "hdfswriter","parameter": {"column": [],"compress": "","defaultFS": "","fieldDelimiter": "","fileName": "","fileType": "","path": "","writeMode": ""}}}],"setting": {"speed": {"channel": ""}}}
}根据官网模板进行修改
[root@node01 datax]# vim job/mysqlToHDFS.json
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","c_id","s_id"],"connection": [{"jdbcUrl": ["jdbc:mysql://node02:3306/test"],"table": ["c_s"]}],"password": "123456","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "string"},{"name": "c_id","type": "int"},{"name": "s_id","type": "string"}],"defaultFS": "hdfs://node01:8020","fieldDelimiter": "\t","fileName": "c_s.txt","fileType": "text","path": "/","writeMode": "append"}}}],"setting": {"speed": {"channel": "1"}}}
}
HDFS的端口号注意版本,2.7.4 是9000;hdfs://node01:9000
MySQL的参数介绍
HDFS参数介绍
运行脚本
[root@node01 datax]# bin/datax.py job/mysqlToHDFS.json
2020-10-02 16:12:16.358 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /export/servers/datax/hook
2020-10-02 16:12:16.359 [job-0] INFO JobContainer -[total cpu info] =>averageCpu | maxDeltaCpu | minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info] =>NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTimePS MarkSweep | 1 | 1 | 1 | 0.245s | 0.245s | 0.245sPS Scavenge | 1 | 1 | 1 | 0.155s | 0.155s | 0.155s2020-10-02 16:12:16.359 [job-0] INFO JobContainer - PerfTrace not enable!
2020-10-02 16:12:16.359 [job-0] INFO StandAloneJobContainerCommunicator - Total 5 records, 50 bytes | Speed 5B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2020-10-02 16:12:16.360 [job-0] INFO JobContainer -
任务启动时刻 : 2020-10-02 16:12:04
任务结束时刻 : 2020-10-02 16:12:16
任务总计耗时 : 12s
任务平均流量 : 5B/s
记录写入速度 : 0rec/s
读出记录总数 : 5
读写失败总数 : 02.4 读取HDFS中的数据写入到Mysql
准备工作
create database test;
use test;
create table c_s2(id varchar(100) null,c_id int null,s_id varchar(20) null
);
查看官方提供的模板
[root@node01 datax]# bin/datax.py -r hdfsreader -w mysqlwriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the hdfsreader document:https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.mdPlease refer to the mysqlwriter document:https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.mdPlease save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "hdfsreader","parameter": {"column": [],"defaultFS": "","encoding": "UTF-8","fieldDelimiter": ",","fileType": "orc","path": ""}},"writer": {"name": "mysqlwriter","parameter": {"column": [],"connection": [{"jdbcUrl": "","table": []}],"password": "","preSql": [],"session": [],"username": "","writeMode": ""}}}],"setting": {"speed": {"channel": ""}}}
}根据官方提供模板进行修改
[root@node01 datax]# vim job/hdfsTomysql.json
{"job": {"content": [{"reader": {"name": "hdfsreader","parameter": {"column": ["*"],"defaultFS": "hdfs://node01:8020","encoding": "UTF-8","fieldDelimiter": "\t","fileType": "text","path": "/c_s.txt"}},"writer": {"name": "mysqlwriter","parameter": {"column": ["id","c_id","s_id"],"connection": [{"jdbcUrl": "jdbc:mysql://node02:3306/test","table": ["c_s2"]}],"password": "123456","username": "root","writeMode": "replace"}}}],"setting": {"speed": {"channel": "1"}}}
}
脚本运行
[root@node01 datax]# bin/datax.py job/hdfsTomysql.json[total cpu info] =>averageCpu | maxDeltaCpu | minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info] =>NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTimePS MarkSweep | 1 | 1 | 1 | 0.026s | 0.026s | 0.026sPS Scavenge | 1 | 1 | 1 | 0.015s | 0.015s | 0.015s2020-10-02 16:57:13.152 [job-0] INFO JobContainer - PerfTrace not enable!
2020-10-02 16:57:13.152 [job-0] INFO StandAloneJobContainerCommunicator - Total 5 records, 50 bytes | Speed 5B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.033s | Percentage 100.00%
2020-10-02 16:57:13.153 [job-0] INFO JobContainer -
任务启动时刻 : 2020-10-02 16:57:02
任务结束时刻 : 2020-10-02 16:57:13
任务总计耗时 : 11s
任务平均流量 : 5B/s
记录写入速度 : 0rec/s
读出记录总数 : 5
读写失败总数 : 0
2.5将Mysql表导入Hive
1.在hive中建表
-- hive建表
CREATE TABLE student2 (classNo string,stuNo string,score int)
row format delimited fields terminated by ',';-- 构造点mysql数据
create table if not exists student2(classNo varchar ( 50 ),stuNo varchar ( 50 ),score int
)
insert into student2 values('1001','1012ww10087',63);
insert into student2 values('1002','1012aa10087',63);
insert into student2 values('1003','1012bb10087',63);
insert into student2 values('1004','1012cc10087',63);
insert into student2 values('1005','1012dd10087',63);
insert into student2 values('1006','1012ee10087',63);2.编写mysql2hive.json配置文件
{"job": {"setting": {"speed": {"channel": 1}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "root","connection": [{"table": ["student2"],"jdbcUrl": ["jdbc:mysql://192.168.43.10:3306/mytestmysql"]}],"column": ["classNo","stuNo","score"]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://192.168.43.10:9000","path": "/hive/warehouse/home/myhive.db/student2","fileName": "myhive","writeMode": "append","fieldDelimiter": ",","fileType": "text","column": [{"name": "classNo","type": "string"},{"name": "stuNo","type": "string"},{"name": "score","type": "int"}]}}}]}
}3.运行脚本
bin/datax.py job/mysql2hive.json 4.查看hive表是否有数据

2.6将Hive表数据导入Mysql
1.要先在mysql建好表
create table if not exists student(classNo varchar ( 50 ),stuNo varchar ( 50 ),score int
)2.hive2mysql.json配置文件
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/hive/warehouse/home/myhive.db/student/*","defaultFS": "hdfs://192.168.43.10:9000","column": [{"index": 0,"type": "string"},{"index": 1,"type": "string"},{"index": 2,"type": "Long"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "root","column": ["classNo","stuNo","score"],"preSql": ["delete from student"],"connection": [{"jdbcUrl": "jdbc:mysql://192.168.43.10:3306/mytestmysql?useUnicode=true&characterEncoding=utf8","table": ["student"]}]}}}]}
}
注意事项:
在Hive的ODS层建表语句中,以“,”为分隔符;
fields terminated by ','
在DataX的json文件中,也以“,”为分隔符。
"fieldDelimiter": "," 与hive表里面的分隔符保持一致即可
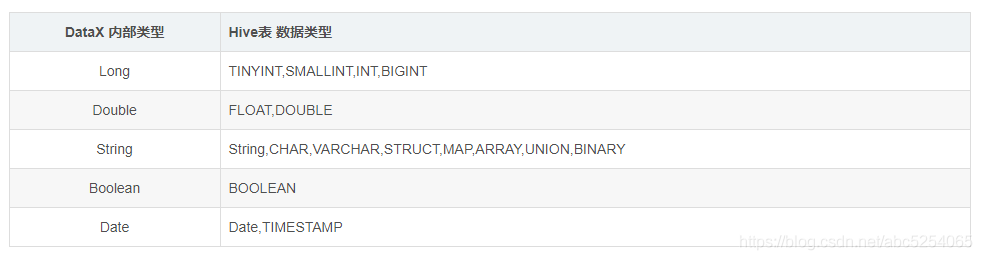
由于DataX不能完全支持所有Hive表的数据类型,应将DataX启动文件中的hdfsreader中的column字段的类型改成DataX支持的类型
相关文章:
使用DataX实现mysql与hive数据互相导入导出
一、概论 1.1 什么是DataX DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。 1.2 DataX 的设计 为了解决异构数据源同步问题…...
语音转录成文本:AI Transcription for mac
AI Transcription是一种人工智能技术,它可以将音频和视频文件转换成文本格式。这种技术可以帮助用户快速地将大量的音频和视频内容转换成文本格式,方便用户进行文本分析、搜索和编辑等操作。 以下是AI Transcription的几个特点: 高效性。AI …...
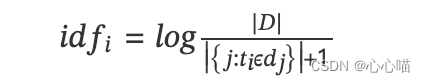
[nlp] TF-IDF算法介绍
(1)TF是词频(Term Frequency) 词频是文档中词出现的概率。 (2) IDF是逆向文件频率(Inverse Document Frequency) 包含词条的文档越少,IDF越大。...

一些感想,写在8月之前
最近换工作了,离开了一个奋斗了4年多的公司,现在在新公司,还在培训中,不那么忙了,就写写最近的想法吧。 因为最近一直在研究框架和搭项目框架,所以就想把一些工作上的过程记录下来,以备不时之需…...

推动数字经济高质量发展需破解三大挑战
随着信息技术的飞速发展,数字经济已成为全球经济发展的重要驱动力。数字经济以其高效、便捷、创新的特点,深刻改变着传统产业和商业模式,为经济发展带来新的活力和动力。然而,要实现数字经济的高质量发展,仍然面临着三…...
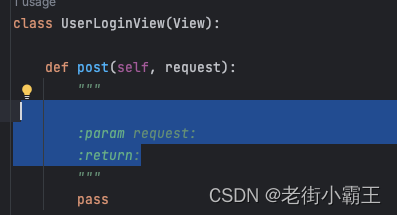
Pycharm工具Python开发自动添加注释(详细)
方法自动添加参数注释 定义了一个函数,在函数下面敲入了三个双引号后,enter回车并没有自动出现注释,如图: 解决办法 Pycharm中依次打开File —> Settings —> Tools —> Python Integrated Tools,如图&…...

RUST 有哪些整型?
在Rust中,有以下几种整型数据类型: i8 :有符号8位整型,取值范围为-128到127。u8 :无符号8位整型,取值范围为0到255。i16 :有符号16位整型,取值范围为-32768到32767。u16 ࿱…...
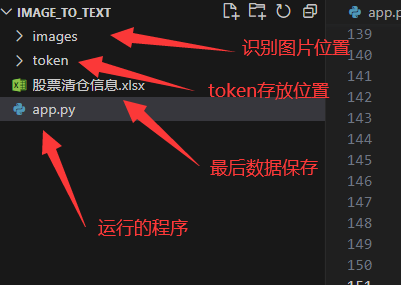
【Python 实战】---- 批量识别图片中的文字,存入excel中【使用百度的通用文字识别】
分析 1. 获取信息图片示例 2. 运行实例 3. 运行结果 4. 各个文件的位置 实现 1. 需求分析 识别图片中的文字【采用百度的通用文字识别】;文字筛选,按照分类获取对应的文本;采用 openpyxl 实现将数据存入 excel 中。2. 获取 access_token 获取本地缓存的...

探索前端图片如何携带token进行验证
前言 图片在前端开发中扮演了重要的角色,它们不仅仅是美观的元素,还可以传递信息和激发用户的兴趣。随着应用场景的增多,前端开发人员就需要在图片加载过程中携带验证的信息。如 token,用于身份验证、权限控制等方面。通过在图片的…...

飞桨AI Studio可以玩多模态了?MiniGPT4实战演练!
MiniGPT4是基于GPT3的改进版本,它的参数量比GPT3少了一个数量级,但是在多项自然语言处理任务上的表现却不逊于GPT3。项目作者以MiniGPT4-7B作为实战演练项目。 创作者:衍哲 体验链接: https://aistudio.baidu.com/aistudio/proj…...

C++笔记之++i和i++是原子操作吗?
C笔记之i和i是原子操作吗? code review! 文章目录 C笔记之i和i是原子操作吗?1.i是原子操作吗?2.i是原子操作吗?3.前置递增和后置递增 1.i是原子操作吗? 2.i是原子操作吗? 3.前置递增和后置递增...
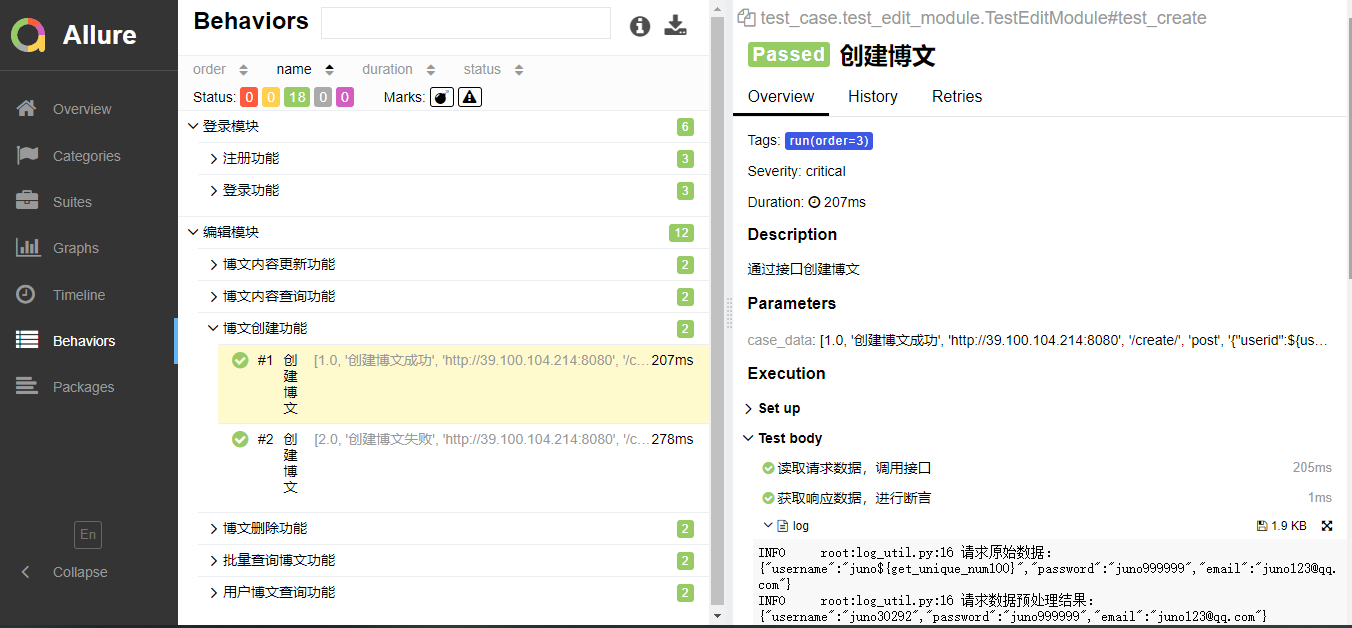
Pytest+Allure+Excel接口自动化测试框架实战
1. Allure 简介 简介 Allure 框架是一个灵活的、轻量级的、支持多语言的测试报告工具,它不仅以 Web 的方式展示了简介的测试结果,而且允许参与开发过程的每个人可以从日常执行的测试中,最大限度地提取有用信息。 Allure 是由 Java 语言开发…...

阿里云国际版账号注册常见问题汇总
公司现与阿里云国际站达成战略合作,为客户提供高品质、高性能、高可用的阿里云产品与服务,助力客户用云服务创造更多价值,达成业务转型、加速和创新,全面提升业务竞争力。助企业在各种业务场景中充分利用混合云基础设施进行优化。…...

Flowable基础
简介 Flowable 是 BPMN 的一个基于 java 的软件实现,不过 Flowable 不仅仅包括 BPMN ,还有 DMN 决策表和 CMMN Case 管理引擎,并且有自己的用户管理、微服务 API 等一系列功能, 是一个服务平台。 官方手册: https://…...
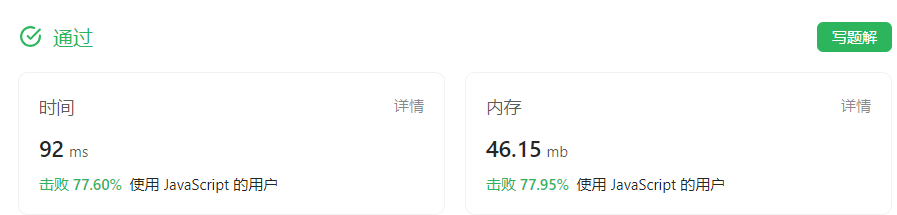
力扣热门100题之合并区间【中等】
题目描述 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入:interv…...

机会成本:隐形的手,驱动你的选择
机会成本这个词不知道你有没有听说过。 机会成本是指在面临多方案择一决策时,被舍弃的选项中的最高价值者。换句话说,机会成本是一种失去的收益,不是实际支付的成本。 机会成本是经济学中一个非常重要的概念,它可以帮助我们更好地…...

win10日程怎么同步到安卓手机?电脑日程同步到手机方法
在如今快节奏的生活中,高效地管理时间变得至关重要。而对于那些经常在电脑上安排日程的人来说,将这些重要的事务同步到手机上成为了一个迫切的需求。因为目前国内使用win10系统电脑、安卓手机的用户较多,所以越来越多的职场人士想要知道&…...

7月31日每日两题
第一题:再解炸弹人 小哼最近爱上了“炸弹人”游戏。你还记得在小霸王游戏机上的炸弹人吗?用放置炸弹的方法来消灭敌人。需将画面上的敌人全部消灭后,并找到隐藏在墙里的暗门才能过关。 现在有一个特殊的关卡如下。你只有一枚炸弹,但是这枚炸弹威力超强(杀伤距离超长,可…...

首期华为云ROMA Connect《企业集成战略与华为数字化之道》高研班在东莞圆满举办
7月25日,首期华为云ROMA Connect《企业集成战略与华为数字化之道》高研班在东莞华为制造业数字化转型中心圆满举办。 20多家东莞精密机械、电子、环保等领域的先进企业董事长、总经理、CIO、总监等高管参加培训。 本次高研班邀请到华为数字化转型专家陈劲、马兵东…...

JS语法知识点
变量声明: 使用 var 关键字声明的变量具有函数作用域,可以在函数内部访问。使用 let 或 const 关键字声明的变量具有块级作用域,只在声明的块内有效。 数据类型: 字符串(String):表示文本数据&a…...

如何快速掌握基因引物设计:Primer3-py 的完整入门指南
如何快速掌握基因引物设计:Primer3-py 的完整入门指南 【免费下载链接】primer3-py Simple oligo analysis and primer design 项目地址: https://gitcode.com/gh_mirrors/pr/primer3-py 在分子生物学研究中,高效准确的引物设计是实验成功的关键。…...

武汉大学等高校联手揭露AI助手的“记忆盲区“:它们真的记得你吗?
这项由武汉大学、香港中文大学和香港科技大学联合开展的研究以预印本形式于2026年5月发表,论文编号为arXiv:2605.06527,有兴趣深入了解的读者可以通过该编号查询完整论文。你有没有试过这样一件事:你和手机里的AI助手聊了很久,告诉…...

BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/g…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan环境搭建指南
2026年京东云OpenClaw/Hermes Agent配置Token Plan环境搭建指南。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

IDM激活脚本:破解30天限制背后的注册表权限技术内幕
IDM激活脚本:破解30天限制背后的注册表权限技术内幕 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 你是否曾经因为IDM的30天试用期到期而烦恼&#…...

抖音直播弹幕实时采集:基于Golang的高性能解决方案
抖音直播弹幕实时采集:基于Golang的高性能解决方案 【免费下载链接】douyin-live-go 抖音(web) 弹幕爬虫 golang 实现 项目地址: https://gitcode.com/gh_mirrors/do/douyin-live-go 在直播电商和内容创作蓬勃发展的今天,实时获取抖音直播间的弹幕…...

Context Engineering 实战:别再往 context 里塞东西了
Context Engineering 实战:别再往 context 里塞东西了 为什么 token 塞满反而让 LLM 变蠢?四种核心策略 Python 代码实现 Agent 跑到第 15 步,突然开始做蠢事。 它把已经检查过的文件又检查了一遍,给出了和第 3 步完全矛盾的结论…...

制造业数据架构设计顶层规划方案:数据资源规划、基础数据管理、数据分析应用、数据治理体系 、实施路线图
该方案针对企业数据架构空白、缺乏统一模型与治理体系的问题,提出了以数据资源规划、主数据与元数据管理、数据分析应用及数据治理为核心的整体架构。通过明确数据分布与流向、构建企业级数据仓库与治理平台,最终实现数据驱动决策与业务规范化࿰…...
:含ISO 200/400/800三档真实胶片响应曲线)
【限时解密】Midjourney范戴克印相私藏LUT包+预设Prompt库(仅开放48小时):含ISO 200/400/800三档真实胶片响应曲线
更多请点击: https://kaifayun.com 第一章:Midjourney范戴克印相的美学溯源与数字复刻逻辑 范戴克印相(Van Dyke Brown process)诞生于19世纪末,是一种以硝酸银、柠檬酸铁铵与酒石酸钾钠配制感光液,经紫外…...

宝丽来胶片模拟不等于加噪点!深度拆解Polaroid SX-70光学特性与MJ v6渲染引擎的4层映射偏差,附12组可直接复用的--sref哈希值
更多请点击: https://intelliparadigm.com 第一章:宝丽来SX-70胶片的光学本质与历史语境 宝丽来SX-70胶片并非传统意义上的“静态感光材料”,而是一套高度集成的自显影光学化学系统。其核心在于多层涂布结构中嵌入的镜面反射层、碱性催化剂囊…...