【论文阅读】The Deep Learning Compiler: A Comprehensive Survey
论文来源:Li M , Liu Y , Liu X ,et al.The Deep Learning Compiler: A Comprehensive Survey[J]. 2020.DOI:10.1109/TPDS.2020.3030548.
这是一篇关于深度学习编译器的综述类文章。
什么是深度学习编译器
深度学习(Deep Learning)编译器将深度学习框架描述的模型在各种硬件平台上生成有效的代码实现,其完成的模型定义到特定代码实现的转换将针对模型规范和硬件体系结构高度优化。具体来说,它们结合了面向深度学习的优化,例如层融合和操作符融合,实现高效的代码生成。
此外,现有的编译器还采用了来自通用编译器(例如LLVM)的成熟工具链,对各种硬件体系结构提供了更好的可移植性。
简而言之,深度学习编译器通过对深度学习模型和计算图的优化,以及对硬件资源的充分利用,提高了深度学习模型的性能和效率。这使得深度学习模型在边缘设备和嵌入式系统上能够更好地运行。
深度学习编译器的基本架构
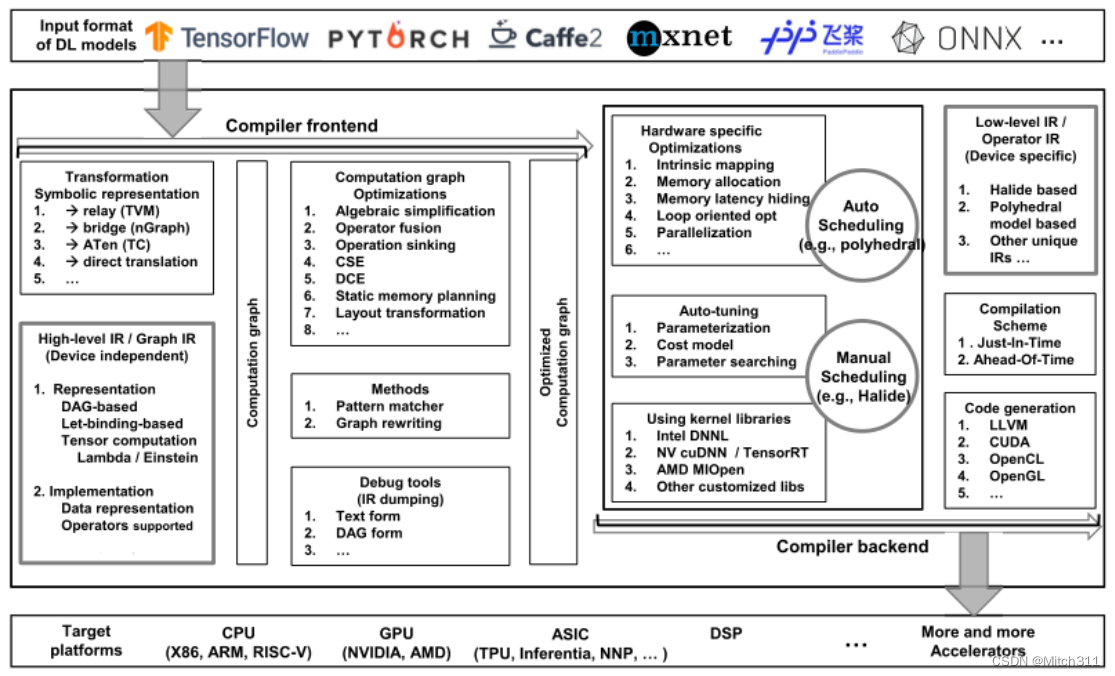
与传统编译器类似,深度学习编译器也采用分层设计,其通用设计架构主要包括编译器前端和编译器后端,其中IR(中间语言)分布在前端和后端,它是程序的抽象,用于程序优化。
深度学习模型在深度学习编译器中被转换为多级IR,其中高阶IR驻留在前端,低阶IR驻留在后端。基于高阶IR,编译器前端负责与硬件无关的转换和优化。基于低阶IR,编译器后端负责特定于硬件的优化、代码生成和编译。
高阶IR,也称为graph IR,表示计算和控制流,与硬件无关。高阶IR的设计挑战是计算和控制流的抽象能力,能够捕获和表达不同的DL模型。高阶IR的目标是建立控制流和op(算子)与数据之间的依赖关系,以及为图级优化提供接口。它还包含用于编译的丰富语义信息,并为定制算子提供可扩展性。
低阶IR是为特定于硬件的优化和针对不同硬件目标的代码生成而设计的。因此,低阶IR应该足够细粒度,以反映硬件特征并表示特定于硬件的优化。
前端将现有的Deep Learning框架中的模型作为输入,然后将该模型转换为计算图表示(例如,graph IR)。前端需要实现多种格式转换,以支持不同框架下的多种格式。计算图优化结合了通用编译器的优化技术和Deep Learning特定优化技术,减少了graph IR的冗余,提高了图graph IR的效率。这样的优化可以分为:
-
node节点级(例如,nop消除和零维张量消除)
-
block块级(代数简化、算子融合、op下降)
-
数据流层(例如CSE、DCE、静态内存规划和布局转换)。
前端完成后,生成优化的计算图并传递给后端,后端将高阶IR转换为低阶IR并执行特定于硬件的优化。一方面,它可以直接将高阶IR转换为第三方工具链,如LLVM IR,以利用现有的基础设施进行通用优化和代码生成。另一方面,它可以利用DL模型和硬件特性的先验知识,通过定制的编译通道,实现更高效的代码生成。通常应用的特定于硬件的优化包括硬件内在映射、内存分配和获取、内存延迟隐藏、并行化以及面向循环的优化。
前端优化
在构建计算图之后,前端应用图级优化。许多优化更容易在图级识别和执行,因为图提供了计算的全局视图。这些优化只应用于计算图,而不是后端实现。因此,它们是独立于硬件的,可以应用于各种后端目标。
前端优化通常由passes定义,可以通过遍历计算图的节点并执行图转换来应用。前端提供了如下方法:
-
从计算图中捕获特定的特征;
-
重写图以进行优化。
除了预定义的passes,开发人员还可以在前端定义定制的passes。一旦一个Deep Learning模型被导入并转换为一个计算图,大多数DL编译器可以确定每个操作的输入张量和输出张量的形状。
节点级优化
计算图的节点足够粗粒度,可以在单个节点内进行优化。节点级优化包括:
-
节点消除(消除不必要的节点)
-
节点替换(用其他低成本节点替换节点)
在通用编译器中,Nop消除删除占用少量空间但不指定操作的no-op指令;在DL编译器中,Nop消除负责消除缺少足够输入的操作。例如,只有一个输入张量的和节点可以被消除,填充宽度为零的填充节点可以被消除。
块级优化
代数简化
代数简化优化包括:
-
代数识别
-
强度约简,我们可以用更便宜的算子取代更昂贵的算子
-
常数折叠,用它可以用它们的值替换常量表达式。
算子融合
算子融合是DL编译器不可缺少的优化方法。它能够更好地共享计算,消除中间分配,通过结合loop nests进一步优化,并减少launch和同步开销。
算子Sinking
算子Sinking这种优化将转置等操作置于批处理归一化、ReLU、sigmoid和channel shuffle等操作之下。
通过算子Sinking这种优化,许多相似的操作彼此之间移动得更近,为代数简化创造了更多的机会。
数据流级优化
通用子表达式消除(CSE)
如果表达式E的值之前已经计算过,并且E的值在之前的计算之后没有改变,那么它就是通用子表达式。
在这种情况下,E的值只计算一次,并且可以使用已经计算出的E的值来避免在其他地方重新计算。深度学习编译器在整个计算图中搜索公共子表达式,并用之前的计算结果替换下面的公共子表达式。
死代码消除(DCE)
如果一组代码的计算结果或副作用没有被使用,那么它就是死代码。
DCE优化会删除死代码。死代码通常不是由程序员引起的,而是由其他图优化引起的。因此DCE和CSE是在其他图优化之后应用的。
静态内存规划
使用静态内存规划优化以尽可能重用内存缓冲区,通常有两种方法:
-
in-place内存共享
-
标准内存共享
in-place内存共享使用相同的内存作为操作的输入和输出,只在计算之前分配一个内存副本。标准内存共享重用以前操作的内存,而不重叠。静态内存规划是离线完成的,这允许应用更复杂的规划算法。
布局转变
布局转换试图找到最佳的数据布局来存储张量到计算图中,然后将布局转换节点插入到图中。
注意,这里不执行实际的转换,而是在编译器后端计算计算图时执行转换。事实上,相同操作在不同的数据布局中的性能是不同的,最佳布局在不同的硬件上也是不同的。
后端优化
特定于硬件的优化
特定于硬件的优化也称为目标相关优化,用于获得针对特定硬件的高性能代码。应用后端优化的一种方法是将低层IR转换为LLVM IR,利用LLVM基础设施生成优化的CPU/GPU代码。另一种方法是使用DL领域知识设计定制优化,更有效地利用目标硬件。
以下有五种在现有DL编译器中广泛采用的方法:
硬件固有的映射
硬件内在映射可以将一定的一组低层IR指令转换为已经在硬件上高度优化的内核。在TVM中,硬件本征映射采用可扩展张量化方法实现,可声明硬件本征的行为和本征映射的降低规则。这种方法使编译器后端能够将硬件实现和高度优化的手工微内核应用到特定的操作模式中,从而获得显著的性能提升。
内存分配和获取
内存分配是代码生成中的另一个挑战,特别是对于gpu和定制加速器。例如,GPU主要包含共享内存空间(内存大小有限,访问时延较低)和本地内存空间(容量大,访问时延较高)。这样的内存层次结构需要有效的内存分配和获取技术来改善数据局部性。为了实现这一优化,TVM引入了内存作用域的调度概念。内存作用域调度原语可以将计算阶段标记为共享的或线程本地的。对于标记为共享的计算阶段,TVM生成具有共享内存分配和协同数据获取的代码,并在适当的代码位置插入内存屏障以保证正确性。
内存延迟隐藏
通过对执行管道重新排序,内存延迟隐藏也是在后端使用的一项重要技术。由于大多数DL编译器支持CPU和GPU上的并行化,内存延迟隐藏可以自然地通过硬件实现(例如,GPU上的扭曲上下文切换)。但是对于具有解耦访问库(DAE)体系结构的TPU类加速器,后端需要执行调度和细粒度同步以获得正确和高效的代码。为了获得更好的性能和减轻编程负担,TVM引入了虚拟线程调度原语,允许用户在虚拟多线程架构上指定数据并行度。然后,TVM通过插入必要的内存屏障,并将来自这些线程的操作穿插到单个指令流中,从而降低了这些实际上并行的线程,这形成了每个线程更好的执行管道,以隐藏内存访问延迟。
面向循环优化
面向循环的优化也应用于后端,为目标硬件生成高效的代码。由于Halide和LLVM已经集成了这样的优化技术,一些DL编译器在后端利用了Halide和LLVM。面向循环优化中应用的关键技术包括循环融合、滑动窗口、平铺、循环重排序和循环展开。
并行化
由于现代处理器通常支持多线程和SIMD并行性,编译器后端需要利用并行性来最大化硬件利用率,以实现高性能。
Halide使用一个叫做parallel的调度原语来指定线程级别并行化的循环的并行化维度,并通过将标记为parallel的循环维度与块和线程的注释进行映射来支持GPU并行化。它将一个大小为n的循环替换为一个宽为n的向量语句,该向量语句可以通过硬件内在映射映射到特定于硬件的SIMD操作码。
Stripe发展了一种多面体模型的变体,称为嵌套多面体模型,该模型引入了并行多面体块作为迭代的基本执行元素。在此扩展之后,一个嵌套的多面体模型可以检测平铺和跨步级别之间的层次并行性。
自动调优
由于在特定于硬件的优化中参数调优有巨大的搜索空间,因此有必要利用自动调优来确定最佳参数配置。在A Comprehensive Survey[4]这篇论文中研究的DL编译器中,TVM、TC和XLA支持自动调优。通常,自动调优实现包括Parameterization(参数化)、代价模型、搜索技术和加速四个关键部分。
Parameterization(参数化)
数据参数描述数据的规格,如输入的形状。目标参数描述在优化调度和代码生成期间要考虑的特定于硬件的特征和约束。例如,对于GPU目标,需要指定共享内存和寄存器大小等硬件参数。
优化选项包括优化调度和相应的参数,如面向循环的优化和瓷砖大小。在TVM中,既考虑了预定义调度,也考虑了自定义调度,还考虑了参数。
代价模型
自动调优中不同代价模型的比较如下:
-
黑箱模型:该模型只考虑最终的执行时间,而不考虑编译任务的特征。建立黑盒模型很容易,但是如果没有任务特性的指导,很容易导致更高的开销和更少的最优解。TC采用了这种模式。
-
基于ML的代价模型:基于ml的成本模型是一种使用机器学习方法预测性能的统计方法。它使模型能够随着新配置的探索而更新,这有助于实现更高的预测精度。TVM和XLA采用这种模型,分别是梯度树提升模型(GBDT)和前馈神经网络。
-
预定义代价模型:基于预定义代价模型的方法,期望根据编译任务的特点建立一个完美的模型,能够评估任务的整体性能。与基于ML的模型相比,预定义模型在应用时产生的计算开销更少,但需要在每个新的DL模型和硬件上重新构建模型,需要大量的工程工作。
相关文章:
【论文阅读】The Deep Learning Compiler: A Comprehensive Survey
论文来源:Li M , Liu Y , Liu X ,et al.The Deep Learning Compiler: A Comprehensive Survey[J]. 2020.DOI:10.1109/TPDS.2020.3030548. 这是一篇关于深度学习编译器的综述类文章。 什么是深度学习编译器 深度学习(Deep Learning)编译器将…...
怎么维护自己的电脑?
方向一:我的电脑介绍 我使用的是一台来自知名品牌的笔记本电脑。它具有高性能的核心配置,如快速处理器、大容量内存和高性能显卡,以及宽敞的存储空间。我选择这台电脑主要是因为它的出色性能和可靠性,能够满足我在学习和工作中的…...
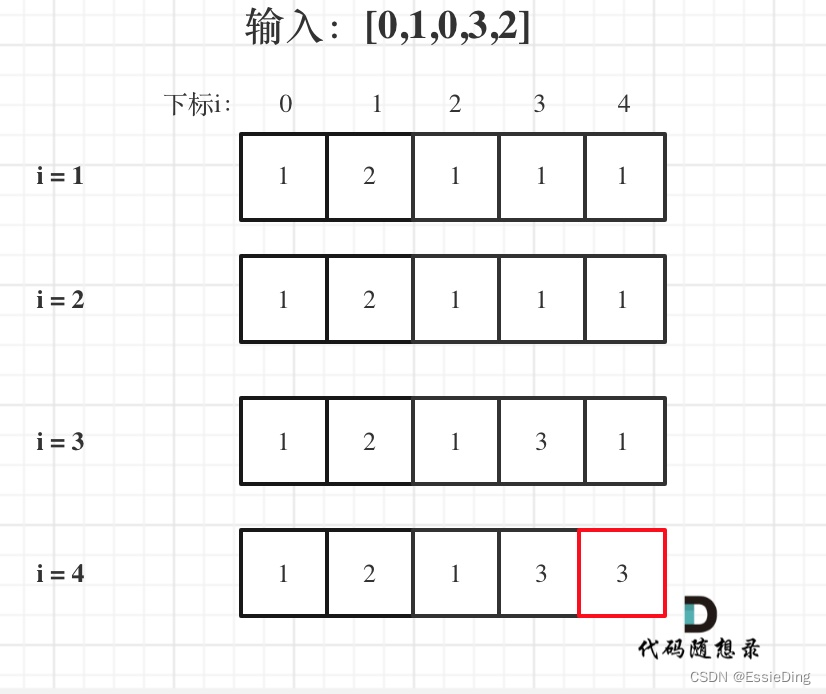
day52|● 300.最长递增子序列 ● 674. 最长连续递增序列 ● 718. 最长重复子数组
300.最长递增子序列 Input: nums [10,9,2,5,3,7,101,18] Output: 4 Explanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4. 这题看似简单,但感觉没想明白递增的判定(当前下标i的递增子序列长度,其实…...

uniapp,vue3路由传递接收参数
官网vue2升vue3的教程中,演示了如何使用onLoad,记得把官网所有内容都看一遍!!! 传递对象参数 uni.navigateTo({url: /pages/login/code/code?data JSON.stringify({limit: 6, iphone: loginForm.username, }), });…...
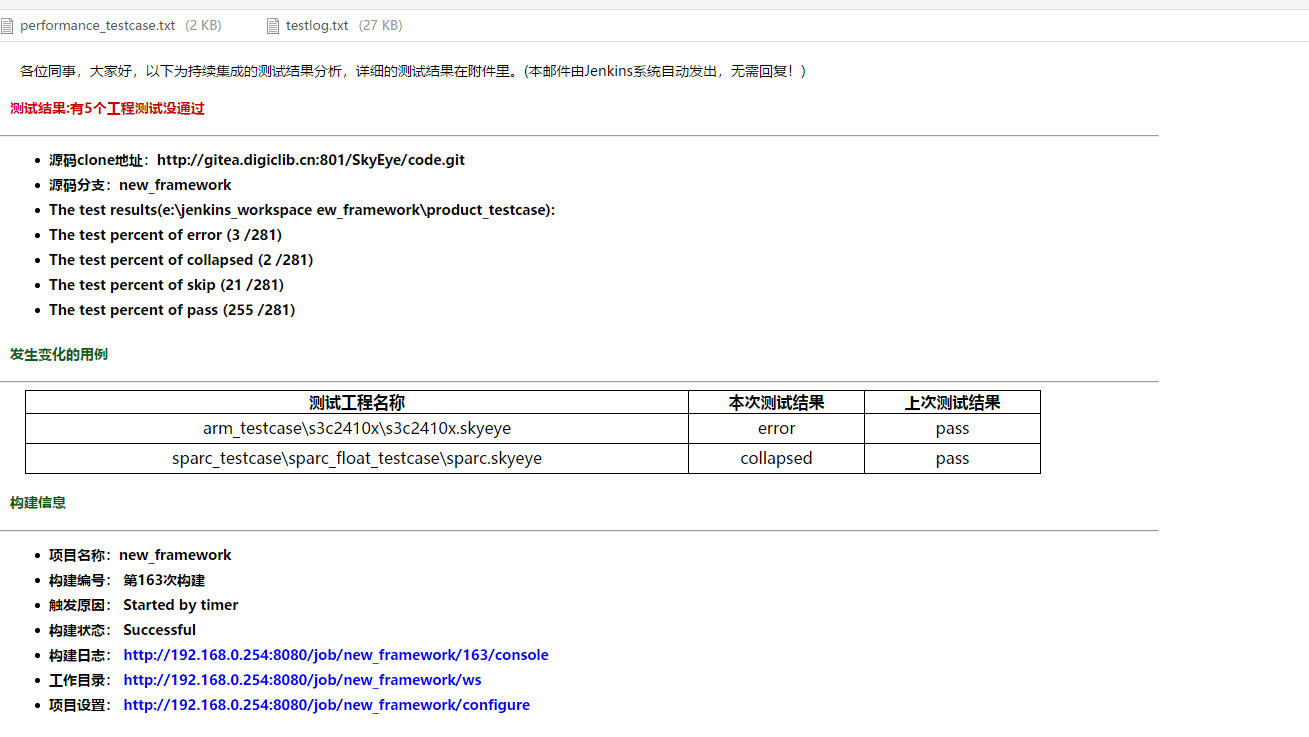
SkyEye与Jenkins的DevOps持续集成解决方案
在技术飞速发展的当下,随着各行各业的软件逻辑复杂程度提升带来的需求变更,传统测试已无法满足与之相对应的一系列测试任务,有必要引入一个自动化、可持续集成构建的DevOps平台来解决此类问题。本文将主要介绍SkyEye与Jenkins的持续集成解决方…...

HCIE Security——防火墙互联技术
目录 一、防火墙接口互联接口 1.防火墙支持的接口及板卡 2.物理链接线缆 3.支持接口种类 (1)物理接口 (2)逻辑接口 二、相关配置命令 1.配置三层接口IP地址 2.配置PPPOE拨号接口 3.配置VLANIF接口、子接口、回环接口 4…...

Rust- 闭包
A closure in Rust is an anonymous function you can save in a variable or pass as an argument to another function. You can create the closure using a lightweight syntax and access variables from the scope in which it’s defined. Here’s an example of a clo…...
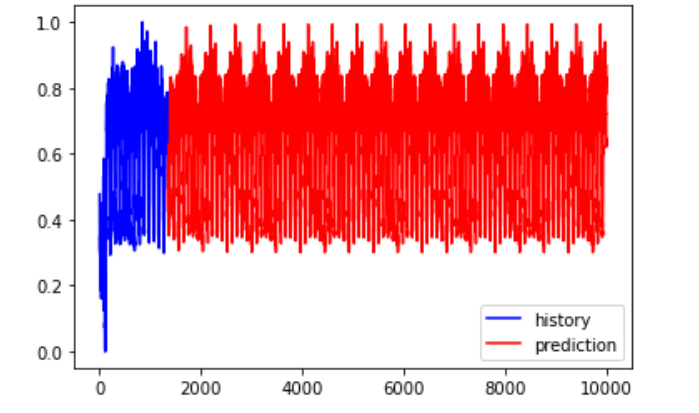
【数据挖掘torch】 基于LSTM电力系统负荷预测分析(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

「JVM」性能调优工具
「JVM」性能调优工具 一、jcmd1、jcmd 能干嘛?2、与JVM相关的命令3、示例 二、jmap1、jmap有什么用?2、jmap的命令大全3、示例 三、jps1、jps有什么用?2、jps命令以及示例 四、jstat1、jstat有什么用?2、jstat命令以及示例 五、js…...
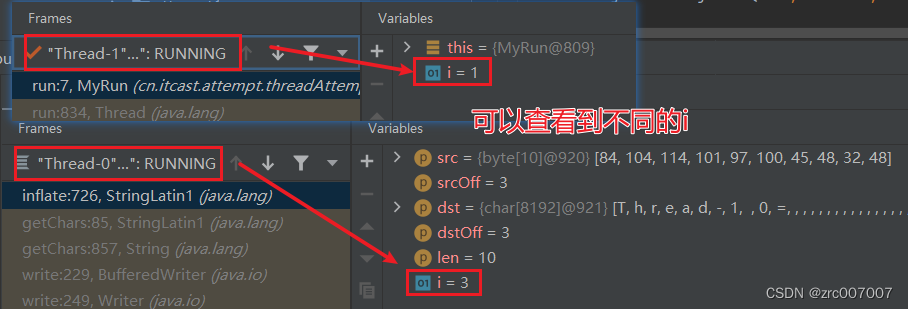
IDEA Debug小技巧 添加减少所查看变量、查看不同线程
问题 IDEA的Debug肯定都用过。它下面显示的变量,有什么门道?可以增加变量、查看线程吗? 答案是:可以。 演示代码 代码如下: package cn.itcast.attempt.threadAttempt.attempt2;public class Test {public static …...

基于SpringBoot+Vue的车辆充电桩管理系统设计与实现(源码+LW+部署文档等)
博主介绍: 大家好,我是一名在Java圈混迹十余年的程序员,精通Java编程语言,同时也熟练掌握微信小程序、Python和Android等技术,能够为大家提供全方位的技术支持和交流。 我擅长在JavaWeb、SSH、SSM、SpringBoot等框架…...

Bean的加载方式
目录 1. 基于XML配置文件 2. 基于XML注解方式声明bean 自定义bean 第三方bean 3.注解方式声明配置类 扩展1,FactoryBean 扩展2,加载配置类并加载配置文件(系统迁移) 扩展3,proxyBeanMethodstrue的使用 4. 使用Import注解导入要注入的bean…...
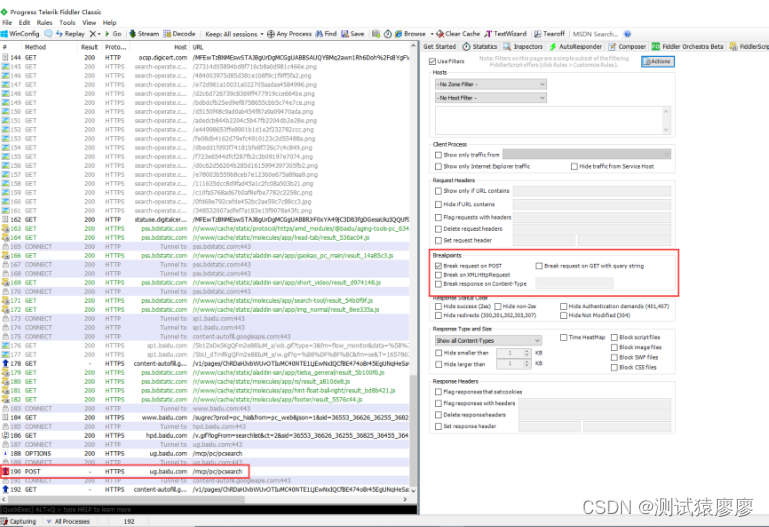
《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(13)-Fiddler请求和响应断点调试
1.简介 Fiddler有个强大的功能,可以修改发送到服务器的数据包,但是修改前需要拦截,即设置断点。设置断点后,开始拦截接下来所有网页,直到取消断点。这个功能可以在数据包发送之前,修改请求参数;…...
Android 13(T) - Media框架(1)- 总览
从事Android Media开发工作三年有余,刚从萌新变成菜鸟,一路上跌跌撞撞学习,看了很多零零碎碎的知识,为了加深对Android Media框架的理解,决定在这里记录下学习过程中想到的一些问题以及一些思考,也希望对初…...
+antdesignvue项目框架搭建基本步骤)
简述vue3(ts)+antdesignvue项目框架搭建基本步骤
目录 项目简介 概念 过程简述 基本步骤 1.创建新项目 2.安装Ant Design Vue 3.配置Ant Design Vue 4.创建页面和组件 5.使用组件 6.运行项目 项目简介 概念 Vue 3(使用TypeScript)和Ant Design Vue项目框架搭建是指在Vue 3框架下,…...

webpack : 无法加载文件 C:\Program Files\nodejs\webpack.ps1
webpack : 无法加载文件 C:\Program Files\nodejs\webpack.ps1 1.问题2. 解决办法: 1.问题 使用webpack打包是报错如下: webpack : 无法加载文件 C:\Program Files\nodejs\webpack.ps1,因为在此系统上禁止运行脚本。有关详细信息,…...
OGRLayer篇 代码示例)
GDAL OGR C++ API 学习之路 (5)OGRLayer篇 代码示例
GetStyleTable virtual OGRStyleTable *GetStyleTable () 返回图层样式表 返回: 指向不应由调用方修改或释放的样式表的指针 // 假设图层对象为 poLayer OGRStyleTable* poStyleTable poLayer->GetStyleTable(); if (poStyleTable ! nullptr) {// 处理样式表信息// ..…...

NIDEC COMPONENTS尼得科科宝滑动型DIP开关各系列介绍
今天AMEYA360对尼得科科宝电子滑动型DIP开关各系列参数进行详细介绍,方便大家选择适合自己的型号。 系列一、滑动型DIP开关 CVS 针脚数:1, 2, 3, 4, 8 安装类型:表面贴装,通孔 可水洗:无 端子类型:PC引脚(只…...
一起学算法(滑动窗口篇)
前言: 对于滑动窗口,有长度固定的窗口,也有长度可变的窗口,一般是基于数组进行求解,对于一个数组中两个相邻的窗口,势必会有一大部分重叠,这部分重叠的内容是不需要重复计算的,所以我…...

HTML <q> 标签
实例 标记短的引用: <q>Here is a short quotation here is a short quotation</q>浏览器支持 元素ChromeIEFirefoxSafariOpera<q>YesYesYesYesYes所有浏览器都支持 <q> 标签。 定义和用法 <q> 标签定义短的引用。 浏览器经常在引用的内容…...

创业公司如何利用 Taotoken 统一管理多个 AI 模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业公司如何利用 Taotoken 统一管理多个 AI 模型服务 对于资源有限的创业团队而言,快速验证产品想法、迭代功能是生存…...

爆仓价格系数推导
多仓 爆仓条件:账户权益 < 维持保证金 即: Equity Maintenance Margin对于一个仓位: 多仓 权益: 权益 初始权益 (当前价 - 开仓价) 数量因为: 价格上涨赚钱。 空仓 权益: 权益 初始权益 (开仓价 -…...

C++面试考点 头文件与实现文件形式
为什么C标准头文件没有所谓的.h后缀? 在一个源文件中,函数模板的声明与定义分离是可以的,即使把函数模板的实现放在调用 之下也是ok的,与普通函数一致。//函数模板的声明 template <class T> T add(T t1, T t2);…...
)
用随机森林实现手写英文字母识别(Python实战)
1. 项目概述:用随机森林搞定手写信件识别,这事儿比你想象中更接地气 “How To Perform Letter Recognition in Python Using Random Forest Classifier”——这个标题乍看像教科书里的章节名,但实际拆开来看,它直指一个非常具体、…...

从塑造品牌形象到沉淀行业公信力软文营销品效合一落地路径及平台选择技巧
当下企业软文营销已经告别只追求表面曝光的初级阶段,进入品牌背书流量曝光线索转化品效合一的成熟时代。单纯追求发稿数量、追求媒体覆盖面,无法为企业带来实际商业价值;只有打通内容传播、品牌信任、受众触达、咨询引流的完整链路,让软文既能塑造品牌形象、沉淀行业公信力,又能…...

YOLOv8 ROS 2深度解析:机器人视觉感知系统的架构设计与实践指南
YOLOv8 ROS 2深度解析:机器人视觉感知系统的架构设计与实践指南 【免费下载链接】yolov8_ros Ultralytics YOLOv8, YOLOv9, YOLOv10, YOLOv11, YOLOv12 for ROS 2 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_ros 在机器人技术快速发展的今天&#…...

如何永久保存微信聊天记录?5分钟掌握免费开源工具WeChatMsg
如何永久保存微信聊天记录?5分钟掌握免费开源工具WeChatMsg 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...
【简洁版】)
Java 高级特性高频面试题 30 道(含答案)【简洁版】
覆盖泛型、反射、注解、Lambda/Stream、函数式接口、动态代理、JDK8 新特性、线程池、JVM、IO/NIO、序列化等核心高频考点,适合中高级 Java 工程师面试。一、泛型(3 题)什么是 Java 泛型?泛型的作用是什么?答案&#…...

Veo生成模糊/断帧/色偏?立刻停用默认设置!20年视频架构师紧急发布的5项必改Veo 2K/4K硬核配置
更多请点击: https://intelliparadigm.com 第一章:Veo 2K/4K视频生成质量崩塌的根源诊断 当Veo模型在2K或4K分辨率下输出视频时,高频细节严重丢失、运动伪影显著增强、纹理结构模糊化,这一现象并非单纯算力不足所致,而…...
)
NotebookLM默认α=0.05合理吗?(基于127个真实知识图谱实验的P值稳健性评估报告)
更多请点击: https://codechina.net 第一章:NotebookLM默认α0.05合理吗?(基于127个真实知识图谱实验的P值稳健性评估报告) 在NotebookLM的知识图谱推理链中,显著性阈值α被硬编码为0.05,该设定…...