PyTorch代码实战入门
人这辈子千万不要马虎两件事
一是找对爱人、二是选对事业
因为太阳升起时要投身事业
太阳落山时要与爱人相拥
一、准备数据集
蚂蚁蜜蜂数据集
蚂蚁蜜蜂的图片,文件名就是数据的label

二、使用Dataset加载数据
打开pycharm,选择Anaconda创建的pytorch环境
将数据集放在项目的根目录下,并修改文件名

新建 read_data.py文件,编写如下代码
from torch.utils.data import Dataset
from PIL import Image
import osclass MyData(Dataset):# 获取训练数据的listdef __init__(self, root_dir, label_dir):self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir, self.label_dir)self.img_path = os.listdir(self.path)# 获取每一张图片及其labeldef __getitem__(self, idx):img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)img = Image.open(img_item_path)label = self.label_dirreturn img, labeldef __len__(self):return len(self.img_path)root_dir = "dataset/train"
ant_label_dir = "ants"
bee_label_dir = "bees"
ants_dataset = MyData(root_dir, ant_label_dir)
bees_dataset = MyData(root_dir, bee_label_dir)train_dataset = ants_dataset + bees_dataset解释:
1. MyData继承Dataset类
2. 重写里面的__init__方法,在MyData类初始化时,通过拼接数据路径,os.listdir()加载出数据的list列表
3. 重写里面的__getitem__方法,将一张一张地将list的图片和对应的label加载出来
4.train_dataset = ants_dataset + bees_dataset,得到训练数据集
三、TensorBoard的使用
安装TensorBoard需要的包
pip install tensorboard
编写如下代码:
from torch.utils.tensorboard import SummaryWriter# 指定log文件生成的位置
writer = SummaryWriter("logs")for i in range(100):'''第一个参数:图像的title第二个参数:纵坐标的值 第三个参数:横坐标的值'''writer.add_scalar("y=3x", 3 * i, i)# 关闭资源
writer.close()
运行代码,会在SummaryWriter指定的位置生成log文件

在Terminal运行下面语句:
可以自己指定端口,防止冲突
tensorboard --logdir=logs --port=6007
运行输出
 在浏览器打开
在浏览器打开

使用 writer.add_image 加载图片
编写下面代码:
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np# 指定log文件生成的位置
writer = SummaryWriter("logs")image_path = "dataset/train/ants/7759525_1363d24e88.jpg"
image_PIL = Image.open(image_path)
image_array = np.array(image_PIL)'''
第一个参数:图像的title
第二个参数:图片的numpy值
第三个参数:步数
第四个参数:将图片进行转换,3通道放在前面
'''
writer.add_image("test", image_array, 1, dataformats='HWC')for i in range(100):'''第一个参数:图像的title第二个参数:纵坐标的值 第三个参数:横坐标的值'''writer.add_scalar("y=3x", 3 * i, i)# 关闭资源
writer.close()
同样在控制台打开运行生成的日志文件

四、Transforms的使用
图片转换工具
ToTensor() 把 PIL格式或者numpy格式转换成tensor
编写如下代码:
from PIL import Image
from torchvision import transformsimg_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path)# 使用transforms
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)print(tensor_img)输出:
tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980],[0.3176, 0.3176, 0.3176, ..., 0.3176, 0.3098, 0.2980],[0.3216, 0.3216, 0.3216, ..., 0.3137, 0.3098, 0.3020],...,[0.3412, 0.3412, 0.3373, ..., 0.1725, 0.3725, 0.3529],[0.3412, 0.3412, 0.3373, ..., 0.3294, 0.3529, 0.3294],[0.3412, 0.3412, 0.3373, ..., 0.3098, 0.3059, 0.3294]],[[0.5922, 0.5922, 0.5922, ..., 0.5961, 0.5882, 0.5765],[0.5961, 0.5961, 0.5961, ..., 0.5961, 0.5882, 0.5765],[0.6000, 0.6000, 0.6000, ..., 0.5922, 0.5882, 0.5804],...,[0.6275, 0.6275, 0.6235, ..., 0.3608, 0.6196, 0.6157],[0.6275, 0.6275, 0.6235, ..., 0.5765, 0.6275, 0.5961],[0.6275, 0.6275, 0.6235, ..., 0.6275, 0.6235, 0.6314]],[[0.9137, 0.9137, 0.9137, ..., 0.9176, 0.9098, 0.8980],[0.9176, 0.9176, 0.9176, ..., 0.9176, 0.9098, 0.8980],[0.9216, 0.9216, 0.9216, ..., 0.9137, 0.9098, 0.9020],...,[0.9294, 0.9294, 0.9255, ..., 0.5529, 0.9216, 0.8941],[0.9294, 0.9294, 0.9255, ..., 0.8863, 1.0000, 0.9137],[0.9294, 0.9294, 0.9255, ..., 0.9490, 0.9804, 0.9137]]])常见的Transforms
在机器学习和深度学习中,数据转换(Transforms)是一种常见的操作,用于对数据进行预处理、增强或标准化。下面是一些常见的数据转换操作:
1. 数据标准化(Normalization):将数据按比例缩放,使其落在特定的范围内,通常是将数据映射到0到1之间或者使用均值为0、方差为1的分布(更快收敛)。这可以通过以下方法实现:
- Min - Max标准化:将数据缩放到指定的最小值和最大值之间。
- Z-Score标准化:将数据转化为均值为0、标准差为1的分布。
2. 数据增强(Data Augmentation):用于扩充训练数据集,增强样本的多样性,提高模型的泛华能力。常见的数据增强操作包括:
- 随机裁剪(Random Crop):随机裁剪图像的一部分,以减少位置的依赖性。
- 随机翻转(Random Filp):随机水平或垂直翻转图像,增加数据的多样性。
- 随机旋转(Random Rotation):随机旋转图像的角度,增加数据的多样性。
3. 图像预处理:用于对图像进行预处理,以减少噪声、增强特征或改变图像的外观。一些常见的图像预处理操作包括:
- 图像平滑(Image Smoothing):使用滤波器对图像进行平滑处理,减少噪声。
- 直方图均衡化(Histogram Equalization):增强图像的对比度,使得图像中的像素值更加均匀分布。
- 图像缩放(Image Resizing):改变图像的尺寸,通常用于将图像调整为模型输入的大小。
4. 文本预处理:用于对文本数据进行预处理和清洗,以便更好地适应模型的输入要求。一些常见的文本预处理操作包括:
- 分词(Tokenization):将文本分割成单个的词或字符。
- 去除停用词(Stopword Removal):去除常见的无意义词语,如“a”,“the”等。
- 文本向量化(Text Vectorzation):将文本转换为数值形式,如使用词袋模型或词嵌入。
以上只是一些常见的数据转换操作示例,实际应用中可能会根据任务和数据的特点进行适当的调整和组合。在使用转换操作时,可以使用各种机器学习框架(如PyTorch、TensorFlow)提供的相关库或函数来实现这些操作。
示例代码如下:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsimg_path = "hymenoptera_data/16.jpg"
img = Image.open(img_path)writer = SummaryWriter("logs")# totensor使用
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("lyy", tensor_img)# Normalize 使用
trans_norm = transforms.Normalize([111,111,111],[10,10,10])
img_norm = trans_norm(tensor_img)
writer.add_image("normalize", img_norm, 2)# resize
trans_resize = transforms.Resize( (512, 512))
img_resize = trans_resize(img) # 输入的是Image类型的图像
img_resize_tensor = transforms.ToTensor()tensor_img = tensor_trans(img_resize)
writer.add_image("resize", tensor_img, 0)# compose 用法
trans_resize_2 =transforms.Resize(123)
trans_compose = transforms.Compose([trans_resize_2, tensor_trans])
img_resize_2 = trans_compose(img)
writer.add_image("resize2", img_resize_2,1)# randomCrop
trans_random = transforms.RandomCrop((20,50))
trans_compose_2 = transforms.Compose([trans_random, tensor_trans])
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("randomCrop", img_crop, i)writer.close()print("end")
五、torchvision中数据集使用
pytorch提供了很多的数据集,提供给我们学习使用。
进入官网

选择Dataset数据集

下面就是常用的数据集

CIFAR10数据集使用示例:

代码示例:
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transfrom = torchvision.transforms.Compose([torchvision.transforms.ToTensor])train_set = torchvision.datasets.CIFAR10(root="./cifar10", train=True, transform=dataset_transfrom, download=True)
test_set = torchvision.datasets.CIFAR10(root="./cifar10", train=False, transform=dataset_transfrom, download=True)writer = SummaryWriter("test_torchvision")
for i in range(10):img, target = test_set[i]writer.add_image("test_torchvision", img, i)writer.close()提示:这样下载数据集很慢,可以使用迅雷下载, ctrl + CIFAR10 进入类里面,里面有下载地址,如下:

把下载好的数据集压缩包,放在指定路径下即可。

然后再tensorboard面板就能看到下载的数据集

六、DataLoader使用
Dataset是整理好的数据集
DataLoader是把这个数据集加载到神经网络中去训练
使用示例:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWritertest_data = torchvision.datasets.CIFAR10("./cifar10", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)writer = SummaryWriter("dataloader")step = 0
for data in test_loader:imgs, targets = datawriter.add_images("dataloader", imgs, step)step = step + 1writer.close()解释:
通过创建 test_loader,您可以使用 for 循环迭代它来逐批获取测试数据
dataset: 指定要加载的数据集test_data。batch_size: 指定每个批次中的样本数量。在这里,每个批次中有64个样本。shuffle: 指定是否对数据进行洗牌(随机重排)。如果设置为True,每个 epoch(训练周期)开始时,数据将被随机打乱顺序。这对于增加数据的随机性、减少模型对输入顺序的依赖性很有用。num_workers: 指定用于数据加载的子进程数量。在这里,设置为0表示在主进程中加载数据,没有额外的子进程参与。如果设置为大于0的值,将使用多个子进程并行加载数据,可以加快数据加载速度。drop_last: 指定当数据样本数量不能被batch_size整除时,是否丢弃最后一个不完整的批次。如果设置为True,最后一个不完整的批次将被丢弃;如果设置为False,最后一个不完整的批次将保留。
运行之后在tensorboard面板查看

相关文章:
PyTorch代码实战入门
人这辈子千万不要马虎两件事 一是找对爱人、二是选对事业 因为太阳升起时要投身事业 太阳落山时要与爱人相拥 一、准备数据集 蚂蚁蜜蜂数据集 蚂蚁蜜蜂的图片,文件名就是数据的label 二、使用Dataset加载数据 打开pycharm,选择Anaconda创建的pytorch环…...
TSINGSEE青犀视频汇聚平台EasyCVR多种视频流播放协议介绍
众所周知,TSINGSEE青犀视频汇聚平台EasyCVR可支持多协议方式接入,包括主流标准协议GB28181、RTSP/Onvif、RTMP等,以及厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。今天我们来说一说,EasyCVR平台支持分…...
Vivado进行自定义IP封装
一. 简介 本篇文章将介绍如何使用Vivado来对上篇文章(FPGA驱动SPI屏幕)中的代码进行一个IP封装,Vivado自带的IP核应该都使用过,非常方便。 这里将其封装成IP核的目的主要是为了后续项目的调用,否则当我新建一个项目的时候,我需要将…...

开放自动化软件的硬件平台
自动化行业的产品主要以嵌入式系统为主,历来对产品硬件的可靠性和性能都提出很高的要求。最典型的产品要数PLC。PLC 要求满足体积小,实时性,可靠性,可扩展性强,环境要求高等特点。它们通常采用工业级高性能嵌入式SoC 实…...
AdvancedInstaller打包程序
文章目录 1. AdvancedInstaller 下载2. AdvancedInstaller 启动3. 新建工程4. 配置安装包详细信息5. 配置安装参数6. 添加要打包的文件7. 设置安装完成后启动程序8. 构建打包 1. AdvancedInstaller 下载 下载网址:https://www.advancedinstaller.com/ 2. AdvancedIn…...

无穷限积分习题
前置知识:无穷限积分 习题1 计算 ∫ 1 ∞ ln x x 2 d x \int_1^{\infty}\dfrac{\ln x}{x^2}dx ∫1∞x2lnxdx 解: \qquad 原式 ( − ln x x ) ∣ 1 ∞ ∫ 1 ∞ 1 x 2 d x ( − ln x x ) ∣ 1 ∞ ( − 1 x ) ∣ 1 ∞ (-\dfrac{\…...

AI 3D结构光技术加持,小米引领智能门锁新标准
一直以来,小米智能门锁系列产品让更多家庭走进了安全便捷的智能生活,安全至上的设计让很多家庭都轻松告别了随身钥匙。 7月27日,小米正式推出小米智能门锁M20 Pro,再一次引领智能门锁产品的发展潮流。该款门锁采用AI 3D结构光技术…...

管理类联考——逻辑——形式逻辑——汇总篇
简述 形式逻辑: 识别题型:逻辑符号表达及标志词:联假言符号化特殊命题“除非否则”;五大关系:矛盾、等价、包含、至少有一真、至少有一假;【通过“关系”,串联起“假联选”言】 识别题型&…...

架构的分类
目录 一、 RUP41 架构 1.1 RUP41架构方法概述 1.2 RUP41架构总体 1.3 RUP41架构方法内容 1.3.1 逻辑视图 1.3.2 开发视图 1.3.3 物理视图 1.3.4 处理视图 1.3.5 场景视图 二、 TOGAF9 架构 2.1 TOGAF9 架构概述 2.2 TOGAF9 架构分类 2.2.1 业务架构 2.2.2 数据架…...

[SQL挖掘机] - 窗口函数 - lag
介绍: lag() 是一种常用的窗口函数,它用于获取某一行之前的行的值。它可以用来在结果集中的当前行之前访问指定列的值。 用法: lag() 函数的语法如下: lag(列名, 偏移量, 默认值) over (partition by 列名1, 列名2, ... order by 列名 [asc|desc], .…...

springboot项目如何自动重启(使用Devtools检测修改并自动重启springboot)
1. 问题: 我们在项目开发阶段,可能经常会修改代码,修改完后就要重启Spring Boot。经常手动停止再启动,比较麻烦。 所以我们引入一个Spring Boot提供的开发工具; 只要源码或配置文件发生修改,Spring Boot应用…...
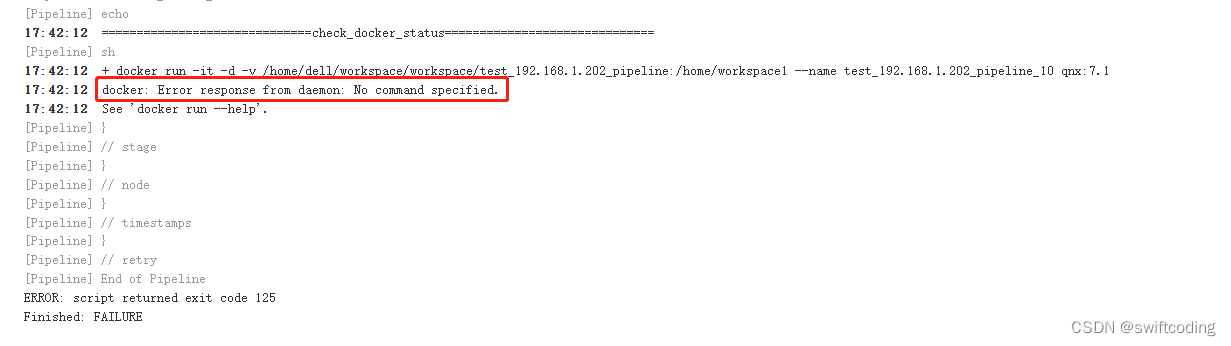
docker: Error response from daemon: No command specified.
执行 docker run -it -d -v /home/dell/workspace/workspace/test_192.168.1.202_pipeline:/home/workspace1 --name test_192.168.1.202_pipeline_10 qnx:7.1报错 问题定位:export导入的镜像需要带上command,以下命令查看command信息 docker ps --no…...

百度地图点标记加调用
先看效果 PHP代码 <?phpnamespace kds_addons\edata\controller;use think\addons\Controller; use think\Db;class Maps extends Controller {// 经纬度计算面积function calculate_area($points){$totalArea 0;$numPoints count($points);if ($numPoints > 2) {f…...
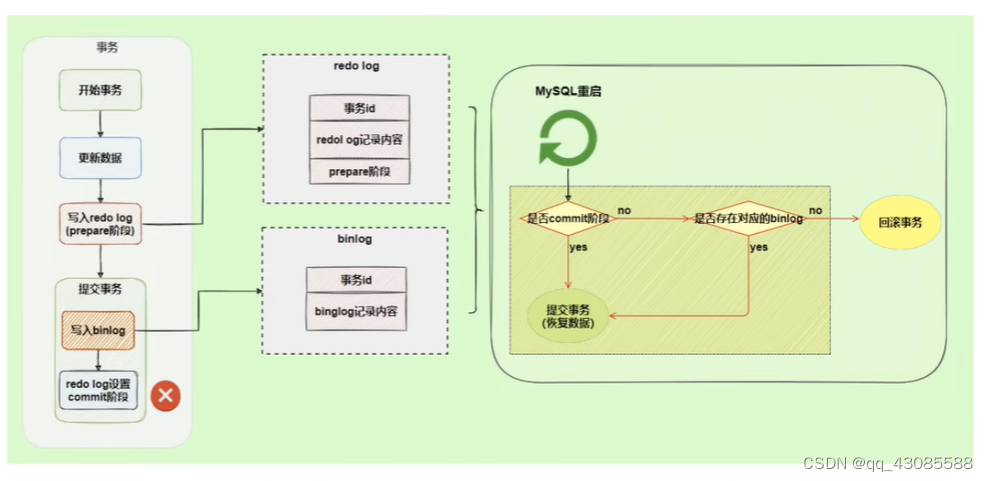
MySQL 其他数据库日志
我们了解数据库事务时,知道两种日志:重做日志,回滚日志。 对于线上数据库应用系统,突然遭遇 数据库宕机 怎么办?在这种情况下,定位宕机的原因 就非常关键。我们可以查看数据库的 错误日志。因为日志中记录…...

为何企业和开发团队应该重视进行兼容性测试
随着科技的不断进步和软件的广泛应用,保证软件在不同平台和环境下正常运行变得至关重要。本文将探讨软件兼容性测试的重要性和好处,并介绍为何企业和开发团队应该重视进行兼容性测试,以确保软件的稳定性和用户体验。 提供用户友好的体验 软件…...

牛客网Verilog刷题——VL51
牛客网Verilog刷题——VL51 题目答案 题目 请编写一个十六进制计数器模块,计数器输出信号递增每次到达0,给出指示信号zero,当置位信号set 有效时,将当前输出置为输入的数值set_num。模块的接口信号图如下: 模块的时序图…...

从零实现深度学习框架——Transformer从菜鸟到高手(一)
引言 💡本文为🔗[从零实现深度学习框架]系列文章内部限免文章,更多限免文章见 🔗专栏目录。 本着“凡我不能创造的,我就不能理解”的思想,系列文章会基于纯Python和NumPy从零创建自己的类PyTorch深度学习框…...
数组指针
数组指针的定义 1.数组指针是指针还是数组? 指针。 int a 10;int* p &a;//指向整型数据的指针 char b w;char* q &b;//指向字符变量的指针 所以数组指针应该是指向数组的指针。 2.数组指针应该怎么定义? int arr[10] { 0 };int(*p)[10] …...

C++设计模式之过滤器设计模式
C过滤器设计模式 什么是过滤器设计模式 过滤器设计模式是一种行为型设计模式,它允许你在特定的条件下对输入或输出进行过滤,以便实现不同的功能。 该模式有什么优缺点 优点 可扩展性:过滤器设计模式允许您轻松地添加、删除或替换过滤器&a…...
)
SpringBoot整合RedisTemplate操作Redis数据库详解(提供Gitee源码)
前言:简单分享一下我在实际开发当中如何使用SpringBoot操作Redis数据库的技术分享,完整的代码我都提供了出来,大家按需复制使用即可! 目录 一、导入pom依赖 二、yml配置文件 三、使用FastJson序列化 四、核心配置类 五、工具…...

slambook-en学习路线图:从初学者到专家的10个关键步骤
slambook-en学习路线图:从初学者到专家的10个关键步骤 【免费下载链接】slambook-en The English version of 14 lectures on visual SLAM. 项目地址: https://gitcode.com/gh_mirrors/sl/slambook-en 想要掌握视觉SLAM技术但不知从何开始?&#…...

如何快速配置Live Server Web Extension:提升开发效率的完整指南
如何快速配置Live Server Web Extension:提升开发效率的完整指南 【免费下载链接】live-server-web-extension It makes your existing server live. This is a browser extension that helps you to live reload feature for dynamic content (PHP, Node.js, ASP.N…...
)
【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单)
更多请点击: https://kaifayun.com 第一章:【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单) 为验证当前主流AI图像生成模型…...

Cursor Pro破解工具终极指南:三步轻松解锁AI编程助手高级功能
Cursor Pro破解工具终极指南:三步轻松解锁AI编程助手高级功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

Python盲水印终极指南:3个简单步骤保护你的数字版权
Python盲水印终极指南:3个简单步骤保护你的数字版权 【免费下载链接】BlindWatermark 使用盲水印保护创作者的知识产权using invisible watermark to protect creators intellectual property 项目地址: https://gitcode.com/gh_mirrors/bl/BlindWatermark 在…...

提示词失效?图像模糊?边缘锯齿?,深度拆解Midjourney毛玻璃效果的3大渲染瓶颈与实时修复路径
更多请点击: https://kaifayun.com 第一章:Midjourney毛玻璃效果的本质与视觉语义定位 毛玻璃效果(Frosted Glass Effect)在 Midjourney 中并非原生支持的渲染模式,而是用户通过提示词工程、风格化参数与后期语义引导…...

在珠宝首饰加工中,遨博协作机器人配合微力控技术,实现宝石的自动化镶嵌
在珠宝首饰的高端制造领域,宝石镶嵌是决定产品最终价值与艺术表现力的灵魂工序。这一过程要求近乎苛刻的精度、无可挑剔的稳定性,以及对脆性材料的极致呵护。长期以来,这依赖于镶嵌师多年练就的“手感”与专注力,属于劳动力高度密…...

MapStruct实战:手把手教你处理SpringBoot API中的字段名不一致问题
MapStruct实战:SpringBoot API字段名不一致的优雅解决方案 在SpringBoot开发中,前后端数据交互时经常遇到字段命名规范不一致的问题。数据库使用user_name,前端却要求userName;或者需要隐藏敏感字段如password,转换成*…...

抖音批量下载器终极指南:免费高效的视频采集解决方案
抖音批量下载器终极指南:免费高效的视频采集解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

从绿光到深紫外:手把手教你选对BBO、LBO、CLBO晶体,搞定激光倍频实验
从绿光到深紫外:非线性晶体选型与倍频实验实战指南 当实验室的1064nm激光器发出那束熟悉的近红外光时,许多研究者脑海中会立刻浮现两个问题:如何高效获得532nm的翠绿光束?又该如何进一步压缩波长至266nm的深紫外区域?…...