如何看待低级爬虫与高级爬虫?
爬虫之所以分为高级和低级,主要是基于其功能、复杂性和灵活性的差异。根据我总结大概有下面几点原因:
功能和复杂性:高级爬虫通常提供更多功能和扩展性,包括处理复杂页面结构、模拟用户操作、解析和清洗数据等。它们解决了开发者在处理复杂任务时遇到的挑战。低级爬虫则更简单,包含基础的爬取功能,适用于简单任务和入门学习。
灵活性和定制化:随着任务需求的复杂化,开发者通常需要更高的灵活性和可定制性来满足特殊要求。高级爬虫框架(例如Scrapy)提供了许多工具、模块和机制,允许开发者根据项目的需要定制爬取流程、数据处理和存储等方面。低级爬虫则相对较少提供这些高级定制选项。
性能和效率:高级爬虫框架通常针对性能和效率进行了优化,以提高抓取速度、降低资源占用等。这对处理大规模数据和高并发情况下的爬取任务非常重要。低级爬虫往往更简单,可能未经过类似的优化,因此在处理大型任务时可能会受限。
综上所述,高级爬虫提供了更多高级功能、灵活性和效率,适用于复杂任务和专业开发者的需求。而低级爬虫则更适合简单任务和初学者入门学习,提供了一个简单直接的方式理解爬虫的基础原理和操作。
低级爬虫和高级爬虫在功能和复杂性上存在一定的差异。以下是对它们的看法:
低级爬虫:
基础功能:低级爬虫通常具有简单的功能,如发起HTTP请求、获取网页内容等。
学习曲线:初学者可以使用低级爬虫来熟悉基本的爬虫操作和编程技巧。它们提供了一个入门的平台,让人们快速理解爬虫的工作原理和基本流程。
简洁性:低级爬虫通常代码较少,并且对于简单的任务来说,执行起来相对较简单。
高级爬虫:
强大的功能:高级爬虫具备更多的功能和灵活性。它们能够处理复杂的页面结构、实现数据清洗和整理、处理验证码、模拟用户行为等各高级操作。
高度定制化:高级爬虫框架(如Scrapy)提供了许多方便的工具和机制,使开发者能够更轻松管理抓取过程、创建定制的数据流水线和进行分布式爬取等。
高效性:高级爬虫通常优化了执行速度和资源利用效率,并有更好的容错机制。这使得它们能够处理大型项目和高并发环境,实现高抓取。
总体而言,低级爬虫适用于简单的抓取任务和初学者入门,而高级爬虫则适用于复杂的、具有特定需求的任务,提供了更多高级功能和工具以满足专业开发者的需求。
低级爬虫代码示例
低级爬虫是指相对简单和基础的爬虫程序,通用于初学者或针对简单任务的场景。下面是一个基本的低级爬虫示例,使用Python的:
import requests# 发起HTTP请求获取网页内容
response = requests.get('https:// 检查是否成功获取响应
if response.status_code == 200:print(response.text)
else:print("Failed to retrieve webpage. Status code:", response.status_code)
以上示例中,使用requests库发送GET请求来获取https://example.com网页的内容。如果响应状态码为200,则打印出网页的文本内容。
这个低级爬虫示例非常简单,并忽略了错误处理、数据解析和其他复杂功能。在实际应用中,你可能需要更多代码来处理不同的情况,例如处理HTTP错误、提取特定的数据、保存爬取结果等。
要进一步学习和扩展你的爬虫技能,可以研究和尝试使用更高级的爬虫框架,如Scrapy、BeautifulSoup、Selenium等,它们提供了更丰富的功能和便捷的工具来编写强大的爬虫程序。
高级爬虫代码示例
以下是一个示例高级爬虫代码,使用Scrapy框架来实现:
import scrapyclass MySpider(scrapy.Spider):name = "myspider"# 定义起始URLstart_urls = ["https://www.example.com/page1","https://www.example.com/page2"]def parse(self, response):# 处理响应,提取数据data = response.css('div.data-container').extract()# 处理下一页链接next_page_link = response.css('a.next-page-link::attr(href)').get()if next_page_link:yield response.follow(next_page_link, callback=self.parse)
上述代码是一个基本的Scrapy爬虫示例。其中MySpider类继承自Scrapy的``类,并定义了爬虫的名称、起始URL和解。
在parse方法中,我们使用CSS选择器将页面中特定CSS选择器的元素,我们也检查是否存在下一页链接,如果有,则使用response.follow跟随该链接并调用parse方法处理下一页。
可以根据具体需求对代码进行修改和扩展,例如添加更多的数据解析逻辑、数据存储操作等。
请注意,这只是一个简单示例,实际的高级爬虫可能会包含更多的功能和复杂的流程。详细的Scrapy教程和文档供了更全面的了解和指导,供进一步学习和应用。
相关文章:
如何看待低级爬虫与高级爬虫?
爬虫之所以分为高级和低级,主要是基于其功能、复杂性和灵活性的差异。根据我总结大概有下面几点原因: 功能和复杂性:高级爬虫通常提供更多功能和扩展性,包括处理复杂页面结构、模拟用户操作、解析和清洗数据等。它们解决了开发者…...

3.分支与循环
一、分支结构 1.概念 一个 CPP 程序默认是按照代码书写顺序,从上到下依次执行下来的。但是,有时我们需要选择性的执行某些语句,来实现更加复杂的逻辑,这时候就需要分支结构语句的功能来实现。选择合适的分支语句可以显著提高程序…...
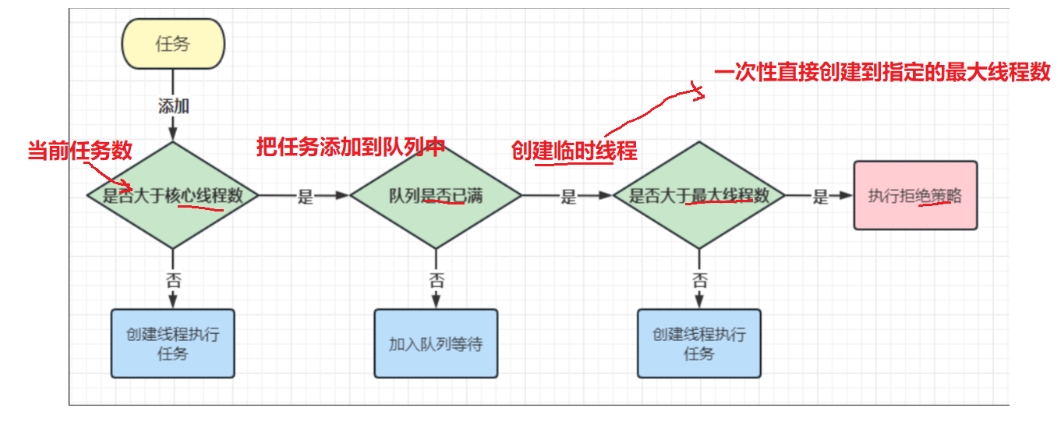
面试之多线程案例(四)
1.单例模式 单例模式是指在内存中只会创建且仅创建一次对象的设计模式。在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地方都共享这一单例对象。…...
抄写Linux源码(Day1:获取并运行 Linux0.11)
Day1:获取并运行 Linux0.11 参考资料:https://zhuanlan.zhihu.com/p/438577225 这是我参考的一个别人写的 Linux0.11 解读:https://github.com/dibingfa/flash-linux0.11-talk 我获取 Linux-0.11 源码的链接:https://github.com/…...
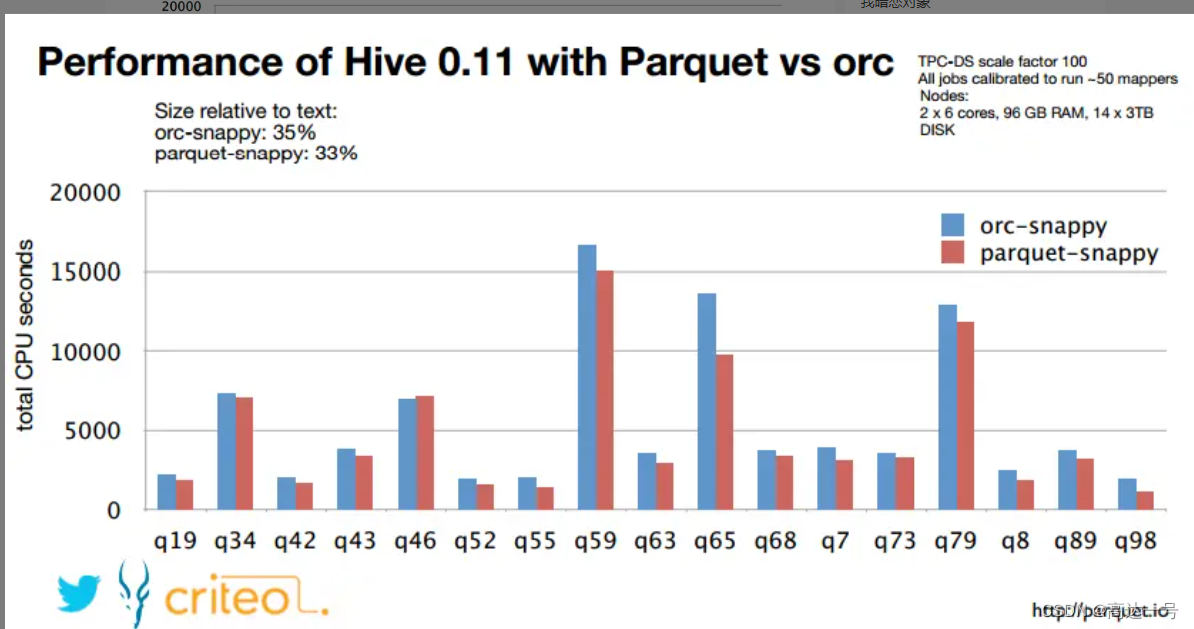
大数据_Hadoop_Parquet数据格式详解
之前有面试官问到了parquet的数据格式,下面对这种格式做一个详细的解读。 参考链接 : 列存储格式Parquet浅析 - 简书 Parquet 文件结构与优势_parquet文件_KK架构的博客-CSDN博客 Parquet文件格式解析_parquet.block.size_davidfantasy的博客-CSDN博…...

Docker的安装和部署
目录 一、Docker的安装部署 (1)关闭防火墙 (2)关闭selinux (3)安装docker引擎 (4)启动docker (5)设置docker自启动 (6)测试doc…...

FPGA项目实现:秒表设计
文章目录 项目要求项目设计 项目要求 设计一个时钟秒表,共六个数码管,前两位显示分钟,中间两位显示时间秒,后两位显示毫秒的高两位,可以通过按键来开始、暂停以及重新开始秒表的计数。 项目设计 为完成此项目共设计…...
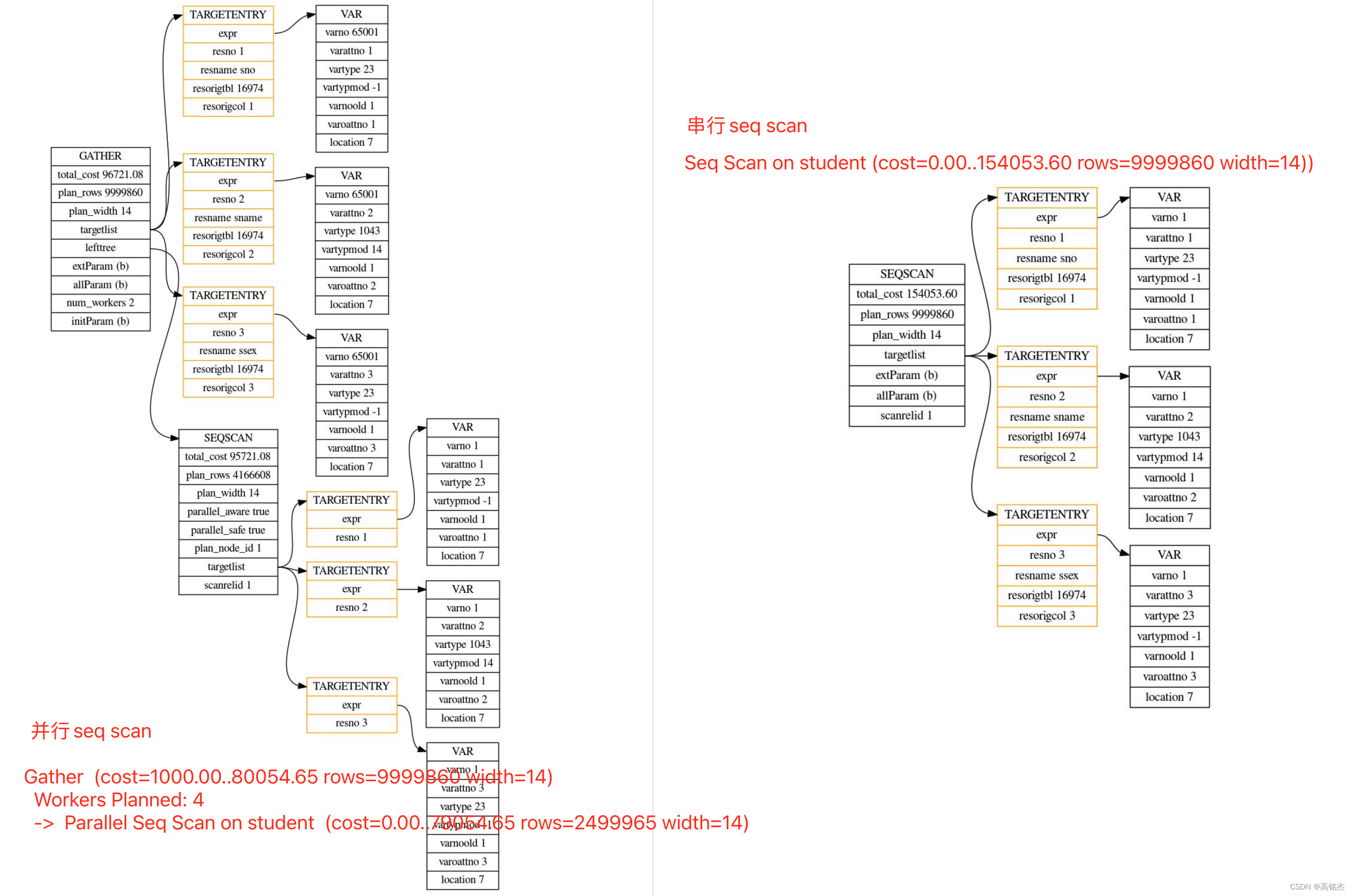
Postgresql源码(109)并行框架实例与分析
1 PostgreSQL并行参数 系统参数 系统总worker限制:max_worker_processes 默认8 系统总并发限制:max_parallel_workers 默认8 单Query限制:max_parallel_workers_per_gather 默认2 表参数限制:parallel_workers alter table tbl …...

ES派生类的prototype方法中,不能访问super的解决方案
1 下面的B.prototype.compile方法中,无法访问super class A {compile() {console.log(A)} }class B extends A {compile() {super.compile()console.log(B)} }B.prototype.compile function() {super.compile() // 报错,不可以在此处使用superconsole.…...

使用adb通过电脑给安卓设备安装apk文件
最近碰到要在开发板上安装软件的问题,由于是开发板上的安卓系统没有解析apk文件的工具,所以无法通过直接打开apk文件来安装软件。因此查询各种资料后发现可以使用adb工具,这样一来可以在电脑上给安卓设备安装软件。 ADB 就是连接 Android 手…...
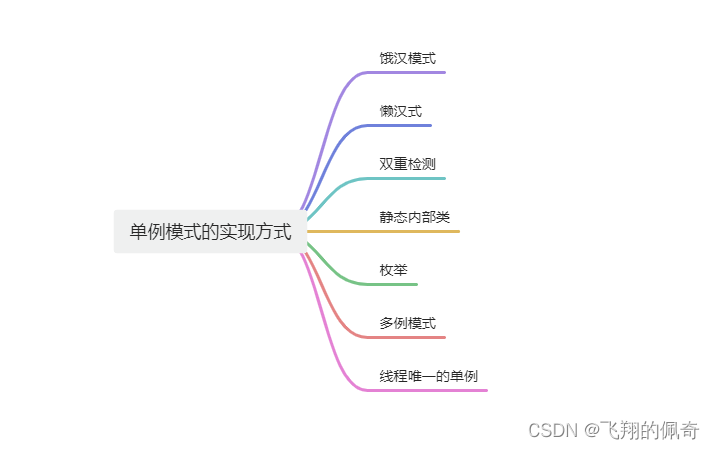
113、单例Bean是单例模式吗?
单例Bean是单例模式吗? 通常来说,单例模式是指在一个JVM中,一个类只能构造出来一个对象,有很多方法来实现单例模式,比如懒汉模式,但是我们通常讲的单例模式有一个前提条件就是规定在一个JVM中,那如果要在两个JVM中保证单例呢?那可能就要用分布式锁这些技术,这里的重点…...
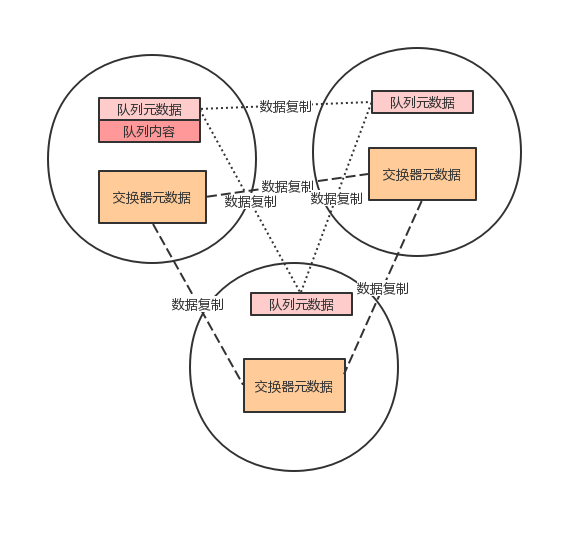
RabbitMQ 集群部署
RabbiMQ 是用 Erlang 开发的,集群非常方便,因为 Erlang 天生就是一门分布式语言,但其本身并不支持负载均衡。 RabbitMQ 的集群节点包括内存节点、磁盘节点。RabbitMQ 支持消息的持久化,也就是数据写在磁盘上,最合适的方案就是既有内存节点,又有磁盘节点。 RabbitMQ 模式大…...

2023年【零声教育】13代C/C++Linux服务器开发高级架构师课程体系分析
对于零声教育的C/CLinux服务器高级架构师的课程到2022目前已经迭代到13代了,像之前小编也总结过,但是课程每期都有做一定的更新,也是为了更好的完善课程跟上目前互联网大厂的岗位技术需求,之前课程里面也包含了一些小的分支&#…...

iOS开发-实现热门话题标签tag显示控件
iOS开发-实现热门话题标签tag显示控件 话题标签tag显示非常常见,如选择你的兴趣,选择关注的群,超话,话题等等。 一、效果图 二、实现代码 由于显示的是在列表中,这里整体控件是放在UITableViewCell中的。 2.1 标签…...

linux系统磁盘性能监视工具iostat
目录 一、iostat介绍 二、命令格式 三、命令参数 四、参考命令:iostat -c -x -k -d 1 (一)输出CPU 属性值 (二)CPU参数分析 (三)磁盘每一列的含义 (四)磁盘参数分…...

BT#蓝牙 - Link Policy Settings
对于Classic Bluetooth的Connection,有一个Link_Policy_Settings,是HCI configuration parameters中的一个。 Link_Policy_Settings 参数决定了本地链路管理器(Link Manager)在收到来自远程链路管理器的请求时的行为,还用来决定改变角色(rol…...

c++ | 动态链接库 | 小结
//环境 linux c //生成动态链接库 //然后调用动态链接库中的函数//出现的问题以及解决//注意在win和在linux中调用动态链接库的函数是不一样的//在要生成链接库的cpp文件中比如以后要调用本文件中的某个函数,需要extern "c" 把你定的函数“再封装”避免重…...

如何使用Flask-SQLAlchemy来管理数据库连接和操作数据?
首先,我们需要安装Flask-SQLAlchemy。你可以使用pip来安装它,就像这样: pip install Flask-SQLAlchemy好了,现在我们已经有了一个可以操作数据库的工具,接下来让我们来看看如何使用它吧! 首先,…...
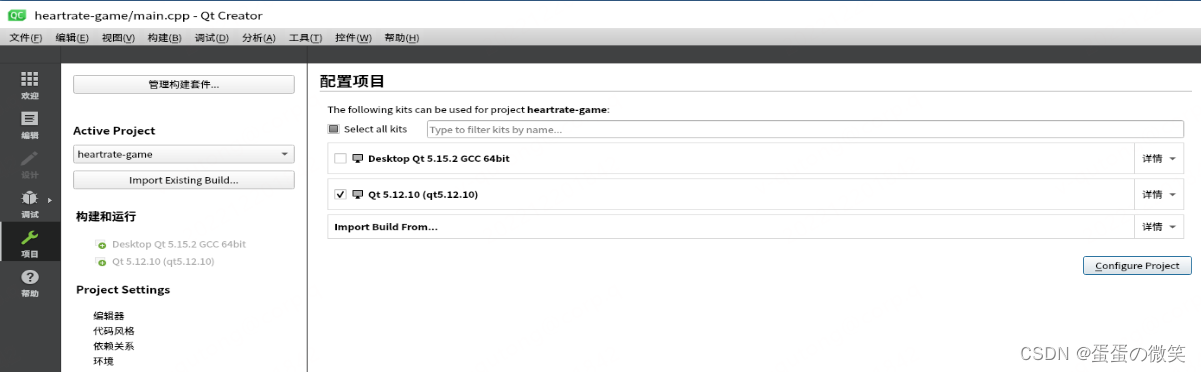
麒麟-飞腾Kylin-V4桌面arm64系统静态编译QT
1.系统具体版本: 2. 因为此版本的源很老了,需要修改版本的源,才能正常更新各种软件,否则,你连麒麟商店都打不开。 sudo vi /etc/apt/sources.list 选择你系统对应版本的源地址: #4.0.2桌面版本: deb ht…...

CentOS 项目发出一篇奇怪的博文
导读最近,在红帽限制其 RHEL 源代码的访问之后,整个社区围绕这件事发生了很多事情。 CentOS 项目发出一篇奇怪的博文 周五,CentOS 项目董事会发出了一篇模糊不清的简短博文,文中称,“发展社区并让人们更容易做出贡献…...

Aviator表达式引擎:从编译优化到规则引擎实战
1. Aviator表达式引擎初探 第一次接触Aviator是在一个电商风控项目中,当时系统需要处理大量实时交易规则判断。传统的if-else代码已经膨胀到难以维护的程度,每次业务规则变更都需要重新发布。这时候技术负责人推荐了Aviator,一个基于Java的高…...
)
告别XDMA限制:用开源Riffa框架在Linux下轻松实现多通道PCIE DMA通信(Kintex-7实测)
突破XDMA瓶颈:开源Riffa框架在Linux下的多通道PCIE DMA实战指南(Kintex-7验证) 当FPGA开发者面临高速数据采集、实时信号处理或多设备协同工作时,PCIE DMA通道的数量往往成为系统性能的瓶颈。Xilinx官方XDMA方案虽然稳定ÿ…...

如何快速上手网易游戏NPK文件解包工具:新手3步完整教程
如何快速上手网易游戏NPK文件解包工具:新手3步完整教程 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否对网易游戏如《阴阳师》、《魔法禁书目录》中的…...

书匠策AI:一个让论文小白也能“开挂“的毕业论文神器,到底有多能打?
各位同学,你有没有经历过这种崩溃时刻——毕业论文 deadline 倒计时,你的Word文档里只有标题,脑子里一片空白,选题没思路、大纲理不清、参考文献不会找,甚至连学校格式都搞不明白? 别慌,今天作…...

企业级浏览器自动化测试架构设计:Chrome for Testing的高可用解决方案与实践指南
企业级浏览器自动化测试架构设计:Chrome for Testing的高可用解决方案与实践指南 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing Chrome for Testing是Google ChromeLabs团队为解决浏览器自动化测试…...

Claude与Figma智能协作:基于MCP协议的设计自动化实践
1. 项目概述:当Claude遇上Figma,设计协作的智能革命如果你是一名产品设计师或前端工程师,大概率经历过这样的场景:在Figma里反复调整一个组件的间距,只为找到那个“感觉对了”的数值;或者为了统一整个项目的…...

浏览器扩展开发实战:光标交互防火墙的设计与实现
1. 项目概述与核心价值最近在折腾浏览器插件开发,偶然在GitHub上看到了一个名为“Raidu Firewall Cursor Extension”的项目。光看这个名字,就让我这个对网络安全和效率工具都感兴趣的老码农眼前一亮。这玩意儿本质上是一个浏览器扩展,但它把…...

工程定制丙级管道井门 物业机房通用款式
工程定制丙级管道井门,作为高层住宅、商业楼宇、物业机房强弱电井的专用消防配套设施,严格遵循国标消防规范生产,是建筑管井防火分隔、安全防护的核心产品。这款丙级管道井门采用钢制一体成型工艺,结构扎实不易变形,具…...

HsMod终极指南:50+功能全面解锁炉石传说模改插件
HsMod终极指南:50功能全面解锁炉石传说模改插件 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,通过50多项实用…...

构建企业的知识图谱
在智能制造与大模型时代,构建制造企业的工业知识图谱(Industrial Knowledge Graph, IKG),是将企业沉淀在老师傅头脑中、纸面技术手册、PLM图纸以及MES日志中的“隐性知识”,转化为 AI 和工业智能体(Industr…...