异步检索在 Elasticsearch 中的理论与实践
异步检索在 Elasticsearch 中的理论与实践
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/async-search.html#submit-async-search
引言
Elasticsearch 是一种强大的分布式搜索和分析引擎,它能够快速地存储、搜索和分析大量数据。在处理大规模数据时,性能和响应时间变得至关重要。为了提高搜索和查询操作的效率,Elasticsearch 支持异步检索。本文将深入探讨异步检索在 Elasticsearch 中的理论原理,展示如何在实践中使用它,并提供使用场景和注意事项。
什么是异步检索?
在传统的同步搜索中,当客户端发出一个查询请求后,它需要等待 Elasticsearch 返回所有匹配结果才能继续处理其他任务。而异步检索允许客户端发起一个查询请求后,不必等待搜索结果立即返回,而是可以继续执行其他操作。Elasticsearch 在后台处理这个查询请求,当查询完成后,客户端会得到一个响应。
异步检索的优点在于它能够显著提高搜索和查询操作的性能和响应时间,特别是在处理大量数据或复杂查询时。
添加测试数据
使用python3脚本完成,根据github修改而来
https://github.com/oliver006/elasticsearch-test-data
生成测试数据脚本见文章末尾
执行命令
python3 es_test_data.py --es_url=http://127.0.0.1:9200 --count=1000000
如何使用异步检索?
1. 创建异步搜索任务
在 Elasticsearch 中,使用异步检索需要创建一个异步搜索任务。你可以通过发送一个异步搜索请求来创建任务。以下是一个使用 Elasticsearch 的 REST API 发起异步搜索请求的示例:
POST /test_data/_async_search?size=0
{"sort": [{ "last_updated": { "order": "asc" } }],"aggs": {"sale_date": {"date_histogram": {"field": "last_updated","calendar_interval": "1d"}}}
}
在上述示例中,我们向名为 test_data 的索引提交了一个异步搜索请求,该请求使用简单的匹配查询来查找包含特定值的文档。
相应内容如下,注意ID的值即可
如果看不到
ID的值,再加一部分数据量再次检索即可
{"id" : "FjU0SDlRSFZ2UTdxZUpkaFdLSF9hOVEdZzBVS3hmd1FTWEc3VmpCc1gzZFZhdzo2NDI0Mzg=","is_partial" : true,"is_running" : true,"start_time_in_millis" : 1690808656033,"expiration_time_in_millis" : 1691240656033,"response" : {"took" : 1001,"timed_out" : false,"terminated_early" : false,"num_reduce_phases" : 0,"_shards" : {"total" : 1,"successful" : 0,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "gte"},"max_score" : null,"hits" : [ ]}}
}
2. 获取异步搜索结果
一旦创建了异步搜索任务,你可以轮询获取任务的结果。Elasticsearch 返回一个任务 ID(上一步返回的ID),你可以使用这个 ID 来检索结果。以下是获取异步搜索结果的示例:
GET /_async_search/<task_id>GET /_async_search/FjU0SDlRSFZ2UTdxZUpkaFdLSF9hOVEdZzBVS3hmd1FTWEc3VmpCc1gzZFZhdzo2NDI0Mzg=
在上述示例中,我们使用 <task_id> 来获取异步搜索任务的状态。
3. 获取异步搜索的状态
获取异步搜索结果后,可以对结果进行处理和解析。通常,结果会以 JSON 格式返回,其中包含搜索的匹配文档、聚合信息等。仅仅是在url中加入status
GET /_async_search/status/FjU0SDlRSFZ2UTdxZUpkaFdLSF9hOVEdZzBVS3hmd1FTWEc3VmpCc1gzZFZhdzo2NDI0Mzg=
返回结果如下
{"id" : "FjU0SDlRSFZ2UTdxZUpkaFdLSF9hOVEdZzBVS3hmd1FTWEc3VmpCc1gzZFZhdzo2NDI0Mzg=","is_running" : false,"is_partial" : false,"start_time_in_millis" : 1690808656033,"expiration_time_in_millis" : 1691240656033,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"completion_status" : 200
}
4. 删除异步检索
DELETE /_async_search/FjU0SDlRSFZ2UTdxZUpkaFdLSF9hOVEdZzBVS3hmd1FTWEc3VmpCc1gzZFZhdzo2NDI0Mzg=
使用场景
异步检索在以下场景中特别有用:
-
大数据量搜索: 当索引包含大量数据时,同步搜索可能会导致请求阻塞并增加响应时间。异步检索能够提高搜索性能,让客户端可以并发处理其他任务。
-
复杂查询: 复杂的搜索查询可能需要更长的处理时间。通过使用异步检索,可以避免客户端长时间等待,提高用户体验。
-
定时任务: 如果你需要定期执行一些查询,并将结果导出或进行其他操作,异步检索可以让你更加灵活地处理这些任务。
使用注意事项
虽然异步检索提供了很多好处,但在使用时也需要注意以下事项:
-
任务状态管理: 确保正确地管理异步搜索任务的状态。任务可能处于不同的状态,包括运行中、完成和失败。及时清理已经完成或失败的任务,避免资源浪费。
-
任务结果有效性: 确保处理异步搜索结果时,对结果进行有效性验证和解析。避免因错误处理结果而导致数据不一致或错误的分析。
-
资源限制: 异步检索仍然占用服务器资源,特别是在处理大量并发任务时。确保服务器资源足够以支持异步检索的需求。
-
超时和重试: 考虑到网络或其他故障可能导致异步搜索请求失败,需要合理设置超时时间并实现重试机制,以确保请求的可靠性。
结论
异步检索是 Elasticsearch 中一个强大且实用的特性,可以显著提高搜索和查询操作的性能,特别在处理大规模数据或复杂查询时。在使用异步检索时,注意合理管理任务状态、验证结果有效性,并注意资源限制和错误处理。合理地应用异步检索,能为我们的应用程序带来更高效的搜索和分析功能。
测试脚本
#!/usr/bin/pythonimport nest_asyncio
nest_asyncio.apply()import json
import csv
import time
import logging
import random
import string
import uuid
import datetimeimport tornado.gen
import tornado.httpclient
import tornado.ioloop
import tornado.optionstry:xrangerange = xrange
except NameError:passasync_http_client = tornado.httpclient.AsyncHTTPClient()
headers = tornado.httputil.HTTPHeaders({"content-type": "application/json"})
id_counter = 0
upload_data_count = 0
_dict_data = Nonedef delete_index(idx_name):try:url = "%s/%s?refresh=true" % (tornado.options.options.es_url, idx_name)request = tornado.httpclient.HTTPRequest(url, headers=headers, method="DELETE", request_timeout=240, auth_username=tornado.options.options.username, auth_password=tornado.options.options.password, validate_cert=tornado.options.options.validate_cert)response = tornado.httpclient.HTTPClient().fetch(request)logging.info('Deleting index "%s" done %s' % (idx_name, response.body))except tornado.httpclient.HTTPError:passdef create_index(idx_name):schema = {"settings": {"number_of_shards": tornado.options.options.num_of_shards,"number_of_replicas": tornado.options.options.num_of_replicas},"refresh": True}body = json.dumps(schema)url = "%s/%s" % (tornado.options.options.es_url, idx_name)try:logging.info('Trying to create index %s' % (url))request = tornado.httpclient.HTTPRequest(url, headers=headers, method="PUT", body=body, request_timeout=240, auth_username=tornado.options.options.username, auth_password=tornado.options.options.password, validate_cert=tornado.options.options.validate_cert)response = tornado.httpclient.HTTPClient().fetch(request)logging.info('Creating index "%s" done %s' % (idx_name, response.body))except tornado.httpclient.HTTPError:logging.info('Looks like the index exists already')pass@tornado.gen.coroutine
def upload_batch(upload_data_txt):try:request = tornado.httpclient.HTTPRequest(tornado.options.options.es_url + "/_bulk",method="POST",body=upload_data_txt,headers=headers,request_timeout=tornado.options.options.http_upload_timeout,auth_username=tornado.options.options.username, auth_password=tornado.options.options.password, validate_cert=tornado.options.options.validate_cert)response = yield async_http_client.fetch(request)except Exception as ex:logging.error("upload failed, error: %s" % ex)returnresult = json.loads(response.body.decode('utf-8'))res_txt = "OK" if not result['errors'] else "FAILED"took = int(result['took'])logging.info("Upload: %s - upload took: %5dms, total docs uploaded: %7d" % (res_txt, took, upload_data_count))def get_data_for_format(format):split_f = format.split(":")if not split_f:return None, Nonefield_name = split_f[0]field_type = split_f[1]return_val = ''if field_type == 'arr':return_val = []array_len_expr = split_f[2]if '-' in array_len_expr:(min,max) = array_len_expr.split('-')array_len = generate_count(int(min), int(max))else:array_len = int(array_len_expr)single_elem_format = field_name + ':' + format[len(field_name) + len(field_type) + len(array_len_expr) + 3 : ]for i in range(array_len):x = get_data_for_format(single_elem_format)return_val.append(x[1])elif field_type == "bool":return_val = random.choice([True, False])elif field_type == "str":min = 3 if len(split_f) < 3 else int(split_f[2])max = min + 7 if len(split_f) < 4 else int(split_f[3])length = generate_count(min, max)return_val = "".join([random.choice(string.ascii_letters + string.digits) for x in range(length)])elif field_type == "int":min = 0 if len(split_f) < 3 else int(split_f[2])max = min + 100000 if len(split_f) < 4 else int(split_f[3])return_val = generate_count(min, max)elif field_type == "ipv4":return_val = "{0}.{1}.{2}.{3}".format(generate_count(0, 245),generate_count(0, 245),generate_count(0, 245),generate_count(0, 245))elif field_type in ["ts", "tstxt"]:now = int(time.time())per_day = 24 * 60 * 60min = now - 30 * per_day if len(split_f) < 3 else int(split_f[2])max = now + 30 * per_day if len(split_f) < 4 else int(split_f[3])ts = generate_count(min, max)return_val = int(ts * 1000) if field_type == "ts" else datetime.datetime.fromtimestamp(ts).strftime("%Y-%m-%dT%H:%M:%S.000-0000")elif field_type == "words":min = 2 if len(split_f) < 3 else int(split_f[2])max = min + 8 if len(split_f) < 4 else int(split_f[3])count = generate_count(min, max)words = []for _ in range(count):word_len = random.randrange(3, 10)words.append("".join([random.choice(string.ascii_letters + string.digits) for x in range(word_len)]))return_val = " ".join(words)elif field_type == "dict":global _dict_datamin = 2 if len(split_f) < 3 else int(split_f[2])max = min + 8 if len(split_f) < 4 else int(split_f[3])count = generate_count(min, max)return_val = " ".join([random.choice(_dict_data).strip() for _ in range(count)])elif field_type == "text":text = ["text1", "text2", "text3"] if len(split_f) < 3 else split_f[2].split("-")min = 1 if len(split_f) < 4 else int(split_f[3])max = min + 1 if len(split_f) < 5 else int(split_f[4])count = generate_count(min, max)words = []for _ in range(count):words.append(""+random.choice(text))return_val = " ".join(words)return field_name, return_valdef generate_count(min, max):if min == max:return maxelif min > max:return random.randrange(max, min);else:return random.randrange(min, max);def generate_random_doc(format):global id_counterres = {}for f in format:f_key, f_val = get_data_for_format(f)if f_key:res[f_key] = f_valif not tornado.options.options.id_type:return resif tornado.options.options.id_type == 'int':res['_id'] = id_counterid_counter += 1elif tornado.options.options.id_type == 'uuid4':res['_id'] = str(uuid.uuid4())return resdef set_index_refresh(val):params = {"index": {"refresh_interval": val}}body = json.dumps(params)url = "%s/%s/_settings" % (tornado.options.options.es_url, tornado.options.options.index_name)try:request = tornado.httpclient.HTTPRequest(url, headers=headers, method="PUT", body=body, request_timeout=240, auth_username=tornado.options.options.username, auth_password=tornado.options.options.password, validate_cert=tornado.options.options.validate_cert)http_client = tornado.httpclient.HTTPClient()http_client.fetch(request)logging.info('Set index refresh to %s' % val)except Exception as ex:logging.exception(ex)def csv_file_to_json(csvFilePath):data = []# Open a csv reader called DictReaderwith open(csvFilePath, encoding='utf-8') as csvf:csvReader = csv.DictReader(csvf)for rows in csvReader:data.append(rows)return json.dumps(data)@tornado.gen.coroutine
def generate_test_data():global upload_data_countif tornado.options.options.force_init_index:delete_index(tornado.options.options.index_name)create_index(tornado.options.options.index_name)# todo: query what refresh is set to, then restore laterif tornado.options.options.set_refresh:set_index_refresh("-1")if tornado.options.options.out_file:out_file = open(tornado.options.options.out_file, "w")else:out_file = Noneif tornado.options.options.dict_file:global _dict_datawith open(tornado.options.options.dict_file, 'r') as f:_dict_data = f.readlines()logging.info("Loaded %d words from the %s" % (len(_dict_data), tornado.options.options.dict_file))format = tornado.options.options.format.split(',')if not format:logging.error('invalid format')exit(1)ts_start = int(time.time())upload_data_txt = ""if tornado.options.options.data_file:json_array = ""if tornado.options.options.data_file.endswith(".csv"):json_array = json.loads(csv_file_to_json(tornado.options.options.data_file))else:with open(tornado.options.options.data_file, 'r') as f:json_array = json.load(f)logging.info("Loaded documents from the %s", tornado.options.options.data_file)for item in json_array:cmd = {'index': {'_index': tornado.options.options.index_name}}# '_type': tornado.options.options.index_type}}if '_id' in item:cmd['index']['_id'] = item['_id']upload_data_txt += json.dumps(cmd) + "\n"upload_data_txt += json.dumps(item) + "\n"if upload_data_txt:yield upload_batch(upload_data_txt)else:logging.info("Generating %d docs, upload batch size is %d" % (tornado.options.options.count,tornado.options.options.batch_size))for num in range(0, tornado.options.options.count):item = generate_random_doc(format)if out_file:out_file.write("%s\n" % json.dumps(item))cmd = {'index': {'_index': tornado.options.options.index_name}}# '_type': tornado.options.options.index_type}}if '_id' in item:cmd['index']['_id'] = item['_id']upload_data_txt += json.dumps(cmd) + "\n"upload_data_txt += json.dumps(item) + "\n"upload_data_count += 1if upload_data_count % tornado.options.options.batch_size == 0:yield upload_batch(upload_data_txt)upload_data_txt = ""# upload remaining items in `upload_data_txt`if upload_data_txt:yield upload_batch(upload_data_txt)if tornado.options.options.set_refresh:set_index_refresh("1s")if out_file:out_file.close()took_secs = int(time.time() - ts_start)logging.info("Done - total docs uploaded: %d, took %d seconds" % (tornado.options.options.count, took_secs))if __name__ == '__main__':tornado.options.define("es_url", type=str, default='http://localhost:9200', help="URL of your Elasticsearch node")tornado.options.define("index_name", type=str, default='test_data', help="Name of the index to store your messages")tornado.options.define("index_type", type=str, default='test_type', help="Type")tornado.options.define("batch_size", type=int, default=1000, help="Elasticsearch bulk index batch size")tornado.options.define("num_of_shards", type=int, default=2, help="Number of shards for ES index")tornado.options.define("http_upload_timeout", type=int, default=3, help="Timeout in seconds when uploading data")tornado.options.define("count", type=int, default=100000, help="Number of docs to generate")tornado.options.define("format", type=str, default='name:str,age:int,last_updated:ts', help="message format")tornado.options.define("num_of_replicas", type=int, default=0, help="Number of replicas for ES index")tornado.options.define("force_init_index", type=bool, default=False, help="Force deleting and re-initializing the Elasticsearch index")tornado.options.define("set_refresh", type=bool, default=False, help="Set refresh rate to -1 before starting the upload")tornado.options.define("out_file", type=str, default=False, help="If set, write test data to out_file as well.")tornado.options.define("id_type", type=str, default=None, help="Type of 'id' to use for the docs, valid settings are int and uuid4, None is default")tornado.options.define("dict_file", type=str, default=None, help="Name of dictionary file to use")tornado.options.define("data_file", type=str, default=None, help="Name of the documents file to use")tornado.options.define("username", type=str, default=None, help="Username for elasticsearch")tornado.options.define("password", type=str, default=None, help="Password for elasticsearch")tornado.options.define("validate_cert", type=bool, default=True, help="SSL validate_cert for requests. Use false for self-signed certificates.")tornado.options.parse_command_line()tornado.ioloop.IOLoop.instance().run_sync(generate_test_data)
本文由 mdnice 多平台发布
相关文章:

异步检索在 Elasticsearch 中的理论与实践
异步检索在 Elasticsearch 中的理论与实践 https://www.elastic.co/guide/en/elasticsearch/reference/8.1/async-search.html#submit-async-search 引言 Elasticsearch 是一种强大的分布式搜索和分析引擎,它能够快速地存储、搜索和分析大量数据。在处理大规模数据时…...
了解Unity编辑器之组件篇Physics 2D(十二)
一、Area Effector 2D区域施加力):用于控制区域施加力的行为 Use Collider Mask(使用碰撞器遮罩):启用后,区域施加力仅会作用于特定的碰撞器。可以使用Collider Mask属性选择要作用的碰撞器。 Collider Ma…...

[Pytorch]手写数字识别——真·手写!
Github网址:https://github.com/diaoquesang/pytorchTutorials/tree/main 本教程创建于2023/7/31,几乎所有代码都有对应的注释,帮助初学者理解dataset、dataloader、transform的封装,初步体验调参的过程,初步掌握openc…...
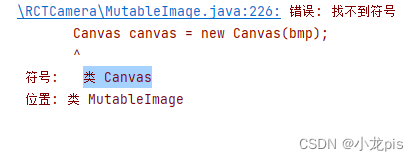
android studio 找不到符号类 Canvas 或者 错误: 程序包java.awt不存在
android studio开发提示 解决办法是: import android.graphics.Canvas; import android.graphics.Color; 而不是 //import java.awt.Canvas; //import java.awt.Color;...
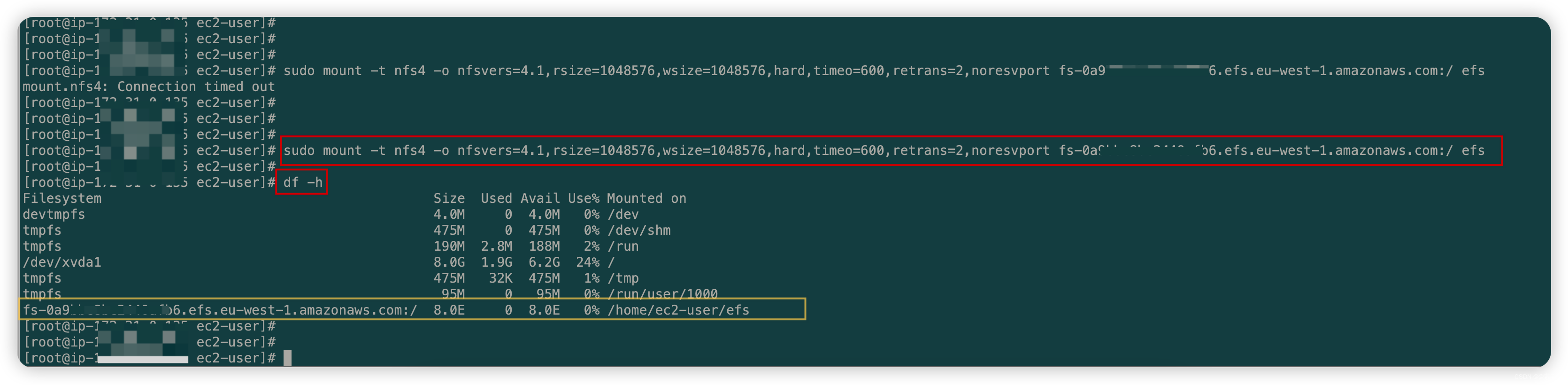
AWS——02篇(AWS之服务存储EFS在Amazon EC2上的挂载——针对EC2进行托管文件存储)
AWS——02篇(AWS之服务存储EFS在Amazon EC2上的挂载——针对EC2进行托管文件存储) 1. 前言2. 关于Amazon EFS2.1 Amazon EFS全称2.2 什么是Amazon EFS2.3 优点和功能2.4 参考官网 3. 创建文件系统3.1 创建 EC2 实例3.2 创建文件系统 4. 在Linux实例上挂载…...

FFmpeg 打包mediacodec 编码帧 MPEGTS
在Android平台上合成视频一般使用MediaCodec进行硬编码,使用MediaMuxer进行封装,但是因为MediaMuxer支持格式有限,一般会采用ffmpeg封装,比如监控一般使用mpeg2ts格式而非MP4,这是因为两者对帧时pts等信息封装差异导致应用场景不同…...

软件测试如何推进项目进度?
在软件研发中,有一种思想叫TDD,即测试驱动开发,TDD是敏捷方法中的一项核心实践,其原理是在开发功能代码之前,先编写单元测试用例代码,对要编写的函数或类明确测试方法后,再进行设计与编码。 本…...
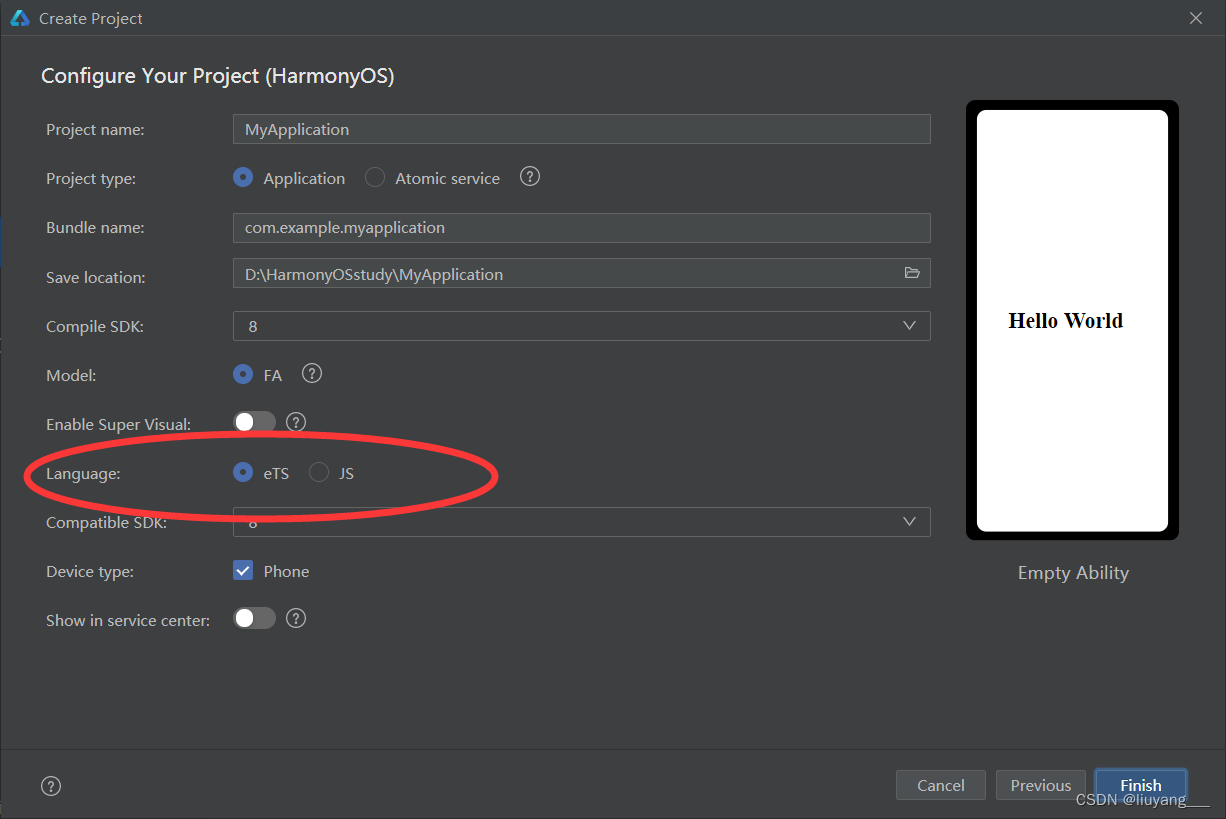
首次尝试鸿蒙开发!
今天是我第一次尝试鸿蒙开发,是因为身边的学长有搞这个的,而我也觉得我也该拓宽一下技术栈! 首先配置环境,唉~真的是非常心累,下载一个DevEco Studio 3.0.0.993,然后配置环境变量这些操作不用多说ÿ…...

前端面试题-react
1 React 中 keys 的作⽤是什么? Keys 是 React ⽤于追踪哪些列表中元素被修改、被添加或者被移除的辅助标识在开发过程中,我们需要保证某个元素的 key 在其同级元素中具有唯⼀性。在 React Diff 算法中 React 会借助元素的 Key 值来判断该元素是新近创建…...
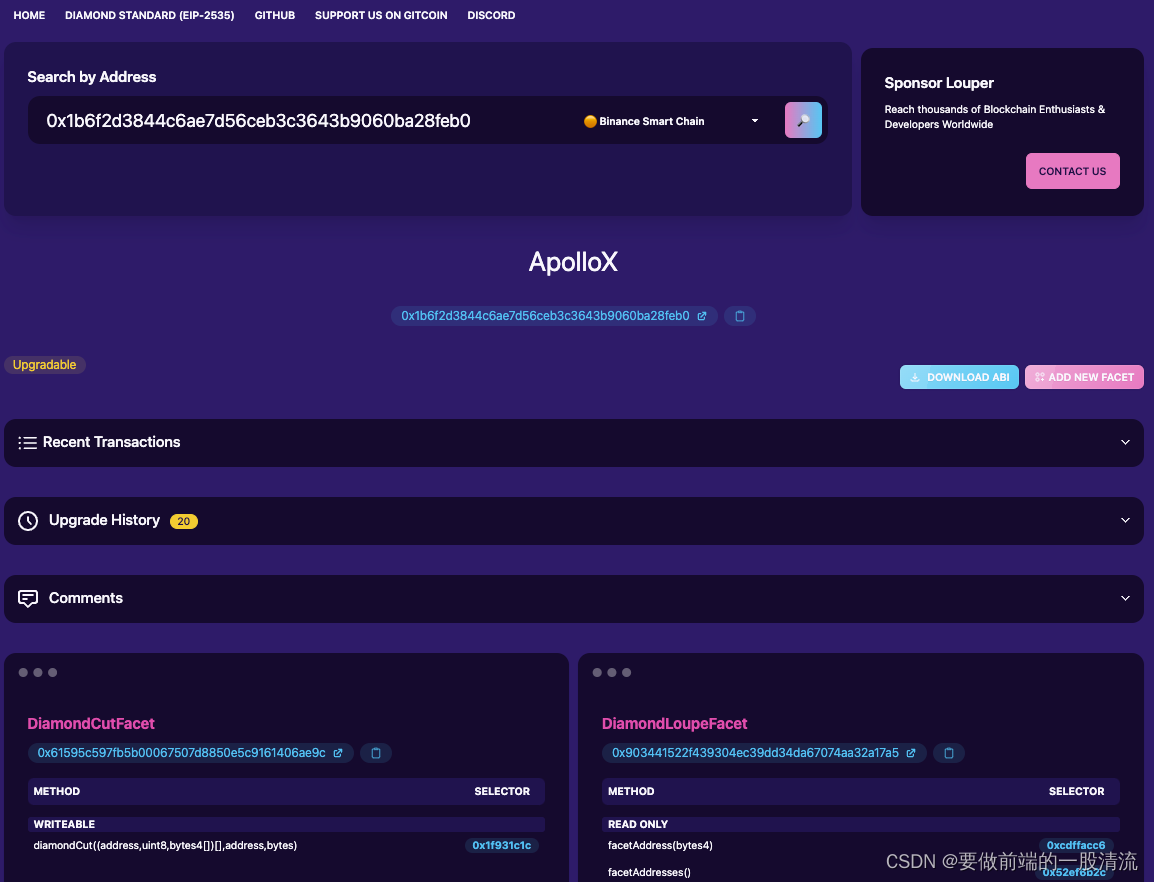
EIP-2535 Diamond standard 实用工具分享
前段时间工作对接到了这标准的协议,于是简单介绍下这个标准分享下方便前端er使用的调用工具 一、标准的诞生 在写复杂逻辑的solidity智能合约时,经常会碰到两个问题,升级和合约大小限制。 升级目前有几种proxy模式,通过delegateca…...
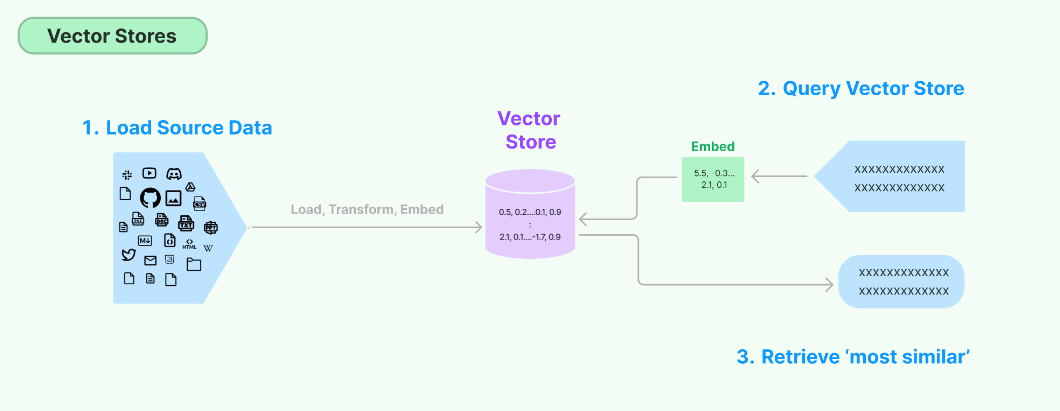
【LangChain】向量存储(Vector stores)
LangChain学习文档 【LangChain】向量存储(Vector stores)【LangChain】向量存储之FAISS 概要 存储和搜索非结构化数据的最常见方法之一是嵌入它并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。向量存储负责存储嵌入数…...
Debian/Ubuntu 安装 Chrome 和 Chrome Driver 并使用 selenium 自动化测试
截至目前,Chrome 仍是最好用的浏览器,没有之一。Chrome 不仅是日常使用的利器,通过 Chrome Driver 驱动和 selenium 等工具包,在执行自动任务中也是一绝。相信大家对 selenium 在 Windows 的配置使用已经有所了解了,下…...

[SQL挖掘机] - 窗口函数 - 合计: with rollup
介绍: 在sql中,with rollup 是一种用于在查询结果中生成小计和总计的选项。它可以与 group by 子句一起使用,用于在分组查询的结果中添加附加行。 with rollup 的作用是为每个指定的分组列生成小计,并在最后添加一行总计。这样,…...

远程控制平台一之推拉流的实现
确定框架 在选用推拉流框架的时候,有了解过nginx+rtmp/rtsp,Janus,以及其他开源的推拉流框架,要么是延迟严重(延迟一分多钟),要么配置复杂,而且这些框架对于只是转发远程画面这个简单需求来说,过于庞大了。机缘巧合之下,我了解到了一个简单易用的框架,就是ZeroMQ的…...
RTT(RT-Thread)线程管理(1.2W字详细讲解)
目录 RTT线程管理 线程管理特点 线程工作机制 线程控制块 线程属性 线程状态之间切换 线程相关操作 创建和删除线程 创建线程 删除线程 动态创建线程实例 启动线程 初始化和脱离线程 初始化线程 脱离线程 静态创建线程实例 线程辅助函数 获得当前线程 让出处…...
你真的会自动化吗?Web自动化测试-PO模式实战,一文通透...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 PO模式 Page Obj…...

C# 使用堆栈实现队列
232 使用堆栈实现队列 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(、、、):pushpoppeekempty 实现 类:MyQueue void push(int x)将元素 x 推到队列的末尾 int pop()从队列的开头移除并返回元素 in…...
git操作:修改本地的地址
Windows下git如何修改本地默认下载仓库地址 - 简书 (jianshu.com) 详细解释: 打开终端拉取git时,会默认在git安装的地方,也就是终端前面的地址。 需要将代码 拉取到D盘的话,现在D盘创建好需要安放代码的文件夹,然后…...
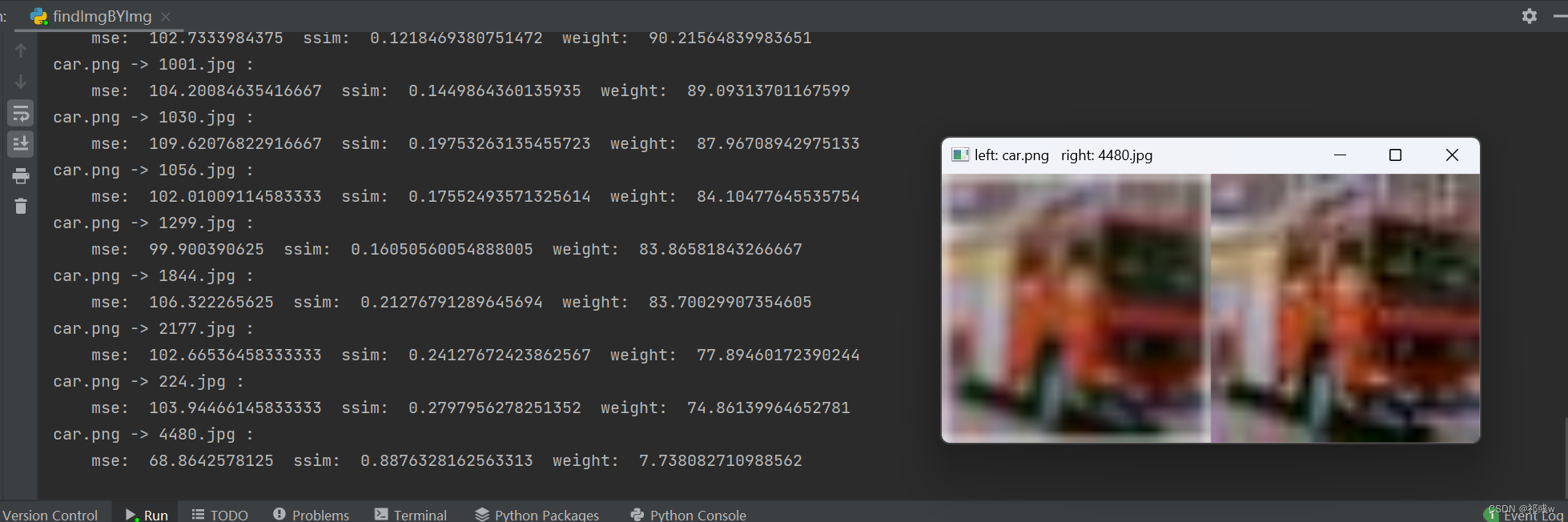
【以图搜图】Python实现根据图片批量匹配(查找)相似图片
目的:可以解决在本地实现根据图片查找相似图片的功能 背景:由于需要查找别人代码保存的图像的命名,但由于数据集是cifa10图像又小又多,所以直接找很费眼睛,所以实现用该代码根据图像查找图像,从而得到保存…...

【无标题】JSP--Java的服务器页面
jsp是什么? jsp的全称是Java server pages,翻译过来就是java的服务器页面。 jsp有什么作用? jsp的主要作用是代替Servlet程序回传html页面的数据,因为Servlet程序回传html页面数据是一件非常繁琐的事情,开发成本和维护成本都非常高…...

Visual C++运行库终极修复指南:一键解决“缺少DLL文件“的完整解决方案
Visual C运行库终极修复指南:一键解决"缺少DLL文件"的完整解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软…...

LDAP认证失败率下降92%!DeepSeek集成最佳实践,含OpenLDAP/Active Directory双环境配置清单
更多请点击: https://intelliparadigm.com 第一章:LDAP认证失败率下降92%!DeepSeek集成最佳实践,含OpenLDAP/Active Directory双环境配置清单 在企业级AI平台落地过程中,统一身份认证是安全与体验的基石。DeepSeek模型…...

4.【Python】Python3 注释
第一步:分析与整理 注释1. 注释的作用 不影响程序执行,只提高可读性。帮助理解代码逻辑,方便团队协作。2. 单行注释 以 # 开头,直到行末的所有内容均为注释。 # 这是一个注释 print("Hello, World!") # 这也是注释3. 多…...

从Starpod项目解析个人AI工作流引擎:架构、实现与应用
1. 项目概述:从“星荚”到个人AI工作流引擎最近在AI工具圈里,一个名为sinaptik-ai/starpod的项目引起了我的注意。乍一看这个标题,可能会觉得有些抽象——“星荚”是什么?AI“豆荚”?但当你深入其GitHub仓库࿰…...

快速上手Redis
一、认识Redis Redis 是一个内存数据库,常用于缓存和高性能数据存储。特点: 数据存储在内存,读写速度快(毫秒级甚至微秒级)支持多种数据结构:String、Hash、List、Set、Sorted Set(ZSet&#…...
从零实现大语言模型:Transformer架构、自注意力机制与PyTorch实战
1. 项目概述:从零构建大语言模型的实践指南 最近几年,大语言模型(LLM)无疑是技术领域最耀眼的存在。从ChatGPT的横空出世到各类开源模型的百花齐放,它们展现出的理解和生成能力令人惊叹。然而,对于许多开发…...

ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程
ComfyUI-Inpaint-CropAndStitch终极指南:30倍加速AI图像修复的完整教程 【免费下载链接】ComfyUI-Inpaint-CropAndStitch ComfyUI nodes to crop before sampling and stitch back after sampling that speed up inpainting 项目地址: https://gitcode.com/gh_mir…...

XHS-Downloader:一款完全免费的小红书内容采集神器
XHS-Downloader:一款完全免费的小红书内容采集神器 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#x…...

基于MCP协议构建AI助手本地工具服务器:从原理到实战
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的项目,叫kirill-markin/example-mcp-server。这名字听起来平平无奇,但如果你正在研究如何让ChatGPT、Claude这类大模型助手变得更“能干”,能直接操作你电脑上的…...
:炎症与免疫调节中的关键细胞因子)
白细胞介素-17(IL-17):炎症与免疫调节中的关键细胞因子
白细胞介素-17(Interleukin-17, IL-17)作为IL-17细胞因子家族中的核心成员,在免疫应答、炎症反应及宿主防御中扮演着举足轻重的角色。自其被发现以来,IL-17在免疫学、炎症性疾病及肿瘤生物学等领域的研究中持续引发关注。本文旨在…...