Python Numpy入门基础(二)数组操作

入门基础(二)
NumPy是Python中一个重要的数学运算库,它提供了了一组多维数组对象和一组用于操作这些数组的函数。以下是一些NumPy的主要特点:
- 多维数组对象:NumPy的核心是ndarray对象,它是一个多维数组对象,可以容纳任意数据类型。
- 矢量化操作:使用NumPy的函数,可以对整个数组进行操作,而不需要显式循环。
- 广播:NumPy的广播机制允许对不同形状的数组执行算术操作,而无需进行显式循环或手动对齐。
- 易于扩展:NumPy可以用C或C++扩展,以加速大型数值计算任务。
- 强大的函数库:NumPy提供了许多用于线性代数、傅里叶分析、随机数生成等领域的函数。
- 易于使用:NumPy与Python的内置数据结构无缝集成,因此可以轻松地将Python代码转换为使用NumPy。
数组操作
组索引和切片
索引从0开始,索引值不能超过长度,否则会报IndexError错误。
一维数组的索引和切片
>>> import numpy as np
>>> a = np.array([1,2,3,4,5])
>>> a[2]
3
>>> a[1:4:2]
array([2, 4])
>>> a[1:3]
array([2, 3])
>>> a[0::2]
array([1, 3, 5])
>>> a[5]
Traceback (most recent call last):File "<pyshell#15>", line 1, in <module>a[5]
IndexError: index 5 is out of bounds for axis 0 with size 5
多维数组的索引
>>> import numpy as np
>>> a = np.arange(24).reshape((2,3,4))
>>> a
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])
>>> a[1,2,3]
23
>>> a[-1,-2,-3]
17
>>> a[0,2,2]
10
>>> a[0,3,3]
Traceback (most recent call last):File "<pyshell#12>", line 1, in <module>a[0,3,3]
IndexError: index 3 is out of bounds for axis 1 with size 3多维数组切片
>>> import numpy as np
>>> a = np.arange(24).reshape((2,3,4)) + 1
>>> a
array([[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12]],[[13, 14, 15, 16],[17, 18, 19, 20],[21, 22, 23, 24]]])
>>> a[:1,2]
array([[ 9, 10, 11, 12]])
>>> a[:,1:3,:]
array([[[ 5, 6, 7, 8],[ 9, 10, 11, 12]],[[17, 18, 19, 20],[21, 22, 23, 24]]])
>>> a[:,:,::2]
array([[[ 1, 3],[ 5, 7],[ 9, 11]],[[13, 15],[17, 19],[21, 23]]])
>>> a[:,:,1::2]
array([[[ 2, 4],[ 6, 8],[10, 12]],[[14, 16],[18, 20],[22, 24]]])
>>> a[1:3,:,:]
array([[[13, 14, 15, 16],[17, 18, 19, 20],[21, 22, 23, 24]]])
>>> a[1:3,1:3,:]
array([[[17, 18, 19, 20],[21, 22, 23, 24]]])
>>> a[1:3,1:3,1:3]
array([[[18, 19],[22, 23]]])
通过布尔数组访问数组元素
>>> import numpy as np
>>> a = np.array([1, 2, 3, 4, 5])
>>> b = np.array([True, False, True, False, True])
>>> a[b]
array([1, 3, 5])
>>> b = np.array([False, True, False, True, False])
>>> a[b]
array([2, 4])
>>> b = a<=3
>>> a[b]
array([1, 2, 3])
>>> b = a%2==0
>>> a[b]
array([2, 4])
>>> b = a%2==1
>>> a[b]
array([1, 3, 5])
数组的整体操作
数组的拼接
在 NumPy 中,可以使用多种方法来拼接数组。以下是一些常用的方法:
numpy.concatenate()
这个函数用于连接两个数组,沿指定的轴在末尾添加第二个数组的元素。
>>> a = np.array([[1, 2], [3, 4]])
>>> b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=0)
array([[1, 2],[3, 4],[5, 6]])
>>> np.concatenate((a, b.T), axis=1)
array([[1, 2, 5],[3, 4, 6]])
>>> np.concatenate((a, b), axis=None)
array([1, 2, 3, 4, 5, 6])numpy.vstack()
这个函数用于垂直方向拼接数组,即行方向添加第二个数组的元素。
>>> a = np.array([1, 2, 3])
>>> b = np.array([4, 5, 6])
>>> np.vstack((a,b))
array([[1, 2, 3],[4, 5, 6]])>>> a = np.array([[1], [2], [3]])
>>> b = np.array([[4], [5], [6]])
>>> np.vstack((a,b))
array([[1],[2],[3],[4],[5],[6]])numpy.hstack()
这个函数用于水平方向拼接数组,即列方向添加第二个数组的元素。
>>> a = np.array((1,2,3))
>>> b = np.array((4,5,6))
>>> np.hstack((a,b))
array([1, 2, 3, 4, 5, 6])
>>> a = np.array([[1],[2],[3]])
>>> b = np.array([[4],[5],[6]])
>>> np.hstack((a,b))
array([[1, 4],[2, 5],[3, 6]])numpy.row_stack()
这个函数是vstack的alias,别名就是同一个函数。
>>> import numpy as np
>>> a = np.array([[1, 2], [3, 4]])
>>> b = np.array([[5, 6]])
>>> np.row_stack((a, b))
array([[1, 2],[3, 4],[5, 6]])
在使用这些函数时,需要确保拼接的数组具有相同的维度,或者在使用 numpy.column_stack() 时具有相同的列数。如果维度不同,可以使用 numpy.reshape() 函数对数组进行重塑。
数组的翻转
在 NumPy 中,也有多种方法可以翻转数组。以下是一些常用的方法:
numpy.flip()
这个函数用于沿指定的轴翻转数组。
Examples
--------
>>> A = np.arange(8).reshape((2,2,2))
>>> A
array([[[0, 1],
[2, 3]],
[[4, 5],
[6, 7]]])
>>> np.flip(A, 0)
array([[[4, 5],
[6, 7]],
[[0, 1],
[2, 3]]])
>>> np.flip(A, 1)
array([[[2, 3],
[0, 1]],
[[6, 7],
[4, 5]]])
>>> np.flip(A)
array([[[7, 6],
[5, 4]],
[[3, 2],
[1, 0]]])
>>> np.flip(A, (0, 2))
array([[[5, 4],
[7, 6]],
[[1, 0],
[3, 2]]])
>>> A = np.random.randn(3,4,5)
>>> np.all(np.flip(A,2) == A[:,:,::-1,...])
True
numpy.flipud()
这个函数用于垂直方向翻转数组,即行方向翻转。
Examples
--------
>>> A = np.diag([1.0, 2, 3])
>>> A
array([[1., 0., 0.],
[0., 2., 0.],
[0., 0., 3.]])
>>> np.flipud(A)
array([[0., 0., 3.],
[0., 2., 0.],
[1., 0., 0.]])
>>> A = np.random.randn(2,3,5)
>>> np.all(np.flipud(A) == A[::-1,...])
True
>>> np.flipud([1,2])
array([2, 1])
numpy.fliplr()
这个函数用于水平方向翻转数组,即列方向翻转。
Examples
--------
>>> A = np.diag([1.,2.,3.])
>>> A
array([[1., 0., 0.],
[0., 2., 0.],
[0., 0., 3.]])
>>> np.fliplr(A)
array([[0., 0., 1.],
[0., 2., 0.],
[3., 0., 0.]])
>>> A = np.random.randn(2,3,5)
>>> np.all(np.fliplr(A) == A[:,::-1,...])
True
在使用这些函数时,需要确保数组的维度适合进行翻转。
数组的复制
Examples
--------
Create an array x, with a reference y and a copy z:
>>> x = np.array([1, 2, 3])
>>> y = x
>>> z = np.copy(x)
Note that, when we modify x, y changes, but not z:
>>> x[0] = 10
>>> x[0] == y[0]
True
>>> x[0] == z[0]
False
Note that, np.copy clears previously set WRITEABLE=False flag.
>>> a = np.array([1, 2, 3])
>>> a.flags["WRITEABLE"] = False
>>> b = np.copy(a)
>>> b.flags["WRITEABLE"]
True
>>> b[0] = 3
>>> b
array([3, 2, 3])
Note that np.copy is a shallow copy and will not copy object
elements within arrays. This is mainly important for arrays
containing Python objects. The new array will contain the
same object which may lead to surprises if that object can
be modified (is mutable):
>>> a = np.array([1, 'm', [2, 3, 4]], dtype=object)
>>> b = np.copy(a)
>>> b[2][0] = 10
>>> a
array([1, 'm', list([10, 3, 4])], dtype=object)
To ensure all elements within an ``object`` array are copied,
use `copy.deepcopy`:
>>> import copy
>>> a = np.array([1, 'm', [2, 3, 4]], dtype=object)
>>> c = copy.deepcopy(a)
>>> c[2][0] = 10
>>> c
array([1, 'm', list([10, 3, 4])], dtype=object)
>>> a
array([1, 'm', list([2, 3, 4])], dtype=object)
数组的排序
Examples
--------
>>> a = np.array([[1,4],[3,1]])
>>> np.sort(a) # sort along the last axis
array([[1, 4],
[1, 3]])
>>> np.sort(a, axis=None) # sort the flattened array
array([1, 1, 3, 4])
>>> np.sort(a, axis=0) # sort along the first axis
array([[1, 1],
[3, 4]])
Use the `order` keyword to specify a field to use when sorting a
structured array:
>>> dtype = [('name', 'S10'), ('height', float), ('age', int)]
>>> values = [('Arthur', 1.8, 41), ('Lancelot', 1.9, 38),
... ('Galahad', 1.7, 38)]
>>> a = np.array(values, dtype=dtype) # create a structured array
>>> np.sort(a, order='height') # doctest: +SKIP
array([('Galahad', 1.7, 38), ('Arthur', 1.8, 41),
('Lancelot', 1.8999999999999999, 38)],
dtype=[('name', '|S10'), ('height', '<f8'), ('age', '<i4')])
Sort by age, then height if ages are equal:
>>> np.sort(a, order=['age', 'height']) # doctest: +SKIP
array([('Galahad', 1.7, 38), ('Lancelot', 1.8999999999999999, 38),
('Arthur', 1.8, 41)],
dtype=[('name', '|S10'), ('height', '<f8'), ('age', '<i4')])
数组的数学操作
加法
>>> added_arr = arr1 + arr2
减法
>>> subtracted_arr = arr1 - arr2
乘法
>>> multiplied_arr = arr1 * arr2
除法
>>> divided_arr = arr1 / arr2
幂运算
>>> power_arr = np.power(arr1, arr2)
数组的统计操作
均值
mean = np.mean(arr)
Examples
--------
>>> a = np.array([[1, 2], [3, 4]])
>>> np.mean(a)
2.5
>>> np.mean(a, axis=0)
array([2., 3.])
>>> np.mean(a, axis=1)
array([1.5, 3.5])
In single precision, `mean` can be inaccurate:
>>> a = np.zeros((2, 512*512), dtype=np.float32)
>>> a[0, :] = 1.0
>>> a[1, :] = 0.1
>>> np.mean(a)
0.54999924
Computing the mean in float64 is more accurate:
>>> np.mean(a, dtype=np.float64)
0.55000000074505806 # may vary
Specifying a where argument:
>>> a = np.array([[5, 9, 13], [14, 10, 12], [11, 15, 19]])
>>> np.mean(a)
12.0
>>> np.mean(a, where=[[True], [False], [False]])
9.0
方差
var = np.var(arr)
Examples
--------
>>> a = np.array([[1, 2], [3, 4]])
>>> np.var(a)
1.25
>>> np.var(a, axis=0)
array([1., 1.])
>>> np.var(a, axis=1)
array([0.25, 0.25])
In single precision, var() can be inaccurate:
>>> a = np.zeros((2, 512*512), dtype=np.float32)
>>> a[0, :] = 1.0
>>> a[1, :] = 0.1
>>> np.var(a)
0.20250003
Computing the variance in float64 is more accurate:
>>> np.var(a, dtype=np.float64)
0.20249999932944759 # may vary
>>> ((1-0.55)**2 + (0.1-0.55)**2)/2
0.2025
Specifying a where argument:
>>> a = np.array([[14, 8, 11, 10], [7, 9, 10, 11], [10, 15, 5, 10]])
>>> np.var(a)
6.833333333333333 # may vary
>>> np.var(a, where=[[True], [True], [False]])
4.0
标准差
std = np.std(arr)
Examples
--------
>>> a = np.array([[1, 2], [3, 4]])
>>> np.std(a)
1.1180339887498949 # may vary
>>> np.std(a, axis=0)
array([1., 1.])
>>> np.std(a, axis=1)
array([0.5, 0.5])
In single precision, std() can be inaccurate:
>>> a = np.zeros((2, 512*512), dtype=np.float32)
>>> a[0, :] = 1.0
>>> a[1, :] = 0.1
>>> np.std(a)
0.45000005
Computing the standard deviation in float64 is more accurate:
>>> np.std(a, dtype=np.float64)
0.44999999925494177 # may vary
Specifying a where argument:
>>> a = np.array([[14, 8, 11, 10], [7, 9, 10, 11], [10, 15, 5, 10]])
>>> np.std(a)
2.614064523559687 # may vary
>>> np.std(a, where=[[True], [True], [False]])
2.0
最大值、最小值
max_value = np.max(arr)
Examples
--------
>>> a = np.arange(4).reshape((2,2))
>>> a
array([[0, 1],
[2, 3]])
>>> np.amax(a) # Maximum of the flattened array
3
>>> np.amax(a, axis=0) # Maxima along the first axis
array([2, 3])
>>> np.amax(a, axis=1) # Maxima along the second axis
array([1, 3])
>>> np.amax(a, where=[False, True], initial=-1, axis=0)
array([-1, 3])
>>> b = np.arange(5, dtype=float)
>>> b[2] = np.NaN
>>> np.amax(b)
nan
>>> np.amax(b, where=~np.isnan(b), initial=-1)
4.0
>>> np.nanmax(b)
4.0
You can use an initial value to compute the maximum of an empty slice, or
to initialize it to a different value:
>>> np.amax([[-50], [10]], axis=-1, initial=0)
array([ 0, 10])
Notice that the initial value is used as one of the elements for which the
maximum is determined, unlike for the default argument Python's max
function, which is only used for empty iterables.
>>> np.amax([5], initial=6)
6
>>> max([5], default=6)
5
min_value = np.min(arr)
Examples
--------
>>> a = np.arange(4).reshape((2,2))
>>> a
array([[0, 1],
[2, 3]])
>>> np.amin(a) # Minimum of the flattened array
0
>>> np.amin(a, axis=0) # Minima along the first axis
array([0, 1])
>>> np.amin(a, axis=1) # Minima along the second axis
array([0, 2])
>>> np.amin(a, where=[False, True], initial=10, axis=0)
array([10, 1])
>>> b = np.arange(5, dtype=float)
>>> b[2] = np.NaN
>>> np.amin(b)
nan
>>> np.amin(b, where=~np.isnan(b), initial=10)
0.0
>>> np.nanmin(b)
0.0
>>> np.amin([[-50], [10]], axis=-1, initial=0)
array([-50, 0])
Notice that the initial value is used as one of the elements for which the
minimum is determined, unlike for the default argument Python's max
function, which is only used for empty iterables.
Notice that this isn't the same as Python's ``default`` argument.
>>> np.amin([6], initial=5)
5
>>> min([6], default=5)
6
相关文章:
Python Numpy入门基础(二)数组操作
入门基础(二) NumPy是Python中一个重要的数学运算库,它提供了了一组多维数组对象和一组用于操作这些数组的函数。以下是一些NumPy的主要特点: 多维数组对象:NumPy的核心是ndarray对象,它是一个多维数组对…...
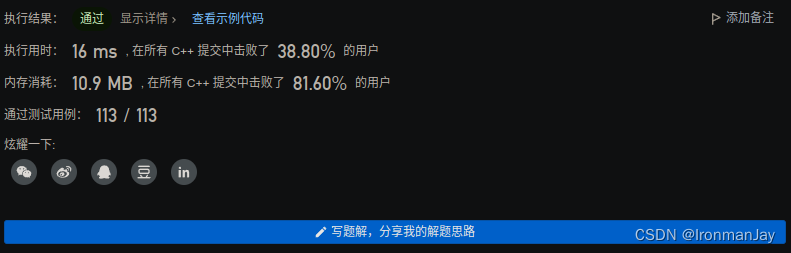
【LeetCode每日一题】——1572.矩阵对角线元素的和
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时间频度】九【代码实现】十【提交结果】 一【题目类别】 矩阵 二【题目难度】 简单 三【题目编号】 1572.矩阵对角线元素的和 四【题目描述】 给你一…...

牛客网Verilog刷题——VL55
牛客网Verilog刷题——VL55 题目答案 题目 请用Verilog实现4位约翰逊计数器(扭环形计数器),计数器的循环状态如下: 电路的接口如下图所示: 输入输出描述: 信号类型输入/输出位宽描述clkwireInput1系统…...
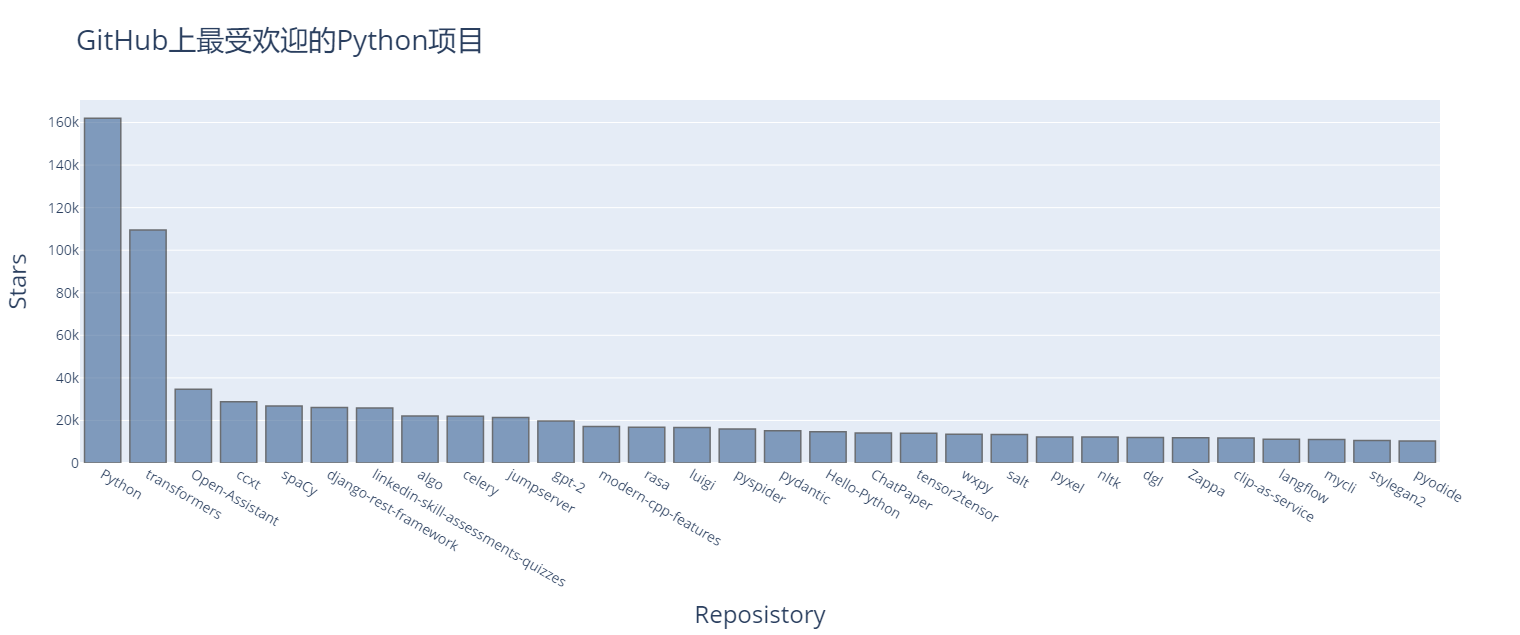
python中数据可视化
1.掷一个D6和一个D10 50000次的结果 die.py from random import randintclass Die:def __init__(self, num_sides6):self.num_sides num_sidesdef roll(self):return randint(1, self.num_sides) die_visual.py from die import Die from plotly.graph_objs import Bar, L…...

DASCTF 2023 0X401七月暑期挑战赛web复现
目录 <1> Web (1) EzFlask(python原型链污染&flask-pin) (2) MyPicDisk(xpath注入&文件名注入) (3) ez_cms(pearcmd文件包含) (4) ez_py(django框架 session处pickle反序列化) <1> Web (1) EzFlask(python原型链污染&flask-pin) 进入题目 得到源…...
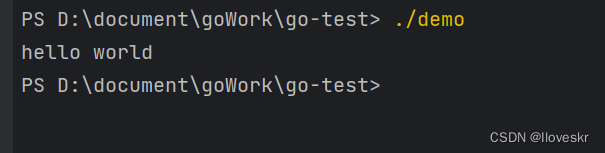
go编译文件
1.编译go文件 go build [go文件]2.执行文件编译文件 ./demo [demo为go文件名称]...
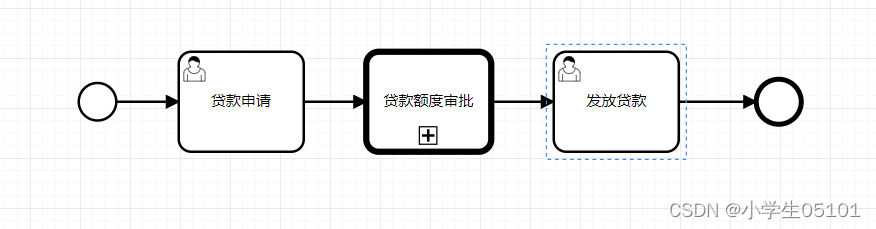
Flowable-子流程-调用活动
目录 定义图形标记XML内容界面操作使用示例子流程设计子流程的XML内容主流程设计主流程的XML内容 视频教程 定义 调用活动是在一个流程定义中调用另一个独立的流程定义,通常可以定义一些通用的流程作为 这种调用子流程,供其他多个流程定义复用。这种子流…...

java 并发
目录 什么是线程?什么是进程?为什么要有线程?有什么关系与区别?什么是守护线程?如何创建、启动 Java 线程?线程池参数详细解释Callable接口和Future类偏向锁 / 轻量级锁 / 重量级锁synchronized 和 java.ut…...
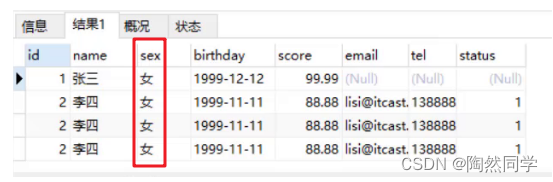
【MySQL】DDL和DML
4,DDL:操作数据库 我们先来学习DDL来操作数据库。而操作数据库主要就是对数据库的增删查操作。 4.1 查询 查询所有的数据库 SHOW DATABASES; 运行上面语句效果如下: 上述查询到的是的这些数据库是mysql安装好自带的数据库,我们以后不要操…...

使用python框架FastAPI
中文文档 Python ORM之SQLAlchemy Fastapi大型项目目录规划 SQL数据库操作 依赖项Depends 待看 和APIRouter from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmakerapp FastAPI()SQ…...
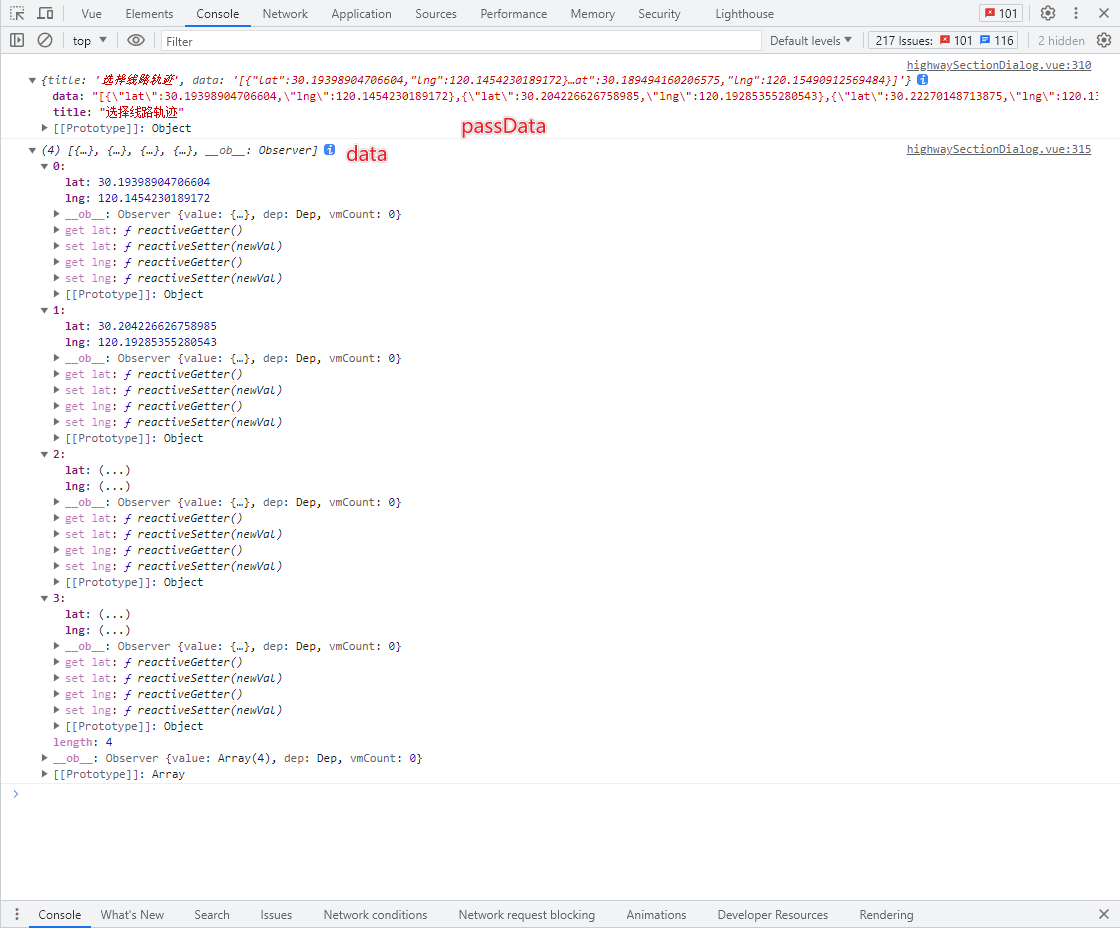
Vue实现leafletMap自定义绘制线段 并且删除指定的已绘制的点位
效果:点击表格可实现选中地图点位,删除按钮点击可删除对应点位并且重新绘制线段,点击确定按钮 保存已经绘制的点位信息传给父组件 并且该组件已实现回显 完整的组件代码如下 文件名称为: leafletMakePointYt <!--* Descripti…...

ChatGPT辅助写论文:提升效率与创造力的利器
写作是人类最重要的交流方式之一,也是学术研究中不可或缺的环节。然而,写作并不是一件容易的事情,尤其是对于科研人员来说,他们需要花费大量的时间和精力来撰写高质量的论文,并且面临着各种各样的挑战,如语…...
)
面试攻略,Java 基础面试 100 问(六)
JAVA 泛型 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本 质是参数化类型,也就是说所操作的数据类型被指定为一个参数。比如我们要写一个排序方法, 能够对整型数组、字符串数组甚至其他任何类型的…...
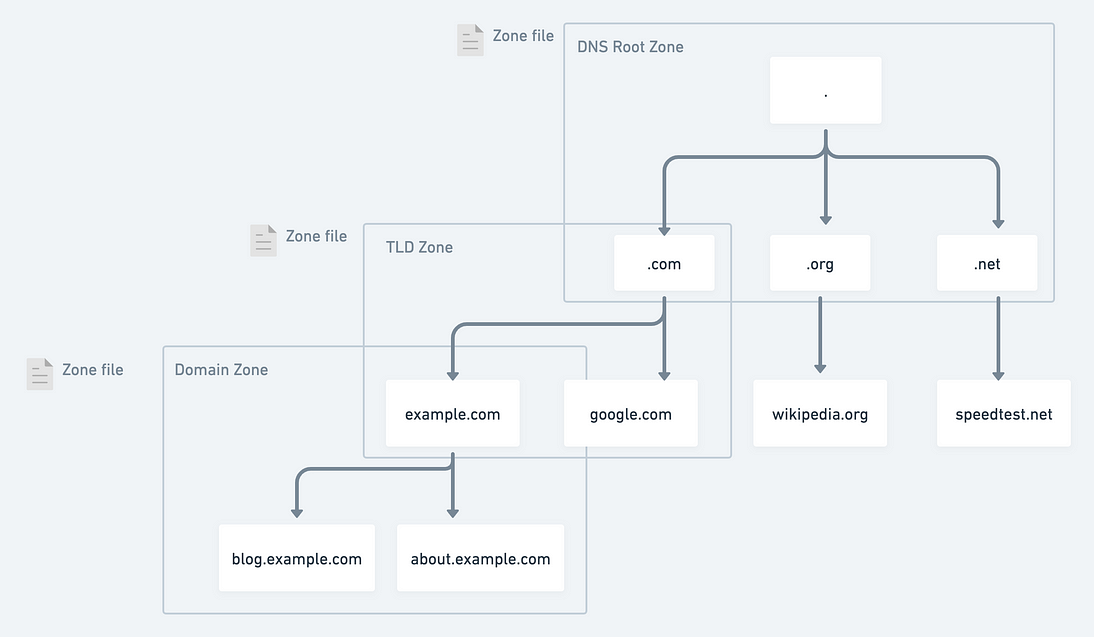
图解系列 DNS查找过程和DNS缓存
DNS 充当地址簿。它将人类可读的域名 (google.com) 转换为机器可读的 IP 地址 (142.251.46.238)。 开局一张图 来自:https://xiaolishen.medium.com/the-dns-lookup-journey-240e9a5d345c 寻址流程 查询浏览器缓存:当你输入一个域名后,浏览…...
《吐血整理》高级系列教程-吃透Fiddler抓包教程(21)-如何使用Fiddler生成Jmeter脚本-上篇
1.简介 我们知道Jmeter本身可以录制脚本,也可以通过BadBoy,BlazeMeter等工具进行录制,其实Fiddler也可以录制Jmter脚本(而且有些页面,由于安全设置等原因,使用Jmeter直接无法打开录制时,这时就…...

vim中出现复制不对齐-乱码问题
不对齐解决: 使用纯文本模式粘贴:在进入 Vim 编辑器后,先按下 :set paste 进入插入模式,然后再进行粘贴操作。这样可以确保粘贴的文本以纯文本格式插入,而不会触发自动缩进或其他格式化操作 中文乱码问题:…...

华为OD机考真题--单词接龙--带答案
2023华为OD统一考试(AB卷)题库清单-带答案(持续更新)or2023年华为OD真题机考题库大全-带答案(持续更新) 题目描述: 单词接龙的规则是: 用于接龙的单词首字母必须要前一个单词的尾字母…...
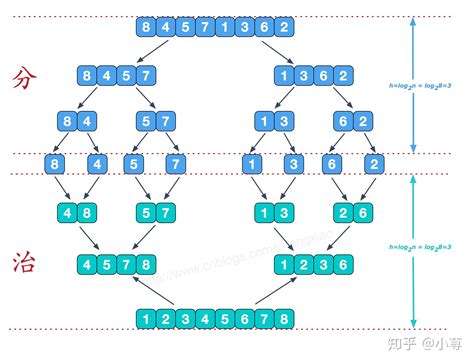
排序进行曲-v3.0
文章目录 小程一言归并排序步骤举例总结时间复杂度分析:空间复杂度分析:注意 应用场景总结 实际举例Other 代码实现结果解释 小程一言 这篇文章是在排序进行曲2.0之后的续讲, 这篇文章主要是对归并排序进行细致分析,以及操作。 希…...
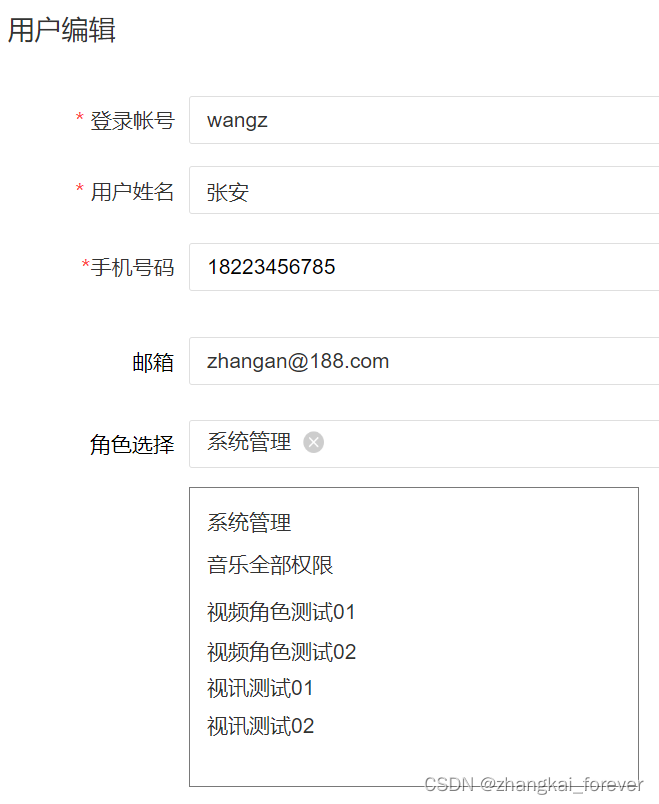
编辑列表操作时的一些思考,关于全量和增量操作
假设我有一个这样的页面,需要对用户的信息做编辑操作 角色下面有一些菜单项,通过一张角色-菜单关系表来维护,那么我要在编辑用户后也要对用户角色关系表做修改,是经过两次比较分别计算出需要增加或者删除的角色用户关系࿰…...
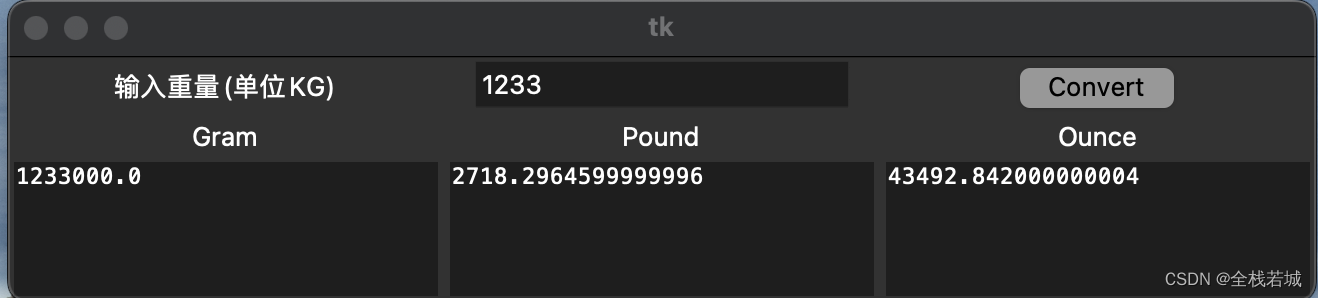
【python】Python tkinter库实现重量单位转换器的GUI程序
文章目录 前言学到什么?导入模块和库创建一个GUI窗口定义函数 from_kg()创建标签、输入框、文本框和按钮设置组件的布局运行窗口循环完整代码运行效果结束语 前言 这段代码是一个简单的重量单位转换器的 GUI 程序,使用了 Python 的 tkinter 库来创建图形界面。该程…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

Unity项目DrawCall降不下来?试试用Mesh Baker合并贴图集,保姆级图文教程
Unity性能优化实战:用Mesh Baker合并贴图集降低DrawCall全流程解析当你的Unity项目帧率开始卡顿,Profiler里DrawCall数字居高不下时,合并贴图集往往是解决问题的关键一步。本文将以一个实际项目为例,带你从零开始使用Mesh Baker的…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...

XXPermissions:Android权限管理框架的架构设计与最佳实践
XXPermissions:Android权限管理框架的架构设计与最佳实践 【免费下载链接】XXPermissions Android Permissions Framework, Adapt to Android 16 项目地址: https://gitcode.com/GitHub_Trending/xx/XXPermissions 在Android应用开发中,权限管理一…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...