[C++项目] Boost文档 站内搜索引擎(2): 文档文本解析模块parser的实现、如何对文档文件去标签、如何获取文档标题...

项目开始的准备工作
在上一篇文章中, 已经从Boost官网获取了Boost库的源码.
接下来就要编写代码了. 不过还需要做一些准备工作.
-
创建项目目录
所有的项目文件肯定要在一个目录下, 找一个位置执行下面这行指令
mkdir Boost-Doc-Searcher -
将文档
html文件, 存放到项目中cd Boost-Doc-Searcher进入刚刚创建的项目目录下, 执行指令:mkdir -p data/input # 将Boost库中的文档目录下的所有文件, 拷贝到 Boost-Doc-Searcher/data/input/. 下 # 我的Boost库源码, 与 项目目录Boost-Doc-Searcher, 在同一个目录下 # ❯ pwd # /home/July/gitCode/gitHub/Boost-Doc-Searcher cp ../boost_1_82_0/doc/html/* data/input/.然后进入,
data/input目录下执行ls -R |grep -E "*.html" |wc -l查看目录下(包括子目录)有多少个
.html文件:
boost 1.82.0版本 一共有8563个文档文件
上面两个步骤, 相当于将Boost文档网页爬取到项目中. 接下来要做的就是对所有的文档html文件进行解析.
这也是本篇文章需要做的内容.
此时, 项目的树形目录结构为:
# ❯ pwd
# /home/July/gitCode/gitHub/Boost-Doc-Searcher
# ❯ tree -d -L 2
# .
# └── data
# └── input
安装boost库
项目的实现, 需要用到boost库中的组件. 所以需要先安装boost库
博主的平台是 CentOS 7
sudo yum install boost-devel
执行上面的命令, 就可以完成安装
文档 去标签-数据清洗模块 parser
项目中已经存储有文档. 要实现Boost文档站内搜索, 就需要用到这些文档的内容.
但是, 这些文档都是.html文件, 里边有许多的标签. 标签内的数据都是对搜索无用的无效数据.
所以需要进行 去标签 的操作. 还需要注意的是 尽量不要修改原文档文件内容, 所以需要把去除标签之后的文档内容在存储到一个文本文件中.
先来创建这个文本文件:
# ❯ pwd
# /home/July/gitCode/gitHub/Boost-Doc-Searcher
mkdir -p data/output
cd data/output
touch raw
然后回到Boost-Doc-Searcher目录下, 创建第一个模块代码文件parser.cc
1. parser代码基本结构
要理清 此代码的基本结构, 就需要理清 此程序需要实现的功能.
此程序要实现的是 对所有文档去标签, 然后将去完标签的文档内容 存储到同一个文本文件中
不过, 结合上一篇文章中分析过的: 搜索之后, 页面会以多个不同的网页的跳转链接拼接而成.
网页的跳转链接大致又分3部分展示: title content url. 那么, 我们在实际处理文档时, 也要从文档中提取到title content url 然后再以这三部分进行存储. 这样方便后面的使用.
并且, 在存储的时候 针对每一个文档内容 是一定需要分隔开的.
那么, parser代码的实现思路就可能包括:
- 使用
boost库提供的工具, 递归遍历data/input目录下(包括子目录)的所有文档html, 并保存其文件名到vector中 - 通过
vector中保存的 文档名, 找到文档 并对 所有文档的内容去标签 - 还是通过
vector中保存的文档名, 读取所有文档的内容, 以每个文档的titlecontenturl构成一个docInfo结构体. 并以vector存储起来 - 将用
vector存储起来的所有文档的docInfo存储到data/output/raw文件中, 每个文档的info用'\n'分割
Boost中提供了很方便的文件处理的组件.
那么, parser代码的的基本结构可以为:
#include <iostream>
#include <string>
#include <utility>
#include <vector>
#include <boost/filesystem.hpp>// 此程序是一个文档解析器
// boost文档的html文件中, 有许多的各种<>标签. 这些都是对搜索无关的内容, 所以需要清除掉
// 为提高解析效率, 可以将 上面的 2 3 步骤合并为一个函数:
// 每对一个文档html文件去标签之后, 就直接获取文档内容构成docInfo结构体, 并存储到 vector 中// 代码规范
// const & 表示输入型参数: const std::string&
// * 表示输出型参数: std::string*
// & 表示输入输出型参数: std::string&#define ENUM_ERROR 1
#define PARSEINFO_ERROR 2
#define SAVEINFO_ERROR 3const std::string srcPath = "data/input"; // 存放所有文档的目录
const std::string output = "data/output/raw"; // 保存文档所有信息的文件typedef struct docInfo {std::string _title; // 文档的标题std::string _content; // 文档内容std::string _url; // 该文档在官网中的url
} docInfo_t;bool enumFile(const std::string& srcPath, std::vector<std::string>* filesList);
bool parseDocInfo(const std::vector<std::string>& filesList, std::vector<docInfo_t>* docResults);
bool saveDocInfo(const std::vector<docInfo_t>& docResults, const std::string& output);int main() {std::vector<std::string> filesList;// 1. 递归式的把每个html文件名带路径,保存到filesList中,方便后期进行一个一个的文件进行读取if (!enumFile(srcPath, &filesList)) {// 获取文档html文件名失败std::cerr << "Failed to enum file name!" << std::endl;return ENUM_ERROR;}// 走到这里 获取所有文档html文件名成功// 2. 按照filesList读取每个文档的内容,并进行去标签解析// 3. 并获取文档的内容 以 标题 内容 url 构成docInfo结构体, 存储到vector中std::vector<docInfo_t> docResults;if (!parseDocInfo(filesList, &docResults)) {// 解析文档内容失败std::cerr << "Failed to parse document information!" << std::endl;return PARSEINFO_ERROR;}// 走到这里 获取所有文档内容 并以 docInfo 结构体形式存储到vector中成功// 4: 把解析完毕的各个文件内容,写入到output , 按照\3作为每个文档的分割符if (!saveDocInfo(docResults, output)) {std::cerr << "Failed to save document information!" << std::endl;return SAVEINFO_ERROR;}return 0;
}
基本结构是:
先规定了一个代码规范:
// const & 表示输入型参数: const std::string& // * 表示输出型参数: std::string* // & 表示输入输出型参数: std::string&
-
首先
const std::string srcPath = "data/input"存储 项目中所有文档html文件所在的目录const std::string output = "data/output/raw"存储 清理后文档内容的 存储文件的路径 -
然后定义结构体, 用于存储单个文档的
titlecontenturltypedef struct docInfo {std::string _title; // 文档的标题std::string _content; // 文档内容std::string _url; // 该文档在官网中的url } docInfo_t; -
再然后, 就是主函数需要执行的内容:
-
首先, 获取
srcPath目录下的所有.html文档文件名(包括相对路径), 并存储到vector中所以, 先定义了一个
std::vector<std::string> filesList, 用于存储文件名然后执行
enumFile(srcPath, &filesList), 并判断结果.
-
获取完所有文档的文件名之后, 就可以根据文件名找到文档. 然后对文档进行去标签处理, 并获取文档的
titlecontenturl. 并将其以docInfo结构体的形式存储到vector中所以定义了一个
std::vector<docInfo_t> docResults, 用于存储去标签之后的文档的信息然后执行
parseDocInfo(filesList, &docResults), 并判断结果
-
最后就是, 将
docResults中存储的每个文档的titlecontenturl信息, 都存储到output文件中.即, 执行
saveDocInfo(docResults, output), 并判断结果
-
这些步骤, 就是parser模块的基本结构了. 之后只需要实现三个接口就可以了
2. enumFile()接口实现
enumFile()接口需要实现, 统计scrPath目录下(包括子目录下)的所有.html文件, 存储到输出型参数filesList中
实现此函数, 需要使用到Boost库中的组件: filesystem
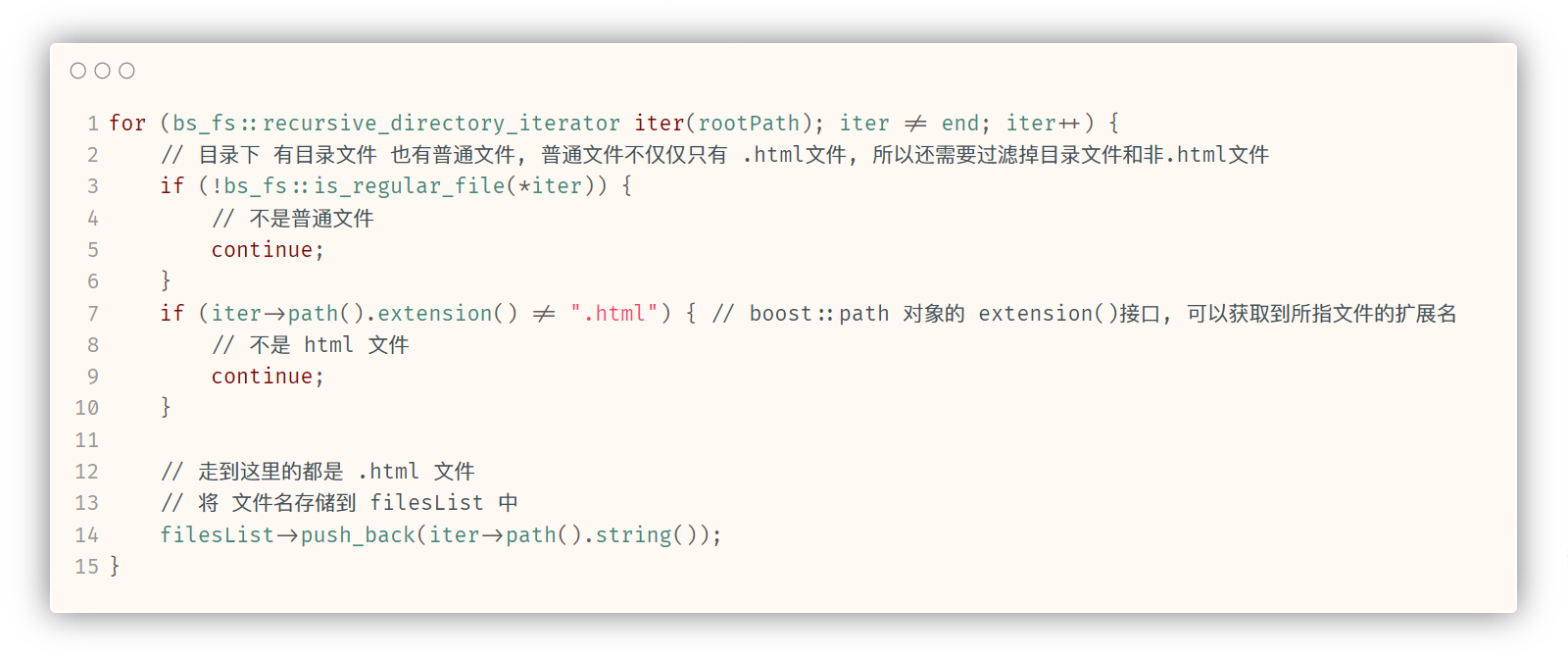
bool enumFile(const std::string& srcPath, std::vector<std::string>* filesList) {// 使用 boost库 来对路径下的文档html进行 递归遍历namespace bs_fs = boost::filesystem;// 根据 srcPath 构建一个path对象bs_fs::path rootPath(srcPath);if (!bs_fs::exists(rootPath)) {// 指定的路径不存在std::cerr << srcPath << " is not exists" << std::endl;return false;}// boost库中 可以递归遍历目录以及子目录中 文件的迭代器, 不初始化可看作空bs_fs::recursive_directory_iterator end;// 再从 rootPath 构建一个迭代器, 递归遍历目录下的所有文件for (bs_fs::recursive_directory_iterator iter(rootPath); iter != end; iter++) {// 目录下 有目录文件 也有普通文件, 普通文件不仅仅只有 .html文件, 所以还需要过滤掉目录文件和非.html文件if (!bs_fs::is_regular_file(*iter)) {// 不是普通文件continue;}if (iter->path().extension() != ".html") { // boost::path 对象的 extension()接口, 可以获取到所指文件的后缀// 不是 html 文件continue;}std::cout << "Debug: " << iter->path().string() << std::endl;// 走到这里的都是 .html 文件// 将 文件名存储到 filesList 中filesList->push_back(iter->path().string());}return true;
}
使用了Boost库中的组件, 可以非常简单的实现遍历某目录下的所有文件.
-
首先是
boost::filesystem::path类:path对象可以表示一条路径.boost库中 对它的描述是这样的:
-
其次
recursive_directory_iterator迭代器:通过
path对象可以实例化recursive_directory_iterator迭代器.此迭代器可以对目录下的所有文件进行迭代, 包括子目录下的文件. 该过程是递归的.

重要的就是这两个内容了.
我们使用srcPath实例化boost::filesystem::path rootPath对象.

然后再使用rootPath实例化recursive_directory_iterator, 让迭代器可以从srcPath目录下开始递归迭代

然后在迭代的过程中, 由于有目录文件和其他非html文件的存在
所以使用is_regular_file()来 判断是否为普通文件类型, 然后在使用path对象的extension()接口 获取扩展名.
再根据扩展名判断是否为html文件.
如果是, 就将迭代器所指的path对象 使用path对象的string()接口, 将path对象表示的路径名存储到filesList中:
至此, enumFile()接口的功能就结束了, 我们可以在函数内 输出每次获取的文件名 来调试看是否正确:

通过wc -l命令可以看出, 确实输出了8563行. 也就表示确实获取到了8563个.html文件名
注意, 因为使用了第三方库
boost, 所以编译时 需要指明链接库
g++ -o parser parser.cc -std=c++11 -lboost_system -lboost_filesystem
3. parseDocInfo()接口实现
parseDocInfo()需要实现的功能是:
遍历filesList获取每个文档的文件名, 通过文件名访问并读取到文件内容. 然后对文件内容去标签, 并获取到 title content url 构成一个docInfo结构体, 并将每个文档的docInfo结构体存储到vector中.
所以, parseDocInfo()的实现框架是这样的:
bool parseDocInfo(const std::vector<std::string>& filesList, std::vector<docInfo_t>* docResults) {// parseDocInfo 是对文档html文件的内容做去标签化 并 获取 title content url 构成结构体// 文档的路径都在 filesList 中存储着, 所以需要遍历 filesList 处理文件for (const std::string& filePath : filesList) {// 获取到文档html的路径之后, 就需要对 html文件进行去标签化等一系列解析操作了// 1. 读取文件内容到 string 中std::string fileContent;if (!ns_util::fileUtil::readFile(filePath, &fileContent)) {// 读取文件内容失败continue;}docInfo_t doc;// 2. 解析并获取title, html文件中只有一个 title标签, 所以再去标签之前 获取title比较方便if (!parseTitle(fileContent, &doc._title)) {// 解析title失败continue;}// 3. 解析并获取文档有效内容, 去标签的操作实际就是在这一步进行的if (!parseContent(fileContent, &doc._content)) {// 解析文档有效内容失败continue;}// 4. 获取 官网的对应文档的 urlif (!parseUrl(filePath, &doc._url)) {continue;}// 做完上面的一系列操作 走到这里时 如果没有不过 doc 应该已经被填充完毕了// doc出此次循环时就要被销毁了, 所以将doc 设置为将亡值 可以防止拷贝构造的发生 而使用移动语义来向 vector中添加元素// 这里发生拷贝构造是非常的消耗资源的 因为 doc._content 非常的大docResults->push_back(std::move(doc));}return true;
}
其中,
ns_util::fileUtil::readFile()接口是一个可以通用的工具接口. 是用来将文件内容读取到指定string中的函数接口.所以, 将函数写到
util.hpp文件中.
parseDocInfo()接口的实现思路就是:
- 遍历
filesList获取当前文件名 - 根据获取到的文件名, 将文件的内容读取到
string fileContent中 - 再分别根据
fileContent, 获取文档的titlecontenturl并对它去标签 - 然后再将构成的
docInfo对象结构体变量, 存储到vector中.
其中, 有四个接口需要完成:
readFile()接口实现
readFile()是读取文件内容到内存中的接口. 此接口可以公用, 因为其他模块中也会用到读取文件内容到内存中的功能.
所以可以把readFile()这个通用的工具接口, 写在util.hpp头文件中.
util.hpp一般用来定义通用的工具接口、宏等
util.hpp:
#pragma once#include <iostream>
#include <vector>
#include <string>
#include <fstream>namespace ns_util {class fileUtil {public:// readFile 用于读取指定文本文件的内容, 到string输出型参数中static bool readFile(const std::string& filePath, std::string* out) {// 要读取文件内容, 就要先打开文件// 1. 以读取模式打开文件std::ifstream in(filePath, std::ios::in);if (!in.is_open()) {// 打卡文件失败std::cerr << "Failed to open " << filePath << "!" << std::endl;return false;}// 走到这里打开文件成功// 2. 读取文件内, 并存储到out中std::string line;while (std::getline(in, line)) {*out += line;}in.close();return true;}};
}
此函数接口以
static修饰 定义在fileUtil类内,fileUtil表示文件操作通用类.
首先以文本文件读取的方式打开filePath路径的文件:

然后, 使用std::getline()从打开的文件流中 按行读取数据到string line中. 每次读取成功就将line的内容添加到输出型参数out之后. 直到读取结束.

std::getline()是按行读取的, 可以用来读取文本文件, 但是不能用来读取二进制数据文件因为,
std::getline()是通过'\n'来判断一行结束的位置的, 并且它会对一些字符过滤或转换. 这用来读取二进制文件是不合理的因为二进制文件可能没有
'\n'符, 并且二进制文件读取, 要求 取原始的字节而不改变.使用
std::getline()读取二进制文件会导致意外的行为或读取错误
执行完读取之后, 关闭打开的文件流. 接口实现完成, 也可以成功获取文档的内容.
接下来就是根据文档内容, 获取title content url, 并去标签化了
parseTitle()接口实现
执行完readFile()之后, fileContent的内容就是文档的原始内容了.
文档的原始内容是html格式的.
而一个完整的html文件中, 有且只能有一个<title></title>标签对.
这个标签对之间的内容, 即为文档的title有效内容.
我们可以随便查看一个文档, 于官网的文档页面对比:

再去查看对应的网页:
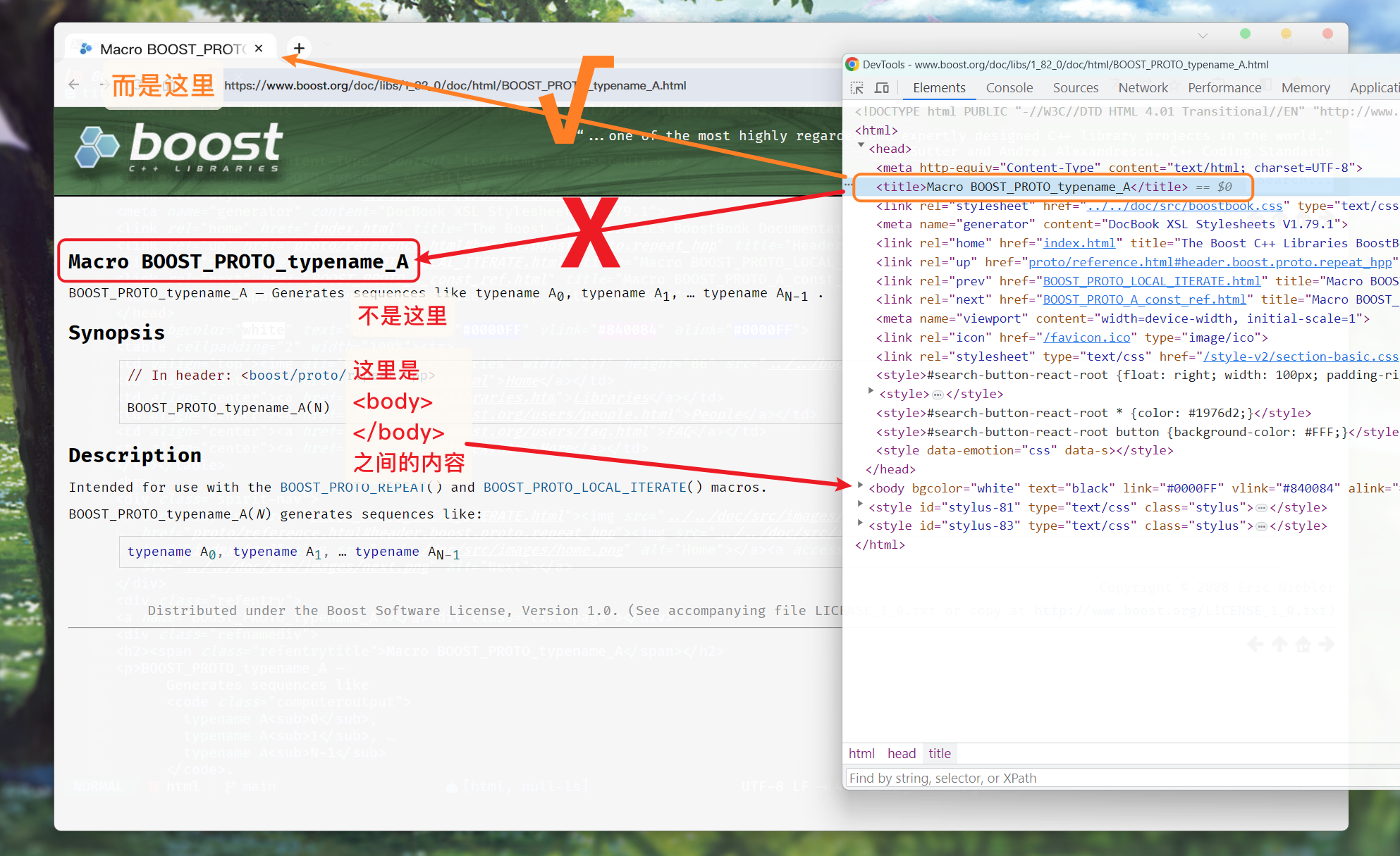
<title></title>标签对, 就表示浏览器标签页上的标题
了解到 一个完整的html文件中, 有且只能有一个<title></title>标签对
那么, 我们就可以直接根据<title></title>来找到文档的标题:
bool parseTitle(const std::string& fileContent, std::string* title) {// 简单分析一个html文件, 可以发现 <title>标签只有一对 格式是这样的: <title> </title>, 并且<title>内部不会有其他字段// 在 > < 之间就是这个页面的 title , 所以我们想要获取 title 就只需要获取<title>和</title> 之间的内容就可以了// 1. 先找 <title>std::size_t begin = fileContent.find("<title>");if (begin == std::string::npos) {// 没找到return false;}// 2. 再找 </title>std::size_t end = fileContent.find("</title>");if (end == std::string::npos) {// 没找到return false;}// 走到这里就是都找到了, 然后就可以获取 > <之间的内容了begin += std::string("<title>").size(); // 让begin从>后一位开始if (begin > end) {return false;}*title = fileContent.substr(begin, end - begin);return true;
}
直接在fileContent中找<title>和</title>的位置:

找到两个字符串的位置之后, 截取从begin + string("<title>").size() 到 end - begin + string("<title>").size()之间的内容就好了
不过, 要注意begin + string("<title>").size() < end 成立

至此, 就已经获取的文档的title并存储到了docInfo结构体变量中.
parseContent()接口实现
parseContent()接口需要实现的功能是, 获取去掉标签的文档html内容.
也就是说, 文档html内容 去标签是在此函数内部实现的.
其实去标签的操作也很简单, 不需要改动fileContent的原内容.
只需要按字节遍历fileContent, 如果是标签内的数据 就不做处理, 如果是标签外的有效数据, 就添加到输出型参数中就可以了
bool parseContent(const std::string& fileContent, std::string* content) {// parseContent 需要实现的功能是, 清除标签// html的语法都是有一定的格式的. 虽然标签可能会成对出现 <head></head>, 也可能会单独出现 <mate>// 但是 标签的的内容永远都是在相邻的 < 和 >之间的, 在 > 和 < 之间的则是是正文的内容// 并且, html文件中的第一个字符永远都是 <, 并且之后还会有> 成对出现// 可以根据这种语法特性来遍历整个文件内容 清除标签enum status {LABLE, // 表示在标签内CONTENT // 表示在正文内};enum status s = LABLE; // 因为首先的状态一定是在标签内for (auto c : fileContent) {switch (s) {case LABLE: {// 如果此时的c表示标签内的内容, 不做处理// 除非 当c等于>时, 表示即将出标签, 此时需要切换状态if (c == '>') {s = CONTENT;}break;}case CONTENT: {// 此时 c 表示正文的内容, 所以需要存储在 content中, 但是为了后面存储以及分割不同文档, 所以也不要存储 \n, 将 \n 换成 ' '存储// 并且, 当c表示<时, 也就不要存储了, 表示已经出了正文内容, 需要切换状态if (c == '<') {s = LABLE;}else {if (c == '\n') {c = ' ';}*content += c;}break;}default:break;}}return true;
}
html文件中的标签, 总是以<开始 以>结尾, 即 在一对<>内的是标签的内容. 在此之外的是有效内容.
并且, html文件内容的开头的第一个字符 一定是<符号.
我们可以根据html文件 这样的内容格式 来设置 一个简单的状态机
即, 在遍历fileContent过程中 所表示的字符 分为在标签内和在标签外 两个状态. 根据情况切换
如果在标签内, 就不做处理 直接进入下一个循环. 如果在标签内, 就将当前字符 添加到输出型参数content之后.
不过, 需要注意的是 如果存在字符在标签外, 但这个字符是'\n' 则考虑将此字符转换为' ' 然后再添加到参数中. 这是为了在最后一个操作中添加不同文档信息的分隔符.
parseUrl()接口实现
paeseUrl()接口需要实现的功能是 获取 当前文档 对应的在官网中的url
比如: BOOST_PROTO_typename_A.html, 在官网中的地址是 https://www.boost.org/doc/libs/1_82_0/doc/html/BOOST_PROTO_typename_A.html
这时候, 就要对比 源码中文档路径 和 项目中文档路径 以及 官网中文档的url 之间的关系了
源码中, 文档的路径是: boost_1_82_0/doc/html/xxxxxx.html 或 boost_1_82_0/doc/html/xxxxxx/xxxxxx.html
项目的parser程序中, filesList中记录的文档路径是: data/input/xxxxxx.html 或 data/input/xxxxxx/xxxxxx.html
而官网对应的文档url是: https://www.boost.org/doc/libs/1_82_0/doc/html/xxxxxx.html 或 https://www.boost.org/doc/libs/1_82_0/doc/html/xxxxxx/xxxxxx.html
那么, parser程序中 当前文档在官网中对应的url就可以是:
https://www.boost.org/doc/libs/1_82_0/doc/html + data/input之后的内容
所以, parseUrl()接口的实现是:
bool parseUrl(const std::string& filePath, std::string* url) {// 先去官网看一看 官网的url是怎么分配的: https://www.boost.org/doc/libs/1_82_0/doc/html/function/reference.html// 我们本地下载的boost库的html路径又是怎么分配的: boost_1_82_0/doc/html/function/reference.html// 我们在程序中获取的文件路径 即项目中文件的路径 又是什么: data/input/function/reference.html// 已经很明显了, url 的获取就是 https://www.boost.org/doc/libs/1_82_0/doc/html + /function/reference.html// 其中, 如果版本不变的话, https://www.boost.org/doc/libs/1_82_0/doc/html 是固定的// 而后半部分, 则是 filePath 除去 data/input, 也就是 const std::string srcPath = "data/input" 部分// 所以, url的获取也很简单std::string urlHead = "https://www.boost.org/doc/libs/1_82_0/doc/html";std::string urlTail = filePath.substr(srcPath.size()); // 从srcPath长度处向后截取*url = urlHead + urlTail;return true;
}
实现了 parseTitle() parseContent() parseUrl()
并在parseDocInfo()接口内 执行 parseTitle(fileContent, &doc._title) parseContent(fileContent, &doc._content) 和 parseUrl(filePath, &doc._url) 之后
docInfo_t doc变量内, 已经存储了 该文档的title 去标签后的content 以及该文档在官网中的url
parseDocInfo()的最后一步, 即为 将doc变量存储到输出型参数docResults(一个vector)中
至此, parseDocInfo()接口完成.
4. saveDocInfo()接口实现
之前的两个接口, 分别完成了:
enumFile(): 获取data/input/目录下所有.html文档文件名(携带相对路径), 存储到filesList(一个vector)中parseDocInfo(): 通过遍历filesList, 获取每个文档文件的路径, 读取文档内容. 并根据文档内容获取title去标签的content, 再根据文档文件路径获取 文档对应在官网中url, 并构成一个docInfo变量 存储到docResult(一个vector)中
也就是, 已经将 每个文档的title 去标签content 官网对应url以一个结构体变量的形式存储在了docResult(一个vector)中
那么, saveDocInfo()要做的就是, 将docResult中存储的每个文档的信息, 以一定的格式写入到 全局output所表示的文本文件(raw)中.
const std::string output = "data/output/raw"; // 保存文档所有信息的文件
该以什么样的格式写入呢?
写入, 不应该只考虑写入格式是否方便. 还需要考虑, 在之后的使用时 从文本文件中获取文档内容, 对文档内容的读取、区分、分割是否方便.
在项目中, 我们采用这种方案写入:
title\3content\3url\ntitle\3content\3url\ntitle\3content\3url\n...
即, 每个文档的信息以这样的格式写入文本文件中: title\3content\3url\n
以'\3'将不同的字段分隔开: "title" '\3' "去标签的content" '\3' "官网对应的url"
并在每个文档内容字段的结尾使用'\n', 以分割不同的文档: title1\3content1\3url1\n title2\3content2\3url2\n...
#define SEP '\3'bool saveDocInfo(const std::vector<docInfo_t>& docResults, const std::string& output) {// 最后就是将 已经结构化的所有的文档数据, 以一定的格式存储在指定的文件中.// 以什么格式存储呢? 每个文档都是结构化的数据: _title _content _url.// 我们可以将 三个字段以'\3'分割, 不过 _url后不用'\3' 而是用'\n'// 因为, 像文件中写入不能只关心写入, 还要考虑读取时的问题. 方便的 读取文本文件, 通常可以用 getline 来获取一行数据// 所以, 当以这种格式 (_title\3_content\3_url\n) 将 文档数据存储到文件中时, getline() 成功读取一次文件内容, 获取的就是一个文档的所有有效内容.// 按照二进制方式进行写入, 二进制写入, 写入什么就是什么 转义字符也不会出现被优化改变的现象std::ofstream out(output, std::ios::out | std::ios::binary);if (!out.is_open()) {// 文件打开失败std::cerr << "open " << output << " failed!" << std::endl;return false;}// 就可以进行文件内容的写入了for (auto& item : docResults) {std::string outStr;outStr = item._title;outStr += SEP;outStr += item._content;outStr += SEP;outStr += item._url;outStr += '\n';out.write(outStr.c_str(), outStr.size());}out.close();return true;
}
使用'\n'分隔不同的文档信息 的优点就是, 一次std::getline()获取到的就是一个文档的信息. 因为std::getline()就是按照'\n'来获取一行内容的.
这样也就可以直接使用ns_util::fileUtil::readFile()接口, 读取文档信息.
而使用'\3'分隔一个文档的不同字段, 是因为'\3'属于控制字符, 是不显示的. 当然也可以用其他不显示字符'\4'之类的.
至此, parser模块的代码就全部完成了
parser模块代码整合 及 演示
util.hpp:
// util.hpp 一般定义一些通用的宏定义、工具函数等#pragma once#include <iostream>
#include <vector>
#include <string>
#include <fstream>namespace ns_util {class fileUtil {public:// readFile 用于读取指定文本文件的内容, 到string输出型参数中static bool readFile(const std::string& filePath, std::string* out) {// 要读取文件内容, 就要先打开文件// 1. 以读取模式打开文件std::ifstream in(filePath, std::ios::in);if (!in.is_open()) {// 打卡文件失败std::cerr << "Failed to open " << filePath << "!" << std::endl;return false;}// 走到这里打开文件成功// 2. 读取文件内, 并存储到out中std::string line;while (std::getline(in, line)) {*out += line;}in.close();return true;}};
}
parser.cc:
#include <iostream>
#include <string>
#include <utility>
#include <vector>
#include <boost/filesystem.hpp>
#include "util.hpp"// 此程序是一个文档解析器
// boost文档的html文件中, 有许多的各种<>标签. 这些都是对搜索无关的内容, 所以需要清除掉
// 本程序实现以下功能:
// 1. 使用boost库提供的容器, 递归遍历 ./data/input 目录下(包括子目录)的所有文档html, 并保存其文件名到 vector中
// 2. 通过 vector 中保存的 文档名, 找到文档 并对 所有文档的内容去标签
// 3. 还是通过 vector中保存的文档名
// 读取所有文档的内容, 以每个文档 标题 内容 url 结构构成一个docInfo结构体. 并以 vector 存储起来
// 4. 将用vector 存储起来的所有文档的docInfo 存储到 ./data/output/raw 文件中, 每个文档的info用 \n 分割
// 至此 完成对所有文档的 解析// 为提高解析效率, 可以将 2 3 步骤合并为一个函数:
// 每对一个文档html文件去标签之后, 就获取文档内容构成docInfo结构体, 并存储到 vector 中// 代码规范
// const & 表示输入型参数: const std::string&
// * 表示输出型参数: std::string*
// & 表示输入输出型参数: std::string&#define ENUM_ERROR 1
#define PARSEINFO_ERROR 2
#define SAVEINFO_ERROR 3
#define SEP '\3'const std::string srcPath = "data/input"; // 存放所有文档的目录
const std::string output = "data/output/raw"; // 保存文档所有信息的文件typedef struct docInfo {std::string _title; // 文档的标题std::string _content; // 文档内容std::string _url; // 该文档在官网中的url
} docInfo_t;bool enumFile(const std::string& srcPath, std::vector<std::string>* filesList);
bool parseDocInfo(const std::vector<std::string>& filesList, std::vector<docInfo_t>* docResults);
bool saveDocInfo(const std::vector<docInfo_t>& docResults, const std::string& output);int main() {std::vector<std::string> filesList;// 1. 递归式的把每个html文件名带路径,保存到filesList中,方便后期进行一个一个的文件进行读取if (!enumFile(srcPath, &filesList)) {// 获取文档html文件名失败std::cerr << "Failed to enum file name!" << std::endl;return ENUM_ERROR;}// 走到这里 获取所有文档html文件名成功// 2. 按照filesList读取每个文档的内容,并进行去标签解析// 3. 并获取文档的内容 以 标题 内容 url 构成docInfo结构体, 存储到vector中std::vector<docInfo_t> docResults;if (!parseDocInfo(filesList, &docResults)) {// 解析文档内容失败std::cerr << "Failed to parse document information!" << std::endl;return PARSEINFO_ERROR;}// 走到这里 获取所有文档内容 并以 docInfo 结构体形式存储到vector中成功// 4: 把解析完毕的各个文件内容,写入到output , 按照\3作为每个文档的分割符if (!saveDocInfo(docResults, output)) {std::cerr << "Failed to save document information!" << std::endl;return SAVEINFO_ERROR;}return 0;
}bool enumFile(const std::string& srcPath, std::vector<std::string>* filesList) {// 使用 boost库 来对路径下的文档html进行 递归遍历namespace bs_fs = boost::filesystem;// 根据 srcPath 构建一个path对象bs_fs::path rootPath(srcPath);if (!bs_fs::exists(rootPath)) {// 指定的路径不存在std::cerr << srcPath << " is not exists" << std::endl;return false;}// boost库中 可以递归遍历目录以及子目录中 文件的迭代器, 不初始化可看作空bs_fs::recursive_directory_iterator end;// 再从 rootPath 构建一个迭代器, 递归遍历目录下的所有文件for (bs_fs::recursive_directory_iterator iter(rootPath); iter != end; iter++) {// 目录下 有目录文件 也有普通文件, 普通文件不仅仅只有 .html文件, 所以还需要过滤掉目录文件和非.html文件if (!bs_fs::is_regular_file(*iter)) {// 不是普通文件continue;}if (iter->path().extension() != ".html") { // boost::path 对象的 extension()接口, 可以获取到所指文件的后缀// 不是 html 文件continue;}// 走到这里的都是 .html 文件// 将 文件名存储到 filesList 中filesList->push_back(iter->path().string());}return true;
}bool parseTitle(const std::string& fileContent, std::string* title) {// 简单分析一个html文件, 可以发现 <title>标签只有一对 格式是这样的: <title> </title>, 并且<title>内部不会有其他字段// 在 > < 之间就是这个页面的 title , 所以我们想要获取 title 就只需要获取<title>和</title> 之间的内容就可以了// 1. 先找 <title>std::size_t begin = fileContent.find("<title>");if (begin == std::string::npos) {// 没找到return false;}std::size_t end = fileContent.find("</title>");if (end == std::string::npos) {// 没找到return false;}// 走到这里就是都找到了, 然后就可以获取 > <之间的内容了begin += std::string("<title>").size(); // 让begin从>后一位开始if (begin > end) {return false;}*title = fileContent.substr(begin, end - begin);return true;
}
bool parseContent(const std::string& fileContent, std::string* content) {// parseContent 需要实现的功能是, 清除标签// html的语法都是有一定的格式的. 虽然标签可能会成对出现 <head></head>, 也可能会单独出现 <mate>// 但是 标签的的内容永远都是在相邻的 < 和 >之间的, 在 > 和 < 之间的则是是正文的内容// 并且, html文件中的第一个字符永远都是 <, 并且之后还会有> 成对出现// 可以根据这种语法特性来遍历整个文件内容 清除标签enum status {LABLE, // 表示在标签内CONTENT // 表示在正文内};enum status s = LABLE; // 因为首先的状态一定是在标签内for (auto c : fileContent) {switch (s) {case LABLE: {// 如果此时的c表示标签内的内容, 不做处理// 除非 当c等于>时, 表示即将出标签, 此时需要切换状态if (c == '>') {s = CONTENT;}break;}case CONTENT: {// 此时 c 表示正文的内容, 所以需要存储在 content中, 但是为了后面存储以及分割不同文档, 所以也不要存储 \n, 将 \n 换成 ' '存储// 并且, 当c表示<时, 也就不要存储了, 表示已经出了正文内容, 需要切换状态if (c == '<') {s = LABLE;}else {if (c == '\n') {c = ' ';}*content += c;}break;}default:break;}}return true;
}
bool parseUrl(const std::string& filePath, std::string* url) {// 先去官网看一看 官网的url是怎么分配的: https://www.boost.org/doc/libs/1_82_0/doc/html/function/reference.html// 我们本地下载的boost库的html路径又是怎么分配的: boost_1_82_0/doc/html/function/reference.html// 我们在程序中获取的文件路径 即项目中文件的路径 又是什么: data/input/function/reference.html// 已经很明显了, url 的获取就是 https://www.boost.org/doc/libs/1_82_0/doc/html + /function/reference.html// 其中, 如果版本不变的话, https://www.boost.org/doc/libs/1_82_0/doc/html 是固定的// 而后半部分, 则是 filePath 除去 data/input, 也就是 const std::string srcPath = "data/input" 部分// 所以, url的获取也很简单std::string urlHead = "https://www.boost.org/doc/libs/1_82_0/doc/html";std::string urlTail = filePath.substr(srcPath.size()); // 从srcPath长度处向后截取*url = urlHead + urlTail;return true;
}bool parseDocInfo(const std::vector<std::string>& filesList, std::vector<docInfo_t>* docResults) {// parseDocInfo 是对文档html文件的内容做去标签化 并 获取 title content url 构成结构体// 文档的路径都在 filesList 中存储着, 所以需要遍历 filesList 处理文件for (const std::string& filePath : filesList) {// 获取到文档html的路径之后, 就需要对 html文件进行去标签化等一系列解析操作了// 1. 读取文件内容到 string 中std::string fileContent;if (!ns_util::fileUtil::readFile(filePath, &fileContent)) {// 读取文件内容失败continue;}// 读取到文档html文件内容之后, 就可以去标签 并且 获取 title content 和 url了docInfo_t doc;// 2. 解析并获取title, html文件中只有一个 title标签, 所以再去标签之前 获取title比较方便if (!parseTitle(fileContent, &doc._title)) {// 解析title失败continue;}// 3. 解析并获取文档有效内容, 去标签的操作实际就是在这一步进行的if (!parseContent(fileContent, &doc._content)) {// 解析文档有效内容失败continue;}// 4. 获取 官网的对应文档的 urlif (!parseUrl(filePath, &doc._url)) {continue;}// 做完上面的一系列操作 走到这里时 如果没有不过 doc 应该已经被填充完毕了// doc出此次循环时就要被销毁了, 所以将doc 设置为将亡值 可以防止拷贝构造的发生 而使用移动语义来向 vector中添加元素// 这里发生拷贝构造是非常的消耗资源的 因为 doc._content 非常的大docResults->push_back(std::move(doc));}return true;
}bool saveDocInfo(const std::vector<docInfo_t>& docResults, const std::string& output) {// 最后就是将 已经结构化的所有的文档数据, 以一定的格式存储在指定的文件中.// 以什么格式存储呢? 每个文档都是结构化的数据: _title _content _url.// 我们可以将 三个字段以'\3'分割, 不过 _url后不用'\3' 而是用'\n'// 因为, 像文件中写入不能只关心写入, 还要考虑读取时的问题. 方便的 读取文本文件, 通常可以用 getline 来获取一行数据// 所以, 当以这种格式 (_title\3_content\3_url\n) 将 文档数据存储到文件中时, getline() 成功读取一次文件内容, 获取的就是一个文档的所有有效内容.// 按照二进制方式进行写入, 二进制写入, 写入什么就是什么 转义字符也不会出现被优化改变的现象std::ofstream out(output, std::ios::out | std::ios::binary);if (!out.is_open()) {// 文件打开失败std::cerr << "open " << output << " failed!" << std::endl;return false;}// 就可以进行文件内容的写入了for (auto& item : docResults) {std::string outStr;outStr = item._title;outStr += SEP;outStr += item._content;outStr += SEP;outStr += item._url;outStr += '\n';out.write(outStr.c_str(), outStr.size());}out.close();return true;
}
上面就是项目中 parser模块的全部代码了.
编译代码, 并运行可执行程序:
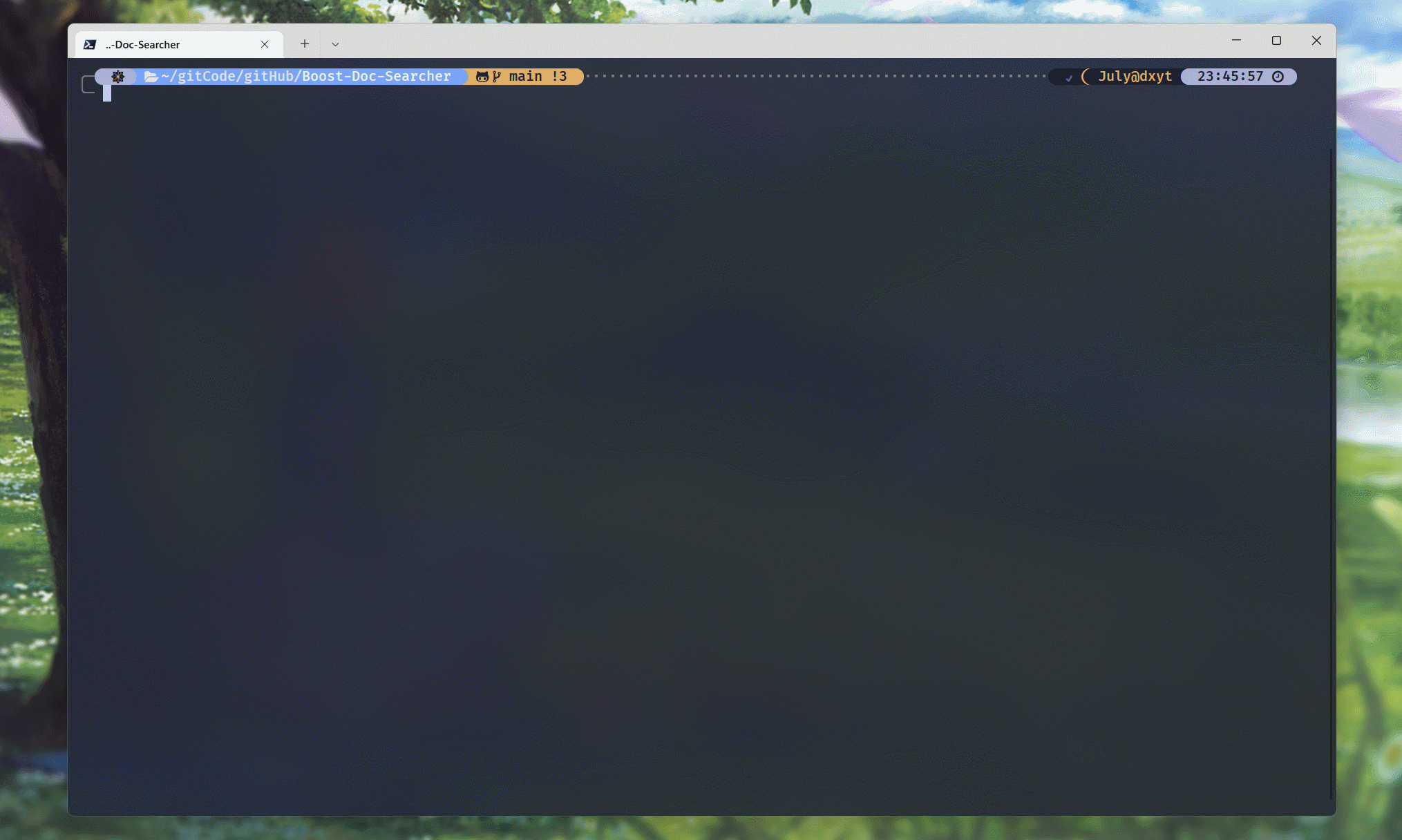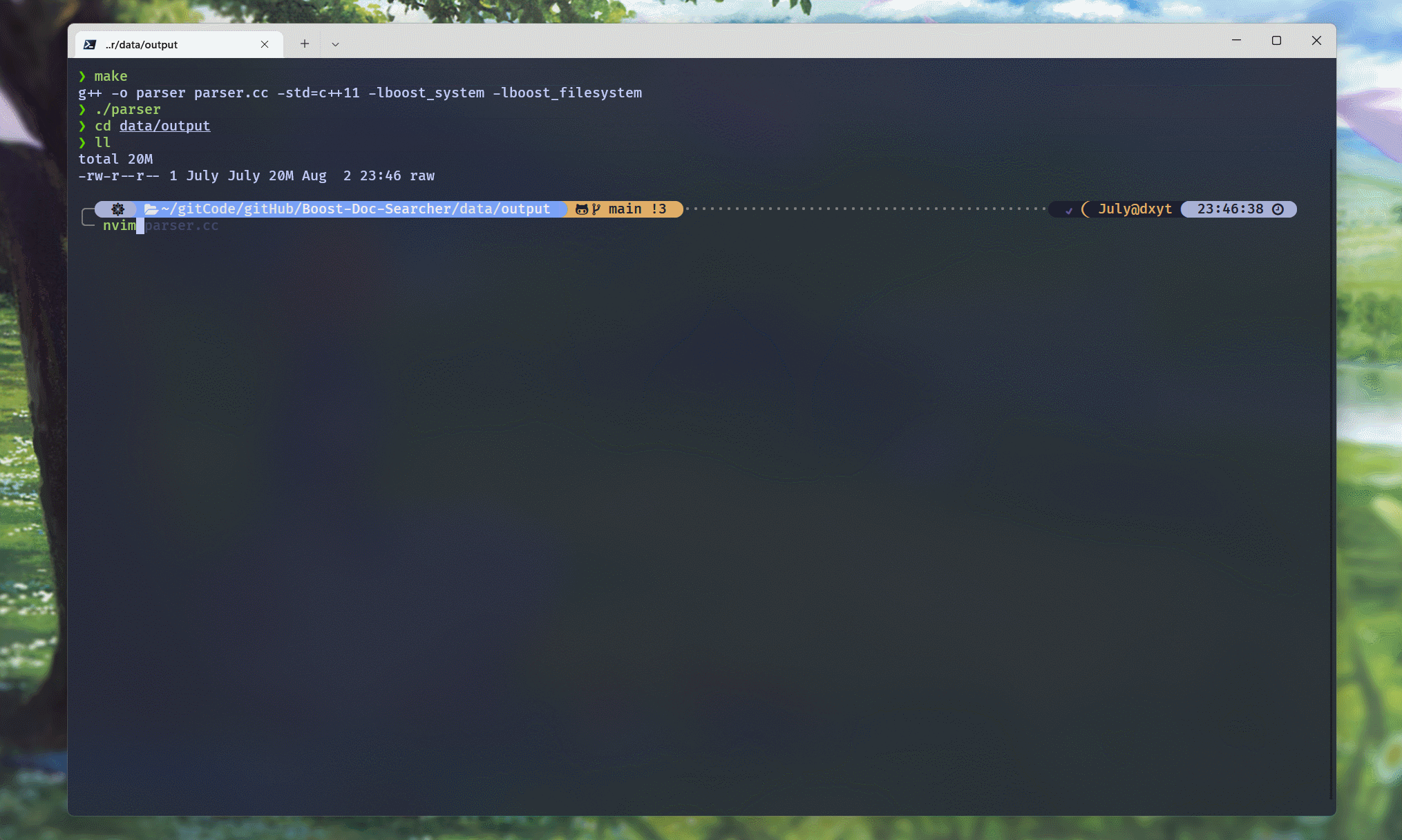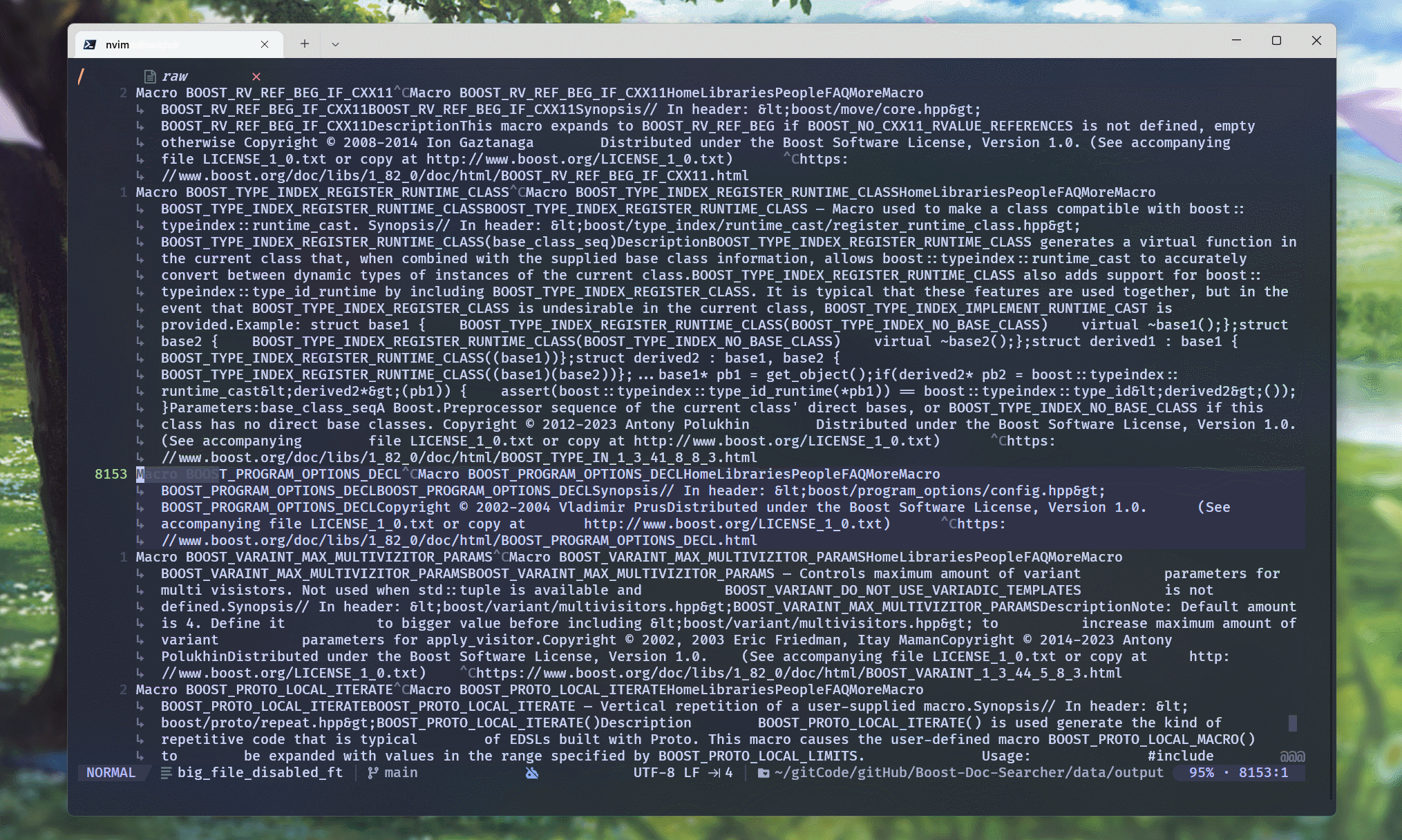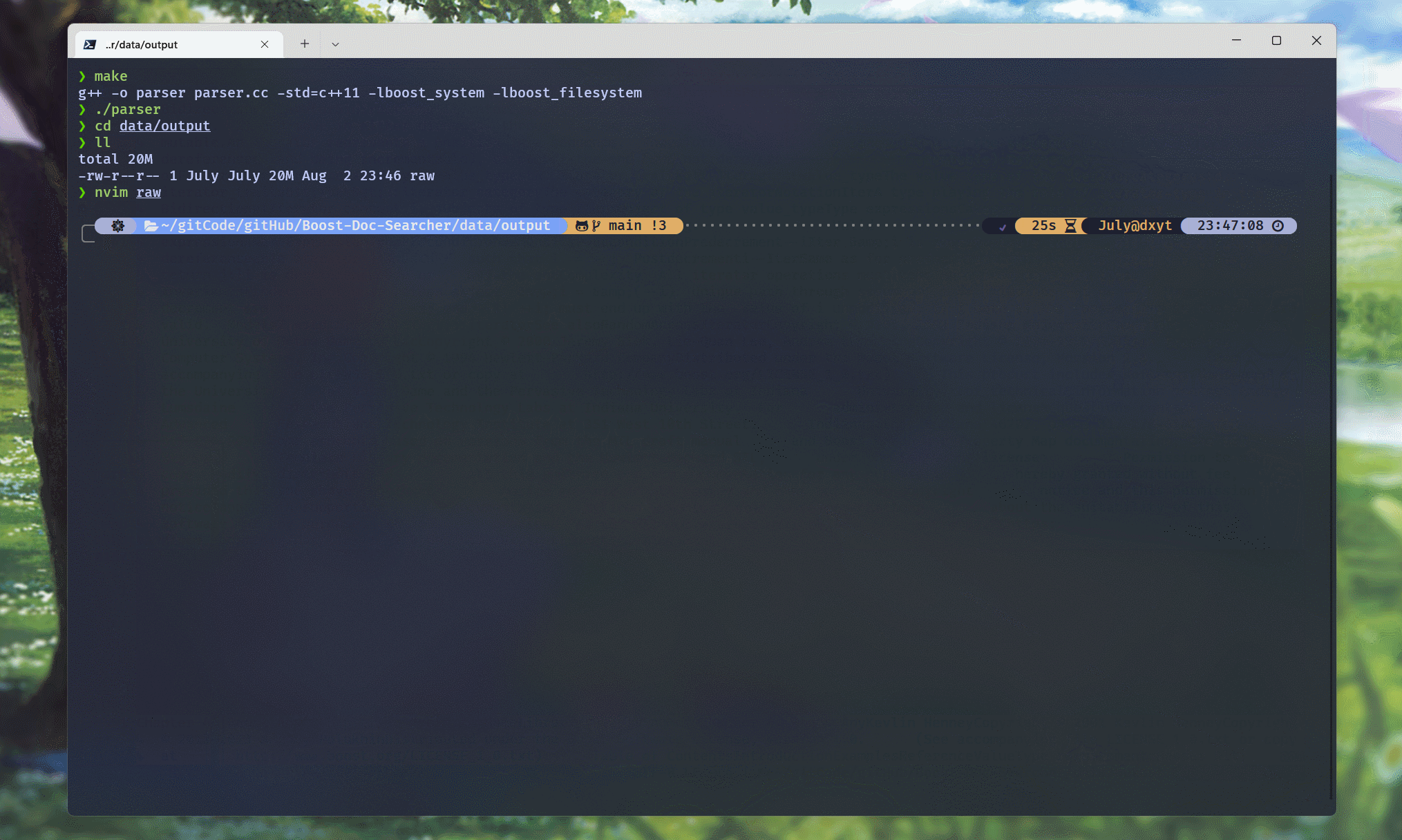
可以看到, raw文件中, 每行都是一个文档的docInfo信息数据.
parser模块的作用
在上一篇介绍Boost文档站内搜索引擎 项目背景文章中, 就提到过:
搜索引擎索引的建立步骤一般是这样的:
- 爬虫程序爬取网络上的内容, 获取网页等数据
- 对爬取的内容进行解析、去标签, 提取文本、链接、媒体内容等信息
- 对提取的文本进行分词、处理, 得到词条
- 根据词条生成索引, 包括正排索引、倒排索引等
爬取网页数据我们不需要做, 可以直接从官网下载源码.
但是, 后面的步骤就需要自己动手做了.
而parser解析器 模块做的 就是建立索引的第2个步骤: 对爬取的内容进行解析、去标签, 提取文本、链接、媒体内容等信息
我们实现的parser解析器, 就是对 所有文档html文件的内容, 进行去标签, 提取文本, 链接等操作, 并将所有内汇总在一个文件中.
OK, 本篇文章到这里就结束了~
感谢阅读~
相关文章:
[C++项目] Boost文档 站内搜索引擎(2): 文档文本解析模块parser的实现、如何对文档文件去标签、如何获取文档标题...
项目开始的准备工作 在上一篇文章中, 已经从Boost官网获取了Boost库的源码. 接下来就要编写代码了. 不过还需要做一些准备工作. 创建项目目录 所有的项目文件肯定要在一个目录下, 找一个位置执行下面这行指令 mkdir Boost-Doc-Searcher将文档html文件, 存放到项目中 cd Boost…...

若依框架vue使用Element 如何把当前页面的所有Table表格row.id和一个表单的16个字段内容通过js传Java后台,Java后台是如何接收的
如果你使用的是Vue.js与Element UI框架,可以按照以下步骤将当前页面的所有表格行的row.id和一个表单的16个字段内容通过JavaScript传递给Java后台: 首先,在Vue组件中,使用Element UI的Table组件和Form组件来构建表格和表单。为了…...
迁移学习:使用Restnet预训练模型构建高效的水果识别模型
引言 本项目在Restnet预训练模型的基础上,通过迁移学习构建了水果分类识别模型,经过30epochs训练,实现了模型的快速收敛,准确率达到了96%以上。通过此项目实战,我们进一步熟悉了如何在预训练模型的基础上进行迁移学习…...

浅谈机器视觉
目录 1.什么是机器视觉 2.学习机器视觉需要掌握的知识 3.机器视觉的由来 4.机器视觉带来的福利 1.什么是机器视觉 机器视觉(Computer Vision)是人工智能领域中的一个分支,旨在通过模仿人类的视觉系统,使计算机能够理解和解释图…...

助力保险行业数字化创新,麒麟信安参展2023中国财险科技应用高峰论坛
2023年7月27日,由中科软科技股份有限公司主办的“中国财险科技应用高峰论坛”在北京古北水镇成功举办。作为享誉中国保险科技界的盛会,本次活动以“数智保险 创新未来”主题,汇聚全国数百位保险公司主管领导、资深保险行业信息化专家…...
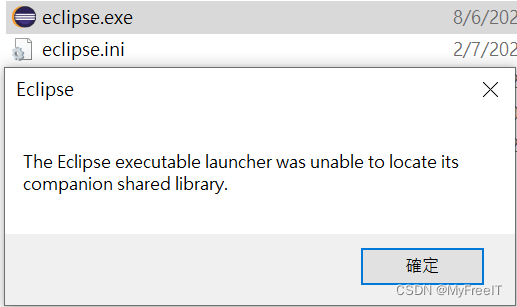
eclipse was unable to locate its companion shared library
当转移或者Copy工程时, eclipse was unable to locate its companion shared library eclipse.ini 里面的路径配置错误导致 --launcher.library C:/Users/**/.p2/pool/plugins/org.eclipse.equinox. launcher.win32.win32.x86_64_1.2.700.v20221108-1024 -product …...

【MySQL】使用C/C++连接MySQL数据库
【MySQL】使用C/C连接MySQL数据库 验证使用select特殊点 本文目的:使用MySQL提供的CAPI完成对数据库的操作 验证 #include <iostream> #include <mysql/mysql.h>int main() {std::cout<<"mysql cilent version: "<<mysql_get_cl…...

【Python】从同步到异步多核:测试桩性能优化,加速应用的开发和验证
目录 测试工作中常用到的测试桩mock能力 应用场景 简单测试桩 http.server扩展:一行命令实现一个静态文件服务器 性能优化:使用异步响应 异步响应 能优化:利用多核 gunicorn 安装 gunicorn 使用 gunicorn 启动服务 性能优化&#…...

使用checkBox组件时,动态设置disabled,仍能触发click事件的原因及解决办法
在使用vant的Checkbox组件时,为了实现复选框组选择一个,禁用掉另一个,同时添加点击事件的功能时。遇到明明disabledtrue,但仍能触发点击事件的情况。为此,分析下触发点击事件的原因及解决方法。 一、原因 1、异步更新…...

【JavaScript】如何进行除法运算且保留小数部分不参与四舍五入【推荐库bignumber.js 】
在 bignumber.js 中进行除法运算并保留小数部分,不参与四舍五入,你可以使用 decimalPlaces 方法来指定保留的小数位数,并使用 ROUND_DOWN 舍入模式来实现截断而不进行四舍五入。 以下是在 bignumber.js 中进行除法运算且保留小数部分&#x…...

掌握Java JDK 1.8 API帮助文档中文版,事半功倍编程
文章目录 1. JDK 1.8 API帮助文档简介2. 如何查阅JDK 1.8 API帮助文档中文版2.1 在线文档2.2 本地文档2.3 集成开发环境(IDE) 3. 如何使用JDK 1.8 API帮助文档中文版3.1 寻找类和方法3.2 阅读文档说明3.3 查看示例代码 4. 总结 引言: Java是一…...
Spring Boot的自动配置原理
一.原理解释 Spring Boot的自动配置是Spring框架的一个重要特性,它旨在简化应用程序的开发和部署过程。自动配置通过基于类路径中的依赖关系和配置文件内容来预先配置Spring应用程序的各种组件和功能。这样,我们可以在无需显式配置大量参数的情况下&…...

NFS服务器
目录 1.nfs简介 2.nfs安装与配置简述 安装包: 配置文件: /etc/exports配置文件的写法 权限:(客户端对共享目录的权限,但是最主要的还是目录本身的权限) 3.nfs配置 服务端 客户端 4.autofs自动挂载…...

说明学习委员之作业管理系统—后端部分
项目背景 学习委员收集作业的过程,繁琐且曲折,作者充分理解并体谅为大家服务的苦逼学习委员,以此为出发点和灵感,设计并开发了此套作业管理系统,希望能帮助各位提高效率,早日摆脱重复机械式的工作…...

质数(判定质数 分解质因数 筛质数)
目录 一、判定质数思路分析代码实现 二、分解质因数思路分析典型题目代码实现 三、质数筛经典题目思路分析1. 朴素筛法2. 埃氏筛法3. 欧拉筛法 一、判定质数 思路分析 由于每个合数的因子是成对出现的,即如果 d d d 是 n n n 的因子,那么 n d \frac…...
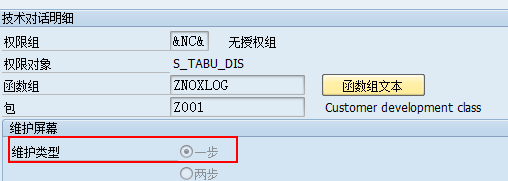
SAP数据库表维护视图生成器的使用
在SAP中,经常需要自定义数据库表。而且可能需要人工维护数据库表中的数据,可以通过SM30进行维护数据;但是SM30事务的权限太大,不适宜将SM30直接分配;因此,可以通过给维护表分配事务代码,来达到控…...
数据结构 | 递归
目录 一、何谓递归 1.1 计算一列数之和 1.2 递归三原则 1.3 将整数转换成任意进制的字符串 二、栈帧:实现递归 三、递归可视化 四、谢尔平斯基三角形 五、复杂的递归问题 六、动态规划 一、何谓递归 递归是解决问题的一种办法,它将问题不断地分…...

微信发视频怎么不压缩画质?试试这几招
微信是我们常用的社交工具了,很多朋友都会用它跟好友分享视频,但想必大家都知道,微信为了节省宽带和存储空间,会自动对上传的视频进行压缩处理,甚至过大的视频会被限制发送,怎么才能让微信不自动压缩画质呢…...
【网络安全带你练爬虫-100练】第16练:使用session发送请求
目录 一、目标1:使用seesion进去请求 二、网络安全O 一、目标1:使用seesion进去请求 (1)应用: 通过创建会话(session)对象来请求并爬取返回的数据包 情景:需要登录才能爬取的网…...

论文代码学习—HiFi-GAN(3)——模型损失函数loss解析
文章目录 引言正文生成器损失函数最小二乘损失函数梅尔频谱图损失函数特征匹配损失函数生成器最终损失函数loss生成器loss对应代码 鉴定器损失函数鉴定器损失函数代码 总结引用 引言 这里翻译了HiFi-GAN这篇论文的具体内容,具体链接。这篇文章还是学到了很多东西&a…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...

3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验?
3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验? 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

Hyper-V离散设备分配图形化解决方案:企业级虚拟化性能优化实践
Hyper-V离散设备分配图形化解决方案:企业级虚拟化性能优化实践 【免费下载链接】DDA 实现Hyper-V离散设备分配功能的图形界面工具。A GUI Tool For Hyper-Vs Discrete Device Assignment(DDA). 项目地址: https://gitcode.com/gh_mirrors/dd/DDA 在数字化转…...

5个高效技巧:重新定义你的Chrome书签管理体验
5个高效技巧:重新定义你的Chrome书签管理体验 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 你是否曾花费数分钟在混乱的书签海洋中寻找那…...

yEd画流程图保姆级避坑指南:从界面解析到高效导出PNG/JPG全流程
yEd流程图高效绘制全攻略:从界面优化到专业导出的进阶技巧第一次打开yEd时,那个布满各种面板和参数的界面确实容易让人望而生畏。但别担心,经过几个月的深度使用,我发现这款工具其实隐藏着许多能极大提升效率的设计细节。本文将带…...

YesCaptcha插件+DdddOCR实战:为无障碍测试或自动化脚本打造免费验证码解决方案
YesCaptcha插件DdddOCR实战:为无障碍测试或自动化脚本打造免费验证码解决方案验证码作为网络安全的重要防线,却常常成为自动化流程和无障碍访问的"拦路虎"。传统解决方案要么成本高昂,要么识别率不稳定。本文将揭示如何通过YesCapt…...