Python爬虫教程篇+图形化整理数据(数学建模可用)
一、首先我们先看要求
1.写一个爬虫程序
2、爬取目标网站数据,关键项不能少于5项。
3、存储数据到数据库,可以进行增删改查操作。
4、扩展:将库中数据进行可视化展示。
二、操作步骤:
首先我们根据要求找到一个适合自己的网站,我找的网站如下所示:
电影 / 精品电影_电影天堂-迅雷电影下载 (dygod.net)
1、根据要求我们导入爬取网页所需要的板块:
import requests #扒取页面
import re #正则
import xlwt #Excel库用于读取和写入
from bs4 import BeautifulSoup #从网页提取信息2、设置url为我们所需要爬的网站,并为其增加ua报头
url = "https://www.dygod.net/html/gndy/dyzz/"
# url1 = "https://movie.douban.com/top250?start=0&filter="hd = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188'
}3.我们记录爬取的电影,以及创建自己的工作表
count = 0 #记录爬取的电影数量
total = []
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook对象
worksheet = workbook.add_sheet('sheet1') #创建工作表
4.我们基于网站上的数据通过F12进入调试模式,找寻自己需要爬取的数据,进行封装和继承,最终保存在movie.xls表格中导进去
def saveExcel(worksheet, count, lst):for i, value in enumerate(lst):worksheet.write(count, i, value)for i in range(2, 10): # 爬取电影的页面数量,范围从第2页到第10页(包含第10页)url = "https://www.dygod.net/html/gndy/dyzz/index_"+str(i)+".html"# print(url)res = requests.get(url,headers=hd)res.encoding = res.apparent_encoding# print(res.text)soup = BeautifulSoup(res.text,"html.parser")# print(soup.title,type(soup.title))ret = soup.find_all(class_="tbspan",style="margin-top:6px") #找到所有电影的表格for x in ret: #遍历每一个电影表格info = []print(x.find("a").string) #电影名称info.append(x.find("a").string)pat = re.compile(r"◎译 名(.*)\n")ret_translated_name = re.findall(pat, str(x))for n in ret_translated_name:n = n.replace(u'/u3000', u'')print("◎译 名:", n)info.append(str(n).split("/")[0])pat = re.compile(r"◎年 代(.*)\n")ret_year = re.findall(pat, str(x))for n in ret_year:n = n.replace(u'/u3000', u'')print("◎年 代:", n)info.append(str(n))pat = re.compile(r"◎产 地(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎产 地:", n)info.append(str(n))pat = re.compile(r"◎类 别(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎类 别:", n)info.append(str(n))pat = re.compile(r"◎语 言(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎语 言:", n)info.append(str(n))pat = re.compile(r"◎字 幕(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎字 幕:", n)info.append(str(n))#print(count,info)saveExcel(worksheet,count,info)count += 1print("="*100)
workbook.save("movie.xls")
print(count)5.如此就做到了爬取我们所需要的数据是不是很简单,最后的汇总源码如下:
# -*- coding:utf-8 -*-
'''
@Author: lingchenwudiandexing
@contact: 3131579667@qq.com
@Time: 2023/8/2 10:24
@version: 1.0
'''
from urllib import responseimport requests #扒取页面
import re #正则
import xlwt #Excel库用于读取和写入
from bs4 import BeautifulSoup #从网页提取信息url = "https://www.dygod.net/html/gndy/dyzz/"
# url1 = "https://movie.douban.com/top250?start=0&filter="hd = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188'
}#正式代码开始
count = 0 #记录爬取的电影数量
total = []
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook对象
worksheet = workbook.add_sheet('sheet1') #创建工作表def saveExcel(worksheet, count, lst):for i, value in enumerate(lst):worksheet.write(count, i, value)for i in range(2, 10): # 爬取电影的页面数量,范围从第2页到第10页(包含第10页)url = "https://www.dygod.net/html/gndy/dyzz/index_"+str(i)+".html"# print(url)res = requests.get(url,headers=hd)res.encoding = res.apparent_encoding# print(res.text)soup = BeautifulSoup(res.text,"html.parser")# print(soup.title,type(soup.title))ret = soup.find_all(class_="tbspan",style="margin-top:6px") #找到所有电影的表格for x in ret: #遍历每一个电影表格info = []print(x.find("a").string) #电影名称info.append(x.find("a").string)pat = re.compile(r"◎译 名(.*)\n")ret_translated_name = re.findall(pat, str(x))for n in ret_translated_name:n = n.replace(u'/u3000', u'')print("◎译 名:", n)info.append(str(n).split("/")[0])pat = re.compile(r"◎年 代(.*)\n")ret_year = re.findall(pat, str(x))for n in ret_year:n = n.replace(u'/u3000', u'')print("◎年 代:", n)info.append(str(n))pat = re.compile(r"◎产 地(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎产 地:", n)info.append(str(n))pat = re.compile(r"◎类 别(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎类 别:", n)info.append(str(n))pat = re.compile(r"◎语 言(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎语 言:", n)info.append(str(n))pat = re.compile(r"◎字 幕(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎字 幕:", n)info.append(str(n))#print(count,info)saveExcel(worksheet,count,info)count += 1print("="*100)
workbook.save("movie.xls")
print(count)
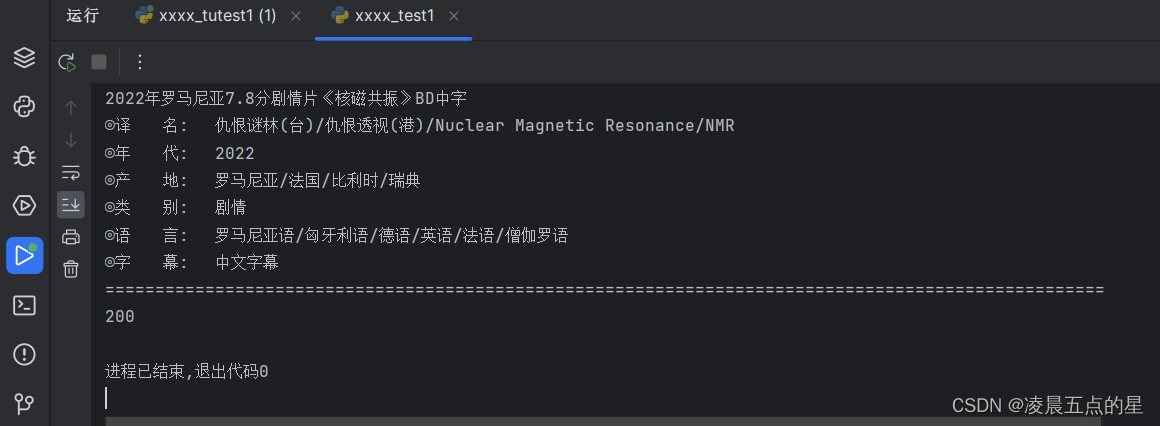
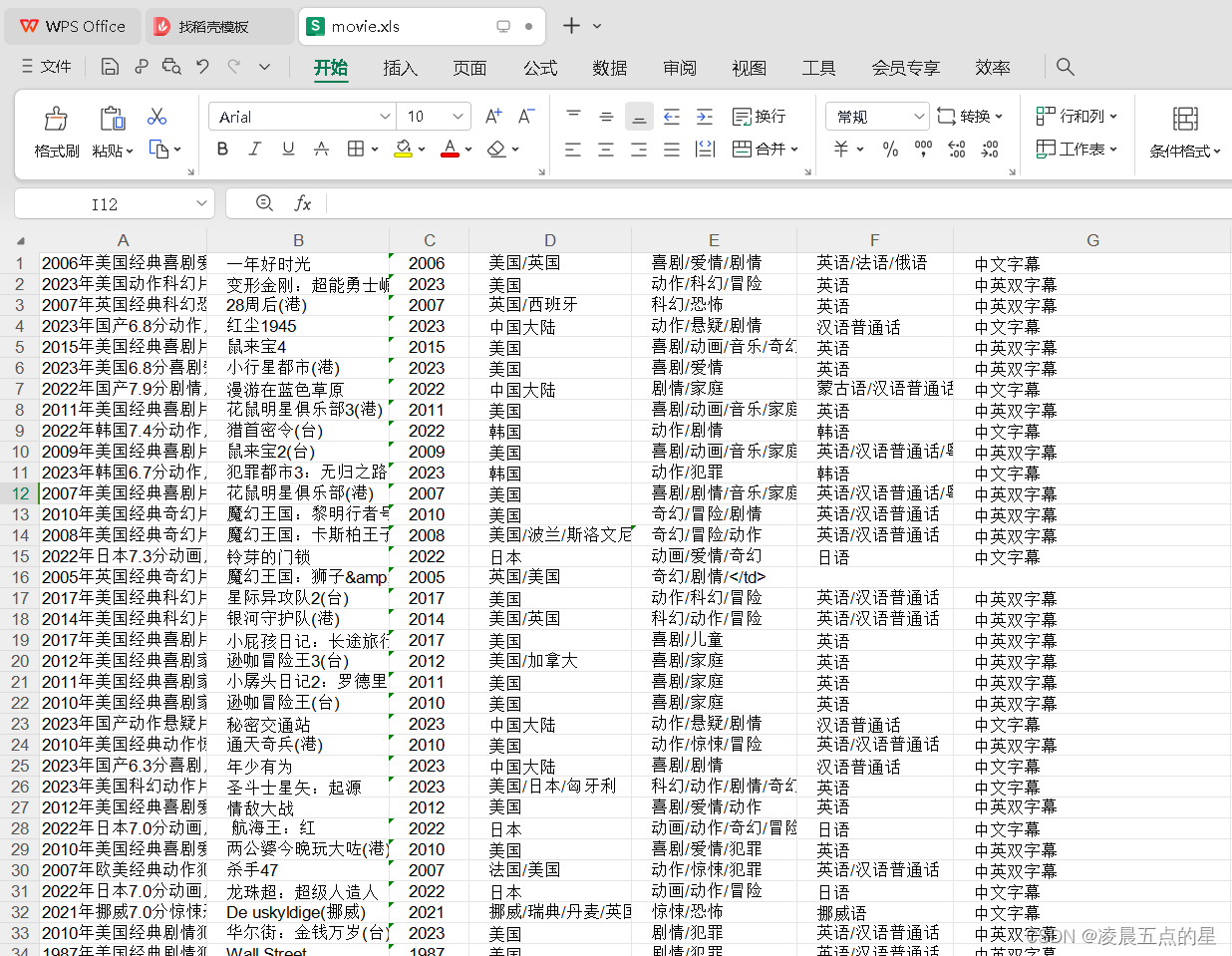
三、基础部分实现结果截屏
四、实验Plus升级版,增加数据汇总为图形化界面,面向对象
1.导入图像化界面的板块
import matplotlib.pyplot as plt
import numpy as np
from bs4 import BeautifulSoup2.实现自己想要实现的图形:(其中几行几列标注清楚)
①:初步:创建自己的画布,以及想要实现展现的语言
# 将数据保存到Pandas DataFrame对象中
columns = ["电影名称", "译名", "年代", "产地", "类别", "语言","字幕"]
df = pd.DataFrame(data, columns=columns)# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']# 创建一个包含4个子图的画布
figure = plt.figure(figsize=(12, 8))②:创建线形图:
# 创建线性图
subplot_line = figure.add_subplot(2, 2, 1)
x_data = np.arange(0, 100)
y_data = np.arange(1, 101)
subplot_line.plot(x_data, y_data)
subplot_line.set_title('线性图')③:创建饼状图:
subplot_pie = figure.add_subplot(2, 2, 3)
subplot_pie.pie(genre_counts.values, labels=genre_counts.index, autopct='%1.1f%%')
subplot_pie.set_title('饼状图')④:创建散点图:(设置好断点,不然会出现字符重叠的情况)
# 创建散点图
subplot_scatter = figure.add_subplot(2, 2, 4)
x_scatter = np.random.rand(50)
y_scatter = np.random.rand(50)
subplot_scatter.scatter(x_scatter, y_scatter)
subplot_scatter.set_title('散点图')
import warnings
warnings.filterwarnings("ignore")
plt.tight_layout()
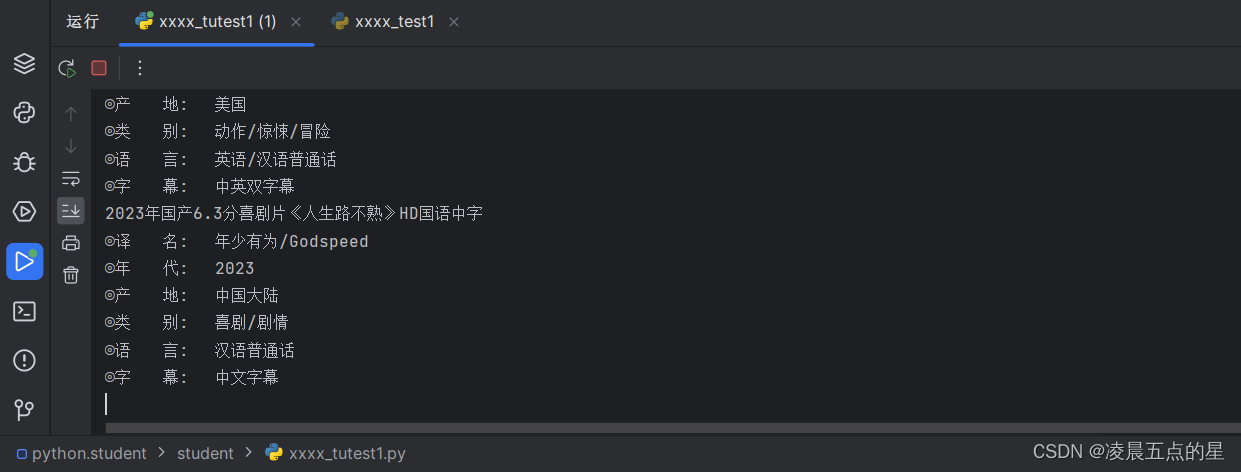
plt.show()⑤:到此我们整个爬虫以及数据记录便结束了,附上Plus实现截图:
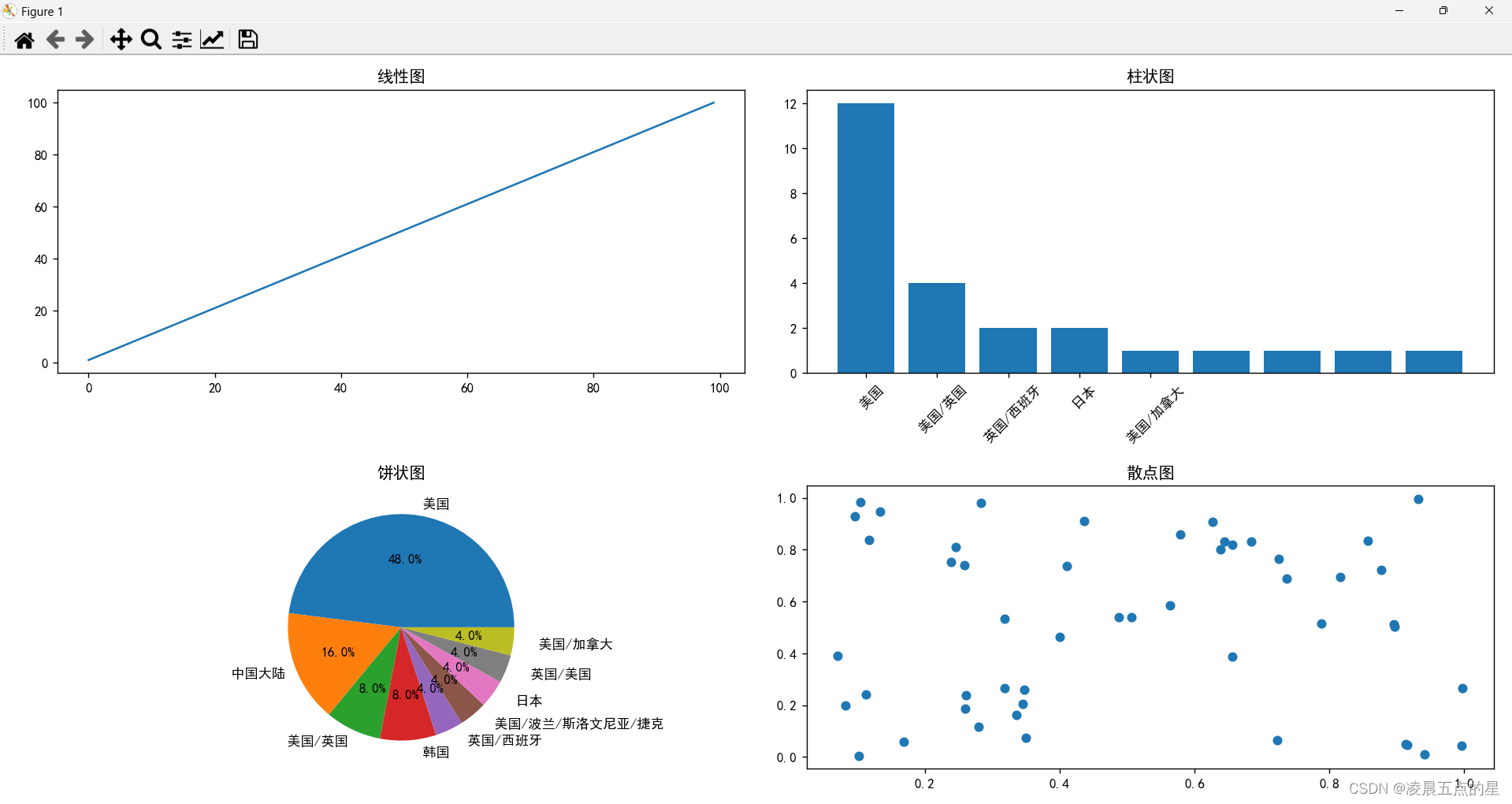
相关文章:
Python爬虫教程篇+图形化整理数据(数学建模可用)
一、首先我们先看要求 1.写一个爬虫程序 2、爬取目标网站数据,关键项不能少于5项。 3、存储数据到数据库,可以进行增删改查操作。 4、扩展:将库中数据进行可视化展示。 二、操作步骤: 首先我们根据要求找到一个适合自己的网…...

数字安全观察·数据安全分析方向
政策形势方面,全球均在加快制定并完善数字经济与数据安全相关政策法规。国际方面,欧盟、美国、英国、印度、俄罗斯等国家持续完善数据安全方面的法律政策,并且尤其关注数据跨境传输方面的问题。同时世界各国都着力关注人工智能数据安全风险&a…...

Kubernetes系列-配置存储 ConfigMap Secret
1 ConfigMap介绍 1.1 概述 在部署应用程序时,我们都会涉及到应用的配置,在容器中,如Docker容器中,如果将配置文件打入容器镜像,这种行为等同于写死配置,每次修改完配置,镜像就得重新构建。当然…...

bacnet ddc控制器如何通过485口转发Modbus协议控制modbus执行设备
要将BACnet DDC控制器通过485口转发Modbus协议控制Modbus执行设备,可以按照以下步骤进行: 确定Modbus执行设备的通信参数:包括串口波特率、数据位、停止位和校验位等参数。确保BACnet DDC控制器的485口通信设置与Modbus执行设备一致。 在BAC…...

构建易于运维的 AI 训练平台:存储选型与最佳实践
伴随着公司业务的发展,数据量持续增长,存储平台面临新的挑战:大图片的高吞吐、超分辨率场景下数千万小文件的 IOPS 问题、运维复杂等问题。除了这些技术难题,我们基础团队的人员也比较紧张,负责存储层运维的仅有 1 名同…...
)
前期自学Java的基础部分总结(二)
一. 抽象类 1.1 抽象类的概述 在java中,一个没有方法体的方法应该定义为抽象方法,而类中如果有抽象方法,该类必须被定义为抽象类 1.2 抽象类的特点 抽象类和抽象方法必须使用abstract关键字修饰 publice abstract class 类名{};public…...

Altova MissionKit 2023Crack
Altova MissionKit 2023Crack MissionKit是一套面向信息架构师和应用程序开发人员的企业级XML、JSON、SQL和UML工具的软件开发套件。MissionKit包括Altova XMLSpy、MapForce、StyleVision和其他市场领先的产品,用于构建当今的真实世界软件解决方案。 使用MissionKit…...

Linux CentOS上快速安装Docker并运行服务
在 CentOS 上快速安装 Docker,可以按照以下步骤进行: 1. 更新系统: sudo yum update 2. 安装 Docker: sudo yum install docker 3. 启动 Docker 服务: sudo systemctl start docker 4. 设置 Docker 开机自启动&…...
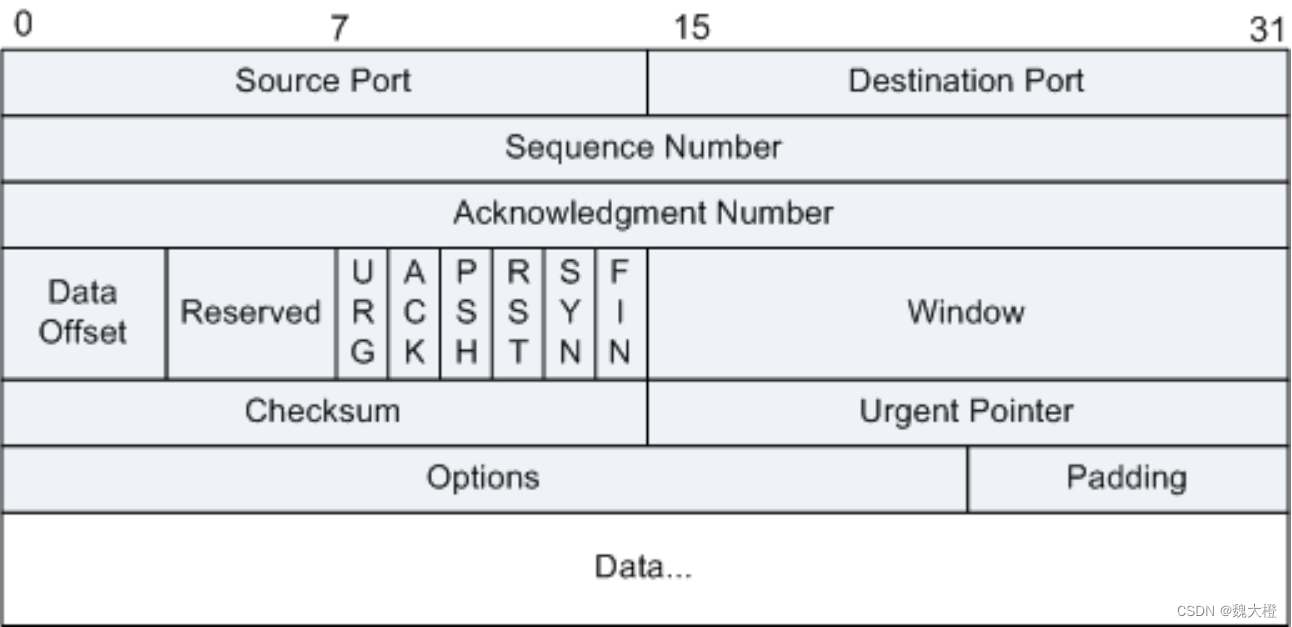
TCP三次握手与四次断开
TCP三次握手机制 三次握手是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。 1、客户端发送建立TCP连接的请求报文,其…...

关于前端与APP录音相关的笔记
文章目录 一、前言二、内容组成1、权限获取2、针对设备兼容3、内容类型转换4、传输存储 三、拓展内容自动播放部分 一、前言 主要针对前端适配录音能力的简要记录,针对默认的wav及其可能需要转换到特定的mp3之类格式以适配需求的问题。(这类通常是兼容tt…...

【Java】SpringBoot项目整合FreeMarker加快页面访问速度
文章目录 什么是FreeMarker?它的优点有那些?使用方式 什么是FreeMarker? Freemarker是一个模板引擎技术,它可以将数据和模板结合起来生成最终的输出。它是一种用于生成文本输出(如HTML、XML、JSON等)的通用…...

conda环境下安装opencv-python包
conda环境下安装opencv-python包 一、#查看环境 conda info --env# conda environments: # base D:\ProgramData\Anaconda3二、激活base环境 进入conda环境 conda init cmd.exe conda activate base三、根据版本号,下载对应的 python-opencv…...
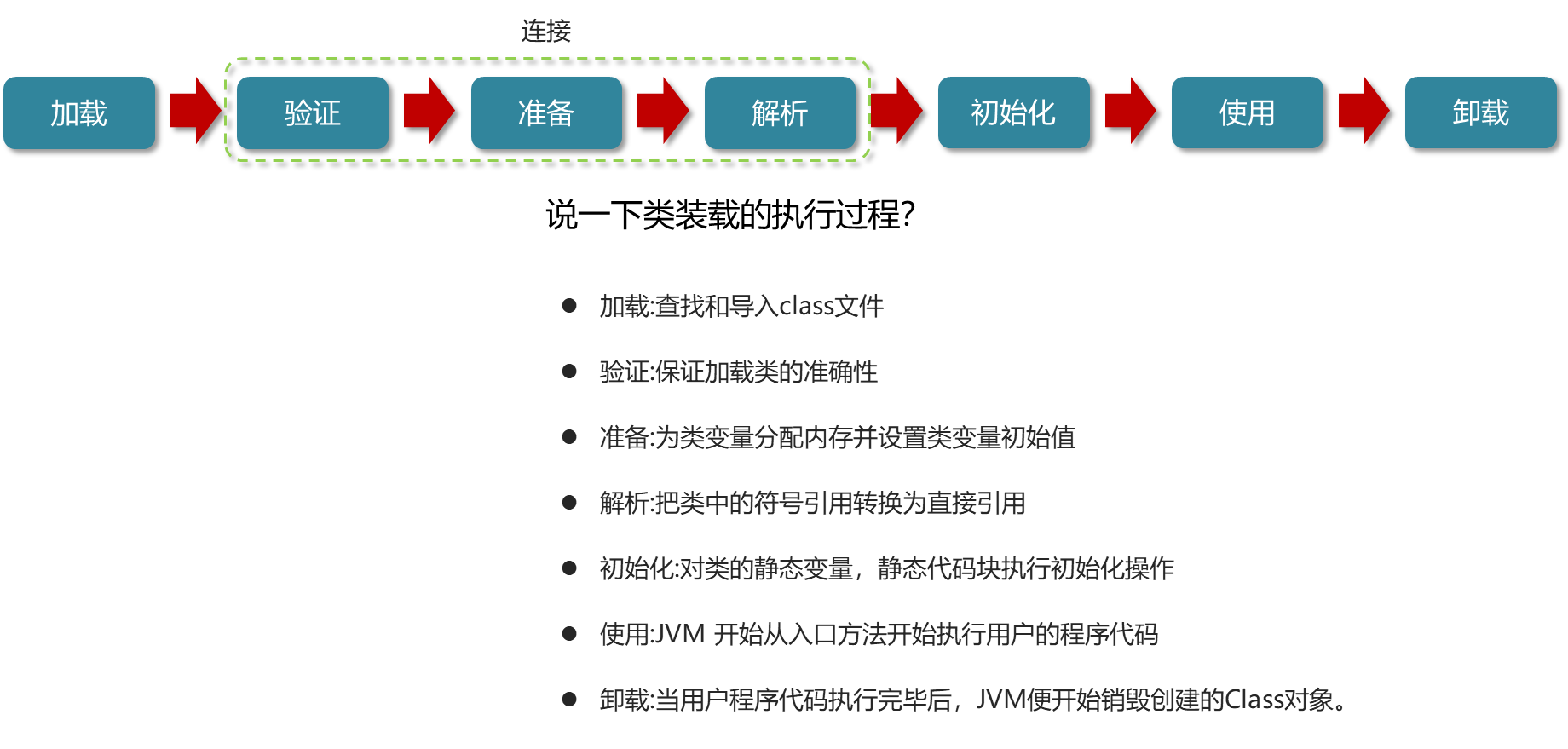
JVM面试题--类加载器
什么是类加载器,类加载器有哪些 类加载子系统,当java源代码编译为class文件之后,由他将字节码装载到运行时数据区 BootStrap ClassLoader 启动类加载器或者叫做引导类加载器,是用c实现的,嵌套在jvm内部,…...

js怎么计算当前一周的日期
你可以使用 JavaScript 的 Date 对象来计算当前一周的日期。首先,你需要获取当前日期,然后使用 Date 对象的 getDay 方法获取当前是星期几(星期日是 0,星期一是 1,以此类推)。然后,你可以根据当前是星期几来计算出本周…...

【图论】差分约束
一.情景导入 x1-x0<9 ; x2-x0<14 ; x3-x0<15 ; x2-x1<10 ; x3-x2<9; 求x3-x0的最大值; 二.数学解法 联立式子2和5,可得x3-x0<23;但式子3可得x3-x0<15。所以最大值为15; 三.图论 但式子多了我们就不好解了࿰…...

13 springboot项目——准备数据和dao类
13.1 静态资源下载 https://download.csdn.net/download/no996yes885/88151513 13.2 静态资源位置 css样式文件放在static的css目录下;static的img下放图片;template目录下放其余的html文件。 13.3 创建两个实体类 导入依赖:lombok <!…...

Java 基础进阶总结(一)反射机制学习总结
文章目录 一、初识反射机制1.1 反射机制概述1.2 反射机制概念1.3 Java反射机制提供的功能1.4 反射机制的优点和缺点 二、反射机制相关的 API 一、初识反射机制 1.1 反射机制概述 JAVA 语言是一门静态语言,对象的各种信息在程序运行时便已经确认下来了,内…...

ERROR: transport error 202: gethostbyname: unknown host报错解决方案
Java 9 syntax for remote debugger: -agentlib:jdwptransportdt_socket,servery,suspendn,address*:5005Java 8 不适用 *:port,应该使用: -agentlib:jdwptransportdt_socket,servery,suspendn,address5005参考 https://stackoverflow.com/questions/50344957/ja…...

PyTorch高级教程:自定义模型、数据加载及设备间数据移动
在深入理解了PyTorch的核心组件之后,我们将进一步学习一些高级主题,包括如何自定义模型、加载自定义数据集,以及如何在设备(例如CPU和GPU)之间移动数据。 一、自定义模型 虽然PyTorch提供了许多预构建的模型层&#…...

JavaEE——SpringMVC中的常用注解
目录 1、RestController (1)、Controller (2)、ResponseBody 2、RequestMappping (1)、定义 (2)、使用 【1】、修饰方法 【2】、修饰类 【3】、指定方法类型 【4】、简化版…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...