【音频分离】demucs V3的环境搭建及训练(window)
文章目录
- 一、环境搭建
- (1)新建虚拟环境,并进入
- (2)安装pyTorch
- (3)进入代码文件夹,批量安装包
- (4)安装其他需要的包
- 二、数据集准备
- (1)下载数据集
- (2)修改配置参数
- (3)创建微调数据集
- (4)解压outputs.tar.gz
- 三、训练
- (1)默认,cpu
- (2)默认,gpu
- (3)修改参数,gpu
- 四、推理
- (1)模型导出
- (2)模型评估
- (3)推理
- 报错
- (1)soundfile.LibsndfileError: Error opening 'C:\\Users\\Lenovo\\AppData\\Local\\Temp\\tmps0ogpyqy.wav': System error.
- (2)FileNotFoundError: [WinError 2] 系统找不到指定的文件。
- (3)TypeError: beat_track() takes 0 positional arguments but 1 positional argument (and 2 keyword-only arguments) were given
- (4)TypeError: chroma_cqt() takes 0 positional arguments but 1 positional argument (and 1 keyword-only argument) were given
- (5)numpy.core._exceptions._ArrayMemoryError: Unable to allocate 1.11 GiB for an array with shape (54134, 1377) and data type complex128
- (6)UserWarning:The version_base parameter is not specified.
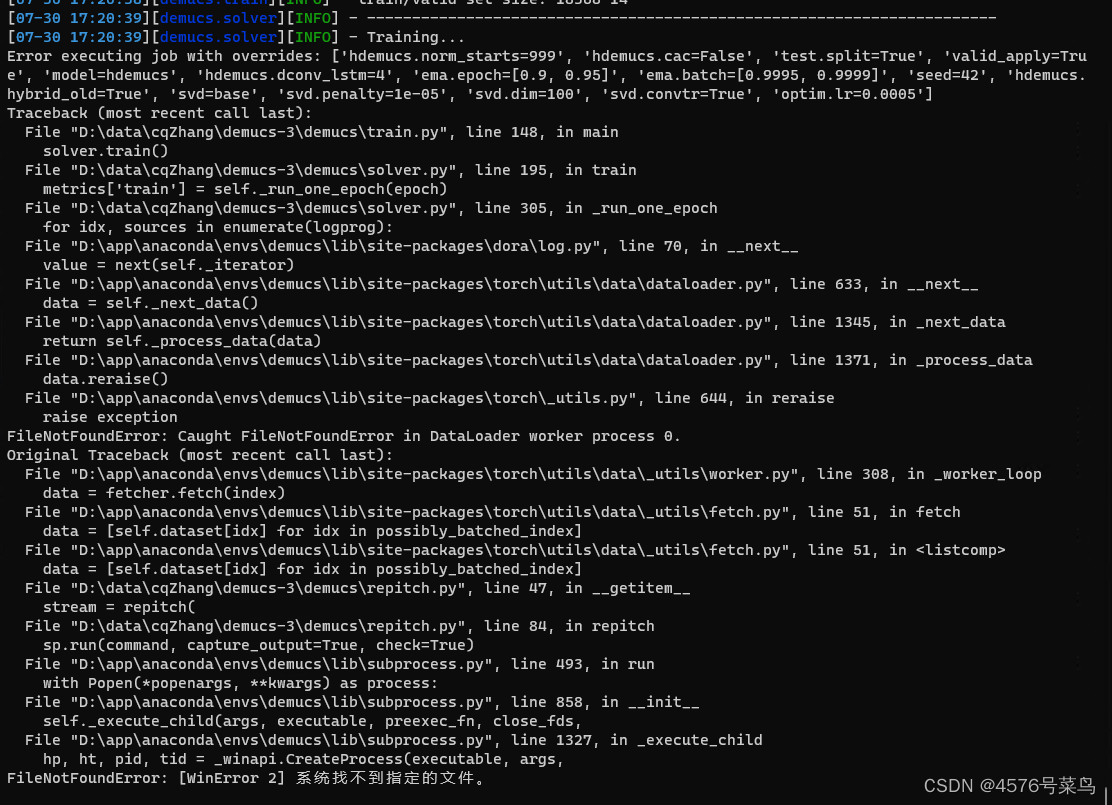
- (7)FileNotFoundError: Caught FileNotFoundError in DataLoader worker process 0.
- (8)torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 562.00 MiB (GPU 0; 15.99 GiB total capacity; 14.06 GiB already allocated; 0 bytes free; 14.72 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
- (9)WARNING:__main__:Model 81de367c has less epoch than expected (8 / 360)
- 写在最后
代码下载
这是一个音频提取、分离的项目
一、环境搭建
(1)新建虚拟环境,并进入
conda create -n demucs python=3.8
activate demucs

(2)安装pyTorch
到pyTorch官网选择对应配置
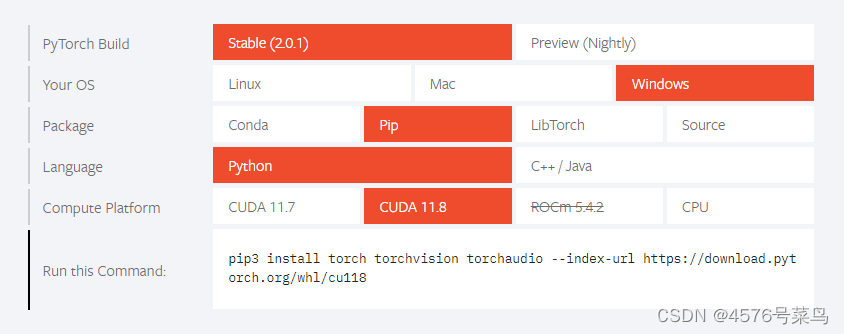
这个是我的配置
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118

(3)进入代码文件夹,批量安装包

d:
cd D:\data\cqZhang\demucs-3
pip install -r requirements.txt

(4)安装其他需要的包
pip install librosa
二、数据集准备
(1)下载数据集
使用Musdb HQ 数据集
获取路径有:
https://zenodo.org/record/3338373
https://www.kaggle.com/datasets/ayu055/musdb18hq
数据集可以放在“\checkpoint\defossez\datasets\musdbhq”路径下,
这与代码原来的位置应该是一致的
(2)修改配置参数
- The
dset.musdbkey insideconf/config.yaml. - The variable
MUSDB_PATHinsidetools/automix.py.

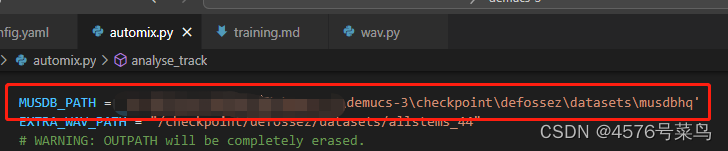
我本来使用的是相对路径,但是他貌似找不到,后来改成绝对路径
其他的路径也一样,如果找不到,就要改成绝对路径
(3)创建微调数据集
原来的命令是export NUMBA_NUM_THREADS=1; python3 -m tools.automix,但它是linux上的命令,
将其改为set NUMBA_NUM_THREADS=1 && python -m tools.automix
运行结束会在项目目录下产生tmp文件夹,里面有新的数据集
修改 conf/config.yaml.中的 dset.musdb
修改 conf/dset/auto_mus.yaml 中的 dset.wav ( OUTPATH)
(4)解压outputs.tar.gz
tar xvf outputs.tar.gz
三、训练
训练有三种命令
我只尝试了第二种
(1)默认,cpu
dora info -f 81de367c
this will show the hyper-parameter used by a specific XP.
Be careful some overrides might present twice, and the right most one will give you the right value for it.
这将显示特定XP使用的超参数。
请注意,有些覆盖可能会出现两次,最正确的一次将为您提供正确的值。
(2)默认,gpu
dora run -d -f 81de367c

注意:如果修改了数据集,要在目录下删除metadata文件夹,否则会出错。
run an XP with the hyper-parameters from XP 81de367c.
-dis for distributed, it will use all available GPUs.
使用XP 81de367c中的超参数运行XP。
-d是分布式的,它将使用所有可用的GPU。
(3)修改参数,gpu
dora run -d -f 81de367c hdemucs.channels=32
start from the config of XP 81de367c but change some hyper-params.
This will give you a new XP with a new signature (here 3fe9c332).
从XP 81de367c的配置开始,但更改了一些超参数。
这将为您提供一个带有新签名的新XP(此处为3fe9c332)。
四、推理
(1)模型导出
python -m tools.export 81de367c

(2)模型评估
python -m tools.test_pretrained --repo ./release_models -n 81de367c

(3)推理
python -m demucs --repo ./release_models -n 81de367c --mp3 D:\data\cqZhang\001.mp3

保存位置./separated
报错
(1)soundfile.LibsndfileError: Error opening ‘C:\Users\Lenovo\AppData\Local\Temp\tmps0ogpyqy.wav’: System error.

在linux上运行会创建一个临时文件,且程序退出后该临时文件会自动删除,
但是在windows上运行时,不能打开创建的临时文件,
Whether the name can be used to open the file a second time, while the named temporary file is still open, varies across platforms (it can be so used on Unix; it cannot on Windows NT or later).
在命名的临时文件仍然打开的情况下,该名称是否可以用于第二次打开文件,因平台而异(它可以在Unix上使用;不能在Windows NT或更高版本上使用)。
处理:
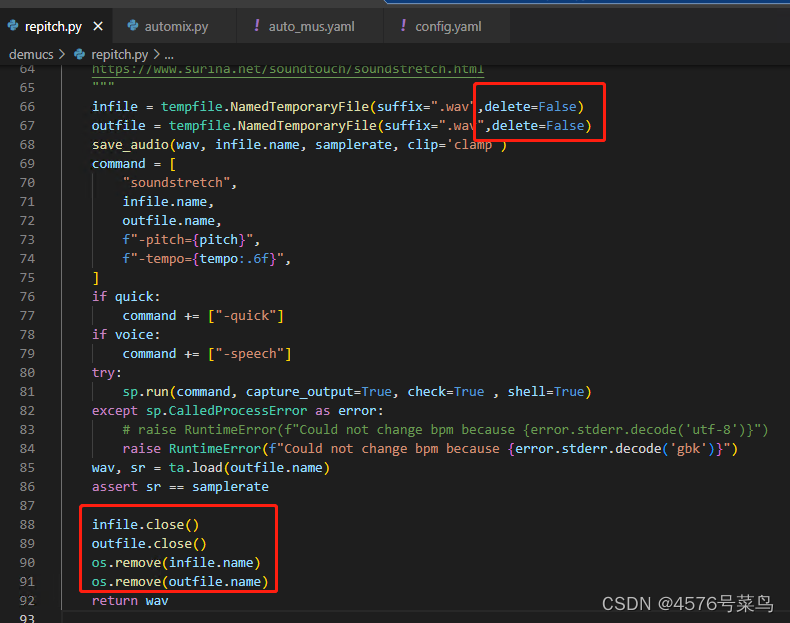
方法1. 更改临时文件保存方式(不保存到系统的临时文件夹里)
方法2. 增加参数:delete=False,手动删除
我采用方法2
执行后会报其他错误,这是另一个问题了

(2)FileNotFoundError: [WinError 2] 系统找不到指定的文件。

出现这个错误,原因大概有三种:
1、先查看路径是否正确
2、再查看该文件是否存在
3、如果还没解决问题,最后很可能就是该命令在dos环境内无法使用
处理:
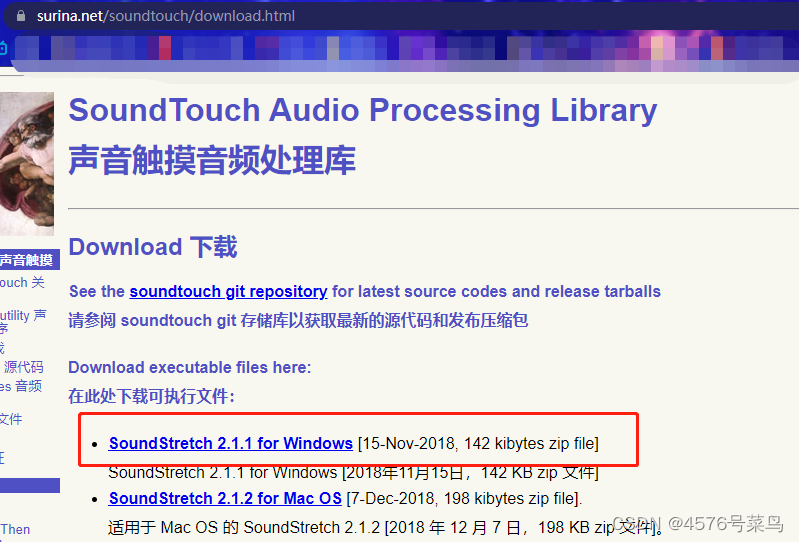
根据实际情况,我判断是第三种问题
到这里下载一个程序,
解压后放在项目目录下
已经成功执行了
(3)TypeError: beat_track() takes 0 positional arguments but 1 positional argument (and 2 keyword-only arguments) were given
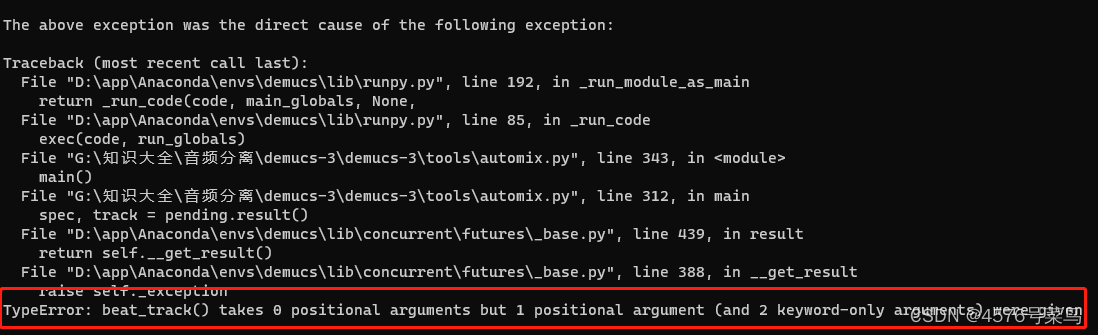
说是参数个数不匹配的问题,其实并不是
处理:
# 将下列代码
tempo, events = beat_track(drums.numpy(), units='time', sr=SR)# 改为
tempo, events = beat_track(y=drums.numpy(), units='time', sr=SR)

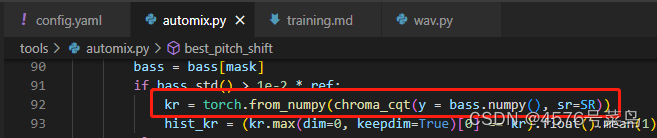
(4)TypeError: chroma_cqt() takes 0 positional arguments but 1 positional argument (and 1 keyword-only argument) were given
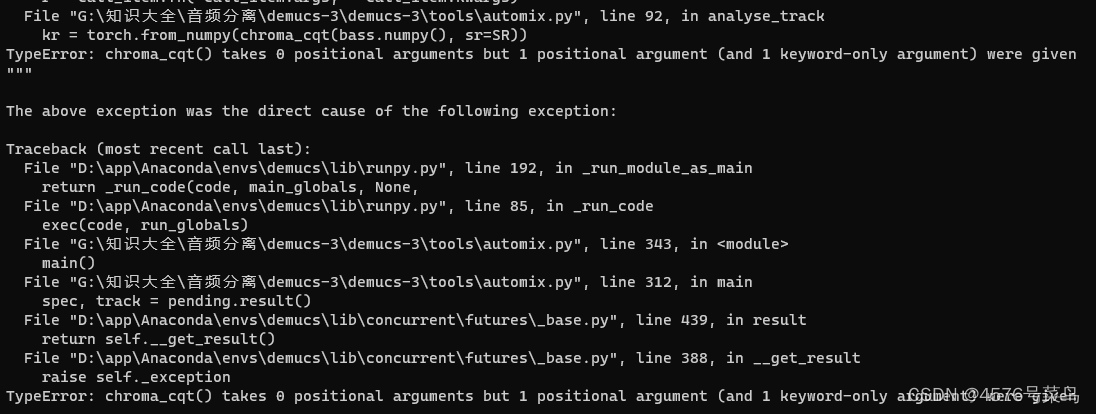
这个问题与上面那个问题一样
说是参数个数不匹配的问题,其实并不是
处理:
# 将下列代码
kr = torch.from_numpy(chroma_cqt(bass.numpy(), sr=SR))# 改为
kr = torch.from_numpy(chroma_cqt(y = bass.numpy(), sr=SR))
(5)numpy.core._exceptions._ArrayMemoryError: Unable to allocate 1.11 GiB for an array with shape (54134, 1377) and data type complex128
内存不足
这个我没有去思考如何减少内存的使用
也许减小数据集有效
我的处理方式是:换一台大内存的机器
它的内存需求不超过40g
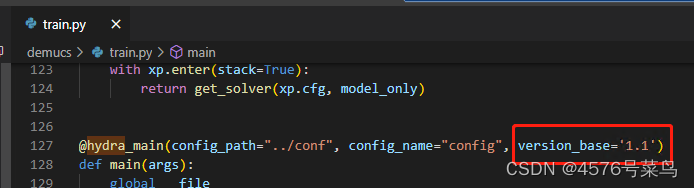
(6)UserWarning:The version_base parameter is not specified.

这是一个版本警告,其实无关紧要
完整的警告如下:
D:\app\anaconda\envs\demucs\lib\site-packages\dora\hydra.py:279: UserWarning:
The version_base parameter is not specified.
Please specify a compatability version level, or None.
Will assume defaults for version 1.1
with initialize_config_dir(str(self.full_config_path), job_name=self._job_name,
处理:
加上参数version_base='1.1'
(7)FileNotFoundError: Caught FileNotFoundError in DataLoader worker process 0.
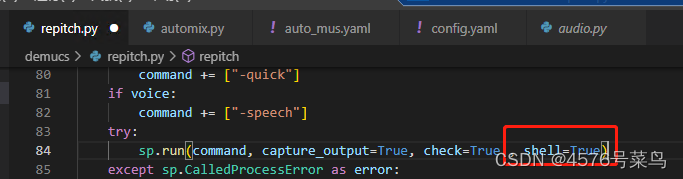
处理:
首先我在demucs/repitch的sp.run()中加入参数shell=True
再次运行dora run -d -f 81de367c,报错信息出现变化
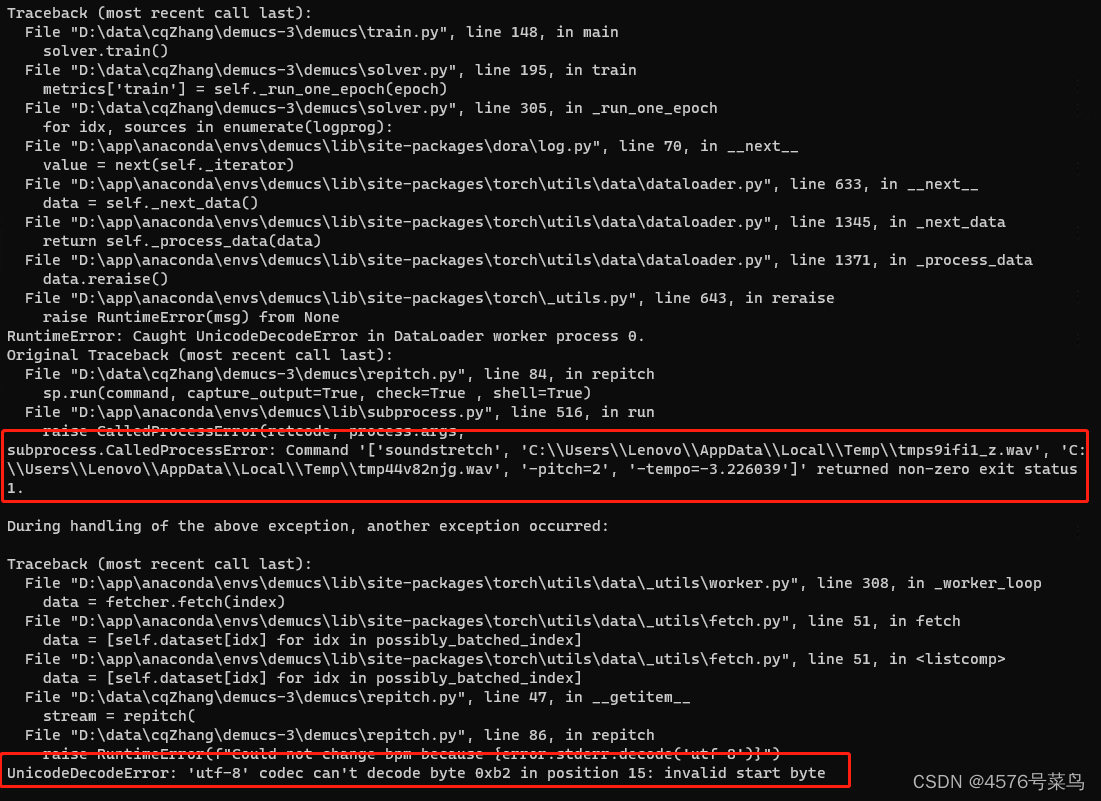
我运行命令soundstretch C:\\Users\\Lenovo\\AppData\\Local\\Temp\\tmps9ifi1_z.wav C:\\Users\\Lenovo\\AppData\\Local\\Temp\\tmp44v82njg.wav -pitch=2 -tempo=-3.226039,执行成功
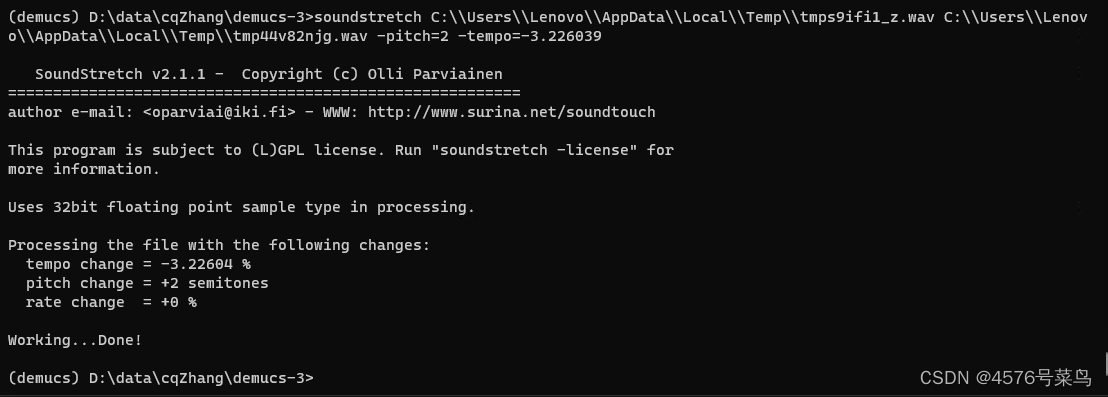
说明文件其实是存在的,但是不知道为啥不能执行成功
第二处应该是编码格式的问题,我将raise RuntimeError(f"Could not change bpm because {error.stderr.decode('utf-8')}")修改为raise RuntimeError(f"Could not change bpm because {error.stderr.decode('gbk')}")解决
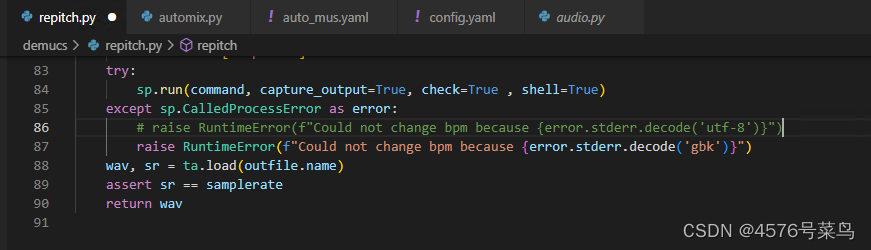
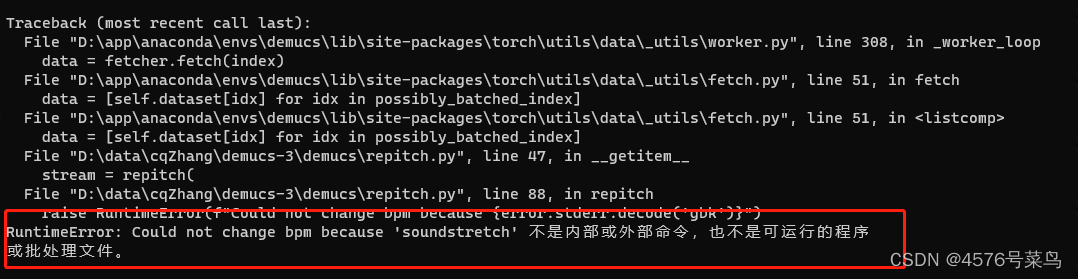
这可能就是报错的主要原因了
将soundstretch放到下面目录
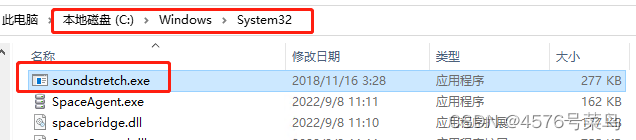
运行出现一下结果,应该是没问题了。(内存不足修改batch_size)

(8)torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 562.00 MiB (GPU 0; 15.99 GiB total capacity; 14.06 GiB already allocated; 0 bytes free; 14.72 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
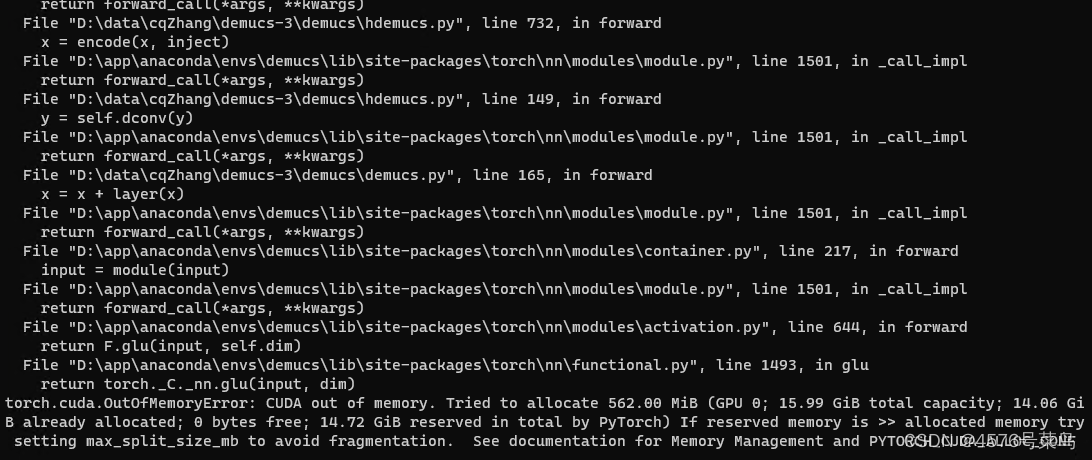
处理:
修改conf/config.yaml里的batch_size
默认64,但是我只有16G的显存,设置成4,目前恰好运行,不知道能不能运行到结束。
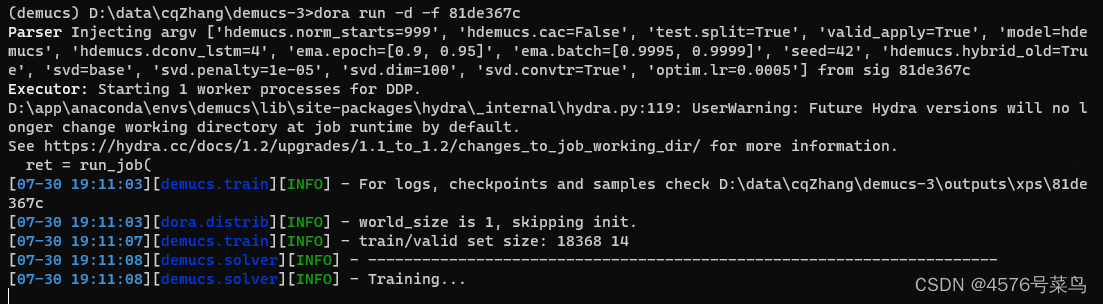
##(9)FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。
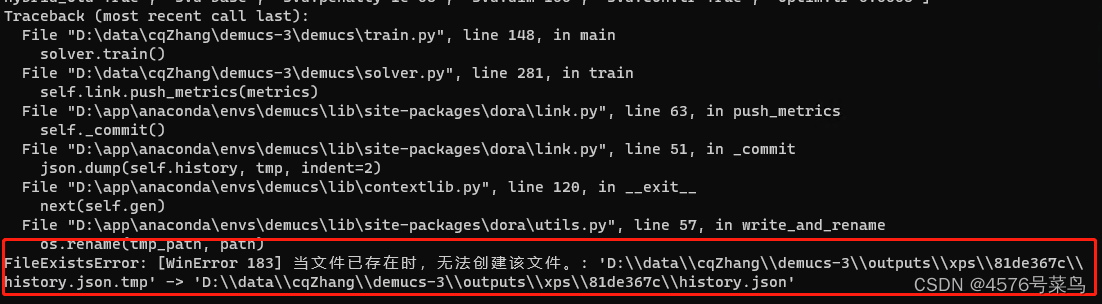
处理:
方法1:修改重命名方式,改成强制覆盖
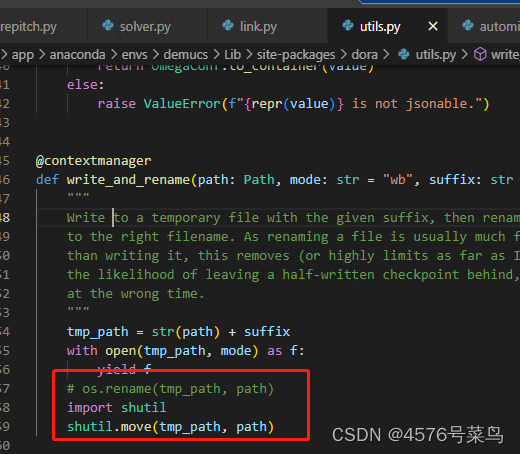
方法2:在重命名前删除已有文件
方法3:修改命名方式,比如加上日期时间
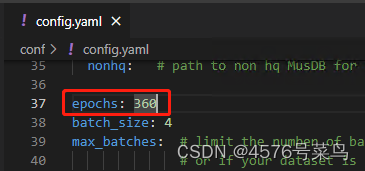
(9)WARNING:main:Model 81de367c has less epoch than expected (8 / 360)

模型没有训练够就想导出。
处理:
只是一个警告,不理会也没关系。
介意的话,把这里改小即可。
写在最后
写一半的时候有其他的事,停了大半个月
现在又有事了,匆匆忙忙把推理部分写上
后面有机会再补充
有机会尝试自己构造数据集训练
相关文章:
【音频分离】demucs V3的环境搭建及训练(window)
文章目录 一、环境搭建(1)新建虚拟环境,并进入(2)安装pyTorch(3)进入代码文件夹,批量安装包(4)安装其他需要的包 二、数据集准备(1)下…...
)
JAVA环境变量配置(windows)
windows配置环境变量(大小写不区分): 新建JAVA_HOME:jdk的根目录 D:\Java\jdk1.8.0_71Path(必须)%JAVA_HOME%\bin新建(类路径)CLASSPATH: .;D:\Java\jdk1.8.0_71\lib(或者.;%JAVA_HO…...

爬虫教程1_Xpath 入门教程
Xpath 入门教程 在编写爬虫程序的过程中提取信息是非常重要的环节,但是有时使用正则表达式无法匹配到想要的信息,或者书写起来非常麻烦,此时就需要用另外一种数据解析方法,也就是本节要介绍的 Xpath 表达式。 Xpath表达式 XPath…...
Python爬虫教程篇+图形化整理数据(数学建模可用)
一、首先我们先看要求 1.写一个爬虫程序 2、爬取目标网站数据,关键项不能少于5项。 3、存储数据到数据库,可以进行增删改查操作。 4、扩展:将库中数据进行可视化展示。 二、操作步骤: 首先我们根据要求找到一个适合自己的网…...

数字安全观察·数据安全分析方向
政策形势方面,全球均在加快制定并完善数字经济与数据安全相关政策法规。国际方面,欧盟、美国、英国、印度、俄罗斯等国家持续完善数据安全方面的法律政策,并且尤其关注数据跨境传输方面的问题。同时世界各国都着力关注人工智能数据安全风险&a…...

Kubernetes系列-配置存储 ConfigMap Secret
1 ConfigMap介绍 1.1 概述 在部署应用程序时,我们都会涉及到应用的配置,在容器中,如Docker容器中,如果将配置文件打入容器镜像,这种行为等同于写死配置,每次修改完配置,镜像就得重新构建。当然…...

bacnet ddc控制器如何通过485口转发Modbus协议控制modbus执行设备
要将BACnet DDC控制器通过485口转发Modbus协议控制Modbus执行设备,可以按照以下步骤进行: 确定Modbus执行设备的通信参数:包括串口波特率、数据位、停止位和校验位等参数。确保BACnet DDC控制器的485口通信设置与Modbus执行设备一致。 在BAC…...

构建易于运维的 AI 训练平台:存储选型与最佳实践
伴随着公司业务的发展,数据量持续增长,存储平台面临新的挑战:大图片的高吞吐、超分辨率场景下数千万小文件的 IOPS 问题、运维复杂等问题。除了这些技术难题,我们基础团队的人员也比较紧张,负责存储层运维的仅有 1 名同…...
)
前期自学Java的基础部分总结(二)
一. 抽象类 1.1 抽象类的概述 在java中,一个没有方法体的方法应该定义为抽象方法,而类中如果有抽象方法,该类必须被定义为抽象类 1.2 抽象类的特点 抽象类和抽象方法必须使用abstract关键字修饰 publice abstract class 类名{};public…...

Altova MissionKit 2023Crack
Altova MissionKit 2023Crack MissionKit是一套面向信息架构师和应用程序开发人员的企业级XML、JSON、SQL和UML工具的软件开发套件。MissionKit包括Altova XMLSpy、MapForce、StyleVision和其他市场领先的产品,用于构建当今的真实世界软件解决方案。 使用MissionKit…...

Linux CentOS上快速安装Docker并运行服务
在 CentOS 上快速安装 Docker,可以按照以下步骤进行: 1. 更新系统: sudo yum update 2. 安装 Docker: sudo yum install docker 3. 启动 Docker 服务: sudo systemctl start docker 4. 设置 Docker 开机自启动&…...
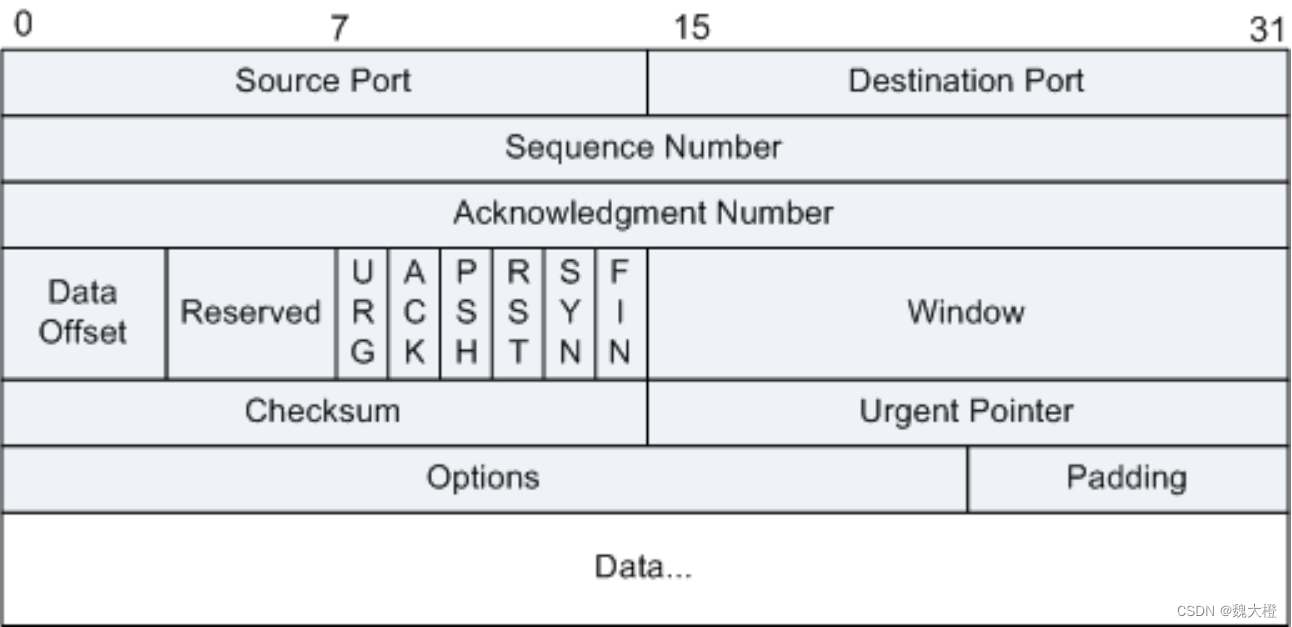
TCP三次握手与四次断开
TCP三次握手机制 三次握手是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。 1、客户端发送建立TCP连接的请求报文,其…...

关于前端与APP录音相关的笔记
文章目录 一、前言二、内容组成1、权限获取2、针对设备兼容3、内容类型转换4、传输存储 三、拓展内容自动播放部分 一、前言 主要针对前端适配录音能力的简要记录,针对默认的wav及其可能需要转换到特定的mp3之类格式以适配需求的问题。(这类通常是兼容tt…...

【Java】SpringBoot项目整合FreeMarker加快页面访问速度
文章目录 什么是FreeMarker?它的优点有那些?使用方式 什么是FreeMarker? Freemarker是一个模板引擎技术,它可以将数据和模板结合起来生成最终的输出。它是一种用于生成文本输出(如HTML、XML、JSON等)的通用…...

conda环境下安装opencv-python包
conda环境下安装opencv-python包 一、#查看环境 conda info --env# conda environments: # base D:\ProgramData\Anaconda3二、激活base环境 进入conda环境 conda init cmd.exe conda activate base三、根据版本号,下载对应的 python-opencv…...
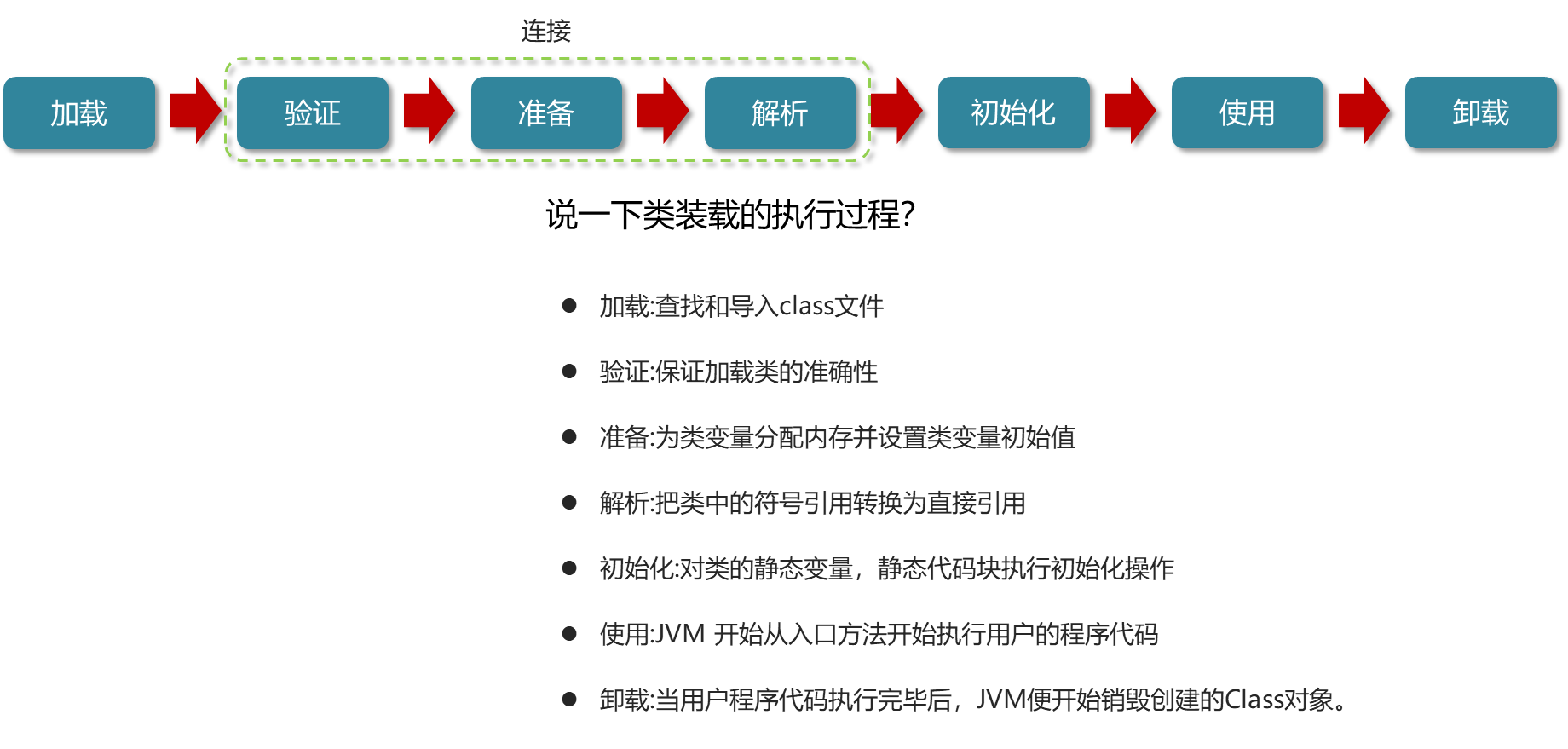
JVM面试题--类加载器
什么是类加载器,类加载器有哪些 类加载子系统,当java源代码编译为class文件之后,由他将字节码装载到运行时数据区 BootStrap ClassLoader 启动类加载器或者叫做引导类加载器,是用c实现的,嵌套在jvm内部,…...

js怎么计算当前一周的日期
你可以使用 JavaScript 的 Date 对象来计算当前一周的日期。首先,你需要获取当前日期,然后使用 Date 对象的 getDay 方法获取当前是星期几(星期日是 0,星期一是 1,以此类推)。然后,你可以根据当前是星期几来计算出本周…...

【图论】差分约束
一.情景导入 x1-x0<9 ; x2-x0<14 ; x3-x0<15 ; x2-x1<10 ; x3-x2<9; 求x3-x0的最大值; 二.数学解法 联立式子2和5,可得x3-x0<23;但式子3可得x3-x0<15。所以最大值为15; 三.图论 但式子多了我们就不好解了࿰…...

13 springboot项目——准备数据和dao类
13.1 静态资源下载 https://download.csdn.net/download/no996yes885/88151513 13.2 静态资源位置 css样式文件放在static的css目录下;static的img下放图片;template目录下放其余的html文件。 13.3 创建两个实体类 导入依赖:lombok <!…...

Java 基础进阶总结(一)反射机制学习总结
文章目录 一、初识反射机制1.1 反射机制概述1.2 反射机制概念1.3 Java反射机制提供的功能1.4 反射机制的优点和缺点 二、反射机制相关的 API 一、初识反射机制 1.1 反射机制概述 JAVA 语言是一门静态语言,对象的各种信息在程序运行时便已经确认下来了,内…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

新能源车轻量化为什么开始盯上高强镁合金?
续航,是悬在每一台纯电动汽车头上的达摩克利斯之剑。多充一度电、多堆一些正极材料,是一条路;但还有另一条路——把车造得更轻。 SAE(美国汽车工程师学会)的测算已经被反复引用:整车每减重100千克ÿ…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...