汽车分析,随时间变化的燃油效率
简述
今天我们来分析一个汽车数据。
数据集由以下列组成:
- 名称:每辆汽车的唯一标识符。
- MPG:燃油效率,以英里/加仑为单位。
- 气缸数:发动机中的气缸数。
- 排量:发动机排量,表示其大小或容量。
- 马力:发动机的功率输出。
- 重量:汽车的重量。
- 加速:提高速度的能力,以秒为单位。
- 车型年份:汽车模型的制造年份。
- 原产地:每辆汽车的原产地国家或地区。
总的来看数据内容不是很多,分析起来还是很容易的。
目标
这个项目的主要目标是了解汽车的不同特性之间的关系,以及它们如何影响燃油效率(MPG -每加仑英里数)。该项目还旨在发现数据中任何有趣的趋势或模式,从而为汽车行业提供见解。
数据清理和预处理
# 导入库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' ## 设置中文显示from scipy.stats import f_onewayfrom scipy.stats import ttest_ind# 导入数据
df = pd.read_csv('D:桌面\\Automobile.csv',encoding='gbk')
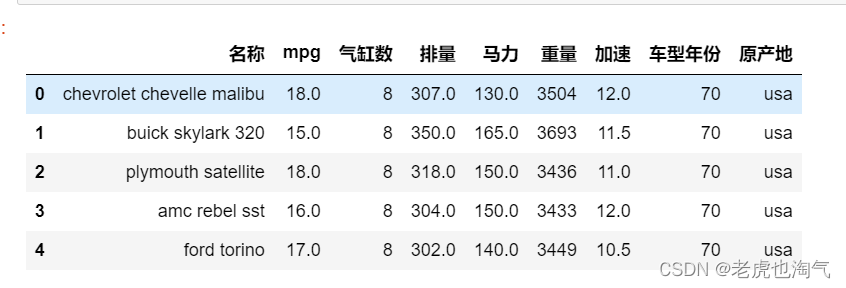
检查所有列的数据类型

检查缺失值

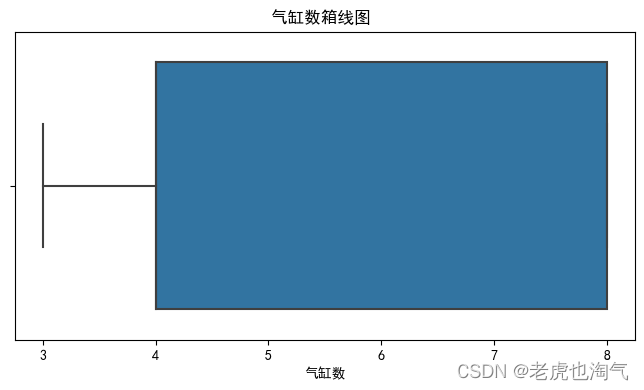
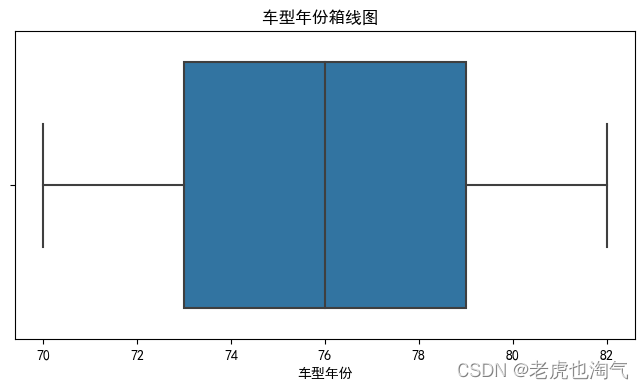
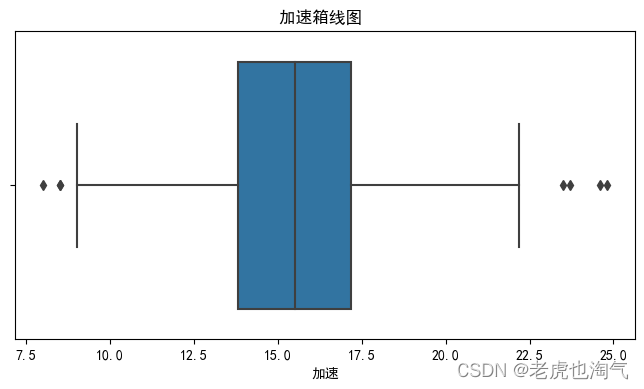
箱型图
df['马力'] = df['马力'].fillna(df['马力'].mean())
# 数字列列表
num_cols = ['mpg', '气缸数', '排量', '马力', '重量', '加速', '车型年份']for col in num_cols:plt.figure(figsize=(8, 4))sns.boxplot(df[col])plt.title(f'{col}箱线图 ')plt.show()

处理 ‘马力’ 中的异常值
首先,计算“马力”(horsepower)的四分位距(IQR)
Q1_hp = df['马力'].quantile(0.25)
Q3_hp = df['马力'].quantile(0.75)
IQR_hp = Q3_hp - Q1_hp
定义异常值的上限和下限。
lower_bound_hp = Q1_hp - 1.5 * IQR_hp
upper_bound_hp = Q3_hp + 1.5 * IQR_hp将异常值限制在一定范围内。
df['马力'] = df['马力'].clip(lower=lower_bound_hp, upper=upper_bound_hp)
重复这个过程,针对“重量”
Q1_weight = df['重量'].quantile(0.25)
Q3_weight = df['重量'].quantile(0.75)
IQR_weight = Q3_weight - Q1_weightlower_bound_weight = Q1_weight - 1.5 * IQR_weight
upper_bound_weight = Q3_weight + 1.5 * IQR_weightdf['重量'] = df['重量'].clip(lower=lower_bound_weight, upper=upper_bound_weight)
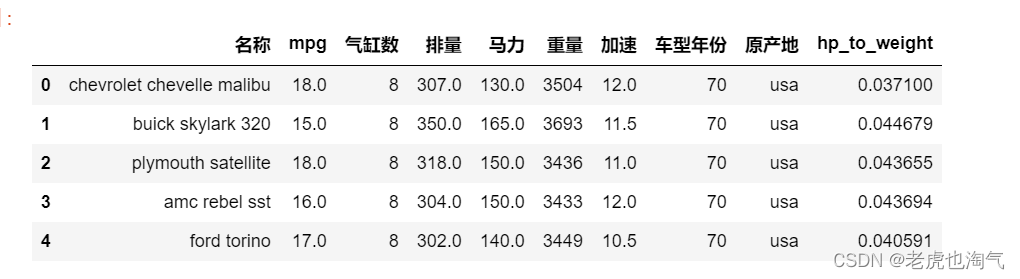
特征工程
创建一个新的特征’hp_to_weight’,它是马力与重量的比率。
df['hp_to_weight'] = df['马力'] / df['重量']
检查前几行 DataFrame 以确认更改。
df.head()
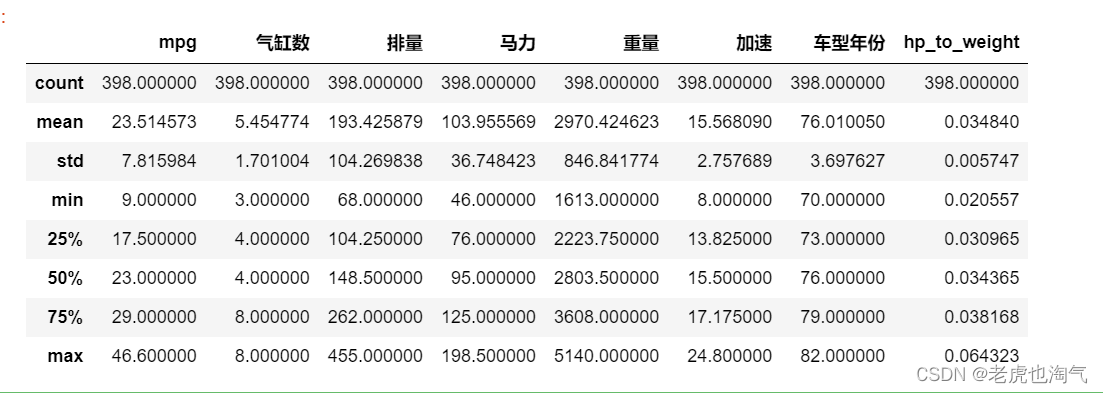
生成数值变量的描述性统计数据。
df.describe()
数据可视化
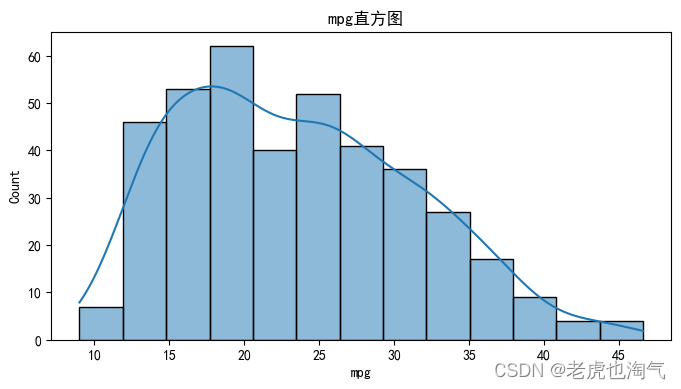
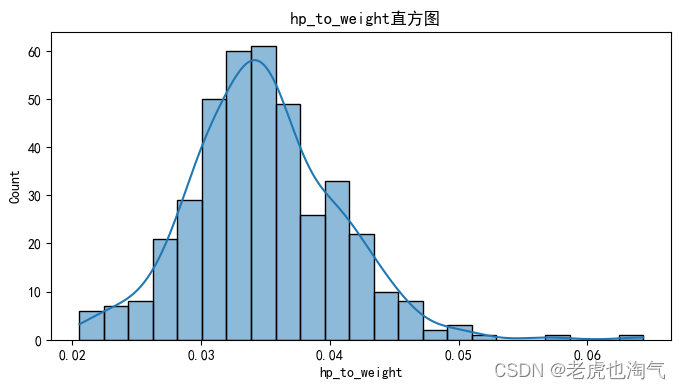
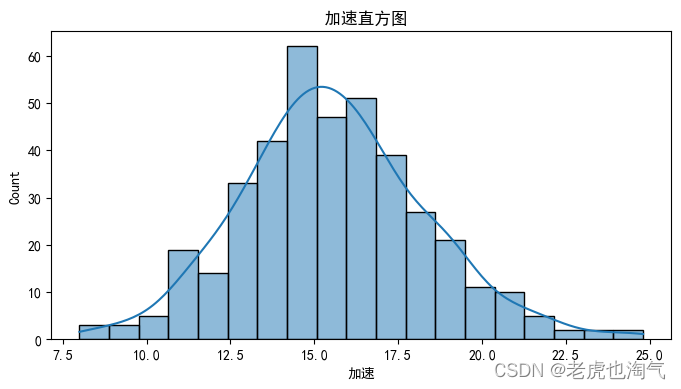
生成数值变量的直方图。
num_cols = ['mpg', '气缸数', '排量', '马力', '重量', '加速', '车型年份', 'hp_to_weight']for col in num_cols:plt.figure(figsize=(8, 4))sns.histplot(df[col], kde=True)plt.title(f' {col}直方图')plt.show()
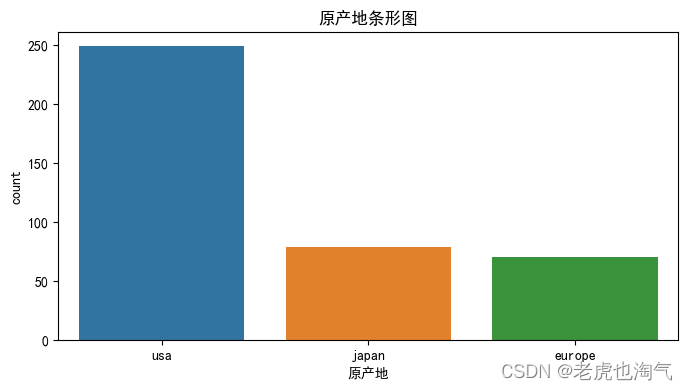
生成分类变量的条形图
plt.figure(figsize=(8, 4))
sns.countplot(x='原产地', data=df)
plt.title('原产地条形图')
plt.show()
双变量分析
为成对的数值变量生成散点图
num_cols = ['mpg', '气缸数', '排量', '马力', '重量', '加速', '车型年份', 'hp_to_weight']sns.pairplot(df[num_cols])
plt.show()

数值变化的相关矩阵
#计算数值变量之间的相关系数。
corr_matrix = df[num_cols].corr()# 显示相关矩阵
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.title('数值变化的相关矩阵')
plt.show()

group1 = df[df['原产地'] == 'usa']['mpg']
group2 = df[df['原产地'] == 'europe']['mpg']
group3 = df[df['原产地'] == 'japan']['mpg']# 进行单因素方差分析。
f_stat, p_value = f_oneway(group1, group2, group3)# 输出 F-statistic 和 p-value
print(f'F-statistic: {f_stat}')
print(f'p-value: {p_value}')

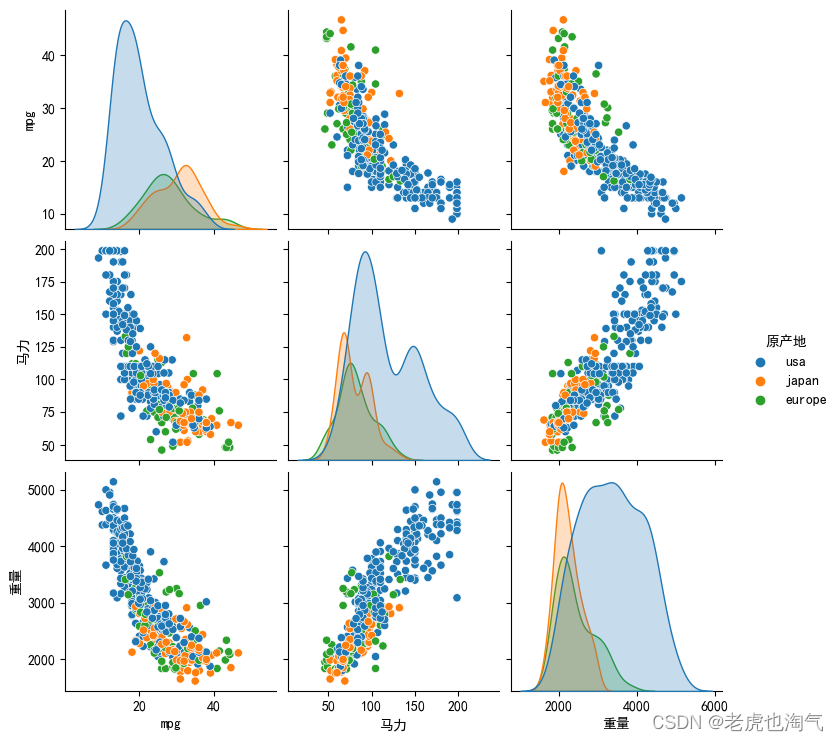
多变量分析
生成一组变量的配对图。
subset_cols = ['mpg', '马力', '重量', '原产地']
sns.pairplot(df[subset_cols], hue='原产地')
plt.show()
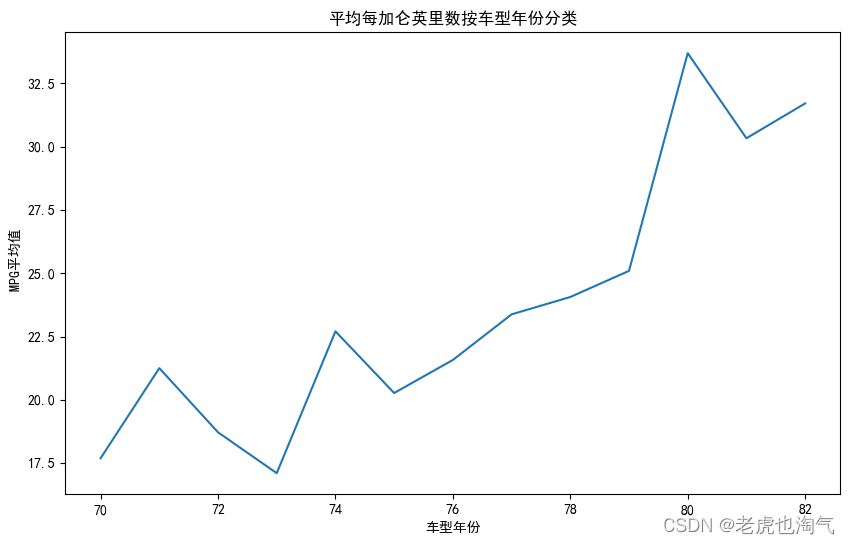
时间分析
# 计算每个型号年份的平均每加仑英里数。
avg_mpg_by_year = df.groupby('车型年份')['mpg'].mean()# 绘制随着时间变化的平均每加仑英里数。
plt.figure(figsize=(10, 6))
sns.lineplot(data=avg_mpg_by_year)
plt.title('平均每加仑英里数按车型年份分类')
plt.xlabel('车型年份')
plt.ylabel(' MPG平均值')
plt.show()
假设检验
# 删除具有缺失“mpg”值的行。
df = df.dropna(subset=['mpg'])# 将数据分成两组。
group1 = df[df['车型年份'] < 75]['mpg'] # 1975年之前制造的汽车
group2 = df[df['车型年份'] >= 75]['mpg'] # 1975年之后制造的汽车# 进行双样本t检验。
from scipy.stats import ttest_ind
t_stat, p_value = ttest_ind(group1, group2)# 输出 the t-statistic the p-value
print(f't-statistic: {t_stat}')
print(f'p-value: {p_value}')

结论
-
随着时间的推移,燃油效率:平均每加仑英里数(mpg)似乎随着时间的推移而增加,这表明汽车变得更加省油。这可能是由于技术的进步和汽车制造业对燃油效率的日益关注。
-
马力和重量:马力和重量之间似乎存在正相关关系,表明较重的汽车往往拥有更强劲的发动机。然而,马力和重量似乎都与mpg负相关,这表明较重的汽车和发动机功率更大的汽车往往更省油。
-
产地和燃油效率:我们的假设检验表明,不同产地的汽车平均每加仑汽油行驶里程有显著差异。这表明汽车的生产地区可能会对其燃油效率产生影响。
-
新功能-马力重量比:我们创造的新功能,马力重量比,可能会为这些变量和mpg之间的关系提供不同的结果
题外话
我整理了一些资源,如果你也对Python和大数据感兴趣,关注下方公众号免费提取资料。



相关文章:
汽车分析,随时间变化的燃油效率
简述 今天我们来分析一个汽车数据。 数据集由以下列组成: 名称:每辆汽车的唯一标识符。MPG:燃油效率,以英里/加仑为单位。气缸数:发动机中的气缸数。排量:发动机排量,表示其大小或容量。马力&…...

大数据面试题之Elasticsearch:每日三题(六)
大数据面试题之Elasticsearch:每日三题 1. 为什么要使用Elasticsearch?2.Elasticsearch的master选举流程?3.Elasticsearch集群脑裂问题? 1. 为什么要使用Elasticsearch? 系统中的数据,随着业务的发展,时间…...
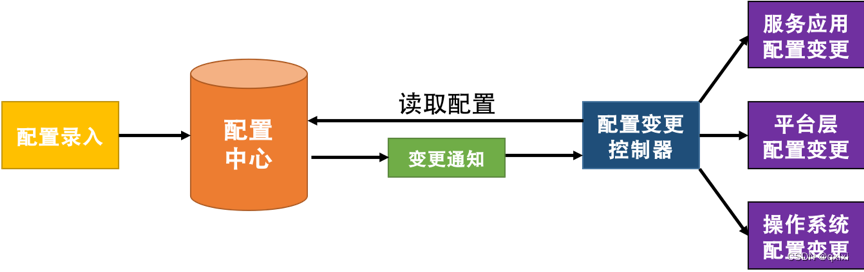
【管理设计篇】聊聊分布式配置中心
为什么需要配置中心 对于一个软件系统来说,除了数据、代码,还有就是软件配置,比如操作系统、数据库配置、服务配置 端口 ip 、邮箱配置、中间件软件配置、启动参数配置等。如果说是一个小型项目的话,可以使用Spring Boot yml文件…...

远程控制平台简介
写在前面 之所以想自己动手实现一个远程控制平台,很大一部分原因是因为我那糟糕的记性,虽然经常加班到很晚,拖着疲惫的步伐回到家,才想起忘记打卡了,如果我能在家控制在办公室的手机打一下卡就好了… 有人说,市场上有TeamViewer,向日葵,AnyDesk,ToDesk,等等这些老大…...
韦东山Linux驱动入门实验班(5)LED驱动---驱动分层和分离,平台总线模型
前言 (1)前面已经已经详细介绍了LED驱动如何进行编写的代码。如果韦东山Linux驱动入门实验班(4)LED驱动已经看懂了,驱动入门实验班后面的那些模块实验,其实和单片机操作差不太多了。我就不再浪费时间进行讲…...

【雕爷学编程】MicroPython动手做(02)——尝试搭建K210开发板的IDE环境
知识点:简单了解K210芯片 2018年9月6日,嘉楠科技推出自主设计研发的全球首款基于RISC-V的量产商用边缘智能计算芯片勘智K210。该芯片依托于完全自主研发的AI神经网络加速器KPU,具备自主IP、视听兼具与可编程能力三大特点,能够充分适配多个业务场景的需求。作为嘉楠科…...

C#——Thread与Task的差异比较及使用环境
C#——Thread与Task的差异比较及使用环境 前言一、差异1. 创建和管理:2. 异步编程:3. 返回值:4. 异常处理:5. 线程复用: 总结 前言 前面两篇文章,分别通过各自的实例讲了关于Task以及Thread的相关的使用特…...

刷题 31-35
三十一、 747. 至少是其他数字两倍的最大数 给你一个整数数组 nums ,其中总是存在 唯一的 一个最大整数 。 请你找出数组中的最大元素并检查它是否 至少是数组中每个其他数字的两倍 。如果是,则返回 最大元素的下标 ,否则返回 -1 。 示例 1&a…...

【mysql】—— 数据类型详解
序言: 本期我将大家认识关于 mysql 数据库中的基本数据类型的学习。通过本篇文章,我相信大家对mysql 数据类型的理解都会更加深刻。 目录 (一)数据类型分类 (二)数值类型 1、tinyint类型 2、bit类型 …...

kafka常用命令
查看主题 ./kafka-topics.sh --list --bootstrap-server 10.1.1.2:9092 创建主题 ./kafka-topics.sh --bootstrap-server 10.1.1.2:9092 --create --topic test_topic --partitions 1 查看消费者列表--list ./kafka-consumer-groups.sh --bootstrap-server 10.1.1.2:9092 -…...
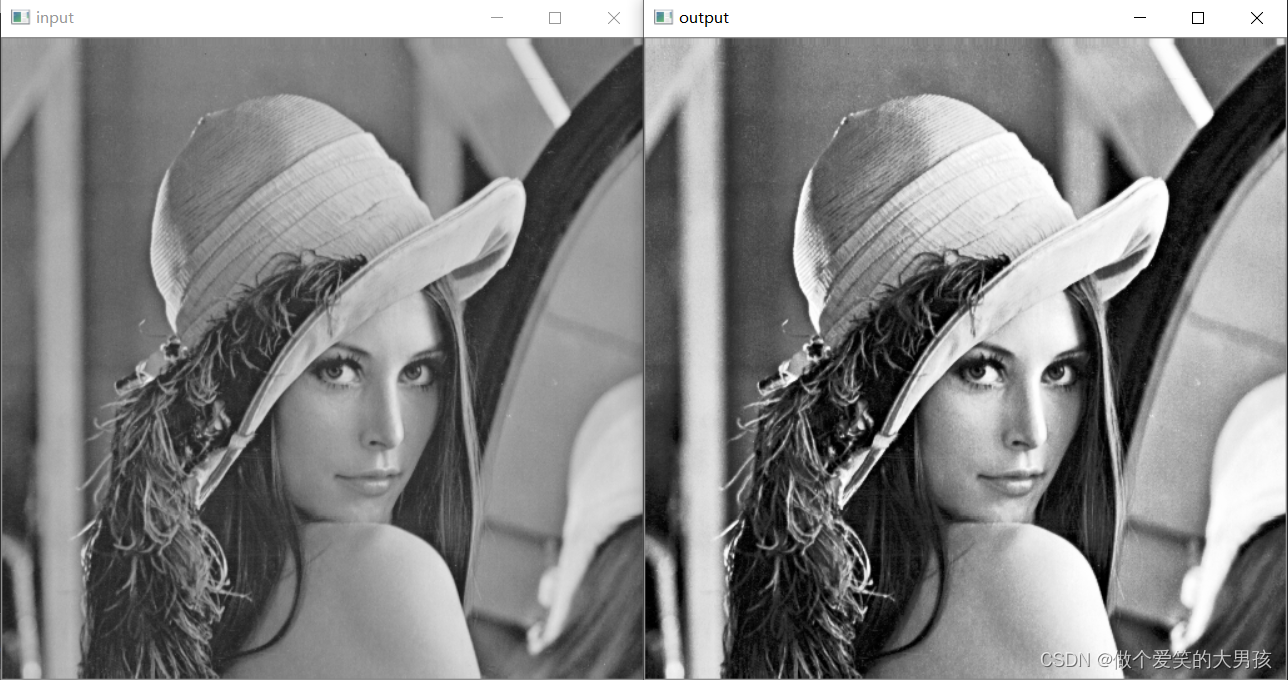
数字图像处理(番外)图像增强
图像增强 图像增强的方法是通过一定手段对原图像附加一些信息或变换数据,有选择地突出图像中感兴趣的特征或者抑制(掩盖)图像中某些不需要的特征,使图像与视觉响应特性相匹配。 图像对比度 图像对比度计算方式如下: C ∑ δ δ ( i , j …...

flutter:轮播
前言 介绍几个比较有不错的轮播库 swipe_deck 与轮播沾边,但是更多的是一种卡片式的交互式界面设计。它的主要概念是用户可以通过左右滑动手势浏览不同的卡片,每张卡片上都有不同的信息或功能。 Swipe deck通常用于展示图片、产品信息、新闻文章、社…...

高忆管理:股票投资策略是什么?有哪些?
在进行股票买卖过程中,出资者需求有自己的方案和出资战略,并且主张严格遵从出资战略买卖,不要跟风操作。那么股票出资战略是什么?有哪些?下面就由高忆管理为我们剖析: 股票出资战略简略来说便是能够协助出资…...
为公网SSH远程Ubuntu配置固定的公网TCP端口地址主图
文章目录 为公网SSH远程Ubuntu配置固定的公网TCP端口地址 为公网SSH远程Ubuntu配置固定的公网TCP端口地址 在上篇文章中,我们通过cpolar建立的临时TCP数据隧道,成功连接了位于其他局域网下的Ubuntu系统,实现了不同操作系统、不同网络下的系统…...

【前端知识】React 基础巩固(四十一)——手动路由跳转、参数传递及路由配置
React 基础巩固(四十一)——手动路由跳转、参数传递及路由配置 一、实现手动跳转路由 利用 useNavigate 封装一个 withRouter(hoc/with_router.js) import { useNavigate } from "react-router-dom"; // 封装一个高阶组件 function withRou…...

Qt几种字符类型的相互转换
Qt几种字符类型的相互转换 将const QString转换为const char*将const char*转换为const QStringQstring转换为string把string转换为QstringQt中弹出一个窗口 将const QString转换为const char* #include <QString> #include <iostream>int main() {const QString …...

软件测试员的非技术必备技能
成为软件测试人员所需的技能 非技术技能 以下技能对于成为优秀的软件测试人员至关重要。 将您的技能组合与以下清单进行比较,以确定软件测试是否适合您 - 分析技能:优秀的软件测试人员应具备敏锐的分析能力。 分析技能将有助于将复杂的软件系统分解为…...

渗透测试:Linux提权精讲(二)之sudo方法第二期
目录 写在开头 sudo expect sudo fail2ban sudo find sudo flock sudo ftp sudo gcc sudo gdb sudo git sudo gzip/gunzip sudo iftop sudo hping3 sudo java 总结与思考 写在开头 本文在上一篇博客的基础上继续讲解渗透测试的sudo提权方法。相关内容的介绍与背…...
ansible安装lnmp(集中式)
文章目录 一、安装nginx二、安装mysql三、安装php测试: 一、安装nginx - name: the nginx playhosts: webserversremote_user: roottasks:- name: stop firewalld #关闭防火墙service: namefirewalld statestopped enabledno- name: selinux stopc…...

Tomcat的基本使用,如何用Maven创建Web项目、开发完成部署的Web项目
Tomcat 一、Tomcat简介二、Tomcat基本使用三、Maven创建Web项目3.1 Web项目结构3.2开发完成部署的Web项目3.3创建Maven Web项目3.3.1方式一3.3.2方式二(个人推荐) 总结 一、Tomcat简介 Web服务器: Web服务器是一个应用程序(软件&…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...

如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南
如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 当你…...
)
内存申请和使用的场景分析(以AP->kernal->ISP为例)
在 ISP(Image Signal Processor)系统中,AP 与 ISP 之间的内存交互本质上是一个**“AP 申请可 DMA 访问的共享内存 → 内核建立映射 → 硬件寻址读写 → 同步与回收”**的过程。下面按数据流分层详细拆解。一、ISP 内存需求的特殊性 与普通应用…...

5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南
5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了…...