自然语言文本分类模型代码
以下是一个基于PyTorch的文本分类模型的示例代码,用于将给定的文本分为多个预定义类别:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TextClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, num_layers, bidirectional, dropout):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, bidirectional=bidirectional, dropout=dropout)self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, text, text_lengths):embedded = self.dropout(self.embedding(text))packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.to('cpu'), enforce_sorted=False)packed_output, (hidden, cell) = self.rnn(packed_embedded)output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1) if self.rnn.bidirectional else hidden[-1,:,:])return self.fc(hidden.squeeze(0))
该模型将输入的文本作为整数序列传递给嵌入层,然后通过多层LSTM层进行处理,最终输出每个类别的预测概率。
在训练模型之前,需要将文本序列转换为整数标记,通常使用分词器/标记器完成此任务。另外还需要定义优化器和损失函数来训练模型。
以下是一个完整的训练脚本的示例:
import torch.optim as optim
from torchtext.datasets import AG_NEWS
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torch.utils.data import DataLoader
from torchtext.data.utils import ngrams_iterator
from torchtext.data.utils import get_tokenizer
from torch.utils.data.dataset import random_split
from collections import Counter# 获取数据集和分词器
train_iter = AG_NEWS(split='train')
tokenizer = get_tokenizer('basic_english')# 构建词汇表
counter = Counter()
for (label, line) in train_iter:counter.update(tokenizer(line))
vocab = build_vocab_from_iterator([counter])
vocab.set_default_index(vocab['<unk>'])# 定义标记化函数和文本处理函数
def yield_tokens(data_iter):for _, text in data_iter:yield tokenizer(text)def text_transform(tokenizer, vocab, data):"""将文本数据转换为张量数据"""data = [vocab[token] for token in tokenizer(data)]return torch.tensor(data)# 定义批次生成器
def collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_label, _text) in batch:label_list.append(_label-1)processed_text = torch.cat([text_transform(tokenizer, vocab, _text), torch.tensor([vocab['<eos>']])])text_list.append(processed_text)offsets.append(processed_text.size(0))label_list = torch.tensor(label_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)text_list = torch.cat(text_list)return label_list, text_list, offsets# 构建数据集和数据加载器
train_iter, test_iter = AG_NEWS()
train_iter = list(train_iter)
test_iter = list(test_iter)
train_dataset = list(map(lambda x: (x[0], x[1]), train_iter))
test_dataset = list(map(lambda x: (x[0], x[1]), test_iter))
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, collate_fn=collate_batch)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True, collate_fn=collate_batch)# 创建模型和优化器
model = TextClassifier(len(vocab), 64, 128, 4, 2, True, 0.5)
optimizer = optim.Adam(model.parameters())# 定义损失函数和训练函数
criterion = nn.CrossEntropyLoss()def train(model, iterator, optimizer, criterion):epoch_loss = 0model.train()for (label, text, offsets) in iterator:optimizer.zero_grad()predictions = model(text, offsets)loss = criterion(predictions, label)loss.backward()optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)# 训练模型
N_EPOCHS = 10
for epoch in range(N_EPOCHS):train_loss = train(model, train_loader, optimizer, criterion)print(f'Epoch: {epoch+1:02} | Train Loss: {train_loss:.3f}')
在训练过程结束后,可以使用该模型对新的文本进行分类。具体方法是将文本转换为整数标记序列,然后使用模型进行预测:
# 对新文本进行分类
def predict(model, sentence):model.eval()tokenized = torch.tensor([vocab[token] for token in tokenizer(sentence)])length = torch.tensor([len(tokenized)])prediction = model(tokenized, length)return F.softmax(prediction, dim=1).detach().numpy()[0]# 进行预测
test_sentence = "World markets are reacting to the news that the UK is set to leave the European Union."
pred_probs = predict(model, test_sentence)
print(pred_probs)
以上代码示例中使用了AG_NEWS数据集作为示例训练数据,可通过以下方式加载数据集:
from torchtext.datasets import AG_NEWS
train_iter = AG_NEWS(split='train')
test_iter = AG_NEWS(split='test')
该数据集包含四个类别的新闻数据,每个类别各有120,000个训练示例和7,600个测试示例。完整的训练脚本和数据集可以在PyTorch官方文档中找到。
相关文章:

自然语言文本分类模型代码
以下是一个基于PyTorch的文本分类模型的示例代码,用于将给定的文本分为多个预定义类别: import torch import torch.nn as nn import torch.nn.functional as Fclass TextClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_…...
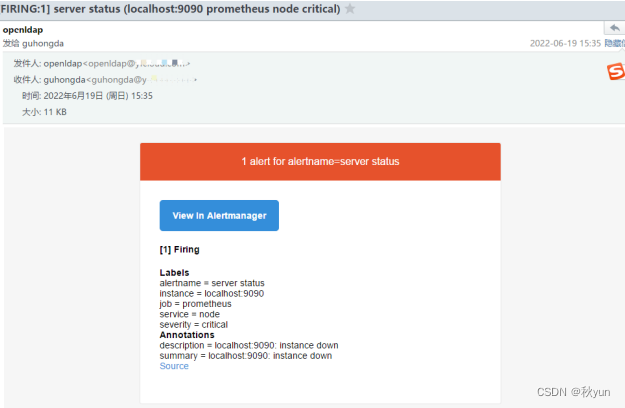
Prometheus实现系统监控报警邮件
Prometheus实现系统监控报警邮件 简介 Prometheus将数据采集和报警分成了两个模块。报警规则配置在Prometheus Servers上, 然后发送报警信息到AlertManger,然后我们的AlertManager就来管理这些报警信息,聚合报警信息过后通过email、PagerDu…...

could not import go.etcd.io/etcd/clientv3-go
问题描述 今天在封装etcd的时候导包报错: could not import go.etcd.io/etcd/clientv3 (no required module provides package "go.etcd.io/etcd/clientv3") 问题解决: get:确保下载了client包 go get go.etcd.io/etcd/client tidy go mod tidy 本文由 mdnice 多平台…...

MySQL的行锁、表锁触发
MySQL的行锁、表锁触发 sql CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR(50), stock INT ); INSERT INTO products (product_id, product_name, stock) VALUES (1001, ‘商品A’, 50), (1002, ‘商品B’, 30), (1003, ‘商品C’, 20); 一、行锁…...

mysql-入门笔记-3
# ----------排序查询-------- # 语法 # select 字段列表 from 表名 order by 字段1 排序方式1 ,字段2 排序方式2 ; DESC 降序 ASC升序 # 1 根据年龄对公司的员工进行升序排序---默认升序-黄色提示代码冗余 select * from userTable order by age ASC ; # 2 根据入职时间,对员…...

3分钟创建超实用的中小学新生录取查询系统,现在可以实现了
在新学期开始之际,作为招生负责人,您是否已经做好准备来迎接新学年的招生工作呢?录取新生所需的任务包括录入成绩信息、核对招生要求以及公布新生录取信息等,这些工作繁重而具有挑战性,给负责招生的老师带来了巨大的压…...
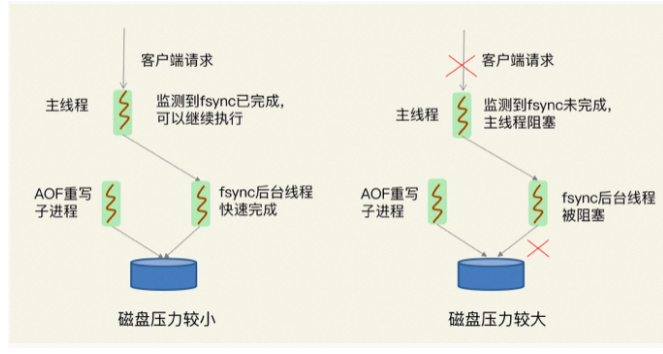
Redis 变慢了 解决方案
一、Redis为什么变慢了 1.Redis真的变慢了吗? 对 Redis 进行基准性能测试 例如,我的机器配置比较低,当延迟为 2ms 时,我就认为 Redis 变慢了,但是如果你的硬件配置比较高,那么在你的运行环境下ÿ…...
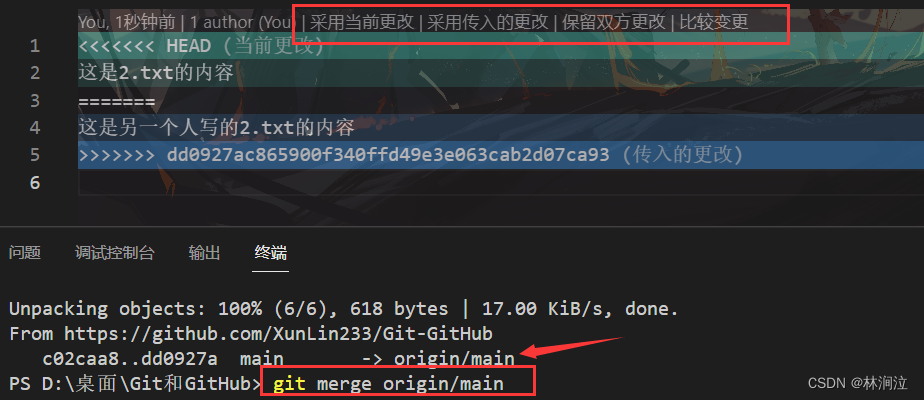
远程仓库的操作
一、远程仓库的操作命令 git remote # 查看当前项目关联的远程库 我事先关联了一个GitHub的远程仓库,关于如何关联远程仓库,可以看这篇文章远程仓库GitHub和Gitee_林涧泣的博客-CSDN博客 git remote add [仓库服务器名] [远程仓库地址] # 关联远程仓库…...

一个监控系统的典型架构
监控系统的典型架构图,从左往右看,采集器是负责采集监控数据的,采集到数据之后传输给服务端,通常是直接写入时序库。然后就是对时序库的数据进行分析和可视化,分析部分最典型的就是告警规则判断,即图上的告…...

让GPT人工智能变身常用工具-中
...
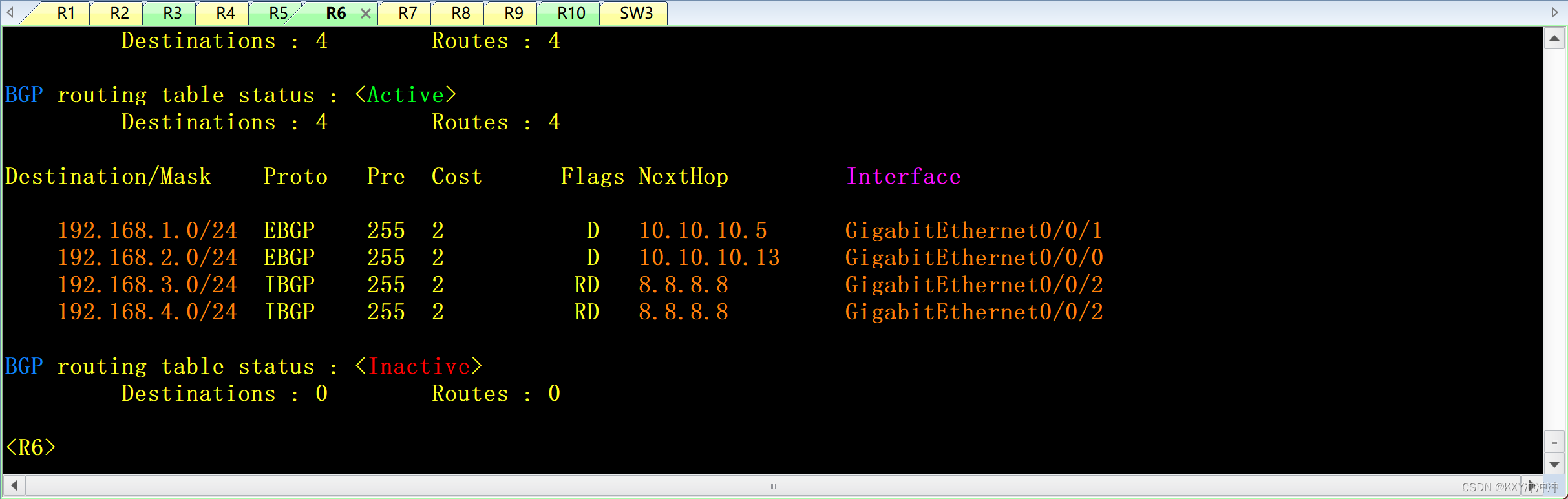
HCIP中期实验
1、该拓扑为公司网络,其中包括公司总部、公司分部以及公司骨干网,不包含运营商公网部分。 2、设备名称均使用拓扑上名称改名,并且区分大小写。 3、整张拓扑均使用私网地址进行配置。 4、整张网络中,运行OSPF协议或者BGP协议的设备…...

《向量数据库指南》——向量数据库Milvus Cloud、Pinecone、Vespa、Weaviate、Vald、GSI 、 Qdrant选哪个?
1、Milvus Cloud(https://milvuscloud.com) Milvus是一个开源的向量数据库,支持高效的向量搜索和相似度匹配。它针对大规模向量数据集的性能进行了优化,并提供了Python、Java、Go和C++等多种语言的客户端接口。Milvus在图像、音频、文本和推荐等领域都有广泛的应用。 2…...
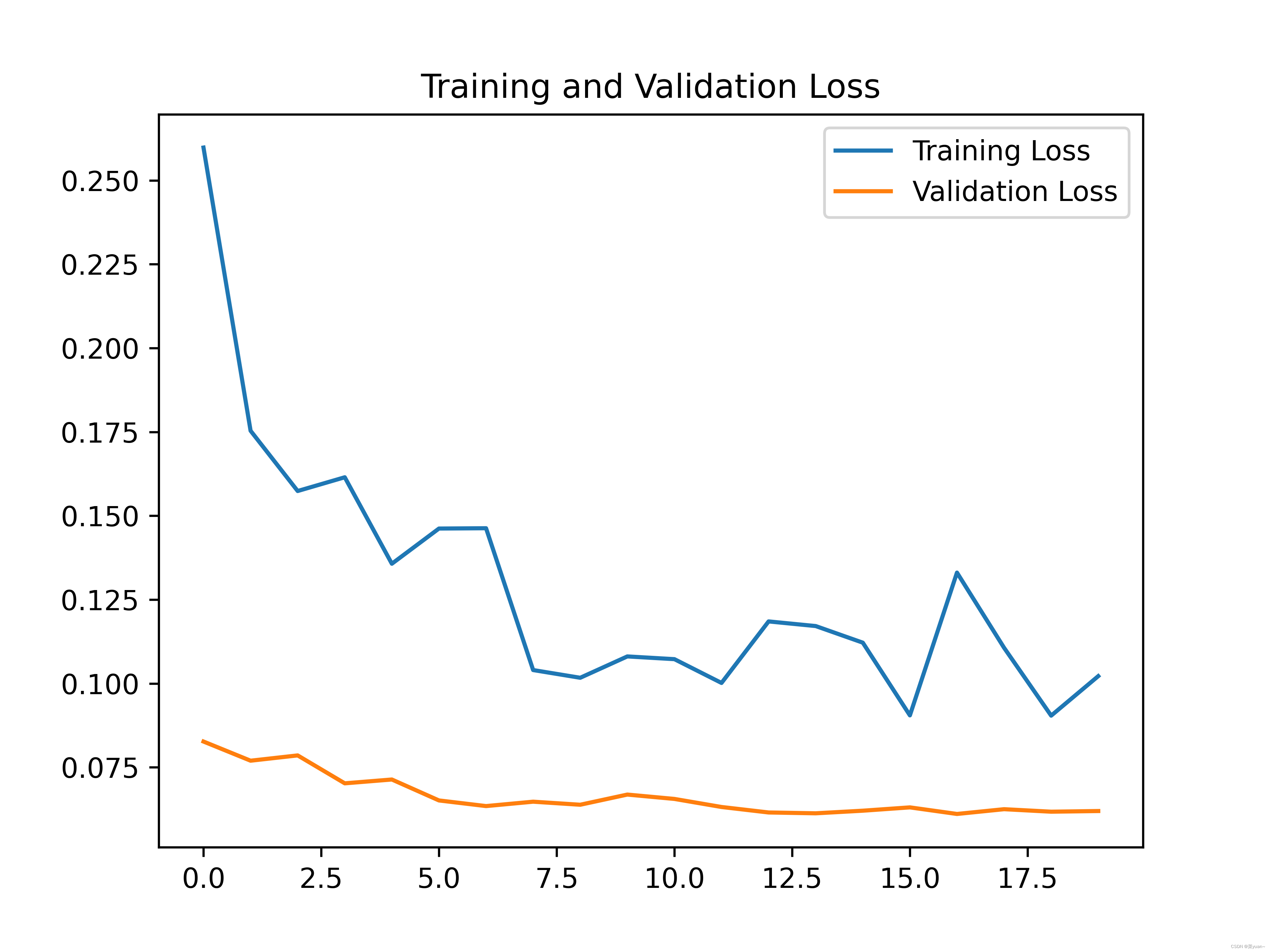
python与深度学习(十一):CNN和猫狗大战
目录 1. 说明2. 猫狗大战2.1 导入相关库2.2 建立模型2.3 模型编译2.4 数据生成器2.5 模型训练2.6 模型保存2.7 模型训练结果的可视化 3. 猫狗大战的CNN模型可视化结果图4. 完整代码5. 猫狗大战的迁移学习 1. 说明 本篇文章是CNN的另外一个例子,猫狗大战,…...

经典CNN(三):DenseNet算法实战与解析
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊|接辅导、项目定制 1 前言 在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如GoogleNet,…...
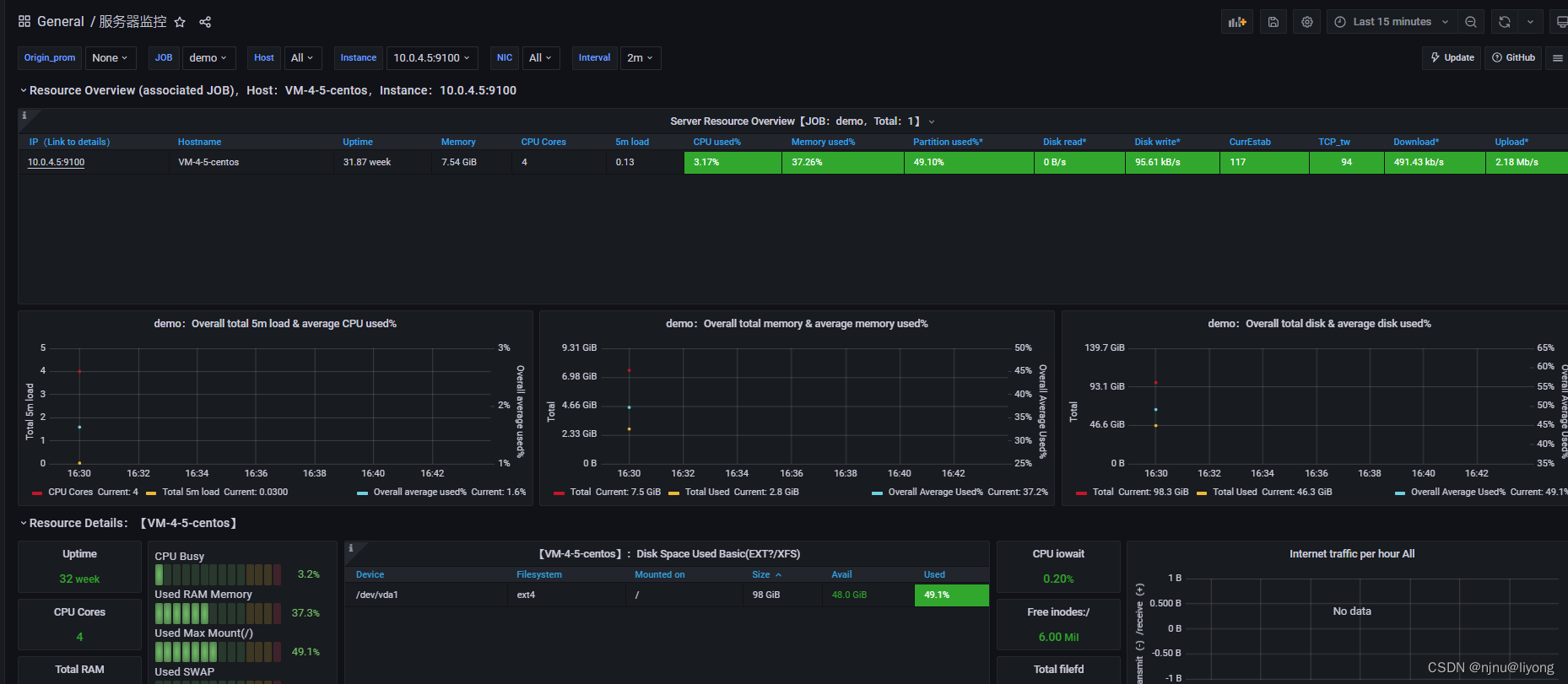
学习笔记——压力测试案例,监控平台
测试案例 # 最简单的部署方式直接单机启动 nohup java -jar lesson-one-0.0.1-SNAPSHOT.jar > ./server.log 2>&1 &然后配置执行计划: 新建一个执行计划 配置请求路径 配置断言配置响应持续时间断言 然后配置一些查看结果的统计报表或者图形 然后我…...

sqlite 踩坑
内存数据库 强制SQLite数据库单纯的存在于内存中的常用方法是使用特殊文件名“ :memory: ” db QSqlDatabase::addDatabase("QSQLITE", "MEMORY"); db.setDatabaseName(":memory:"); 调用此接口完成后,不…...
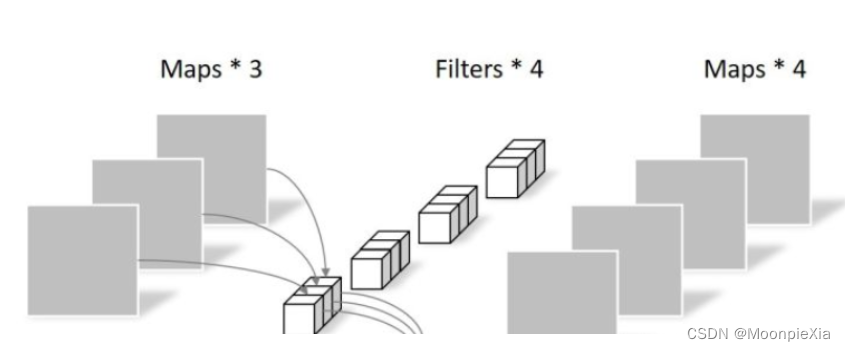
【论文笔记】神经网络压缩调研
神经网络压缩调研 背景现有的深度模型压缩方法NetWork Prunning 网络剪枝设计结构化矩阵知识蒸馏权值共享Parameter Quantization(参数量化)量化和二进制化伪量化Architecture Design(Depth Separable Convolution)分解卷积 背景 …...

红外NEC通信协议
一、NEC简介 红外(Infrared,IR)遥控是一种无线、非接触控制技术,常用于遥控器、无线键盘、鼠标等设备之间的通信。IR协议的工作原理是,发送方通过红外线发送一个特定的编码,接收方通过识别该编码来执行相应的操作。 IR协议是指红外…...

数据分析DAY1
数据分析 引言 这一周:学习了python的numpy和matplotlib以及在飞桨paddle上面做了几个小项目 发现numpy和matplotlib里面有很多api,要全部记住是不可能的,也是不可能全部学完的,所以我们要知道并且熟悉一些常用的api࿰…...

算法通关村—迭代实现二叉树的前序,中序,后序遍历
1. 前序中序后序递归写法 前序 public void preorder(TreeNode root, List<Integer> res) {if (root null) {return;}res.add(root.val);preorder(root.left, res);preorder(root.right, res);}后序 public static void postOrderRecur(TreeNode head) {if (head nu…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...

NanaZip:现代Windows文件压缩问题的终极解决方案
NanaZip:现代Windows文件压缩问题的终极解决方案 【免费下载链接】NanaZip The 7-Zip derivative intended for the modern Windows experience 项目地址: https://gitcode.com/gh_mirrors/na/NanaZip 还在为Windows文件压缩工具界面老旧、功能单一而烦恼吗&…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...