多线程(JavaEE初阶系列6)
目录
前言:
1.什么是线程池
2.标准库中的线程池
3.实现线程池
结束语:
前言:
在上一节中小编带着大家了解了一下Java标准库中的定时器的使用方式并给大家实现了一下,那么这节中小编将分享一下多线程中的线程池。给大家讲解一下什么是“池”,为什么要使用线程池。
1.什么是线程池
之前我们也有讲过“池”这个概念,我们讲过字符串常量池,数据连接池...
线程池就是提前把线程准备好,创建线程不是直接从系统中申请而是从池子中拿,当线程不用了的时候也是还给池子。它存在的目的就是为了提高效率,它最大的好处就是减少每次启动、销毁线程的损耗。线程的创建虽然比进程轻量,但是在频繁的创建的情况下,开销也是不可忽略的。
那么为什么从池子里拿比创建线程要更高效呢?
- 从线程池拿线程,纯粹的用户态操作。
- 从系统创建线程,涉及到用户态和内核态之间的切换。真正的创建是要在内核态完成。
在上述过程中提到了用户态、内核态这两个概念,那么下来给大家解释一下什么是用户态,什么是内核态。
一个操作系统 = 内核 + 配套的应用程序
- 其中内核就是操作系统中最核心的功能模块的集合,里面有硬件管理、各种驱动、进程管理、内存管理、文件系统...
- 内核则需要给上层的应用程序提供支持。
比如我们执行:println("hello")这样的一个操作。
首先应用程序调用系统内核,告诉内核我要进行打印一个字符串的操作,内核再通过驱动程序,操作显示器来完成上述的请求。应用程序有很多,但是内核只有一个,内核要给这么多程序提供服务有的时候服务就不会那么及时。
举一个例子:比如银行里的工作人员和来银行办理事务的人,假设工作人员只有一个人,客户有很多,此时工作人员就相当于内核,客户就是用户。工作人员待的柜台就是用户态,银行的大厅就是用户态。如下图所示:
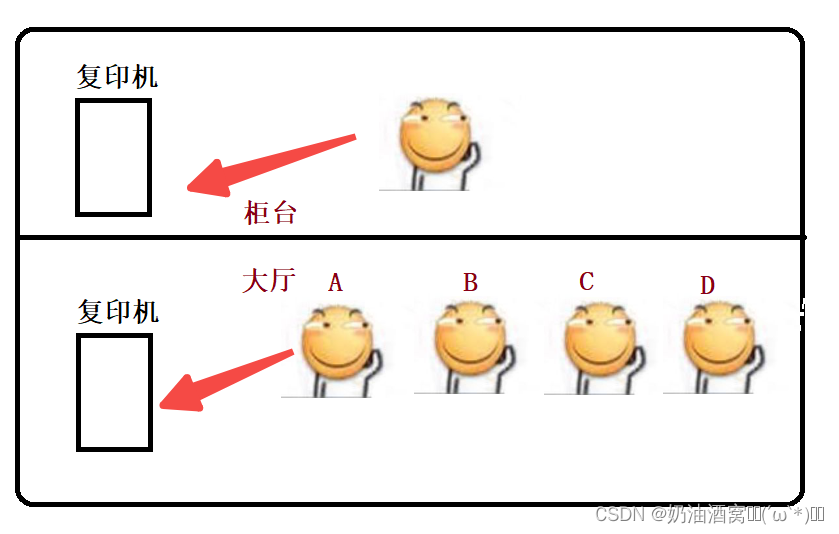
滑稽A此时来到柜台给工作人员说:我想办张银行卡。
此时就需要复印一些文件,这时我们有两种解决办法:
- A滑稽自己去大厅的复印机去复印,然后拿给工作人员。
- 工作人员去柜台里面的复印机去复印。
那么此时如果A滑稽自己去复印的话速度就会很快,立即复印,立即回来。但是如果是工作人员去复印的话可能就会很慢,因为柜台只有它一个人,他可能还需要给其他人提供服务。所以这也就例比于我们计算机中的用户态操作和内核态操作了,A滑稽自己复印就是用户态操作,而工作人员复印就是内核态操作。
结论:纯用户态操作,时间是可控的。涉及到内核态操作,时间就不太可控了。
2.标准库中的线程池
Java标准库中提供了线程的线程池。
ExecutorService pool = Executors.newFixedThreadPool(10);在这里我们可以看到和我们之前创建一个对象不太一样。

注意:这里我们使用的是工厂模式!!!
创建对象的时候不再直接new,而是使用一些其他方法(通常是静态方法)协助我们把对象创建出来。
在Executors.newFixedThreadPoll()是不会设定固定值的,这里是按需创建,用完之后也不会立即销毁,留着以备后用。
下面我们来给大家演示一下:
代码展示:
package Time;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;//线程池的使用
public class ThreadDemo3 {public static void main(String[] args) {//创建一个线程池ExecutorService pool = Executors.newFixedThreadPool(10);//添加任务到线程池中pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello");}});}
}
结果展示:

说道这里我们就不得不去看一下Java的官方文档中对线程池的解释了。
我打开Java的官方文档,没有的同学可以点击这个链接进入☞Java Platform SE 8
进入之后点击下面的进入ThreadPoolExecutor的页面。
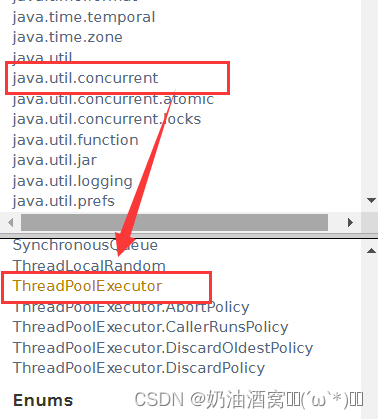
我们可以看到它的参数有以下几个:

我们分别给大家解释一下:
- corePollSize:核心线程数,如果类比一家公司的话,那么他们就是公司里面的正式员工。
- maximumPollSize:最大线程数,相当于是公司中的正式员工+实习生。如果当前的任务比较多,线程池就会多创建一些“临时线程”。如果当前任务比较少,比较空闲了,线程池就会把多创建出来的临时线程给销毁。也就相当于在公司里面如果任务比较多的话就多招几个实习生,但是如果任务不多的话就辞退实习生,保留正式员工。
- KeepAliveTime:线程的存活时间,如果任务不多了,那么临时创建的线程也不是一下子就销毁的,而是保留一段时间在销毁,相当于是在公司中,如果任务不多的话,实习生也不是瞬间就被辞退了,而是观察一段时间,看公司是不是长时间要处于一个不忙的状态。
- unit:时间单位。
- workQueue:线程池也要管理很多任务,这些任务也是通过阻塞队列来组织的,程序猿可以手动指定给线程池一个队列,此时程序猿就很方便的可以控制/获取队列中的信息了,submit方法其实就是把任务放到该队列中。
- threadFactor:工程模式,创建线程的辅助的类。
- handler: 线程池的拒绝策略,如果线程池的池子满了,继续往里添加任务,那么该如何进行拒绝呢?我们接着往下看。
关于线程池的拒绝策略,标准库给我们提供了四种。
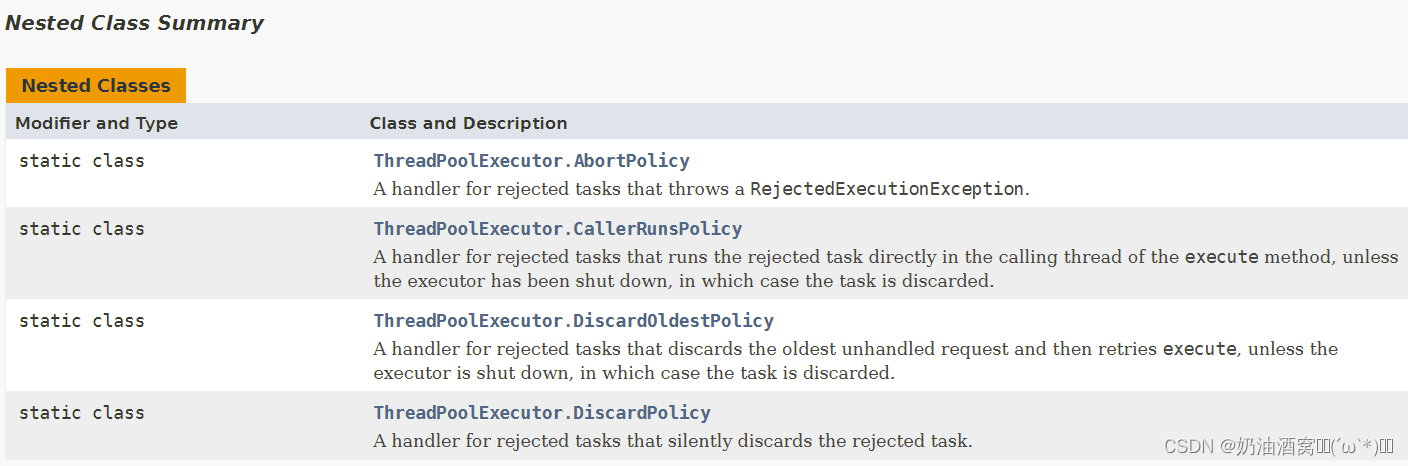
下面来给大家分别解释一下:
- ThreadPoolExecutor.AbortPolicy:表示如果任务满了,继续添加任务,添加的操作就会直接抛出异常。
- ThreadPoolExecutor.CallerRunsPolicy:添加的线程自己负责执行这个任务。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃最老的任务。
- ThreadPoolExecutor.DiscardPolicy:丢弃最新的任务。
3.实现线程池
下面我们就自己来实现一个线程池。
代码展示:
package Time;import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;//自己实现的线程池
class MyThreadPool{//阻塞队列用来存放任务private BlockingDeque<Runnable> queue = new LinkedBlockingDeque<>();public void submit(Runnable runnable) throws InterruptedException {queue.put(runnable);}//此处实现一个固定线程数的线程池public MyThreadPool(int n) {for (int i = 0; i < n; i++) {Thread t = new Thread(() -> {try {while (true) {//此处需要让线程池内部有一个while循环,不停的取任务Runnable runnable = queue.take();runnable.run();}} catch (InterruptedException e) {e.printStackTrace();}});t.start();}}
}
public class ThreadDemo4 {public static void main(String[] args) throws InterruptedException {MyThreadPool pool = new MyThreadPool(10);for (int i = 0; i < 1000; i++) {int number = i;pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello " + number);}});Thread.sleep(3000);}}
}
结果展示: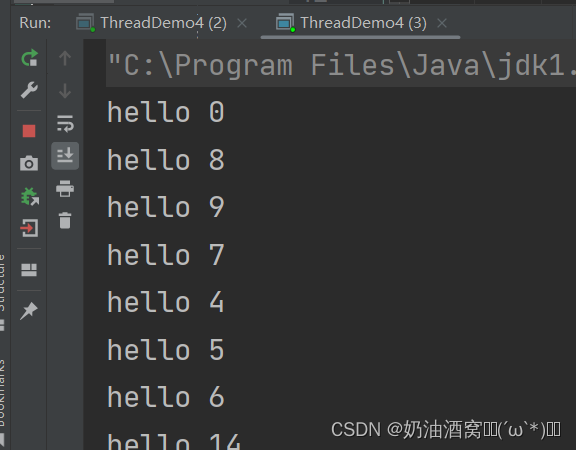
此处我们可以看到,线程池中任务的执行顺序和添加顺序不一定是相同的,这是非常正常的,因为这是个线程的调度是无序的。
结束语:
这节小编就与大家分享到这里啦,这节中小编主要与大家分享了什么是线程池,带着大家一起看了标准库中的线程池,并且我们自己还实现了一遍,希望这节对大家线程池有一定了解,想要学习的同学记得关注小编和小编一起学习吧!如果文章中有任何错误也欢迎各位大佬及时为小编指点迷津(在此小编先谢过各位大佬啦!)
相关文章:
多线程(JavaEE初阶系列6)
目录 前言: 1.什么是线程池 2.标准库中的线程池 3.实现线程池 结束语: 前言: 在上一节中小编带着大家了解了一下Java标准库中的定时器的使用方式并给大家实现了一下,那么这节中小编将分享一下多线程中的线程池。给大家讲解一…...

shell清理redis模糊匹配的多个key
#!/bin/bash# 定义Redis服务器地址和端口 REDIS_HOST"localhost" REDIS_PORT6380# 获取匹配键的数量 function get_matching_keys() {local key_pattern"$1"redis-cli -h $REDIS_HOST -p $REDIS_PORT -n 0 KEYS "$key_pattern" }# 删除匹配的键 …...
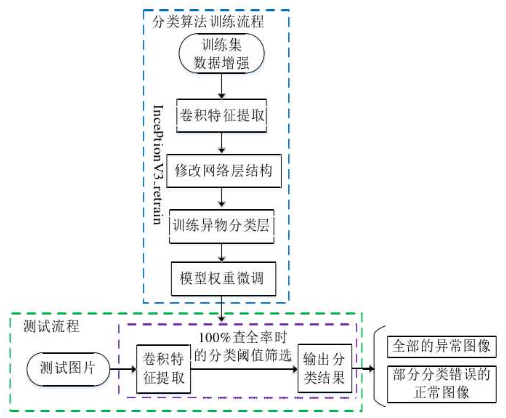
【电网异物检测硕士论文摘抄记录】电力巡检图像中基于深度学习的异物检测方法研究
根据国家电力行业发展报告统计,截止到 2018 年,全国电网 35 千伏及以上的输电线路回路长度达到 189 万千米,220 千伏及以上输电线路回路长度达73 万千米。截止到 2015年,根据国家电网公司的统计 330 千伏及以上输电线路故障跳闸总…...
C++共享数据的保护
虽然数据隐藏保护了数据的安全性,但各种形式的数据共享却又不同程度地破坏了数据的安全。因此,对于既需要共享有需要防止改变的数据应该声明为常量。因为常量在程序运行期间不可改变,所以可以有效保护数据。 1.常对象 常对象:它…...

MyBatisPlus学习记录
MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在简化开发、提高效率 MyBatisPlus简介 入门案例 创建新模块,选择Spring初始化,并配置模块相关基础信息选择当前模块需要使用的技术集(仅选择MySQL …...
如何开启一个java微服务工程
安装idea IDEA常用配置和插件(包括导入导出) https://blog.csdn.net/qq_38586496/article/details/109382560安装配置maven 导入source创建项目 修改项目编码utf-8 File->Settings->Editor->File Encodings 修改项目的jdk maven import引入…...

libhv之hio_t分析
上一篇文章解析了fd是怎么与io模型关联。其中最主要的角色扮演者:hio_t 1. hio_t与hloop的关系 fd的值即hio_t所在loop ios变量中所在的index值。 hio_t ios[fd] struct hloop_s { ...// ios: with fd as array.index//io_array保存了和hloop关联的所有hio_t&…...
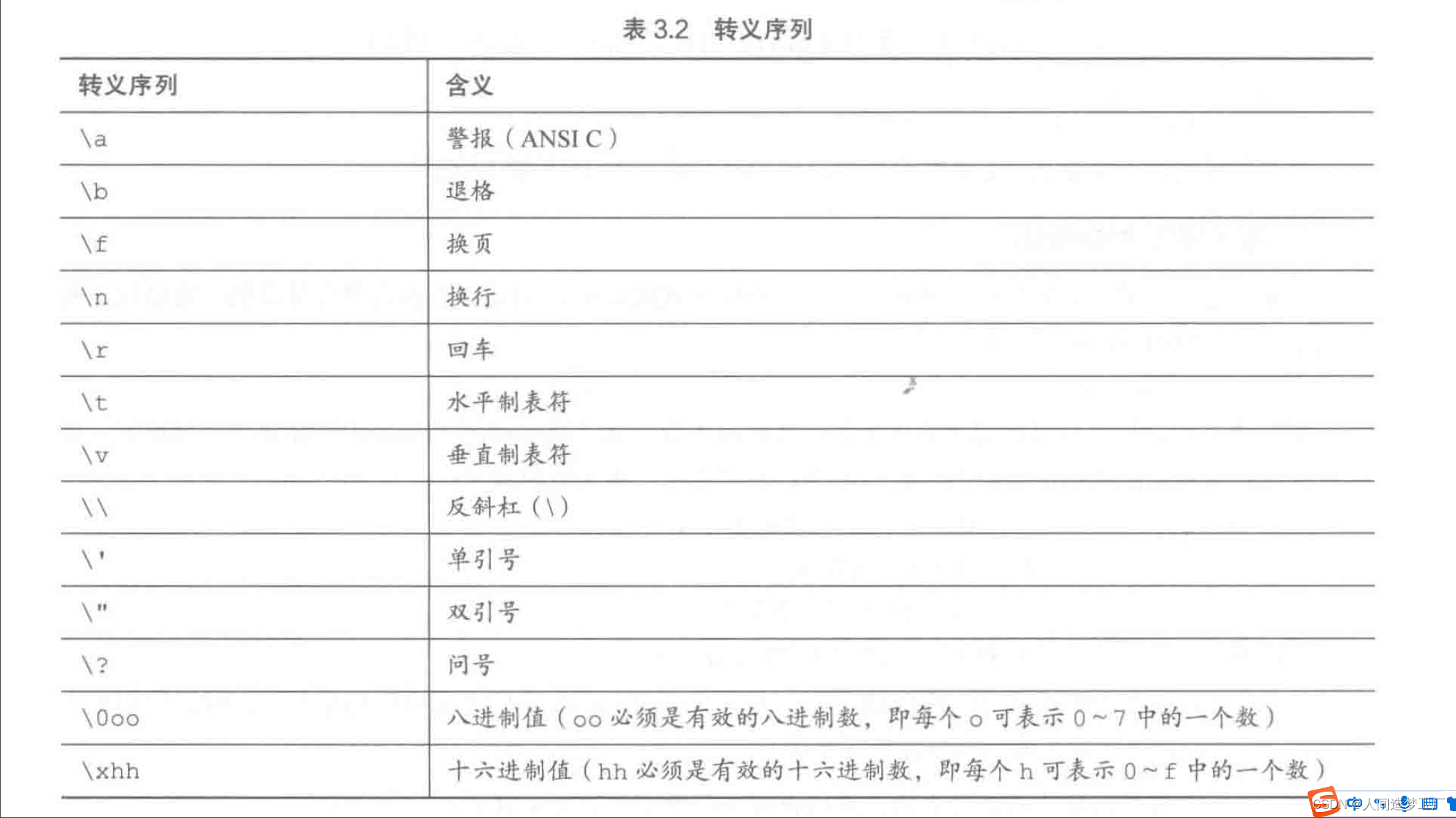
C语言的转义字符
转义字符也叫转移序列,包含如下: 转移序列 \0oo 和 \xhh 是 ASCII 码的特殊表示。 八进制数示例: 代码: #include<stdio.h> int main(void) {char beep\007;printf("%c\n",beep);return 0; }结果: …...
【腾讯云 Cloud Studio 实战训练营】CloudStudio体验真正的现代化开发方式,双手插兜不知道什么叫对手!
CloudStudio体验真正的现代化开发方式,双手插兜不知道什么叫对手! 文章目录 CloudStudio体验真正的现代化开发方式,双手插兜不知道什么叫对手!前言出现的背景一、CloudStudio 是什么?二、CloudStudio 的特点三、CloudS…...
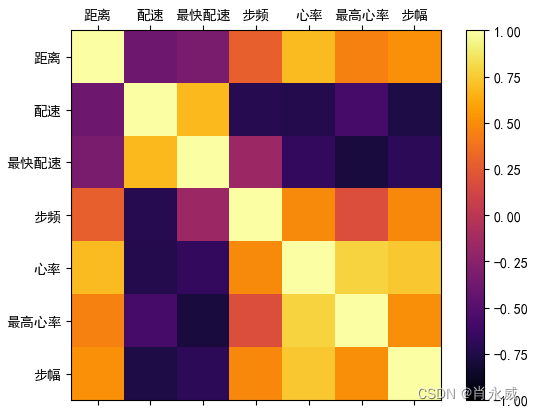
Pandas时序数据分析实践—时序数据集
1. 跑步运动为例,对运动进行时序分析 时序数据是指时间序列数据,是按照时间顺序排列的数据集合,每个数据点都与一个特定的时间戳相关联。在跑步活动中,我们可以将每次跑步的数据记录作为一个时序数据样本,每个样本都包…...

use strict 是什么意思?使用它区别是什么?
use strict 是什么意思?使用它区别是什么? use strict 代表开启严格模式,这种模式下使得 JavaScript 在更严格的条件下运行,实行更严格解析和错误处理。 开启“严格模式”的优点: 消除 JavaScript 语法的一些不合理…...
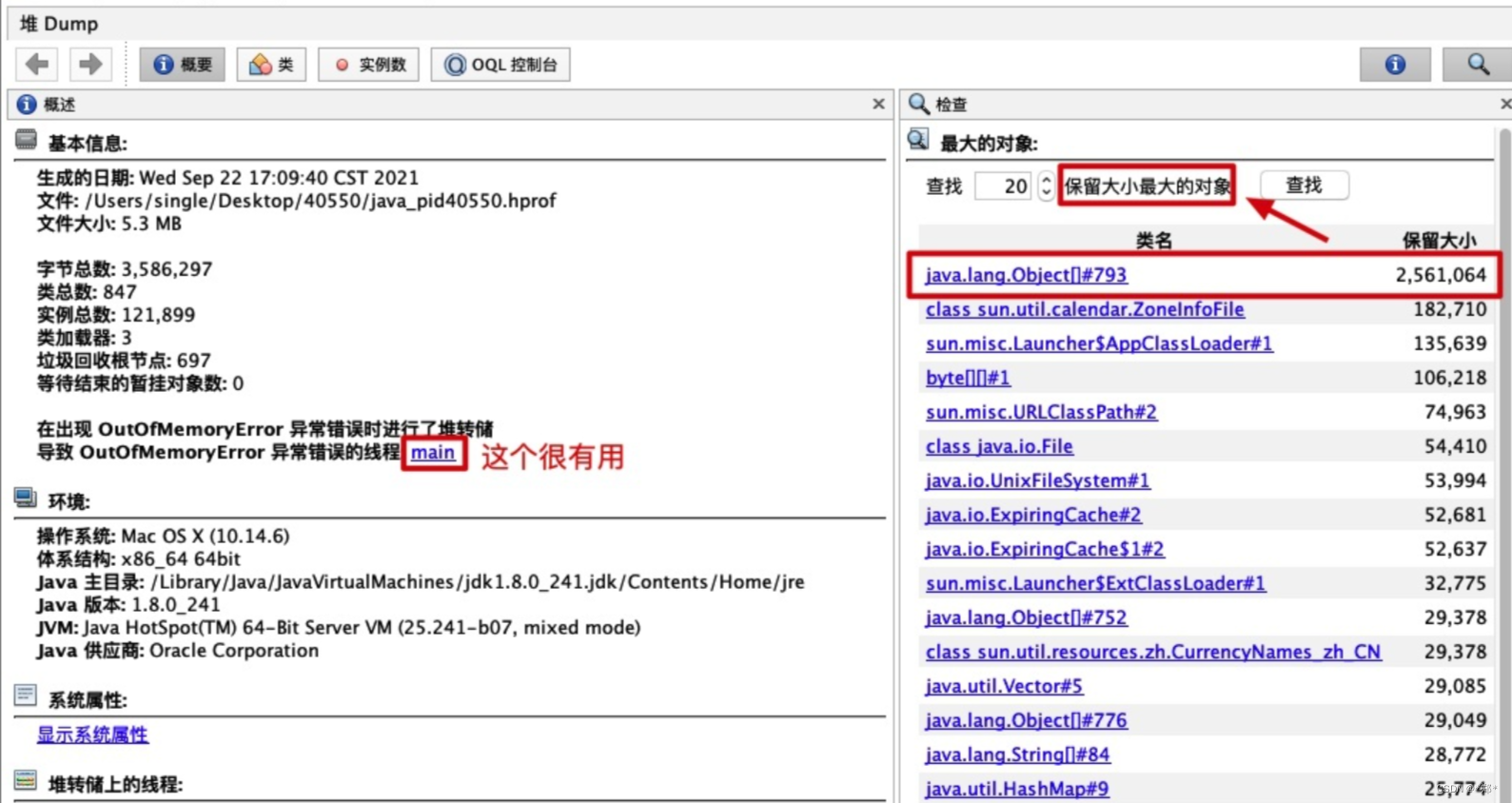
常见OOM异常分析排查
常见OOM异常分析排查 Java内存溢出Java堆溢出原因解决思路总结 Java内存溢出 java堆用于存储对象实例,如果不断地创建对象,并且保证GC Root到对象之间有可达路径,垃圾回收机制就不会清理这些对象,对象数量达到最大堆的容量限制后就会产生内存溢出异常. Java堆溢出原因 无法在…...

kubernetes网络之网络策略-Network Policies
Kubernetes 中,Network Policy(网络策略)定义了一组 Pod 是否允许相互通信,或者与网络中的其他端点 endpoint 通信。 NetworkPolicy 对象使用标签选择Pod,并定义规则指定选中的Pod可以执行什么样的网络通信࿰…...
交换机VLAN技术和实验(eNSP)
目录 一,交换机的演变 1.1,最小网络单元 1.2,中继器(物理层) 1.3,集线器(物理层) 1.4,网桥(数据链路层) 二,交换机的工作行为 2.…...
8.Winform界面打包成DLL提供给其他的项目使用
背景 希望集成一个Winform的框架,提供权限菜单,根据权限出现各个Winform子系统的菜单界面。不希望把所有的界面都放放在同一个解决方案下面。用各个子系统建立不同的解决方案,建立代码仓库,进行管理。 实现方式 将Winform的UI界…...

海量数据存储组件Hbase
hdfs hbase NoSQL数据库 支持海量数据的增删改查 基于Rowkey查询效率特别高 kudu 介于hdfs和hbase之间 hbase依赖hadoopzookeeper,同时整合框架phoenix(擅长读写),hive(分析数据) k,v 储存结构 稀疏的(为空的不存…...
(一)基于Spring Reactor框架响应式异步编程|道法术器
在执行程序时: 通常为了提供性能,处理器和编译器常常会对指令进行重排序。 从排序分为编译器重排序和处理器重排序两种 * (1)编译器重排序: 编译器保证不改变单线程执行结构的前提下,可以调整多线程语句执行顺序; * (2)处理器重排序: 如果不存在数据依赖…...

Vue3 让localstorage变响应式
Hook使用方式: import {useLocalStore} from "../js/hooks"const aauseLocalStore("aa",1) 需求一: 通过window.localStorage.setItem可以更改本地存储是,还可以更新aa的值 window.localStorage.setItem("aa&quo…...
【深度学习】InST,Inversion-Based Style Transfer with Diffusion Models,论文,风格迁移,实战
代码:https://github.com/zyxElsa/InST 论文:https://arxiv.org/abs/2211.13203 文章目录 AbstractIntroductionRelated WorkImage style transferText-to-image synthesisInversion of diffusion models MethodOverview ExperimentsComparison with Sty…...

【CSS】3D卡片效果
效果 index.html <!DOCTYPE html> <html><head><title> Document </title><link type"text/css" rel"styleSheet" href"index.css" /></head><body><div class"card"><img…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...

MeloTTS实战:多语言语音合成的高效解决方案
MeloTTS实战:多语言语音合成的高效解决方案 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trending/me/…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...