实现langchain-ChatGLM API调用客户端(及未解决的问题)
langchain-ChatGLM是一个基于本地知识库的LLM对话库。其基于text2vec-large-Chinese为Embedding模型,ChatGLM-6B为对话大模型。原项目地址:https://github.com/chatchat-space/langchain-ChatGLM
对于如何本地部署ChatGLM模型,可以参考我之前的文章http://t.csdn.cn/16STJ
在本项目中,我们编写了langchai-ChatGLM API调用的客户端代码。经过测试虽然客户端可以正常调用服务器的API,但是对于删除知识库的指令服务器无法正常执行
1 langchain-ChatGLM API服务器端程序
下面程序段为langchain-ChatGLM项目中的api.py文件
import argparse
import json
import os
import shutil
from typing import List, Optional
import urllibimport nltk
import pydantic
import uvicorn
from fastapi import Body, FastAPI, File, Form, Query, UploadFile, WebSocket
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing_extensions import Annotated
from starlette.responses import RedirectResponsefrom chains.local_doc_qa import LocalDocQA
from configs.model_config import (KB_ROOT_PATH, EMBEDDING_DEVICE,EMBEDDING_MODEL, NLTK_DATA_PATH,VECTOR_SEARCH_TOP_K, LLM_HISTORY_LEN, OPEN_CROSS_DOMAIN)
import models.shared as shared
from models.loader.args import parser
from models.loader import LoaderCheckPointnltk.data.path = [NLTK_DATA_PATH] + nltk.data.pathclass BaseResponse(BaseModel):code: int = pydantic.Field(200, description="HTTP status code")msg: str = pydantic.Field("success", description="HTTP status message")class Config:schema_extra = {"example": {"code": 200,"msg": "success",}}class ListDocsResponse(BaseResponse):data: List[str] = pydantic.Field(..., description="List of document names")class Config:schema_extra = {"example": {"code": 200,"msg": "success","data": ["doc1.docx", "doc2.pdf", "doc3.txt"],}}class ChatMessage(BaseModel):question: str = pydantic.Field(..., description="Question text")response: str = pydantic.Field(..., description="Response text")history: List[List[str]] = pydantic.Field(..., description="History text")source_documents: List[str] = pydantic.Field(..., description="List of source documents and their scores")class Config:schema_extra = {"example": {"question": "工伤保险如何办理?","response": "根据已知信息,可以总结如下:\n\n1. 参保单位为员工缴纳工伤保险费,以保障员工在发生工伤时能够获得相应的待遇。\n2. 不同地区的工伤保险缴费规定可能有所不同,需要向当地社保部门咨询以了解具体的缴费标准和规定。\n3. 工伤从业人员及其近亲属需要申请工伤认定,确认享受的待遇资格,并按时缴纳工伤保险费。\n4. 工伤保险待遇包括工伤医疗、康复、辅助器具配置费用、伤残待遇、工亡待遇、一次性工亡补助金等。\n5. 工伤保险待遇领取资格认证包括长期待遇领取人员认证和一次性待遇领取人员认证。\n6. 工伤保险基金支付的待遇项目包括工伤医疗待遇、康复待遇、辅助器具配置费用、一次性工亡补助金、丧葬补助金等。","history": [["工伤保险是什么?","工伤保险是指用人单位按照国家规定,为本单位的职工和用人单位的其他人员,缴纳工伤保险费,由保险机构按照国家规定的标准,给予工伤保险待遇的社会保险制度。",]],"source_documents": ["出处 [1] 广州市单位从业的特定人员参加工伤保险办事指引.docx:\n\n\t( 一) 从业单位 (组织) 按“自愿参保”原则, 为未建 立劳动关系的特定从业人员单项参加工伤保险 、缴纳工伤保 险费。","出处 [2] ...","出处 [3] ...",],}}def get_folder_path(local_doc_id: str):return os.path.join(KB_ROOT_PATH, local_doc_id, "content")def get_vs_path(local_doc_id: str):return os.path.join(KB_ROOT_PATH, local_doc_id, "vector_store")def get_file_path(local_doc_id: str, doc_name: str):return os.path.join(KB_ROOT_PATH, local_doc_id, "content", doc_name)async def upload_file(file: UploadFile = File(description="A single binary file"),knowledge_base_id: str = Form(..., description="Knowledge Base Name", example="kb1"),
):saved_path = get_folder_path(knowledge_base_id)if not os.path.exists(saved_path):os.makedirs(saved_path)file_content = await file.read() # 读取上传文件的内容file_path = os.path.join(saved_path, file.filename)if os.path.exists(file_path) and os.path.getsize(file_path) == len(file_content):file_status = f"文件 {file.filename} 已存在。"return BaseResponse(code=200, msg=file_status)with open(file_path, "wb") as f:f.write(file_content)vs_path = get_vs_path(knowledge_base_id)vs_path, loaded_files = local_doc_qa.init_knowledge_vector_store([file_path], vs_path)if len(loaded_files) > 0:file_status = f"文件 {file.filename} 已上传至新的知识库,并已加载知识库,请开始提问。"return BaseResponse(code=200, msg=file_status)else:file_status = "文件上传失败,请重新上传"return BaseResponse(code=500, msg=file_status)async def upload_files(files: Annotated[List[UploadFile], File(description="Multiple files as UploadFile")],knowledge_base_id: str = Form(..., description="Knowledge Base Name", example="kb1"),
):saved_path = get_folder_path(knowledge_base_id)if not os.path.exists(saved_path):os.makedirs(saved_path)filelist = []for file in files:file_content = ''file_path = os.path.join(saved_path, file.filename)file_content = file.file.read()if os.path.exists(file_path) and os.path.getsize(file_path) == len(file_content):continuewith open(file_path, "ab+") as f:f.write(file_content)filelist.append(file_path)if filelist:vs_path, loaded_files = local_doc_qa.init_knowledge_vector_store(filelist, get_vs_path(knowledge_base_id))if len(loaded_files):file_status = f"documents {', '.join([os.path.split(i)[-1] for i in loaded_files])} upload success"return BaseResponse(code=200, msg=file_status)file_status = f"documents {', '.join([os.path.split(i)[-1] for i in loaded_files])} upload fail"return BaseResponse(code=500, msg=file_status)async def list_kbs():# Get List of Knowledge Baseif not os.path.exists(KB_ROOT_PATH):all_doc_ids = []else:all_doc_ids = [folderfor folder in os.listdir(KB_ROOT_PATH)if os.path.isdir(os.path.join(KB_ROOT_PATH, folder))and os.path.exists(os.path.join(KB_ROOT_PATH, folder, "vector_store", "index.faiss"))]return ListDocsResponse(data=all_doc_ids)async def list_docs(knowledge_base_id: Optional[str] = Query(default=None, description="Knowledge Base Name", example="kb1")
):local_doc_folder = get_folder_path(knowledge_base_id)if not os.path.exists(local_doc_folder):return {"code": 1, "msg": f"Knowledge base {knowledge_base_id} not found"}all_doc_names = [docfor doc in os.listdir(local_doc_folder)if os.path.isfile(os.path.join(local_doc_folder, doc))]return ListDocsResponse(data=all_doc_names)async def delete_kb(knowledge_base_id: str = Query(...,description="Knowledge Base Name",example="kb1"),
):# TODO: 确认是否支持批量删除知识库knowledge_base_id = urllib.parse.unquote(knowledge_base_id)if not os.path.exists(get_folder_path(knowledge_base_id)):return {"code": 1, "msg": f"Knowledge base {knowledge_base_id} not found"}shutil.rmtree(get_folder_path(knowledge_base_id))# self-added code#shutil.rmtree(get_vs_path(knowledge_base_id))# /self-added codereturn BaseResponse(code=200, msg=f"Knowledge Base {knowledge_base_id} delete success")async def delete_doc(knowledge_base_id: str = Query(...,description="Knowledge Base Name",example="kb1"),doc_name: str = Query(None, description="doc name", example="doc_name_1.pdf"),
):knowledge_base_id = urllib.parse.unquote(knowledge_base_id)if not os.path.exists(get_folder_path(knowledge_base_id)):return {"code": 1, "msg": f"Knowledge base {knowledge_base_id} not found"}doc_path = get_file_path(knowledge_base_id, doc_name)if os.path.exists(doc_path):os.remove(doc_path)remain_docs = await list_docs(knowledge_base_id)if len(remain_docs.data) == 0:shutil.rmtree(get_folder_path(knowledge_base_id), ignore_errors=True)return BaseResponse(code=200, msg=f"document {doc_name} delete success along with the whole knowledge base")else:status = local_doc_qa.delete_file_from_vector_store(doc_path, get_vs_path(knowledge_base_id))if "success" in status:return BaseResponse(code=200, msg=f"document {doc_name} delete success")else:return BaseResponse(code=1, msg=f"document {doc_name} delete fail")else:return BaseResponse(code=1, msg=f"document {doc_name} not found")async def update_doc(knowledge_base_id: str = Query(...,description="知识库名",example="kb1"),old_doc: str = Query(None, description="待删除文件名,已存储在知识库中", example="doc_name_1.pdf"),new_doc: UploadFile = File(description="待上传文件"),
):knowledge_base_id = urllib.parse.unquote(knowledge_base_id)if not os.path.exists(get_folder_path(knowledge_base_id)):return {"code": 1, "msg": f"Knowledge base {knowledge_base_id} not found"}doc_path = get_file_path(knowledge_base_id, old_doc)if not os.path.exists(doc_path):return BaseResponse(code=1, msg=f"document {old_doc} not found")else:os.remove(doc_path)delete_status = local_doc_qa.delete_file_from_vector_store(doc_path, get_vs_path(knowledge_base_id))if "fail" in delete_status:return BaseResponse(code=1, msg=f"document {old_doc} delete failed")else:saved_path = get_folder_path(knowledge_base_id)if not os.path.exists(saved_path):os.makedirs(saved_path)file_content = await new_doc.read() # 读取上传文件的内容file_path = os.path.join(saved_path, new_doc.filename)if os.path.exists(file_path) and os.path.getsize(file_path) == len(file_content):file_status = f"document {new_doc.filename} already exists"return BaseResponse(code=200, msg=file_status)with open(file_path, "wb") as f:f.write(file_content)vs_path = get_vs_path(knowledge_base_id)vs_path, loaded_files = local_doc_qa.init_knowledge_vector_store([file_path], vs_path)if len(loaded_files) > 0:file_status = f"document {old_doc} delete and document {new_doc.filename} upload success"return BaseResponse(code=200, msg=file_status)else:file_status = f"document {old_doc} success but document {new_doc.filename} upload fail"return BaseResponse(code=500, msg=file_status)async def local_doc_chat(knowledge_base_id: str = Body(..., description="Knowledge Base Name", example="kb1"),question: str = Body(..., description="Question", example="工伤保险是什么?"),history: List[List[str]] = Body([],description="History of previous questions and answers",example=[["工伤保险是什么?","工伤保险是指用人单位按照国家规定,为本单位的职工和用人单位的其他人员,缴纳工伤保险费,由保险机构按照国家规定的标准,给予工伤保险待遇的社会保险制度。",]],),
):vs_path = get_vs_path(knowledge_base_id)if not os.path.exists(vs_path):# return BaseResponse(code=1, msg=f"Knowledge base {knowledge_base_id} not found")return ChatMessage(question=question,response=f"Knowledge base {knowledge_base_id} not found",history=history,source_documents=[],)else:for resp, history in local_doc_qa.get_knowledge_based_answer(query=question, vs_path=vs_path, chat_history=history, streaming=True):passsource_documents = [f"""出处 [{inum + 1}] {os.path.split(doc.metadata['source'])[-1]}:\n\n{doc.page_content}\n\n"""f"""相关度:{doc.metadata['score']}\n\n"""for inum, doc in enumerate(resp["source_documents"])]return ChatMessage(question=question,response=resp["result"],history=history,source_documents=source_documents,)async def bing_search_chat(question: str = Body(..., description="Question", example="工伤保险是什么?"),history: Optional[List[List[str]]] = Body([],description="History of previous questions and answers",example=[["工伤保险是什么?","工伤保险是指用人单位按照国家规定,为本单位的职工和用人单位的其他人员,缴纳工伤保险费,由保险机构按照国家规定的标准,给予工伤保险待遇的社会保险制度。",]],),
):for resp, history in local_doc_qa.get_search_result_based_answer(query=question, chat_history=history, streaming=True):passsource_documents = [f"""出处 [{inum + 1}] [{doc.metadata["source"]}]({doc.metadata["source"]}) \n\n{doc.page_content}\n\n"""for inum, doc in enumerate(resp["source_documents"])]return ChatMessage(question=question,response=resp["result"],history=history,source_documents=source_documents,)async def chat(question: str = Body(..., description="Question", example="工伤保险是什么?"),history: List[List[str]] = Body([],description="History of previous questions and answers",example=[["工伤保险是什么?","工伤保险是指用人单位按照国家规定,为本单位的职工和用人单位的其他人员,缴纳工伤保险费,由保险机构按照国家规定的标准,给予工伤保险待遇的社会保险制度。",]],),
):for answer_result in local_doc_qa.llm.generatorAnswer(prompt=question, history=history,streaming=True):resp = answer_result.llm_output["answer"]history = answer_result.historypassreturn ChatMessage(question=question,response=resp,history=history,source_documents=[],)async def stream_chat(websocket: WebSocket, knowledge_base_id: str):await websocket.accept()turn = 1while True:input_json = await websocket.receive_json()question, history, knowledge_base_id = input_json["question"], input_json["history"], input_json["knowledge_base_id"]vs_path = get_vs_path(knowledge_base_id)if not os.path.exists(vs_path):await websocket.send_json({"error": f"Knowledge base {knowledge_base_id} not found"})await websocket.close()returnawait websocket.send_json({"question": question, "turn": turn, "flag": "start"})last_print_len = 0for resp, history in local_doc_qa.get_knowledge_based_answer(query=question, vs_path=vs_path, chat_history=history, streaming=True):await websocket.send_text(resp["result"][last_print_len:])last_print_len = len(resp["result"])source_documents = [f"""出处 [{inum + 1}] {os.path.split(doc.metadata['source'])[-1]}:\n\n{doc.page_content}\n\n"""f"""相关度:{doc.metadata['score']}\n\n"""for inum, doc in enumerate(resp["source_documents"])]await websocket.send_text(json.dumps({"question": question,"turn": turn,"flag": "end","sources_documents": source_documents,},ensure_ascii=False,))turn += 1async def document():return RedirectResponse(url="/docs")def api_start(host, port):global appglobal local_doc_qallm_model_ins = shared.loaderLLM()llm_model_ins.set_history_len(LLM_HISTORY_LEN)app = FastAPI()# Add CORS middleware to allow all origins# 在config.py中设置OPEN_DOMAIN=True,允许跨域# set OPEN_DOMAIN=True in config.py to allow cross-domainif OPEN_CROSS_DOMAIN:app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],)app.websocket("/local_doc_qa/stream-chat/{knowledge_base_id}")(stream_chat)app.get("/", response_model=BaseResponse)(document)app.post("/chat", response_model=ChatMessage)(chat)app.post("/local_doc_qa/upload_file", response_model=BaseResponse)(upload_file)app.post("/local_doc_qa/upload_files", response_model=BaseResponse)(upload_files)app.post("/local_doc_qa/local_doc_chat", response_model=ChatMessage)(local_doc_chat)app.post("/local_doc_qa/bing_search_chat", response_model=ChatMessage)(bing_search_chat)app.get("/local_doc_qa/list_knowledge_base", response_model=ListDocsResponse)(list_kbs)app.get("/local_doc_qa/list_files", response_model=ListDocsResponse)(list_docs)app.delete("/local_doc_qa/delete_knowledge_base", response_model=BaseResponse)(delete_kb)app.delete("/local_doc_qa/delete_file", response_model=BaseResponse)(delete_doc)app.post("/local_doc_qa/update_file", response_model=BaseResponse)(update_doc)local_doc_qa = LocalDocQA()local_doc_qa.init_cfg(llm_model=llm_model_ins,embedding_model=EMBEDDING_MODEL,embedding_device=EMBEDDING_DEVICE,top_k=VECTOR_SEARCH_TOP_K,)uvicorn.run(app, host=host, port=port)if __name__ == "__main__":parser.add_argument("--host", type=str, default="0.0.0.0")parser.add_argument("--port", type=int, default=7861)# 初始化消息args = Noneargs = parser.parse_args()args_dict = vars(args)shared.loaderCheckPoint = LoaderCheckPoint(args_dict)api_start(args.host, args.port)我们可以在api_start方法中看到服务器程序开放了以下的API:
1 upload_file 上传一个文件
2 upload_files 上传多个文件
3 local_doc_chat 基于本地知识库进行对话
4 bing_search_chat 基于bing搜索进行对话
5 list_knowledge_base 列出所有的知识库
6 list_files 列出一个知识库下面所有文件
7 delete_knowledge_base 删除一个知识库
8 delete_file 删除某一个知识库下面一个文件
9 update_file 将某一知识库里一个文件替换为另一个问题
另外,在文件最上方定义了三种服务器返回的消息类型BaseResponse,ListDocsResponse,ChatMessage。在api_start方法中可以找到每一个API对于的返回消息类型。各个消息均为json文件
基于以上内容,我对除了bing_search_chat之外所有的API编写了对应的客户端。使用python的requests类发送HTTP请求并获取回应。下面是完整代码:
import requestsAPI_BASE_URL = "http://localhost:7861" # the server's url
API_KB_URL = API_BASE_URL + "/local_doc_qa" # the url for knowledge base answer# upload local file for knowledge base
def upload_file(knowledge_base_id, file_path):with open(file_path, "rb") as file:files = {"file": file}data = {"knowledge_base_id": knowledge_base_id}try:response = requests.post(API_KB_URL + "/upload_file", data=data, files=files)response.raise_for_status()#print(f"File '{file_path}' uploaded successfully to knowledge base '{knowledge_base_id}'.")print_msg(response)except requests.exceptions.RequestException as e:print(f"Failed to upload '{file_path}' knowledge base: {e}")# upload multiple files for knowledge base
def upload_files(knowledge_base_id, file_paths):files = [(f"files", open(file_path, "rb")) for file_path in file_paths]data = {"knowledge_base_id": knowledge_base_id}try:response = requests.post(API_KB_URL + "/upload_files", data=data, files=files)response.raise_for_status()#print(f"File '{file_paths}' uploaded successfully to knowledge base '{knowledge_base_id}'.")print_msg(response)except requests.exceptions.RequestException as e:print(f"Failed to upload '{file_paths}' knowledge base: {e}")# replace an existing file with another one
def update_file(knowledge_base_id, old_file, new_file):files = {"new_doc": open(new_file, "rb")}params = {"knowledge_base_id": knowledge_base_id, "old_doc": old_file}try:response = requests.post(API_KB_URL + "/update_file", params=params, files=files)response.raise_for_status()#print(f"Replace '{old_file}' with '{new_file}' in knowledge base '{knowledge_base_id}'")print_msg(response)except requests.exceptions.RequestException as e:print(f"Fail to update file {new_file} to knowledge base")# chat with chatglm
def chat_with_llm(question, knowledge_base_id=None, history=None):# use chat with knowledge base (if knowledge base is available), or chat with LLMurl = API_KB_URL + "/local_doc_chat" if knowledge_base_id else API_BASE_URL + "/chat"data = {"question": question,"history": history or [],}if knowledge_base_id:data["knowledge_base_id"] = knowledge_base_idtry:# send request to LLMresponse = requests.post(url, json=data)response.raise_for_status()chat_response = response.json()print("LLM Response:", chat_response.get("response"))print("Reference:", chat_response.get("source_documents"))return chat_responseexcept requests.exceptions.RequestException as e:print(f"Error while chatting with LLM: {e}")return None# list knowledge bases
def list_kbs():try:response = requests.get(API_KB_URL + "/list_knowledge_base")response.raise_for_status()kbs = response.json()print("List of Knowledge Bases:")for kb in kbs.get("data"):print(kb)return kbsexcept requests.exceptions.RequestException as e:print(f"Error while listing knowledge bases: {e}")return None# list documents in a knowledge base
def list_files(knowledge_base_id):try:response = requests.get(API_KB_URL + "/list_files", params={"knowledge_base_id":knowledge_base_id})response.raise_for_status()docs = response.json()print(f"List of Documents in Knowledge Base '{knowledge_base_id}':")for doc in docs.get("data"):print(doc)return docsexcept requests.exceptions.RequestException as e:print(f"Error while listing documents: {e}")return None# delete a knowledge base
def delete_knowledge_base(knowledge_base_id):param = {"knowledge_base_id": knowledge_base_id}try:response = requests.delete(API_KB_URL + "/delete_knowledge_base", params=param)response.raise_for_status()print_msg(response)except requests.exceptions.RequestException as e:print(f"Error while deleting knowledge base: {e}")# delete a single file from a selected knowledge base
def delete_file(knowledge_base_id, file_path):params = {"knowledge_base_id": knowledge_base_id,"doc_name": file_path}try:response = requests.delete(API_KB_URL + "/delete_file", params=params)response.raise_for_status()print_msg(response)except requests.exceptions.RequestException as e:print(f"Failed to delete file: {e}")# print the status information returned by the server (for base and listdoc response only)
def print_msg(response):print(response.json().get("msg"))程序说明:
1
def print_msg(response):print(response.json().get("msg"))
该方法用于打出服务器回复信息中msg部分
2
API_BASE_URL = "http://localhost:7861" # the server's url
API_KB_URL = API_BASE_URL + "/local_doc_qa" # the url for knowledge base answer这里本地服务器默认的url为http://localhost:7861(可以在服务器配置文件中看到),所有和知识库相关的API的endpoint均为/local_doc_qa/(API名称),而不使用知识库直接和模型对话的时候endpoint直接为/chat
3
程序主体内容就是对各个API客户端方法的实现。其实现原理都差不多,均为传入参数并封装为json文件,然后在服务器请求的参数中将json文件传入服务器,再等待服务器的回复。其中要注意的是upload_file, upload_files, local_doc_chat, chat, update_file使用POST指令。list_knowledge_base,list_files使用GET指令。delete_knowledge_base和delete_file使用DELETE指令
在程序完成后,我对各个指令的实现进行测试
1 测试使用的数据
为了测试模型是否可以参考知识库内容进行回答,我找了3篇关于番茄种植的文段,并提出了一个需要结合三篇文段内容的知识型问题
文段
文本1:种植番茄的方法
番茄是家庭菜园中广受欢迎的水果(没错,它们是水果!),因其多功能和美味而备受喜爱。要成功种植番茄,请按照以下步骤进行:选择合适的位置:番茄需要每天至少6-8小时的直接阳光。在花园中选一个能充分接受阳光的地方。
准备土壤:番茄喜欢排水良好、富含有机物质的土壤。在种植前,将堆肥或腐熟的粪肥混入土壤中,以改善其肥力。
种植:在您所在地区的最后霜日期后种植番茄苗。挖一个略深于苗木根系的洞,将苗木放入洞中,用土填充并轻轻压实。
浇水:在种植后立即给新种植的苗木浇水。一旦苗木生根,要定期浇水,每周浇水量约为1-1.5英寸。
支撑:番茄是藤本植物,需要支撑才能向上生长。用桩或笼子支撑植物,防止其蔓延在地面上。
修剪:定期修剪掉主干和侧枝之间生长的小枝,以便将能量集中在结果上。
施肥:在种植后几周,以及出现第一批果实时,施用均衡肥料。
文本2:常见的番茄害虫和疾病 种植番茄虽然令人满足,但也可能面临与害虫和疾病有关的挑战。您可能会遇到以下一些常见问题:
蚜虫:这些微小的昆虫会吸取植物的汁液,导致植物生长受阻,叶子变形。
枯萎病:早疫病和晚疫病都可能影响番茄,导致叶子和果实上出现黑斑,最终导致植物死亡。
烟粉虱:这些小型飞虫会吸食植物汁液并排泄粘性的蜜露,吸引霉菌并导致叶片发黄。
枯萎蔓枝菌:这是一种土壤传播的真菌,会导致植株下部叶片枯萎和发黄,最终导致植株死亡。
大黄螟:这些大型的绿色毛虫如果不加以控制,可能会迅速让番茄植株叶片凋萎。
文本3:值得一试的番茄品种 番茄有各种不同的形状、大小和颜色,每种都有独特的口味和用途。考虑种植这些受欢迎的番茄品种:
罗马番茄:由于其肉质的质地和较少的种子,非常适合制作酱汁和罐装食品。
小番茄:小巧、甜美,非常适合作为零食,用于沙拉或装饰菜肴。
牛腿番茄:个头大而多汁,非常适合制作三明治和切片。
传统品种:这些是口味和外观独特的老品种,通常代代相传。
葡萄番茄:椭圆形且甜美,非常适合用于沙拉和烤制。
绿色斑纹番茄:一种味道略带酸味的绿色条纹番茄,非常适合用于沙拉和莎莎酱。
问题:如何防止番茄植株蔓延在地面上,枯萎蔓枝菌的常见症状是什么,以及哪种番茄品种最适合制作酱汁和罐装食品?
2 启动测试
先开启一个终端,运行langchain-ChatGLM项目下面的api.py程序,启动服务器
python api.py
单纯为了测试,我这里直接把要调用的API写到客户端程序的主方法里,然后运行客户端。在客户端终端就可以看到程序打印出的回复
在使用upload_file上传单个文件,upload_files上传多个文件,list_knowledge_base列出知识库,list_files列出知识库内文件,和chat_with_llm和模型对话这几项都成功。模型也可以结合知识库内容回答并给出对应索引位置
但是在使用所有和删除相关的方法时(包括delete_knowledge_base delete_file update_file),会出现以下问题:
1 有些时候即使删除了某个文件,模型依然会引用已删除的文件。我一开始以为是历史对话造成的结果,但是在重启模型后该问题依然出现。
在知识库本地储存的位置中,知识库content文件夹(储存文本的文件夹)下要删除的文件的确消失了,但是有可能该文件对应的向量库并没有成功被移除。(根据api.py文件里内容在向量库里移除文件的方法应该是local_doc_qa.delete_file_from_vector_store,但是我目前还没有深入去研究local_doc_qa里的内容)
我也尝试了在删除文件时同时删除该文件夹下面的vector_store文件夹shutil.rmtree(get_vs_path(knowledge_base_id, doc_name))
这么做会导致LLM的知识库引用直接为空。向量库只有一个文件,应该包含了该知识库所有文件转化的向量,所有没法从中删除单个文件内容
2 在删除文件后进行提问会出现以下报错
INFO: 127.0.0.1:56826 - “POST /local_doc_qa/local_doc_chat HTTP/1.1” 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File “/home/pai/lib/python3.9/site-packages/uvicorn/protocols/http/h11_impl.py”, line 429, in run_asgi
result = await app( # type: ignore[func-returns-value]
File “/home/pai/lib/python3.9/site-packages/uvicorn/middleware/proxy_headers.py”, line 78, in call
return await self.app(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/fastapi/applications.py”, line 276, in call
await super().call(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/applications.py”, line 122, in call
await self.middleware_stack(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/errors.py”, line 184, in call
raise exc
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/errors.py”, line 162, in call
await self.app(scope, receive, _send)
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/exceptions.py”, line 79, in call
raise exc
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/exceptions.py”, line 68, in call
await self.app(scope, receive, sender)
File “/home/pai/lib/python3.9/site-packages/fastapi/middleware/asyncexitstack.py”, line 21, in call
raise e
File “/home/pai/lib/python3.9/site-packages/fastapi/middleware/asyncexitstack.py”, line 18, in call
await self.app(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/routing.py”, line 718, in call
await route.handle(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/routing.py”, line 276, in handle
await self.app(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/routing.py”, line 66, in app
response = await func(request)
File “/home/pai/lib/python3.9/site-packages/fastapi/routing.py”, line 237, in app
raw_response = await run_endpoint_function(
File “/home/pai/lib/python3.9/site-packages/fastapi/routing.py”, line 163, in run_endpoint_function
return await dependant.call(**values)
File “/mnt/workspace/langchain-ChatGLM/api.py”, line 293, in local_doc_chat
for resp, history in local_doc_qa.get_knowledge_based_answer(
File “/mnt/workspace/langchain-ChatGLM/chains/local_doc_qa.py”, line 231, in get_knowledge_based_answer
related_docs_with_score = vector_store.similarity_search_with_score(query, k=self.top_k)
File “/home/pai/lib/python3.9/site-packages/langchain/vectorstores/faiss.py”, line 221, in similarity_search_with_score
docs = self.similarity_search_with_score_by_vector(embedding, k)
File “/mnt/workspace/langchain-ChatGLM/vectorstores/MyFAISS.py”, line 86, in similarity_search_with_score_by_vector
_id0 = self.index_to_docstore_id[l]
KeyError: 23
INFO: 127.0.0.1:57038 - “GET /local_doc_qa/list_knowledge_base HTTP/1.1” 200 OK
INFO: 127.0.0.1:57042 - “GET /local_doc_qa/list_files?knowledge_base_id=pizza HTTP/1.1” 200 OK
INFO: 127.0.0.1:57046 - “POST /local_doc_qa/local_doc_chat HTTP/1.1” 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File “/home/pai/lib/python3.9/site-packages/uvicorn/protocols/http/h11_impl.py”, line 429, in run_asgi
result = await app( # type: ignore[func-returns-value]
File “/home/pai/lib/python3.9/site-packages/uvicorn/middleware/proxy_headers.py”, line 78, in call
return await self.app(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/fastapi/applications.py”, line 276, in call
await super().call(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/applications.py”, line 122, in call
await self.middleware_stack(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/errors.py”, line 184, in call
raise exc
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/errors.py”, line 162, in call
await self.app(scope, receive, _send)
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/exceptions.py”, line 79, in call
raise exc
File “/home/pai/lib/python3.9/site-packages/starlette/middleware/exceptions.py”, line 68, in call
await self.app(scope, receive, sender)
File “/home/pai/lib/python3.9/site-packages/fastapi/middleware/asyncexitstack.py”, line 21, in call
raise e
File “/home/pai/lib/python3.9/site-packages/fastapi/middleware/asyncexitstack.py”, line 18, in call
await self.app(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/routing.py”, line 718, in call
await route.handle(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/routing.py”, line 276, in handle
await self.app(scope, receive, send)
File “/home/pai/lib/python3.9/site-packages/starlette/routing.py”, line 66, in app
response = await func(request)
File “/home/pai/lib/python3.9/site-packages/fastapi/routing.py”, line 237, in app
raw_response = await run_endpoint_function(
File “/home/pai/lib/python3.9/site-packages/fastapi/routing.py”, line 163, in run_endpoint_function
return await dependant.call(**values)
File “/mnt/workspace/langchain-ChatGLM/api.py”, line 293, in local_doc_chat
for resp, history in local_doc_qa.get_knowledge_based_answer(
File “/mnt/workspace/langchain-ChatGLM/chains/local_doc_qa.py”, line 231, in get_knowledge_based_answer
related_docs_with_score = vector_store.similarity_search_with_score(query, k=self.top_k)
File “/home/pai/lib/python3.9/site-packages/langchain/vectorstores/faiss.py”, line 221, in similarity_search_with_score
docs = self.similarity_search_with_score_by_vector(embedding, k)
File “/mnt/workspace/langchain-ChatGLM/vectorstores/MyFAISS.py”, line 86, in similarity_search_with_score_by_vector
_id0 = self.index_to_docstore_id[l]
KeyError: 23
这段报错信息似乎说明各个文件的文本向量库是以字典形式储存的。在删除一个文件后某一个key对应的value缺失导致报错。由这一点基本上可以说明langchain-ChatGLM官方给出的api.py关于删除知识库文件的部分是有bug的。我尝试了对api.py进行修改,但目前还没有成功。
3 LLM只采用知识库中一个文件的内容。在我使用种植番茄的例子之前我使用的是一个做披萨的例子,传入了3个披萨配方然后问模型“怎么做披萨”.模型自始至终只会基于第一个配方回答,但是在引用文段中包括了其他两个配方的内容。最后发现可能的问题是第一个配方中每一条内容之间都有空格换行,而其他两个配方内容是连在一起的。有可能embedding模型在对文本分段过程中受到了格式的影响。因此在传入知识库文件时要尽量保持文件格式一致。
以上是我开发langchain-ChatGLM客户端的记录。如果大家谁发现了我提到这两个遗留问题的解决方法也请帮忙告诉我
相关文章:
)
实现langchain-ChatGLM API调用客户端(及未解决的问题)
langchain-ChatGLM是一个基于本地知识库的LLM对话库。其基于text2vec-large-Chinese为Embedding模型,ChatGLM-6B为对话大模型。原项目地址:https://github.com/chatchat-space/langchain-ChatGLM 对于如何本地部署ChatGLM模型,可以参考我之前…...

【AltWalker】模型驱动:轻松实现自动化测试用例的生成和组织执行
目录 模型驱动的自动化测试 优势 操作步骤 什么是AltWalker? 安装AltWalker 检查是否安装了正确的版本 牛刀小试 创建一个测试项目 运行测试 运行效果 在线模型编辑器 VScode扩展 本地部署 包含登录、选择产品、支付、退出登录的模型编写 模型效果 1…...

大数据课程E3——Flume的Sink
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Sink的HDFS Sink; ⚪ 掌握Sink的Logger Sink; ⚪ 掌握Sink的File Roll Sink; ⚪ 掌握Sink的Null Sink; ⚪ 掌握Sink的AVRO Sink; ⚪ 掌握Sink的Custom Sink; 一、HDFS Sink …...

如何快速做单元测试?
首先写unit test之前,要确认自己的测试遵循两个原则: 1、尽量不要干涉原来的代码。从阅读代码的体验来说,不要让你的测试(哪怕是一小段if..else...的代码)出现在你准备测试的代码中。 2、代码要只是测试某个class里面…...

不同对象的集合转换
https://blog.csdn.net/qq_42483473/article/details/128984514 import com.alibaba.fastjson.JSON;import java.util.ArrayList; import java.util.List;/*** author */ public class ObjectConversion {/*** 从List<A> copy到List<B>* param list List<B>…...
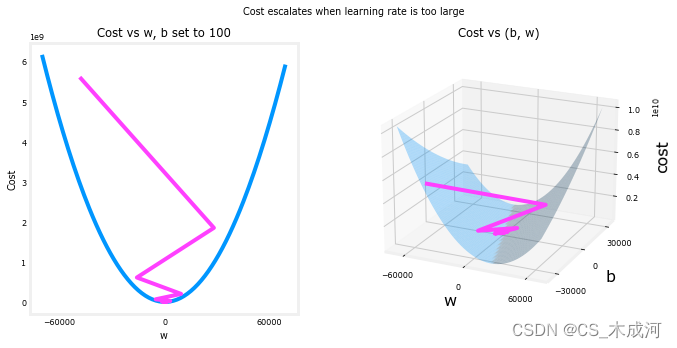
【机器学习】Gradient Descent
Gradient Descent for Linear Regression 1、梯度下降2、梯度下降算法的实现(1) 计算梯度(2) 梯度下降(3) 梯度下降的cost与迭代次数(4) 预测 3、绘图4、学习率 首先导入所需的库: import math, copy import numpy as np import matplotlib.pyplot as plt plt.styl…...

直播读弹幕机器人:直播弹幕采集+文字转语音(附完整代码)
目录 前言代码实现请求数据解析数据文字转语音完整代码 高级点的tk界面版 前言 直播读弹幕机器人是指能够实时读取直播平台上观众发送的弹幕,并将其转化为语音进行播放的机器人。这种机器人通常会使用文字转语音技术,将接收到的弹幕文本转为语音&#x…...

K3s vs K8s:轻量级对决 - 探索替代方案
在当今云原生应用的领域中,Kubernetes(简称K8s)已经成为了无可争议的领导者。然而,随着应用规模的不断增长,一些开发者和运维人员开始感受到了K8s的重量级特性所带来的挑战。为了解决这一问题,一个名为K3s的…...
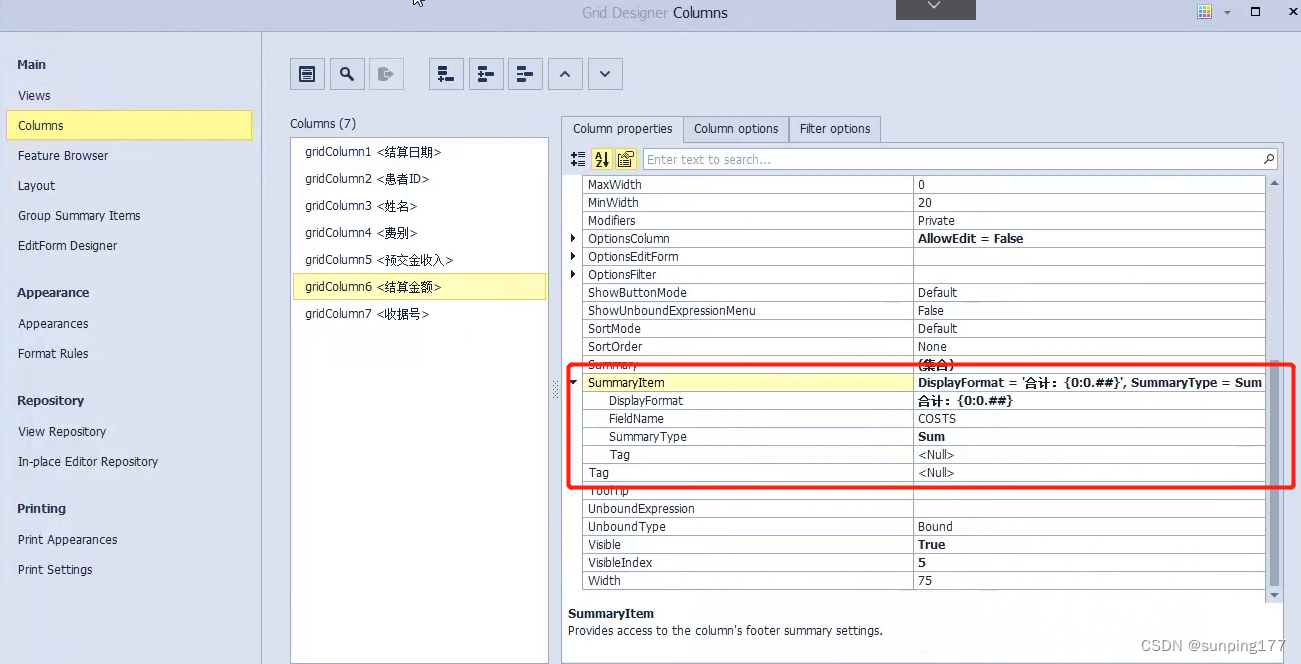
dev控件gridControl,gridview中添加合计
需求:在合并结账查询中,双击每一条结账出现这次结账对应的结算明细: 弹出的页面包括:结算日期,ID,姓名,费别,预交金收入,结算金额,收据号,合计&a…...

SpringBoot基础认识
创建SpringBoot模块 首先需要引设置maven并引用maven环境 1.打开项目结构,new module,选择Spring Initializr,URL选默认: group填写分组如com.kdy , Artifact起个模块名如springboot_quickstart,Type选择M…...
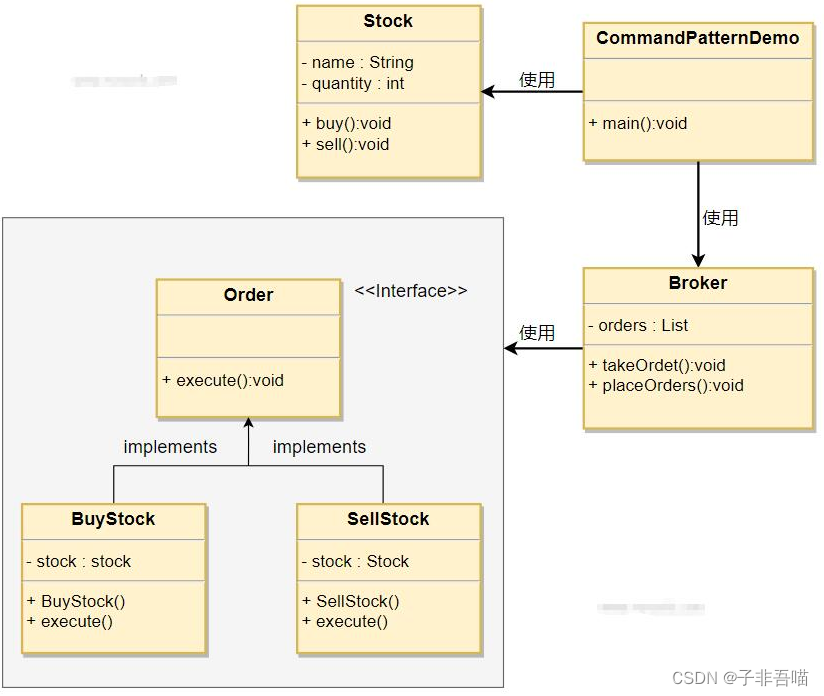
二十三种设计模式第十九篇--命令模式
命令模式是一种行为设计模式,它将请求封装成一个独立的对象,从而允许您以参数化的方式将客户端代码与具体实现解耦。在命令模式中,命令对象充当调用者和接收者之间的中介。这使您能够根据需要将请求排队、记录请求日志、撤销操作等。 命令模…...

STM32基础入门学习笔记:基础知识和理论 开发环境建立
文件目录: 一:基础知识和理论 1.ARM简介 2.STM32简介 3.STM32命名规范 4.STM32内部功能* 5.STM32接口定义 二:开发环境建立 1.开发板简介 2.ISP程序下载 3.最小系统电路 4.KEIL的安装 5.工程简介与调试流程 6.固件库的安装 7.编…...

Qt应用开发(基础篇)——数值微调输入框QAbstractSpinBox、QSpinBox、QDoubleSpinBox
目录 一、前言 二、QAbstractSpinBox类 1、accelerated 2、acceptableInput 3、alignment 4、buttonSymbols 5、correctionMode 6、frame 7、keyboardTracking 8、readOnly 9、showGroupSeparator 10、specialValueText 11、text 12、wrapping 13、信号 二、Q…...

html | 无js二级菜单
1. 效果图 2. 代码 <meta charset"utf-8"><style> .hiddentitle{display:none;}nav ul{list-style-type: none;background-color: #001f3f;overflow:hidden; /* 父标签加这个,防止有浮动子元素时,该标签失去高度*/margin: 0;padd…...
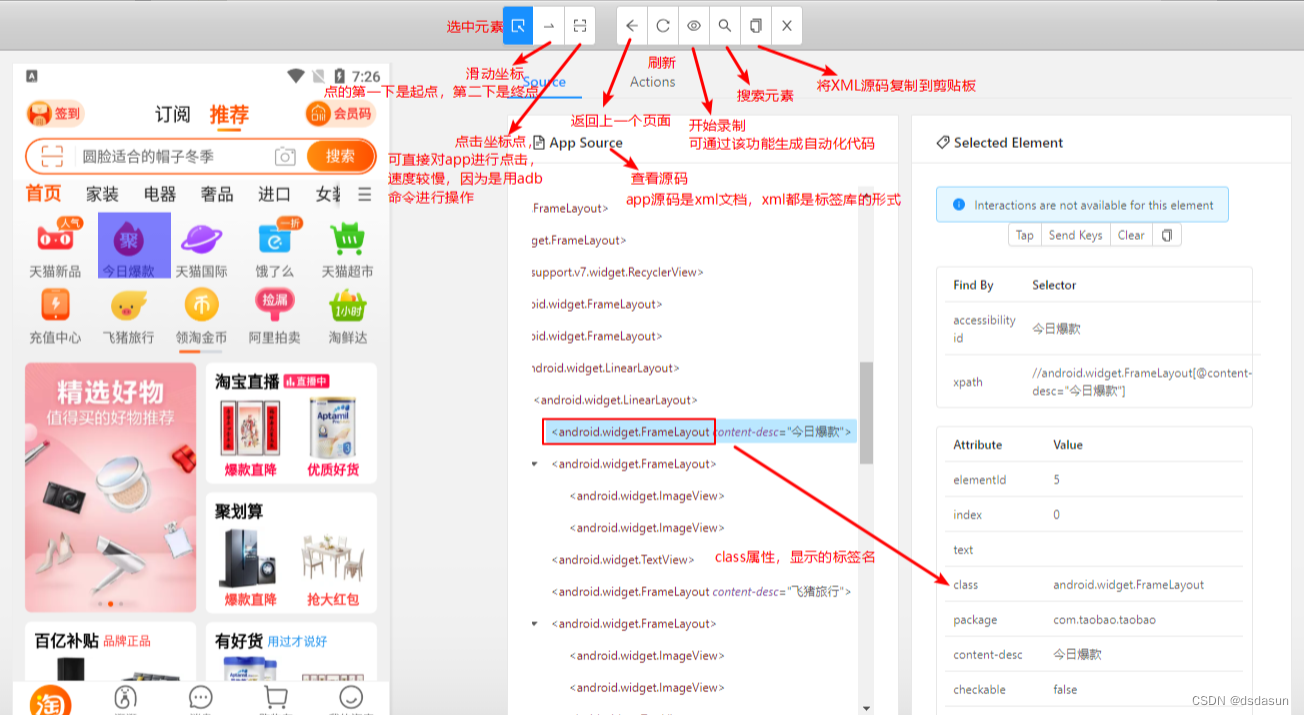
appium的基本使用
appium的基本使用 一、appium的基本使用appium环境安装1、安装Android SDK 2、安装Appium3、安装手机模拟器4、Pycharm安装 appium-python-alicent5、连接appium和模拟器6、Python代码调用appium软件,appium软件在通过adb命令调用android操作系统(模拟器…...
Dockerfile构建nginx镜像(编译安装)
Dockerfile构建nginx镜像 1、建立工作目录 [rootdocker ~]# mkdir nginx [rootdocker ~]# cd nginx/ 2、编写Dockerfile文件 [rootdocker nginx]# vim run.sh [rootdocker nginx]# vim Dockerfile #基于的基础镜像 FROM centos:7#镜像作者信息 MAINTAINER Crushlinux <…...

手机屏幕视窗机器视觉定位软硬件-康耐德
【检测目的】 手机屏幕视窗视觉定位 【效果图片】 【安装示意图】 【硬件配置】...

Databend 开源周报第 104 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 从 Kafka 载入数…...
用于医学图像分类的双引导的扩散网络
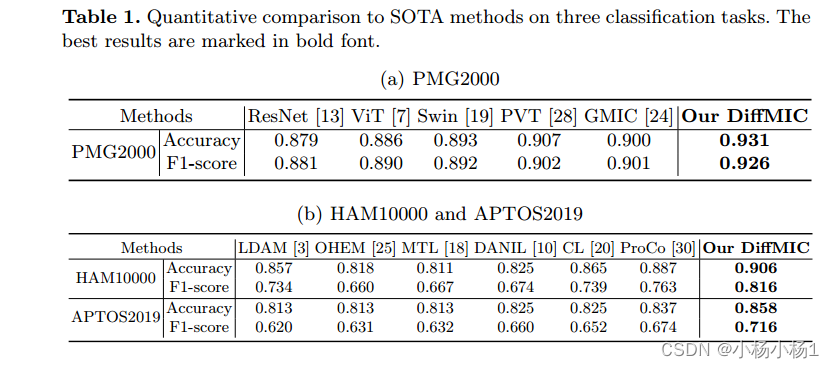
文章目录 DiffMIC: Dual-Guidance Diffusion Network for Medical Image Classification摘要本文方法实验结果 DiffMIC: Dual-Guidance Diffusion Network for Medical Image Classification 摘要 近年来,扩散概率模型在生成图像建模中表现出了显著的性能…...

8.2day03 Redis入门+解决员工模块
概述 在我们日常的Java Web开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景࿰…...

智能硬件适配引擎:92%成功率重构OpenCore EFI配置标准
智能硬件适配引擎:92%成功率重构OpenCore EFI配置标准 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在开源系统定制领域,硬件…...

3分钟搞定百度网盘提取码:新手也能快速上手的终极解决方案
3分钟搞定百度网盘提取码:新手也能快速上手的终极解决方案 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否经常遇到这样的烦恼:朋友分享的百度网盘链接明明就在眼前,却因为缺少那个关…...

5个简单步骤:用YimMenu在GTA V中打造安全游戏体验
5个简单步骤:用YimMenu在GTA V中打造安全游戏体验 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南
如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要行情而烦恼吗?想在工作时…...

如何快速自定义游戏光标:提升操作精度的完整指南
如何快速自定义游戏光标:提升操作精度的完整指南 【免费下载链接】YoloMouse Game Cursor Changer 项目地址: https://gitcode.com/gh_mirrors/yo/YoloMouse 在激烈的游戏战斗中,你是否经常因为找不到鼠标光标而错失良机?当屏幕特效绚…...
)
【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单)
更多请点击: https://kaifayun.com 第一章:【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单) 为验证当前主流AI图像生成模型…...

新手必看!OpenClaw 2.7.5 Windows 部署全流程
🦞 Windows 端 OpenClaw 完整部署实操教程 OpenClaw 一键安装包|可视化部署,简化环境配置流程✨适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版)✨核心优势:全程可视化操作&…...

Google I/O 2026 发布会大招不断,免费用户能体验哪些新功能?
Google I/O 2026 发布会大招频出,免费用户能体验哪些新功能?每年五月,硅谷山景城都会热闹一次。Google I/O 是谷歌一年一度的开发者大会,但这些年它早就不只是给开发者看的了,普通用户、科技媒体、竞争对手,…...

专科英语A级和B级考试历年真题试卷及答案PDF电子版
高等学校英语应用能力考试(PRETCO)A 级、B 级历年真题试卷及答案 PDF 电子版,专为高职高专、大专在校生备考整理。内容涵盖2022年、2023年、2024年、2025年 6 月、12 月全套真题,含听力原文、答案解析、写作范文,题型覆…...

英雄联盟Akari助手:一键智能配置,释放你的游戏潜能 [特殊字符]
英雄联盟Akari助手:一键智能配置,释放你的游戏潜能 🚀 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在…...