GFS 分布式文件系统
目录
一、GlusterFS 概述
1.2.GlusterFS特点
1.3.GlusterFS 术语
1.4GlusterFS 的工作流程
二、GlusterFS的卷类型
2.1分布式卷(Distribute volume)
2.1.1特点
2.2条带卷(Stripe volume)
2.2.1条带卷特点
2.3复制卷(Replica volume)
2.3.1复制卷特点
2.4分布式条带卷(Distribute Stripe volume)
2.5分布式复制卷(Distribute Replica volume)
2.6条带复制卷(Stripe Replica volume)
2.7分布式条带复制卷(Distribute Stripe Replicavolume)
三、部署 GlusterFS 群集
3.1磁盘分区,并挂载
3.2修改主机名,配置/etc/hosts文件
3.3安装、启动GlusterFS(所有node节点上操作)
3.3.1 书写yum源脚本并执行
3.4安装gluster并开启
3.5添加节点到存储信任池中(在 node1 节点上操作)
3.5.1在每个Node节点上查看群集状态
3.6创建卷
3.6.1.创建分布式卷
3.6.2创建条带卷
3.6.3创建复制卷
3.6.4创建分布式条带卷
3.6.5创建分布式复制卷
3.6.6查看当前所有卷的列表
3.7部署 Gluster 客户端
3.7.1安装客户端软件
3.7.2.创建挂载目录
3.7.3配置 /etc/hosts 文件
3.7.4挂载 Gluster 文件系统
4.8测试 Gluster 文件系统
四、扩展
4.1.查看GlusterFS卷
4.2.查看所有卷的信息
4.3.查看所有卷的状态
4.4.停止一个卷
4.5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
4.6.设置卷的访问控制
4.6.1#仅拒绝
4.6.2#仅允许
一、GlusterFS 概述
GlusterFS 是一个开源的分布式文件系统。 由存储服务器、客户端以及NFS/Samba 存储网关(可选,根据需要选择使用)组成。
没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性。
1.2.GlusterFS特点
扩展性和高性能
高可用性
全局统一命名空间
弹性卷管理
基于标准协议
1.3.GlusterFS 术语
Brick(存储块): 指可信主机池中由主机提供的用于物理存储的专用分区,是GlusterFS中的基本存储单元,同时也是可信存储池中服务器上对外提供的存储目录。 存储目录的格式由服务器和目录的绝对路径构成,
表示方法为 :SERVER:EXPORT,如 192.168.80.10:/data/mydir/。
Volume(逻辑卷): 一个逻辑卷是一组 Brick 的集合。卷是数据存储的逻辑设备,类似于 LVM 中的逻辑卷。大部分 Gluster 管理操作是在卷上进行的。
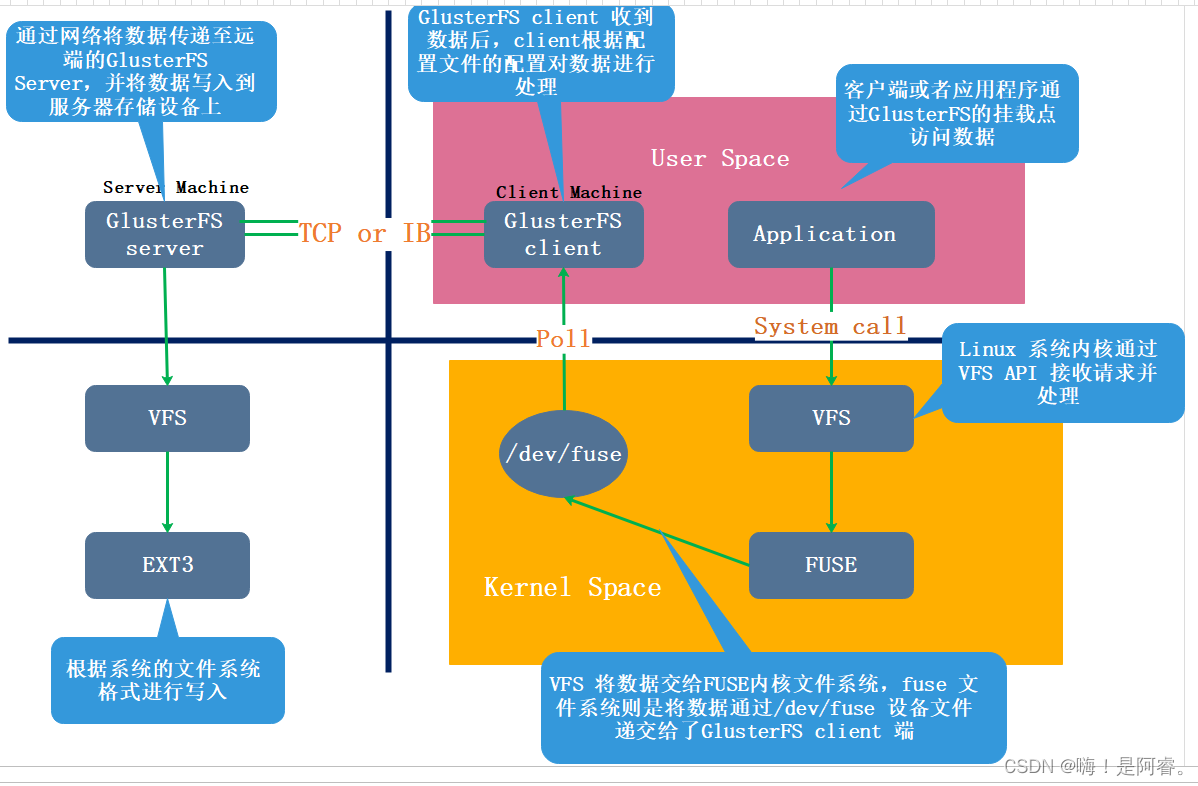
FUSE: 是一个内核模块,允许用户创建自己的文件系统,无须修改内核代码。 伪文件系统
VFS: 内核空间对用户空间提供的访问磁盘的接口。 虚拟端口
Glusterd(后台管理进程): 服务端 在存储群集中的每个节点上都要运行。
GFS 以上虚拟文件系统
1.4GlusterFS 的工作流程
二、GlusterFS的卷类型
GlusterFS 支持七种卷,即分布式卷、条带卷、复制卷、分布式条带卷、分布式复制卷、条带复制卷和分布式条带复制卷。
2.1分布式卷(Distribute volume)
文件通过 HASH 算法分布到所有 Brick Server 上,这种卷是 GlusterFS 的默认卷;以文件为单位根据 HASH 算法散列到不同的 Brick,其实只是扩大了磁盘空间,如果有一块磁盘损坏,数据也将丢失,属于文件级的 RAID0, 不具有容错能力。 在该模式下,并没有对文件进行分块处理,文件直接存储在某个 Server 节点上。 由于直接使用本地文件系统进行文件存储,所以存取效率并没有提高,反而会因为网络通信的原因而有所降低。
2.1.1特点
- 文件分布在不同的服务器,不具备冗余性。
- 更容易和廉价地扩展卷的大小。
- 单点故障会造成数据丢失。
- 依赖底层的数据保护。
创建一个名为dis-volume的分布式卷,文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中
gluster volume create dis-volume server1:/dir1 server2:/dir2 server3:/dir32.2条带卷(Stripe volume)
类似 RAID0,文件被分成数据块并以轮询的方式分布到多个 Brick Server 上,文件存储以数据块为单位,支持大文件存储, 文件越大,读取效率越高,但是不具备冗余性。
#示例原理: File 被分割为 6 段,1、3、5 放在 Server1,2、4、6 放在 Server2。
2.2.1条带卷特点
- 数据被分割成更小块分布到块服务器群中的不同条带区。
- 分布减少了负载且更小的文件加速了存取的速度。
- 没有数据冗余。
#创建了一个名为stripe-volume的条带卷,文件将被分块轮询的存储在Server1:/dir1和Server2:/dir2两个Brick中
gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir22.3复制卷(Replica volume)
将文件同步到多个 Brick 上,使其具备多个文件副本,属于文件级 RAID 1,具有容错能力。因为数据分散在多个 Brick 中,所以读性能得到很大提升,但写性能下降。 复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低。
#示例原理: File1 同时存在 Server1 和 Server2,File2 也是如此,相当于 Server2 中的文件是 Server1 中文件的副本。
2.3.1复制卷特点
- 卷中所有的服务器均保存一个完整的副本。
- 卷的副本数量可由客户创建的时候决定,但复制数必须等于卷中 Brick 所包含的存储服务器数。
- 至少由两个块服务器或更多服务器。
- 具备冗余性。
#创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir22.4分布式条带卷(Distribute Stripe volume)
Brick Server 数量是条带数(数据块分布的 Brick 数量)的倍数,兼具分布式卷和条带卷的特点。 主要用于大文件访问处理,创建一个分布式条带卷最少需要 4 台服务器。
#示例原理:
File1 和 File2 通过分布式卷的功能分别定位到Server1和 Server2。在 Server1 中,File1 被分割成 4 段,其中 1、3 在 Server1 中的 exp1 目录中,2、4 在 Server1 中的 exp2 目录中。在 Server2 中,File2 也被分割成 4 段,其中 1、3 在 Server2 中的 exp3 目录中,2、4 在 Server2 中的 exp4 目录中。
#创建一个名为dis-stripe的分布式条带卷,配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),条带数为 2(stripe 2)
gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4创建卷时,存储服务器的数量如果等于条带或复制数,那么创建的是条带卷或者复制卷;如果存储服务器的数量是条带或复制数的 2 倍甚至更多,那么将创建的是分布式条带卷或分布式复制卷。
2.5分布式复制卷(Distribute Replica volume)
Brick Server 数量是镜像数(数据副本数量)的倍数,兼具分布式卷和复制卷的特点。主要用于需要冗余的情况下。
#示例原理:
File1 和 File2 通过分布式卷的功能分别定位到 Server1 和 Server2。在存放 File1 时,File1 根据复制卷的特性,将存在两个相同的副本,分别是 Server1 中的exp1 目录和 Server2 中的 exp2 目录。在存放 File2 时,File2 根据复制卷的特性,也将存在两个相同的副本,分别是 Server3 中的 exp3 目录和 Server4 中的 exp4 目录。
#创建一个名为dis-rep的分布式复制卷,配置分布式的复制卷时,卷中Brick所包含的存储服务器数必须是复制数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),复制数为 2(replica 2)
gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir42.6条带复制卷(Stripe Replica volume)
类似 RAID 10,同时具有条带卷和复制卷的特点。
2.7分布式条带复制卷(Distribute Stripe Replicavolume)
三种基本卷的复合卷,通常用于类 Map Reduce 应用。
三、部署 GlusterFS 群集
Node1节点:node1/192.168.237.21 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node2节点:node2/192.168.237.22 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node3节点:node3/192.168.1237.23 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node4节点:node4/192.168.237.24 磁盘:/dev/sdb1 挂载点:/data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1客户端节点:192.168.237.253.1磁盘分区,并挂载
#写一个分区脚本脚本
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
doecho -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/nullmkfs.xfs /dev/${VAR}"1" &> /dev/nullmkdir -p /data/${VAR}"1" &> /dev/nullecho "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null#运行脚本
chmod +x /opt/fdisk.sh
cd /opt/
./fdisk.sh3.2修改主机名,配置/etc/hosts文件
#192.168.237.21
hostnamectl set-hostname node1
su
#192.168.237.22
hostnamectl set-hostname node2
su
#192.168.237.23
hostnamectl set-hostname node3
su
#192.168.237.24
hostnamectl set-hostname node4
suvim /etc/hosts
192.168.237.21 node1
192.168.237.22 node2
192.168.237.23 node3
192.168.237.24 node43.3安装、启动GlusterFS(所有node节点上操作)
#将gfsrepo 软件上传到/opt目录下

3.3.1 书写yum源脚本并执行
vim glfs.sh#!/bin/bash
function backuprepo {
cd /etc/yum.repos.d
mkdir repo.bak
mv *.repo repo.bak
#mount /dev/sr0 /mnt > /dev/null
}makeglfsrepo(){
echo '[glfs]
name = glfs
baseurl=file:///opt/gfsrepo
enabled=1
gpgcheck=0' > glfs.repo
}useglfsrepo (){
yum clean all > /dev/null
yum makecache > /dev/null}#install () {#yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
#systemctl start glusterd.service
#systemctl enable glusterd.service
#systemctl status glusterd.service
#}
#============main==============
backuprepo
makeglfsrepo
useglfsrepo
#install#运行脚本
chmod +x /opt/glfs.sh
cd /opt/
./glfs.sh3.4安装gluster并开启
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdmasystemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service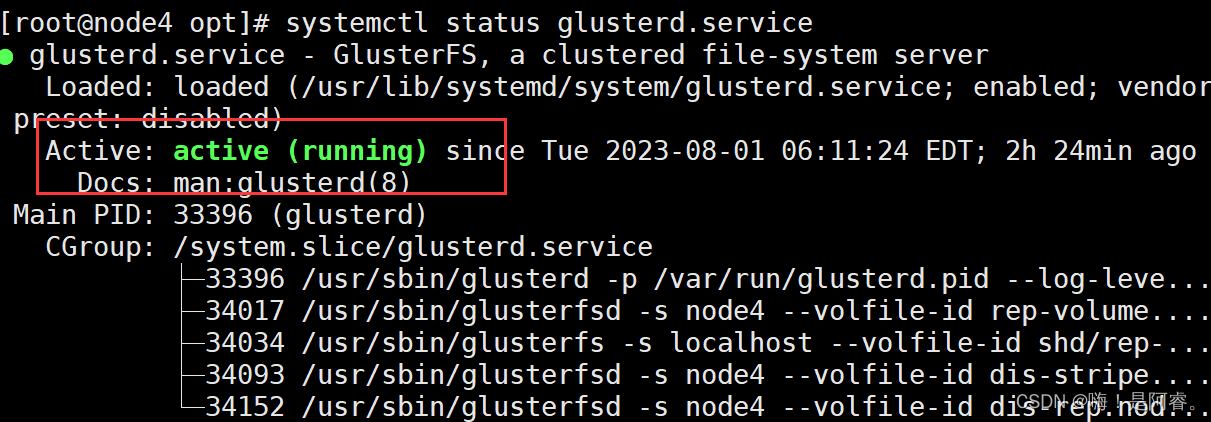
如果有 故障原因是版本过高导致
执行一下操作再,装一遍gluster
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y3.5添加节点到存储信任池中(在 node1 节点上操作)
#只要在一台Node节点上添加其它节点即可
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node43.5.1在每个Node节点上查看群集状态
gluster peer status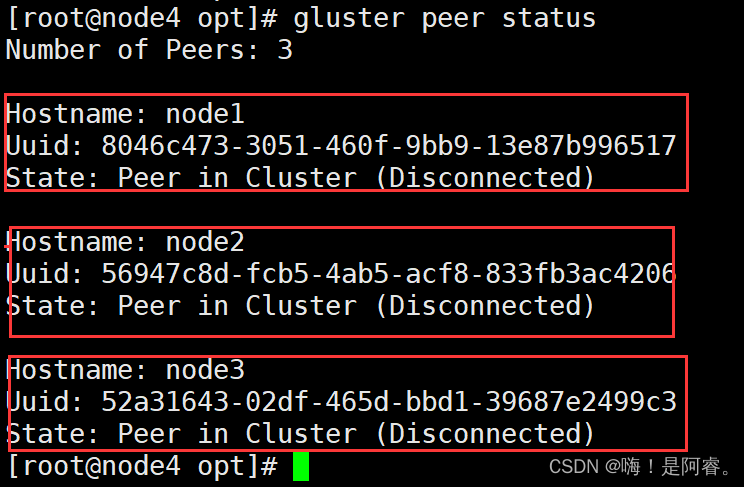
3.6创建卷
| 卷名称 | 卷类型 | Brick |
| dis-volume | 分布式卷 | node1(/data/sdb1)、node2(/data/sdb1) |
| stripe-volume | 条带卷 | node1(/data/sdc1)、node2(/data/sdc1) |
| rep-volume | 复制卷 | node3(/data/sdb1)、node4(/data/sdb1) |
| dis-stripe | 分布式条带卷 | node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1) |
| dis-rep | 分布式复制卷 | node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、 |
3.6.1.创建分布式卷
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force #查看卷列表
gluster volume list#启动新建分布式卷
gluster volume start dis-volume#查看创建分布式卷信息
gluster volume info dis-volume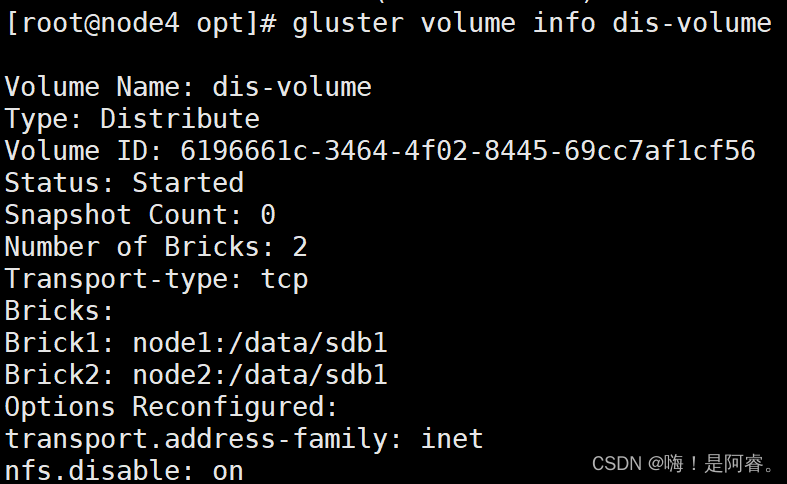
3.6.2创建条带卷
#指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
gluster volume start stripe-volume
gluster volume info stripe-volume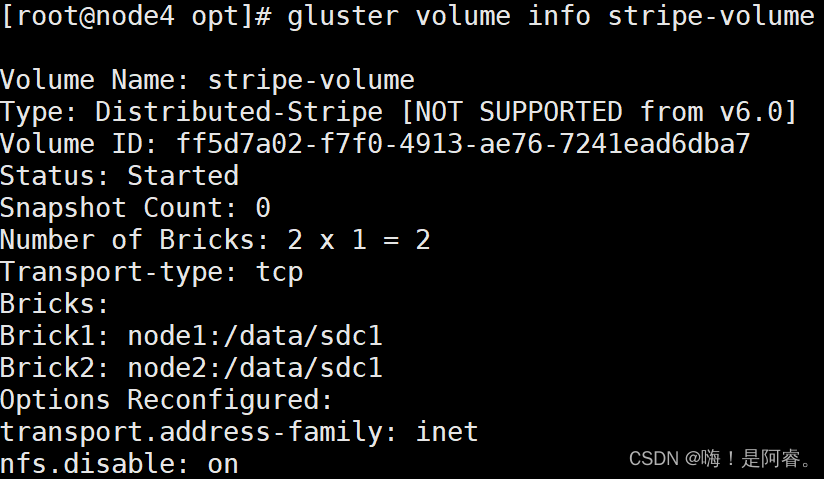
3.6.3创建复制卷
#指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force
gluster volume start rep-volume
gluster volume info rep-volume
3.6.4创建分布式条带卷
#指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式条带卷
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
gluster volume start dis-stripe
gluster volume info dis-stripe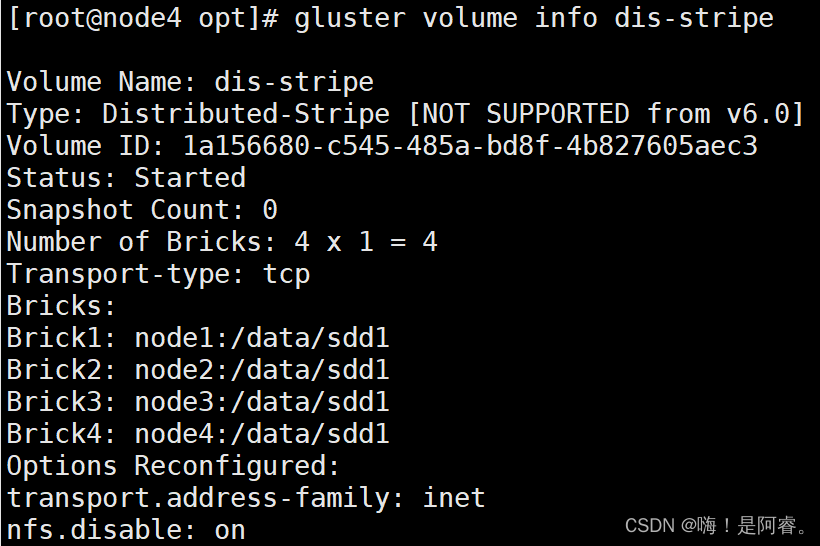
3.6.5创建分布式复制卷
指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
gluster volume start dis-rep
gluster volume info dis-rep 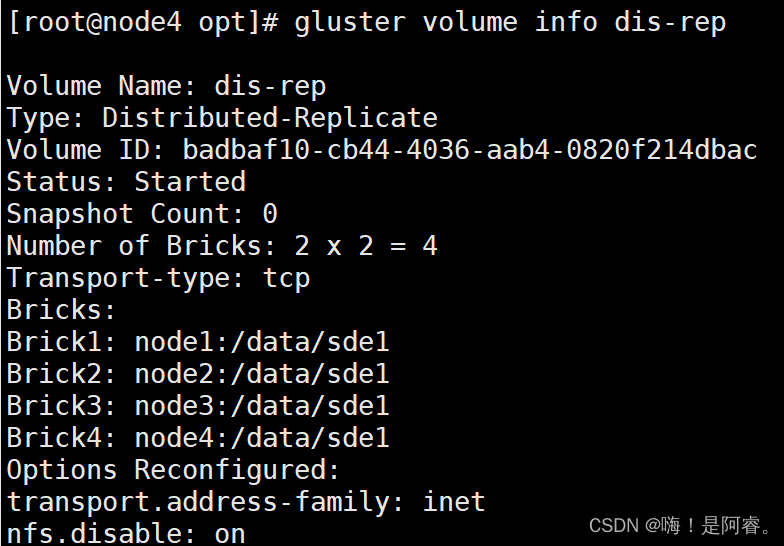
3.6.6查看当前所有卷的列表
gluster volume list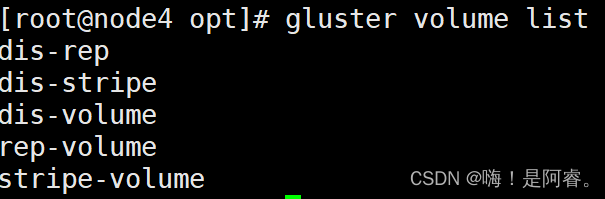
3.7部署 Gluster 客户端
3.7.1安装客户端软件
#将gfsrepo 软件上传到/opt目下
vim glfs.sh#!/bin/bash
function backuprepo {
cd /etc/yum.repos.d
mkdir repo.bak
mv *.repo repo.bak
#mount /dev/sr0 /mnt > /dev/null
}makeglfsrepo(){
echo '[glfs]
name = glfs
baseurl=file:///opt/gfsrepo
enabled=1
gpgcheck=0' > glfs.repo
}useglfsrepo (){
yum clean all > /dev/null
yum makecache > /dev/null}#install () {#yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
#systemctl start glusterd.service
#systemctl enable glusterd.service
#systemctl status glusterd.service
#}
#============main==============
backuprepo
makeglfsrepo
useglfsrepo
#install#运行脚本
chmod +x /opt/glfs.sh
cd /opt/
./glfs.sh#安装Gluster
yum -y install glusterfs glusterfs-fuse3.7.2.创建挂载目录
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test3.7.3配置 /etc/hosts 文件
vim /etc/hosts
192.168.237.21 node1
192.168.237.22 node2
192.168.237.23 node3
192.168.237.24 node43.7.4挂载 Gluster 文件系统
#临时挂载
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_repdf -Th#永久挂载
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 04.8测试 Gluster 文件系统
#1.卷中写入文件,客户端操作
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40ls -lh /optcp /opt/demo* /test/dis
cp /opt/demo* /test/stripe/
cp /opt/demo* /test/rep/
cp /opt/demo* /test/dis_stripe/
cp /opt/demo* /test/dis_rep/#2.查看文件分布
#查看分布式文件分布
[root@node1 ~]# ls -lh /data/sdb1 #数据没有被分片
总用量 160M
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo4.log
[root@node2 ~]# ll -h /data/sdb1
总用量 40M
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo5.log#查看条带卷文件分布
[root@node1 ~]# ls -lh /data/sdc1 #数据被分片50% 没副本 没冗余
总用量 101M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log[root@node2 ~]# ll -h /data/sdc1 #数据被分片50% 没副本 没冗余
总用量 101M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log#查看复制卷分布
[root@node3 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余
总用量 201M
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo5.log[root@node4 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余
总用量 201M
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo5.log#查看分布式条带卷分布
[root@node1 ~]# ll -h /data/sdd1 #数据被分片50% 没副本 没冗余
总用量 81M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log[root@node2 ~]# ll -h /data/sdd1
总用量 81M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log[root@node3 ~]# ll -h /data/sdd1
总用量 21M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log[root@node4 ~]# ll -h /data/sdd1
总用量 21M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log#查看分布式复制卷分布 #数据没有被分片 有副本 有冗余
[root@node1 ~]# ll -h /data/sde1
总用量 161M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo4.log[root@node2 ~]# ll -h /data/sde1
总用量 161M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo4.log[root@node3 ~]# ll -h /data/sde1
总用量 41M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo5.log
[root@node3 ~]# [root@node4 ~]# ll -h /data/sde1
总用量 41M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo5.log----- 破坏性测试 -----
#挂起 node2 节点或者关闭glusterd服务来模拟故障
[root@node2 ~]# systemctl stop glusterd.service#在客户端上查看文件是否正常
#分布式卷数据查看
[root@localhost test]# ll /test/dis/ #在客户机上发现少了demo5.log文件,这个是在node2上的
总用量 163840
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo4.log#条带卷
[root@localhost test]# cd /test/stripe/ #无法访问,条带卷不具备冗余性
[root@localhost stripe]# ll
总用量 0#分布式条带卷
[root@localhost test]# ll /test/dis_stripe/ #无法访问,分布条带卷不具备冗余性
总用量 40960
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo5.log#分布式复制卷
[root@localhost test]# ll /test/dis_rep/ #可以访问,分布式复制卷具备冗余性
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo5.log#挂起 node2 和 node4 节点,在客户端上查看文件是否正常
#测试复制卷是否正常
[root@localhost rep]# ls -l /test/rep/ #在客户机上测试正常 数据有
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo5.log#测试分布式条卷是否正常
[root@localhost dis_stripe]# ll /test/dis_stripe/ #在客户机上测试没有数据
总用量 0#测试分布式复制卷是否正常
[root@localhost dis_rep]# ll /test/dis_rep/ #在客户机上测试正常 有数据
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo5.log四、扩展
扩展其他的维护命令
4.1.查看GlusterFS卷
gluster volume list 4.2.查看所有卷的信息
gluster volume info4.3.查看所有卷的状态
gluster volume status4.4.停止一个卷
gluster volume stop dis-stripe4.5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume stop dis-stripe4.6.设置卷的访问控制
4.6.1#仅拒绝
gluster volume set dis-rep auth.deny 192.168.80.1004.6.2#仅允许
gluster volume set dis-rep auth.allow 192.168.80.* #设置192.168.80.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)相关文章:
GFS 分布式文件系统
目录 一、GlusterFS 概述 1.2.GlusterFS特点 1.3.GlusterFS 术语 1.4GlusterFS 的工作流程 二、GlusterFS的卷类型 2.1分布式卷(Distribute volume) 2.1.1特点 2.2条带卷(Stripe volume) 2.2.1条…...

PHP-mysql学习笔记
如题 记录发送emoji数据无法正常显示的问题PHPMysql 记录 发送emoji数据无法正常显示的问题 问题描述 前端发送关于emoji的表情数据给php,php写入mysql php接收到了数据,但无法写入写入过后返回前端无法正常显示 PHP 在对应的pdd函数中设置字符集为utf8mb4 Mysql emoji数…...
AI技术快讯:清华开源ChatGLM2双语对话语言模型
ChatGLM2-6B是一个开源项目,提供了ChatGLM2-6B模型的代码和资源。根据提供的搜索结果,以下是对该项目的介绍: 论文:https://arxiv.org/pdf/2103.10360.pdf ChatGLM2-6B是一个开源的双语对话语言模型,是ChatGLM-6B模…...

网络基础知识
1、什么是链接? 链接是指两个设备之间的连接。它包括用于一个设备能够与另一个设备通信的电缆类型和协议。 2、OSI 参考模型的层次是什么? 有 7 个 OSI 层:物理层,数据链路层,网络层,传输层,会话层,表…...
【应用层】HTTPS协议详细介绍
文章目录 前言一、什么是"加密"二、常见的加密方式三、数据摘要(数据指纹)四、证书总结 前言 HTTPS也是一个应用层协议,是在HTTP协议的基础上引入了一个加密层,由于HTTP协议内容都是按照文本的方式明文传输的ÿ…...

【Tensorboard+Pytorch】使用注意事项
安装 tensorboard/tensorboardx版本需要与tensorflow保持一致(本人使用2.2) 调用 环境变量 在终端或CMD中使用时,常见报错“tensorboard 不是内部或外部命令……”,需要添加环境变量路径path。具体为tensorboard.exe所在目录(A…...
设计模式行为型——命令模式
目录 什么是命令模式 命令模式的实现 命令模式角色 命令模式类图 命令模式举例 命令模式代码实现 命令模式的特点 优点 缺点 使用场景 注意事项 什么是命令模式 命令模式(Command Pattern)是一种数据驱动的设计模式,它属…...
)
13-2_Qt 5.9 C++开发指南_线程同步_QMutex+QMutexLocker(目前较为常用)
文章目录 1.线程同步的概念2. 基于互斥量的线程同步3.QMutex实现线程同步源代码3.1 qdicethread.h3.2 qdicethread.cpp3.3 dialog.h3.4 dialog.cpp 4.QMutexLocker 实现线程同步源代码4.1 qdicethread.h4.2 qdicethread.cpp4.3 dialog.h4.4 dialog.cpp 1.线程同步的概念 在多线…...
金融行业选择哪种SSL证书才安全可靠
由于金融领域等网站拥有大量客户的敏感信息,且每天都有大量交易需要进行,涉及到大量的资金问题,当这些机构提供的网络和Web应用程序没有足够的安全措施来阻止黑客窃取数据时,就会出现严重的安全问题。而且由于黑客每天都在开发越来…...
面试总结(三)
1.进程和线程的区别 根本区别:进程是操作系统分配资源的最小单位;线程是CPU调度的最小单位所属关系:一个进程包含了多个线程,至少拥有一个主线程;线程所属于进程开销不同:进程的创建,销毁&…...
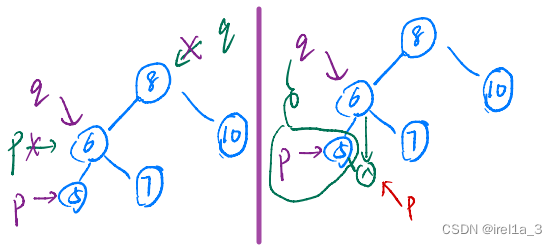
青大数据结构【2016】
一、单选 二、简答 3.简述遍历二叉树的含义及常见的方法。 4.简要说明图的邻接表的构成。 按顺序将图G中的顶点数据存储在一维数组中, 每一个顶点vi分别建立一个单链表,单链表关联依附顶点vi的边(有向图为以vi为尾的弧)。 邻接…...
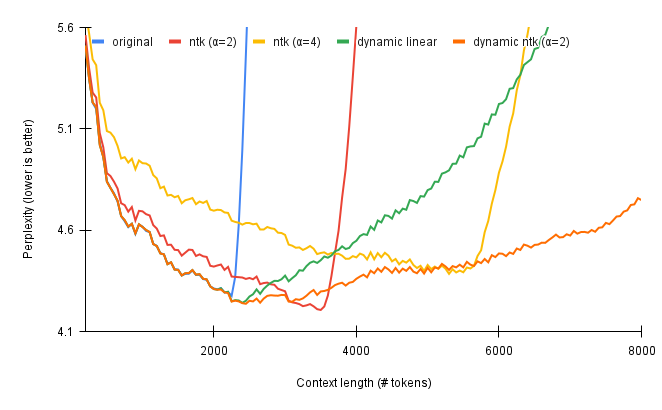
聊聊拉长LLaMA的一些经验
Sequence Length是指LLM能够处理的文本的最大长度,越长,自然越有优势: 更强的记忆性。更多轮的历史对话被拼接到对话中,减少出现遗忘现象 长文本场景下体验更佳。比如文档问答、小说续写等 当今开源LLM中的当红炸子鸡——LLaMA…...

线程池的使用详解
一 使用线程池的好处 池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。 线程池提供了一种限制和管理资源(包括执行一个任…...

刷题笔记 day4
力扣 611 有效三角形的个数 首先需要知道如何判断 三个数是否能构成三角形。 假如 存在三个数 a < b < c,如果要构成三角形,需要满足: ab > c ; a c > b ; b c > a ; 任意两个数大于第三个数就可构成三角形。 其实不难…...

Python 2.x 中如何使用flask模块进行Web开发
Python 2.x 中如何使用 Flask 模块进行 Web 开发 引言: 随着互联网的快速发展,Web开发成为了互联网行业中一项非常重要的技术。而在 Python 的Web开发中,Flask框架是一种非常流行的选择。它简单轻巧,灵活易用,适合中小型项目的快…...

spring websocket 调用受权限保护的方法失败
版本 spring-security 5.6.10 spring-websocket 5.3.27 现象 通过AbstractWebSocketHandler实现websocket端点处理器 调用使用PreAuthorize注解的方法报错,无法在SecurityContext中找到认证信息 org.springframework.security.authentication.AuthenticationCred…...

Vue.js2+Cesium 四、模型对比
Vue.js2Cesium 四、模型对比 Cesium 版本 1.103.0,低版本 Cesium 不支持 Compare 对比功能。 Demo 同一区域的两套模型,实现对比功能 <template><div style"width: 100%; height: 100%;"><divid"cesium-container"…...

Linux 之 Vi 编辑器
文章目录 1. vi/vim介绍2. vi/vim使用详解2.1 vi/vim的特点2.2 vi/vim三种编辑模式2.3 文本编辑方式 1. vi/vim介绍 vi编辑器是linux和unix上最基本的文本编辑器,工作在字符模式下。由于不需要图形界面,vi是效率很高的文本编辑器。尽管在linux上也有很多…...

Python超实用!批量重命名文件/文件夹,只需1行代码
大家好,这里是程序员晚枫,之前在小破站给大家分享了一个视频:批量重命名文件。 最近在程序员晚枫的读者群里,发现很多朋友对这个功能很感兴趣,尤其是对下一步的优化:批量重命名文件夹。 这周我利用下班时…...

sqoop
一、bg 可以在关系型数据库和hdfs、hive、hbase之间导数 导入:从RDBMS到hdfs、hive、hbase 导出:相反 sqoop1 和sqoop2 (1.99.x)不兼容,sqoop2 并没有生产的稳定版本, Sqoop1 import原理(导入) 从传统数据库获取元数据信息&…...

Unity启动Logo跳过指南:三步实现多平台秒开启动
1. 为什么Unity启动Logo不是“装饰”,而是必须被正视的交付环节你刚打包完一个Unity游戏,兴冲冲地发给测试同事,对方点开exe——先是一片黑屏,接着弹出那个熟悉的、带渐变动画的Unity Logo,再过3秒才进主菜单。测试发来…...

ESXi勒索防护实战:堵住配置天窗,构建三层纵深防御
1. 这不是“又一起”勒索事件,而是ESXi生态链断裂的警报 2023年底开始,全球范围内大量VMware ESXi服务器被植入名为 ESXiArgs (也称 KPOT )的勒索软件,攻击波及金融、医疗、教育、制造等数十个行业。这不是传统意义…...

朱雀广告平台:3分钟了解开源广告系统的核心优势
朱雀广告平台:3分钟了解开源广告系统的核心优势 【免费下载链接】zhuque 开放源码的一站式广告平台,包含ssp/adx/dsp/dmp模块 项目地址: https://gitcode.com/gh_mirrors/zhu/zhuque 在数字营销时代,广告技术平台是企业实现精准投放和…...

告别手动抓瞎:用vmp3-import-fix-x86和Universal Import Fixer搞定VMP3.5壳的IAT修复
VMP3.5壳IAT修复的高效工具链实践指南 逆向工程领域里,VMProtect始终是令人又爱又恨的存在。特别是3.5版本引入的IAT混淆机制,让不少安全研究员在深夜调试时抓狂。传统手动修复不仅耗时耗力,还容易遗漏关键调用。经过多次实战验证࿰…...

【紧急预警】你还在裸用ChatGPT写生产代码?这4类高危漏洞已致37家团队线上事故
更多请点击: https://kaifayun.com 第一章:ChatGPT编程辅助的底层风险认知与责任边界界定 当开发者将ChatGPT嵌入编码工作流时,其输出常被误认为具备工程级可靠性。然而,模型生成的代码本质上是统计拟合结果,不具备形…...

液冷及前沿散热技术的理论分析:从宏观系统到芯片级散热的范式跃迁
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 211、985硕士,从业16年 从事结构设计、热设计、售前、产品设计、项目管理等工作,涉足消费电子、新能源、医疗设备、制药信息化、核工业等…...

如何5分钟掌握SD-PPP:Photoshop AI插件完整入门指南
如何5分钟掌握SD-PPP:Photoshop AI插件完整入门指南 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp SD-PPP是一款革命性的Photoshop AI插件,它将强大的AI绘图能力无缝集成到Adobe Photoshop…...

5种方法高效解决DWG文件格式兼容性问题:LibreDWG开源CAD库完整指南
5种方法高效解决DWG文件格式兼容性问题:LibreDWG开源CAD库完整指南 【免费下载链接】libredwg Official mirror of libredwg. With CI hooks and nightly releases. PRs ok 项目地址: https://gitcode.com/gh_mirrors/li/libredwg LibreDWG是一个免费开源的C…...

如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk
如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk 【免费下载链接】ppInk Fork from Gink 项目地址: https://gitcode.com/gh_mirrors/pp/ppInk 你是否曾在演示、教学或远程协作中,需要在屏幕上快速标注重点,却发现工具要么太复杂࿰…...

5分钟实现OBS多平台同步直播:obs-multi-rtmp插件完全指南
5分钟实现OBS多平台同步直播:obs-multi-rtmp插件完全指南 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 你是否厌倦了在不同直播平台间来回切换的繁琐操作?obs-…...