大模型开发(十五):从0到1构建一个高度自动化的AI项目开发流程(上)
全文共5600余字,预计阅读时间约13~20分钟 | 满满干货(附全部代码),建议收藏!
本文目标:提出一种利用大语言模型(LLMs)加快项目的开发效率的解决思路,本文作为第一部分,主要集中在如何完整的执行引导Chat模型创建外部函数代码、代码管理以及测试的全部流程。
代码下载地址
一、背景
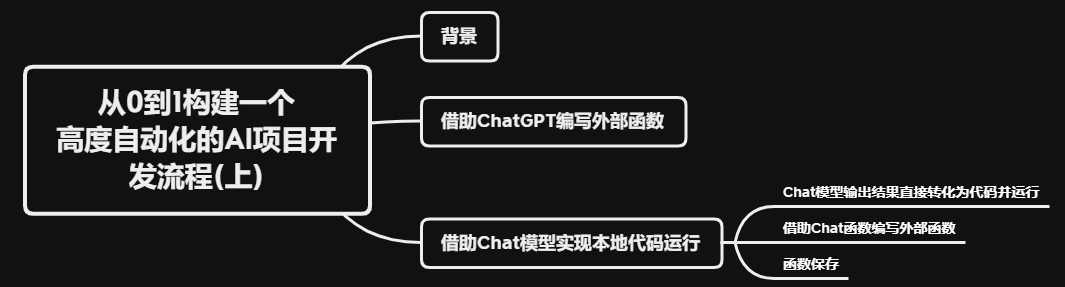
在这篇文章大模型开发(十四):使用OpenAI Chat模型 + Google API实现一个智能收发邮件的AI应用程序已经实现了围绕谷歌云Gmail API进行AI应用开发的流程,过程中虽然定义了两个比较关键的自动化函数,但对于AI开发流程来说,还需要更多的探索和要求需要借助AI介入,将大语言模型应用于软件开发流程以提高软件开发效率,本身也是大语言模型目前非常热门的应用方向。大语言模型强悍的人类意图理解能力和代码编写能力,会使开发工程师能够在大语言模型的加持下大幅提高开发效率。
对于AI应用开发来说,借助大语言模型来提高开发效率可以分以下两个阶段,本文的实现就是在做第二阶段的典型实现案例。
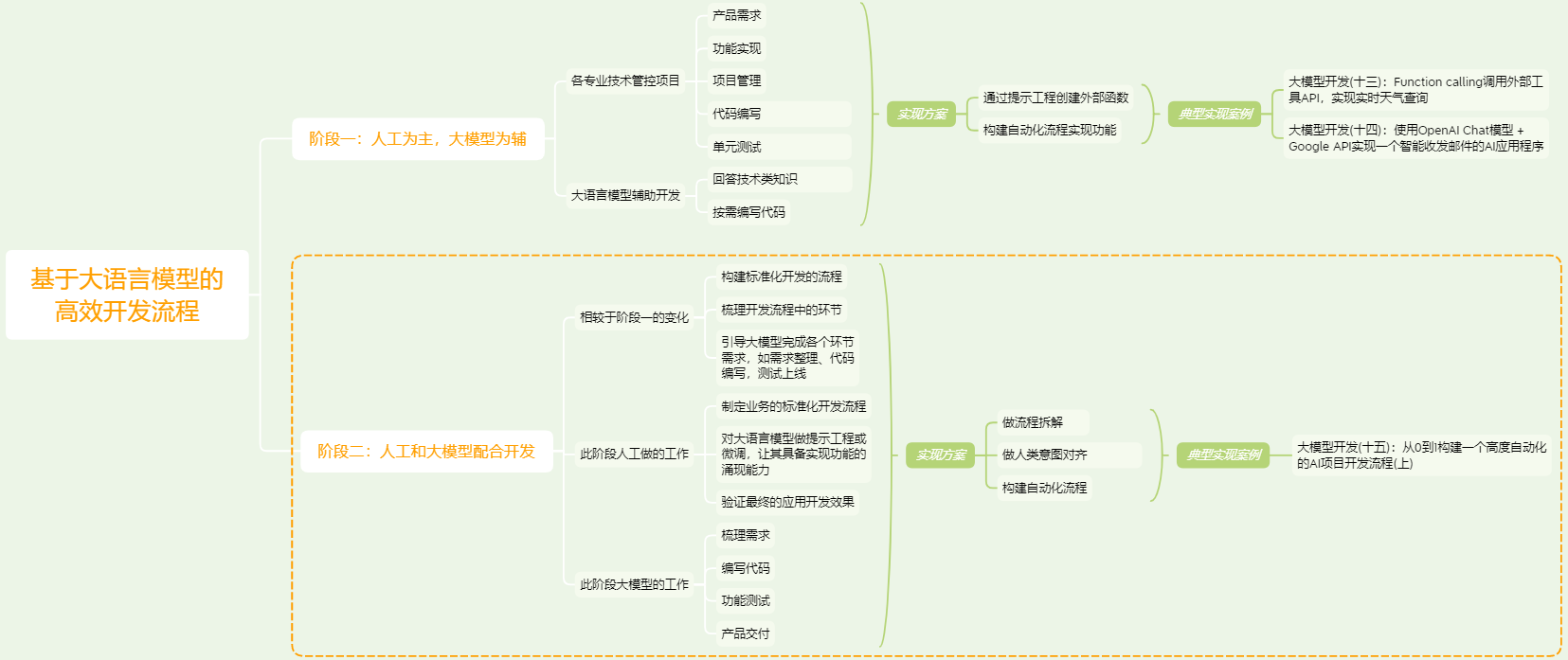
基于以上的第二阶段流程,本文就借助之前实现的邮件AI应用的开发项目,来看一下如何利用大语言模型加快项目的开发效率。
二、借助ChatGPT编写外部函数
借助Chat模型来帮提高AI应用开发效率,一个最基础的策略,就是尝试让Chat模型完成对应功能的外部函数的编写。一种比较简单的实现方式是整理需求后直接在ChatGPT中提问,令其生成外部函数的代码,然后复制到当前代码环境中进行测试和修改。
例如,围绕Gmail API的调用,编写一个函数能够查看最近接收到的5封邮件,则可以按照如下方式对ChatGPT进行提问:
Prompt:
我现在已经获取了Gmail API并完成了OAuth 2.0客户端和授权,并将查看邮件的凭据保存为token.json文件。现在想要编写一个函数来查阅最近的n封邮件,函数要求如下:
1.函数参数为n和userId,其中userId是字符串参数,默认情况下取值为’me’,表示查看我的邮件,而n则是整数,代表需要查询的邮件个数;
2.函数返回结果为一个包含多个字典的列表,并用json格式进行表示,其中一个字典代表一封邮件信息,每个字典中需要包含邮件的发件人、发件时间、邮件主题和邮件内容四个方面信息;
3.请将全部功能封装在一个函数内;
4.请在函数编写过程中,帮我编写详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;
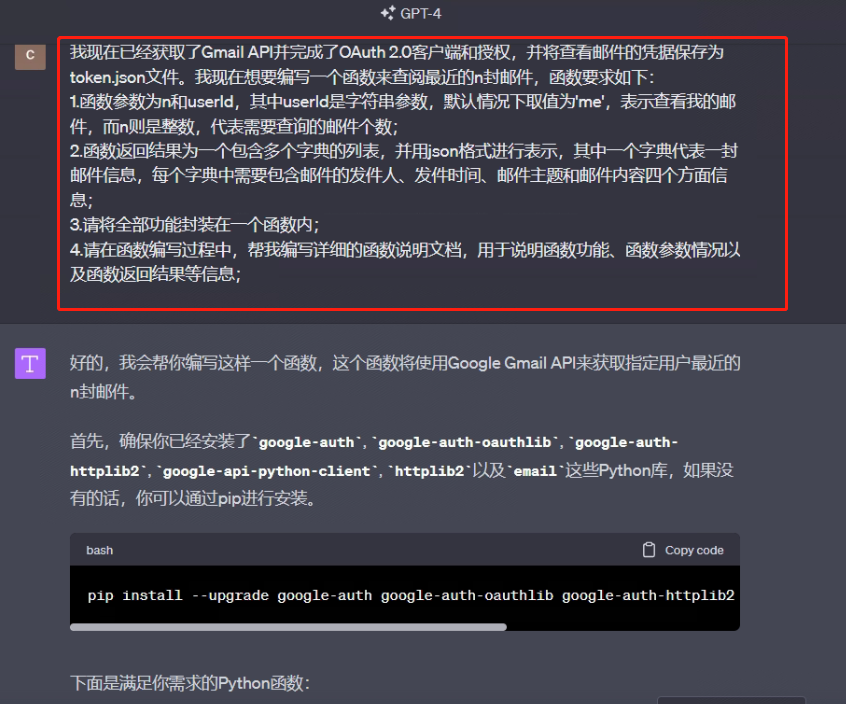
ChatGPT生成的函数如下,可以尝试运行一下,在测试之前先统一一下Gmail API的授权文件:
SCOPES = ['https://www.googleapis.com/auth/gmail.send','https://www.googleapis.com/auth/gmail.readonly']
flow = InstalledAppFlow.from_client_secrets_file('credentials-web.json', SCOPES)
creds = flow.run_local_server(port=8000, access_type='offline', prompt='consent')with open('token.json', 'w') as token:token.write(creds.to_json())
import base64
import re
import json
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import builddef get_recent_emails(n, userId='me'):"""获取最近的n封邮件功能:这个函数用于获取最近的n封邮件信息。返回的邮件信息包括邮件的发件人、发件时间、邮件主题和邮件内容。参数:n (int):需要获取的邮件数量。userId (str):用户ID。默认值为'me',代表当前授权用户。返回:返回一个包含多个字典的列表,以json格式表示。每个字典对应一封邮件信息,包括邮件的发件人、发件时间、邮件主题和邮件内容。"""# If modifying these SCOPES, delete the file token.json.SCOPES = ['https://www.googleapis.com/auth/gmail.readonly']creds = Noneif os.path.exists('token.json'):creds = Credentials.from_authorized_user_file('token.json')if not creds or not creds.valid:if creds and creds.expired and creds.refresh_token:creds.refresh(Request())else:flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)creds = flow.run_local_server(port=0)# Save the credentials for the next runwith open('token.json', 'w') as token:token.write(creds.to_json())service = build('gmail', 'v1', credentials=creds)# Get the recent n emailsresults = service.users().messages().list(userId=userId, maxResults=n).execute()messages = results.get('messages', [])email_list = []for message in messages:msg = service.users().messages().get(userId=userId, id=message['id']).execute()email_data = msg['payload']['headers']for values in email_data:name = values['name']if name == 'From':from_name = values['value']if name == 'Date':date = values['value']if name == 'Subject':subject = values['value']try:payload = msg['payload']body = payload['body']data = body['data']data = data.replace("-","+").replace("_","/")decoded_data = base64.b64decode(data)soup = BeautifulSoup(decoded_data , "lxml")body_text = soup.body()body_text = body_text[0].replace('\r\n', ' ').replace('\n', ' ')except:body_text = "Not available"email_dict = {'Date': date, 'From': from_name, 'Subject': subject, 'Body': body_text}email_list.append(email_dict)return json.dumps(email_list, indent=4, ensure_ascii=False)输出是这样的:
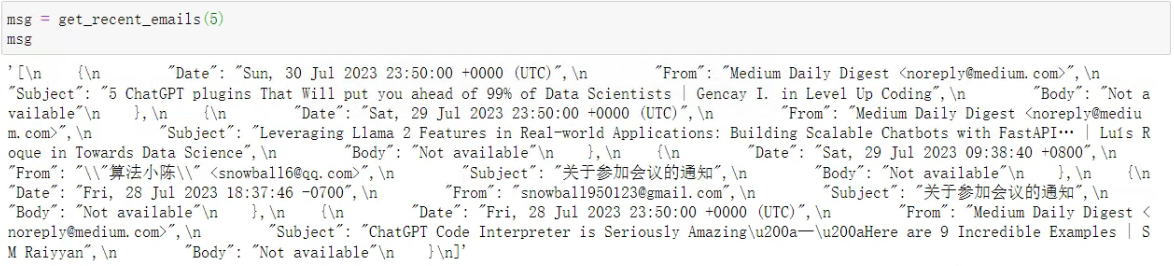
然后测试这样的函数结果能否被Chat模型解读:
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=[{"role": "system", "content": "这是我的Gmail邮箱最近五封邮件的内容:%s" % msg},{"role": "system", "content": "邮件内容是由Gmail API获取"},{"role": "user", "content": "请问我的Gmail最近五封邮件是谁发送的,都有什么内容?"}]
)
response.choices[0].message['content']
输出结果如下:

Chat模型能够顺利获取这5封邮件的信接继续测试,接下来测试这个由ChatGPT编写的get_emails函数,其参数说明能否被auto_functions函数正常识别,并创建functions参数,代码如下:
先导入auto_functions函数:
def auto_functions(functions_list):"""Chat模型的functions参数编写函数:param functions_list: 包含一个或者多个函数对象的列表;:return:满足Chat模型functions参数要求的functions对象"""def functions_generate(functions_list):# 创建空列表,用于保存每个函数的描述字典functions = []def chen_ming_algorithm(data):"""陈明算法函数,该函数定义了一种特殊的数据集计算过程:param data: 必要参数,表示带入计算的数据表,用字符串进行表示:return:陈明函数计算后的结果,返回结果为表示为JSON格式的Dataframe类型对象"""df_new = pd.read_json(data)res = np.sum(df_new, axis=1) - 1return res.to_json(orient='records')chen_ming_function_description = inspect.getdoc(chen_ming_algorithm)chen_ming_function_name = chen_ming_algorithm.__name__chen_ming_function = {"name": "chen_ming_algorithm","description": "用于执行陈明算法的函数,定义了一种特殊的数据集计算过程","parameters": {"type": "object","properties": {"data": {"type": "string","description": "执行陈明算法的数据集"},},"required": ["data"],},}# 对每个外部函数进行循环for function in functions_list:# 读取函数对象的函数说明function_description = inspect.getdoc(function)# 读取函数的函数名字符串function_name = function.__name__user_message1 = '以下是某函数说明:%s。' % chen_ming_function_description +\'根据这个函数的函数说明,请帮我创建一个function对象,用于描述这个函数的基本情况。这个function对象是一个JSON格式的字典,\这个字典有如下5点要求:\1.字典总共有三个键值对;\2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\5.输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % chen_ming_function_nameassistant_message1 = json.dumps(chen_ming_function)user_prompt = '现在有另一个函数,函数名为:%s;函数说明为:%s;\请帮我仿造类似的格式为当前函数创建一个function对象。' % (function_name, function_description)response = openai.ChatCompletion.create(model="gpt-4-0613",messages=[{"role": "user", "name":"example_user", "content": user_message1},{"role": "assistant", "name":"example_assistant", "content": assistant_message1},{"role": "user", "name":"example_user", "content": user_prompt}])functions.append(json.loads(response.choices[0].message['content']))return functionsmax_attempts = 3attempts = 0while attempts < max_attempts:try:functions = functions_generate(functions_list)break # 如果代码成功执行,跳出循环except Exception as e:attempts += 1 # 增加尝试次数print("发生错误:", e)if attempts == max_attempts:print("已达到最大尝试次数,程序终止。")raise # 重新引发最后一个异常else:print("正在重新运行...")return functions
functions_list = [get_emails]
functions = auto_functions(functions_list)
functions
看下结果:

接下来测试functions函数说明能否被Chat模型正确识别:
response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "user", "content": '请帮我查下最近3封邮件的邮件内容'}],functions=functions,function_call="auto", )
response
看下效果:
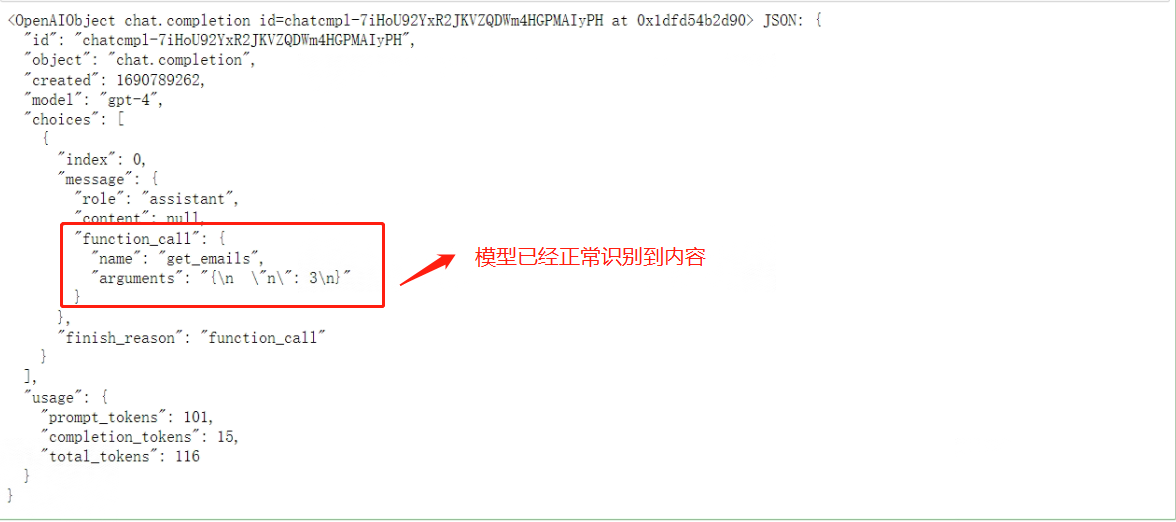
总的来说,在上述借助ChatGPT编写外部函数的流程中,总共做了三件事:
- 先获取API相关凭据,跑通了整个API授权流程
- 在非常了解Function calling功能以及设置的auto_functions基础上,对ChatGPT进行合理的提示
- 在获得了ChatGPT编写的函数之后,借助auto_functions进行外部函数功能验证
三、借助Chat模型实现本地代码运行
借助ChatGPT编写外部函数已经能够极大程度加快AI应用的开发效率,但每次都向ChatGPT提问然后复制粘贴代码到本地进行验证,这就不是很AI了。所以通过自然语言提示,直接在代码环境中创建外部函数代码,并自动进行测试和封装,这一过程是必须要做的。
要做到这点,首先需要跑通利用Chat模型创建函数并直接运行这一流程。
3.1 Chat模型输出结果直接转化为代码并运行
Chat模型的输入和输出都是字符串,因此若希望Chat模型输出结果直接转化为可以运行的外部函数,不仅需要合理的提示,还需要补充一些可以提取字符串中python代码并直接运行的方法,一个比较简单的测试过程是:
- Step 1:查看当前使用的gpt-4-0613模型是否能在合理的提示下,创建符合外部函数要求的函数
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=[{"role": "system", "content": "你是一个python代码编辑器,你的功能是输出python代码,请勿输出任何和python代码无关的内容"},{"role": "user", "content": "请帮我定义一个python函数,输出Hello world字符串,请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档。"}]
)
看下输出:

- Step 2:Chat模型输出的字符串是一个markdown格式对象,将其保存为md格式
看看格式化的代码是什么样的,代码如下:
with open('helloworld.md', 'a', encoding='utf-8') as f:f.write(response.choices[0].message['content'])
看下helloworld.md中的内容:

- Step 3:封装函数
Chat模型创建的函数本身并没有任何问题,但如果想实现直接在本地调用,经过多次尝试,一种比较高效的解决问题的方法是直接在上述字符串中通过正则表达式提取出只包含Python代码的字符串,代码如下:
def extract_code(s):"""如果输入的字符串s是一个包含Python代码的Markdown格式字符串,提取出代码部分。否则,返回原字符串。参数:s: 输入的字符串。返回:提取出的代码部分,或原字符串。"""# 判断字符串是否是Markdown格式if '```python' in s or 'Python' in s or'PYTHON' in s:# 找到代码块的开始和结束位置code_start = s.find('def')code_end = s.find('```\n', code_start)# 提取代码部分code = s[code_start:code_end]else:# 如果字符串不是Markdown格式,返回原字符串code = sreturn code
测试一下执行结果:
code_s = extract_code(response.choices[0].message['content'])
code_s

其实到这里就能看出来,已经可以完整的提取出s中包含的代码部分,并将其保存为一个字符串。而对于一个用字符串表示的python程序,可以通过如下方式将其写入本地py文件并进行代码查看:
with open('helloworld.py', 'w', encoding='utf-8') as f:f.write(code_s)
此时就会在本地创建一个保存了print_hello_world函数的py文件:

所以综上,一个完整的自动流程应该具备以下能力:
-
定义一个完整的extract_function_code函数。该函数可以在字符串中提取python代码,并提取该段代码的函数名称,同时对该函数进行py文件的本地保存
-
在保存时,分tested和untested两个文件,tested文件夹用于保存手动验证过的函数,untested则用于保存尚未进行验证的函数,并将每个函数命名为function_name_module.py。
-
运行该函数时会在当前环境下执行该代码(定义该函数),并且同时可以选择打印函数的全部信息或者只是打印函数的名称
基于以上功能需求,一个示例函数如下:
def extract_function_code(s, detail=0, tested=False):"""函数提取函数,同时执行函数内容,可以选择打印函数信息,并选择代码保存的地址"""def extract_code(s):"""如果输入的字符串s是一个包含Python代码的Markdown格式字符串,提取出代码部分。否则,返回原字符串。参数:s: 输入的字符串。返回:提取出的代码部分,或原字符串。"""# 判断字符串是否是Markdown格式if '```python' in s or 'Python' in s or'PYTHON' in s:# 找到代码块的开始和结束位置code_start = s.find('def')code_end = s.find('```\n', code_start)# 提取代码部分code = s[code_start:code_end]else:# 如果字符串不是Markdown格式,返回原字符串code = sreturn code# 提取代码字符串code = extract_code(s)# 提取函数名称match = re.search(r'def (\w+)', code)function_name = match.group(1)# 将函数写入本地if tested == False:with open('./functions/untested functions/%s_module.py' % function_name, 'w', encoding='utf-8') as f:f.write(code)else:with open('./functions/tested functions/%s_module.py' % function_name, 'w', encoding='utf-8') as f:f.write(code)# 执行该函数try:exec(code, globals())except Exception as e:print("An error occurred while executing the code:")print(e)# 打印函数名称if detail == 0:print("The function name is:%s" % function_name)if detail == 1:with open('%s.py' % function_name, encoding='utf-8') as f:content = f.read()print(content)
有了该函数,即可更加便捷的将Chat模型输出结果一键进行函数提取、保存和运行。
3.2 借助Chat函数编写外部函数
在这个流程基础之上,可以尝试引导让Chat函数直接编写符合要求的外部函数,此处就以统计邮箱全部邮件个数的函数为例。
此前定义的get_latest_email函数如下:
def get_latest_email(userId):"""查询Gmail邮箱中最后一封邮件信息:param userId: 必要参数,字符串类型,用于表示需要查询的邮箱ID,\注意,当查询我的邮箱时,userId需要输入'me';:return:包含最后一封邮件全部信息的对象,该对象由Gmail API创建得到,且保存为JSON格式"""# 从本地文件中加载凭据creds = Credentials.from_authorized_user_file('token.json')# 创建 Gmail API 客户端service = build('gmail', 'v1', credentials=creds)# 列出用户的一封最新邮件results = service.users().messages().list(userId=userId, maxResults=1).execute()messages = results.get('messages', [])# 遍历邮件for message in messages:# 获取邮件的详细信息msg = service.users().messages().get(userId='me', id=message['id']).execute()return json.dumps(msg)
- Step 1:通过inspect.getsource方式直接提取上述函数的代码并采用字符串格式进行输出,代码如下:
code = inspect.getsource(get_latest_email)
看下输出:

- Step 2:采用Few-shot的方式对其进行提示
先读取函数的描述信息,代码如下:
# 写入本地
with open('./functions/tested functions/%s_module.py' % 'get_latest_email', 'w', encoding='utf-8') as f:f.write(code)# 从本地读取
with open('./functions/tested functions/%s_module.py' % 'get_latest_email', encoding='utf-8') as f:content = f.read()
读取数据如下:

所以最终的Prompt如下:
assistant_example_content = contentsystem_content = "我现在已完成Gmail API授权,授权文件为本地文件token.json。"user_example_content = "请帮我编写一个python函数,用于查看我的Gmail邮箱中最后一封邮件信息,函数要求如下:\1.函数参数userId,userId是字符串参数,默认情况下取值为'me',表示查看我的邮件;\2.函数返回结果是一个包含最后一封邮件信息的对象,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"user_content = "请帮我编写一个python函数,用于查看我的Gmail邮箱中总共有多少封邮件,函数要求如下:\1.函数参数userId,userId是字符串参数,默认情况下取值为'me',表示查看我的邮件;\2.函数返回结果是当前邮件总数,返回结果本身必须是一个json格式对象;\3.请将全部功能封装在一个函数内;\4.请在函数编写过程中,在函数内部加入中文编写的详细的函数说明文档,用于说明函数功能、函数参数情况以及函数返回结果等信息;"messages=[{"role": "system", "content": system_content},{"role": "user", "name":"example_user", "content": user_example_content},{"role": "assistant", "name":"example_assistant", "content": assistant_example_content},{"role": "user", "name":"example_user", "content": user_content}]
Chat模型的提示方法和ChatGPT的提示方法有很大的区别,当传递相同的意思时,二者有效的提示方法可能也会有很大的区别,因此具体如何提示需要反复多次进行测试。上述只是提供一种思路,还是有很大的提升空间
- Step 3:调用模型
response = openai.ChatCompletion.create(model="gpt-4-0613",messages=messages
)
看一下输出结果:
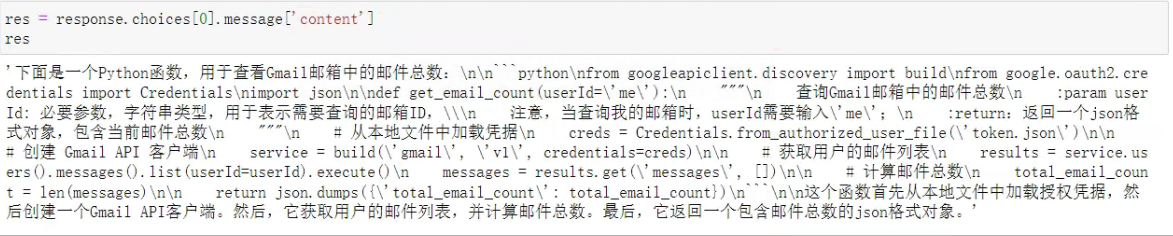
- Step 4:提取代码后写入本地
extract_function_code(res, detail=0)
看下本地代码:

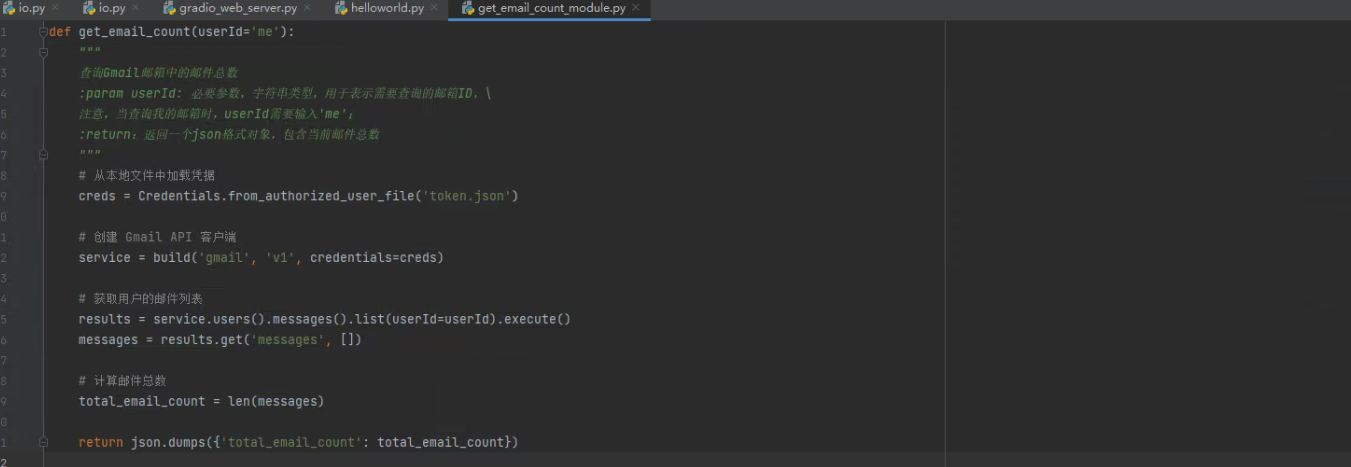
- Step 5:运行函数验证

该函数能够正确统计当前邮箱的邮件个数。
- Step 6:测试该函数能否能被顺利的转化为functions参数
functions_list = [get_email_count]functions = auto_functions(functions_list)
functions
看下输出结果:

- Step 7:测试functions函数说明能否被Chat模型正确识别
response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "user", "content": '请帮我查下Gmail邮箱里现在总共有多少封邮件'}],functions=functions,function_call="auto", )
response
看下输出结果:
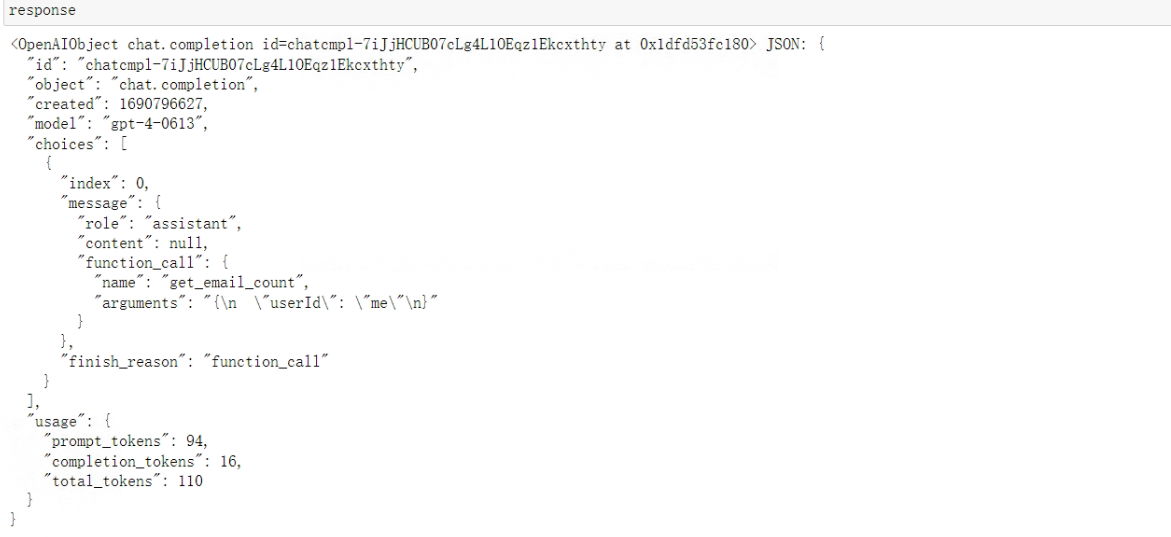
至此,就完成了统计邮件总数的函数编写。这一套流程相较于之前来说,外部函数编写的效率在extract_function_code函数加持下已经非常高了,只需要少量的人工来编写prompt、并围绕新函数进行测试,即可完成外部函数的编写。
3.3 函数保存
对于按照上述开发流程,当**函数功能经过了测试,就可以将其转移至tested文件夹内,表示该函数能够顺利的被大语言模型识别并作为外部函数进行调用。**代码如下:
import shutil
import os
import globdef functions_move(module_name):"""将通过测试的函数转移到tested functions文件夹内"""current_directory = os.getcwd()src_dir = current_directory + "\\functions\\untested functions"dst_dir = current_directory + "\\functions\\tested functions"src_file = os.path.join(src_dir, module_name)dst_file = os.path.join(dst_dir, module_name)shutil.move(src_file, dst_file)
四、总结
本文作为AI开发流程高效优化的第一步,完整的执行引导Chat模型创建外部函数代码、代码管理以及测试的全部流程。
但其实,AI应用的开发流程还可以更高效,比如面对大量潜在的未知用户需求(比如现在我想查看下邮箱里是否有某人发来的未读邮件),一个比较好的思路是借助大语言模型(LLMs),即时将用户的需求翻译成外部函数创建的prompt,然后即时创建外部函数加入到Chat模型中来实时更新Chat模型能力,并最终提供更加完善的解决方案。这是一种更高级的自动化形式,使得大模型不仅可以编写功能实现的代码,而且需求到功能的过程也可以由大模型自己来进行总结。若能做到这一点,这个产品的功能就相当于是可以实现自生长(根据用户的需求实时成长),毫无疑问,这样的一个开发过程,才更加贴近想象中的智能化开发过程。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!
下一篇继续进行流程优化!
相关文章:
大模型开发(十五):从0到1构建一个高度自动化的AI项目开发流程(上)
全文共5600余字,预计阅读时间约13~20分钟 | 满满干货(附全部代码),建议收藏! 本文目标:提出一种利用大语言模型(LLMs)加快项目的开发效率的解决思路,本文作为第一部分,主要集中在如何完整的执行引导Chat模…...

HarmonyOS 开发基础(二)组件拼凑简单登录页面
一、简单登录页面 Entry Component /* 组件可以基于struct实现,组件不能有继承关系,struct可以比class更加快速的创建和销毁。*/ struct Index {State message: string Hello Worldbuild() {// https://developer.harmonyos.com/cn/docs/documentation/…...
flutter minio
背景 前端 经常需要上传文件 图片 视频等等 到后端服务器, 如果到自己服务器 一般会有安全隐患。也不方便管理这些文件。如果要想使用一些骚操作 比如 按照前端请求生成不同分辨率的图片,那就有点不太方便了。 这里介绍以下 minio,࿰…...

ChatGPT:人工智能交互的新时代
ChatGPT的背景和发展: ChatGPT是OpenAI公司在GPT-3基础上的进一步升级。GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的深度学习模型,它能够处理自然语言,实现自动对话、写作等任务。而ChatGPT在…...

C. Binary String Copying - 思维
分析: 赛时我是直接模拟的,tle然后mle,补提,发现规律,每一个改变的字符串都只会对应一个需要改变的区间,例如第一个样例前两个101100 -> 011100和101100 -> 011100,对应区间在确定改变的范…...

哈工大计算机网络课程网络安全基本原理详解之:密钥分发中心与公钥认证中心
哈工大计算机网络课程网络安全基本原理详解之:密钥分发中心与公钥认证中心 在介绍密钥分发中心的概念前,先来回顾一下之前介绍的身份认证协议AP4.0:利用随机数R来避免“回放攻击”,并借助于对称加密算法来保证R的加密传输和解密&…...

md5sum
概念作用及原理 md5sum是一种常用的哈希算法,用于计算数据的MD5哈希值。MD5(Message Digest Algorithm 5)是一种广泛使用的加密散列函数,用于将任意长度的数据映射为固定长度的哈希值(通常是128位)。这个哈…...

图文档数字化:实现高效管理的几大步骤
在当今数字化时代,企业越来越意识到数字化管理对于图文档的重要性。传统的纸质文件管理往往效率低下,容易出现丢失和混乱的情况。为了提高工作效率、降低成本并确保数据安全,许多企业选择采用PDM(产品数据管理)系统来实…...

服务器磁盘占用过高分析
使用命令 du -sh查看出占用较大的目录,如下: 目录大小处理办法/usr/local/mysql/data16G转移部分文件/usr/local/nacos2.1G维持现状/logs4.4G删除部分文件/var1.9G删除部分文件 du -sh命令使用示例: du -sh /* 查看根目录各文件(夹)占用大小…...
【C语言】通讯录3.0 (文件存储版)
前言 通讯录是一种记录联系人信息的工具,包括姓名、电话号码、电子邮件地址、住址等。 文章的一二三章均于上一篇相同,可以直接看第四章改造内容。 此通讯录是基于通讯录2.0(动态增长版)的基础上进行增加文件操作功能,…...

【C#常用操作】
excel相关操作 using Excel Microsoft.Office.Interop.Excel;public Excel.Application app; public Excel.Workbooks wbs; public Excel.Workbook wb; public Excel.Worksheets wss; public Excel.Worksheet ws;/// <summary> /// 取得打开excel句柄 /// </summary…...
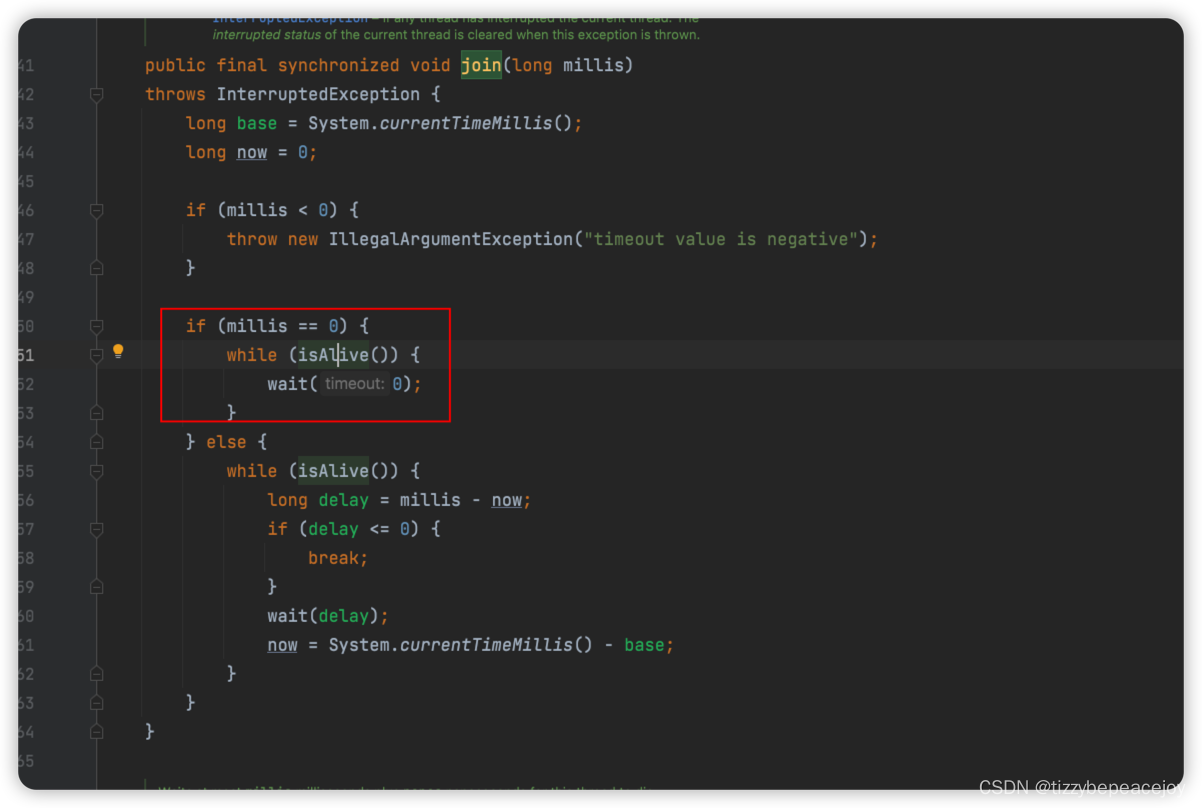
深入理解CountDownLatch计数器
入理解CountDownLatch计数器 其他知识点 Java 多线程基础 深入理解aqs ReentrantLock用法详解 深入理解信号量Semaphore 深入理解并发三大特性 并发编程之深入理解CAS 深入理解CountDownLatch Java 线程池 使用用法 CountDownLatch用法详解 CountDownLatch实现原理 下面例子来…...

从SQL注入绕过最新安全狗WAF中学习fuzz
前言 SQL注入并不是很精通,通过实战绕过WAF来进行加强SQL注入能力,希望对正在学习的师傅能有一丝帮助。 安装 安装前言 我是本地搭建的环境进行测试的 环境是windows11phpstudy2018sqli-labs phpstudy的安装我不再复述,这里简单说一下安全…...

C语言每日一题:12《数据结构》相交链表。
题目: 题目链接 思路一: 1.如果最后一个节点相同说明一定有交点。 2.使用两个循环获取一下长度,同时可以获取到尾节点。 3。注意初始化lenA和lenB为1,判断下一个节点是空是可以保留尾节点的。长度会少一个,尾节点没有…...

【Spring框架】SpringMVC
目录 什么是Spring MVC实现客户端和程序之间的“连接”1.1 RequestMapping1.2GetMapping1.3PostMapping 获取参数2.1.1 获取单个参数2.1.2 获取多个参数2.1.3 获取对象2.2 后端参数重命名2.3 RequestBody 接收JSON对象2.4 获取URL中参数PathVariable2.5 上传⽂件RequestPart2.6…...

HDFS中namenode安全模式
HDFS中namenode安全模式 安全模式的现象探究step1step2step3step4 安全模式的概述控制进入时间和离开条件安全模式自动进入离开安全模式手动进入离开 安全模式的现象探究 step1 HDFS集群在停机状态下,使用hdfs -daemon命令逐个进程启动集群,观察现象首…...
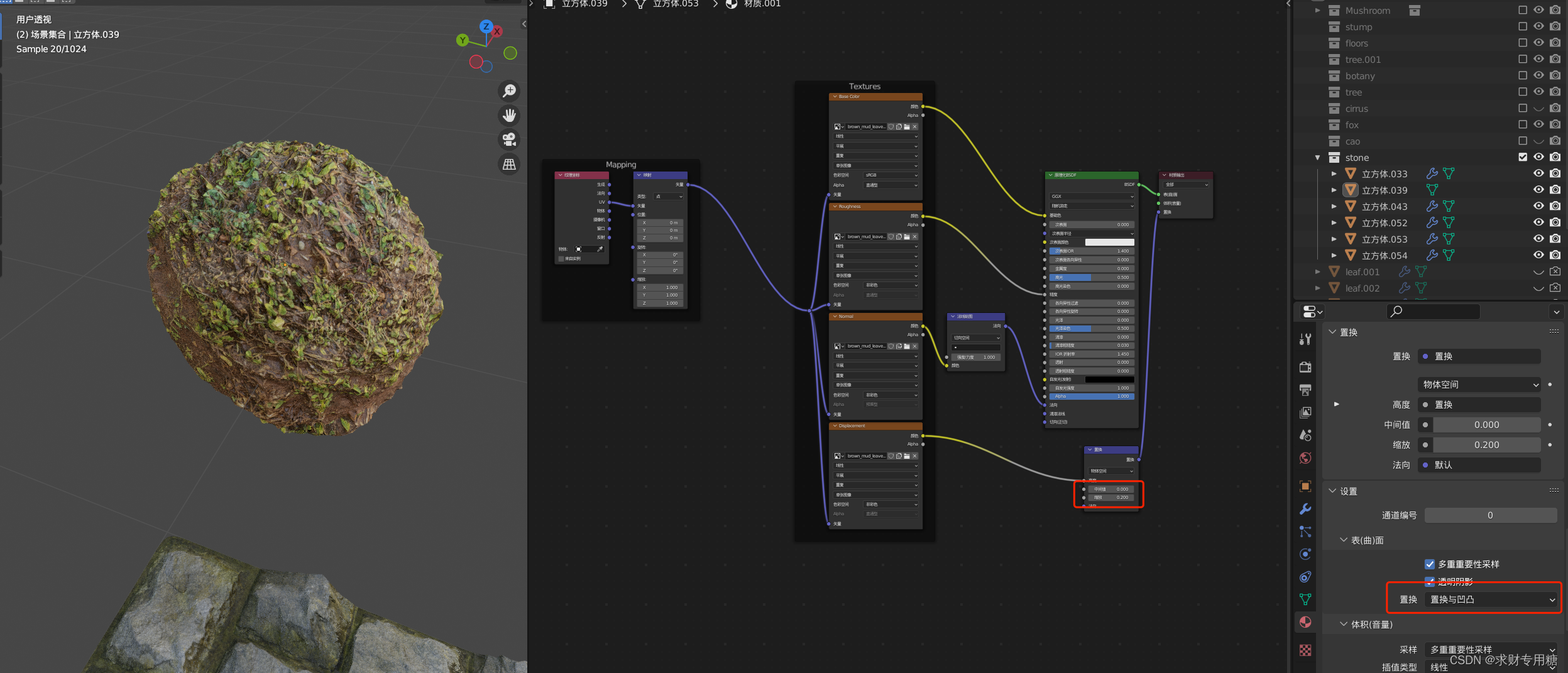
blender凹凸感和置换形变
一、怎么做出凹凸感 需要三个部分的内容: 1、一个基础的纹理:告诉计算机需要用一个什么样的纹理做凹凸,纹理一般采用黑白,在计算机里面,从 0 - 1之间的值可以用从黑到白之间不同的灰度来表示因此,有一张黑白…...
力扣 343. 整数拆分
题目来源:https://leetcode.cn/problems/integer-break/description/ C题解1:动态规划。dp[i] 代表数字i拆分后得到的最大乘积。递归公式为拆分后两个数的最大乘积相乘,即 dp[i] max(dp[i], dp[j] * dp[i-j])。对于n2或3需要另外讨论。 cla…...
【JavaWeb】正则表达式
🎄欢迎来到边境矢梦的csdn博文,本文主要讲解Java 中正则表达式 的相关知识🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以关注一下🫰🫰&am…...

Vue中常用到的标签和指令
一、标签 在 Vue 中,并没有特定的标签是属于 Vue 的,因为 Vue 是一个用于构建用户界面的框架,可以与 HTML 标签一起使用。Vue 中可以使用的标签和元素基本上与 HTML 标准一致。 以下是一些常见的HTML标签,也可以在 Vue 中使用&a…...
)
【性能评估】信标辅助双跳认知无线电无线中继选择方案的性能评估研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

如何免费激活Windows和Office:3步实现永久激活的终极指南
如何免费激活Windows和Office:3步实现永久激活的终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows激活弹窗烦恼吗?是否遇到过Office突然变成只读模式…...

传统开发VS低代码开发,谁更胜一筹?
低代码开发,让企业应用搭建像搭积木一样简单 在当今数字化时代,企业对于应用程序的需求日益增长。然而,传统的软件开发方式往往面临着开发周期长、成本高、技术门槛高等问题,这使得许多企业在数字化转型的道路上举步维艰。而低代…...

曼德勃罗集的 Three.js 实现
效果预览 经典的曼德勃罗集(Mandelbrot Set)分形渲染,配合动态缩放动画探索分形边界的无限细节。使用线性插值平滑着色,呈现出彩虹般的色彩过渡。 👉 点击查看《曼德勃罗集的》完整源码与效果演示 Shader 实现原理…...

DeepStream9.0 service-maker
service-maker在前几个版本就推出了,DeepStream9.0做了增强: Added Pyservice maker support for Smart-Recording(就是实时录制码流) 如果你用过 NVIDIA DeepStream,应该很熟悉它的典型开发方式:围绕 G…...

免费网盘直链解析工具:九个主流网盘的高速下载完整解决方案
免费网盘直链解析工具:九个主流网盘的高速下载完整解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 /…...

Mythos模型的技术本质:执行态建模与终端状态感知
1. 这不是一次普通模型发布:Mythos背后的真实技术分水岭 “Claude Mythos Preview”这七个字,最近在安全圈和AI工程一线引发的震动,远超多数人最初预估。它不是又一个参数堆叠的“更大模型”,也不是一次常规的SOTA刷新——它是一次…...

AwesomeSites自动化工具解析:autoreadme脚本的工作原理与使用
AwesomeSites自动化工具解析:autoreadme脚本的工作原理与使用 【免费下载链接】AwesomeSites every websites have been tested and fixed, all can be running in localhost. After clone the repository enter the websites folder, simply start a local HTTP se…...

Spingboot企业员工信息管理系统—免费毕设源码分享28210
摘要本论文介绍了基于Spring Boot框架开发的“传奇今生企业员工信息管理系统”。系统提高企业人力资源管理的效率和精确度,通过数字化手段优化员工信息管理流程,提升企业管理水平。系统分为用户端和管理员端,提供了丰富的功能模块。用户端功能…...

TCP三次握手与四次挥手——连接管理的“仪式感“
**导读:**如果说HTTP是互联网世界的"通用语言",那么TCP就是支撑这一切的"地下管道"。但这条管道不是想通就通的——它有一套严格的"礼仪规范",也就是我们常说的三次握手和四次挥手。今天,我们就来聊…...