聊聊拉长LLaMA的一些经验
Sequence Length是指LLM能够处理的文本的最大长度,越长,自然越有优势:
-
更强的记忆性。更多轮的历史对话被拼接到对话中,减少出现遗忘现象
-
长文本场景下体验更佳。比如文档问答、小说续写等
当今开源LLM中的当红炸子鸡——LLaMA,第一版上下文长度是2048,第二版长度是4096。相比之下ChatGPT、GPT4已经支持到16k,Claude甚至支持到了100k。足以见得将LLaMA拉长是如此的任重而道远。本文将会介绍三种在旋转位置编码(RoPE)基础上扩充上下文的高性价比方案,在文末会介绍我的实践经验。
线性插值法
Kaiokendev的博客[1]中提到了方法,和Meta的一篇工作[2]不谋而合,其思想主要是将目标长度压缩到原始长度。如下图所示,LLaMA-1预训练的长度为2048,如果我们想把它拉长到4096:
-
方法一:推理时直接拉长到4096。这考虑位置编码的外推性(即在短文本上训练,长文本上推理的能力[2]),而RoPE的外推性则是相当一般[2]。由于训练时长度都是小于2048的,超过2048部分Attention分数会飙升,导致困惑度急剧上升。
-
方法二:在原始模型基础上做长度为4096的继续训练。这里先岔开介绍另一款模型——MPT-30B的做法,根据官方博客[3]的介绍:
As mentioned earlier, MPT-30B was trained with a long context window of 8k tokens (vs. 2k for LLaMa and Falcon) and can handle arbitrarily long context windows via ALiBi or with fine-tuning. To build 8k support into MPT-30B efficiently, we first pre-trained on 1T tokens using sequences that were 2k tokens long, and continued training for an additional 50B tokens using sequences that were 8k tokens long.
MPT-30B采用ALiBi位置编码(外推性优于RoPE),在2k的长度进行1T token的训练,然后在8k长度上进行50B token的预训练——这是在外推性强于RoPE的ALiBi上的情况。LLaMA-1预训练的token数是1T以上,想要在长度为4096样本上效果不下降,那需要训练足够多的token数才行,这就需要较大的成本了。
-
方法三:另一种思路则是将4096的位置编码通过线性插值法压缩到2048内,这样只需要在少量的长度为4096的数据上进行继续预训练,便可达到不错的效果。
![来自论文[2]](https://img-blog.csdnimg.cn/img_convert/07e08cfdbeb2ba90f2a3541289b93bf5.png)
来自论文[2]
代码实现
线性插值法的实现代码相当的简单,这需要在原始RoPE上进行微小的改动,即加上下图的scale参数。
![来自[7],scaled_rope/LlamaLinearScaledRotaryEmbedding.py](https://img-blog.csdnimg.cn/img_convert/b374ead16e271c455df57f150cc1c2e5.png)
来自[7],scaled_rope/LlamaLinearScaledRotaryEmbedding.py
效果
Meta的工作[2]中进行了充足实验和公式推导证明,如果想看具体的代码,建议看lmsys.org(Vicuna的出品方)的一篇工作[4]:How Long Can Open-Source LLMs Truly Promise on Context Length? 他们对比了商用模型、号称支持长文本的开源模型和“Vicuna+线性插值法”的效果,并给出了几个结论:
-
商用模型在长文本的效果上很能打!而那些号称支持长文本的开源模型,在长文本上则表现不佳。
-
随着文本长度的增加,越接近边界,Vicuna+线性插值法的效果降低越明显。这可能是因为训练数据存在短文本的情况。
![来自[4]](https://img-blog.csdnimg.cn/img_convert/71364130a4652cf14f12aa1a43c58c8b.png)
来自[4]
![来自[4]](https://img-blog.csdnimg.cn/img_convert/5a148ea3efbc31e96c1abbefeb457b91.png)
来自[4]
写这篇文章的同时,ChatGLM团队更新了ChatGLM2-6B-32K,也是使用了插值法。同时推出了长文本的中英评测集LongBench,在这个评测集上ChatGLM2-6B-32K展示了强大的实力,但值得注意的是,该评测集的评测方式是使用ChatGLM2-6B来进行评估的。
NTK插值法
NTK插值法的提出于一篇Reddit帖子[5],它提出使用Neural Tangent Kernel (NTK)来解决这个问题。
if you apply Neural Tangent Kernel (NTK) theory to this problem, it becomes clear that simply interpolating the RoPE's fourier space "linearly" is very sub-optimal, as it prevents the network to distinguish the order and positions of tokens that are very close by. Borrowing from NTK literature, scaling down the fourier features too much will eventually even prevent succesful finetunes (this is corroborated by the recent paper by Meta that suggests an upper bound of ~600x)
Instead of the simple linear interpolation scheme, I've tried to design a nonlinear interpolation scheme using tools from NTK literature. Basically this interpolation scheme changes the base of the RoPE instead of the scale, which intuitively changes the "spinning" speed which each of the RoPE's dimension vectors compared to the next. Because it does not scale the fourier features directly, all the positions are perfectly distinguishable from eachother, even when taken to the extreme (eg. streched 1million times, which is effectively a context size of 2 Billion)
帖子中作者还用了时钟的例子来解释线性插值和NTK插值的异同:
RoPE behaves like a clock. Your 12 hours wall clock is basically a RoPE of dimension 3 with a base of 60. So for each second, the minute hand turns 1/60th of a minute, and for each minute, the hour hand turns 1/60th.
Now if you slowed down time by a factor of 4x, that is a linear RoPE scaling used in SuperHOT. Unfortunately now it is really really hard to distinguish each second, because now the seconds hand barely moves each second. So if someone gave you two different times, which is only different by a single second, you won't be able to distinguish them from afar (let's say the NNs have myopia because that's basically what NTK predicts)
Now NTK-Aware RoPE scaling does not slow down the seconds. One second is still one second, but it slows down minutes by a factor of let's say 1.5, and the hours by a factor of 2. This way you can fit 90 minutes in a hour, and fit 24 hours in half a day. So now you basically have a clock that can measure 129.6k seconds instead of 43.2k seconds.
Because you don't need a precise measurement of the hour hand when looking at the time, scaling the hours more compared to seconds is crucial. You don't want to lose the precision of the seconds hand, but you can afford to lose precision on the minutes hand and even more on the hours hand.
Then, it's just a matter of deriving the base change formula in order to obtain such a scaling. (where less precise dimensions are scaled more and more)
代码实现
NTK的实现则更加简单了,根据超参数alpha,对应修改base变量即可:
![来自[7],scaled-rope/scaled_rope/LlamaNTKScaledRotaryEmbedding.py](https://img-blog.csdnimg.cn/img_convert/ab60a9b258792528f0204bbb902855a3.png)
来自[7],scaled-rope/scaled_rope/LlamaNTKScaledRotaryEmbedding.py
效果
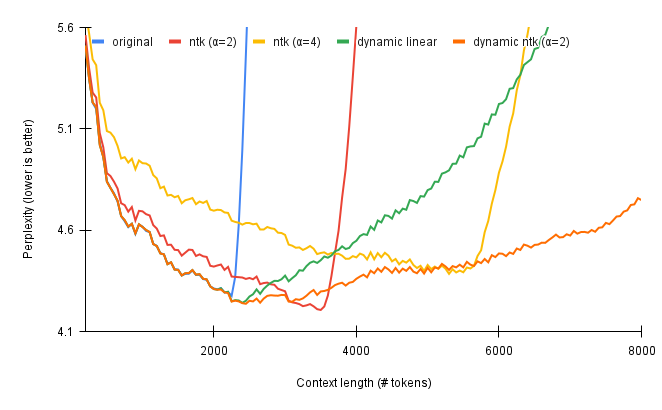
在效果上,帖子中也给出了NTK插值法和线性插值法的PPL比较,可以看到,在二者都不做Finetune的情况下,NTK插值法具备更低的PPL。
![来自[5]](https://img-blog.csdnimg.cn/img_convert/45f51c6e047d2b98da49edf6825b2df9.png)
来自[5]
动态插值法
动态插值法同样出自于一篇Reddit帖子[6],它的出发点很简单:
My idea was to use the exact position values for the first 2k context (after all, why mess with a good thing?) and then re-calculate the position vector for every new sequence length as the model generates token by token.
这种做法可以和先前的两种方法相结合,[7]中也给出了详细的代码实现。
效果
作者和前两种方法做了对比,展示了动态插值法在PPL下降上的优势。
实践经验
我在实践的过程中,评估效果主要使用longChat[4]中使用的评估方式,以下是一些takeaway tips,欢迎大家一起交流。
-
线性插值法具备完整的理论支持和大量的实验证明,在我的实践中,“线性插值法+Finetune”取得了最佳效果。
-
NTK插值法的实验中,对比的是不做Finetune的情况,在我的实践中,“NTK插值+Finetune”效果会明显优于单独的“NTK插值”,但它的收敛速度会慢于“线性插值法+Finetune”。
-
动态插值法的实验同样是在不做Finetune的情况对比的,目前为止我并没有尝试过这种方法。在Reddit的评论区有人提出一个很好的问题:如果采取这种方法,逐token推理时,文本的长度是在变化的,则导致无法使用kv-cache,这会对性能产生很大的影响。
最后,拉长LLaMA的方案可以不从RoPE入手(如:LongLLaMA[8]),但“线性插值法+Finetune”无疑是一种性价比很高的方案,推荐大家尝试!
——2023.07.31
Reference
[1] Extending Context is Hard…but not Impossible†
[2] EXTENDING CONTEXT WINDOW OF LARGE LANGUAGE MODELS VIA POSITION INTERPOLATION
[3] MPT-30B: Raising the bar for open-source foundation models
[4] How Long Can Open-Source LLMs Truly Promise on Context Length?
[5] NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation.
[6] Dynamically Scaled RoPE further increases performance of long context LLaMA with zero fine-tuning
[7] GitHub - jquesnelle/scaled-rope
[8] Focused Transformer: Contrastive Training for Context Scaling
相关文章:
聊聊拉长LLaMA的一些经验
Sequence Length是指LLM能够处理的文本的最大长度,越长,自然越有优势: 更强的记忆性。更多轮的历史对话被拼接到对话中,减少出现遗忘现象 长文本场景下体验更佳。比如文档问答、小说续写等 当今开源LLM中的当红炸子鸡——LLaMA…...

线程池的使用详解
一 使用线程池的好处 池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。 线程池提供了一种限制和管理资源(包括执行一个任…...

刷题笔记 day4
力扣 611 有效三角形的个数 首先需要知道如何判断 三个数是否能构成三角形。 假如 存在三个数 a < b < c,如果要构成三角形,需要满足: ab > c ; a c > b ; b c > a ; 任意两个数大于第三个数就可构成三角形。 其实不难…...

Python 2.x 中如何使用flask模块进行Web开发
Python 2.x 中如何使用 Flask 模块进行 Web 开发 引言: 随着互联网的快速发展,Web开发成为了互联网行业中一项非常重要的技术。而在 Python 的Web开发中,Flask框架是一种非常流行的选择。它简单轻巧,灵活易用,适合中小型项目的快…...

spring websocket 调用受权限保护的方法失败
版本 spring-security 5.6.10 spring-websocket 5.3.27 现象 通过AbstractWebSocketHandler实现websocket端点处理器 调用使用PreAuthorize注解的方法报错,无法在SecurityContext中找到认证信息 org.springframework.security.authentication.AuthenticationCred…...

Vue.js2+Cesium 四、模型对比
Vue.js2Cesium 四、模型对比 Cesium 版本 1.103.0,低版本 Cesium 不支持 Compare 对比功能。 Demo 同一区域的两套模型,实现对比功能 <template><div style"width: 100%; height: 100%;"><divid"cesium-container"…...

Linux 之 Vi 编辑器
文章目录 1. vi/vim介绍2. vi/vim使用详解2.1 vi/vim的特点2.2 vi/vim三种编辑模式2.3 文本编辑方式 1. vi/vim介绍 vi编辑器是linux和unix上最基本的文本编辑器,工作在字符模式下。由于不需要图形界面,vi是效率很高的文本编辑器。尽管在linux上也有很多…...

Python超实用!批量重命名文件/文件夹,只需1行代码
大家好,这里是程序员晚枫,之前在小破站给大家分享了一个视频:批量重命名文件。 最近在程序员晚枫的读者群里,发现很多朋友对这个功能很感兴趣,尤其是对下一步的优化:批量重命名文件夹。 这周我利用下班时…...

sqoop
一、bg 可以在关系型数据库和hdfs、hive、hbase之间导数 导入:从RDBMS到hdfs、hive、hbase 导出:相反 sqoop1 和sqoop2 (1.99.x)不兼容,sqoop2 并没有生产的稳定版本, Sqoop1 import原理(导入) 从传统数据库获取元数据信息&…...
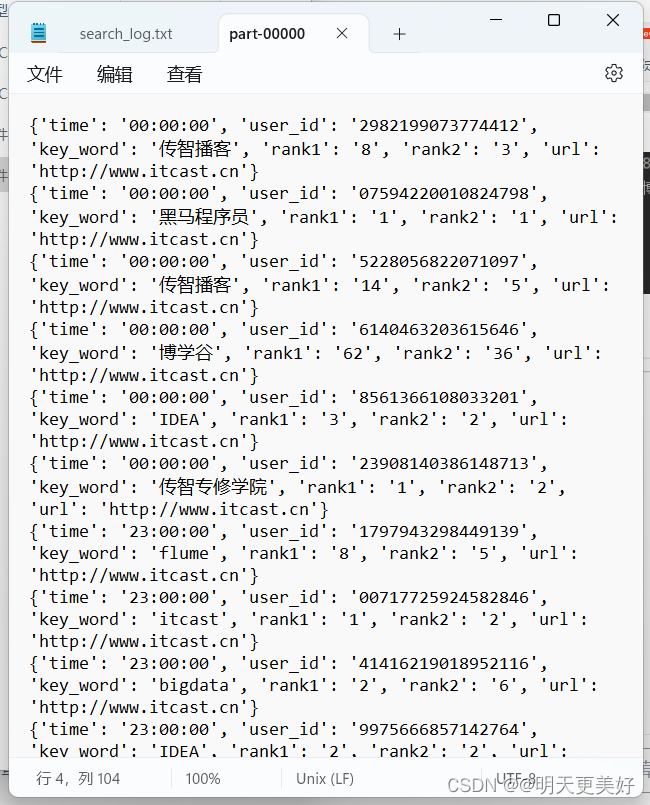
PySpark 数据操作(综合案例)
搜索引擎日志分析 要求: 读取文件转换成RDD,并完成: 打印输出:热门搜索时间段(小时精度)Top3打印输出:热门搜索词Top3打印输出:统计黑马程序员关键字在哪个时段被搜索最多将数据转…...

产品经理如何平衡用户体验与商业价值?
近期负责前端产品设计工作的小李忍不住抱怨:公司总是要求客户第一,实现客户良好体验,但在实际操作过程中,面向用户 体验提升的需求,研发资源计划几乎很难排上,资源都放在公司根据业务价值排序的需求…...
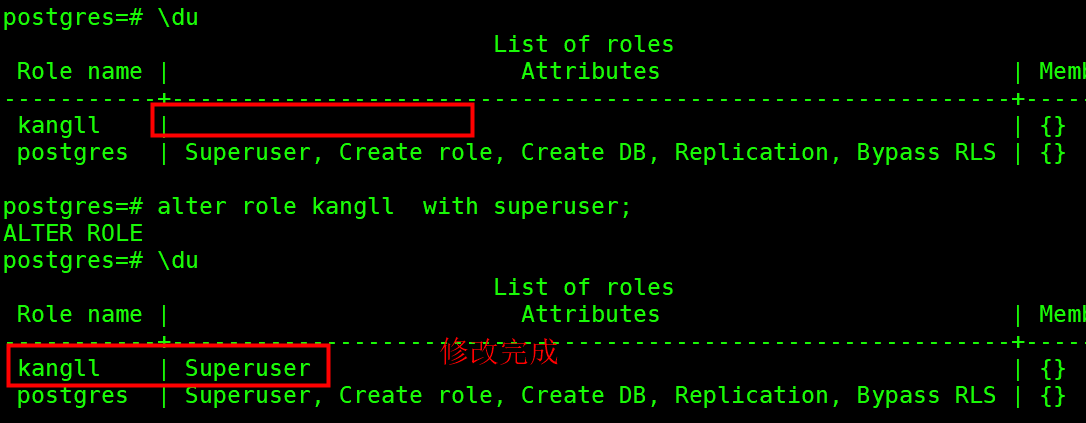
【PostgreSQL】系列之 一 CentOS 7安装PGSQL15版本(一)
目录 一、何为PostgreSQL? 二、PostgreSQL安装 2.1安装依赖 2.2 执行安装 2.3 数据库初始化 2.4 配置环境变量 2.5 创建数据库 2.6 配置远程 2.7 测试远程 三、常用命令 四、用户创建和数据库权限 一、何为PostgreSQL? PostgreSQL是以加州大学…...

Nginx解决文件服务器文件名显示不全的问题
Nginx可以搭建Http文件服务器,但默认的搭建会长文件名显示不全,比如如下: 问题:显示不全,出现...,需要进行解决 这里使用重新编绎nginx的方式,见此文: https://unix.stackexchange…...
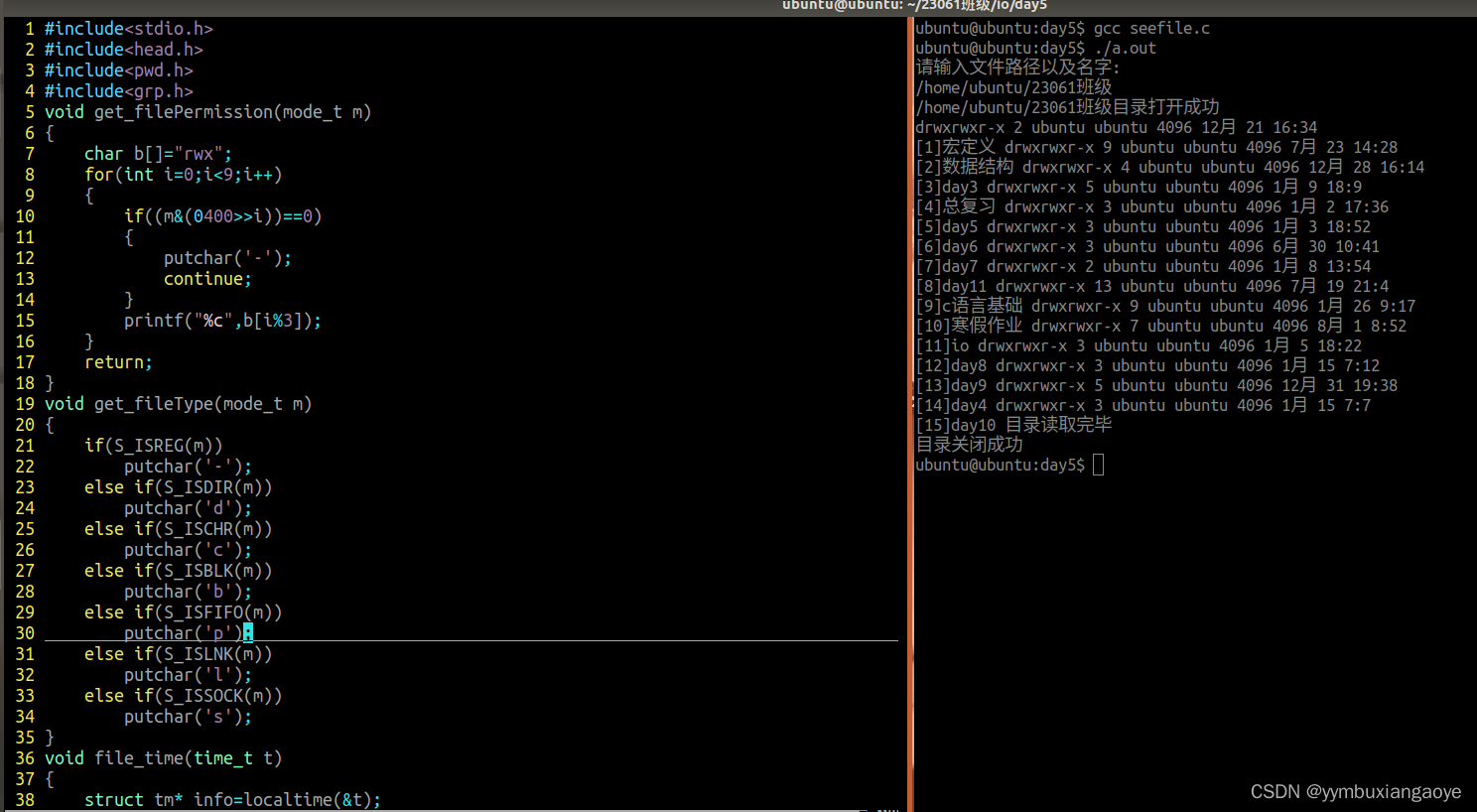
IO进程线程第四天(8.1)
作业1: 从终端获取一个文件的路径以及名字。 若该文件是目录文件,则将该文件下的所有文件的属性显示到终端,类似ls -l该文件夹 若该文件不是目录文件,则显示该文件的属性到终端上,类似ls -l这单个文件 #include<…...

WAF绕过-权限控制篇-后门免杀
WAF绕过主要集中在信息收集,漏洞发现,漏洞利用,权限控制四个阶段。 1、什么是WAF? Web Application Firewall(web应用防火墙),一种公认的说法是“web应用防火墙通过执行一系列针对HTTP/HTTPS的安…...

LED灯的驱动,GPIO子系统,添加按键的中断处理
1.应用程序发送指令控制LED亮灭 2.按键1 按下,led1电位反转 按键2按下,led2电位反转 按键3 按下,led3电位反转 驱动程序: #include <linux/init.h> #include <linux/module.h> #include<linux/of.h> #include…...

Gradle和Maven的区别
Gradle和Maven 当涉及到构建和管理项目时,Gradle和Maven是两个非常流行的选项。本文将讨论Gradle和Maven之间的区别以及它们的配置信息差异。 1. Gradle和Maven的区别 1.1 构建脚本语言 Maven使用XML作为构建脚本语言,而Gradle使用基于Groovy的DSL&…...
C#中 使用yield return 优化大数组或集合的访问
概要 我们在开发过程中,经常需要在一个很大的数组或集合中搜索元素,以满足业务需求。 本文主要介绍通过使用yield return的方式,避免将大量数据全部加载进入内存,再进行处理。从而提高程序的性能。 设计和实现 基本业务场景&a…...
)
ROS实现导航中止(pub命令版+C++代码版)
pub命令 rostopic pub /move_base/cancel actionlib_msgs/GoalID -- {}C代码: stop_navigation.cpp #include <ros/ros.h> #include <geometry_msgs/Twist.h> #include <nav_msgs/Odometry.h> #include <sys/time.h> #include <unistd…...
【VTK】读取一个 STL 文件,并使用 Qt 显示出来,在 Windows 上使用 Visual Studio 配合 Qt 构建 VTK
知识不是单独的,一定是成体系的。更多我的个人总结和相关经验可查阅这个专栏:Visual Studio。 文章目录 A.hA.cppRef. 直接先把效果放出来,有需要就往下看。 A.h // A.h #pragma once#include <QtWidgets/QMainWindow> #include "…...

微信小程序161~200
收货地址实现删除收货地址删除滑块SwipeCell自动收起调用之前的swipeCell商品管理配置商品管理分包-封装商品模块接口import http from "../utils/http"/*** description 获取商品列表数据* param {Object} param {page,limit,categoryId,category2Id}* returns Prom…...
)
STM32F103C8T6+TJA1042+UTA0403:一个CAN通讯新手踩过的所有坑(附完整接线图与代码)
STM32F103C8T6与TJA1042的CAN通讯实战:从零到通的完整避坑指南 当蓝色PCB上那颗STM32F103C8T6第一次通过CAN总线发出数据帧时,我的示波器上终于出现了规整的差分信号波形——这距离我首次焊接CAN收发器已经过去了整整三周。作为嵌入式开发的新手…...
)
揭秘PlayAI语音中台三大核心壁垒:声学模型蒸馏技术、行业术语动态热更新引擎、信创环境全栈适配方案(附某央企POC压测原始数据)
更多请点击: https://kaifayun.com 第一章:PlayAI企业级语音解决方案全景概览 PlayAI 是面向中大型企业的端到端语音智能平台,深度融合ASR(自动语音识别)、TTS(文本转语音)、NLU(自…...

Tiger框架深度剖析:从依赖注入到组件管理的完整指南
Tiger框架深度剖析:从依赖注入到组件管理的完整指南 【免费下载链接】tiger 项目地址: https://gitcode.com/gh_mirrors/ti/tiger Tiger框架是一个基于Java的依赖注入框架,专为Android和Java应用设计,提供了一套完整的组件管理解决方…...

效率优化:把网申填表交给塔塔网申的简历代投,省下时间刷题
招聘季一到,后台一堆私信。本以为大家会问算法题、系统设计,结果点开一看——全在骂网申填表。有个读者给我算了一笔账:投了30家公司,每家填20分钟,就是10个小时。10个小时能干嘛?刷好几套LeetCode…...

天勤 get_account 资金字段读懂:下单前可用与保证金检查
前言 策略信号对了却下不出去,我第一反应看 get_account():是 available 不够,还是把 balance 当可用去和保证金比了。有次模拟盘「明明没下单」却报资金不足,查了半天是字段读错;还有一次夜盘加仓,白天算好…...

智能电表:解锁智能照明精细化能耗管控新密码
摘要随着双碳政策深度落地与智慧楼宇数字化升级,智能照明已成为商业园区、市政道路、综合体的标配设施。传统机械式电表仅具备基础电量统计功能,存在数据滞后、精度不足、无分区计量、无异常监测等短板,无法适配现代照明多回路、多场景、长时…...

从CST到ADS/Keysight:手把手教你导出精准的Touchstone文件做联合仿真
从CST到ADS/Keysight:手把手教你导出精准的Touchstone文件做联合仿真 在射频和微波系统设计中,电磁仿真与电路仿真的无缝衔接是提升设计效率的关键。许多工程师都曾遇到过这样的困境:在CST中精心优化的天线或滤波器模型,导出后却无…...

对抗机器学习实战:从模型脆弱性到工业级鲁棒性工程
1. 项目概述:当模型开始“看走眼”,我们该怎么办?你有没有遇到过这样的情况:一张清晰的猫图,被模型坚定地判为“烤面包”;一段语音指令,加了点人耳几乎听不出的杂音,智能音箱就把它理…...

从‘阿强爱上阿珍’到程序验证:自然演绎规则在软件测试中的实战应用
逻辑引擎:自然演绎规则在软件质量保障中的工程化实践 当测试工程师面对一段复杂的状态机代码时,他们手中的武器不仅仅是JUnit或Selenium——数理逻辑中的自然演绎规则正在成为新一代质量保障的"秘密武器"。从反证法驱动的边界条件设计…...