【无标题】使用Debate Dynamics在知识图谱上进行推理(2020)7.31
使用Debate Dynamics在知识图谱上进行推理
- 摘要
- 介绍
- 背景与相关工作
- 我们的方法

摘要
我们提出了一种新的基于 Debate Dynamics 的知识图谱自动推理方法。
其主要思想是将三重分类任务定义为两个强化学习主体之间的辩论游戏,这两个主体提取论点(知识图中的路径),目的是分别促进事实为真(命题)或事实为假(对立面)。基于这些论点,一个二元分类器(称为裁判)决定事实是真是假。这两个代理可以被认为是稀疏的。对抗性特征生成器(Adversarial Feature Generator),为正题或反题提供可解释的证据。与其他黑盒方法相比,这些论点允许用户了解法官的决定。
由于这项工作的重点是创建一种可解释的方法,以保持有竞争力的预测准确性,我们将我们的方法以三重分类和链接预测任务为基准。因此,我们发现我们的方法在基准数据集FB15k-237、WN18RR和Hetionet上优于几个基线。我们还进行了一项调查,发现提取的论点对用户来说是有信息的。
Debate Dynamics是一种用于推理的框架。它的主要目的是从知识图谱中自动提取和评估论点,以支持决策制定和信息检索等任务。
Debate Dynamics可以自动从知识图谱中提取论点,并将它们表示为辩论图,该图包括论点和它们之间的关系。然后,它将辩论图输入到论证框架中,该框架使用论证理论来生成反驳和评估论点的强度。最后,它可以根据论证框架的结果做出决策。
Debate Dynamics的优势在于它可以处理复杂的知识图谱,并自动提取和评估论点。它还可以支持多种论证框架,因此可以应用于各种不同的问题领域,例如自然语言处理、信息检索和决策支持系统等。
Adversarial Feature Generator(对抗特征生成器)
是一种机器学习技术,通常用于生成能够欺骗分类器的特征。它的基本思想是通过训练两个对抗的神经网络,一个生成器和一个判别器,从噪声中生成具有特定特征的样本,以欺骗判别器,使它无法准确识别样本的真实标签。
在Adversarial Feature Generator中,生成器试图生成具有与真实样本类似的特征,而判别器则试图区分生成的特征与真实样本的特征。这两个神经网络通过反复训练来提高自己的表现,直到生成器可以生成与真实样本无法区分的特征为止。
介绍
关于现实世界的各种信息可以用实体及其关系来表达。
知识图谱(KGs)以三元组(s,p,o)的形式存储关于世界的事实,其中s(主体)和o(对象)对应于图中的节点,p(谓词)表示连接两者的边类型。KG中的节点表示整个世界的实体,谓词描述实体对之间的关系。
KGs可用于不同领域的各种人工智能任务,如命名实体消除歧义、内部语言处理、视觉相关性检测或协作过滤。然而,一个主要问题是,大多数真实世界的KGs是不完整的(即,真实的事实缺失)或包含虚假的事实。为解决这一问题而设计的机器学习算法试图根据观察到的连接模式来插入缺失的三元组或检测虚假事实。此外,许多任务,如问答或协作过滤,可以在预测KG中的新链接方面进行模拟。
在KGs上进行推理的大多数机器学习方法都 将实体和谓词嵌入到低维向量空间中,然后可以基于这些嵌入来计算三元组的合理性得分。大多数基于嵌入的方法的共同点是它们的黑盒性质,因为它隐藏了用户对这个分数的贡献。当涉及到在现实世界中部署KGs时,这种缺乏透明度的情况构成了一个潜在的限制。在机器学习领域,可解释性最近引起了关注。与 一次性黑盒模型(one-way black-box) 相比,可理解的机器学习方法能够构建机器和用户交互并相互影响的系统。
如果一个模型是一种一次性黑盒模型(one-way black-box),那么它只能用于生成输出,而不能从输出推断出模型内部的实现方式或其他详细信息。这意味着我们无法通过观察输出来理解模型是如何进行决策的或者对特定输入做出响应的。
大多数可解释的Al方法可以大致分为两组:后解释性(post-hoc interpretability) 和 集成透明度(integrated transparency)。
虽然后解释性旨在解释已经训练的黑盒模型的结果,但基于集成透明度的方法要么采用 内部解释机制 ,要么由于 模型复杂性低 自然地可以被解释 (例如,线性模型)。由于低复杂性和预测准确性往往是相互冲突的目标,因此通常需要在性能和可解释性之间进行权衡。
这项工作的目标是设计一种具有集成透明度的KG推理方法,该方法既不牺牲性能,又 允许人类参与 。
后解释性(post-hoc interpretability)
指在模型已经训练好并且预测能力已经被评估之后,对模型进行解释的过程。与之相对的是先解释性(ante-hoc interpretability),它是指在训练模型时就考虑到模型可解释性的过程。
后解释性的目的是为了让用户理解模型的决策过程和结果,以便更好地理解模型的行为、检测模型的偏差和错误,并为决策提供支持和解释。
Integrated Transparency(集成透明度)
指在机器学习中,将可解释性与模型的其他性能指标集成在一起的方法。旨在实现模型的高性能和可解释性之间的平衡,从而提高模型在实际应用中的可靠性和可信度。
集成透明度方法通常包括以下几个步骤:
1.确定可解释性指标:确定与模型可解释性相关的指标,例如局部解释性、全局解释性和可视化等。
2.确定其他性能指标:确定与模型其他性能指标相关的指标,例如准确性、召回率和精确度等。
3.集成指标:将可解释性指标和其他性能指标集成在一起,以综合评估模型的性能。这可以通过加权平均、决策树或神经网络等方法实现。
4.解释性反馈:根据集成指标的结果,为用户提供解释性反馈,以帮助他们理解模型的决策过程和结果。
Internal Explanation Mechanism(内部解释机制)(集成透明度中)
指在机器学习模型中添加一种用于解释模型决策过程的机制,这种机制通常是由一系列规则、约束或者其他形式的知识表示来实现的。它可以帮助用户理解模型是如何做出决策的,以及模型内部的特征和权重是如何影响模型决策的。
内部解释机制通常包括以下几个方面:
特征重要性:确定模型中每个特征对决策的影响程度。
规则和约束:定义模型内部的规则和约束,以支持对模型决策的解释。
可视化:通过可视化方式展示模型内部的决策过程和特征影响。
解释性反馈:为用户提供有关模型决策过程的解释性反馈。
模型复杂性低是指机器学习模型的结构和参数相对简单,模型的计算和决策过程也相对容易理解和解释。这种模型通常具有较少的参数和较少的层数,可以更快地训练和预测,并且更容易被理解和解释。
允许人类参与(Allowing a human-in-the-loop)可以包括以下几个方面:
数据标注:人类可以对数据进行标注,以帮助模型更好地理解和学习数据的特征和关系。
模型训练:人类可以在模型训练的过程中提供反馈,例如调整模型参数、选择特征等,以改善模型的性能。
模型推断:人类可以对模型的推断结果进行审核和纠错,以提高模型的准确性和可靠性。
模型决策:人类可以参与到模型的决策过程中,例如提供决策依据、制定决策规则等,以保证决策的合理性和可靠性。
本文介绍了一种基于强化学习的三重分类新方法——R2D2(Reveal Relations using Debate Dynamics)。受通过辩论增加Al的安全性的启发,我们将三重分类任务建模为两个主体之间的辩论,每个主体都提出了支持的论点(三元组为真)或相反的论点(三元组错误)。基于这些论点,一个称为裁判的二元分类器决定事实是真是假。与大多数基于 表示学习 的方法不同,论点可以显示给用户,这样他们就可以追溯法官的分类,并可能推翻判决或请求额外的论据。因此,R2D2的集成透明机制不是基于低复杂性组件,而是基于可解释特征的自动提取。
虽然深度学习使手动特征工程在很大程度上成为冗余,但这一优势是以产生难以解释的结果为代价的。我们的工作是试图通过使用深度学习技术自动选择稀疏的、可解释的特征来打破这一循环。这项工作的主要贡献如下。
- 据我们所知,R2D2构成了第一个基于辩论动力学的KGs推理模型。
- 我们在数据集FB15k-237和WN18RR上对R2D2的三重分类进行了基准测试。我们的发现表明,R2D2在准确性、PR AUC和ROC AUC方面优于所有基线方法,同时更具可解释性。
- 为了证明R2D2原则上可以用于KG完成,我们还评估了它在FB15k-237子集上的链路预测性能。为了包括现实世界的任务,我们在Hetionet上使用R2D2来寻找药物的基因-疾病关联和新的靶向疾病。R2D2在两个数据集上的标准测量
Representation learning(表示学习)
指一类机器学习方法,旨在自动学习数据的特征表示,以便更好地理解和处理数据。它通过学习数据的高层次特征表示,可以实现更好的数据压缩、分类、聚类、生成等任务,并且可以提高模型的泛化能力和鲁棒性。
表示学习可以自动从原始数据中学习特征表示,避免了手工设计特征表示的过程,并且可以适应不同的数据分布和任务需求。
表示学习通常分为两种类型:有监督和无监督学习。有监督表示学习是指在有标签数据上学习特征表示,例如卷积神经网络(CNN)在图像分类任务中学习特征表示;无监督表示学习是指在无标签数据上学习特征表示,例如自编码器(Autoencoder)在数据压缩和降维任务中学习特征表示。
背景与相关工作
为了指明三元组(s,p,o)是真还是假,我们考虑二元的特征函数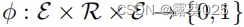 。
。
对于所有(s,p,o)∈KG,我们假设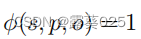 (即KG是一个为真的事实的集合)。然而,在XG中不包含三元组的情况下,它并不意味着相应的事实是假的,而是未知的(开放世界假设)。由于目前使用的大多数KG都是不完整的,因为它们不包含所有的真三元组,或者实际上包含虚假的事实,因此许多经典的机器学习任务都与KG推理有关。
(即KG是一个为真的事实的集合)。然而,在XG中不包含三元组的情况下,它并不意味着相应的事实是假的,而是未知的(开放世界假设)。由于目前使用的大多数KG都是不完整的,因为它们不包含所有的真三元组,或者实际上包含虚假的事实,因此许多经典的机器学习任务都与KG推理有关。
KG推理可以大致分为以下两个任务:
- 缺失三元组的推理(KG完成或链接预测);
- 预测三元组的真值(三元组分类);
虽然这些任务的不同表述通常在文献中找到(例如,完成任务可能涉及预测主体或对象实体以及一对实体之间的关系),但在整个工作中使用以下定义。

许多对KG的机器学习的方法可以被训练在这两种设置中操作。例如,一个三元组分类器 的形式为: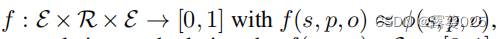
导出了一种由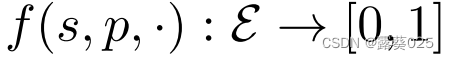 给出的完成方法,其中可以使用不同对象实体的函数值来产生排序。虽然R2D2的体系结构是为三元组分类设计的,但我们证明了它原则上也可以在KG完成设置中工作。
给出的完成方法,其中可以使用不同对象实体的函数值来产生排序。虽然R2D2的体系结构是为三元组分类设计的,但我们证明了它原则上也可以在KG完成设置中工作。
Triple Classifier(三元组分类器)
指一种用于对知识图谱中三元组进行分类的算法或模型。
Triple Classifier的目标是对给定的三元组进行分类,即判断该三元组是否正确或者是否存在错误。这种分类通常包括以下几个类别:
正确的三元组:表示该三元组在知识图谱中存在,并且与实际世界的事实相符合。
错误的三元组:表示该三元组在知识图谱中不存在,或者与实际世界的事实不符合。
不确定的三元组:表示该三元组的正确性无法确定,需要进一步的验证和确认。
表示学习是一种有效且流行的技术,是许多KG精化方法的基础。其基本思想是将实体和关系投影到低维向量空间中,然后将三元组的可能性建模为嵌入空间上的函数。
最近提出了多跳推理方法 MINERVA,这与我们的工作有很大关系,其基本思想是向代理显示查询主题和谓词,并让他们执行策略引导的遍历以找到正确的对象实体。MINERVA产生的路径也导致了某种程度的可解释性。然而,我们发现,只有积极挖掘论文和对立论点,从而暴露辩论的双方,才能让用户做出明智的决定。为这两个位置挖掘证据也可以被视为对抗性特征生成,使分类器(判断)对矛盾证据或损坏的数据具有鲁棒性。
我们的方法
我们根据两个对立主体之间的距离来制定三元组分类的任务。
因此,一个查询三元组对应于辩论的中心陈述。代理通过挖掘KG上的路径来进行,这些路径为论文或对立面提供了证据。
更准确地说,他们顺序遍历图,并根据考虑 过去转换(Past Transition) 和查询三元组的策略选择下一跳。这个转换将添加到当前路径,从而扩展参数。所有路径都由一个名为裁判的二进制分类器处理,该分类器试图根据代理提供的参数来区分真三元组和假三元组。
辩论的主要步骤可以概括如下:
- 辩论围绕着一个三元组问题向两个代理人提出。
- 两位代理人轮流从KGs中提取路径,作为论文和对立面的论据。
- 裁判将自变量与查询三元组一起处理,并估计查询三元组的真值。
当裁判的参数通过监督式学习来进行拟合的时候,两个代理(Agent)都是通过强化学习(Reinforcement Learning)算法训练来实现在图中导航的。通过下面列出的固定范围决策过程对代理的学习任务进行建模。
Past Transition(过去转化)
指在逻辑推理中,将一个谓词的过去时态转化为现在时态,以便进行推理和推导。过去时态和现在时态在语法形式上有所不同,但是它们在语义上是等价的,可以互相转化。
在知识推理中,经常需要使用过去时态描述过去的事件或状态,但是在逻辑推理中,过去时态无法直接参与推理。因此,需要使用Past Transition将过去时态转化为现在时态,以便进行推理和推导。例如,将“John was a student”(John曾经是学生)转化为“John is a student”(John是学生),以便在推理过程中使用。
Past Transition通常包括以下几个步骤:
识别谓词的过去时态:首先需要识别谓词的过去时态形式,例如“was”、“had”等。
转化为现在时态:将过去时态转化为现在时态,例如将“was”转化为“is”。
修改主语:根据需要,可能需要修改主语的人称和数,以便与现在时态一致。
在机器学习中,监督式学习是一种通过给定输入和输出数据,训练模型来预测新数据的方法。在监督式学习中,通常需要定义一个模型和一组参数,然后通过训练数据来拟合这些参数,使得模型能够准确地预测输出结果。
在评判者的场景中,也需要使用模型和参数来评估和判断某个对象或行为的好坏。这些参数可以通过监督式学习的方法来进行拟合,以实现更准确的评判和判断。
相关文章:
【无标题】使用Debate Dynamics在知识图谱上进行推理(2020)7.31
使用Debate Dynamics在知识图谱上进行推理 摘要介绍背景与相关工作我们的方法 摘要 我们提出了一种新的基于 Debate Dynamics 的知识图谱自动推理方法。 其主要思想是将三重分类任务定义为两个强化学习主体之间的辩论游戏,这两个主体提取论点(知识图中…...

windows下若依vue项目部署
下载若依项目,前端后端项目本地启动前端打包,后端打包配置nginx.conf 需要注意的是:路径别用中文,要不然报错 #前台访问地址及端口80,在vue.config.js中可查看server {listen 80;server_name localhost; #后台…...
【目标检测】基于yolov5的水下垃圾检测(附代码和数据集,7684张图片)
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就…...

P1734 最大约数和
题目描述 选取和不超过 S 的若干个不同的正整数,使得所有数的约数(不含它本身)之和最大。 输入格式 输入一个正整数 S。 输出格式 输出最大的约数之和。 输入输出样例 输入 11 输出 9 说明/提示 【样例说明】 取数字 4 和 6&a…...

Excel将单元格中的json本文格式化
打开Excel文件并按下ALT F11打开Visual Basic for Applications(VBA)编辑器。 输入下面的代码 Sub FormatJSONCells()Dim cell As RangeDim jsonString As StringDim json As ObjectDim formattedJSON As String 循环遍历选定的单元格范围For Each ce…...
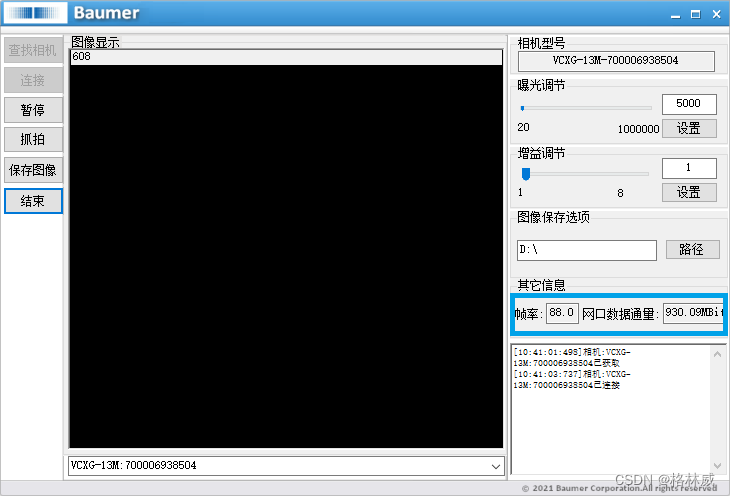
Baumer工业相机堡盟工业相机如何通过BGAPI SDK获取相机当前实时帧率(C#)
Baumer工业相机堡盟工业相机如何通过BGAPISDK里函数来计算相机的实时帧率(C#) Baumer工业相机Baumer工业相机的帧率的技术背景Baumer工业相机的帧率获取方式CameraExplorer如何查看相机帧率信息在BGAPI SDK里通过函数获取相机帧率 Baumer工业相机通过BGA…...
XGBoost的基础思想与实现
目录 1. XGBoost VS 梯度提升树 1.1 XGBoost实现精确性与复杂度之间的平衡 1.2 XGBoost极大程度地降低模型复杂度、提升模型运行效率 1.3 保留了部分与梯度提升树类似的属性 2. XGBoost回归的sklearnAPI实现 2.1 sklearn API 实现回归 2.2 sklearn API 实现分类 3. XGBo…...

【Docker】Docker的服务更新与发现
consul 一、服务注册与发现1. 服务注册与发现的概念2. 服务发现的机制二、consul 的概念1. 什么是 consul2. consul 的特性三、consul 的部署1. consul 服务器架构2. consul 的部署过程2.1 环境配置2.2 consul 服务器建立 Consul 服务查看集群信息通过 http api 获取集群信息2.…...
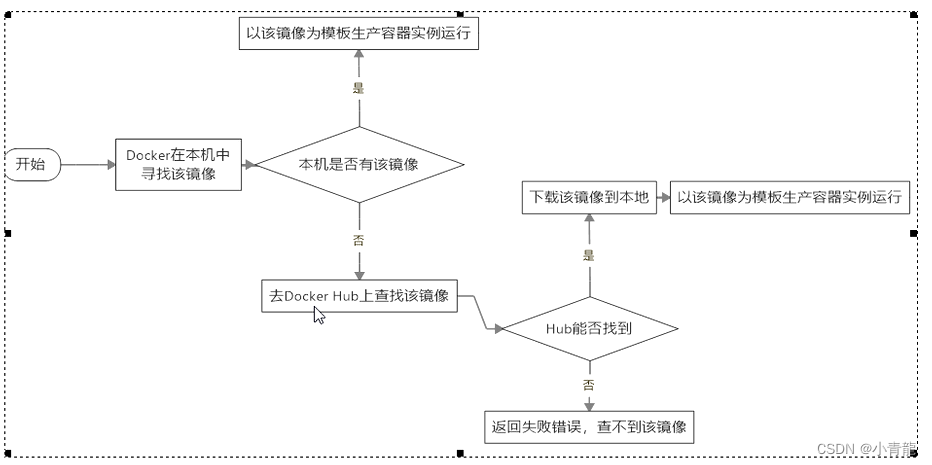
【Docker 学习笔记】Docker架构及三要素
文章目录 一、Docker 简介二、Docker 架构1. Docker 客户端和服务器2. Docker 架构图3. Docker 运行流程图 三、Docker 三要素1. 镜像(Image)2. 容器(Container)3. 仓库(Repository) 一、Docker 简介 Dock…...
matlab编程实践14、15
目录 数独 "四独"游戏 解的存在和唯一性 算法 常微分方程 数独 采用蛮力试凑法来解决数独问题。(采用单选数,以及计算机科学技术中的递推回溯法) 以上的数独是图14-2的两个矩阵的和,左侧的矩阵可以由kron和magic函…...

C++ ——STL容器【list】模拟实现
代码仓库: list模拟实现 list源码 数据结构——双向链表 文章目录 🍇1. 节点结构体🍈2. list成员🍉3. 迭代器模板🍊4. 迭代器🍋5. 插入删除操作🍌5.1 insert & erase🍌5.2 push_…...

ubuntu 16.04 安装mujoco mujoco_py gym stable_baselines版本问题
ubuntu 16.04系统 Python 3.7.16 mujoco200 (py37mujoco) abc123:~/github/spinningup$ pip list Package Version Editable project location ----------------------------- --------- --------------------------- absl-py …...
技术)
自然语言处理(NLP)技术
自然语言处理技术是一种人工智能技术,它的目标是使计算机能够理解、分析、处理和生成自然语言(人类使用的语言)。NLP技术包括文本分类、情感分析、机器翻译、语音识别、语音合成、信息检索、信息抽取、问答系统等。NLP技术的应用非常广泛&…...
如何将ubuntu LTS升级为Pro
LTS支持周期是5年; Pro支持周期是10年。 Ubuntu Pro专业版笔记 步骤: 打开“软件和更新” 可以看到最右侧的标签是Ubuntu Pro。 在没有升级之前,如果使用下面两步: sudo apt updatesudo apt upgrade 出现如下提示ÿ…...
如何学习ARM嵌入式开发?
ARM和单片机还是有许多区别的,可以说比单片机的应用更为复杂吧,往往在单片机里只需要对一个寄存器赋值就可以的初始化,在ARM下就要调用库函数了。甚至每个引脚其功能都多了许多,相应的配置也会更为麻烦,但如果做多了AR…...

二、使用运行自己的docker python容器环境
第一篇参考: https://blog.csdn.net/weixin_42357472/article/details/131953866 运行容器同时执行命令或脚本 1)这是打开一个对外的jupyter notebook容器环境 docker run -d --name my_container -p 8090:8888 mynewpythonimage jupyter notebook --…...

mac版窗口管理 Magnet for mac中文最新
magnet mac版是一款运行在苹果电脑上的一款优秀的窗口大小控制工具,拖拽窗口到屏幕边缘可以自动半屏,全屏或者四分之一屏幕,还可以设定快捷键完成分屏。这款专业的窗口管理工具当您每次将内容从一个应用移动到另一应用时,当您需要…...
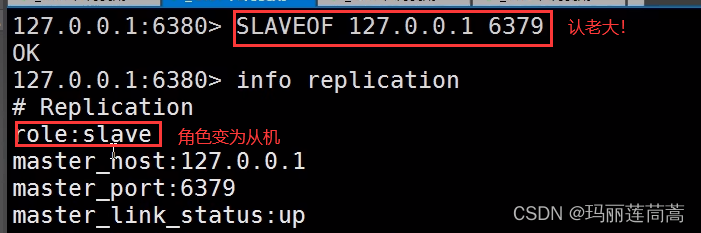
Redis(五)—— Redis进阶部分
一、Redis配置文件详解 注意这是Redis服务本身的配置文件,相当于maven的settings.xml,而不是我们在springboot去配置Redis的那个application.yml。 核心部分include 引入其他redis配置文件,相当于spring的<import>bind 设置IP…...

Go Ethereum源码学习笔记000
Go Ethereum源码学习笔记 前言时代的弄潮儿: Blockchain为什么要研究以太坊& Go-Ethereum 的原理 前言 这个专栏的内容是免费的,因为自己这边都是基于开源库和开源内容整理的学习笔记,在这个过程中进行增删改查,将自己的理解融入其中&am…...

layui 设置选中时间为当天时间最大值23:59:59、laydate设置选中时间为当天时间最大值23:59:59
既是涨知识的一天,又是干前端的一天! laydate.render({ elem: #validityPeriod, //type: datetime,//类型要一定要相匹配 type: date, // 设置日期选择模式 trigger: click, format: yyyy-MM-dd HH:mm:ss, // 设置日期的显示格式 min: startDate, max: …...

Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别
Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维…...

镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书
镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书副标题:聚合动态三维实时重构、无感厘米级定位、全域跨镜连续追踪、身体指纹生物核验四大自研核心,一站式覆盖楼宇、仓储、硐室全场景透明智能管控前言当下城市建筑楼宇、物资仓储…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

Bifrost:轻量高效的实时数据同步平台架构与实战
1. 项目概述:Bifrost,一个被低估的现代数据同步利器如果你正在处理跨数据库、跨数据源的数据同步任务,并且对传统ETL工具的笨重、配置复杂感到头疼,那么maximhq/bifrost这个项目绝对值得你花时间深入了解。我第一次接触Bifrost是在…...

Cursor编辑器性能优化:精准重置缓存与进程的开发者效率工具
1. 项目概述:一个被低估的开发者效率工具如果你是一名开发者,尤其是深度使用 Cursor 这类 AI 驱动的代码编辑器,那么你一定遇到过这样的场景:编辑器突然变得卡顿、代码补全失灵、AI 建议变得驴唇不对马嘴,或者插件行为…...
)
用STM32+LoRa+阿里云IoT Studio,我DIY了一个低成本畜牧电子围栏(附完整代码)
基于STM32与LoRa的智能畜牧围栏系统开发实战 在广袤的牧区,牲畜走失一直是困扰牧民的核心问题。传统物理围栏不仅成本高昂,在草原这类开放地形中实施难度也很大。本文将详细介绍如何利用STM32微控制器、LoRa远距离通信模块和阿里云IoT Studio平台&#x…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十三)用户指引自助教学源码—东方仙盟
代码<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" content"IEedge,chrome1"> <title>你的导师-未来之窗</title> <style>*…...
)
【2026年阿里巴巴集团暑期实习- 5月16日-算法岗-第二题- 坏掉的键盘】(题目+思路+JavaC++Python解析+在线测试)
题目内容 小明准备输入一个仅由小写英文字母组成的字符串,但他的键盘在一开始就有且仅有一个按键失灵,导致该字母在原串中的所有出现都没有被输入,最终得到的字符串为 sss。小明还告诉你:原本要输入的完整字符串中任意相邻两个字符都不相同。 请你计算,对于每一个可能的…...

面试鸭:程序员面试备战工作台,构建结构化知识图谱与智能复习系统
1. 项目概述:一个面向求职者的“面试鸭”最近在技术社区里,看到不少朋友在讨论一个叫“mianshiya”的开源项目。乍一看这个名字,还以为是哪个美食博主分享的菜谱。点进去才发现,这其实是一个为程序员,特别是正在准备面…...