[PyTorch][chapter 45][RNN_2]
目录:
- RNN 问题
- RNN 时序链问题
- RNN 词组预测的例子
- RNN简洁实现
一 RNN 问题
RNN 主要有两个问题,梯度弥散和梯度爆炸
1.1 损失函数
梯度
其中:
则
1.1 梯度爆炸(Gradient Exploding)
上面矩阵进行连乘后k,可能会出现里面参数会变得极大

解决方案:
梯度剪裁:对W.grad进行约束

def print_current_grad(model):for w in model.parameters():print(w.grad.norm())loss.criterion(output, y)
model.zero_grad()
loss.backward()
print_current_grad(model)
torch.nn.utils.clip_grad_norm_(p,10)
print_current_grad(model)
optimizer.step()
1.2 梯度弥散(Gradient vanishing)
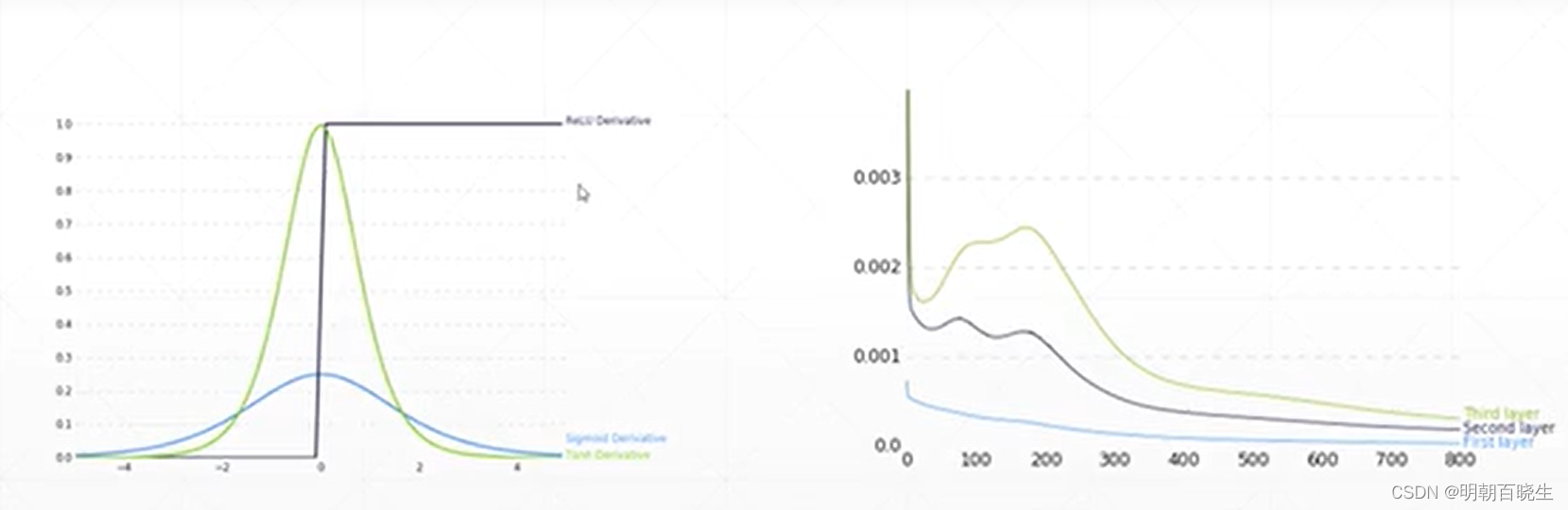
是由于时序链过程,导致梯度为0,前面的层参数无法更新。
解决方案 :
LSTM.
二 RNN 时序链问题
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 24 15:12:49 2023@author: chengxf2
"""import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
import matplotlib.pyplot as plt # 导入作图相关的包'''生成训练的数据集
return x: 当前时刻的输入值[batch_size=1, time_step=num_time_steps-1, feature=1]y: 当前时刻的标签值[batch_size=1, time_step=num_time_steps-1, feature=1]
'''
def sampleData():#生成一个[0-3]之间的数据start = np.random.randint(3,size=1)[0]num_time_steps =20#时序链长度为num_time_stepstime_steps= np.linspace(start, start+10,num_time_steps)data = np.sin(time_steps)data = data.reshape(num_time_steps,1)#[batch, seq, dimension]x= torch.tensor(data[:-1]).float().view(1,num_time_steps-1,1)y= torch.tensor(data[1:]).float().view(1, num_time_steps-1,1)return x,y,time_steps'''网络模型args:input_size – 输入x的特征数量。hidden_size – 隐藏层的特征数量。num_layers – RNN的层数。nonlinearity – 指定非线性函数使用tanh还是relu。默认是tanh。bias – 默认是Truebatch_first – 如果True的话,那么输入Tensor的shape应该是[batch_size, time_step, feature],输出也是这样。默认是Falsedropout – 如果值非零,那么除了最后一层外,其它层的输出都会套上一个dropout层。bidirectional – 如果True,将会变成一个双向RNN,默认为False。
'''
class Net(nn.Module):def __init__(self,input_dim = 1, hidden_dim =10, out_dim = 1):super(Net, self).__init__()self.rnn= nn.RNN(input_size = input_dim, hidden_size = hidden_dim,num_layers = 1,batch_first = True)self.linear= nn.Linear(in_features= hidden_dim, out_features=out_dim)#前向传播函数def forward(self,x,hidden_prev):# 给定一个h_state初始状态,(batch_size=1,layer=1,hidden_dim=10)# 给定一个序列x.shape:[batch_size, time_step, feature]hidden_dim =10#print("\n x.shape",x.shape)out,hidden_prev= self.rnn(x,hidden_prev)out = out.view(-1,hidden_dim) #[1,seq,h]=>[1*seq,h]out = self.linear(out)#[seq,h]=>[seq,1]out = out.unsqueeze(dim=0) #[seq,1] 指定的维度上面添加一个维度[batch=1,seq,1]return out, hidden_prevdef main():model = Net()criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(),lr=1e-3)hidden_dim =10#初始值hidden_prv = torch.zeros(1,1,hidden_dim)for iter in range(5000):x,y,time_steps =sampleData() #[batch=1,seq=99,dim=1]output, hidden_prev =model(x,hidden_prv)hidden_prev = hidden_prev.detach()loss = criterion(output, y)model.zero_grad()loss.backward()optimizer.step()if iter %100 ==0:print("Iter:{} loss{}".format(iter, loss.item()))# 对最后一次的结果作图查看网络的预测效果plt.plot(time_steps[0:-1], y.flatten(), 'r-')plt.plot(time_steps[0:-1], output.data.numpy().flatten(), 'b-')
main()三 RNN 词组预测的例子
这是参考李沐写得一个实现nn.RNN功能的例子
,一般很少用,都是直接用nn.RNN.
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 26 14:17:49 2023@author: chengxf2
"""import math
import torch
from torch import nn
from torch.nn import functional as F
import numpy
import d2lzh_pytorch as d2l#生成随机变量
def normal(shape,device):return torch.randn(size=shape, device=device)*0.01#模型需要更新的权重系数
def get_params(vocab_size=27, num_hiddens=10, device='cuda:0'):num_inputs = num_outputs = vocab_sizeW_xh = normal((num_inputs,num_hiddens),device)W_hh = normal((num_hiddens,num_hiddens),device)b_xh = torch.zeros(num_hiddens,device=device)b_hh = torch.zeros(num_hiddens,device=device)W_hq = normal((num_hiddens,num_outputs),device)b_q = torch.zeros(num_outputs, device= device)params = [W_xh,W_hh, b_xh,b_hh, W_hq,b_q]for param in params:param.requires_grad_(True)return params#初始的隐藏值 hidden ,tuple
def init_rnn_state(batch_size, hidden_size, device):h_init= torch.zeros((batch_size,hidden_size),device=device)return (h_init,)#RNN 函数定义了如何在时间序列上更新隐藏状态和输出
def rnn(X, h_init, params):W_xh,W_hh, b_xh,b_hh, W_hq,b_q = paramshidden, = h_initoutputs =[]for x_t in X:z_t = torch.mm(x_t, W_xh)+b_xh+ torch.mm(x_t,W_hh)+b_hhhidden =torch.tanh(z_t)out = torch.mm(hidden,W_hq)+b_qoutputs.append(out)#[batch_size*T, dimension]return torch.cat(outputs, dim=0),(hidden,)#根据给定的词,预测后面num_preds 个词
def predict_ch8(prefix, num_preds, net, vocab, device):#生成初始状态state = net.begin_state(batch_size=1, device=device)#把第一个词拿出来outputs = [vocab[prefix[0]]]get_input = lambda: torch.tensor([outputs[-1]],device=device,(1,1))for y in prefix[1:]:_,state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds):y, state = net(get_input(), state)outputs, (int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idex_to_toke[i] for i in output])#梯度剪裁def grad_clipping(net, theta):if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad_]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad**2)) for p in params)if norm > theta:for param in params:param.grad[:]*=theta/normclass RNNModel:#从零开始实现RNN 网络模型#def __init__(self, vocab_size, hidden_size, device, get_params, init_rnn_state,forward_fn):forward_fnself.vocab_size = vocab_size, self.num_hiddens = hidden_sizeself.params = get_params(vocab_size, hidden_size, device)self.init_state = init_rnn_state(batch_size, hidden_size, device)self.forwad_fn = forward_fn#X.shape [batch_size,num_steps] def __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)#[num_steps, batch_size]return self.forwad_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)# 训练模型def train_epoch_ch8(net, train_iter, loss, updater, device,)state, timer = None, d21.Timer()metric = d21.Accumulator(2)for X,Y in train_iter:if state is None or use_random_iter:state = net.beign_state(bacth_size=X.shape[0])elseif isinstance(net, nn.Module) and not isinstance(o, t)state.detach_()elsefor s in state:s.detach_()y = Y.T.reshape(-1)X,y = X.to(device),y.to(device)y_hat,state=net(X,state)l = loss(y_hat,y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()elsel.backward()grad_clipping(net, 1)updater(batch_size=1)metric.add(1&y.numel(),y.numel())return math.exp(metric[0]/metric[1]))def train(net, train_iter,vocab, lr,num_epochs, device, use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d21.animator(xlabel='epoch',ylabel='preplexity',legend=['train'],xlim=[10,num_epochs])if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(),lr)else:updater = lambda batch_size: d21.sgd(net.parameters,batch_size,lr)predict = lambda prefix: predict_ch8(prefix, num_preds=50, net, vocab, device)for epoch in range(num_epochs):ppl, spped = train_epoch_ch8(net, train_iter, updater(),use_random_iter())if (epoch+1)%10 ==0:print(predict('time traverller'))animator.add(epoch+1, [ppl])print(f'困惑度{ppl:lf},{speed:1f} 标记/秒')print(predict('time traveller'))print(predict('traveller'))def main():num_hiddens =512num_epochs, ,lr = 500,1vocab_size = len(vocab)#[批量大小,时间步数]batch_size, num_steps = 32, 10train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)F.one_hot(torch.tensor([0,2]), len(vocab))X= torch.arange(10).reshape((2,5))Y = F.one_hot(X.T,28).shape #[step, batch_num]model = RNNModel(vocab_size, num_hiddens, dl2.try_gpu(), get_params, init_rnn_state, rnn) train_ch8(model, train_iter, vocab,lr,num_epochs,dl2.try_gpu())if __name__ == "__main__":main()四 RNN简洁实现
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 28 10:11:33 2023@author: chengxf2
"""import torch
from torch import nn
from torch.nn import functional as Fclass SimpleRNN(nn.Module):def __init__(self,batch_size, input_size, hidden_size,out_size):super(SimpleRNN,self).__init__()self.batch_size,self.num_hiddens = batch_size,hidden_sizeself.rnn_layer = nn.RNN(input_size,hidden_size)self.linear = nn.Linear(hidden_size, out_size)def forward(self, X,state):'''Parameters----------X : [seq,batch, feature]state : [layer, batch, feature]-------#output:(layer, batch_size, hidden_size)state_new : []'''hidden, hidden_new = self.rnn_layer(X, state)hidden = hidden.view(-1, hidden.shape[-1])output = self.linear(hidden)return output ,hiddendef init_hidden_state(self):'''初始化隐藏状态'''state = torch.zeros((1,self.batch_size, self.num_hiddens))return statedef main():seq_len = 3 #时序链长度batch_size =5 #批量大小input_size = 27hidden_size = 10out_size = 9X = torch.rand(size=(seq_len,batch_size,input_size))model = SimpleRNN(batch_size,input_size, hidden_size,out_size)init_state = model.init_hidden_state()output, hidden = model.forward(X, init_state)print("\n 输出值:",output.shape)print("\n 时刻的隐藏状态")print(hidden.shape)if __name__ == "__main__":main()pytorch入门10--循环神经网络(RNN)_rnn代码pytorch_微扬嘴角的博客-CSDN博客
【PyTorch】深度学习实践之 RNN基础篇——实现RNN_pytorch实现rnn_zoetu的博客-CSDN博客
RNN 的基本原理+pytorch代码_rnn代码_黄某某很聪明的博客-CSDN博客
55 循环神经网络 RNN 的实现【动手学深度学习v2】_哔哩哔哩_bilibili
《动手学深度学习》环境搭建全程详细教程 window用户_https://zh.d21.ai/d21-zh-1.1.zip_溶~月的博客-CSDN博客
ModuleNotFoundError: No module named ‘d2l’_卡拉比丘流形的博客-CSDN博客
相关文章:
[PyTorch][chapter 45][RNN_2]
目录: RNN 问题 RNN 时序链问题 RNN 词组预测的例子 RNN简洁实现 一 RNN 问题 RNN 主要有两个问题,梯度弥散和梯度爆炸 1.1 损失函数 梯度 其中: 则 1.1 梯度爆炸(Gradient Exploding) 上面矩阵进行连乘后…...

基于canvas画布的实用类Fabric.js的使用
目录 前言 一、Fabric.js简介 二、开始 1、引入Fabric.js 2、在main.js中使用 3、初始化画布 三、方法 四、事件 1、常用事件 2、事件绑定 3、事件解绑 五、canvas常用属性 六、对象属性 1、基本属性 2、扩展属性 七、图层层级操作 八、复制和粘贴 1、复制 2…...
)
基于SpringBoot+Vue驾校理论课模拟考试系统源码(自动化部署)
DrivingTestSimulation Unity3D Project, subject two, simulated driving test 【更新信息】 更新时间-2021-1-17 解决了方向盘不同机型转动轴心偏离 更新时间-2021-2-18 加入了手刹系统 待更新-2021-6-19(工作太忙少有时间更新,先指出问题…...

SpringBoot使用Redis对用户IP进行接口限流
使用接口限流的主要目的在于提高系统的稳定性,防止接口被恶意打击(短时间内大量请求)。 一、创建限流注解 引入redis依赖 <!--redis--><dependency><groupId>org.springframework.boot</groupId><artifactId&g…...

MeterSphere学习篇
从开发环境部署开始 metersphere-1.20.4 源码下载地址: https://gitee.com/fit2cloud-feizhiyun/MeterSphere/tree/v1.20/ MeterSphere GitHub 相关插件程序下载 相关准备 安装mysql 配置IDEA...

大数据技术之Clickhouse---入门篇---数据类型、表引擎
星光下的赶路人star的个人主页 今天没有开始的事,明天绝对不会完成 文章目录 1、数据类型1.1 整型1.2 浮点型1.3 布尔型1.4 Decimal型1.5 字符串1.6 枚举类型1.7 时间类型1.8 数组 2、表引擎2.1 表引擎的使用2.2 TinyLog2.3 Memory2.4 MergeTree2.4.1 Partition by分…...
【微服务架构设计】微服务不是魔术:处理超时
微服务很重要。它们可以为我们的架构和团队带来一些相当大的胜利,但微服务也有很多成本。随着微服务、无服务器和其他分布式系统架构在行业中变得更加普遍,我们将它们的问题和解决它们的策略内化是至关重要的。在本文中,我们将研究网络边界可…...

天下风云出我辈,AI准独角兽实在智能获评“十大数字经济风云企业
时值盛夏,各地全力拼经济的氛围同样热火朝天。在浙江省经济强区余杭区这片创业热土上,人工智能助力数字经济建设正焕发出蓬勃生机。 7月28日,经专家评审、公开投票,由中共杭州市余杭区委组织部(区委两新工委ÿ…...

SpringBoot2学习笔记
信息来源:https://www.bilibili.com/video/BV19K4y1L7MT?p5&vd_source3969f30b089463e19db0cc5e8fe4583a 作者提供的文档:https://www.yuque.com/atguigu/springboot 作者提供的代码:https://gitee.com/leifengyang/springboot2 ----…...

安达发|APS生产派单系统对数字化工厂有哪些影响和作用
数字化工厂是当今制造业的热门话题,而APS软件则是这一领域的颠覆者。它以其独特的影响和作用,给制造业带来了巨大的改变。让我们一起来看看APS软件对数字化工厂有哪些影响和作用吧! 提高生产效率的神器 1.APS软件作为数字化工厂的核心系统&a…...

状态机的介绍和使用 | 京东物流技术团队
1 状态机简介 1.1 定义 我们先来给出状态机的基本定义。一句话: 状态机是有限状态自动机的简称,是现实事物运行规则抽象而成的一个数学模型。 先来解释什么是“状态”( State )。现实事物是有不同状态的,例如一个自…...
tinkerCAD案例:32. 使用对齐工具构建喷泉
tinkerCAD案例:32. 使用对齐工具构建喷泉 In this lesson, you will practice the basics in Tinkercad, such as move, rotate, and scale. You will also learn how to use the Align Tool. 在本课中,您将练习 Tinkercad 中的基础知识,例如…...
一起学数据结构(2)——线性表及线性表顺序实现
目录 1. 什么是数据结构: 1.1 数据结构的研究内容: 1.2 数据结构的基本概念: 1.2.1 逻辑结构: 1.2.2 存储结构: 2. 线性表: 2.1 线性表的基本定义: 2.2 线性表的运用: 3 .线性…...
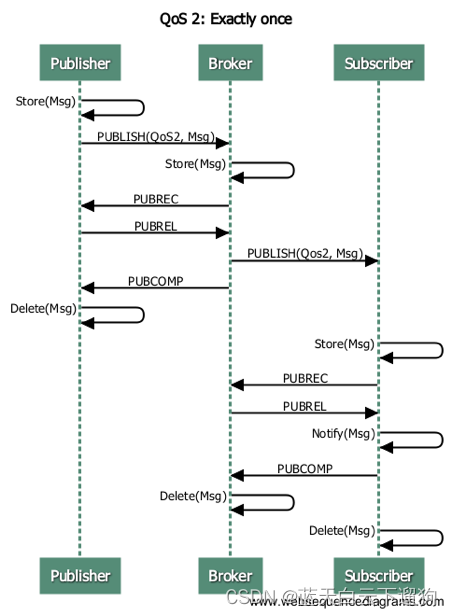
mqtt协议流程图
转载于...
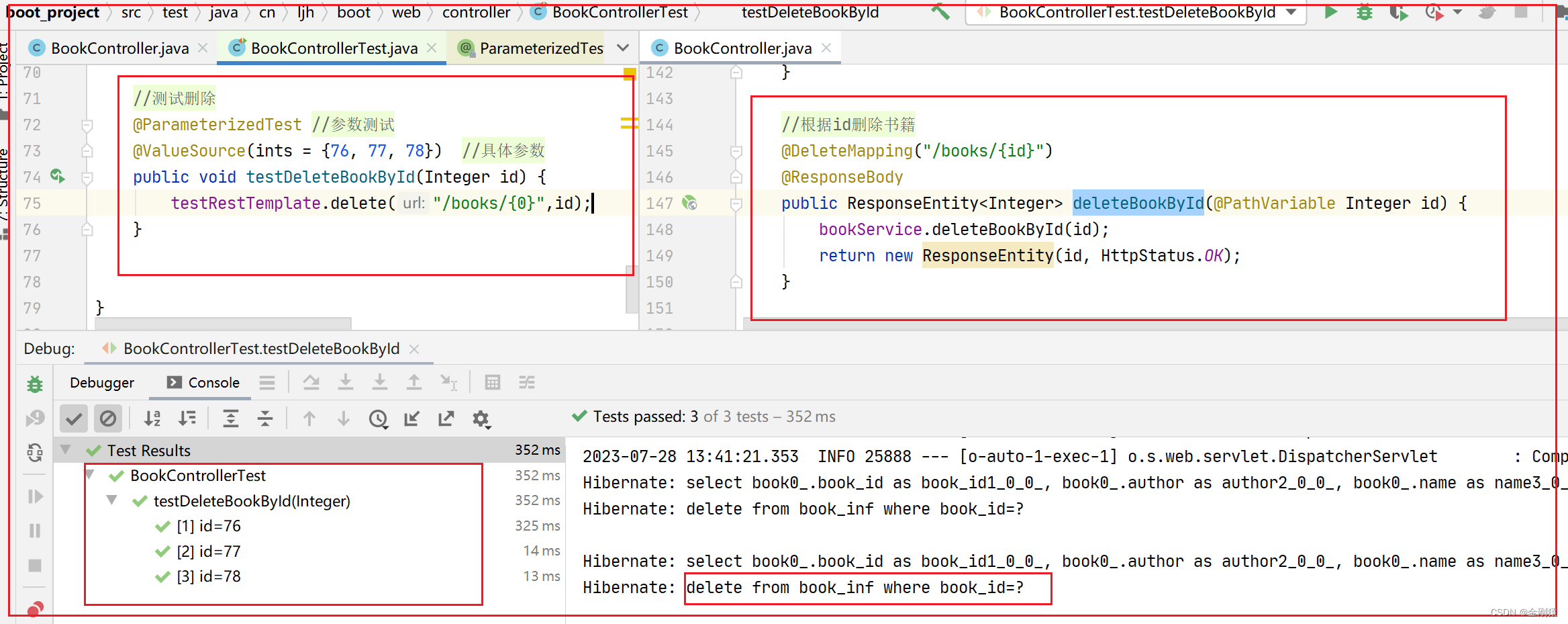
7、单元测试--测试RestFul 接口
单元测试–测试RestFul 接口 – 测试用例类使用SpringBootTest(webEnvironment WebEnvironment.RANDOM_PORT)修饰。 – 测试用例类会接收容器依赖注入TestRestTemplate这个实例变量。 – 测试方法可通过TestRestTemplate来调用RESTful接口的方法。 测试用例应该定义在和被测…...
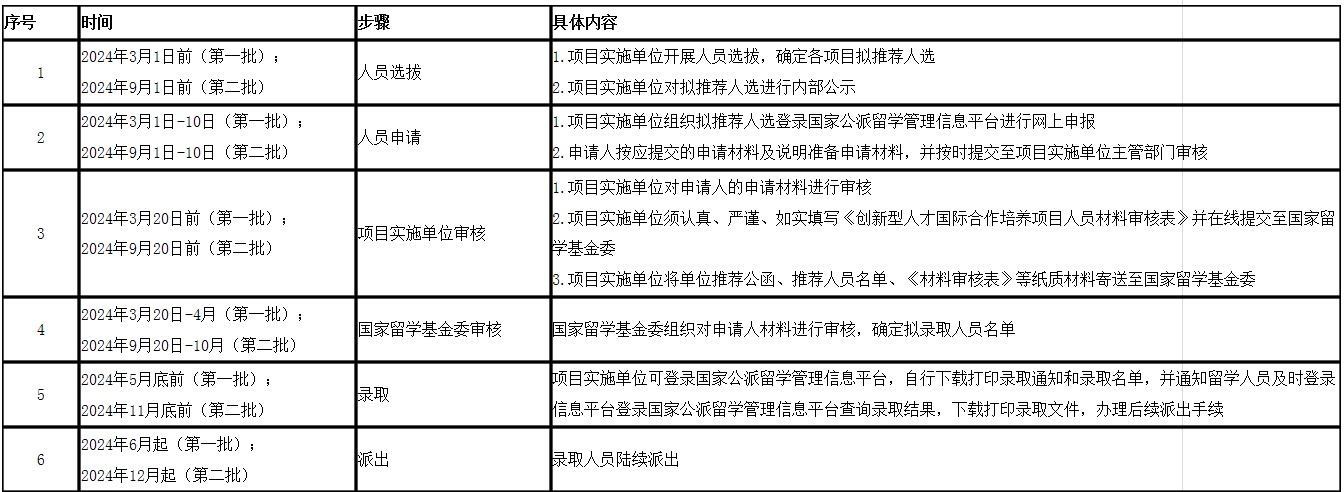
国家留学基金委(CSC)|发布2024年创新型人才国际合作培养项目实施办法
2023年7月28日,国家留学基金委(CSC)发布了《2024年创新型人才国际合作培养项目实施办法》,在此知识人网小编做全文转载。详细信息请参见https://www.csc.edu.cn/chuguo/s/2648。 2024年创新型人才国际合作培养项目实施办法 第一章…...
找好听的配乐、BGM就上这6个网站,免费商用。
推荐几个音乐素材网站给你,各种类似、风格的都有,而且免费下载,还可以商用,建议收藏起来~ 菜鸟图库 https://www.sucai999.com/audio.html?vNTYxMjky 站内有上千首音效素材,网络流行的音效素材这里都能找到…...

【前端知识】React 基础巩固(三十五)——ReduxToolKit (RTK)
React 基础巩固(三十五)——ReduxToolKit (RTK) 一、RTK介绍 Redux Tool Kit (RTK)是官方推荐的编写Redux逻辑的方法,旨在成为编写Redux逻辑的标准方式,从而解决上面提到的问题。 RTK的核心API主要有如下几个: confi…...
android Android Studio Giraffe | 2022.3.1 版本Lombok不兼容 解决方案
android Android Studio Giraffe | 2022.3.1 版本Lombok不兼容 解决方案 1.查看当前的android studio 版本 Android Studio Giraffe | 2022.3.1 Build #AI-223.8836.35.2231.10406996, built on June 29, 2023 2.打开 idea 官网下载页面 idea下载历史版本 找到对应的版本编号…...

前端框架学习-基础前后端分离
前端知识栈 前端三要素:HTML、CSS、JS HTML 是前端的一个结构层,HTML相当于一个房子的框架,可类比于毛坯房只有一个结构。CSS 是前端的一个样式层,有了CSS的装饰,相当于房子有了装修。JS 是前端的一个行为层ÿ…...

AI 项目经理 Agent:拆解任务、分配资源与监控风险
AI项目经理Agent:拆解任务、分配资源与监控风险的全流程落地指南从GPT-4发布以来,“AI替代白领”的声音此起彼伏,但作为一名在互联网大厂带过3个亿级SaaS交付项目、同时搞了2年AI辅助项目管理(AIPM)落地的软件工程师&a…...

基于CircuitPython与PyPortal的交互式冒险游戏开发实战
1. 项目概述与核心价值如果你对嵌入式开发感兴趣,但又觉得从点灯、读传感器开始有些枯燥,或者你是一位创客、教育者,想找一个能融合编程、故事创作和硬件交互的趣味项目,那么基于CircuitPython和PyPortal的交互式冒险游戏开发&…...

基于CRICKIT与CircuitPython的蛇形机器人避障项目实践
1. 项目概述与核心思路最近在捣鼓一个挺有意思的创客项目:用Adafruit的CRICKIT扩展板和CircuitPython,做一个能自己溜达、遇到障碍会躲开的蛇形机器人。这玩意儿听起来复杂,其实拆解开来,核心就是“感知-决策-执行”这个经典的控制…...

Amphenol ICC RJE1Y62A8327E401线束解析
在工业自动化、通信系统和高端电子设备中,线束组件不仅是连接器件的基础,更是保证系统信号完整性、电源稳定性和长期可靠运行的关键部件。今天,我们深度解析Amphenol ICC (Commercial Products)旗下的工业级线束型号RJE1Y62A8327E401…...

ChatGPT插件开发者签证通道开放?深度解析2026年美国USCIS新增O-1B“AI原生应用架构师”认证路径
更多请点击: https://intelliparadigm.com 第一章:ChatGPT插件生态系统的演进脉络与O-1B新政战略定位 ChatGPT插件系统自2023年3月开放以来,经历了从封闭API集成到开放开发者协议、再到平台化治理的三阶段跃迁。早期插件依赖硬编码函数调用&…...

车载网络测试演进:从CAN总线到TSN与SOA的实战解析
1. 项目概述:一场关于“神经”与“体检”的进化史几年前,我和几个同行在路边摊就着麻小和扎啤,聊起车载以太网测试,那时它还是个新鲜玩意儿,大家讨论的焦点更多是“要不要做”和“怎么做”。几年过去,再回头…...

电源扰动测试与功率分析仪应用实践
1. 电源扰动测试的核心价值与行业需求在电力电子产品的研发验证阶段,电源扰动测试是评估设备可靠性的关键环节。我曾在某工业电源模块项目中,因忽视电源扰动测试导致产品在东南亚市场出现大规模故障——当地电网电压频繁跌落至170V,使得我们的…...

Diablo Edit2终极指南:如何轻松编辑暗黑破坏神2角色存档
Diablo Edit2终极指南:如何轻松编辑暗黑破坏神2角色存档 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 暗黑破坏神2作为经典的动作角色扮演游戏,拥有庞大的玩家群体。然而…...

ARM异常处理机制与ESR寄存器详解
1. ARM异常处理机制概述在ARMv8/v9架构中,异常处理是处理器响应硬件或软件事件的核心机制。当发生异常时,处理器会暂停当前程序执行,跳转到预定义的异常向量表入口,同时将异常相关信息记录在异常综合征寄存器(ESR)中。异常可能由多…...

达梦数据库主备集群手工搭建及主备切换演练
环境:DM8、Linux(CentOS 7 ),三台服务器。 本文记录从零搭一套"一主一备一监视" 式的主备集群,纯手工操作,不依赖图形化工具。 一、环境规划 1.1 IP规划 角色主机名业务IP心跳IP实例名主库&…...