数据分析DAY1
数据分析
引言
这一周:学习了python的numpy和matplotlib以及在飞桨paddle上面做了几个小项目
发现numpy和matplotlib里面有很多api,要全部记住是不可能的,也是不可能全部学完的,所以我们要知道并且熟悉一些常用的api,并且学到哪用到哪,遇到不会的api也不要害怕,直接去网上查找或者自己尝试着摸索就可以了的,代码也不需要特别死扣,思路是最重要的。
什么是数据分析?
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
使用python做数据分析的常用库
- numpy 基础数值算法
- matplotlib 数据可视化
- pandas 序列高级函数
numpy的核心:多维数组
- 代码简洁:减少Python代码中的循环。
- 底层实现:厚内核©+薄接口(Python),保证性能。
numpy基础
ndarray数组
用np.ndarray类的对象表示n维数组
import numpy as np
ary = np.array([1, 2, 3, 4, 5, 6])
print(type(ary))#<class 'numpy.ndarray'>内存中的ndarray对象
元数据(metadata)
存储对目标数组的描述信息,如:dim count、dimensions、dtype、data等。
实际数据
完整的数组数据[1,2,3,4,5,6]
将实际数据与元数据分开存放,一方面提高了内存空间的使用效率,另一方面减少对实际数据的访问频率,提高性能。
ndarray数组对象的特点
- Numpy数组是同质数组,即所有元素的数据类型必须相同
- Numpy数组的下标从0开始,最后一个元素的下标为数组长度减1
ndarray数组对象的创建
np.array(任何可被解释为Numpy数组的逻辑结构)
import numpy as np
a = np.array([1, 2, 3, 4, 5, 6])
print(a)
np.arange(起始值(0),终止值,步长(1))
import numpy as np
a = np.arange(0, 5, 1)
print(a)
b = np.arange(0, 10, 2)
print(b)#默认生成每一个元素的维度都是一维的,而且它每一个元素的是默认的int32
np.zeros(数组元素个数, dtype=‘类型’)
import numpy as np
a = np.zeros(10)
print(a)#默认生成每一个元素的是float64,默认0.
np.ones(数组元素个数, dtype=‘类型’)
import numpy as np
a = np.ones(10)
print(a)#默认生成的每一个元素都是float64,都是1.
# 构建一个结构与a1相同的全0数组
print(np.zeros_like(a1))
# 构建一个结构与a3相同的全1数组
print(np.ones_like(a3))#维度是一样的
ndarray对象属性的基本操作
**数组的维度:**np.ndarray.shape
import numpy as np
ary = np.array([1, 2, 3, 4, 5, 6])
print(type(ary), ary, ary.shape)
#二维数组
ary = np.array([[1,2,3,4],[5,6,7,8]
])
print(type(ary), ary, ary.shape)
**元素的类型:**np.ndarray.dtype
import numpy as np
ary = np.array([1, 2, 3, 4, 5, 6])
print(type(ary), ary, ary.dtype)
#转换ary元素的类型
b = ary.astype(float)
print(type(b), b, b.dtype)
#转换ary元素的类型
c = ary.astype(str)
print(type(c), c, c.dtype)
**数组元素的个数:**np.ndarray.size
import numpy as np
ary = np.array([[1,2,3,4],[5,6,7,8]
])
#观察维度,size,len的区别
print(ary.shape, ary.size, len(ary))
#shape指的是数组的维度,size指的是数组的元素个数,len指的是数组的行数
数组元素索引(下标)
数组对象[…, 页号, 行号, 列号]
下标从0开始,到数组len-1结束。
import numpy as np
a = np.array([[[1, 2],[3, 4]],[[5, 6],[7, 8]]])
print(a, a.shape)#(3,2,2)
print(a[0])#第一页
print(a[0][0])#第一页第一行
print(a[0][0][0])#第一页第一行第一列
print(a[0, 0, 0])#第二种写法
#当是三维数组的时候,循环遍历每一个元素
for i in range(a.shape[0]):#页数for j in range(a.shape[1]):#行数for k in range(a.shape[2]):#列数print(a[i, j, k])#访问每一个元素
ndarray对象属性操作详解
Numpy的内部基本数据类型
| 类型名 | 类型表示符 |
|---|---|
| 布尔型 | bool_ |
| 有符号整数型 | int8(-128~127)/int16/int32/int64 |
| 无符号整数型 | uint8(0~255)/uint16/uint32/uint64 |
| 浮点型 | float16/float32/float64 |
| 复数型 | complex64/complex128 |
| 字串型 | str_,每个字符用32位Unicode编码表示 |
自定义复合类型
#如果不用这种方法,那么你也可以先创建一个类,里面有对象的各种属性,然后再创建一个对象列表,但是这样虽然思路上十分清晰,但是很耗时间,占内存,所以不建议使用这种方法,numpy里面虽然大部分只能用在数字上,但是也为此有了一种自定义复合类型。如果要访问属性的时候,只需要访问他的字段
# 自定义复合类型
import numpy as npdata=[('zs', [90, 80, 85], 15),('ls', [92, 81, 83], 16),('ww', [95, 85, 95], 15)
]
#第一种设置dtype的方式
a = np.array(data, dtype='U3, 3int32, int32')
print(a)
print(a[0][0],:,a[0][1])
print(a[0]['f0'], ":", a[1]['f1'])
print("=====================================")
#第二种设置dtype的方式
b = np.array(data, dtype=[('name', 'str_', 2),('scores', 'int32', 3),('ages', 'int32', 1)])
print(b[0]['name'], ":", b[0]['scores'])
print("=====================================")#第三种设置dtype的方式
#最常用
c = np.array(data, dtype={'names': ['name', 'scores', 'ages'],'formats': ['U3', '3int32', 'int32']})
print(c[0]['name'], ":", c[0]['scores'], ":", c.itemsize)
print("=====================================")#第四种设置dtype的方式
d = np.array(data, dtype={'name': ('U3', 0),#数字代表的是偏移位置,单位是字节'scores': ('3i4', 16),'age': ('i4', 28)})
print(d[0]['name'], d[0]['scores'], d.itemsize)print("=====================================")
#测试日期类型数组
f = np.array(['2011', '2012-01-01', '2013-01-01 01:01:01','2011-02-01'])
f = f.astype('M8[D]')#把类型转化为只精确到天数的
f = f.astype('int32')
print(f[3]-f[0])#一个月31print("=====================================")
#复数
a = np.array([[1 + 1j, 2 + 4j, 3 + 7j],[4 + 2j, 5 + 5j, 6 + 8j],[7 + 3j, 8 + 6j, 9 + 9j]])
print(a.T)#进行转置for x in a.flat:#flat返回一个可迭代的一维数组print(x.array(a.flat))#[1.+1.j 2.+4.j 3.+7.j 4.+2.j 5.+5.j 6.+8.j 7.+3.j 8.+6.j 9.+9.j]print(x.imag)#得到每一个元素的虚部类型字符码
| 类型 | 字符码 |
|---|---|
| np.bool_ | ? |
| np.int8/16/32/64 | i1/i2/i4/i8 |
| np.uint8/16/32/64 | u1/u2/u4/u8 |
| np.float/16/32/64 | f2/f4/f8 |
| np.complex64/128 | c8/c16 |
| np.str_ | U<字符数> |
| np.datetime64 | M8[Y] M8[M] M8[D] M8[h] M8[m] M8[s]` |
类型字符码格式
<字节序前缀><维度><类型><字节数或字符数>
| 释义 | |
|---|---|
| 3i4 | 大端字节序,3个元素的一维数组,每个元素都是整型,每个整型元素占4个字节。 |
| <(2,3)u8 | 小端字节序,6个元素2行3列的二维数组,每个元素都是无符号整型,每个无符号整型元素占8个字节。 |
| U7 | 包含7个字符的Unicode字符串,每个字符占4个字节,采用默认字节序。 |
ndarray数组对象的维度操作
视图变维(数据共享): reshape() 与 ravel()
import numpy as np
a = np.arange(1, 9)
print(a) # [1 2 3 4 5 6 7 8]
b = a.reshape(2, 4)#一定要拿一个变量来接收 #视图变维 : 变为2行4列的二维数组
print(b)
a[0]=10000
print(b)
#[[10000 2 3 4]
# [ 5 6 7 8]]
c = b.reshape(2, 2, 2) #视图变维 变为2页2行2列的三维数组
print(c)
d = c.ravel() #视图变维 变为1维数组
print(d)
**复制变维(数据独立):**flatten()
e = c.flatten()
print(e)
c += 10
print(c, e, sep='\n')
就地变维:直接改变原数组对象的维度,不返回新数组
a.shape = (2, 4)
print(a)
a.resize(2, 2, 2)
print(a)
ndarray数组切片操作
#数组对象切片的参数设置与列表切片参数类似
# 步长+:默认切从首到尾
# 步长-:默认切从尾到首
数组对象[起始位置:终止位置:步长, ...]
#默认位置步长:1
import numpy as np
a = np.arange(1, 10)
print(a) # 1 2 3 4 5 6 7 8 9
print(a[:3]) # 1 2 3
print(a[3:6]) # 4 5 6
print(a[6:]) # 7 8 9
print(a[::-1]) # 9 8 7 6 5 4 3 2 1
print(a[:-4:-1]) # 9 8 7
print(a[-4:-7:-1]) # 6 5 4
print(a[-7::-1]) # 3 2 1
print(a[::]) # 1 2 3 4 5 6 7 8 9
print(a[:]) # 1 2 3 4 5 6 7 8 9
print(a[::3]) # 1 4 7
print(a[1::3]) # 2 5 8
print(a[2::3]) # 3 6 9
多维数组的切片操作
import numpy as np
a = np.arange(1, 28)
a.resize(3,3,3)
print(a)
#切出1页
print(a[1, :, :])
#切出所有页的第二行
print(a[:, 1, :])
#切出0页的第二列
print(a[0, :, 1])
ndarray数组的掩码操作
import numpy as np
a = np.arange(0, 10)
mask = [True, False,True, False,True, False,True, False,True, False]
print(a[mask])#得到True组成的数组
# bool掩码
a = np.arange(10)
mask = a % 2 == 0
print(a[mask])
print(a[a%2==0])
# 3与7的公倍数
a = np.arange(1, 100)
print(a[(a%3==0) & (a%7==0)])# 索引掩码
a = np.array([10, 20, 30, 40])
mask = [0,3,2,0,1,2,0,3,1,2,3,0,2]
print(a[mask])
#[10 40 30 10 20 30 10 40 20 30 40 10 30]
多维数组的组合与拆分
垂直方向操作:
import numpy as np
a = np.arange(1, 7).reshape(2, 3)
b = np.arange(7, 13).reshape(2, 3)
# 垂直方向完成组合操作,生成新数组
c = np.vstack((a, b))#上下组合
# 垂直方向完成拆分操作,生成两个数组
d, e = np.vsplit(c, 2)#水平拆分,第一个参数是待拆分的元素,第二个元素是待拆分的数组总数
水平方向操作:
import numpy as np
a = np.arange(1, 7).reshape(2, 3)
b = np.arange(7, 13).reshape(2, 3)
# 水平方向完成组合操作,生成新数组
c = np.hstack((a, b))
# 水平方向完成拆分操作,生成两个数组
d, e = np.hsplit(c, 2)
深度方向操作:(3维)
import numpy as np
a = np.arange(1, 7).reshape(2, 3)
b = np.arange(7, 13).reshape(2, 3)
# 深度方向(3维)完成组合操作,生成新数组
i = np.dstack((a, b))
# 深度方向(3维)完成拆分操作,生成两个数组
k, l = np.dsplit(i, 2)
多维数组组合与拆分的相关函数:
# 通过axis作为关键字参数指定组合的方向,取值如下:
# 若待组合的数组都是二维数组:
# 0: 垂直方向组合
# 1: 水平方向组合
# 若待组合的数组都是三维数组:
# 0: 垂直方向组合
# 1: 水平方向组合
# 2: 深度方向组合
np.concatenate((a, b), axis=0)
# 通过给出的数组与要拆分的份数,按照某个方向进行拆分,axis的取值同上
np.split(c, 2, axis=0)
长度不等的数组组合:
import numpy as np
a = np.array([1,2,3,4,5])
b = np.array([1,2,3,4])
# 填充b数组使其长度与a相同,头部添加0个元素,尾部添加1个元素
b = np.pad(b, pad_width=(0, 1), mode='constant', constant_values=-1)#默认mode='constant',constant_values=0
print(b)
# 垂直方向完成组合操作,生成新数组
c = np.vstack((a, b))
print(c)
简单的一维数组组合方案
a = np.arange(1,9) #[1, 2, 3, 4, 5, 6, 7, 8]
b = np.arange(9,17) #[9,10,11,12,13,14,15,16]
#把两个数组摞在一起成两行
c = np.row_stack((a, b))
print(c)
#把两个数组组合在一起成两列
d = np.column_stack((a, b))
print(d)
ndarray类的其他属性
- shape - 维度
- dtype - 元素类型
- size - 元素数量
- ndim - 维数,len(shape)
- itemsize - 元素字节数
- nbytes - 总字节数 = size x itemsize
- real - 复数数组的实部数组
- imag - 复数数组的虚部数组
- T - 数组对象的转置视图
- flat - 扁平迭代器,#生成可迭代的一维数组对象
import numpy as np
a = np.array([[1 + 1j, 2 + 4j, 3 + 7j],[4 + 2j, 5 + 5j, 6 + 8j],[7 + 3j, 8 + 6j, 9 + 9j]])
print(a.shape)
print(a.dtype)
print(a.ndim)
print(a.size)
print(a.itemsize)
print(a.nbytes)
print(a.real, a.imag, sep='\n')
print(a.T)
print([elem for elem in a.flat])
b = a.tolist()#把数组转换成列表
print(b)
相关文章:

数据分析DAY1
数据分析 引言 这一周:学习了python的numpy和matplotlib以及在飞桨paddle上面做了几个小项目 发现numpy和matplotlib里面有很多api,要全部记住是不可能的,也是不可能全部学完的,所以我们要知道并且熟悉一些常用的api࿰…...

算法通关村—迭代实现二叉树的前序,中序,后序遍历
1. 前序中序后序递归写法 前序 public void preorder(TreeNode root, List<Integer> res) {if (root null) {return;}res.add(root.val);preorder(root.left, res);preorder(root.right, res);}后序 public static void postOrderRecur(TreeNode head) {if (head nu…...

二叉搜索树(BST)的模拟实现
序言: 构造一棵二叉排序树的目的并不是为了排序,而是为了提高查找效率、插入和删除关键字的速度,同时二叉搜索树的这种非线性结构也有利于插入和删除的实现。 目录 (一)BST的定义 (二)二叉搜…...

【MFC】01.MFC框架-笔记
基本概念 MFC Microsoft Fundation class 微软基础类库 框架 基于Win32 SDK进行的封装 属性:缓解库关闭 属性->C/C/代码生成/运行库/MTD 属性->常规->MFC的使用:在静态库中使用MFC,默认是使用的共享DLL,运行时库 SD…...

基于ArcGIS污染物浓度及风险的时空分布
在GIS发展的早期,专业人士主要关注于数据编辑或者集中于应用工程,以及主要把精力花费在创建GIS数据库并构造地理信息和知识。慢慢的,GIS的专业人士开始在大量的GIS应用中使用这些知识信息库。用户应用功能全面的GIS工作站来编辑地理数据集&am…...

【项目开发计划制定工作经验之谈】
一、背景介绍 随着信息技术的发展,项目管理越来越受到企业和组织的重视。项目管理是一项旨在规划、组织、管理和控制项目的活动,以达到特定目标的过程。项目开发计划是项目管理的一个重要组成部分,它是指定项目目标、工作范围、进度、质量、…...

基于STM32的格力空调红外控制
基于STM32的格力空调红外控制 1.红外线简介 在光谱中波长自760nm至400um的电磁波称为红外线,它是一种不可见光。目前几乎所有的视频和音频设备都可以通过红外遥控的方式进行遥控,比如电视机、空调、影碟机等,都可以见到红外遥控的影子。这种技…...

rust中thiserror怎么使用呢?
thiserror 是一个Rust库,可以帮助你更方便地定义自己的错误类型。它提供了一个类似于 macro_rules 的宏,可以帮助你快速地定义错误类型,并为错误添加上下文信息。下面是一个使用 thiserror 的示例: 首先,在你的Rust项…...

ceph tier和bcache区别
作者:吴业亮 博客:wuyeliang.blog.csdn.net Ceph tier(SSD POOL HDD POOL)不推荐的原因: 数据在两个资源池之间迁移代价太大,存在粒度问题(对象级别),且需要进行write…...

Idea 2023.2 maven 打包时提示 waring 问题解决
Version idea 2023.2 问题 使用 Maven 打包 ,控制台输出 Waring 信息 [WARNING] [WARNING] Plugin validation issues were detected in 7 plugin(s) [WARNING] [WARNING] * org.apache.maven.plugins:maven-dependency-plugin:3.3.0 [WARNING] * org.apache.…...
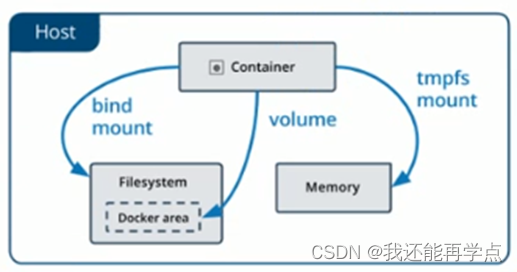
docker数据持久化
在Docker中若要想实现容器数据的持久化(所谓的数据持久化即数据不随着Container的结束而销毁),需要将数据从宿主机挂载到容器中。目前Docker提供了三种不同的方式将数据从宿主机挂载到容器中。 (1)Volumes:…...

安全防护,保障企业图文档安全的有效方法
随着企业现在数据量的不断增加和数据泄露事件的频发,图文档的安全性成为了企业必须高度关注的问题。传统的纸质文件存储方式已不适应现代企业的需求,而在线图文档管理成为了更加安全可靠的数字化解决方案。那么在在线图文档管理中,如何采取有…...

Open3D (C++) 基于拟合平面的点云地面点提取
目录 一、算法原理1、原理概述2、参考文献二、代码实现三、结果展示1、原始点云2、提取结果四、相关链接本文由CSDN点云侠原创,原文链接。爬虫网站自重,把自己当个人,爬些不完整的误导别人有意思吗???? 一、算法原理...
 - OneForAll 简单应用)
【Linux】Kali Linux 渗透安全学习笔记(2) - OneForAll 简单应用
OneForAll (以下简称“OFA”)是一个非常好用的子域收集工具,可以通过一级域名找到旗下的所有层级域名,通过递归的方式我们很容易就能够知道此域名下的所有域名层级结构,对于进一步通过域名推测站点功能起到非常重要的作…...
DAY56:单调栈(二)下一个最大元素Ⅱ(环形数组处理思路)
文章目录 思路写法1完整版环形数组处理:i取模,遍历两遍写法2完整版(环形数组推荐写法)debug测试:逻辑运算符短路特性result数组在栈口取元素,是否会覆盖原有数值? 给定一个循环数组 nums &#…...

kafka简介
kafka是什么? Kafka最初采用Scala语言开发的一个多分区、多副本并且基于ZooKeeper协调的分布式消息系统。目前Kafka已经定位为一个分布式流式处理平台,它的特性有高吞吐、可持久化、可水平扩展、支持流处理。 Apache Kafka是一个分布式的发布-订阅消息系…...
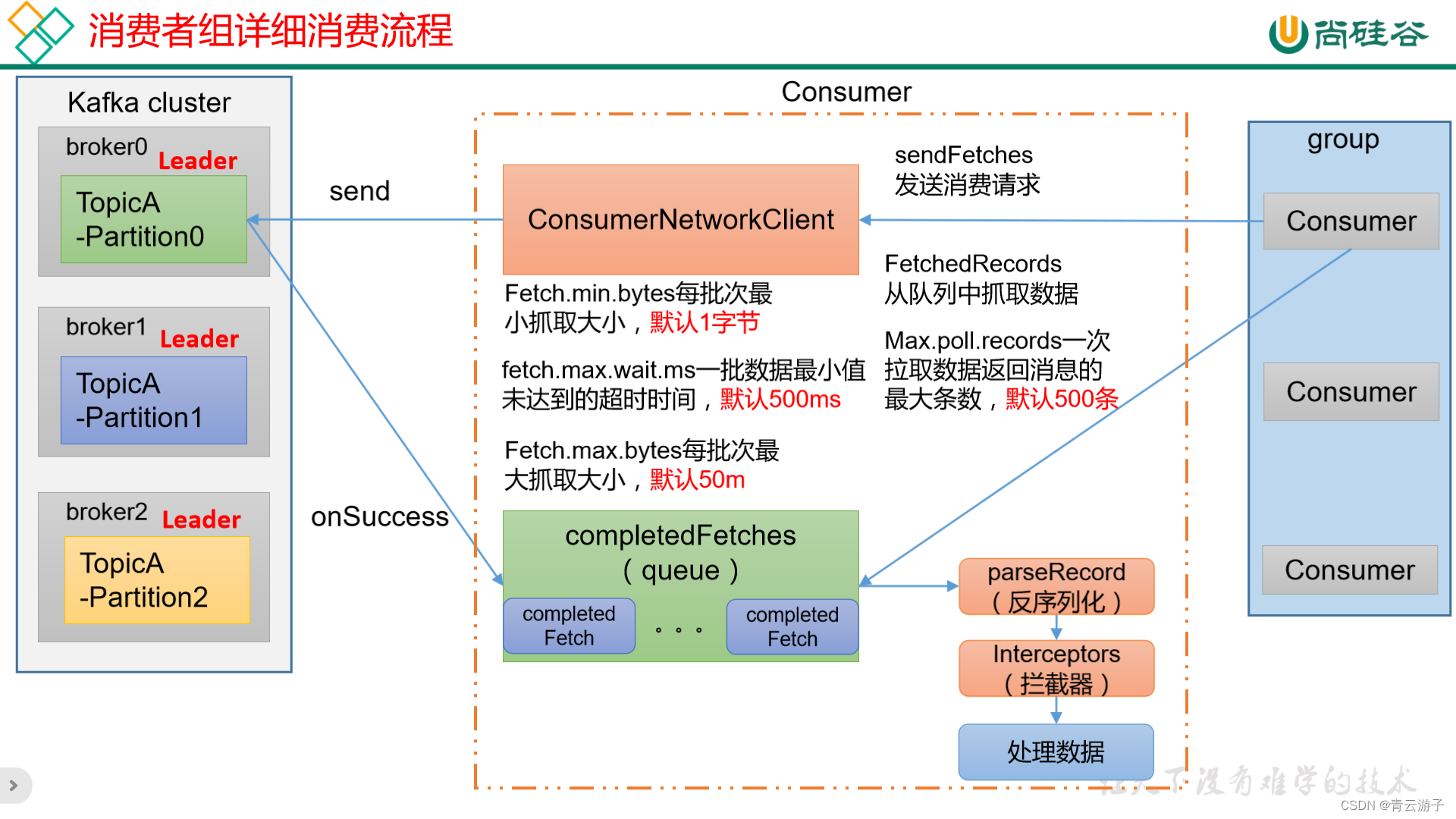
Kafka-消费者组消费流程
消费者向kafka集群发送消费请求,消费者客户端默认每次从kafka集群拉取50M数据,放到缓冲队列中,消费者从缓冲队列中每次拉取500条数据进行消费。...
FFmepg视频解码
1 前言 上一篇文章<FFmpeg下载安装及Windows开发环境设置>介绍了FFmpeg的下载安装及环境配置,本文介绍最简单的FFmpeg视频解码示例。 2 视频解码过程 本文只讨论视频解码。 FFmpeg视频解码的过程比较简单,实际就4步: 打开媒体流获取…...

SpringCloud深入理解 | 生产者、消费者
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! SpringCloud Spring Cloud是一组用于构建分布式系统和微服务架构的开源框架和工具集合。它是在Spring生态系统的基础上构建的,旨在简化开发人员构建分布式…...

web题型
0X01 命令执行 漏洞原理 没有对用户输入的内容进行一定过滤直接传给shell_exec、system一类函数执行 看一个具体例子 cmd1|cmd2:无论cmd1是否执行成功,cmd2将被执行 cmd1;cmd2:无论cmd1是否执行成功,cmd2将被执行 cmd1&cmd2:无论cmd1是否执行成…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...