Attention Is All You Need
Attention Is All You Need
- 摘要
- 1. 简介
- 2. Background
- 3. 模型架构
- 3.1 编码器和解码器堆栈
- 3.2 Attention
- 3.2.1 缩放的点积注意力(Scaled Dot-Product Attention)
- 3.2.2 Multi-Head Attention
- 3.2.3 Attention 在我们模型中的应用
- 3.3 Position-wise前馈网络
- 3.4 Embeddings and Softmax
- 3.5 Positional Encoding
- 4. Why Self-Attention
代码:https://github.com/jadore801120/attention-is-all-you-need-pytorch
单位:Google
会议:Advances in Neural Information Processing Systems 30 (NIPS 2017)
摘要
- 主要的序列转导模型是基于复杂的循环或卷积神经网络(RNN和CNN),包括一个编码器和一个解码器。
- 表现最好的模型还通过注意力机制连接编码器和解码器。
- 我们提出了一个新的简单的网络架构,Transformer,完全基于注意力机制,完全摒弃递归和卷积。
- 在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更具并行性,并且需要更少的训练时间。
- 我们的模型在WMT 2014 English-to-German 翻译任务上实现了28.4 BLEU,比现有的最佳结果(包括集合)提高了2个BLEU以上。
- 在WMT 2014 English-to-French翻译任务中,我们的模型在8个gpu上训练3.5天后,建立了一个新的单模型最先进的BLEU分数41.0,这是文献中最佳模型训练成本的一小部分。
1. 简介
- 递归神经网络(RNN),特别是长短期记忆(LSTM)和门控递归神经网络,已经被牢固地确立为序列建模和转导问题(如语言建模和机器翻译)的最新方法。
- 循环模型通常沿输入和输出序列的符号位置进行因子计算。将位置与计算时间中的步骤对齐,它们生成一个隐藏状态序列h_t,作为前一个隐藏状态h_t−1和位置 t 的输入的函数。
- 这种固有的顺序性排除了训练示例中的并行化,这在较长的序列长度下变得至关重要,因为内存约束限制了跨示例的批处理。
- 然而,顺序计算的基本约束仍然存在。
- 注意机制已经成为各种任务中引人注目的序列建模和转导模型的组成部分,允许在不考虑它们在输入或输出序列中的距离的情况下对依赖关系进行建模。
- 然而,在除少数情况外的所有情况下,这种注意机制都与循环网络结合使用。
- 在这项工作中, 我们提出了Transformer,一个模型架构避免了重复,而是完全依赖于一种注意力机制来绘制输入和输出之间的全局依赖关系。 Transformer允许在8 P100 GPUs训练后,能够显著地更平行化,并能达到翻译质量的新状态。
2. Background
- 减少顺序计算的目标也构成了Extended Neural GPU,ByteNet 和ConvS2S的基础,它们都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。
- 在这些模型中,将两个任意输入或输出位置的信号关联起来所需的操作数量随着位置之间的距离而增长,ConvS2S为线性增长,ByteNet为对数增长。这使得学习距离较远位置之间的依赖关系变得更加困难。
- 在Transformer中,这被减少到一个恒定的操作数量,尽管其代价是由于平均注意加权位置而降低了有效分辨率,我们用3.2节中描述的多头注意抵消了这一影响。
- 自我注意(Self-attention),有时被称为内注意(intra-attention ),是一种将单个序列的不同位置联系起来以计算该序列的表示的注意机制。 自我注意在阅读理解、抽象总结、文本蕴涵和学习任务无关的句子表征等任务中得到了成功的应用。
- 端到端记忆网络基于循环注意机制而不是顺序排列的递归,并且在简单语言问答和语言建模任务中表现良好。
- 然而,据我们所知,Transformer是第一个完全依赖于self-attention来计算其输入和输出表示的转导模型,而不使用序列对齐rnn或卷积。
3. 模型架构
- 大多数竞争性的神经序列转导模型具有编码器-解码器结构。
- 这里,编码器映射符号表示的输入序列(x1, …, xn)到连续表示序列 z = (z1,…,zn)。给定z,解码器然后生成一个输出序列(y1,…,ym)每次一个元素的符号。
- 在每一步,模型都是自回归的,在生成下一个符号时,使用之前生成的符号作为附加输入。
- Transformer遵循这个整体架构,使用堆叠的 self-attention 和 point-wise,全连接层 for 编码器和解码器,分别如图1的左半部分和右半部分所示。
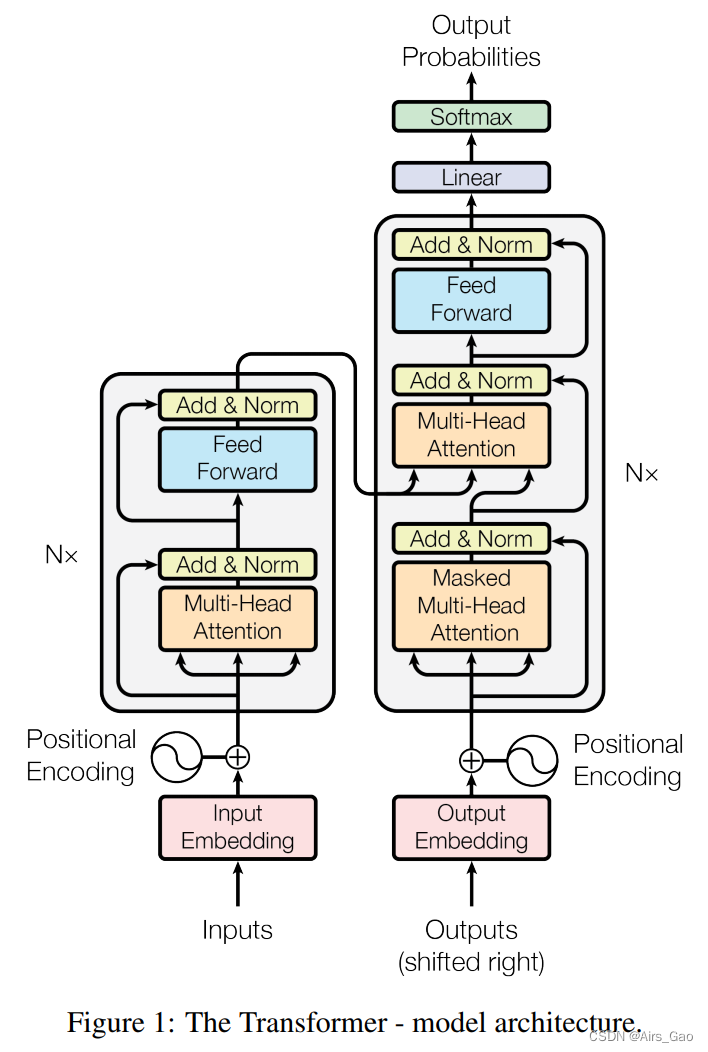
3.1 编码器和解码器堆栈
- Encoder: 编码器由N = 6个相同层的堆栈组成。每一层有两个子层。第一个是multi-head self-attention机制,第二个是简单的、按位置的(position-wise)全连接前馈网络。
- 我们在每两个子层周围使用残差连接(residual connection),然后进行层归一化。即各子层的输出为 LayerNorm(x + Sublayer(x)),其中Sublayer(x)是子层本身实现的函数。
- 为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度为d_model = 512。
- Decoder: 解码器也由N = 6层相同的堆栈组成。除了每个编码器层中的两个子层之外,解码器插入第三个子层,该子层对编码器堆栈的输出执行multi-head attention。
- 与编码器类似,我们在每个子层周围使用残差连接,然后进行层归一化。
- 我们还修改了解码器堆栈中的self-attention sub-layer,以防止位置关注后续位置。
- 这种掩蔽,再加上输出嵌入被偏移一个位置的事实,确保了位置 i 的预测只能依赖于位置小于 i 的已知输出。
3.2 Attention
- 注意函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。
- 输出是作为值的加权和计算的,其中分配给每个值的权重是由查询与相应键的兼容性函数计算的。
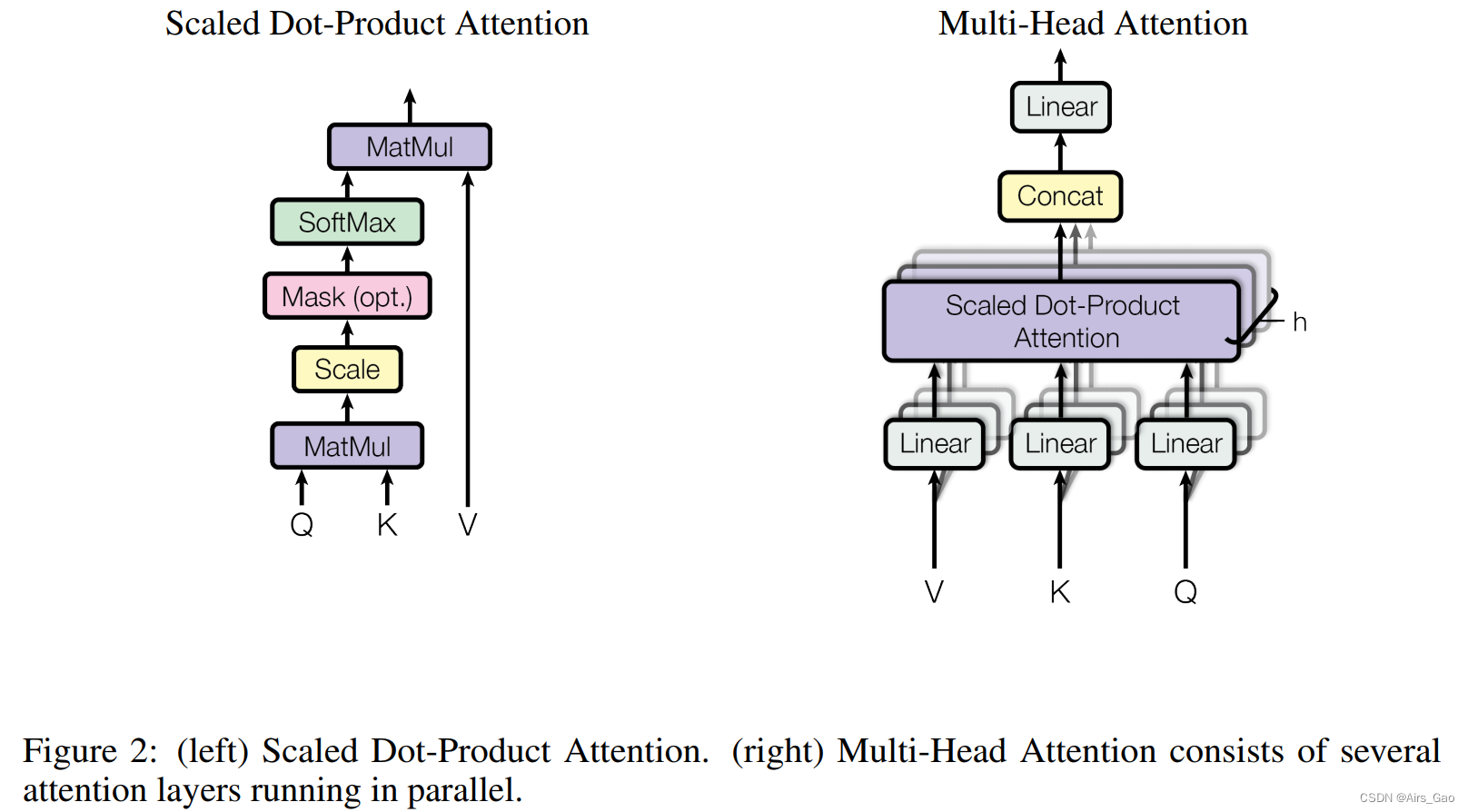
3.2.1 缩放的点积注意力(Scaled Dot-Product Attention)
-
我们称这种特殊的关注为 “Scaled Dot-Product Attention”(图2)。
-
输入由维度dk的queries and keys,以及维度dv的值组成。我们计算query with all keys的点积,将每个值除以“根号下dk”,应用softmax函数来获得这些值的权重。
-
在实践中,我们同时计算一组queries的注意力函数,它们被打包成一个矩阵Q。 keys and values也打包到矩阵K和V中。我们计算输出矩阵为:
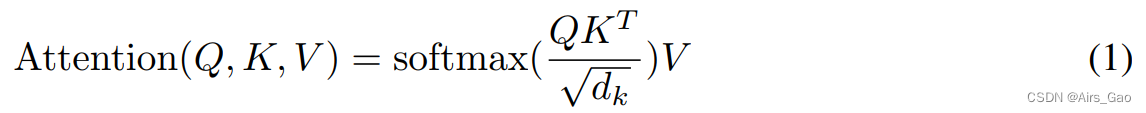
-
两种最常用的注意函数是加性注意和点积(乘)注意。
-
除了
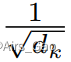
的比例因子外,点积注意力与我们的算法相同。 -
加性注意使用一个具有单个隐藏层的前馈网络来计算兼容性函数。
-
虽然两者在理论复杂性上相似,但点积注意在实践中要更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
-
当d_k值较小时,两种机制的表现相似,当d_k值较大时,加性注意优于点积注意。
-
我们怀疑,对于较大的d_k值,点积的大小会变大,从而将softmax函数推入具有极小梯度的区域。
-
为了抵消这种影响,我们将点积乘以
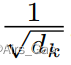
3.2.2 Multi-Head Attention
-
我们发现,与其使用d_model维度的keys, values 和 queries执行单一的注意力函数,不如将keys, values 和 queries分别以不同的、学习过的线性投影h次线性投影到dk、dk和dv维度,这是有益的。
-
然后,在queries, keys and values的每个投影版本上,我们并行地执行注意力函数,生成d维输出值。
-
将它们连接起来并再次进行投影,得到最终值,如图2所示。
-
多头注意允许模型在不同位置共同注意来自不同表示子空间的信息。对于单一注意力头,平均会抑制这一点。
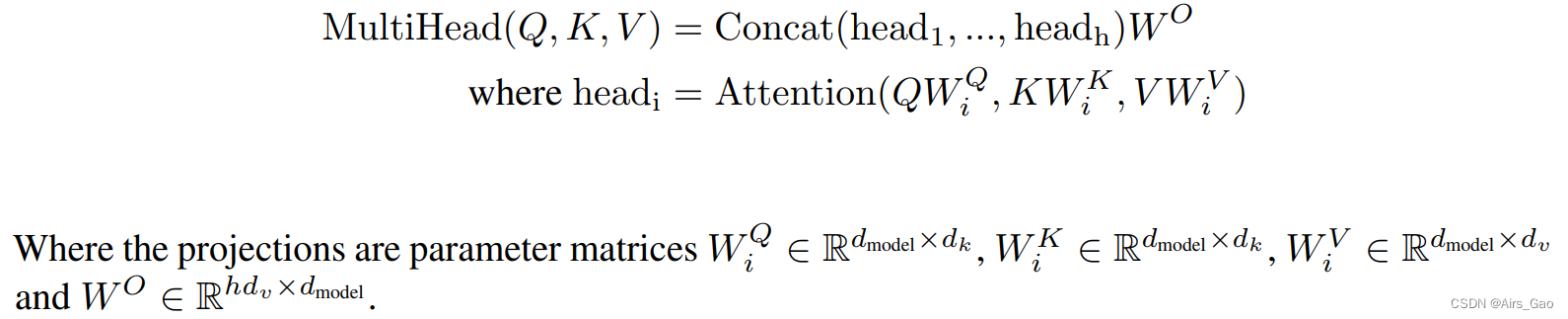
-
在这项工作中,我们使用h = 8个平行的注意层,或头。对于每一个,我们使用d_k = d_v = d_model/h = 64。
-
由于每个头部的维数降低,因此总计算成本与全维的单头部关注相似。
3.2.3 Attention 在我们模型中的应用
Transformer以三种不同的方式使用多头注意力:
- 在“encoder-decoder attention”层中,queries来自前一个解码器层,而memory keys and values来自编码器的输出。这允许解码器中的每个位置都参与输入序列中的所有位置。这模仿了序列到序列模型中典型的编码器-解码器注意机制。
- 编码器包含self-attention层。在self-attention层中,所有的keys, values and queries都来自同一个地方,在这种情况下,是编码器中前一层的输出。
- 类似地,解码器中的自注意层允许解码器中的每个位置注意到解码器中的所有位置直至并包括该位置。我们需要防止解码器中的向左信息流以保持自回归特性。我们通过屏蔽(设置为负无穷)softmax输入中对应于非法连接的所有值来实现缩放点积注意,如图2所示。
3.3 Position-wise前馈网络
- 除了注意子层之外,编码器和解码器中的每一层都包含一个完全连接的前馈网络,该网络分别相同地应用于每个位置。这包括两个线性转换,中间有一个ReLU激活。
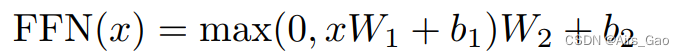
- 虽然线性变换在不同位置上是相同的,但它们在每一层之间使用不同的参数。
- 另一种描述它的方式是两个核大小为1的卷积。
- 输入和输出的维数d_model = 512,内层的维数 d_ff = 2048。
3.4 Embeddings and Softmax
- 与其他序列转导模型类似,我们使用学习嵌入将输入 tokens 和输出 tokens 转换为维度d_model的向量。
- 我们还使用通常学习的线性变换和softmax函数将解码器输出转换为预测的下一个tokens概率。
- 在我们的模型中,我们在两个嵌入层和pre-softmax线性变换之间共享相同的权矩阵。
- 在嵌入层中,我们将这些权重乘以
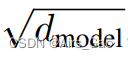
3.5 Positional Encoding
- 由于我们的模型不包含递归和卷积,为了使模型利用序列的顺序,我们必须注入一些关于序列中标记的相对或绝对位置的信息。
- 为此,我们在输入嵌入中编码器和解码器堆栈的底部 添加了“位置编码”。
- 位置编码与嵌入具有相同的维数模型,因此可以对两者进行求和。位置编码有多种选择,有learned and fixed。
- 在这项工作中,我们使用了不同频率的正弦和余弦函数:
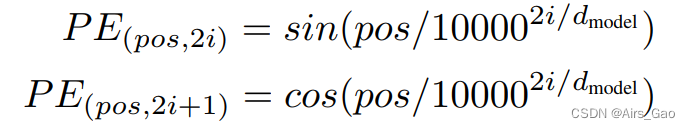
其中pos是位置,I是尺寸。也就是说,位置编码的每一个维度对应于一个正弦波。波长形成从2π到10000·2π的几何级数。 - 我们选择这个函数是因为我们假设它可以让模型很容易地学习相对位置,因为对于任何固定的偏移量 k, PE_pos+k可以表示为的线性函数PE_pos。
- 我们还尝试使用学习的位置嵌入,并发现这两个版本产生了几乎相同的结果。我们选择正弦版本是因为它可以允许模型外推到比训练期间遇到的序列长度更长的序列。
4. Why Self-Attention
- 在本节中,我们将自注意层的各个方面与通常用于映射一个可变长度符号表示序列的循环层和卷积层进行比较(x1, … , xn)到另一个等长的序列(z1,…, zn),带xi,zi ∈ R^d; 例如,在典型的序列转导编码器或解码器中的隐藏层。为了激励我们使用self-attention,我们考虑了三个必要条件。
- 一个是每层的总计算复杂度。另一个是可以并行化的计算量,通过所需的最小顺序操作数来衡量。
- 第三个是网络中远程依赖关系之间的路径长度。学习远程依赖关系是许多序列转导任务中的关键挑战。影响学习这种依赖关系能力的一个关键因素是网络中向前和向后信号必须经过的路径长度。输入和输出序列中任意位置组合之间的路径越短,学习远程依赖关系就越容易。因此,我们还比较了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。
- 如表1所示,自关注层用恒定数量的顺序执行操作连接所有位置,而循环层需要O(n)个顺序操作。

- 就计算复杂性而言,当序列长度n小于表示维数d时,自注意层比循环层更快,这是机器翻译中最先进的模型(如word-piece)使用的句子表示最常见的情况和字节对表示。
- 为了提高涉及很长序列的任务的计算性能,自注意力可以限制为仅考虑输入序列中以相应输出位置为中心的大小为 r 的邻域。这将使最大路径长度增加到O(n=r)。我们计划在未来的工作中进一步研究这种方法。
- 一个核宽度为k < n的卷积层不能连接所有的输入和输出位置对。
- 在相邻核的情况下,这样做需要O(n=k)个卷积层的堆栈,在扩展卷积的情况下需要O(logk(n))个卷积层的堆栈,从而增加网络中任意两个位置之间最长路径的长度。
- 卷积层的开销通常比循环层高k倍。然而,可分离卷积[6]大大降低了复杂性,为O(k·n·d + n·d^2)。然而,即使k = n,可分离卷积的复杂性也等于自注意层和点前馈层的组合,这是我们在模型中采用的方法。
- 作为附带好处,self-attention可以产生更多可解释的模型。
- 不仅个体注意力头清楚地学会执行不同的任务,许多注意力头似乎表现出与句子的句法和语义结构相关的行为。
相关文章:
Attention Is All You Need
Attention Is All You Need 摘要1. 简介2. Background3. 模型架构3.1 编码器和解码器堆栈3.2 Attention3.2.1 缩放的点积注意力(Scaled Dot-Product Attention)3.2.2 Multi-Head Attention3.2.3 Attention 在我们模型中的应用 3.3 Position-wise前馈网络…...
手写线程池 - C++版 - 笔记总结
1.线程池原理 创建一个线程,实现很方便。 缺点:若并发的线程数量很多,并且每个线程都是执行一个时间较短的任务就结束了。 由于频繁的创建线程和销毁线程需要时间,这样的频繁创建线程会大大降低 系统的效率。 2.思考 …...

PHP 容器化引发线上 502 错误状态码的修复
最后更新时间 2023-01-24. 背景 笔者所在公司技术栈为 Golang PHP,目前部分项目已经逐步转 Go 语言重构,部分 PHP 业务短时间无法用 Go 重写。 相比 Go 语言,互联网公司常见的 Nginx PHP-FPM 模式,经常会出现性能问题—— 特…...

QT中UDP之UDPsocket通讯
目录 UDP: 举例: 服务器端: 客户端: 使用示例: 错误例子并且改正: UDP: (User Datagram Protocol即用户数据报协议)是一个轻量级的,不可靠的࿰…...

【C语言】10-三大结构之循环结构-1
1. 引言 在日常生活中经常会遇到需要重复处理的问题,例如 统计全班 50 个同学平均成绩的程序求 30 个整数之和检查一个班级的同学程序是否及格要处理以上问题,最原始的方法是分别编写若干个相同或相似的语句或者程序段进行处理 例如:处理 50 个同学的平均成绩可以先计算一个…...

Windows下RocketMQ的启动
下载地址:下载 | RocketMQ 解压后 一、修改runbroker.cmd 修改 bin目录下的runbroker.cmd set "JAVA_OPT%JAVA_OPT% -server -Xms2g -Xmx2g" set "JAVA_OPT%JAVA_OPT% -XX:MaxDirectMemorySize15g" set "JAVA_OPT%JAVA_OPT% -cp %CLASSP…...

linux内核升级 docker+k8s更新显卡驱动
官方驱动 | NVIDIA在此链接下载对应的显卡驱动 # 卸载可能存在的旧版本nvidia驱动(如果没有安装过可跳过,建议执行) sudo apt-get remove --purge nvidia* # 安装驱动需要的依赖 sudo apt-get install dkms build-essential linux-headers-generic sudo vim /etc/mo…...

express学习笔记2 - 三大件概念
中间件 中间件是一个函数,在请求和响应周期中被顺序调用(WARNING:提示:中间件需要在响应结束前被调用) 路由 应用如何响应请求的一种规则 响应 / 路径的 get 请求: app.get(/, function(req, res) {res…...

Steam搬砖蓝海项目
这个项目早在很久之前就已经存在,并且一直非常稳定。如果你玩过一些游戏,你一定知道Steam是什么平台。Steam平台是全球最大的综合性数字发行平台之一,玩家可以在该平台购买、下载、讨论、上传和分享游戏和软件。 今天我给大家解释一下什么是…...

就业并想要长期发展选数字后端还是ic验证?
“就业并想要长期发展选数字后端还是ic验证?” 这是知乎上的一个热点问题,浏览量达到了13,183。看来有不少同学对这个问题感到疑惑。之前更新了数字后端&数字验证的诸多文章,从学习到职业发展,都写过,唯一没有做过…...

当服务器域名出现解析错误的问题该怎么办?
域名解析是互联网用户接收他们正在寻找的域的地址的过程。更准确地说,域名解析是人们在浏览器中输入时使用的域名与网站IP地址之间的转换过程。您需要站点的 IP 地址才能知道它所在的位置并加载它。但,在这个过程中,可能会出现多种因素…...

面试必考精华版Leetcode2095. 删除链表的中间节点
题目: 代码(首刷看解析 day22): class Solution { public:ListNode* deleteMiddle(ListNode* head) {if(head->nextnullptr) return nullptr;ListNode *righthead;ListNode *lefthead;ListNode *NodeBeforeLeft;while(right!n…...

对 Redis 实现分布式事务的探索与实现
对 Redis 实现分布式事务的探索与实现 一、简介简介优势 二、Redis 的事务机制事务WATCH 命令MULTI 命令EXEC 命令UNWATCH 命令 三、Redis 的分布式事务集群架构分布式事务分布式事务实现方式1. 两阶段提交(2PC)方式Paxos 算法实现方式Raft 算法实现方式…...

Matlab实现Spectral Clustering算法
Spectral Clustering算法是一种基于图论的聚类算法,它可以将数据点按照图结构进行划分,发现复杂和非线性可分的结构。在这篇博客中,我将介绍Spectral Clustering算法的原理和步骤,并给出一个用Matlab实现的代码示例。 目录 一、…...

Android 测试
工程目录图 1- Espresso 2- uiautomator Espresso 文档UI Automator文档ui-automator 英文文档 请点击下面工程名称,跳转到代码的仓库页面,将工程 下载下来 Demo Code 里有详细的注释 代码:testespresso 参考文献 Android 利用 espre…...

全面解析大语言模型的工作原理
当ChatGPT在去年秋天推出时,在科技行业乃至世界范围内引起了轰动。当时,机器学习研究人员尝试研发了多年的语言大模型(LLM),但普通大众并未十分关注,也没有意识到它们变得多强大。 如今,几乎每个…...

cmake+pybind11打包c++库成python wheel安装包
目录 写在前面准备1、pybind11获取源码编译安装 2、conda demo官方源码修改CMakeLists.txt编译生成安装测试 参考完 写在前面 1、本文内容 有时候我们需要用c代码,供python调用,本文提供将c库封装成python接口的方法,并将库打包成可通过pip安…...
史上最细,接口自动化测试框架-Pytest+Allure+Excel整理(代码)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Allure框架 Allu…...

【计算机视觉中的 GAN 】 - 条件图像合成和 3D 对象生成(2)
一、说明 上文 【计算机视觉中的 GAN 】或多或少是GANs,生成学习和计算机视觉的介绍。我们达到了在 128x128 图像中生成可区分图像特征的程度。但是,如果你真的想了解GAN在计算机视觉方面的进展,你肯定必须深入研究图像到图像的翻译。…...

智安网络|常见的网络安全陷阱:你是否掉入了其中?
在数字化时代,网络安全成为了一个重要的议题。随着我们越来越多地在互联网上进行各种活动,诸如在线银行交易、社交媒体分享和在线购物等,我们的个人信息也更容易受到攻击和滥用。虽然有许多关于网络安全的指导和建议,但仍然有许多…...

从BMP文件头到像素遍历:手把手教你用C语言和VS2022读取图片的RGB数据
从BMP文件头到像素遍历:手把手教你用C语言和VS2022读取图片的RGB数据 在数字图像处理领域,理解图像数据的底层存储结构是开发者必须掌握的核心技能。BMP作为Windows系统中最基础的位图格式,其简单的文件结构使其成为学习图像处理的理想起点。…...

长期使用Taotoken Token Plan套餐的成本节省实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐的成本节省实际感受 1. 从按量付费到套餐订阅的转变 我们团队在接入大模型API进行日常开发与内容…...

如何在Linux上安装Realtek R8125 2.5GbE网卡驱动:完整指南
如何在Linux上安装Realtek R8125 2.5GbE网卡驱动:完整指南 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms 你是否正…...

go-jsonnet实际应用案例:Kubernetes配置管理与微服务架构
go-jsonnet实际应用案例:Kubernetes配置管理与微服务架构 【免费下载链接】go-jsonnet 项目地址: https://gitcode.com/gh_mirrors/go/go-jsonnet 在现代云原生应用开发中,Kubernetes配置管理和微服务架构的复杂性常常让开发者头疼。go-jsonnet作…...

JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现
JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现 【免费下载链接】jmeter-grpc-request JMeter gRPC Request load test plugin for gRPC 项目地址: https://gitcode.com/gh_mirrors/jm/jmeter-grpc-request 随着微服务架构的普及,gRPC已…...

不用命令行!OpenClaw 2.7.5 Win11 专属部署,双击直达本地 AI 助手
前言 本教程专为Windows用户设计,提供可视化部署方案。通过专用部署包实现全程图形化操作,彻底告别命令行和手动配置环境。即使是零基础用户也能轻松完成部署,快速搭建专属数字员工系统,显著提升工作效率。教程完美适配Windows 1…...

【更新 v 2.7.5 版本】桌面版 Open Claw 本地一键部署指南
✨ 核心亮点 零代码门槛|全程可视化|无需手动配环境|内置所有依赖|28 万 Tokens 额度 🔗 下载地址 https://xiake.yun/api/download/package/16?promoCodeIV8E496E2F7A 📝 前言 开源圈热门的「数字员…...

初次使用Taotoken官方价折扣进行模型测试的成本节省体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken官方价折扣进行模型测试的成本节省体验 1. 项目背景与成本挑战 最近启动一个新项目,需要集成大模型能…...

谷歌 I/O 2026 炸场:Gemini 3.5 Flash 震撼发布!反超 3.1 Pro,开启“全自动 Agent 狂飙”时代
在刚刚开幕的 Google I/O 2026 开发者大会上,谷歌正式扔下了一颗重磅炸弹:发布全新 Gemini 3.5 系列 的首款旗舰轻量模型 —— Gemini 3.5 Flash。 这次的发布极为硬核,谷歌彻底打破了我们对 “Flash 是低配版/轻量版” 的固有认知。根据 Dee…...

数据血缘是什么?一数据血缘、数据质量和数据地图的区别是什么?
数据血缘、数据质量、数据地图,这三个概念经常被混为一谈,尤其是刚入行的新人,觉得不就是管数据的吗,非要分那么清楚?就连一些工作了三五年的工程师,在面试时也常常搞混,比如把血缘当成地图&…...