python与深度学习(十一):CNN和猫狗大战
目录
- 1. 说明
- 2. 猫狗大战
- 2.1 导入相关库
- 2.2 建立模型
- 2.3 模型编译
- 2.4 数据生成器
- 2.5 模型训练
- 2.6 模型保存
- 2.7 模型训练结果的可视化
- 3. 猫狗大战的CNN模型可视化结果图
- 4. 完整代码
- 5. 猫狗大战的迁移学习
1. 说明
本篇文章是CNN的另外一个例子,猫狗大战,是自制数据集的例子。之前的例子都是python中库自带的,但是这次的例子是自己搜集数据集,如下图所示整理,数据集的链接会放在评论区。
2. 猫狗大战
2.1 导入相关库
以下第三方库是python专门用于深度学习的库
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, BatchNormalization
from keras.optimizers import RMSprop, Adam
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
from keras.layers import MaxPool2D
import matplotlib.pyplot as plt
import pandas
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
2.2 建立模型
这是采用另外一种书写方式建立模型。
构建了三层卷积层,三层池化层,然后是展平层(将二维特征图拉直输入给全连接层),然后是三层全连接层,并且加入了dropout层。
"1.模型建立"
# 1.卷积层,输入图片大小(150, 150, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu'
conv_layer1 = Conv2D(input_shape=(150, 150, 3), filters=16, kernel_size=(5, 5), activation='relu')
# 2.最大池化层,池化层大小(2, 2), 步长为2
max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2)
# 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu'
conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu')
# 4.最大池化层,池化层大小(2, 2), 步长为2
max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2)
# 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu'
conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu')
# 6.最大池化层,池化层大小(2, 2), 步长为2
max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2)
# 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu'
conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu')
# 8.最大池化层,池化层大小(2, 2), 步长为2
max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2)
# 9.展平层
flatten_layer = Flatten()
# 10.Dropout层, Dropout(0.2)
third_dropout = Dropout(0.2)
# 11.全连接层/隐藏层1,240个节点, 激活函数'relu'
hidden_layer1 = Dense(240, activation='relu')
# 12.全连接层/隐藏层2,84个节点, 激活函数'relu'
hidden_layer3 = Dense(84, activation='relu')
# 13.Dropout层, Dropout(0.2)
fif_dropout = Dropout(0.5)
# 14.输出层,输出节点个数1, 激活函数'sigmoid'
output_layer = Dense(1, activation='sigmoid')
model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2,conv_layer3, max_pool3, conv_layer4, max_pool4,flatten_layer, third_dropout, hidden_layer1,hidden_layer3, fif_dropout, output_layer])
2.3 模型编译
模型的优化器是Adam,学习率是0.01,
损失函数是binary_crossentropy,二分类交叉熵,
性能指标是正确率accuracy,
另外还加入了回调机制。
回调机制简单理解为训练集的准确率持续上升,而验证集准确率基本不变,此时已经出现过拟合,应该调制学习率,让验证集的准确率也上升。
"2.模型编译"
# 模型编译,2分类:binary_crossentropy
model.compile(optimizer=Adam(lr=0.0001), # 优化器选择Adam,初始学习率设置为0.0001loss='binary_crossentropy', # 代价函数选择 binary_crossentropymetrics=['accuracy']) # 设置指标为准确率
model.summary() # 模型统计# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracypatience=2, # 设置耐心容忍次数为2verbose=1, #factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少min_lr=0.000001 # 学习率最小值0.000001) # 监控val_accuracy增加趋势
2.4 数据生成器
加载自制数据集
利用数据生成器对数据进行数据加强,即每次训练时输入的图片会是原图片的翻转,平移,旋转,缩放,这样是为了降低过拟合的影响。
然后通过迭代器进行数据加载,目标图像大小统一尺寸1501503,设置每次加载到训练网络的图像数目,设置而分类模型(默认one-hot编码),并且数据打乱。
"3.数据生成器"
# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(rescale=1 / 255.0,rotation_range=5, # 图片随机旋转的角度5度width_shift_range=0.1,height_shift_range=0.1, # 水平和竖直方向随机移动0.1shear_range=0.1, # 剪切变换的程度0.1zoom_range=0.1, # 随机放大的程度0.1fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'dog-cats', 'train')
val_path = os.path.join(sys.path[0], 'dog-cats', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
2.5 模型训练
模型训练的次数是20,每1次循环进行测试
"4.模型训练"
# 模型的训练, model.fit
result = model.fit(train_iter, # 设置训练数据的迭代器epochs=20, # 循环次数20次validation_data=val_iter, # 验证数据的迭代器callbacks=[reduce], # 回调机制设置为reduceverbose=1)
2.6 模型保存
以.h5文件格式保存模型
"5.模型保存"
# 保存训练好的模型
model.save('my_cnn_cat_dog.h5')
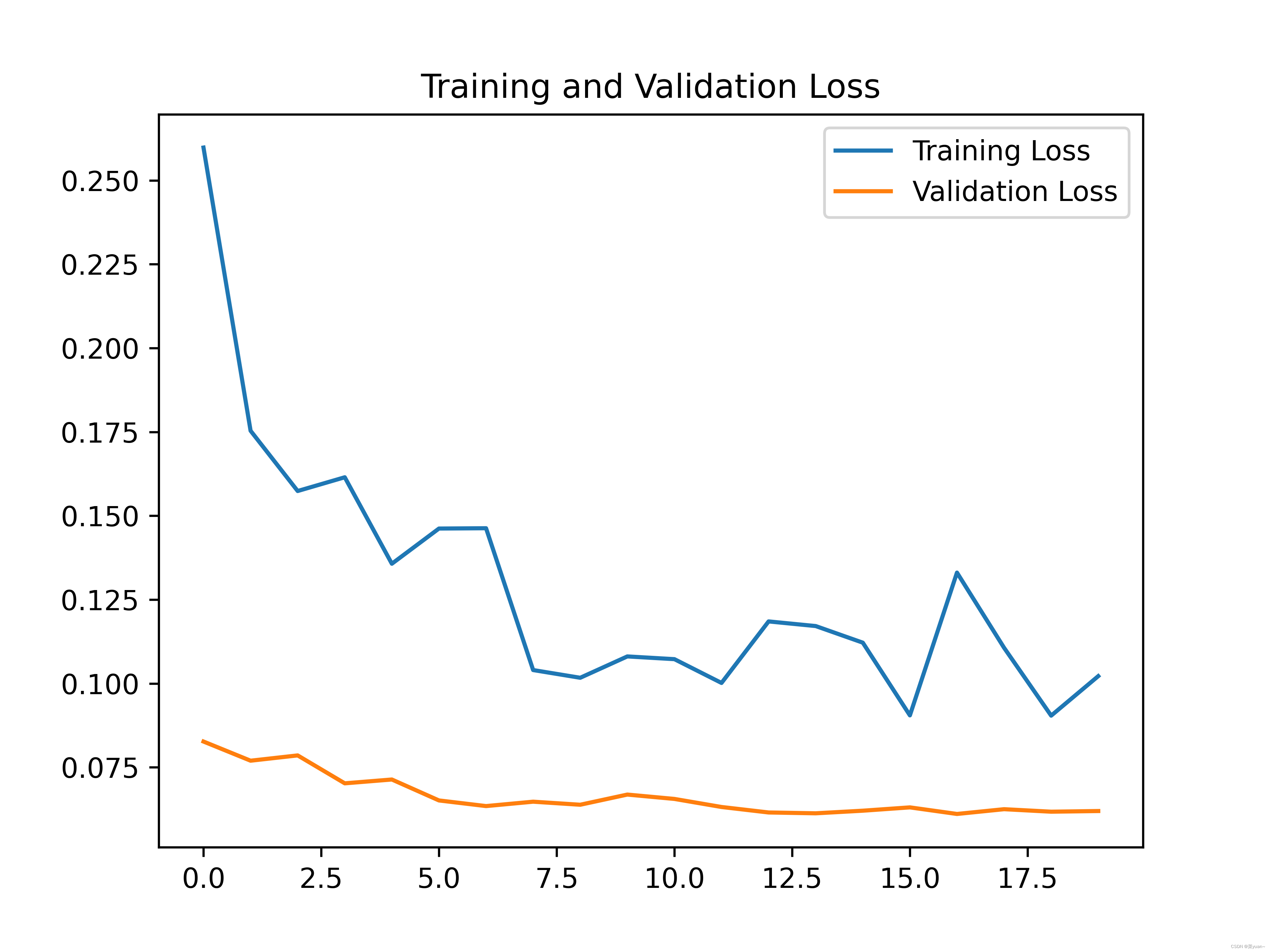
2.7 模型训练结果的可视化
对模型的训练结果进行可视化,可视化的结果用曲线图的形式展现
"6.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('cat_dog_acc.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('cat_dog_loss.png', dpi=600)
plt.show() # 将结果显示出来
3. 猫狗大战的CNN模型可视化结果图
Epoch 1/20
250/250 [==============================] - 59s 231ms/step - loss: 0.6940 - accuracy: 0.4925 - val_loss: 0.6899 - val_accuracy: 0.5050 - lr: 1.0000e-04
Epoch 2/20
250/250 [==============================] - 55s 219ms/step - loss: 0.6891 - accuracy: 0.5125 - val_loss: 0.6787 - val_accuracy: 0.5880 - lr: 1.0000e-04
Epoch 3/20
250/250 [==============================] - 54s 216ms/step - loss: 0.6791 - accuracy: 0.5840 - val_loss: 0.6655 - val_accuracy: 0.6080 - lr: 1.0000e-04
Epoch 4/20
250/250 [==============================] - 60s 238ms/step - loss: 0.6628 - accuracy: 0.6040 - val_loss: 0.6501 - val_accuracy: 0.6300 - lr: 1.0000e-04
Epoch 5/20
250/250 [==============================] - 57s 226ms/step - loss: 0.6480 - accuracy: 0.6400 - val_loss: 0.6281 - val_accuracy: 0.6590 - lr: 1.0000e-04
Epoch 6/20
250/250 [==============================] - 67s 268ms/step - loss: 0.6275 - accuracy: 0.6565 - val_loss: 0.6160 - val_accuracy: 0.6690 - lr: 1.0000e-04
Epoch 7/20
250/250 [==============================] - 62s 247ms/step - loss: 0.6252 - accuracy: 0.6570 - val_loss: 0.6026 - val_accuracy: 0.6790 - lr: 1.0000e-04
Epoch 8/20
250/250 [==============================] - 63s 251ms/step - loss: 0.5915 - accuracy: 0.6770 - val_loss: 0.5770 - val_accuracy: 0.6960 - lr: 1.0000e-04
Epoch 9/20
250/250 [==============================] - 57s 228ms/step - loss: 0.5778 - accuracy: 0.6930 - val_loss: 0.5769 - val_accuracy: 0.6880 - lr: 1.0000e-04
Epoch 10/20
250/250 [==============================] - 55s 219ms/step - loss: 0.5532 - accuracy: 0.7085 - val_loss: 0.5601 - val_accuracy: 0.6970 - lr: 1.0000e-04
Epoch 11/20
250/250 [==============================] - 55s 221ms/step - loss: 0.5408 - accuracy: 0.7370 - val_loss: 0.6002 - val_accuracy: 0.6810 - lr: 1.0000e-04
Epoch 12/20
250/250 [==============================] - ETA: 0s - loss: 0.5285 - accuracy: 0.7350
Epoch 12: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05.
250/250 [==============================] - 56s 226ms/step - loss: 0.5285 - accuracy: 0.7350 - val_loss: 0.5735 - val_accuracy: 0.6960 - lr: 1.0000e-04
Epoch 13/20
250/250 [==============================] - 70s 280ms/step - loss: 0.4969 - accuracy: 0.7595 - val_loss: 0.5212 - val_accuracy: 0.7410 - lr: 5.0000e-05
Epoch 14/20
250/250 [==============================] - 73s 292ms/step - loss: 0.4776 - accuracy: 0.7740 - val_loss: 0.5146 - val_accuracy: 0.7470 - lr: 5.0000e-05
Epoch 15/20
250/250 [==============================] - 71s 285ms/step - loss: 0.4605 - accuracy: 0.7930 - val_loss: 0.5180 - val_accuracy: 0.7530 - lr: 5.0000e-05
Epoch 16/20
250/250 [==============================] - 74s 298ms/step - loss: 0.4619 - accuracy: 0.7825 - val_loss: 0.5100 - val_accuracy: 0.7510 - lr: 5.0000e-05
Epoch 17/20
250/250 [==============================] - 72s 289ms/step - loss: 0.4558 - accuracy: 0.7885 - val_loss: 0.4991 - val_accuracy: 0.7630 - lr: 5.0000e-05
Epoch 18/20
250/250 [==============================] - 75s 300ms/step - loss: 0.4498 - accuracy: 0.7900 - val_loss: 0.4966 - val_accuracy: 0.7580 - lr: 5.0000e-05
Epoch 19/20
250/250 [==============================] - 61s 243ms/step - loss: 0.4269 - accuracy: 0.8060 - val_loss: 0.5000 - val_accuracy: 0.7690 - lr: 5.0000e-05
Epoch 20/20
250/250 [==============================] - 56s 224ms/step - loss: 0.4202 - accuracy: 0.8090 - val_loss: 0.4845 - val_accuracy: 0.7700 - lr: 5.0000e-05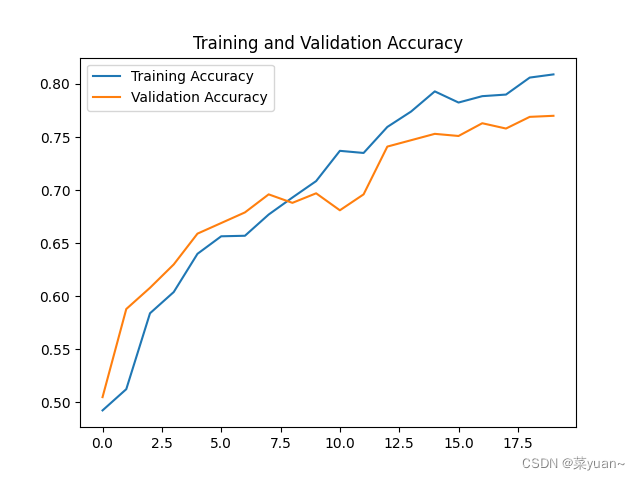
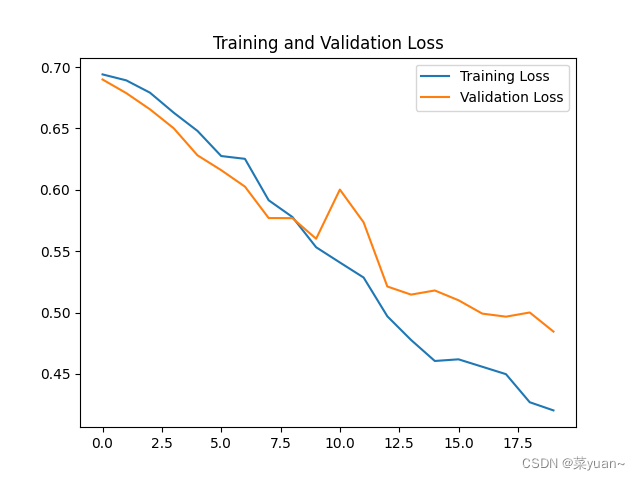
从以上结果可知,模型的准确率达到了77%。可以发现并不是很高,因此采用下面的迁移学习。
4. 完整代码
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, BatchNormalization
from keras.optimizers import RMSprop, Adam
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
from keras.layers import MaxPool2D
import matplotlib.pyplot as plt
import pandas
from keras.callbacks import EarlyStopping, ReduceLROnPlateau"1.模型建立"
# 1.卷积层,输入图片大小(150, 150, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu'
conv_layer1 = Conv2D(input_shape=(150, 150, 3), filters=16, kernel_size=(5, 5), activation='relu')
# 2.最大池化层,池化层大小(2, 2), 步长为2
max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2)
# 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu'
conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu')
# 4.最大池化层,池化层大小(2, 2), 步长为2
max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2)
# 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu'
conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu')
# 6.最大池化层,池化层大小(2, 2), 步长为2
max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2)
# 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu'
conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu')
# 8.最大池化层,池化层大小(2, 2), 步长为2
max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2)
# 9.展平层
flatten_layer = Flatten()
# 10.Dropout层, Dropout(0.2)
third_dropout = Dropout(0.2)
# 11.全连接层/隐藏层1,240个节点, 激活函数'relu'
hidden_layer1 = Dense(240, activation='relu')
# 12.全连接层/隐藏层2,84个节点, 激活函数'relu'
hidden_layer3 = Dense(84, activation='relu')
# 13.Dropout层, Dropout(0.2)
fif_dropout = Dropout(0.5)
# 14.输出层,输出节点个数1, 激活函数'sigmoid'
output_layer = Dense(1, activation='sigmoid')
model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2,conv_layer3, max_pool3, conv_layer4, max_pool4,flatten_layer, third_dropout, hidden_layer1,hidden_layer3, fif_dropout, output_layer])
"2.模型编译"
# 模型编译,2分类:binary_crossentropy
model.compile(optimizer=Adam(lr=0.0001), # 优化器选择Adam,初始学习率设置为0.0001loss='binary_crossentropy', # 代价函数选择 binary_crossentropymetrics=['accuracy']) # 设置指标为准确率
model.summary() # 模型统计# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracypatience=2, # 设置耐心容忍次数为2verbose=1, #factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少min_lr=0.000001 # 学习率最小值0.000001) # 监控val_accuracy增加趋势
"3.数据生成器"
# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(rescale=1 / 255.0,rotation_range=5, # 图片随机旋转的角度5度width_shift_range=0.1,height_shift_range=0.1, # 水平和竖直方向随机移动0.1shear_range=0.1, # 剪切变换的程度0.1zoom_range=0.1, # 随机放大的程度0.1fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'dog-cats', 'train')
val_path = os.path.join(sys.path[0], 'dog-cats', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
"4.模型训练"
# 模型的训练, model.fit
result = model.fit(train_iter, # 设置训练数据的迭代器epochs=20, # 循环次数20次validation_data=val_iter, # 验证数据的迭代器callbacks=[reduce], # 回调机制设置为reduceverbose=1)"5.模型保存"
# 保存训练好的模型
model.save('my_cnn_cat_dog.h5')"6.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('cat_dog_acc.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('cat_dog_loss.png', dpi=600)
plt.show() # 将结果显示出来5. 猫狗大战的迁移学习
迁移学习简单来说就是将别人已经训练好的模型拿来自己用。
from keras.applications import DenseNet121
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, BatchNormalization
from keras.optimizers import RMSprop, Adam
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
from keras.layers import MaxPool2D
import matplotlib.pyplot as plt
import pandas
from keras.callbacks import EarlyStopping, ReduceLROnPlateau"1.模型建立"
# 加载DenseNet网络模型,并去掉最后一层全连接层,最后一个池化层设置为max pooling
net = DenseNet121(weights='imagenet', include_top=False, pooling='max')
# 设计为不参与优化,即MobileNet这部分参数固定不动
net.trainable = False
newnet = Sequential([net, # 去掉最后一层的DenseNet121Dense(1024, activation='relu'), # 追加全连接层BatchNormalization(), # 追加BN层Dropout(rate=0.5), # 追加Dropout层,防止过拟合Dense(1,activation='sigmoid') # 根据宝可梦数据的任务,设置最后一层输出节点数为5
])
newnet.build(input_shape=(None, 150, 150, 3))"2.模型编译"
newnet.compile(optimizer=Adam(lr=0.0001), loss="binary_crossentropy", metrics=["accuracy"])
newnet.summary()# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracypatience=2, # 设置耐心容忍次数为2verbose=1, #factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少min_lr=0.000001 # 学习率最小值0.000001) # 监控val_accuracy增加趋势"3.数据生成器"
# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(rescale=1 / 255.0,rotation_range=5, # 图片随机旋转的角度5度width_shift_range=0.1,height_shift_range=0.1, # 水平和竖直方向随机移动0.1shear_range=0.1, # 剪切变换的程度0.1zoom_range=0.1, # 随机放大的程度0.1fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'dog-cats', 'train')
val_path = os.path.join(sys.path[0], 'dog-cats', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=10, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=10, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
"4.模型训练"
# 模型的训练, newnet.fit
result = newnet.fit(train_iter, # 设置训练数据的迭代器epochs=20, # 循环次数20次validation_data=val_iter, # 验证数据的迭代器callbacks=[reduce], # 回调机制设置为reduceverbose=1)"5.模型保存"
# 保存训练好的模型
newnet.save('my_cnn_cat_dog_3.h5')"6.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('cat_dog_acc_3.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('cat_dog_loss_3.png', dpi=600)
plt.show() # 将结果显示出来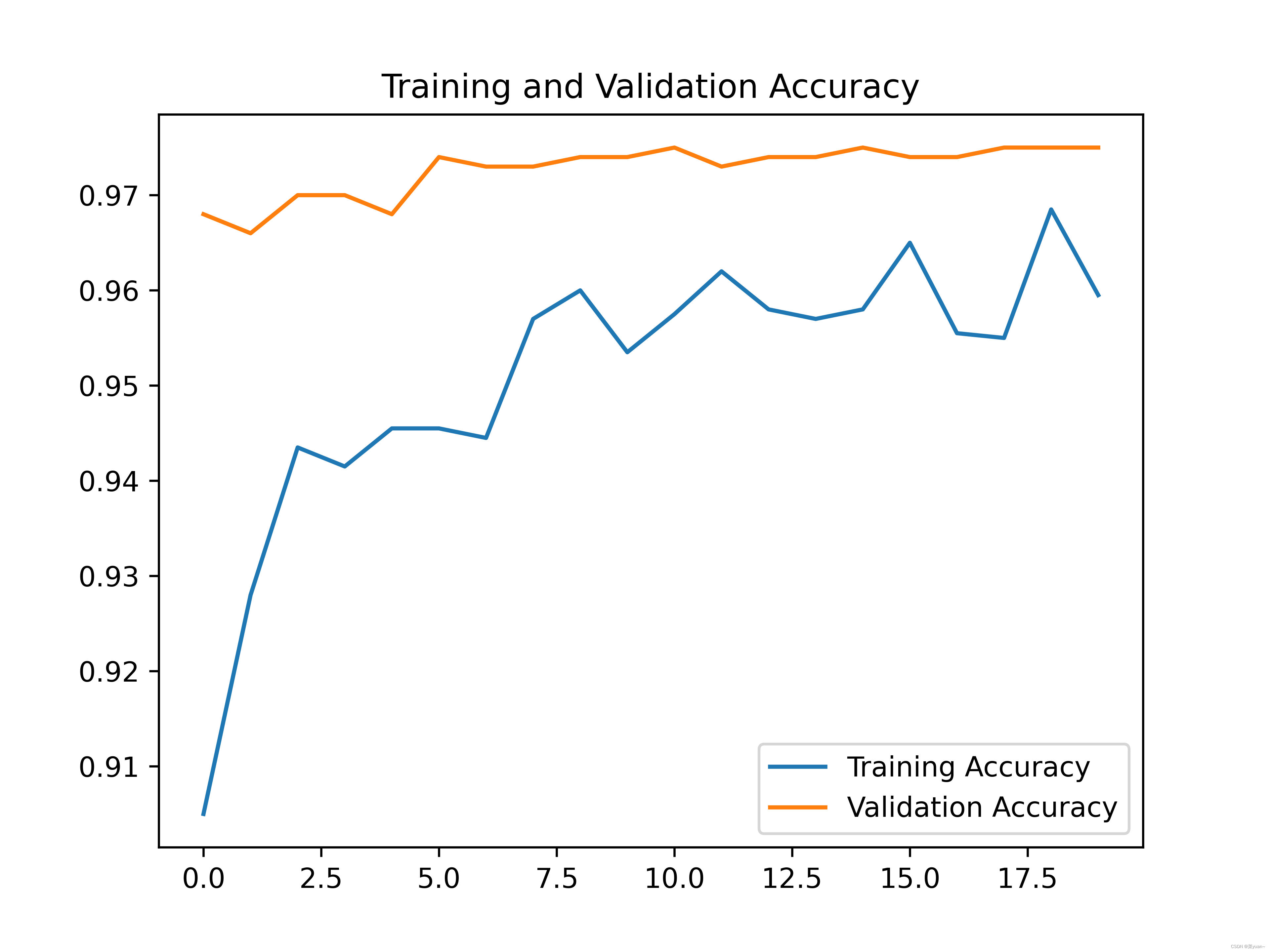
可以发现,通过迁移学习之后的模型准确率达到了96%。
相关文章:
python与深度学习(十一):CNN和猫狗大战
目录 1. 说明2. 猫狗大战2.1 导入相关库2.2 建立模型2.3 模型编译2.4 数据生成器2.5 模型训练2.6 模型保存2.7 模型训练结果的可视化 3. 猫狗大战的CNN模型可视化结果图4. 完整代码5. 猫狗大战的迁移学习 1. 说明 本篇文章是CNN的另外一个例子,猫狗大战,…...

经典CNN(三):DenseNet算法实战与解析
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊|接辅导、项目定制 1 前言 在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的方法,比如GoogleNet,…...
学习笔记——压力测试案例,监控平台
测试案例 # 最简单的部署方式直接单机启动 nohup java -jar lesson-one-0.0.1-SNAPSHOT.jar > ./server.log 2>&1 &然后配置执行计划: 新建一个执行计划 配置请求路径 配置断言配置响应持续时间断言 然后配置一些查看结果的统计报表或者图形 然后我…...

sqlite 踩坑
内存数据库 强制SQLite数据库单纯的存在于内存中的常用方法是使用特殊文件名“ :memory: ” db QSqlDatabase::addDatabase("QSQLITE", "MEMORY"); db.setDatabaseName(":memory:"); 调用此接口完成后,不…...
【论文笔记】神经网络压缩调研
神经网络压缩调研 背景现有的深度模型压缩方法NetWork Prunning 网络剪枝设计结构化矩阵知识蒸馏权值共享Parameter Quantization(参数量化)量化和二进制化伪量化Architecture Design(Depth Separable Convolution)分解卷积 背景 …...

红外NEC通信协议
一、NEC简介 红外(Infrared,IR)遥控是一种无线、非接触控制技术,常用于遥控器、无线键盘、鼠标等设备之间的通信。IR协议的工作原理是,发送方通过红外线发送一个特定的编码,接收方通过识别该编码来执行相应的操作。 IR协议是指红外…...

数据分析DAY1
数据分析 引言 这一周:学习了python的numpy和matplotlib以及在飞桨paddle上面做了几个小项目 发现numpy和matplotlib里面有很多api,要全部记住是不可能的,也是不可能全部学完的,所以我们要知道并且熟悉一些常用的api࿰…...

算法通关村—迭代实现二叉树的前序,中序,后序遍历
1. 前序中序后序递归写法 前序 public void preorder(TreeNode root, List<Integer> res) {if (root null) {return;}res.add(root.val);preorder(root.left, res);preorder(root.right, res);}后序 public static void postOrderRecur(TreeNode head) {if (head nu…...

二叉搜索树(BST)的模拟实现
序言: 构造一棵二叉排序树的目的并不是为了排序,而是为了提高查找效率、插入和删除关键字的速度,同时二叉搜索树的这种非线性结构也有利于插入和删除的实现。 目录 (一)BST的定义 (二)二叉搜…...

【MFC】01.MFC框架-笔记
基本概念 MFC Microsoft Fundation class 微软基础类库 框架 基于Win32 SDK进行的封装 属性:缓解库关闭 属性->C/C/代码生成/运行库/MTD 属性->常规->MFC的使用:在静态库中使用MFC,默认是使用的共享DLL,运行时库 SD…...

基于ArcGIS污染物浓度及风险的时空分布
在GIS发展的早期,专业人士主要关注于数据编辑或者集中于应用工程,以及主要把精力花费在创建GIS数据库并构造地理信息和知识。慢慢的,GIS的专业人士开始在大量的GIS应用中使用这些知识信息库。用户应用功能全面的GIS工作站来编辑地理数据集&am…...

【项目开发计划制定工作经验之谈】
一、背景介绍 随着信息技术的发展,项目管理越来越受到企业和组织的重视。项目管理是一项旨在规划、组织、管理和控制项目的活动,以达到特定目标的过程。项目开发计划是项目管理的一个重要组成部分,它是指定项目目标、工作范围、进度、质量、…...

基于STM32的格力空调红外控制
基于STM32的格力空调红外控制 1.红外线简介 在光谱中波长自760nm至400um的电磁波称为红外线,它是一种不可见光。目前几乎所有的视频和音频设备都可以通过红外遥控的方式进行遥控,比如电视机、空调、影碟机等,都可以见到红外遥控的影子。这种技…...

rust中thiserror怎么使用呢?
thiserror 是一个Rust库,可以帮助你更方便地定义自己的错误类型。它提供了一个类似于 macro_rules 的宏,可以帮助你快速地定义错误类型,并为错误添加上下文信息。下面是一个使用 thiserror 的示例: 首先,在你的Rust项…...

ceph tier和bcache区别
作者:吴业亮 博客:wuyeliang.blog.csdn.net Ceph tier(SSD POOL HDD POOL)不推荐的原因: 数据在两个资源池之间迁移代价太大,存在粒度问题(对象级别),且需要进行write…...

Idea 2023.2 maven 打包时提示 waring 问题解决
Version idea 2023.2 问题 使用 Maven 打包 ,控制台输出 Waring 信息 [WARNING] [WARNING] Plugin validation issues were detected in 7 plugin(s) [WARNING] [WARNING] * org.apache.maven.plugins:maven-dependency-plugin:3.3.0 [WARNING] * org.apache.…...
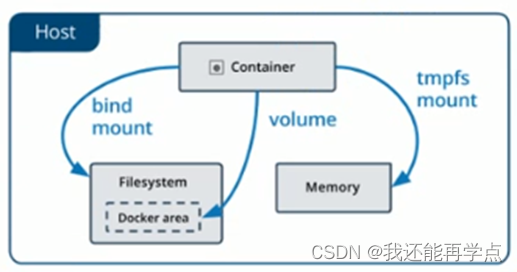
docker数据持久化
在Docker中若要想实现容器数据的持久化(所谓的数据持久化即数据不随着Container的结束而销毁),需要将数据从宿主机挂载到容器中。目前Docker提供了三种不同的方式将数据从宿主机挂载到容器中。 (1)Volumes:…...

安全防护,保障企业图文档安全的有效方法
随着企业现在数据量的不断增加和数据泄露事件的频发,图文档的安全性成为了企业必须高度关注的问题。传统的纸质文件存储方式已不适应现代企业的需求,而在线图文档管理成为了更加安全可靠的数字化解决方案。那么在在线图文档管理中,如何采取有…...

Open3D (C++) 基于拟合平面的点云地面点提取
目录 一、算法原理1、原理概述2、参考文献二、代码实现三、结果展示1、原始点云2、提取结果四、相关链接本文由CSDN点云侠原创,原文链接。爬虫网站自重,把自己当个人,爬些不完整的误导别人有意思吗???? 一、算法原理...
 - OneForAll 简单应用)
【Linux】Kali Linux 渗透安全学习笔记(2) - OneForAll 简单应用
OneForAll (以下简称“OFA”)是一个非常好用的子域收集工具,可以通过一级域名找到旗下的所有层级域名,通过递归的方式我们很容易就能够知道此域名下的所有域名层级结构,对于进一步通过域名推测站点功能起到非常重要的作…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...

AVR+ESP8266双核架构打造独立WiFi天气显示器:从硬件设计到软件实现
1. 项目概述:一个独立WiFi天气显示器的诞生几年前,我琢磨着在书桌上放一个能实时显示天气信息的小玩意儿,市面上成品要么功能单一,要么价格不菲,要么数据源依赖复杂的服务器。于是,我决定自己动手ÿ…...

10.刷机变砖、IMEI 丢失、基带未知、触控失灵?一站式终极修复方案
摘要 本文面向具备基础计算机操作能力的维修从业者与高级用户,系统讲解当前主流品牌手机(华为、小米、OPPO、vivo、一加、苹果)的刷机与维修核心流程。内容涵盖底层引导架构差异、Fastboot/Recovery/DFU模式操作规范、分区表保护策略、驱动兼容性处理以及常见硬件故障的软件…...

监控摄像头小众场景爆发,融合类产品成新蓝海
随着户外运动热潮的持续和物联网技术的全面落地,打猎相机市场在2025年迎来了真正的爆发期,并在2026年继续向智能化、网联化深度演进。根据最新的行业监测数据,2025年全球消费类IPC(网络摄像机)出货量突破1.92亿台&…...

从零开始掌握MuSiC:单细胞RNA测序反卷积的完整指南
从零开始掌握MuSiC:单细胞RNA测序反卷积的完整指南 【免费下载链接】MuSiC Multi-subject Single Cell Deconvolution 项目地址: https://gitcode.com/gh_mirrors/music2/MuSiC 还在为复杂的单细胞数据分析而烦恼吗?想要从批量RNA测序数据中准确识…...