使用langchain与你自己的数据对话(四):问答(question answering)
之前我已经完成了使用langchain与你自己的数据对话的前三篇博客,还没有阅读这三篇博客的朋友可以先阅读一下:
- 使用langchain与你自己的数据对话(一):文档加载与切割
- 使用langchain与你自己的数据对话(二):向量存储与嵌入
- 使用langchain与你自己的数据对话(三):检索(Retrieval)
今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第五门课:问答(question answering)
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
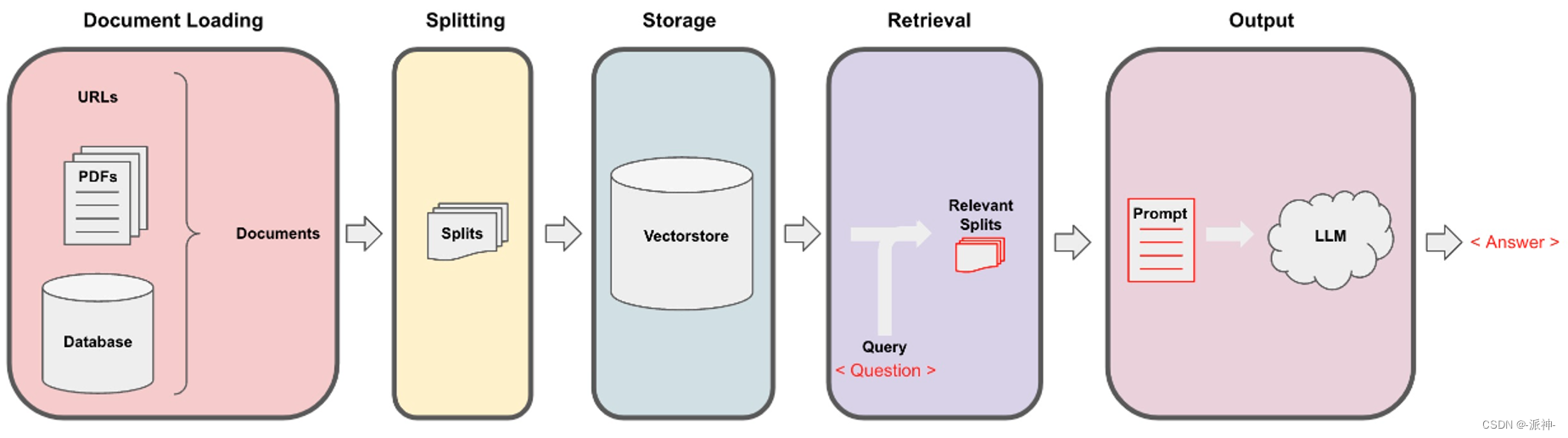
在上一篇博客:检索(Retrieval) 中我们介绍了基本语义相似度(Basic semantic similarity),最大边际相关性(Maximum marginal relevance,MMR), 过滤元数据, LLM辅助检索等内容,接下来就来到了最后一个环节:output
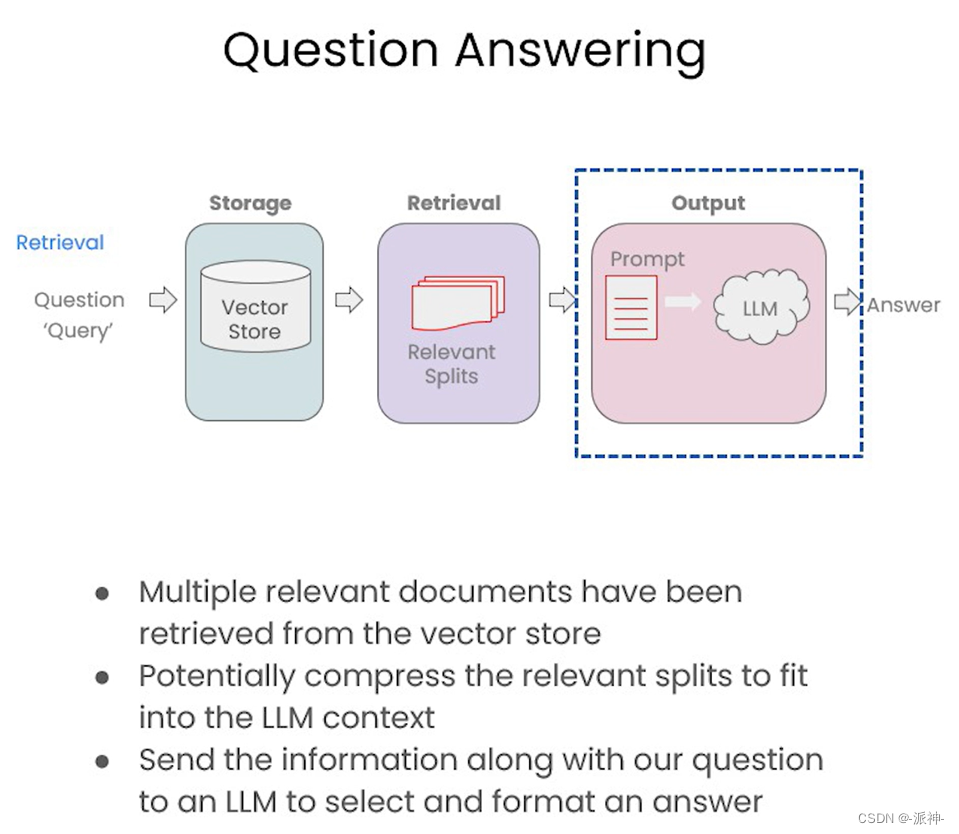
在最后的输出环节中,我们会将前一阶段检索(Retrieval)的结果,也就是与用户问题相关的文档块(可能会存在多个相关的文档块),连同用户的问题一起喂给LLM,最后LLM返回给我们所需要的答案:
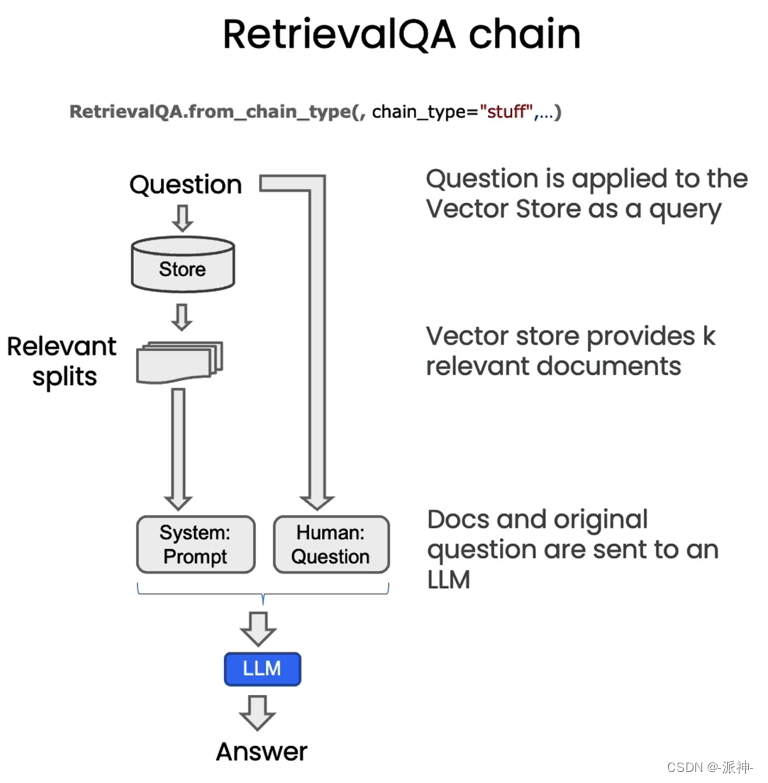
在默认的情况下,我们会将所有的相关文档一次性的全部传给LLM,即所谓的“stuff”的chain type方式。这在我之前写的博客中有详细的说明,stuff方式虽然很方便,但是也存在缺点,就是当检索出来的相关文档很多时,就会报超出最大 token 限制的错。除了stuff方式还有如下几种chain type的方式如下图所示:
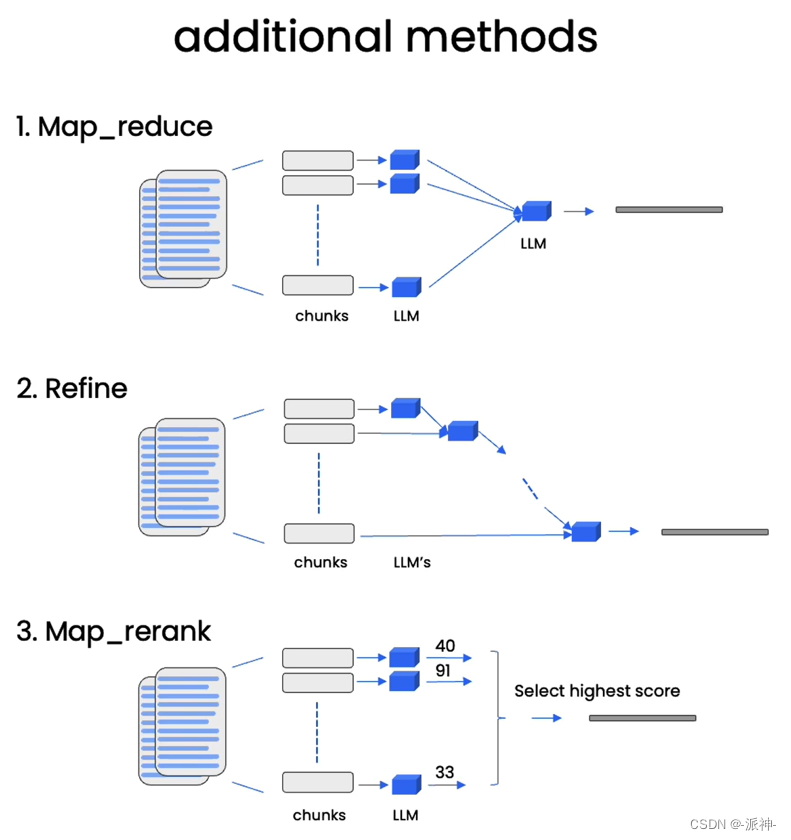
关于map_reduce,refine, map_rerank等方式基本原理在我之前写的博客:LangChain大型语言模型(LLM)应用开发(四):Q&A over Documents中都有说明,这里不再赘述,不过在本文后续的代码演示中我会涉及到这几种方式。
加载向量数据库
在讨论这些新技术之前,先让我们完成一些基础性工作,比如设置一下openai的api key:
import os
import openai
import sys
sys.path.append('../..')from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']接下来我们需要先加载一下在之前的博客中我们在本地创建的关于吴恩达老师的机器学习课程cs229课程讲义(pdf)的向量数据库:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddingspersist_directory = 'docs/chroma/'embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)#打印向量数据库中的文档数量
print(vectordb._collection.count())
这里我们加载了之前保存在本地的向量数据库,并查询了数据库中的文档数量为209,这与我们之前创建该数据库时候的文档数量是一致的,接下来我们提出一个问题:“What are major topics for this class?”,即“ 这门课的主要主题是什么?” 然后用similarity_search方法来查询一下与该问题相关的文档块:
question = "What are major topics for this class?"
docs = vectordb.similarity_search(question,k=3)
len(docs)
这里我们看到similarity_search方法搜索到了3给与该问题相关的文档块。接下来我们查看一下这3个文档:
docs
这里我们看到similarity_search返回的3给文档中,第一,第二篇文档的内容是相同的,这是因为我们在创建这个向量数据库时重复加载了一篇文档(pdf),这导致similarity_search搜索出来文档存在重复的可能性,要解决这个问题,可以使用max_marginal_relevance_search方法,该方法可以让结果的相关性和多样性保持均衡,关于具体实现的原理可以参考我之前写的博客。
RetrievalQA chain
接下来我们要创建一个检索问答链(RetrievalQA),然后将相关文档的搜索结果以及用户的问题喂给RetrievalQA,让它来产生最终的答案,不过首先我们需要创建一个openai的LLM:
from langchain.chat_models import ChatOpenAI#创建llm
llm = ChatOpenAI(temperature=0)
llm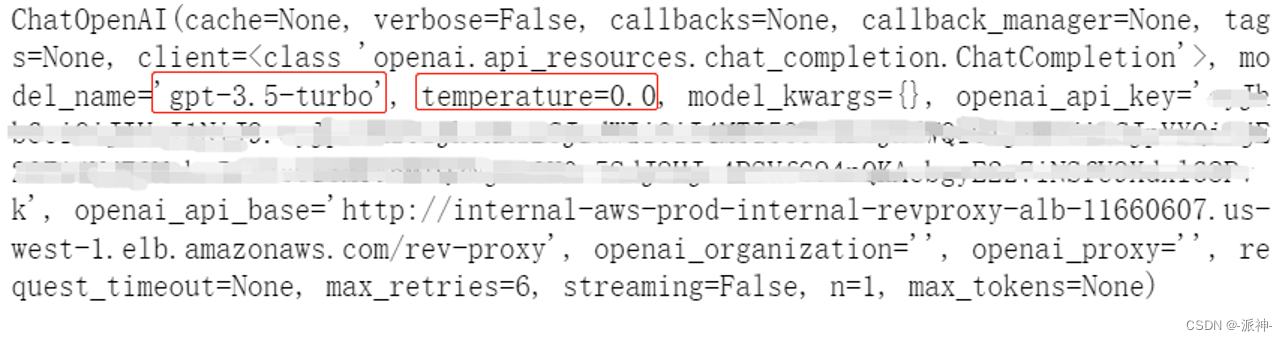
这里我们创建的openai的llm默认使用了“gpt-3.5-turbo”模型,同时我们还设置了temperature参数为0,这样做是为了降低llm给出答案的随机性。下面我们来创建一个检索问答链(RetrievalQA),然后我们将llm和检索器(retriever)作为参数传给RetrievalQA,这样RetrievalQA就可以根据之前的问题,给出最终的答案了。
from langchain.chains import RetrievalQAqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever()
)question = "What are major topics for this class?"
result = qa_chain({"query": question})
result["result"] 
这里我们看到,RetrievalQA给出了一个答案,该答案是在对向量数据库检索到的3给文档的基础上总结出来的。为了让RetrievalQA给出一个格式化的答案,我们还可以创建一个prompt,在这个prompt中我们将会告诉llm,它应该给出一个怎样的答案,以及答案的格式是怎么样的:
from langchain.prompts import PromptTemplate# Build prompt
template = """Use the following pieces of context to answer the question at the end. \
If you don't know the answer, just say that you don't know, don't try to make up an answer. \
Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" \
at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""QA_CHAIN_PROMPT = PromptTemplate.from_template(template)我们把这个prompt翻译成中文,这样便于大家理解:

在这个prompt中的{context}变量中会保存检索器搜索出来的相关文档的内容,而{question}变量保存的是用户的问题。
下面我们来测试一下加入了prompt的RetrievalQA的返回结果,不过首先我们还是需要重新定义一个RetrievalQA,并将prompt作为参数传给它,同时设置return_source_documents=True,这样RetrievalQA在回答问题的时候会同时返回与问题相关的文档块。
# Run chain
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)下面我们让RetrievalQA来回答一下问题:
question = "What are major topics for this class?"
result = qa_chain({"query": question})
result["result"]![]()
这里我们看到qa_chain根据模板的要求给出了一个简洁的答案,并在最后加上了 “thanks for asking!”。接下来我们查看一下qa_chain返回的相关文档:
result["source_documents"]
这里我们看到qa_chain返回的相关文档和我们之前用向量数据库的similarity_search方法搜索的相关文档基本是一致的,只不过在similarity_search方法中我们设置了k=3,所以similarity_search方法只返回3给相关文档,而RetrievalQA方法默认使用的是“stuff”方式,因此它会让向量数据库检索所有相关文档,所以最后检索到了4篇文档,其中第一第二篇,第三第四篇文档都是相同的,这是因为我们在创建向量数据库时将第一个文档(Lecture01.pdf)加载了两篇,导致向量数据库最后会搜索出内容重复的文档。接下来我们再让qa_chain回答一个问题:
question = "Is probability a class topic?"
result = qa_chain({"query": question})
result["result"]![]()
下面我们查看一下该问题的相关文档:
result["source_documents"]
同样,对于该问题,qa_chain也返回了4给相关文档,并且也是重复的,从元数据中可以看到它们来自于Lecture01.pdf 和Lecture03.pdf 这个原始的pdf文件。
RetrievalQA chain types
接下来我们来更改一下RetrievalQA的chain_type参数,将原来默认的“stuff”改成“map_reduce”:
qa_chain_mr = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),chain_type="map_reduce"
)question = "Is probability a class topic?"
result = qa_chain_mr({"query": question})
result["result"]
这里我们看到针对前面的同一个问题:"Is probability a class topic?",这次由于我们设置了chain_type=map_reduce, qa_chain_mr却没有给出肯定的答案。这个主要的原因是由于map_reduce的机制所导致的,map_reduce在执行过程中会让LLM对向量数据库中的每个文档块做一次总结,最后把所有文档块的总结汇总在一起再做一次最终的总结,因此它不像“stuff”那样,直接搜索所有文档块,只输出相关文档块,抛弃掉不相关的文档块,因此map_reduce在做最终总结的时候它的输入仍然包含了大量的不相关文档的总结内容,最终导致焦点被模糊了,无法给出正确的答案。下面我们再尝试一下refine,map_rerank这两种方式:
qa_chain_refine = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),chain_type="refine"
)question = "Is probability a class topic?"
result = qa_chain_refine({"query": question})
result["result"]
这里我们看到refine方式给出的答案也类似map_reduce的结果,它也没有给出肯定的答案,主要原因也是由于refine的工作机制也类似于map_reduce,llm会对每一个文档块进行总结,并且逐步汇总一个总结,这使得最终总结中也包含了大量不相关的总结内容,最终导致焦点被模糊了,没有给出正确的答案。
qa_chain_mr = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),chain_type="map_rerank"
)question = "Is probability a class topic?"
result = qa_chain_mr({"query": question})
result["result"]
我们看到map_rerank方式的给出来肯定的结果,这是因为在执行map_rerank时LLM会对每一个文档块进行打分,那么与问题相关的文档块自然会得到高分,而那些和问题不相关的文档块则会得到低分,那么在做最终总结时LLM只选取分数高的文档块,而那些分数低的文档块会被丢弃,所以它能得到肯定的答案。
总结
今天我们介绍了如何通过答链RetrievalQA,来检索向量数据库并回答用户的问题。其中我们介绍了几种RetrievalQA检索向量数据库的工作方式,也就是chain type方式,其实默认方式是stuff,除此之外还有map_reduce,refine, map_rerank等几种方式,它们都有各自的优缺点。同时我们还介绍了通过使用prompt模板,可以让LLM返回格式化的结果。希望今天的内容对大家学习langchain有所帮助!
参考资料
Stuff | 🦜️🔗 Langchain
Refine | 🦜️🔗 Langchain
Map reduce | 🦜️🔗 Langchain
Map re-rank | 🦜️🔗 Langchain
DLAI - Learning Platform Beta
相关文章:
使用langchain与你自己的数据对话(四):问答(question answering)
之前我已经完成了使用langchain与你自己的数据对话的前三篇博客,还没有阅读这三篇博客的朋友可以先阅读一下: 使用langchain与你自己的数据对话(一):文档加载与切割使用langchain与你自己的数据对话(二):向量存储与嵌入使用langc…...

如何快速开拓海外华人市场?附解决方案!
开拓华人市场对于企业来说是非常必要的。华人市场庞大且潜力巨大,拥有巨额的消费能力。随着华人经济的不断增长,越来越多的企业开始意识到华人市场的重要性。 通过开拓华人市场,企业可以获得更多的销售机会,并且在竞争激烈的市场…...
【云原生-制品管理】制品管理的优势
制品介绍制品管理-DevOps制品管理优势总结 制品介绍 制品管理指的是存储、版本控制和跟踪在软件开发过程中产生的二进制文件或“制品”的过程。这些制品可以包括编译后的源代码、库和文档,包括操作包、NPM 和 Maven 包(或像 Docker 这样的容器镜像&…...
)
Java爬虫----HttpClient方式(获取数据篇)
目录 一、爬虫的定义 二、获取数据 (1)基于Get方式的请求(无参) (2)基于Get方式请求(有参) (3)基于Post方式的请求(无参) &…...

计算机视觉实验:图像增强应用实践
本次实验主要从基于统计、函数映射的图像增强方法和基于滤波的图像增强方法两种方法中对一些图像增强的算法进行实现。主要的编程语言为python,调用了python自带的PIL图像库用于读取图像,利用numpy进行图像运算,最后使用opencv第三方库进行对…...

ES6:Generator函数详解
ES6:Generator函数详解 1、 概念2、yield表达式2.1 yield 语句与 return 语句区别2.2 Generator函数不加yield语句,这时变成了一个单纯的暂缓执行函数2.3 yield 表达式只能用在 Generator 函数里面,用在其它地方都会报错2.4 yield 表达式如果…...
前端小练-产品宣传页面
文章目录 前言页面结构固定钉头部轮播JS特效 完整代码总结 前言 经过一个月的爆肝,花费了一个月(期间还花费了将近半个月的时间打比赛,还要备研)算是把数二高数的内容强化了一遍,接下来刷熟练度即可,可惜的…...

arm学习之stm32设备树学习-中断控制led灯亮灭+字符设备指令控制led灯亮灭
中断控制led灯亮灭 驱动文件源码 led-key.c #include<linux/init.h> #include<linux/module.h> #include<linux/of.h> #include<linux/of_gpio.h> #include<linux/gpio.h> #include<linux/of_irq.h> #include<linux/interrupt.h> s…...
快速开发框架若依的基础使用详解
Hi I’m Shendi 快速开发框架若依的基础使用详解 最近在为公司制作新的项目,经过了一段时间的技术沉淀,我开始尝试接触市面上用的比较多的快速开发框架,听的最多的当属若依吧 于是就选用了若依 介绍 为什么选?目的是为了提高开发…...

RabbitMQ 教程 | 第4章 RabbitMQ 进阶
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是 DevO…...
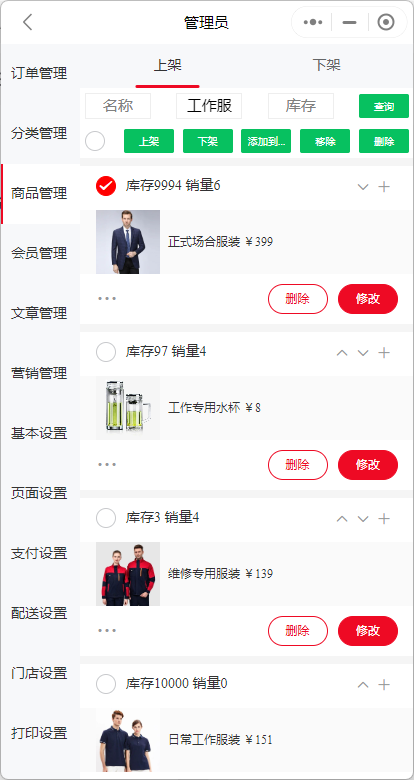
小程序如何从分类中移除商品
有时候商家可能需要在商品分类中删除某些商品,无论是因为商品已下架、库存不足还是其他原因。在这篇文章中,我们将介绍如何从分类中移除商品。 方式一:分类管理中删除商品。 进入小程序管理后台,找到分类管理,在分…...

P1219 [USACO1.5] 八皇后 Checker Challenge
题目 思路 非常经典的dfs题,需要一点点的剪枝 剪枝①:行、列,对角线的标记 剪枝②:记录每个皇后位置 代码 #include<bits/stdc.h> using namespace std; const int maxn105; int a[maxn];int n,ans; bool vis1[maxn],vis…...
如何在不使用脚本和插件的情况下手动删除 3Ds Max 中的病毒?
如何加快3D项目的渲染速度? 3D项目渲染慢、渲染卡顿、渲染崩溃,本地硬件配置不够,想要加速渲染,在不增加额外的硬件成本投入的情况下,最好的解决方式是使用渲云云渲染,在云端批量渲染,批量出结…...
SpringCloud Gateway 在微服务架构下的最佳实践
作者:徐靖峰(岛风) 前言 本文整理自云原生技术实践营广州站 Meetup 的分享,其中的经验来自于我们团队开发的阿里云 CSB 2.0 这款产品,其基于开源 SpringCloud Gateway 开发,在完全兼容开源用法的前提下&a…...
Android studio修改app图标
步骤如下: 1.右键app名称→New→ImageAsset 2. 进行下面的配置 图源:https://blog.csdn.net/Qingshan_z/article/details/126661650 3.配置分辨率 4.图标自动保存在mipmap文件夹下 再启动就更换成功了!!! 参考&…...

<C++> 三、内存管理
1.C/C内存分布 我们先来看下面的一段代码和相关问题 int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";const char *pChar3 "abcd";int *ptr1…...
大模型开发(十五):从0到1构建一个高度自动化的AI项目开发流程(上)
全文共5600余字,预计阅读时间约13~20分钟 | 满满干货(附全部代码),建议收藏! 本文目标:提出一种利用大语言模型(LLMs)加快项目的开发效率的解决思路,本文作为第一部分,主要集中在如何完整的执行引导Chat模…...

HarmonyOS 开发基础(二)组件拼凑简单登录页面
一、简单登录页面 Entry Component /* 组件可以基于struct实现,组件不能有继承关系,struct可以比class更加快速的创建和销毁。*/ struct Index {State message: string Hello Worldbuild() {// https://developer.harmonyos.com/cn/docs/documentation/…...
flutter minio
背景 前端 经常需要上传文件 图片 视频等等 到后端服务器, 如果到自己服务器 一般会有安全隐患。也不方便管理这些文件。如果要想使用一些骚操作 比如 按照前端请求生成不同分辨率的图片,那就有点不太方便了。 这里介绍以下 minio,࿰…...

ChatGPT:人工智能交互的新时代
ChatGPT的背景和发展: ChatGPT是OpenAI公司在GPT-3基础上的进一步升级。GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的深度学习模型,它能够处理自然语言,实现自动对话、写作等任务。而ChatGPT在…...

原神抽卡数据分析神器:告别盲目抽卡,用数据掌控你的欧皇之路
原神抽卡数据分析神器:告别盲目抽卡,用数据掌控你的欧皇之路 【免费下载链接】genshin-wish-export Easily export the Genshin Impact wish record. 项目地址: https://gitcode.com/GitHub_Trending/ge/genshin-wish-export 你是否曾在原神抽卡时…...

CUDA为什么能统治AI世界?NVIDIA真正可怕的并不是GPU
前言很多人第一次接触AI行业时,都会听到一个词:CUDA。而且你会发现一个非常奇怪的现象:很多AI框架、深度学习项目、GPU训练环境,几乎都默认要求:NVIDIA显卡CUDA环境甚至很多时候:没有CUDA,AI项目…...

【Elasticsearch从入门到精通】第10篇:Elasticsearch REST API最佳实践——Content-Type、模糊性与访问控制
上一篇【第09篇】Elasticsearch API规范详解——多索引、日期数学与通用选项 下一篇【第11篇】Elasticsearch索引API详解——索引创建、删除与别名管理(明日更新,敬请期待) 摘要 掌握Elasticsearch REST API的使用规范不仅能避免常见错误&am…...

昇腾CANN ops-blas:GEMM 在 NPU 上为什么可以快到极致
矩阵乘是所有深度学习计算的根。Attention、全连接、卷积展开——归根到底都是矩阵乘。ops-blas 是 CANN 里专门做高性能 GEMM(General Matrix Multiply)的算子库,核心目标是把昇腾 NPU 的 Cube 单元利用率拉到 90% 以上。 ops-blas 和 ops-n…...

对比直接购买,使用Taotoken的Token Plan套餐如何节省API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买,使用Taotoken的Token Plan套餐如何节省API成本 1. 成本管理中的常见挑战 对于需要持续调用大模型API的开…...

2026年TOP5运营多年口碑平稳的金价查询app有哪些
前几天跟闺蜜约饭,她一坐下来就疯狂吐槽:前一周特意蹲了网上说的金价合适的时段,攒了好久的钱想去买那条种草了半年的金项链,结果到了线下门店才知道,当天大盘价已经涨了21块钱,比她查的那个三天没更新的小…...
手机版通用)
鬼谷八荒2026官方正版最新版pc免费下载(看到请立即转存 资源随时失效)手机版通用
下载链接 逆天改命与八荒求道:解析《鬼谷八荒》的幕后历程、核心玩法与行业对比 在近年来的国产独立游戏浪潮中,修仙题材始终占据着举足轻重的地位。而在众多作品里,《鬼谷八荒》凭借其独特的画风与开放世界沙盒的定位,一度引发了…...
3个步骤快速掌握Py Eddy Tracker:海洋中尺度涡旋识别与追踪的完整解决方案
3个步骤快速掌握Py Eddy Tracker:海洋中尺度涡旋识别与追踪的完整解决方案 【免费下载链接】py-eddy-tracker Eddy identification and tracking 项目地址: https://gitcode.com/gh_mirrors/py/py-eddy-tracker Py Eddy Tracker是一个专门用于海洋中尺度涡旋…...

UE4SS终极指南:掌握虚幻引擎游戏修改的核心技术
UE4SS终极指南:掌握虚幻引擎游戏修改的核心技术 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE…...
)
告别传统菜单!用SARibbon库为你的Qt应用打造Office风格界面(附高分屏适配)
告别传统菜单!用SARibbon库为你的Qt应用打造Office风格界面(附高分屏适配) 当用户第一次打开你的Qt应用时,第一印象往往决定了他们是否会继续使用。传统的菜单栏界面在2023年看起来已经过时,而类似Office的Ribbon界面则…...