【LLM系列之指令微调】长话短说大模型指令微调的“Prompt”
1 指令微调数据集形式“花样”太多
大家有没有分析过 prompt对模型训练或者推理的影响?之前推理的时候,发现不加训练的时候prompt,直接输入模型性能会变差的,这个倒是可以理解。假如不加prompt直接训练,是不是测试的时候不加prompt也可以?还有一个就是多轮prompt和单轮prompt怎么构造的问题?好多模型训练方式不统一 包括指令数据形式有所不同,选择困难症又来了。。

先说一些观点,假如我们在微调一个大模型,单次实验微调所用的指令微调数据集应该选取“质量高、多样性”,在训练资源充足的情况可以加入数量更多,长度更大的数据集。可以基于多个质量比较高的数据,做一份格式统一的多样性数据用来做sft,一次性微调完比较好,多次微调效果可能会折扣。或者有继续微调比较合适的方案也可以,不损失之前模型的效果(或者损失比较小),目前可以尝试Lora或者Qlora的方式微调底座模型,然后将训练好的Lora权重合并到原始模型,这样可以减轻多次微调对模型的影响。
2 常见指令微调模板
通过观测一些排行榜靠前和主流指令微调数据集,笔者总结一些常见的指令微调的Prompt:
常见的是stanford_alpaca中模板
PROMPT_DICT = {"prompt_input": ("Below is an instruction that describes a task, paired with an input that provides further context. ""Write a response that appropriately completes the request.\n\n""### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:"),"prompt_no_input": ("Below is an instruction that describes a task. ""Write a response that appropriately completes the request.\n\n""### Instruction:\n{instruction}\n\n### Response:"),
}
Llama2中的模板
instruction = """[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n{} [/INST]"""Linly-AI中模板
### Instruction:{prompt.strip()} ### Response:
OpenLLM 排行榜top1的NousResearch
和alpaca模板差不多
### Instruction:
<prompt>### Response:
<leave a newline blank for model to respond>
### Instruction:
<prompt>### Input:
<additional context>### Response:
<leave a newline blank for model to respond>Yayi模板
https://huggingface.co/wenge-research/yayi-7b-llama2
prompt = "你是谁?"
formatted_prompt = f"""<|System|>:
You are a helpful, respectful and honest assistant named YaYi developed by Beijing Wenge Technology Co.,Ltd. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.<|Human|>:
{prompt}<|YaYi|>:
"""
StableBeluga2的模板
### System:
This is a system prompt, please behave and help the user.### User:
Your prompt here### Assistant:
The output of Stable Beluga 2
比如
system_prompt = "### System:\nYou are Stable Beluga, an AI that follows instructions extremely well. Help as much as you can. Remember, be safe, and don't do anything illegal.\n\n"message = "Write me a poem please"
prompt = f"{system_prompt}### User: {message}\n\n### Assistant:\n"
Guanaco数据集常用模板
### Human: {prompt}
### Assistant:
prompt = "Introduce yourself"
formatted_prompt = (f"A chat between a curious human and an artificial intelligence assistant."f"The assistant gives helpful, detailed, and polite answers to the user's questions.\n"f"### Human: {prompt} ### Assistant:"
)
3 多轮对话输入和输出构造
参考yangjianxin1/Firefly项目和LinkSoul-AI/Chinese-Llama-2-7b项目,一般采用的方式是:
在计算loss时,我们通过mask的方式,input部分的loss不参与参数更新,只有“target”部分的loss参与参数更新。 这种方式充分利用了模型并行计算的优势,训练更加高效,且多轮对话中的每个target部分都参与了训练,训练更充分。 否则,就需要把一个n轮对话,拆分成n条数据,且只计算最后一个target的loss,大大降低了训练效率。
具体实现方式1:
# https://github.com/LinkSoul-AI/Chinese-Llama-2-7b/blob/main/train.py
def tokenize(item, tokenizer):roles = {"human": "user", "gpt": "assistant"}input_ids = []labels = []if "instruction" in item and len(item["instruction"]) > 0:system = item["instruction"]else:system = dummy_message["system"]system = B_SYS + system + E_SYS# add system before the first content in conversationsitem["conversations"][0]['value'] = system + item["conversations"][0]['value']for i, turn in enumerate(item["conversations"]):role = turn['from']content = turn['value']content = content.strip()if role == 'human':content = f"{B_INST} {content} {E_INST} "content_ids = tokenizer.encode(content)labels += [IGNORE_TOKEN_ID] * (len(content_ids))else:# assert role == "gpt"content = f"{content} "content_ids = tokenizer.encode(content, add_special_tokens=False) + [tokenizer.eos_token_id] # add_special_tokens=False remove bos token, and add eos at the endlabels += content_idsinput_ids += content_idsinput_ids = input_ids[:tokenizer.model_max_length]labels = labels[:tokenizer.model_max_length]trunc_id = last_index(labels, IGNORE_TOKEN_ID) + 1input_ids = input_ids[:trunc_id]labels = labels[:trunc_id]if len(labels) == 0:return tokenize(dummy_message, tokenizer)input_ids = safe_ids(input_ids, tokenizer.vocab_size, tokenizer.pad_token_id)labels = safe_ids(labels, tokenizer.vocab_size, IGNORE_TOKEN_ID)return input_ids, labels
具体实现方式1:
# https://github.com/yangjianxin1/Firefly/blob/master/component/dataset.py
class SFTDataset(Dataset):def __init__(self, file, tokenizer, max_seq_length):self.tokenizer = tokenizerself.bos_token_id = tokenizer.bos_token_idself.eos_token_id = tokenizer.eos_token_idself.eos_token = tokenizer.eos_tokenself.bos_token = tokenizer.bos_tokenself.max_seq_length = max_seq_lengthlogger.info('Loading data: {}'.format(file))with open(file, 'r', encoding='utf8') as f:data_list = f.readlines()logger.info("there are {} data in dataset".format(len(data_list)))self.data_list = data_listdef __len__(self):return len(self.data_list)def __getitem__(self, index):# 每条数据格式为: <s>input1</s>target1</s>input2</s>target2</s>...data = self.data_list[index]data = json.loads(data)conversation = data['conversation']# 收集多轮对话utterances = []for x in conversation:utterances.append(x['human'])utterances.append(x['assistant'])utterances_ids = self.tokenizer(utterances, add_special_tokens=False).input_ids# 模型的输入格式为:<s>input1</s>target1</s>input2</s>target2</s>...input_ids = [self.bos_token_id]target_mask = [0] # 用于对input进行mask,只计算target部分的lossfor i, utterances_id in enumerate(utterances_ids):input_ids += (utterances_id + [self.eos_token_id])if i % 2 == 0:target_mask += [0] * (len(utterances_id) + 1)else:target_mask += [1] * (len(utterances_id) + 1)assert len(input_ids) == len(target_mask)# 对长度进行截断input_ids = input_ids[:self.max_seq_length]target_mask = target_mask[:self.max_seq_length]attention_mask = [1] * len(input_ids)assert len(input_ids) == len(target_mask) == len(attention_mask)inputs = {'input_ids': input_ids,'attention_mask': attention_mask,'target_mask': target_mask}return inputs
核心代码就是通过IGNORE_INDEX(-100)遮蔽掉input对应的目标输出即可。
4 如何高效率微调大模型
如何短时间、高效率的训练出实际效果不错、综合能力比较强的大模型呢?从指令微调数据集处理工作上,个人认为可以从以下方式进行:
(1) 事先准备多种高质量的指令微调数据集,每个数据集尽量保持差异性。那高质量如何定义呢?我们可以从一些效果不错的模型收集它们训练使用的指令数据集
(2)笔者在实验过程中,发现加入多伦对话的数据有助于提升模型生成能力,如果仅用单轮对话或者单轮指令训练出的模型生成长度可能偏短。
(3)另外通过实验发现,如果模型微调的时候使用模板,那么推理的时候应该也使用模板,否则效果会影响,直观上就是生成效果不理想,生成比较短,甚至“驴唇不对马嘴”;训练使用了英文模板,推理的时候未使用提示模板的情况下会出现中英文混杂现象。
相关文章:
【LLM系列之指令微调】长话短说大模型指令微调的“Prompt”
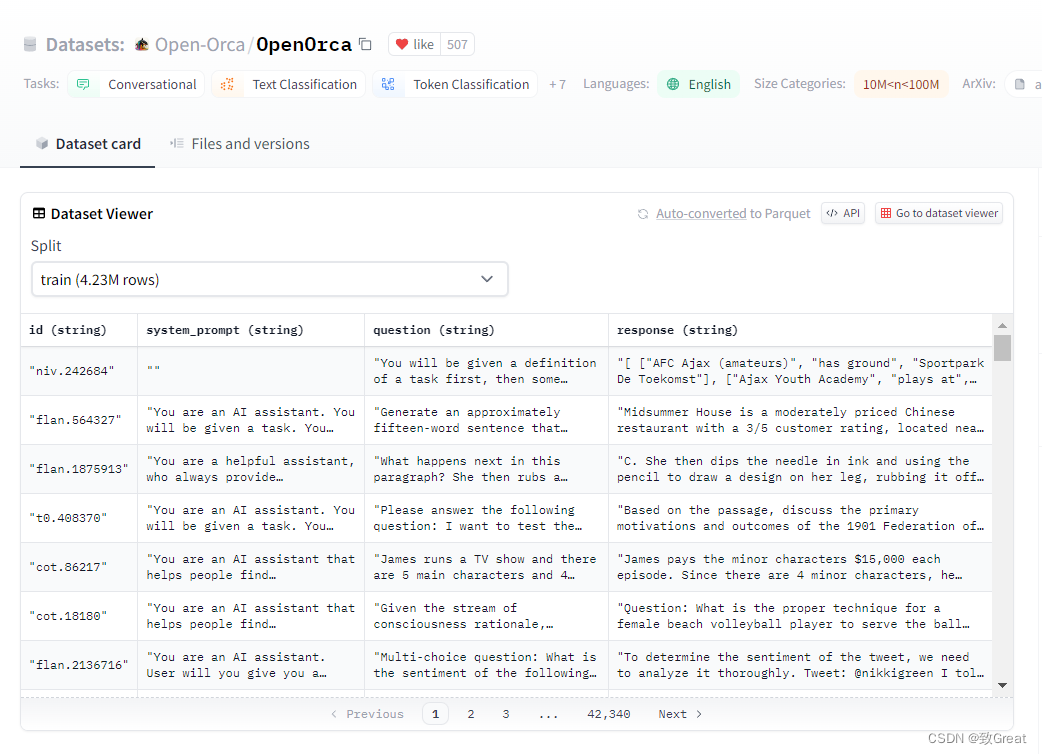
1 指令微调数据集形式“花样”太多 大家有没有分析过 prompt对模型训练或者推理的影响?之前推理的时候,发现不加训练的时候prompt,直接输入模型性能会变差的,这个倒是可以理解。假如不加prompt直接训练,是不是测试的时…...

MacOS使用brew如何下载Nginx
首先,第一步切换源: 切换 brew.git 仓库地址: cd "$(brew --repo)" git remote set-url origin https://mirrors.aliyun.com/homebrew/brew.git 替换 homebrew-core.git 仓库地址: cd "$(brew --repo)/Library/Taps/home…...

linux ftp
使用ftp连接本机进行文件传输 1、下载vsftpd服务器程序 apt install vsftpd 2、使用tcp抓包 tcpdump -nt -i lo port 20 在FTP连接到本地主机(127.0.0.1)时,数据可能通过本地回环接口(loopback interface)传输&…...
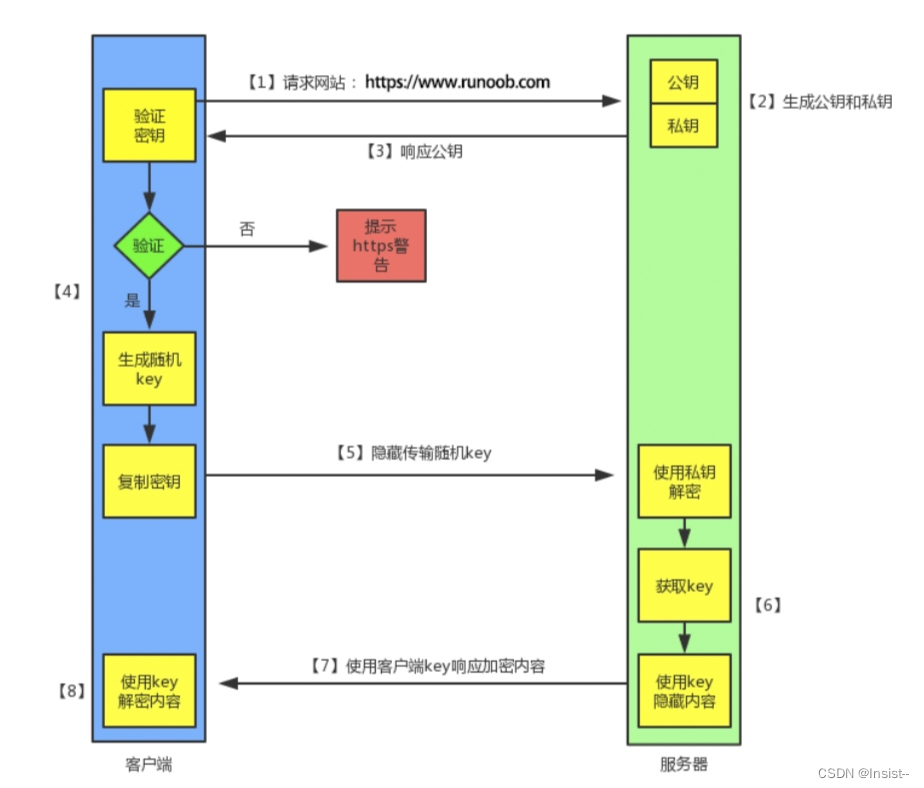
你知道HTTP与HTTPS有什么区别吗?
作者:Insist-- 个人主页:insist--个人主页 作者会持续更新网络知识和python基础知识,期待你的关注 目录 一、什么是HTTP? 二、什么是HTTPS? 三、HTTPS 的工作原理 1、客户端发起 HTTPS 请求 2、服务端的配置 3、…...
keil使用printf函数重定串口输出,程序卡在Reset_Handler
最近在做国产芯片GD32F103项目,使用printf()函数重定向USART0串口输出,发现程序没有运行,单步调试发现,程序卡在startup_gd32f10x.s文件的Reset_Handler处,记录一下解决方法。 解决办法: 1、引用头文件#in…...

Redis预热 雪崩 击穿 穿透
redis预热 在Redis中,预热是指在实际的负载之前,提前将数据加载到内存中,以便在请求到来时能够快速响应。预热可以减少冷启动时的延迟,并提高系统的性能。 有几种方法可以进行Redis的预热: 使用持久化机制࿱…...
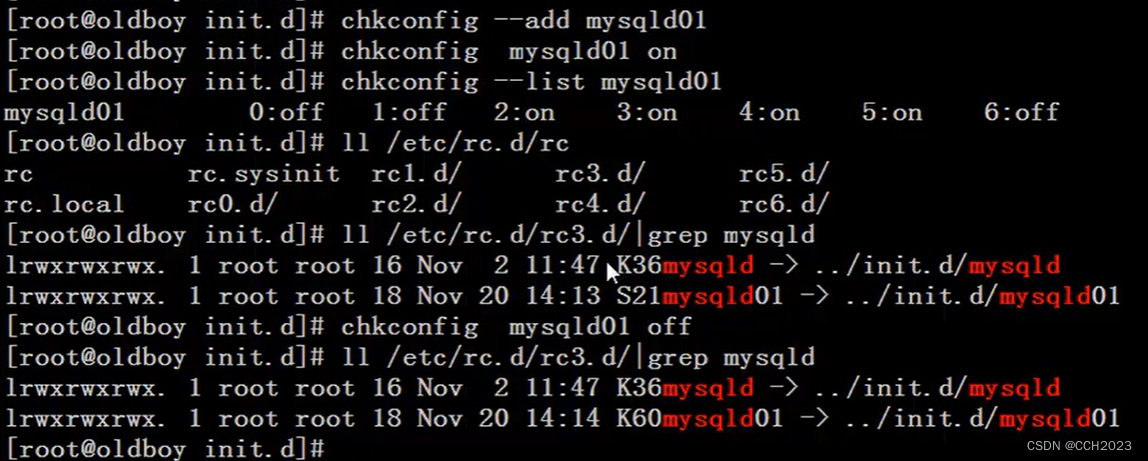
Shell脚本学习-MySQL单实例和多实例启动脚本
已知MySQL多实例启动命令为: mysqld_safe --defaults-file/data/3306/my.cnf & 停止命令为: mysqladmin -uroot -pchang123 -S /data/3306/mysql.sock shutdown 请完成mysql多实例的启动脚本的编写: 问题分析: 要想写出脚…...
vue3搭建(vite+create-vue)
目录 前提条件 输入命令 对于Add an End-to-End Testing Solution nightwatch和Cypress 和 Playwright 运行 前提条件 熟悉命令行已安装 16.0 或更高版本的 Node.js (node -v查看版本) 输入命令 npm init vuelatest 这一指令将会安装并执行 create-…...

服务器中了360后缀勒索病毒怎么解决,360后缀勒索病毒解密数据恢复
某医药公司是一家小型企业,拥有自己的服务器存储重要数据和文件。某天早上,IT管理员发现企业服务器中了360后缀的勒索病毒,所有数据文件都被加密了。这个病毒的入侵让公司业务受到严重影响,企业立即启动了勒索病毒解密数据恢复的措…...

3000字详解:风控核心岗位及核心价值
01、信贷场景中所谓风控是什么? 从一个小故事说起: “风控是什么?” “你走过大桥么?” “桥上有栏杆么?” “有” “你过桥时会扶栏杆么” “一般不扶” “那栏杆是不是没必要有呢” “那还是得有啊…...

fiddler 手机抓包(含https) 完整流程
第一部分:下载并安装fiddler 一.使用任一浏览器搜索【fiddler下载安装】,并下载fiddler 安装包。 二.fiddler安装包下载成功后,将下载的fiddler压缩包解压到自定义文件夹【fiddler】或者解压到当前文件夹下,双击文件夹中的【fidd…...

ChatGPT学python——制作自己的AI模型(一)初步了解
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★前端炫酷代码分享 ★ ★ uniapp-从构建到提升★ ★ 从0到英雄,vue成神之路★ ★ 解决算法,一个专栏就够了★ ★ 架…...

多赛道出海案例,亚马逊云科技为企业提供全新解决方案实现高速增长
数字化浪潮之下,中国企业的全球化步伐明显提速。从“借帆出海”到“生而全球化”,中国企业实现了从低端制造出口,向技术创新和品牌先导的升级。为助力中国企业业务高效出海,亚马逊云科技于2023年6月9日在深圳大中华喜来登酒店举办…...

异步消息传递技术 JMS AMQP MQTT
广泛使用的三种异步消息传递技术:JMS AMQP MQTT JMS AMQP MQTT JMS(Java Message Service):一个类似JDBC的规范,提供了与消息服务相关的API接口 JMS消息模型: P2P 点对点模型:消息发到一个队…...

利用Python实现汉译英的三种方法
一、前言 有道翻译API(主要推荐) 百度翻译API(需要申请key与密钥,每月100万免费字符) 谷歌翻译API(需要梯子,而且不稳定,不推荐) 二、代码 1、判断文本是否存在中文…...
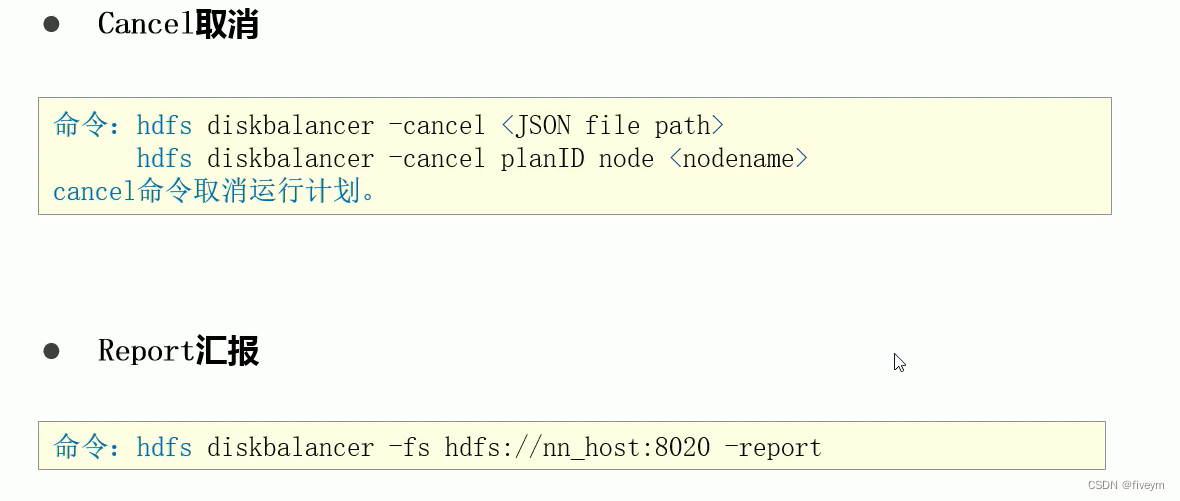
磁盘均衡器:HDFS Disk Balancer
HDFS Disk Balancer 背景产生的问题以及解决方法 hdfs disk balancer简介HDFS Disk Balancer功能数据传播报告 HDFS Disk Balancer开启相关命令 背景 相比较于个人PC,服务器一般可以通过挂载多块磁盘来扩大单机的存储能力在Hadoop HDFS中,DataNode负责最…...

蔚小理新势力互联网造车在CAN FD硬件主框架及后装控制方案开发
在国内,新势力造车影响已经非常之大,整个造车大潮中,新整车企业蔚来汽车、小鹏汽车、理想汽车无一例外选择了CAN FD作为主要的车载通信总线,特斯拉推出了引领汽车EE架构集中化的趋势,即使在车载以太网EE架构快速发展的…...
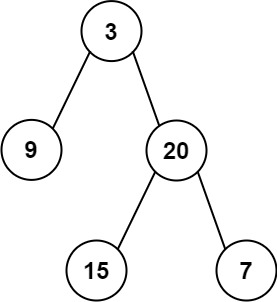
左叶子之和
404. 左叶子之和 简单(有点意思 第一次我也写错了 先自己递归去写 如果不行看答案 我感觉还是蛮不错的) 示例 1: 输入: root [3,9,20,null,null,15,7] 输出: 24 解释: 在这个二叉树中,有两个左叶子,分别是 9 和 15…...
Java版知识付费平台免费搭建 Spring Cloud+Spring Boot+Mybatis+uniapp+前后端分离实现知识付费平台qt
Java版知识付费源码 Spring CloudSpring BootMybatisuniapp前后端分离实现知识付费平台 提供职业教育、企业培训、知识付费系统搭建服务。系统功能包含:录播课、直播课、题库、营销、公司组织架构、员工入职培训等。 提供私有化部署,免费售…...

LeetCode343. 整数拆分
343. 整数拆分 文章目录 [343. 整数拆分](https://leetcode.cn/problems/integer-break/)一、题目二、题解方法一:动态规划方法改良 一、题目 给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k > 2 ),并使这些整…...

3分钟掌握gmpublisher:Garry‘s Mod工坊发布的终极解决方案
3分钟掌握gmpublisher:Garrys Mod工坊发布的终极解决方案 【免费下载链接】gmpublisher ⚙️ Workshop Publishing Utility for Garrys Mod, written in Rust & Svelte and powered by Tauri 项目地址: https://gitcode.com/gh_mirrors/gm/gmpublisher 还…...

洛可可≠堆砌!从构图节奏、卷草纹矢量逻辑到S形动线设计,深度拆解Midjourney生成真·18世纪法式优雅的4大底层规则
更多请点击: https://codechina.net 第一章:洛可可≠堆砌!从构图节奏、卷草纹矢量逻辑到S形动线设计,深度拆解Midjourney生成真18世纪法式优雅的4大底层规则 洛可可风格的本质不是装饰元素的无序叠加,而是以数学韵律…...

ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署
更多请点击: https://kaifayun.com 第一章:ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署 环境准备与API密钥获取 首先注册ElevenLabs账号并进入 Profile → API Keys页面,生成…...

CANN/asc-devkit cyl_bessel_i0f函数
cyl_bessel_i0f 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...

中兴B863AV3.2-M刷机避坑指南:S905L3A芯片识别、固件选择与Amlogic USB Burning Tool 2.2.0配置详解
中兴B863AV3.2-M刷机全流程精解:从芯片识别到固件烧录的进阶实践 在智能电视盒的玩家圈子里,中兴B863AV3.2-M因其出色的硬件配置和可玩性备受关注。这款搭载Amlogic S905L3A芯片的设备,通过刷机可以解锁更多功能,但过程中暗藏的&q…...

独立开发者如何利用Taotoken的透明计费规避项目超支风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的透明计费规避项目超支风险 对于独立开发者而言,项目预算的控制是决定项目能否持续、健康…...

FLUX.1-dev-Controlnet-Union:一站式多模态图像控制解决方案,让AI生成更精准可控
FLUX.1-dev-Controlnet-Union:一站式多模态图像控制解决方案,让AI生成更精准可控 【免费下载链接】FLUX.1-dev-Controlnet-Union 项目地址: https://ai.gitcode.com/hf_mirrors/InstantX/FLUX.1-dev-Controlnet-Union 你是否曾经在AI图像生成中遇…...

罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现
罗技鼠标宏逆向工程:PUBG后坐力补偿系统的架构设计与实现 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏中ÿ…...

AD23新手必看:从画完PCB到嘉立创成功下单Gerber,保姆级避坑指南
AD23新手必看:从画完PCB到嘉立创成功下单Gerber,保姆级避坑指南 第一次用Altium Designer 23完成PCB设计后,面对Gerber文件导出和嘉立创下单的复杂流程,很多新手都会感到手足无措。本文将从实际经验出发,带你一步步避开…...

2026年降AI技术进化深度解读:从换词替句到语义重构各代技术效果完整对比
2026年降AI技术进化深度解读:从换词替句到语义重构各代技术效果完整对比 跟同学聊起降AI技术进化解读,发现大家理解差距很大。理解浅的踩很多坑,理解深的很快解决了。 这篇文章把原理和实战方法都讲清楚。 理解降AI技术进化解读的核心逻辑 …...