RocketMQ工作原理
文章目录
- 三.RocketMQ工作原理
- 1.消息的生产
- 消息的生产过程
- Queue选择算法
- 2.消息的存储
- 1.commitlog文件
- 目录与文件
- 消息单元
- 2.consumequeue
- 目录与文件
- 索引条目
- 3.对文件的读写
- 消息写入
- 消息拉取
- 性能提升
- 3.indexFile
- 1.索引条目结构
- 2.文件名的作用
- 3.查询流程
- 4.消息的消费
- 1.推拉消费类型
- 拉取式消费
- 推送式消费
- 对比
- 2.消费模式
- 广播消费
- 集群消费
- 消息进度保存
- 3.Rebalance机制
- 什么是Rebalance
- Rebalance限制
- Rebalance危害
- Rebalance产生的原因
- Rebalance过程
- 4.Queue分配算法
- 平均分配策略
- 环形分配策略
- 一致性hash策略
- 同机房策略
- 5.至少一次原则
- 5.订阅关系的一致性
- 1.正确订阅关系
- 2.错误订阅关系
- 6.offset管理
- 1.offset本地管理模式
- 2.offset远程消费模式
- 3.offset用途
- 4.重试队列
- 5.offset的同步提交和异步提交
- 7.消息幂等
- 1.什么是消息幂等
- 2.消息重复的场景分析
- 发送消息时重复
- 消费时消息重复
- Rebalance时消息重复
- 3.通用解决方案
- 两要素
- 解决方案
- 4.消息幂等的实现
- 8.消息堆积与消费延迟
- 1.概念
- 2.产生原因分析
- 拉取消息
- 消息消费
- 3.消费耗时
- 4.消费并发度
- 5.单机线程数计算
- 6.如何避免
- 梳理消息的消费耗时
- 设置消费并发度
- 9.消息的清理
三.RocketMQ工作原理
1.消息的生产
消息的生产过程
Producer可以将消息写入某Broker的某Queue中,其经历了如下过程:
- Producer发送消息之前,会先向NameServer发出获取
消息Topic的路由信息的请求 - NameServer返回该Topic的路由表及Broker列表
- Producer对消息做一些特殊处理,例如,消息本身超过4M,则会对其进行压缩
- Producer向选择的Queue所在的Broker发出RPC请求,将消息发送到选择出的Queue
路由表:实际是一个Map,key为topic名称,value是一个QueueData实例列表
QueueData:并不是一个Queue对应一个QueueData,而是一个Broker中该Topic的所有的Queue对应的数据
只要涉及到该Topic的Broker,一个Broker对应一个QueueData。
简单来说,路由表的key为topic,value为ListBroker列表:也是一个Map,key为brokerName,value为BrokerData。
一个Broker对应一个BrokerData实例,对吗?不对,主从的BrokerName是相同的,一套BrokerName相同的MS小集群对应一个BrokerData。BrokerData包含brokerName及一个map,map的key为brokerId,value为该broker对应的地址。
brokerId为0表示该broker为master,非0表示为slave
Queue选择算法
对于无序消息,其Queue选择算法,也称为消息投递算法,常见的有两种:
- 轮询算法:
默认选择算法。该算法保证了每个Queue中可以均匀的获取到消息
该算法存在一个问题:由于某些愿意你,在某些broker上的Queue可能投递延迟严重,从而导致Producer的缓存队列中出现较大的消息积压,影响消息的投递性能。
- 最小投递延迟算法
该算法会统计每次消息投递的时间延迟,然后根据统计出的结果将消息投递到时间延迟最小的Queue。如果延迟相同,则采用轮询算法投递。该算法可以有效提升消息的投递性能。
可能导致单个broker接受的消息很多,分配不均,导致消费者集群消费也不均匀,因为一个消费者组中的一个消费者消费一个Broker中的Queue
2.消息的存储
RocketMQ中的消息存储在本地文件系统中,这些相关文件默认在当前用户主目录下的store目录下。
- abort:该文件再Broker启动后会自动创建,正常关闭Broker,该文件会自动消失。若在没有启动Broker的情况下,发现这个文件是存在的,说明之前Broker是非正常关闭的。
- checkpoint: 其中存储着commitlog、consumequeue、index文件的最后刷盘时间戳
- commitlog: 其中存放着commitlog文件,而消息是写在commitlog文件中的
- config: 存放着Broker运行期间的一些配置数据
- consumequeue:其中存放着consumequeue文件,队列就存放在这个目录中
- index:其中存放着消息索引文件indexFile
- lock:运行期间使用到的全局资源锁
1.commitlog文件
目录与文件
- commitlog目录中存放着很多mappedFile文件,当前Broker中的所有消息都是落盘到这些mappedFile文件中的。mappedFile文件大小为1GB(小于等于1GB),文件名由20位十进制数构成,表示当前文件的第一条消息的起始位置偏移量
- 需要注意的是,一个Broker中仅包含一个commitlog目录,所有的mappedFile文件都是存放在该目录中的。即无论当前Broker中存放着多少个Topic的消息,这些消息都是被顺序写入到了mappedFile文件中的。也就是说,这些消息在Broker中存放时并没有被按照Topic进行分类存放。
- mappedFile和mappedFile之间的偏移量是关联的,比如第一个mappedFile的偏移量到了0.98G,来了一个0.03G的消息,只能放到下一个mappedFile,下一个mappedFile的起始偏移量为0.98G。文件名即其偏移量
第一个文件名一定是20位的0构成的。因为第一个文件的第一条消息的偏移量commitlog offset为0
当第一个文件放满时,会自动生成第二个文件继续存放消息,文件名为当前偏移量。假设第一个文件大小为1073741820(1G = 1073741820字节),第二个文件名就是00000000001073741820
以此类推,第n个文件名应该是前n-1个文件大小只和。
一个Broker中所有mappedFile文件的commitlog offset是连续的。
存储是顺序写入的,所以其访问效率高。无论是SSD磁盘还是SATA磁盘,通常情况下,顺序存取效率都高于随机读写。
消息单元
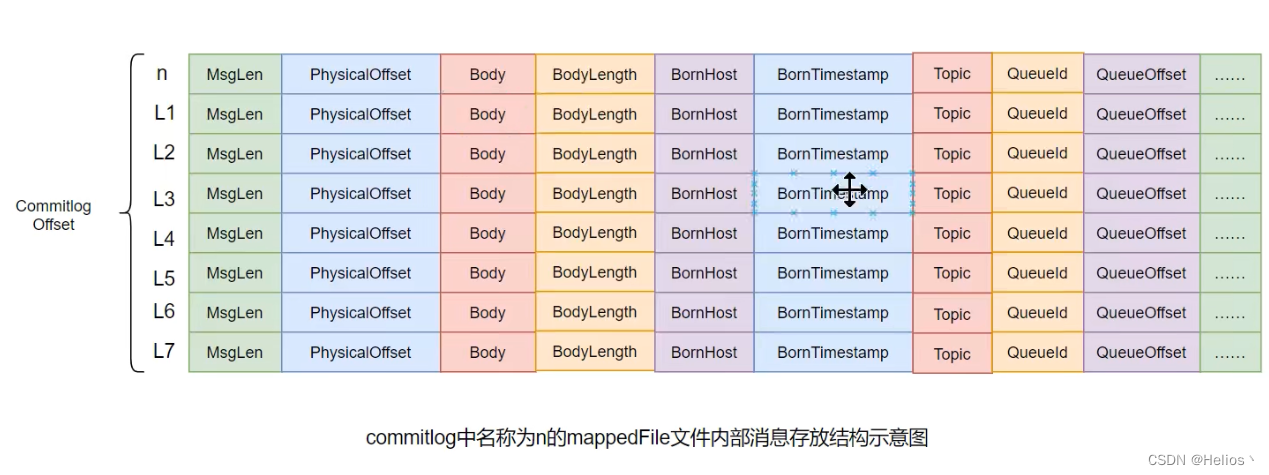
需要注意到,消息单元中是包含Queue相关属性的。所以我们就需要十分留意commitlog与Queue间的关系是什么?
1.我们注意到commitlog的名称为n,第一条消息的偏移量也为n
2.第n条消息的的偏移量为前m个消息的MsgLen之和
2.consumequeue
目录与文件
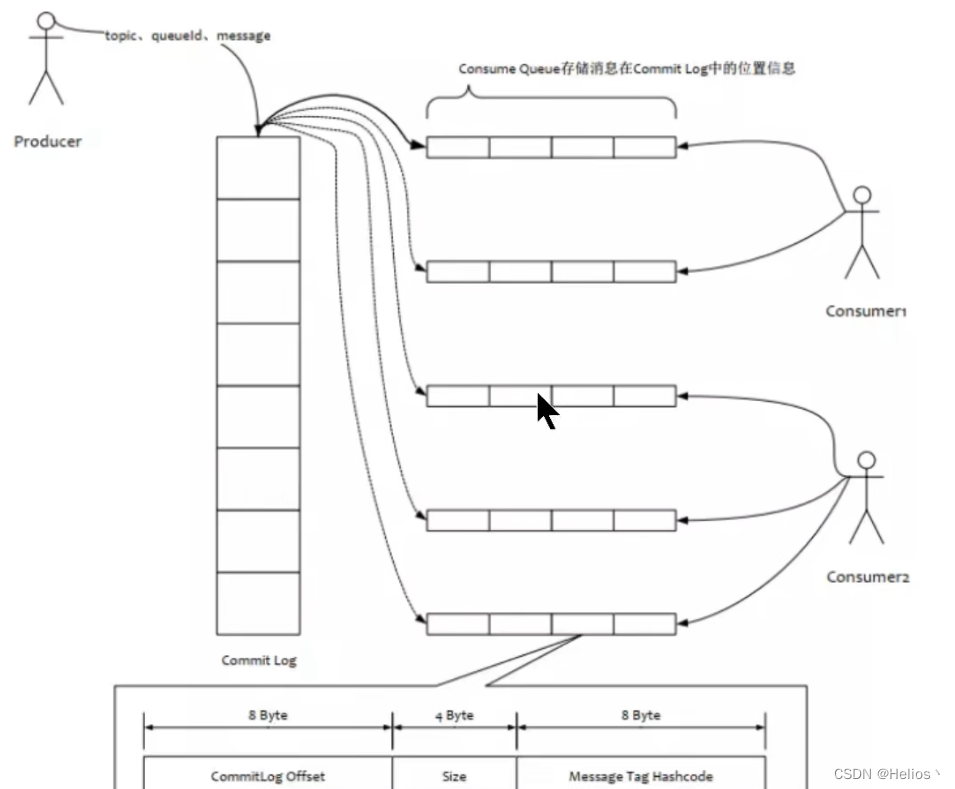
- 为了提高效率,会为每个Topic在store/consumequeue中创建一个目录,目录名为Topic名称。在该Topic目录下,会再为每个该Topic的Queue建立一个目录,目录名为queueId。每个目录中存放着若干Consumer文件,consumequeue文件是commitlog的索引文件,可以根据consumequeue定位到具体的消息。
- consumequque文件名也是由20位数字构成,表示当前文件的第一个索引条目的起始唯一偏移量。与mappedFile文件名不同的是,其后续文件名是固定的。因为consumequeue文件大小是固定不变的。
索引条目
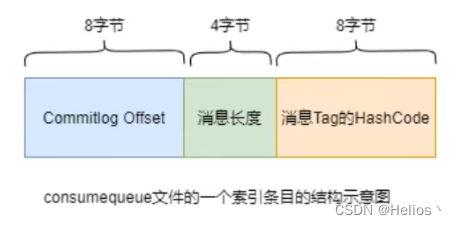
每个consumequeue文件可以包含30w个索引条目,每个索引包含三个消息的重要属性:在commitlog中的偏移量,消息长度MsgLen,消息Tag的hashCode。这三个属性占20个字节,所以每个文件的大小固定为30w * 20 字节
一个consumequeue文件中所有消息的Topic一定是相同的。但每条消息的Tag可能是不同的。
3.对文件的读写
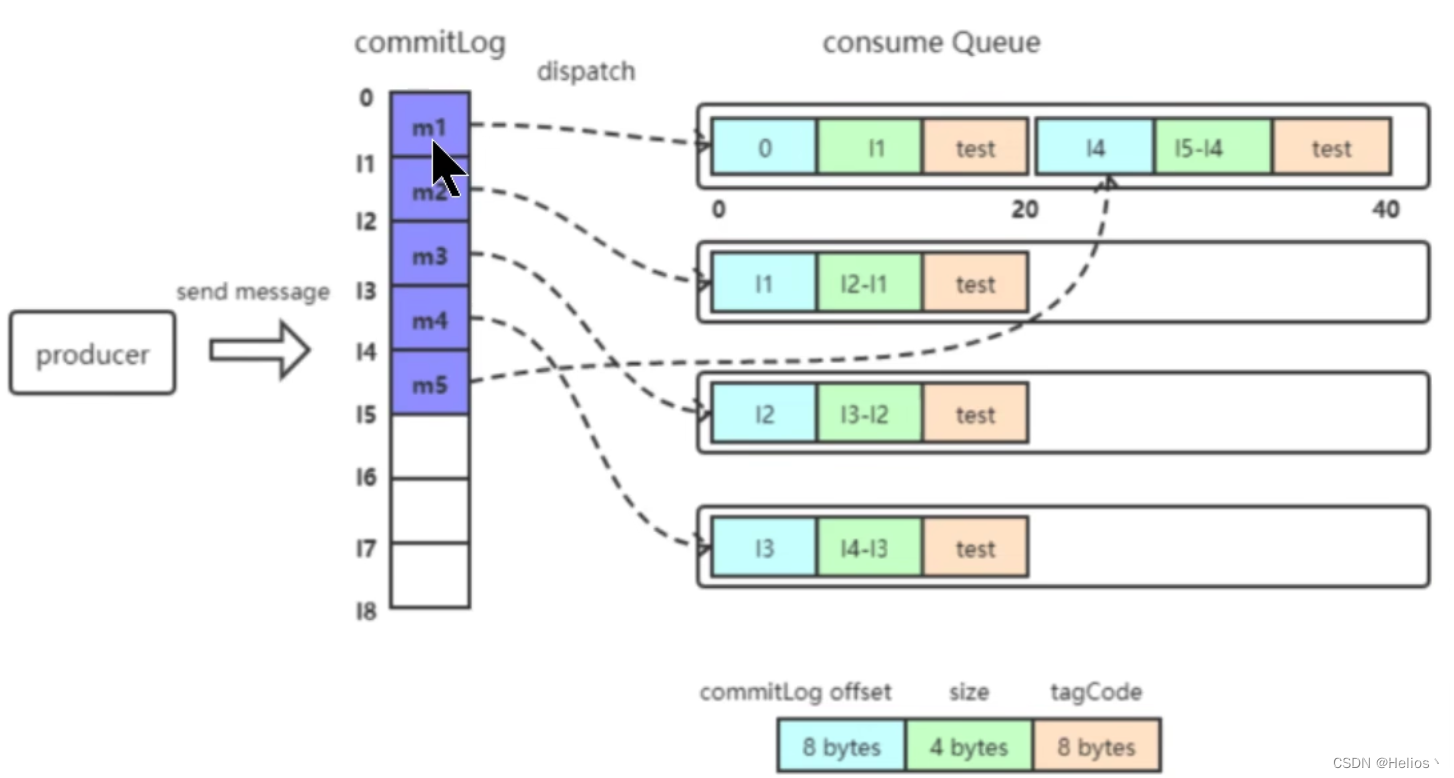
消息写入
一条消息进入到Broker后经历了一下几个过程才最终被持久化。
- Broker根据queueId,获取到该消息对应索引条目要在consumequeue目录中写入偏移量(有全局offset的),即QueueOffset
- 将QueueId、queueOffset等数据,与消息一起封装为消息单元
- 将消息单元写入到commitlog
- 形成消息索引条目
- 将消息索引目录分发到相应的consumequeue
消息拉取
- 当consumer拉取消息时会经历一下几个步骤:
- consumer要获取到其要消费消息所在queue的
消费偏移量offset,计算出其要消费消息的消息offset -
消费offset即消费进度,consumer对某个Queue的消费offset,即消费到了该Queue的第几条消息
- Consumer向Broker发送拉取请求,其中会包含其要拉取消息的Queue,消息offset即消息Tag
- Broker计算在该consumequeue中的queueOffset
-
queueOffset = 消息offset * 20字节
- 从该ququeOffset处开始向后向后查找第一个指定Tag的索引条目。
- 解析该索引条目的前8个字节,即可定位到该消息在commitlog中的commitlog offset
- 从对应commitlog offset中读取消息单元,并发送给Consumer
性能提升
RocketMQ中,无论消息本身还是消息索引,都是存储在磁盘上的。其不会影响消息的消费吗?当然不会。其实RocketMQ的性能在目前的MQ产品中还是非常高的。因为系统通过一系列相关机制大大提升了性能。
- 首先,RocketMQ对文件的对鞋操作都是通过
mmap零拷贝进行的,将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率。 - 其次,consumequeue中的数据是顺序存放的,还引入了PageCache的预读取机制,使得对consumequeue文件的读取几乎接近于内存读取,即使在有消息堆积情况下也不会影响性能。
- RocketMQ中可能会影响性能的是对commitlog文件的读取。因为对commitlog文件来说,读取消息时会产生大量的随机访问,而随机访问会严重影响性能。不过,如果合适的系统IO调度算法,比如设置调度算法为Deadline(采用SSD固态硬盘的话),随机读的性能也会有所提升。
腾讯工程技术有一篇Linux 零拷贝的文章,可以看下
3.indexFile
除了通过的指定Topic进行消费外,RocketMQ还提供了根据key进行消息查询的功能。该查询时通过store目录中index子目录中的indexFile进行索引实现的快速查询。当然,这个indexFile中的索引数据是在包含了key的消息被发送到Broker时写入的。如果消息中没有key,就不会被写入。
1.索引条目结构
-
每个Broker中包含一组indexFile,每个indexFile都是以一个
时间戳命名的(这个indexFile被创建时的时间戳)。每个indexFile分三部分:indexHeader、slots槽位、indexes索引数据。每个indexFile文件中包含500w个slot槽。而每个slot槽又可能会挂载很多的index索引单元。
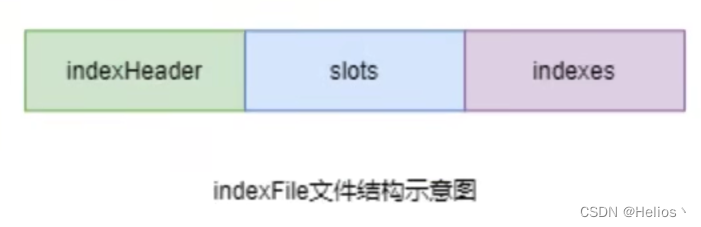
-
indexHeader固定40个字节,其中存放着如下数据:
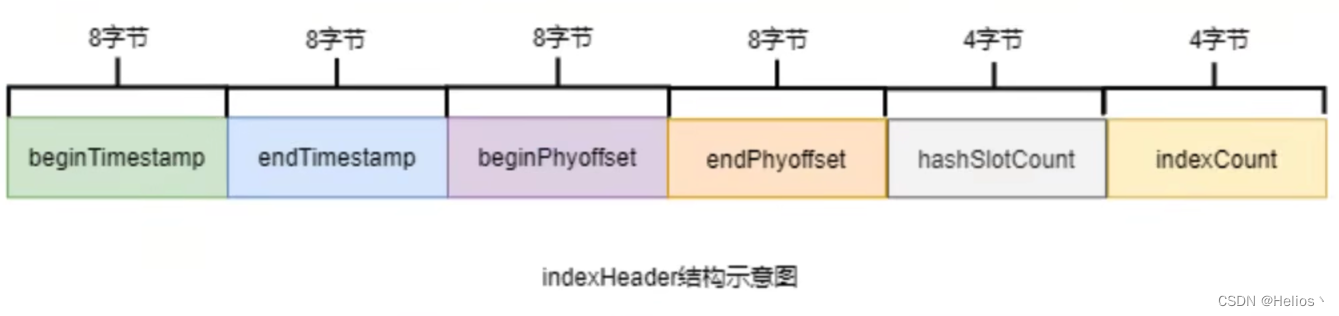
beginTimestamp: 该indexFile中第一条消息的存储时间
endTimestamp: 该indexFile中最后一条消息的存储时间
beginPhyoffset:该indexFile中第一条消息在commitlog中的偏移量
endPhyoffset: 该indexFile中最后一条消息在commitlog中的偏移量
hashSlotCount: 已经填充有index的slot数量(并不是每个slot槽下都挂载有index索引单元)
indexCount: 该indexFile中包含的索引个数(统计所有slot槽下的所有index索引个数之和)
-
index中最复杂的是Slots和Indexes间的关系。在实际存储时,Indexes是在整体Slots后面的,即Slots有指定大小。但为了便于理解,将他们的关系展示为如下形式:
-
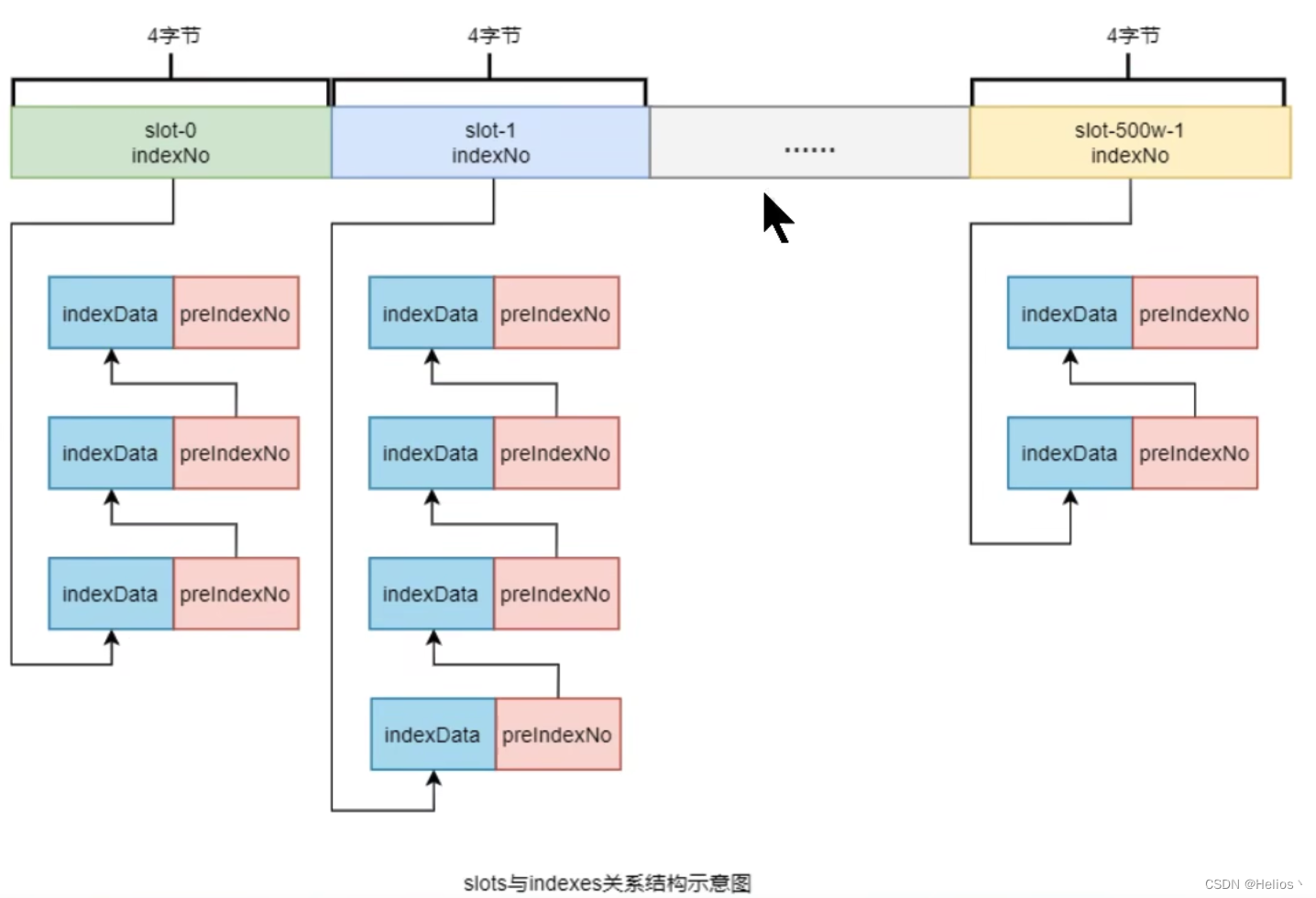
-
key的hash值 % 500w的结果即为slot槽位,然后将该slot值修改为该index索引单元的indexNo,根据这个indexNo,根据这个indexNo可以计算出该index单元在indexFile中的位置。不过,该取模结果的重复率是很高的,为了解决该问题,每个index索引单元中增加了preIndexNo,用于指定该slot中当前index索引单元的前一个index索引单元。而slot中始终存放的是其下最新的索引单元的indexNo,这样的话,只要找到了slot就可以找到其最新的index索引单元,而通过这个index索引单元就可以找到其之前的所有index索引单元。
indexNo是一个在indexFile中的流水号,从0开始依次递增。即在一个indexFile中,所有indexNo是依次递增的。indexNo在index索引单元中是没有体现出来的,其是通过indexes依次数出来的
- index索引单元默认20个字节,其中存放着以下四个属性:
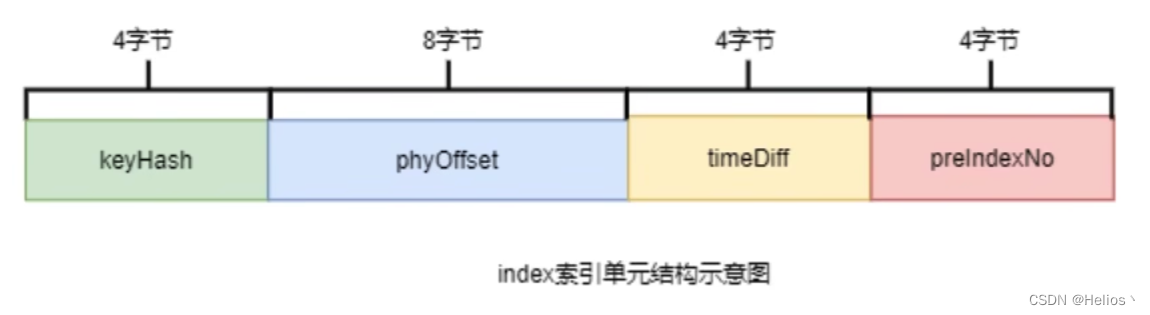
keyHash: 消息中指定的业务key的hash值
phyOffset: 当前key对应的消息在commitlog中的偏移量commitlog offset
timeDiff:当前key对应消息的存储时间与当前indexFile创建的时间差(第一个key消息时间)
preIndexNo:当前slot下当前index索引单元的前一个index索引单元的indexNo
2.文件名的作用
indexFile的文件名为当前文件被创建时的时间戳,这个时间戳有什么用处呢?
根据业务key进行查询时,查询条件除了key之外,还需要指定一个要查询的时间戳,表示要查询不大于改时间戳的最新的消息,即查询指定时间戳之前存储的最新消息。这个时间戳文件名可以简化查询,提高查询效率。具体后面会详细讲解。
indexFile是何时创建的?其创建的条件(时机)有两个:
- 当第一条带key的消息发送来后,系统发现没有ndexFile,此时会创建第一个indexFile
- 当一个indexFile中挂载的index索引单元个数超过2000w个时,会创建新的indexFile。当带key的消息发送到来后,系统会找到最新的indexfile, 并从起indexHeader的最后4字节读取到indexCount。若indexCount > 2000w时,会创建新的indexFile
- 由此可知,一个indexFile的最大大小是:40 + 500w * 4 + 2000w * 20 字节
3.查询流程
当消费者通过业务key来查询相应的消息时,其需要经过一个相对较复杂的查询流程。不过,在分析查询流程之前,首先要清楚几个定位计算式子:
- 计算指定消息key的slot槽位序号: slot槽位序号 = key的hash % 500w
- 计算槽位序号为n的slot在indexFile中的起始位置: slot(n)位置 = 40 + (n - 1) * 4
- 计算indexNo为m的index在indexFile中的位置:index(m)位置 = 40 + 500w * 4 + (m - 1) * 20
1.输入业务key与要查询的时间,开始查询
2.根据传入的时间找到相应的indexFile
3.计算出传入时间与indexFile文件名的差值diff
4.计算出业务key的hash值
5.计算出slot槽位序号n
6.根据slot槽位序号计算出该slot在indexFile中的位置
7.找到slot后读取slot值,即当前slot中最新的index索引单元的indexNo
8.根据indexNo计算出该index单元在indexFile的位置
9.计算出的时间差diff - 当前index单元中的timeDiff
10.如果结果 >= 0 且 key的hash值一致,读取该index单元的phyOffset,定位到相应的消息
11.如果结果 < 0,读取该index单元的preIndexNo,作为要查找的下一个index索引单元的indexNo,回到步骤8
- 也就是说,只取小于指定时间的一条数据
4.消息的消费
消费者从Broker中获取消息的方式有两种:pull拉取和push推动.消费者组对于消息消费的模式又分为两种:集群消费clustering和广播消费Broadcasting
1.推拉消费类型
拉取式消费
Consumer主动从Broker中拉取消息,主动权由Consumer控制.一旦获取了批量消息,就会启动消费过程.不过,该方式的实时性较弱,即Broker中有了新消息时消费者并不能及时发现.
用户自己指定拉取时间间隔,拉取时间间隔较长,可能拉取到的消息较多,实时性也较差.拉取时间间隔太短,空请求比例增加
推送式消费
该模式下Broker收到数据后会主动推送给Consumer.该消费模式一般实时性较高.
该消费类型是典型的发布-订阅模式,即Consumer向其关联的Queue注册了监听器,一旦发现有新的消息到来会就触发回调的执行,回调方法是Consumer去Queue中拉取消息.而这些都是基于Consumer与Broker间的长连接.长连接的维护是需要消耗系统资源的.
对比
- pull: 需要应用去实现对关联Queue的遍历,实时性差;但便于应用控制消息的拉取.
- push: 封装了对关联Queue的遍历,实时性强,但会占用较多的系统资源.
2.消费模式
广播消费
广播消费模式下,相同Consumer Group的每个Consumer实例都接收同一个Topic的全量消息.即每条消息都会被发送到Consumer Group中的每个Consumer.
集群消费
集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊同一个Topic的消息.即每条消息只会被发送到Consumer Group中的某个Consumer.
消息进度保存
- 广播模式: 消费进度保存在consumer端.因为广播模式下consumer group中的每个consumer都会消费所有消息,但他们的消费进度是不同的.所以consumer各自保存各自的消费进度.
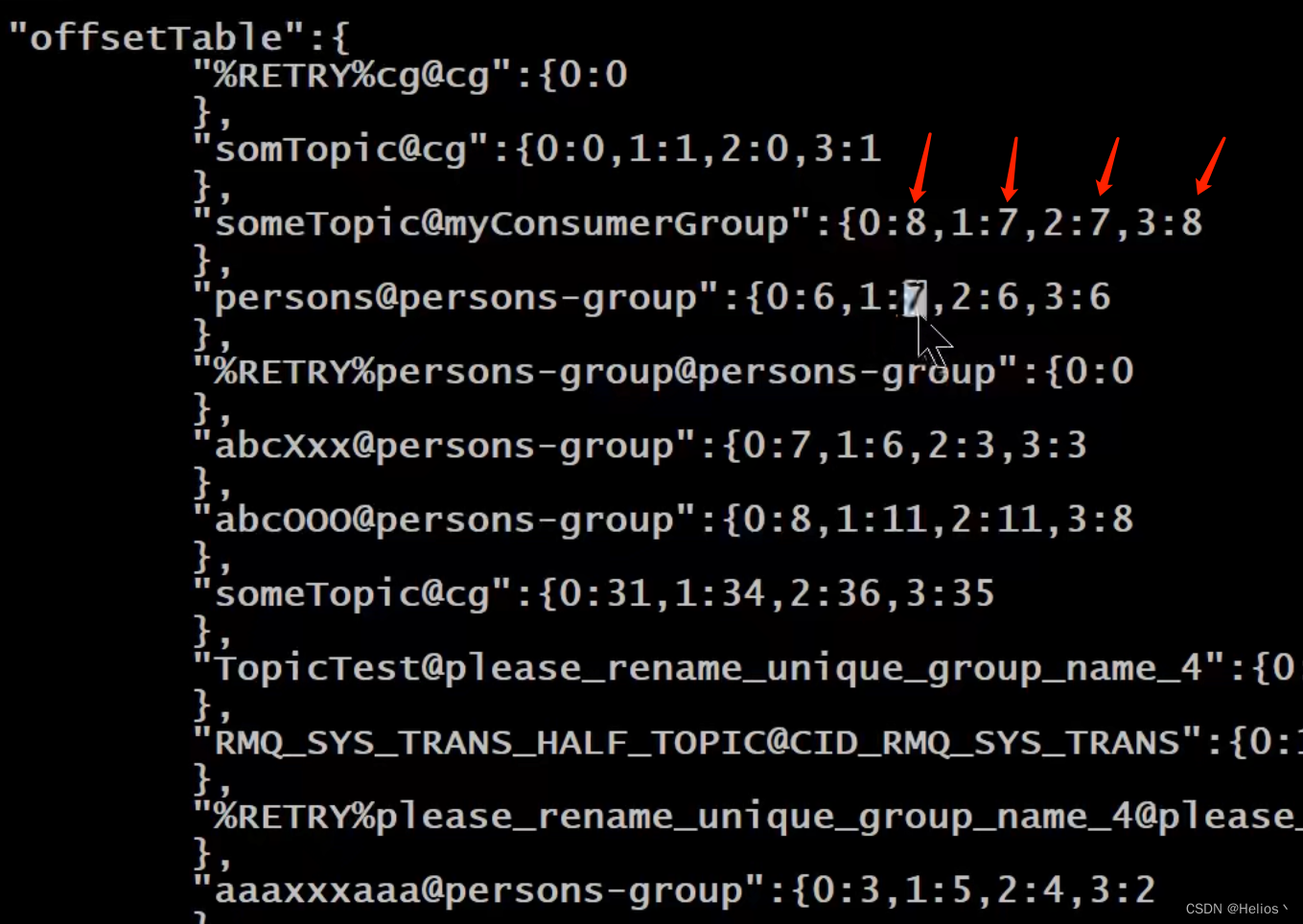
- 集群模式: 消费进度保存在broker中.consumer group中的所有consumer共同消费同一个Topic中的消息,同一条消息只会被消费一次.消费进度参与到了消费的负载均衡中,故消费进度是需要共享的.
broker中的消费进度: 在consumeroffset.json文件中的queueId的消费进度+1,如下图中,queueId为0的queue消费进度为8
3.Rebalance机制
Rebalance讨论的前提是:集群消费,广播消费没有这个问题
什么是Rebalance
Rebalance即再均衡,指的是,将一个Topic下的多个Queue在同一个Consumer Group中的多个Consumer间进行重新分配的过程
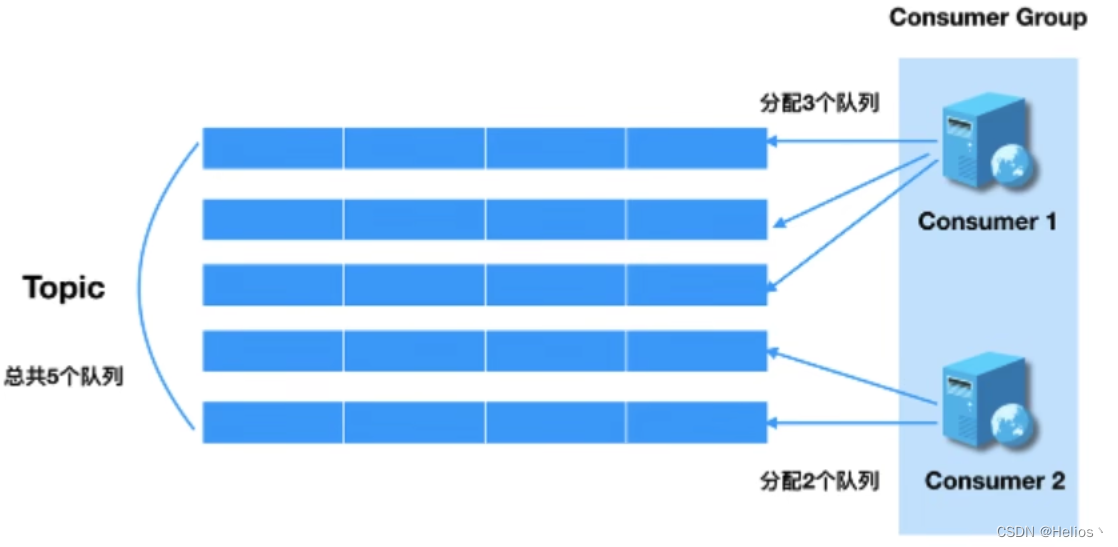
Rebalance机制本意是为了提升消息的并行消费能力.例如,一个Topic下有5个队列,在只有一个消费者的情况下,这个消费者将负责这5个队列的消息.如果此时我们增加一个消费者,那么就可以给其中一个消费者分配2个队列,给另一个分配3个队列,从而提升消息的并行消费能力.
Rebalance限制
由于一个队列最多分配给一个消费者,一个消费者组中消费者实例数量大于队列数量,多余的消费者将分配不到任何队列.
Rebalance危害
- 消费暂停: 在只有一个Consumer时,其负责消费的所有队列;在新增了Consumer后会触发Rebalance的发生.此时原Consumer就需要暂停部分队列的消费,等到这些队列分配给新的Consumer后,这些暂停的队列才能继续被消费.
- 消费重复: Consumer在消费新分配给自己的队列时,必须接着之前Consumer提交的消费进度的offset继续消费.然而默认情况下,offset是异步提交的,这个异步性提交给Broker的offset与Consumer实际消费的消息并不一致.这个不一致的差值就是可能会重复消费的消息.
同步提交: consumer提交了其消费完毕的一批消息的offset给broker后,需要等待broker的成功ACK.当收到ACK后,consumer
才能继续获取并消费下一批消息.在等待ACK期间,consumer是阻塞的.
异步提交: consumer提交了其消费完毕的一批消息的offset给broker后, 不需要等待broker的成功ACK.consumer可以直接获取并消费下一批消息.比如consumerA实际消费到800了,broker中的offset还是500,那么Rebalance后,consumerB从500开始消费,500-800之间就属于重复消费了.
对于一次性读取消息的数量,需要根据业务场景选择一个相对均衡的是很有必要的.因为数量过大,系统性能提升了,但产生重复消费的消息数量可能会增加;数量过小,系统性能下降,但被重复消费的消息数量可能减少.
- 消费突刺: 由于Rebalance可能导致重复消费,如果需要重复消费的消息过多,或者因为Rebalance暂停时间过长从而导致积压了部分消息.那么有可能会导致Rebalance结束后瞬间需要消费很多消息.
Rebalance产生的原因
导致Rebalance产生的原因,无非是两个:
- 消费者所订阅的Queue数量发生变化
- 消费者组中消费者数量发生变化
1.具体到生产环境下,Queue数量发生变化的场景:
Broker扩容或缩容
Broker升级运维
Broker与NameServer间的网络异常
Queue扩容或缩容
2.消费者数量发生变化的场景:
Consumer Group扩容或缩容
Consumer升级运维
Consumer 与 NameServer间网络异常
Rebalance过程
在Broker中维护着多个Map集合,这些集合中动态存放着当前Topic中Queue的信息,Consumer Group中Consumer实例的信息.一旦发现消费者所订阅的Queue数量发生变化,或者消费者组中消费者的数量发生变化,立即向Consumer Group中的每个实例发出Rebalance通知.
TopicConfigManager: key是topic名称,value是TopicConfig.TopicConfig中维护着该Topic中所有Queue的数据.
ConsumerManager: key是ConsumerGroupId,value为ConsumserGroupInfo.ConsumerConfigInfo维护着该Group中所有Consumer实例数据.
ConsumerOffsetManager: key为Topic与Consumer Group的组合, value为一个内层Map,内存Map的key为QueueId, 内层Map的value为该Queue的消费进度offset. 详细见Broker的store/config/consumerOffset.json
Consumer实例在接收到通知后会采用Queue分配算法自己获取到相应的Queue,即由Consumer实例自主进行Rebalance.
4.Queue分配算法
一个Topic的Queue只能由ConsumerGroup中的一个Consumer消费,而一个Consumer可以同时消费多个Queue中的消息.那么Queue与Consumer间的配对关系是如何确定的,即Queue要分配给哪个Consumer进行消费,也是有算法策略的.常见的有四种策略.这些策略是通过在创建Consumer时的构造器传进去的.
平均分配策略
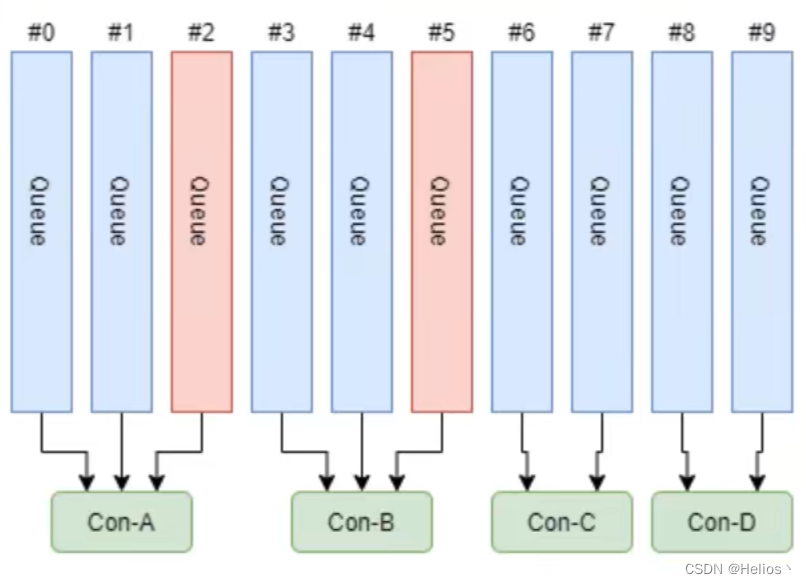
该算法是要根据avg = QueueCount / ConsumerCount的计算结果进行分配的.如果能够整除,则按顺序将avg个Queue逐个分配Consumer;如果不能整除,则将多余的Queue按照Consumer顺序逐个分配.
先计算每个Consumer分配的数量,再进行分配,即ConsumerA消费Queue1,Queue2,ConsumerB消费Queue3,Queue4,ConsumerC消费Queue5…
环形分配策略
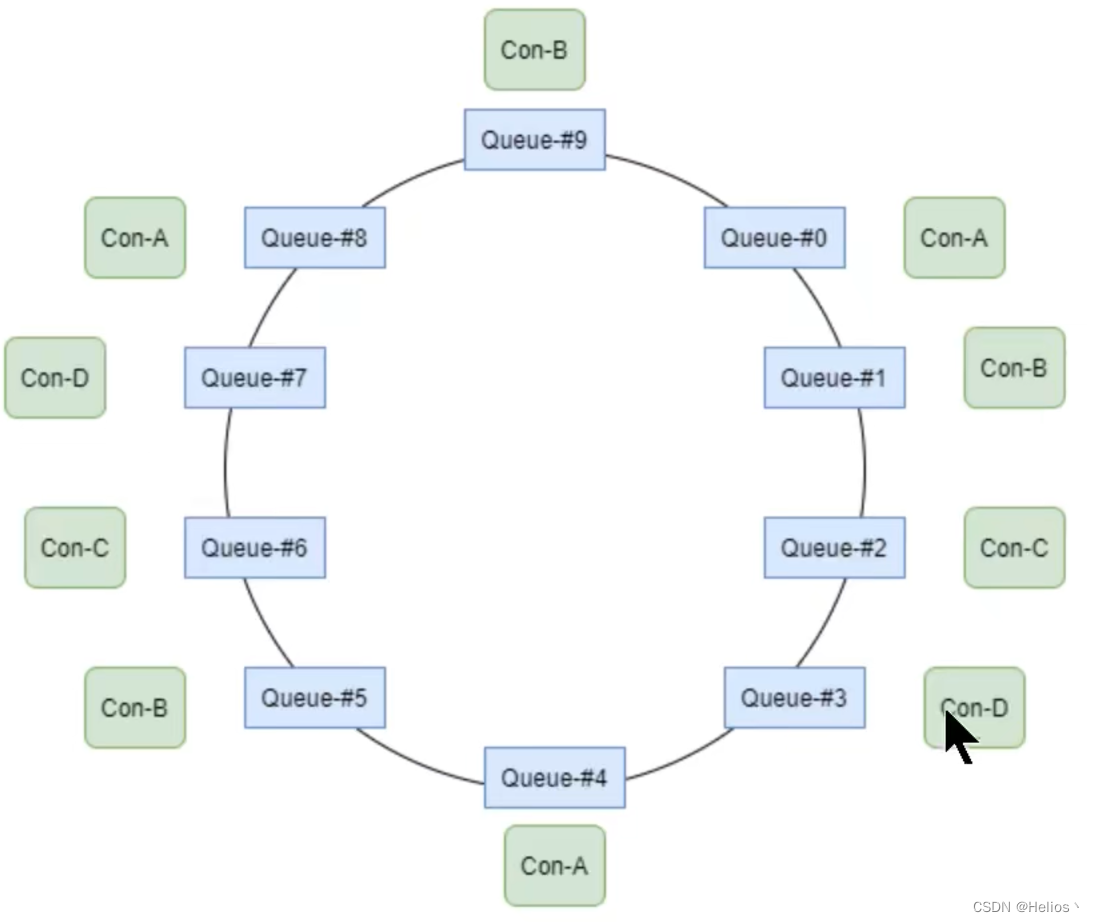
环形平均算法指按照消费者的顺序,依次由Queue队列组成的环形图中逐个分配
一致性hash策略
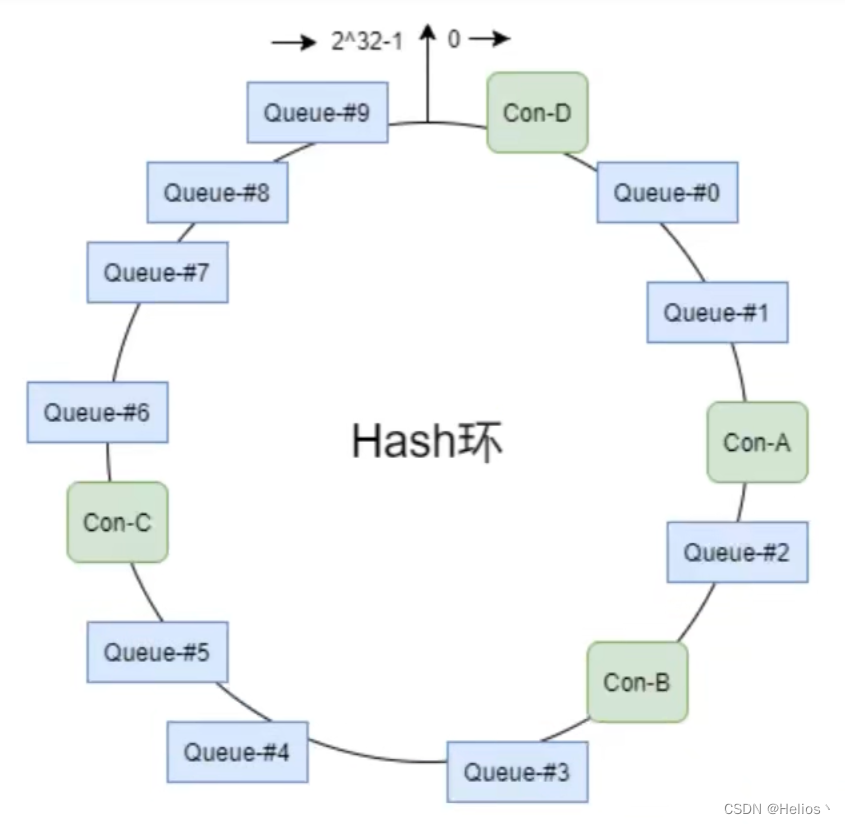
该算法会将Consumer的hash值作为Node节点放到hash环上,然后将Queue的hash值也放到hash环上,通过顺时针方向,距离queue最近的那个Consumer就是该Queue要分配的consumer.
该算法存在的问题:分配不均.
优点: 可以有效减少由于消费者组扩容或缩容带来的大量的Rebalance.
同机房策略
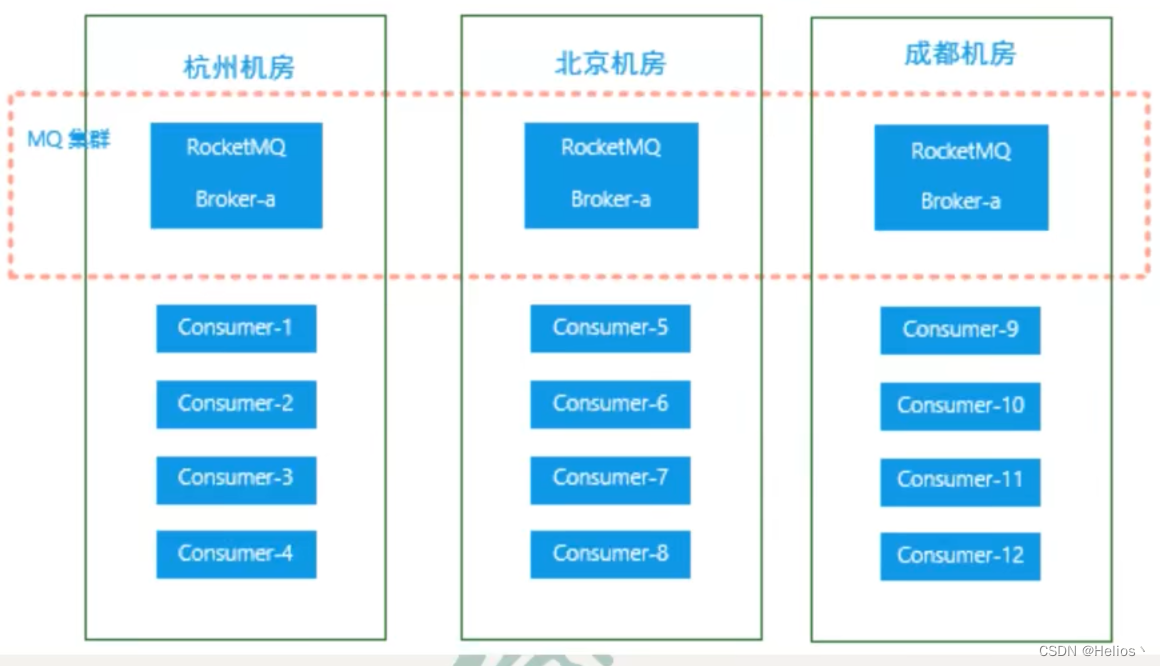
该算法会根据queue的部署机房位置和Consumer的位置,过滤出当前consumer相同机房的queue.然后按照平均分配策略或环形平均策略对同机房queue进行匹配.如果没有同机房queue,则按照平均分配策略或环形平均策略对所有queue进行匹配.
5.至少一次原则
RocketMQ有一个原则:每条消息必须要被成功消费一次.
那什么是成功消费呢?Consumer在消费完消息后会向其消费进度记录器提交其消费消息的offset,offset被成功记录到记录器中,那么这条消费就被成功消费了.
什么是消费进度记录器?
对于广播消费模式来说,Consumer本身就是消费进度记录器.
对于集群消费模式来说,Broker是消费进度记录器.
5.订阅关系的一致性
订阅关系的一致性指的是,同一个消费者组(GroupID相同)下所有Consumer实例所订阅的Topic下的Consumer实例所订阅的Topic与Tag的处理逻辑必须完全一致.否则,消息消费的逻辑就会混乱,甚至导致消息丢失.
1.正确订阅关系
多个消费者组订阅了多个Topic,并且每个消费者组里的多个消费者实例的订阅关系保持了一致.
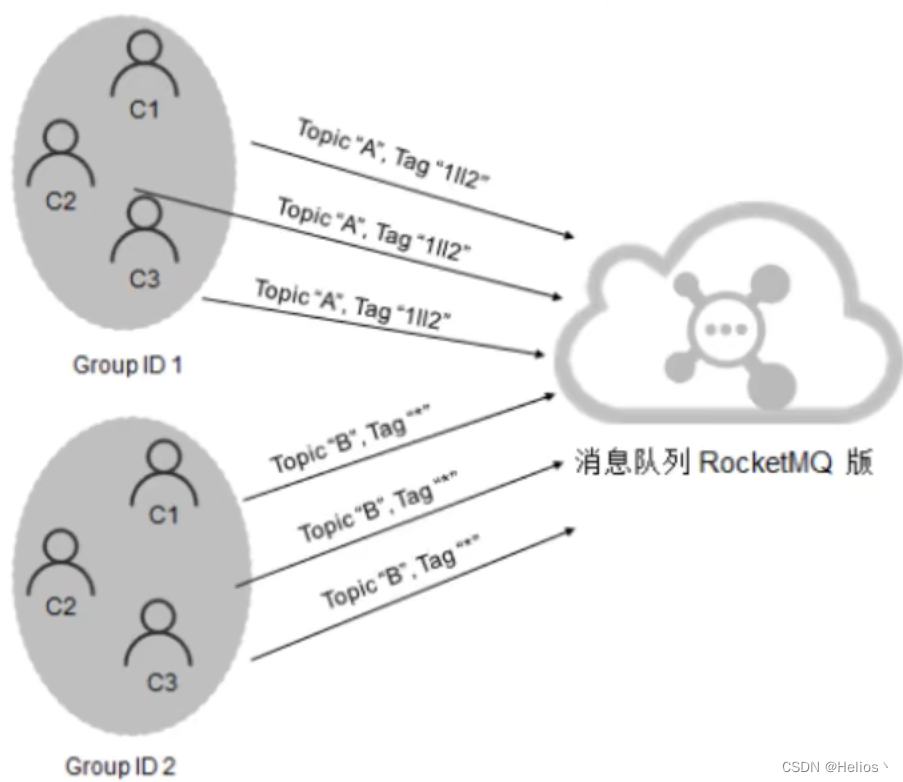
2.错误订阅关系
订阅了不同Topic
订阅了不同Tag
订阅了不同数量的Topic
6.offset管理
这里的offset指的是Consumer的消费进度offset.
消费进度offset是用来记录每个Queue的不同消费组的消费进度的.
根据消费进度记录器的不同,可以分为两种模式:本地模式和远程模式
1.offset本地管理模式
当消费模式为广播消费时,offset使用本地模式存储.因为每条消息会被所有的消费者消费,每个消费者管理自己的进度,各个消费者之间不存在消费进度的交集.
Consumer在广播消费模式下offset相关数据以json的形式持久化到Consumer本地磁盘文件中,文件路径为当前用户主目录下的.rocketmq_offsets/ c l i e n t I d / g r o u p / o f f s e t s . j s o n . 其中 {clientId}/group/offsets.json.其中 clientId/group/offsets.json.其中{clientId}为当前消费者id,默认为ip@DEFAULT;group为消费者组名称.
2.offset远程消费模式
当消费模式为集群消费时,offset使用远程模式管理.因为所有Consumer实例对消息采用的是均衡消费,所有Consumer共享Queue的消费进度.
Consumer在集群消费模式下,offset相关数据以json形式存储在Broker所在磁盘文件中,文件路径为当前用户主目录下的:store/config/consumerOffset.json
Broker启动时会加载这个文件,并写入到一个双层Map,即ConsumerOffsetManager, 前面提到过.
3.offset用途
这里有个问题: 消费者是如何知道其要消费哪个消息的,即消费者是如何知道其要消费消息在Queue中的偏移量offset的?其实消费者的第一条消息是通过consumer.setConsumeFromWhere()方法指定起始位置的.
在消费者启动后,其要消费的第一条消息的起始位置常用的有三种,这三种位置可以通过枚举类型常量设置.这个枚举类型为ConsumeFromWhere

CONSUME_FROM_LAST_OFFSET: 从queue的当前最后一条消息开始消费
CONSUME_FROM_FIRST_OFFSET: 从queue的第一条消息开始消费
CONSUME_FROM_TIMESTAMP: 从指定的具体时间戳位置的消息开始消费.
- 这个具体时间戳是通过另外一个语句指定的:consumer.setConsumeTimestamp(“202301010800”)来指定年月日时分
当消费完一批消息后,Consumer会提交其消费进度offset给Broker,Broker在收到消费进度后会将其更新到那个双层Map即consumerOffset.json文件中,然后向该Consumer进行ACK,而
ACK内容包含三项数据:
minOffset, maxOffset, 以及下次消费的起始offset(nextBeginOffset)
4.重试队列
当RocketMQ队消息的消费出现异常时,会将发生异常的消息的offset提交到Broker的重试队列.系统在发生消息消费异常时会为当前的Topic创建一个重试队列,该队列以%RETRY%TopicName@groupName命名(同样可以在consumerOffset.json文件中看到),到达重试时间后进行消费重试.
5.offset的同步提交和异步提交
集群模式下,Consumer消费完消息后会向Broker提交消费进度offset,其提交方式分为两种.
同步提交: consumer提交了其消费完毕的一批消息的offset给broker后,需要等待broker的成功ACK.当收到ACK后,consumer
才能继续获取并消费下一批消息.在等待ACK期间,consumer是阻塞的.其严重影响了消费者的吞吐量.异步提交: consumer提交了其消费完毕的一批消息的offset给broker后, 不需要等待broker的成功ACK.consumer可以直接获取并消费下一批消息.比如consumerA实际消费到800了,broker中的offset还是500,那么Rebalance.增加了消费者的吞吐量.但是需要注意,broker收到提交的offset后,还是会向消费者进行响应的,只是不影响consumer继续消费, consumer会从Broker中直接获取nextBeginOffset.
7.消息幂等
1.什么是消息幂等
当出现消费者对某条消息重复消费的情况时,重复消费的结果与第一个次消费的结果是相同的,并且多次消费并未对业务系统产生任何负面影响,那么这个消费过程就是消费幂等的.
在互联网应用中,尤其是网络不稳定的情况下,消息很有可能会出现重复发送或重复消费.如果重复的消息可能影响业务处理,那么就应该对消息做幂等处理.
2.消息重复的场景分析
什么情况下可能会出现消息被重复消费呢?最常见的有以下三种情况:
发送消息时重复
当一条消息已被成功发送到Broker并完成持久化,此时出现了网络闪断,从而导致Broker对Producer应答失败.此时如果Producer意识到消息发送失败并尝试再次发送消息,此时Broker中就可能会出现两条内容相同并且MessageID也相同的消息,那么后续Consumer就一定会消费两次该消息.
消费时消息重复
消息已投递到Consumer并完成业务处理,当Consumer给Broker反馈应答时网络闪断,Broker没有接收到消费成功响应.为了保证消息至少被消费一次的原则,Broker将在网络恢复后再次尝试投递之前已被处理过的消息.此时消费者就会收到与之前处理过的内容相同,MessageID也想通的消息.
Rebalance时消息重复
当Consumer Group中的Consumer数量发生变化时,或其订阅的Topic的Queue数量发生变化时,会触发Rebalance,此时Consumer可能会收到曾经被消费过的消息.
3.通用解决方案
两要素
幂等解决方案的设计中涉及到两项要素:幂等令牌,与唯一性处理.只要充分利用好两要素,就可以设计出好的幂等解决方案.
- 幂等令牌: 是生产者和消费者两者中的既定协议,通常指具备唯一业务标识的字符串.例如:订单号
- 唯一性: 服务端通过采用一定的算法策略,保证同一个业务不会被重复执行成功多次.例如:订单号查询后确认可以消费再消费.
解决方案
对于常见的系统,幂等性操作的通用性解决方案是:
1.首先通过缓存去重.在缓存中如果已经存在了某幂等令牌,则说明本次操作是重复性操作;若缓存没有命中,则进入下一步.
2.如果1校验未通过,比如缓存过期,在唯一性处理之前,先在数据库中查询幂等令牌作为索引的数据是否还存在.若存在,则说明本次操作为重复性操作;若不存在,则进入下一步.
3.在同一事务中完成三项操作:唯一性处理后,将幂等令牌写入到缓存,并将幂等令牌作为唯一索引的数据写入到DB中.
以支付场景为例:
1.当支付请求到达后,首先在Redis缓存中获取key为支付流水号的缓存value.若value不为空,则说明本次是重复操作,业务系统直接返回调用侧重复支付标识.若value为空,进行下一步.
2.使用支付流水号查询DB中是否有支付记录,如果有,业务系统直接返回重复支付标识.若支付记录没有,进行下一步.
3.完成支付任务,在Redis缓存中记录支付流水号,记录入DB. 这三项必须都成功, 一般先做业务处理,然后记录redis,最后入库.
4.消息幂等的实现
消费幂等的解决方案很简单:为消息指定不会重复的唯一标识.因为MessageID可能出现重复的情况,所以真正安全的幂等处理,不建议以MessageID作为处理依据.最好的方式是以业务唯一标识作为迷瞪处理的关键依据,而业务的唯一标识可以通过消息key设置.比如设置key为orderId_100, 可以解析出100,然后进行幂等处理.
8.消息堆积与消费延迟
1.概念
消息处理流程中,如果Consumer的消费速度跟不上Producer的发送速度,MQ中未处理的消息会越来越多,这部分消息就被称为堆积消息.消息出现堆积进而会造成消息的消费延迟.以下场景需要重点关注消息堆积和消费延迟问题:
- 业务系统上下游能力不匹配造成的持续堆积,且无法自行恢复
- 业务系统对消息的消费实时性要求较高,即使是短暂的堆积造成的消费延迟也无法接受.
2.产生原因分析
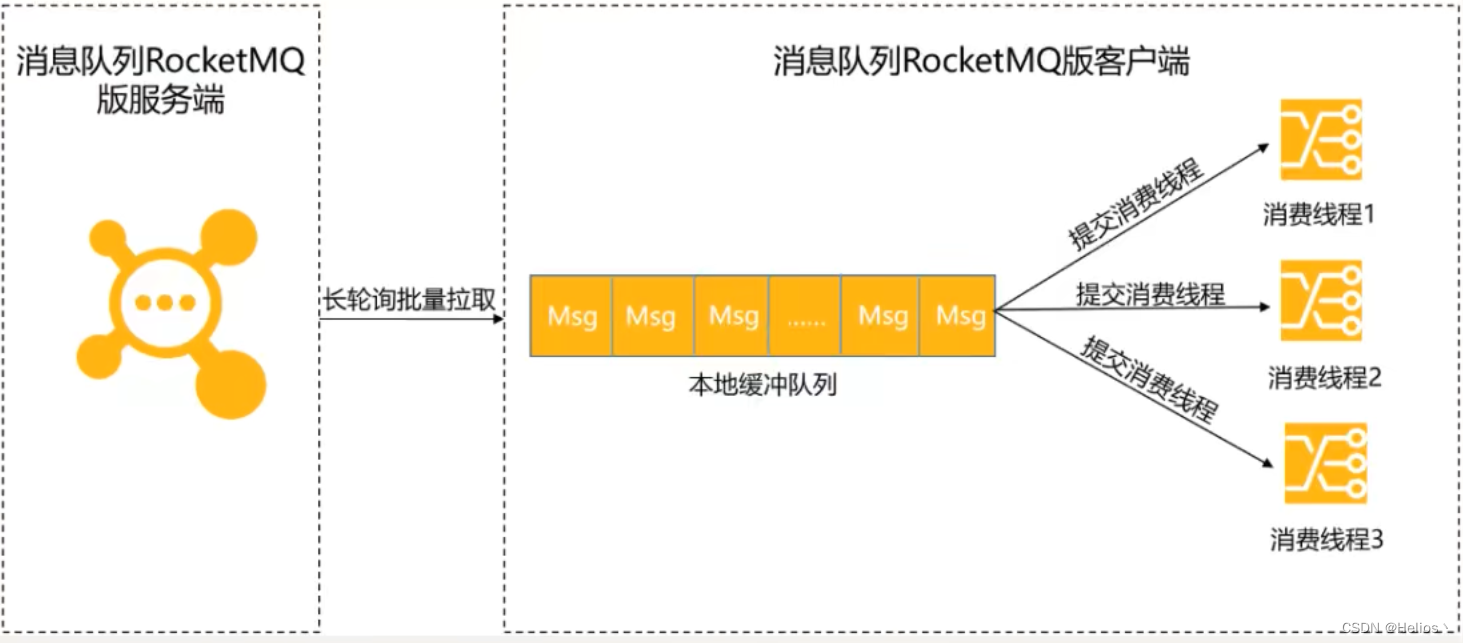
Consumer使用长轮训Pull模式消费消息时,分为以下两个阶段:
拉取消息
Consumer通过长轮训Pull模式批量拉取的方式从服务端获取消息,将拉取到的消息缓存到本地缓冲队列中.对于拉取式消费,在内网环境下,会有很高的吞吐量,所以这一阶段一般不会成为消息堆积的瓶颈.
消息消费
Consumer将本地缓存的消息提交到消费线程中,使用业务消费逻辑对消息进行处理,处理完毕后获取到一个结果.这是真正的消费过程.此时Consumer的消费能力就完全依赖于消息的消费耗时和消费并发度.如果由于业务处理逻辑复杂等原因,导致处理单条消息的耗时较长,则整体的消息吞吐量肯定不会高,此时就会导致Consumer本地缓存队列达到上限,停止从服务端拉取消息.
3.消费耗时
影响消息处理时长的代码逻辑,可能主要产生于两种类型的代码: CPU内部计算型代码和外部I/O操作型代码.
通常情况下代码如果没有复杂的递归和循环的话,内部计算耗时相对外部I/O操作来说可以忽略不计.所以外部I/O型代码是影响消息处理时长的主要症结所在.
4.消费并发度
一般情况下,消费者端的消费并发度由单节点线程数和节点数量共同决定,其值为单节点线程数*节点数量.不过,通常需要优先调节单节点的线程数,若单机硬件资源达到了上限,则需要横向拓展来提高消费并发度.
对于普通消息,延时消息及事务消息,并发度计算都是单节点线程数*节点数量.但对于顺序消息则是不同的.顺序消息的消费并发度等于Topic的Queue分区数量.
1)全局顺序消息:该Topic只有一个Queue分区.这样就能保证全局顺序消费.为了保证这个全局顺序性,ConsumerGroup中在同一时刻只能有一个Consumer的一个线程进行消费,所以并发度为1.
2)分区顺序消息:在每个Topic内部的不同Queue, 保证在每个Queue对应的消费者同一时刻只消费一条消息,但是不同Queue之间不能保证顺序性.如msg1,msg2在queue1,msg3和msg4在queue2,msg1必定在msg2前面消费,但是msg3可能在msg1之前消费.
5.单机线程数计算
对于一台主机中线程池数的设置需要谨慎,不能盲目直接调大线程数,设置过大的线程数反而会带来大量的线程切换的开销.理想环境下单节点的最优线程数计算模型为: C * (T1 + T2) / T1.
- C: CPU内核数
- T1: CPU内部逻辑计算耗时
- T2: 外部IO操作耗时
最优线程数解释: C + C * T2 / T1, 让C个线程在执行CPU内部逻辑计算, T2 / T1 可能为就10, 那么就有10C个线程在等I/O结果,并不消耗CPU,这样的话,每个CPU都不浪费.
应该是先设置一个比较小的线程数,然后通过压测去不断调大线程数,直到找到最佳的线程数(平均消费耗时最低).
6.如何避免
为了避免在业务使用时出现非预期的消息堆积和消费延迟问题,需要在前期设计阶段对整个业务逻辑进行完善的排查和梳理.其中最重要的就是梳理消息的消费耗时和消息消费的并发度.
梳理消息的消费耗时
通过压测获取消息的消费耗时,并对耗时较高的操作的代码逻辑进行分析.梳理消息的消费耗时需要关注以下信息:
- 消费消息逻辑的计算复杂度是否过高,代码是否存在无限循环和递归等缺陷.
- 消息消费逻辑中的I/O操作是否是必须的,能否用本地缓存等方案规避.
- 消费逻辑中的复杂耗时的操作是否可以做异步化处理.如果可以,是否会造成逻辑错乱.
设置消费并发度
对于消息消费并发度的计算,可以通过以下两步实施:
- 逐步调大单个Consumer节点的线程数,并观测节点的系统指标,得到单个节点最优的消费线程数和消息吞吐量.
- 根据上下游链路的流量峰值计算出需要设置的节点数
节点数 = 流量峰值 / 单节点消息吞吐量
9.消息的清理
消息被消费后会被清理掉吗? 不会的.
消息时被顺序存储在commitlog文件的,且消息大小不定长,所以消息的清理是不可能以消息为单位进行清理的,而是以commitlog文件为单位进行清理的.否则会急剧下降清理效率,并实现逻辑复杂.
这个参数在broker的配置文件中.
commitlog文件存在一个过期时间,默认为72小时,即三天.除了用户手动清理外,在以下情况下也会被自动清理,无论文件中的消息是否被消费过:
- 文件过期,且到达清理时间点(默认为凌晨4点),自动清理过期文件
- 文件过期,且磁盘空间占用率已达到过期清理警戒线(默认75%)后,无论是否达到清理时间点,都会自动清理过期文件.
- 磁盘占用了达到清理警戒线(默认85%)后,开始按照设定好的规则清理文件,无论是否过期,默认会从最老的文件开始清理.
- 磁盘占用率达到系统危险警戒线(90%)后,Broker将拒绝写入消息.
相关文章:
RocketMQ工作原理
文章目录 三.RocketMQ工作原理1.消息的生产消息的生产过程Queue选择算法 2.消息的存储1.commitlog文件目录与文件消息单元 2.consumequeue目录与文件索引条目 3.对文件的读写消息写入消息拉取性能提升 3.indexFile1.索引条目结构2.文件名的作用3.查询流程 4.消息的消费1.推拉消…...
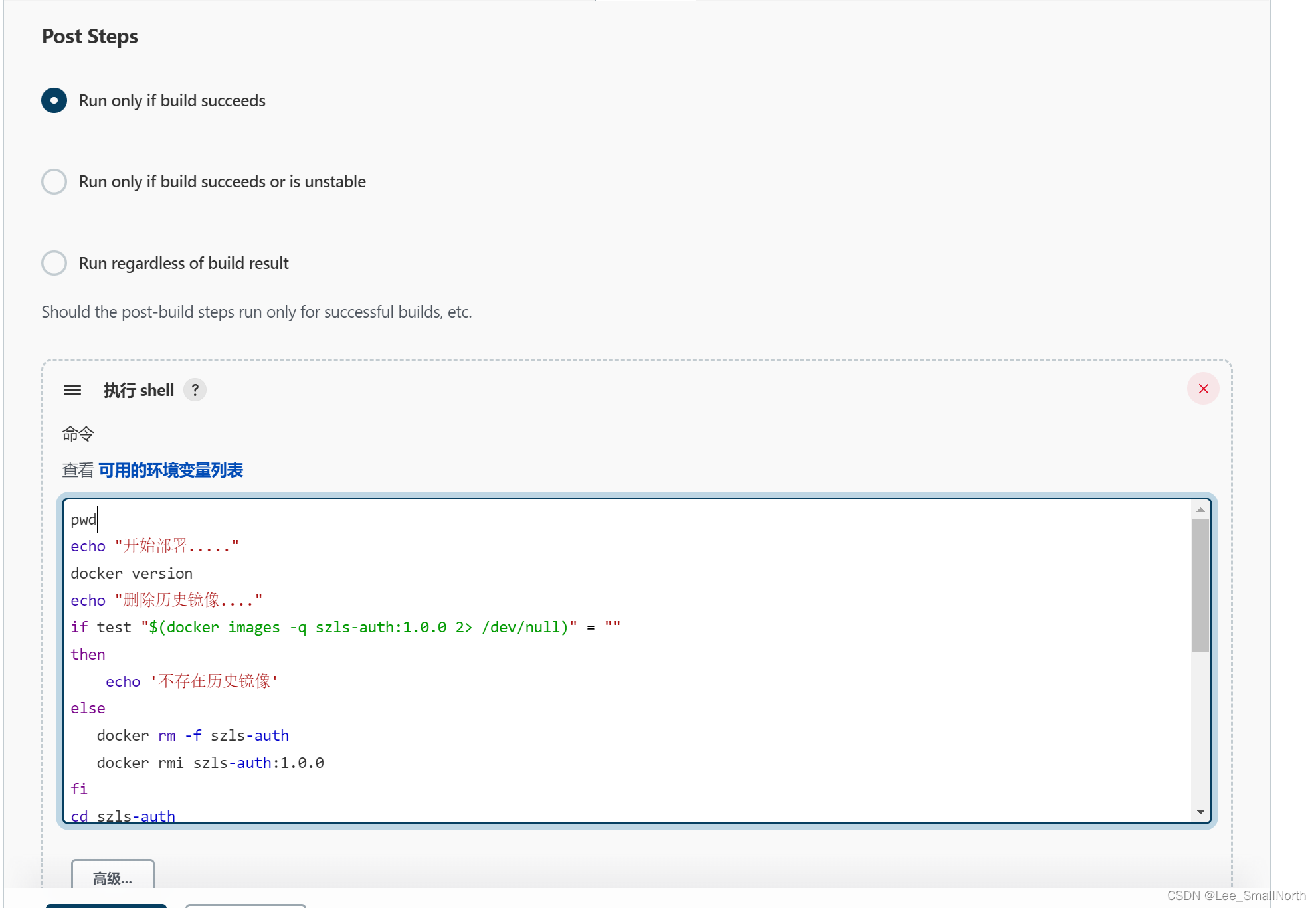
Jenkins+Docker+Docker-Compose自动部署,SpringCloud架构公共包一个任务配置
前言 Jenkins和docker的安装,随便百度吧,实际场景中我们很多微服务的架构,都是有公共包,肯定是希望一个任务能够把公共包的配置加进去,一并构建,ok,直接上干货。 Jenkins 全局环境安装 pwd e…...
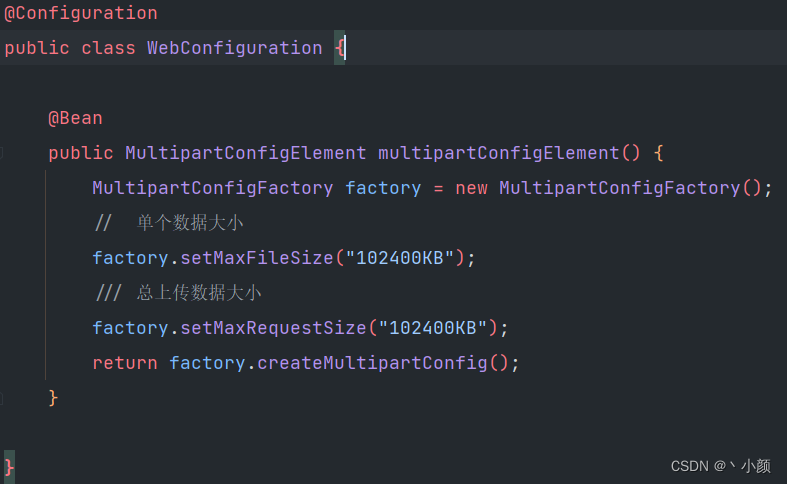
spring boot 2 配置上传文件大小限制
一、起因:系统页面上传一个文件超过日志提示的文件最大100M的限制,需要更改配置文件 二、经过: 1、在本地代码中找到配置文件,修改相应数值后交给运维更新生产环境配置,但是运维说生产环境没有这行配置,遂…...
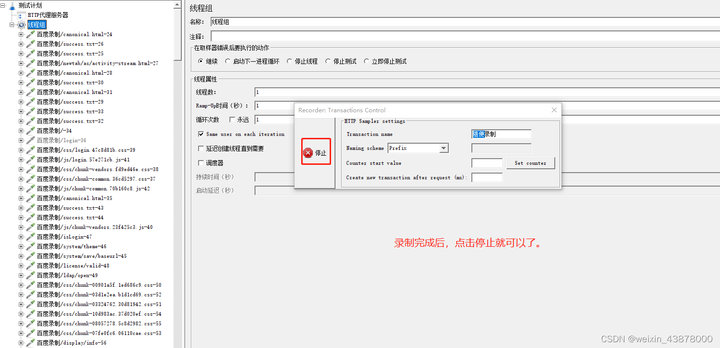
Jmeter —— 录制脚本
1. 第一步:添加http代理服务器,在测试计划--》添加--》非测试元件--》http代理服务器 2. 第二步:添加线程组(这个线程组是用来放录制的脚本,不添加也可以,就直接放在代理服务器下) 测试计划--》…...
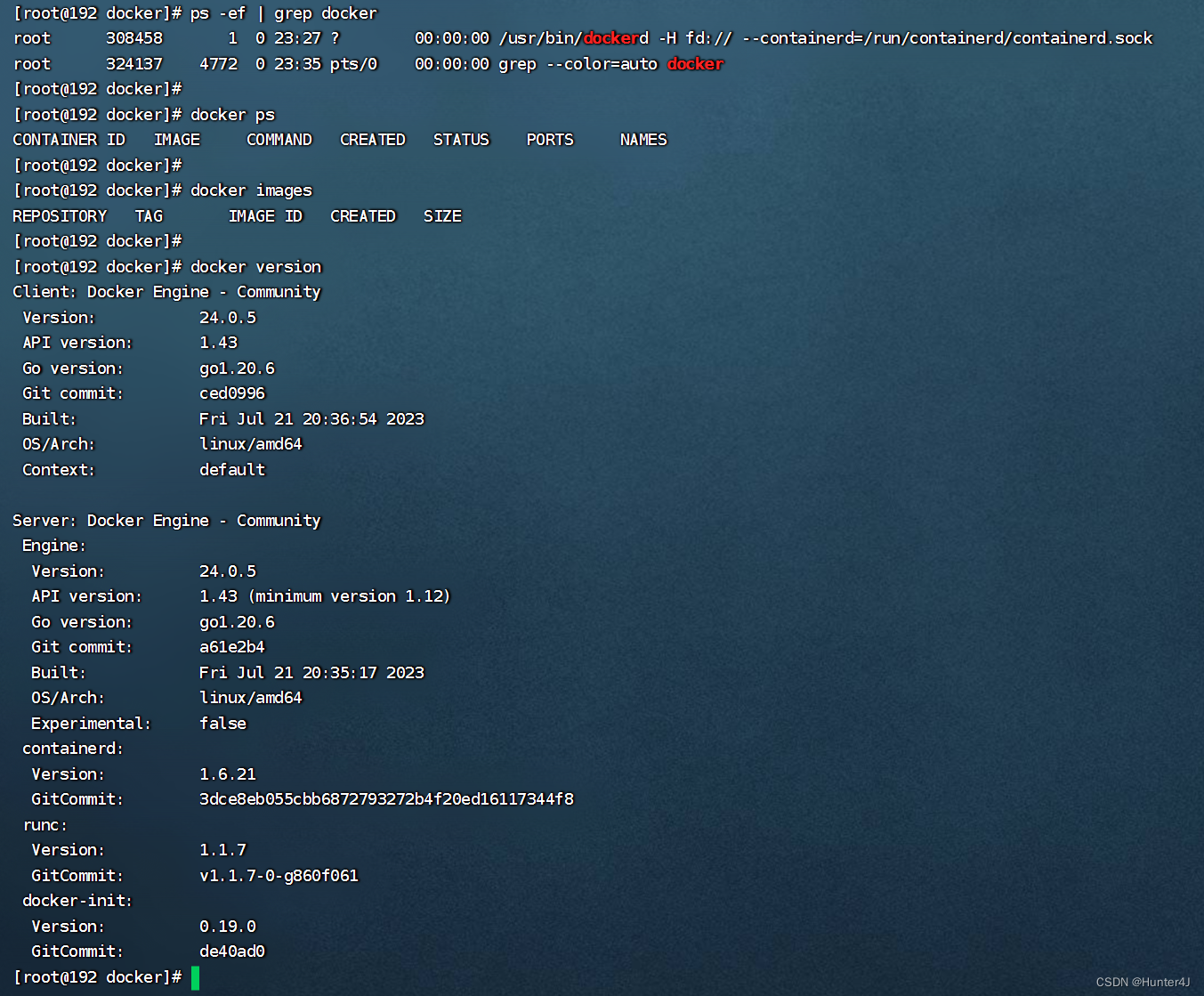
从零开始学Docker(一):Docker的安装部署
前述:本次学习与整理来至B站【Python开发_老6哥】老师分享的课程,有兴趣的小伙伴可以去加油啦,附链接 宿主机环境:RockyLinux 9 版本管理 Docker引擎主要有两个版本:企业版(EE)和社区版&#…...

【ROS 02】ROS通信机制
机器人是一种高度复杂的系统性实现,在机器人上可能集成各种传感器(雷达、摄像头、GPS...)以及运动控制实现,为了解耦合,在ROS中每一个功能点都是一个单独的进程,每一个进程都是独立运行的。更确切的讲,ROS是进程&#…...
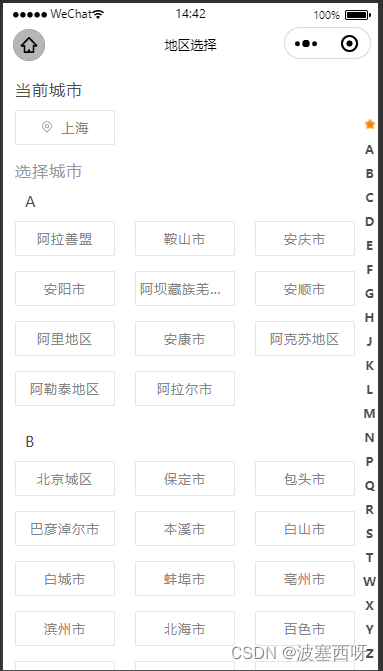
uniapp 选择城市定位 根据城市首字母分类排序
获取城市首字母排序,按字母顺序排序 <template><view class"address-wrap" id"address"><!-- 搜索输入框-end --><template v-if"!isSearch"><!-- 城市列表-start --><view class"address-sc…...
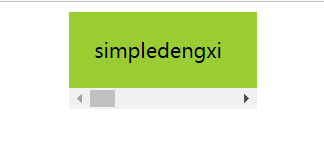
flex盒子 center排布,有滚动条时,拖动滚动条无法完整显示内容
文章目录 问题示例代码解决问题改进后的效果 问题 最近在开发项目的过程中,发现了一个有趣的事情,与flex盒子有关,不知道算不算是一个bug,不过对于开发者来说,确实有些不方便,感兴趣的同学不妨也去试试。 …...

Workbox使用分享
一、简要介绍 1.1 什么是Workbox 官方文档原文: At this point, service workers may seem tricky. There’s lots of complex interactions that are hard to get right. Network requests! Caching strategies! Cache management! Precaching! It’s a lot to r…...

秋招算法备战第32天 | 122.买卖股票的最佳时机II、55. 跳跃游戏、45.跳跃游戏II
122. 买卖股票的最佳时机 II - 力扣(LeetCode) 通过做差可以得到利润序列,然后只要利润需求的非负数求和就可以,因为这里没有手续费,某天买入之后买出可以等价为这几天连续买入卖出 class Solution:def maxProfit(se…...

Python状态模式介绍、使用
一、Python状态模式介绍 Python状态模式(State Pattern)是一种行为型设计模式,它允许对象在不同的状态下表现不同的行为,从而避免在代码中使用多重条件语句。该模式将状态封装在独立的对象中,并根据当前状态选择不同的…...
Github-Copilot初体验-Pycharm插件的安装与测试
引言: 80%代码秒生成!AI神器Copilot大升级 最近copilot又在众多独角兽公司的合力下,取得了重大升级。GitHub Copilot发布还不到两年, 就已经为100多万的开发者,编写了46%的代码,并提高了55%的编码速度。 …...

Spring AOP API详解
上一章介绍了Spring对AOP的支持,包括AspectJ和基于schema的切面定义。在这一章中,我们将讨论低级别的Spring AOP API。对于普通的应用,我们推荐使用前一章中描述的带有AspectJ pointcuts 的Spring AOP。 6.1. Spring 中的 Pointcut API 这一…...
分治法 Divide and Conquer
1.分治法 分治法(Divide and Conquer)是一种常见的算法设计思想,它将一个大问题分解成若干个子问题,递归地解决每个子问题,最后将子问题的解合并起来得到整个问题的解。分治法通常包含三个步骤: 1. Divid…...
.__init__()的作用是什么?)
super(Module_ModuleList, self).__init__()的作用是什么?
class Module_ModuleList(nn.Module):def __init__(self):super(Module_ModuleList, self).__init__()self.linears nn.ModuleList([nn.Linear(10, 10)])在这段代码中,super(Module_ModuleList, self).__init__() 的作用是调用父类 nn.Module 的 __init__ 方法&…...
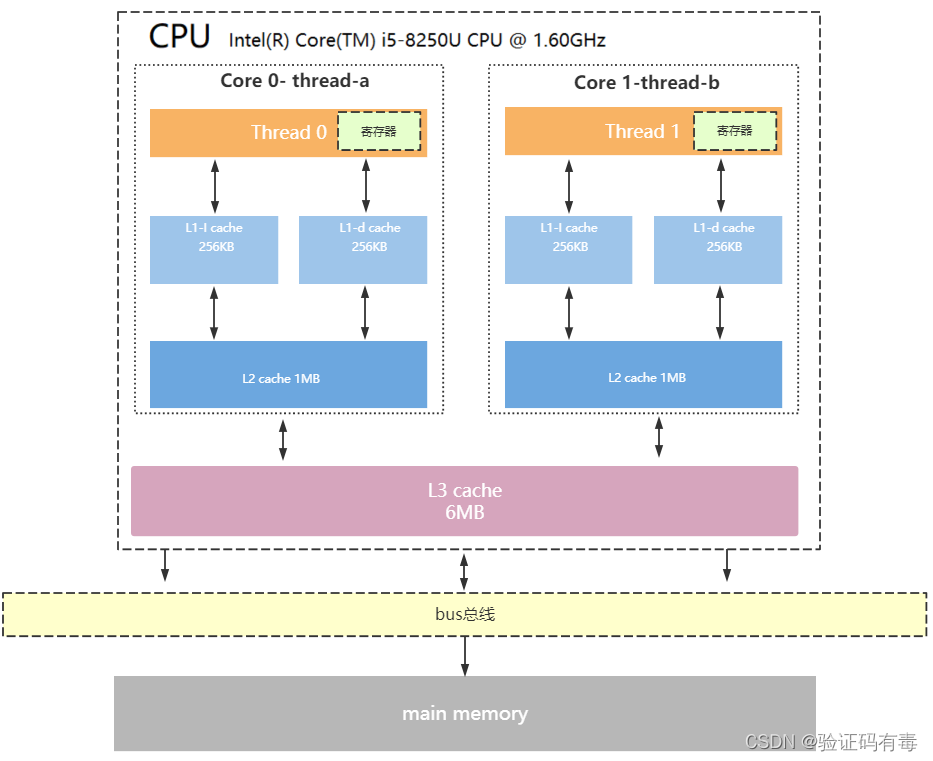
【并发专题】操作系统模型及三级缓存架构
目录 课程内容一、冯诺依曼计算机模型详解1.计算机五大核心组成部分2.CPU内部结构3.CPU缓存结构4.CPU读取存储器数据过程5.CPU为何要有高速缓存 学习总结 课程内容 一、冯诺依曼计算机模型详解 现代计算机模型是基于-冯诺依曼计算机模型 计算机在运行时,先从内存中…...
)
java基础复习(第二日)
java基础复习(二) 1.抽象的(abstract)方法是否可同时是静态的(static),是否可同时是本地方法(native),是否可同时被 synchronized修饰? 都不能。 抽象方法需要子类重写…...
Ansible自动化运维工具
Ansible自动化运维工具 一、ansible介绍二、ansible环境安装部署三、ansible命令行模块1、command模块2、shell模块3、cron模块4、user模块5、group模块6、copy模块7、file模块8、hostname模块9、ping模块10、yum模块11、service/systemd模块12、script模块13、mount模块14、ar…...
LeetCode-116-填充每个节点的下一个右侧节点指针
一:题目描述: 给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下: struct Node {int val;Node *left;Node *right;Node *next; }填充它的每个 next 指针,让这个指…...
每篇10题)
前端面试的性能优化部分(3)每篇10题
21.如何优化移动端网页的性能? 优化移动端网页的性能是提升用户体验、降低用户流失的关键。以下是一些优化移动端网页性能的常见方法: 压缩和合并资源: 压缩 CSS、JavaScript 和图片等静态资源,减少文件大小,同时合并…...

在Python项目中快速接入Taotoken多模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中快速接入Taotoken多模型API的完整步骤指南 对于希望将大模型能力集成到Python应用中的开发者而言,直接对…...

云厂商AI基础设施争夺战:Bedrock、Azure AI Studio与Vertex AI深度对比
1. 项目概述:一场没有硝烟的AI基础设施争夺战你打开云厂商控制台,发现“Bedrock”“Azure AI Studio”“Vertex AI”这些名字突然变得比以前更醒目;你翻看技术团队的采购清单,GPU实例价格单旁多了一行加粗标注:“含专属…...

Unity纹理保真优化:ASTC压缩与Mipmap精准控制方案
1. 这不是“去马赛克”,而是精准还原被压缩破坏的视觉信息Unity游戏开发中,你有没有遇到过这样的场景:美术同事发来一张4K高清角色贴图,你兴冲冲拖进Unity,设置成Texture Type Default、Compression ASTC_6x6&#x…...

SAM优化原理与PyTorch实战:从尖锐度抑制到泛化能力提升
1. 项目概述:当“找最低点”升级为“找最稳的洼地”你有没有试过调参调到凌晨三点,模型在训练集上准确率飙到99.8%,一跑验证集直接掉到72%?那种看着loss曲线一路俯冲、心里却越来越慌的感觉,我太熟了——就像精心搭好一…...

星露谷物语SMAPI模组加载器:终极安装与使用完整指南
星露谷物语SMAPI模组加载器:终极安装与使用完整指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否想在星露谷物语中体验数百个模组带来的无限可能,却又担心安装复杂和…...

Windows热键冲突终极解决方案:Hotkey Detective帮你找回失窃的快捷键
Windows热键冲突终极解决方案:Hotkey Detective帮你找回失窃的快捷键 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective…...

官方证书+创作基金等你拿|“AI绘童趣·童心创科普”庆六一活动正式启动!
为庆祝六一国际儿童节,守护青少年纯真的好奇心与想象力,百度文心大模型携手海豚出版社、天津人民出版社,共同推出“文心创作周六一特辑”,面向全国青少年及社会创作者发起“AI绘童趣童心创科普”青少年科普绘本创作活动。活动以ER…...

Palantir 现在干的活,本质上就是你描述的那个方向,但它在“深度”和“广度”上比你目前的 MVP 设想走得更远。如果说你想做的是一个“能听懂人话的 SQL 查询工具”,那么 Palantir
Palantir 现在干的活,本质上就是你描述的那个方向,但它在“深度”和“广度”上比你目前的 MVP 设想走得更远。如果说你想做的是一个“能听懂人话的 SQL 查询工具”,那么 Palantir 构建的是一个 “企业级的数字孪生操作系统”。它不仅仅是在“…...

海外网红营销AI skills到底是什么?2026年出海品牌选型指南
这两年,海外网红营销圈冒出了一个新词——AI skills。很多人第一次听到时有点摸不着头脑:这不就是AI功能吗?换个名字而已?但其实,它和传统AI功能还真不是一回事。本文想做的事很简单:讲清楚这个新概念到底是…...

SpinalHDL流水线设计:从时序抽象到工程实践
1. 项目概述:从Verilog的“线”到SpinalHDL的“流”在数字电路设计里,时序逻辑的流水线(Pipeline)是个老生常谈但又至关重要的概念。无论是为了提升系统主频,还是为了平衡组合逻辑路径的延迟,我们总免不了要…...