LLM大模型——langchain相关知识总结
目录
- 一、简介
- LangChain的主要价值支柱
- 简单安装
- 二、 LangChain的主要模块
- 1.Model I/O
- prompt模版定义
- 调用语言模型
- 2. 数据连接
- 3. chains
- 4. Agents
- 5. Memory
- Callbacks
- 三、其他记录
- 多进程调用
主要参考以下开源文档
文档地址:https://python.langchain.com/en/latest/
学习github:https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
一、简介
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。主要有 2 个能力:
- 可以将 LLM 模型与外部数据源进行连接
- 允许与 LLM 模型进行交互
LangChain的主要价值支柱
-
组件:用于处理语言模型的抽象,以及每个抽象的实现集合。无论是否使用LangChain框架的其余部分,组件都是模块化的,易于使用。
-
现成的链:用于完成特定更高级别任务的组件的结构化组装,可以理解为一个个任务。
简单安装
pip install langchain
二、 LangChain的主要模块
1.Model I/O
提供了丰富的语言模型的借口供用户调用
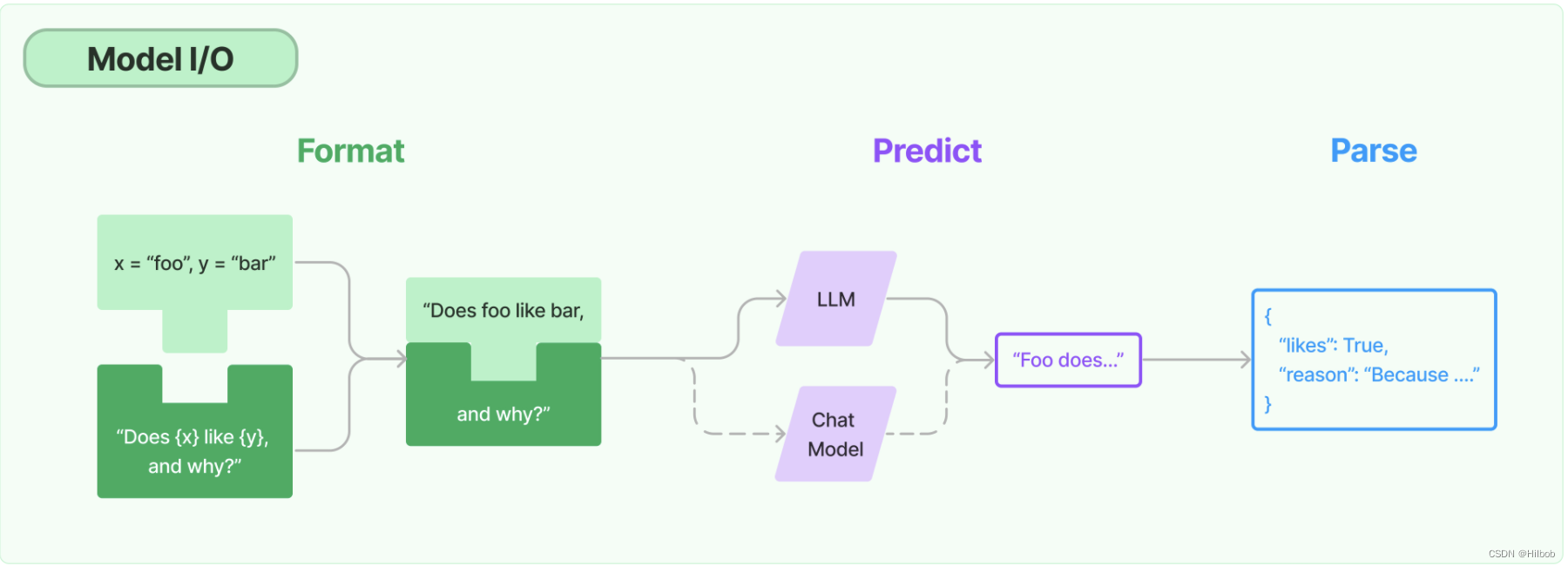
这里主要记录一波我觉得比较有用的几个点:
prompt模版定义
这个适用于批量处理某些问题,我可以定义一个模版,然后替换中间的某些内容喂入llm即可:
from langchain import PromptTemplatetemplate = """
你好请你回答下面的问题:{question}?
"""prompt = PromptTemplate.from_template(template)
prompt.format(product="question")
有时候对于一个模版,我们可能需要传递多个参数。那么可以用下面的操作:
template = """
我会给你一些例子如下:
{example},
请你参考上面的例子,回答下面的问题:{question}?
"""
prompt = PromptTemplate(input_variables=["example", "question"], template=template
)
parm={"example": "xxxx", "question":"qqqqqq"}
prompt.format(**parm)
调用语言模型
这里有两种类别:一种是llm,仅以单个文本为输入;另一种是chat model,以文本列表为输入。
llm调用:openai的模型需要key,这里需要点科技,自己去openai官网申请下
import os
from langchain.llms import OpenAI
os.environ["OPENAI_API_KEY"] = '你的api key'llm = OpenAI(model_name="text-davinci-003", max_tokens=1024)
result = llm("你是谁?")
chat model调用
from langchain.chat_models import ChatOpenAI
from langchain.schema import (AIMessage,HumanMessage,SystemMessage
)
chat = ChatOpenAI(openai_api_key="...")
result = chat([HumanMessage(content="你是谁?")])
2. 数据连接
提供了特定数据的接口,包括文档加载,文档处理,词嵌入等类,可以很方便处理输入。类似的构建基于知识库的聊天模型或者处理超长文本输入时,用这个就很方便。
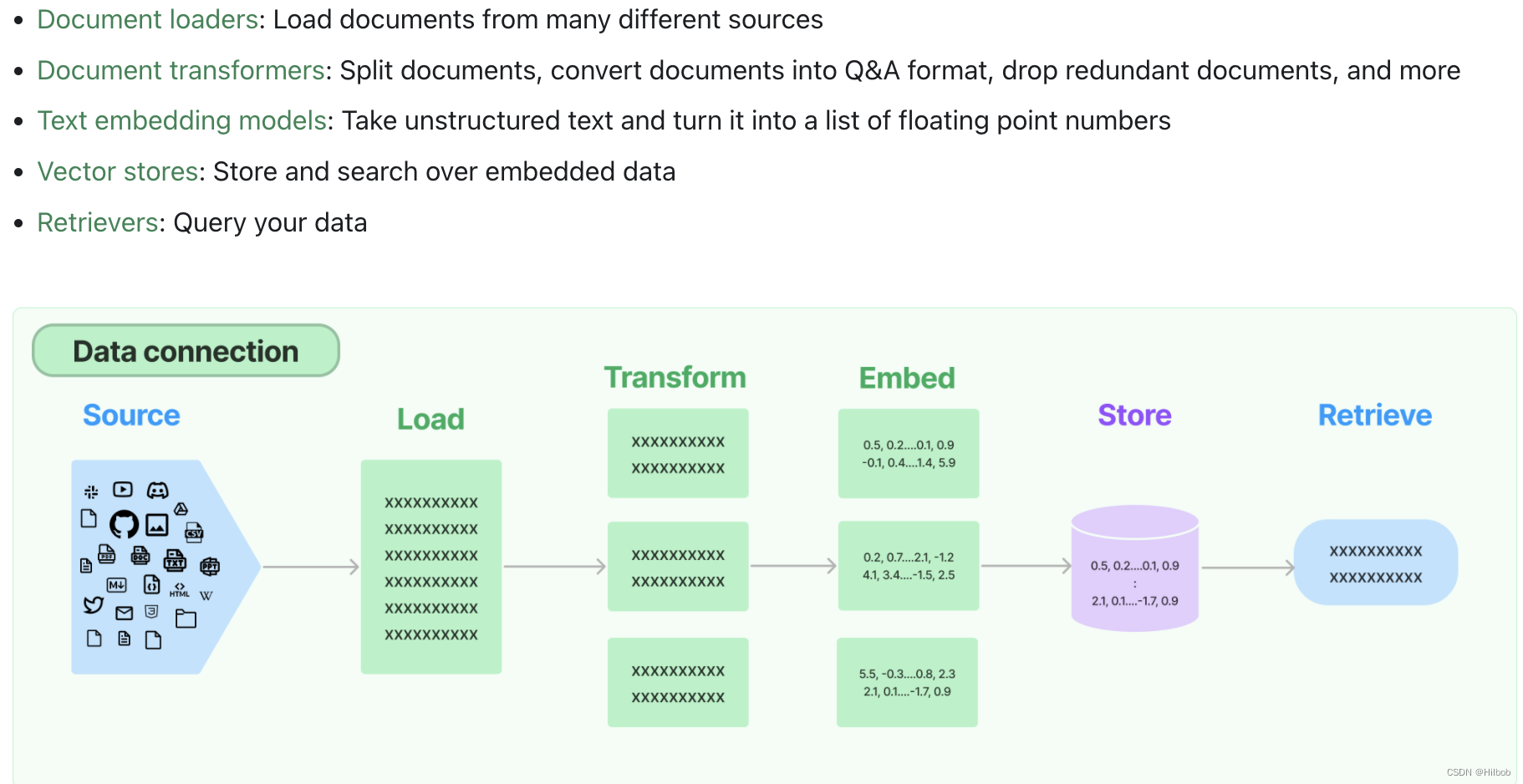
这里记录一个处理超长文本输入的例子,首先使用document_loaders加载文本。如果想要用openai api输入一个超长的文本并进行返回,一旦文本超过了 api 最大的 token 限制就会报错。一个解决办法是使用text_splitter对输入进行分段,比如通过 tiktoken 计算并分割,然后将各段发送给 api 进行总结,最后将各段的总结再进行一个全部的总结。
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI# 导入文本
loader = UnstructuredFileLoader("test.txt")
# 将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 0
)# 切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')# 加载 llm 模型
llm = OpenAI(model_name="text-davinci-003", max_tokens=1500)# 创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)# 执行总结链
chain.run(split_documents)
3. chains
结构化调用序列:虽然说单独地使用LLM对于简单的应用程序来说很方便,但有时候我们可能需要使用不同的LLM,这时候使用chain来管理就很方便了。LangChain为此类“链式”应用程序提供了Chain接口。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChainllm = OpenAI(temperature=0.95)
prompt = PromptTemplate(input_variables=["question"],template="回答下面问题 {question}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run("1+1=?"))
4. Agents
让链根据给定的高级指令选择使用哪些工具,这里我没怎么用过,到时候用到就看文档吧
5. Memory
在链运行之间保留应用程序状态
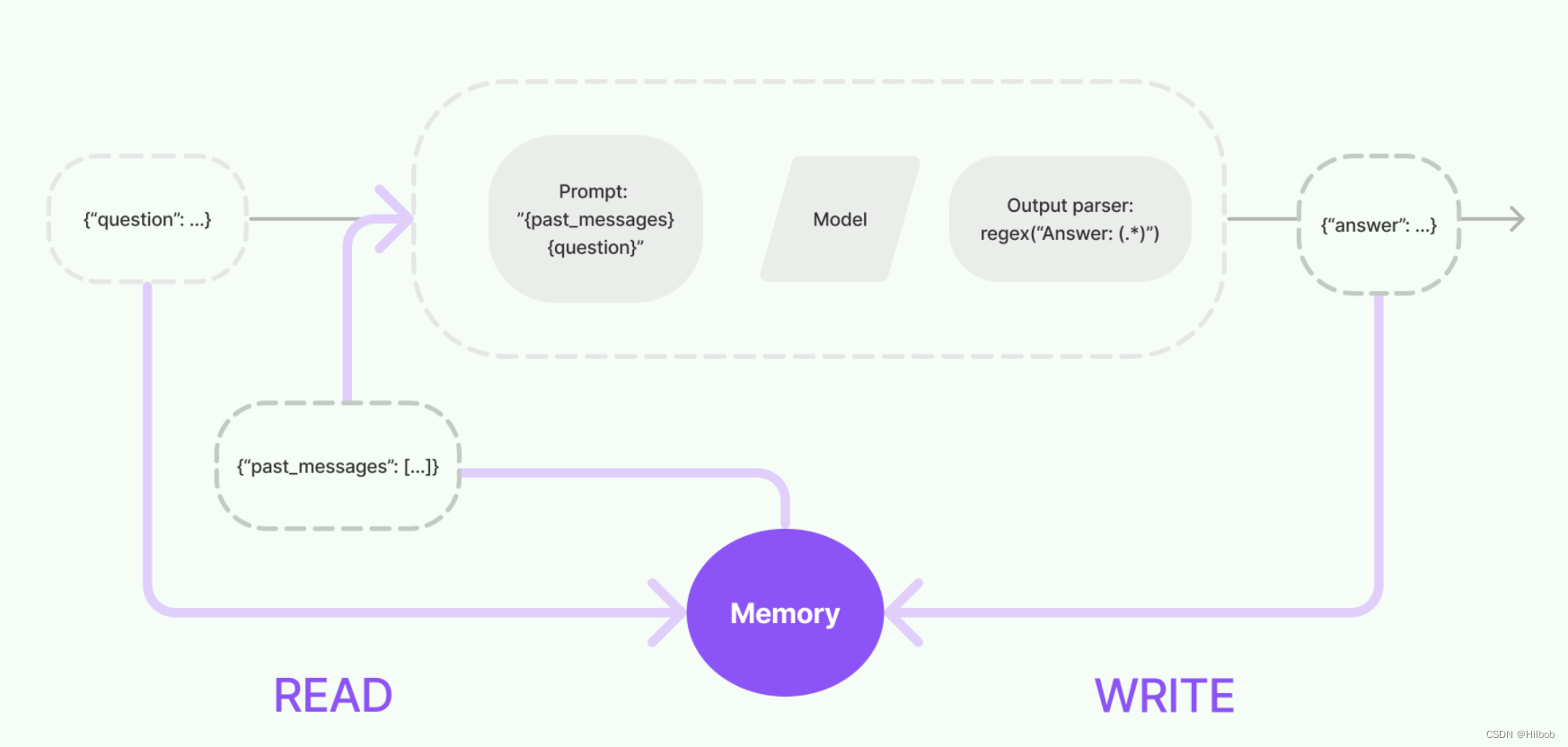
这里典型的应用就是聊天模型,我们需要记忆以往的聊天内容,用这个就比较方便了
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemoryllm = OpenAI(temperature=0.95)
template = """你是我的聊天机器人,让我们聊天吧。
历史对话内容如下:
{chat_history}那现在新的问题如下: {question}
请你回复进行:
"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory
)
conversation({"question": "你好"})
做个for循环重复调用即可
Callbacks
记录并流式传输任何链的中间步骤,这个回调系统允许我们挂接在LLM应用程序的各个阶段。这对于日志记录、监视、流式传输和其他任务非常有用。
三、其他记录
多进程调用
如果有一大批数据需要预测,可以使用python的多进程调用
import os
import openai
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
# 运行此API配置,需要将目录中的.env中api_key替换为自己的
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']from concurrent.futures import ProcessPoolExecutor, as_completed
import time
import collections# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。
# 如果你想要每次得到不一样的有新意的答案,可以尝试调整该参数。
# 以下的对话均无记忆,即每次调用预测不会记得之前的对话。(想要有记忆功能请看下一节的langchain的Memory模块)
chat = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")print(chat)# 定义预测函数
def predict(params):query, input = paramsres = chat(input)res = res.contentreturn query, res# def predict(prompt):
# return promptdef main():start_time = time.time()# 多进程并行预测# 您可能需要根据自己的需求调整间隔时间。另外,您可以根据需要调整进程池的大小,以获得更好的性能。template_string = """请回答下面的问题:{query}"""input_data = ['1+1等于几啊?', '2+2等于几啊?', '3+3等于几啊?', '4+4等于几啊?']prompt_template = ChatPromptTemplate.from_template(template_string)from langchain.schema import HumanMessage, SystemMessagesystem_msg = SystemMessage(content="你是一个数学家。")print(system_msg)# output_data = collections.defaultdict(int)with ProcessPoolExecutor(max_workers=2) as executor:# 异步调用(多进程并发执行)futures = []for query in input_data:prompt = prompt_template.format_messages(query=query)job = executor.submit(predict, (query, [system_msg]+prompt))futures.append(job)# 因为异步等待结果,返回的顺序是不定的,所以记录一下进程和输入数据的对应query2res = collections.defaultdict(int) # 异步等待结果(返回顺序和原数据顺序可能不一致) ,直接predict函数里返回结果?for job in as_completed(futures):query, res = job.result(timeout=None) # 默认timeout=None,不限时间等待结果query2res[query] = restime.sleep(1) # 为了避免超过OpenAI API的速率限制,每次预测之间间隔1秒end_time = time.time()total_run_time = round(end_time-start_time, 3)print('Total_run_time: {} s'.format(total_run_time))print(query2res)# 保存结果import pandas as pddf = pd.DataFrame({'query': list(query2res.keys()), 'infer_result': list(query2res.values())})df.to_excel('./chatgpt_infer_result.xlsx', index=False)
相关文章:
LLM大模型——langchain相关知识总结
目录 一、简介LangChain的主要价值支柱简单安装 二、 LangChain的主要模块1.Model I/Oprompt模版定义调用语言模型 2. 数据连接3. chains4. Agents5. MemoryCallbacks 三、其他记录多进程调用 主要参考以下开源文档 文档地址:https://python.langchain.com/en/lates…...

【Python】数据可视化利器PyCharts在测试工作中的应用
目录 PyCharts 简介 PyCharts 的安装 缺陷统计 测试用例执行情况 使用JavaScript情况 缺陷趋势分析 将两张图放在一个组合里(grid) 将两张图重叠成一张图(overlap) 将多张图组合在一个page 中(page࿰…...
AOP的实战(统一功能处理模块)
一、用户登录权限效验 用户登录权限的发展从之前每个方法中自己验证用户登录权限,到现在统一的用户登录验证处理,它是一个逐渐完善和逐渐优化的过程。 1.1 最初用户登录验证 我们先来回顾一下最初用户登录验证的实现方法: RestController…...

时间复杂度为O(n2)的三种简单排序算法
1.冒泡排序 冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少少一个元素移动到它应该在的位置,重复n次,就完成了n个数据的排序工作。 /*** …...

LeetCode 热题 100 JavaScript --226. 翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 3: 输入:root [] 输出:[] 提示: 树中节点数目范围在 [0, 100] 内 -100 < Node.val < 100 var invertTree function(root…...

hive所有窗口函数详情总结
hive窗口函数详情总结 解释语法hive开窗函数排序开窗函数样例数据RANK()DENSE_RANK()ROW_NUMBER() 分析开窗函数样例数据:last_valuefirst_valuelaglead 其他窗口函数cume_distpercent_rank 解释 开窗函数用于为行定义一个窗口(指运算将要操作的行的集合…...

Talk | 新加坡国立大学博士生施宇钧:DragDiffusion-基于扩散模型的关键点拖拽图片编辑
本期为TechBeat人工智能社区第518期线上Talk! 北京时间8月2日(周三)20:00, 新加坡国立大学博士生—施宇钧的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “DragDiffusion-基于扩散模型的关键点拖拽图片编辑”,他…...

22 | 贝叶斯分类算法
文章目录 介绍什么是贝叶斯分类算法?贝叶斯分类算法的应用场景贝叶斯定理贝叶斯定理的基本原理贝叶斯定理的公式推导贝叶斯定理的应用举例代码介绍 什么是贝叶斯分类算法? 贝叶斯分类算法是一类基于贝叶斯定理的分类技术。在统计分类任务中,这些算法使用特定的假设来建立特…...

java.sql.SQLSyntaxErrorException: ORA-00909: 参数个数无效
问题: 在Select里采用Contact(%,#name,%)报错参数个数无效 原因: 回想以前用Mysql的时候就是这样用的,没有问题,在这里就出问题了,所以确定问题在oracle数据库上,经过查询得知,oracle和mysql…...

数据结构8-哈希表
数据结构8-哈希表 动态分配内存方式: #include <stdio.h> #include <stdlib.h>#define SIZE 20struct DataItem {int data; int key; };struct DataItem* hashArray[SIZE]; struct DataItem* dummyItem; struct DataItem* item;//获取键值 int has…...

vue3引用Font-Awesome字体图标库
环境:vue3tsviteelement plus 介绍:这里安装引用的是Font-Awesome 6.x 版本,有专业版(付费),这里只介绍免费版字体使用方法 一、安装 1.使用npm安装,终端打开项目目录或者命令行cd到目录文件夹…...

Python: Django 服务部署可能遇到的一些问题
502 bad gateway 不要用 python3 manage.py runserver 启动服务, 而要用: daphne -b 0.0.0.0 -p <端口> <工程名>.asgi:application此外,在 setting.py 中,修改: import osSECRET_KEY os.environ.get(D…...

Python爬虫时遇到连接超时解决方案
在进行Python爬虫任务时,经常会遇到连接超时(TimeoutError)错误。连接超时意味着爬虫无法在规定的时间内建立与目标服务器的连接,导致请求失败。为了帮助您解决这个常见的问题,本文将提供一些解决办法,并提…...
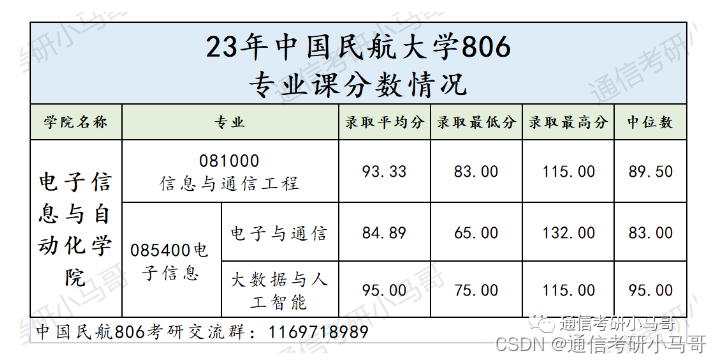
这所国字头双一流,根本招不满,学硕都没人报!
一、学校及专业介绍 中国民航大学,位于天津市,是民航局、天津市、教育部共建高校,是天津市“双一流”建设高校和高水平特色大学建设高校。 1.1 招生情况 2023年中国民航大学电子信息与自动化学院,初试考806信号与系统的一共有两…...

macos 查询端口占用 命令
在 macOS 上查询端口占用的命令是通过使用lsof(list open files)工具来实现的。 lsof可以显示当前系统中打开的文件(包括网络连接和端口)的相关信息。 打开终端应用程序(Terminal),然后输入以下…...

无代码开发:打破传统开发模式,引领数字化转型新方向
随着数字化转型的加速,企业对于高效、便捷的软件开发需求愈发旺盛。无代码开发作为一种新兴的软件开发模式,以其可视化、模块化的开发方式,为数字化转型提供了新的方向。本文将从无代码开发的优势、应用场景、如何实现等方面进行详细解读&…...
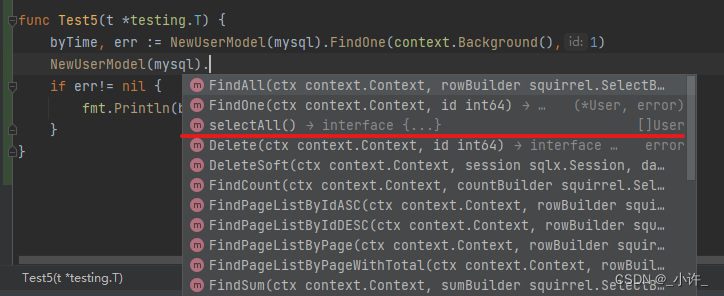
go-zero超强工具goctl的常用命令api,rpc,model及其构建的服务解析
goctl api 详情移步: go-zero的路由机制解析 基于go-zero的api服务刨析并对比与gin的区别 goctl rpc goctl支持多种rpc,较为流行的是google开源的grpc,这里主要介绍goctl rpc protoc的代码生成与使用。 protoc是grpc的命令,作用…...
手机python编程软件怎么用,手机python编程软件下载
大家好,小编来为大家解答以下问题,手机python编程软件保存的代码在哪里,手机python编程软件怎么运行,现在让我们一起来看看吧! 原标题:盘点几个在手机上可以用来学习编程的软件 前天在悟空问答的时候&#…...
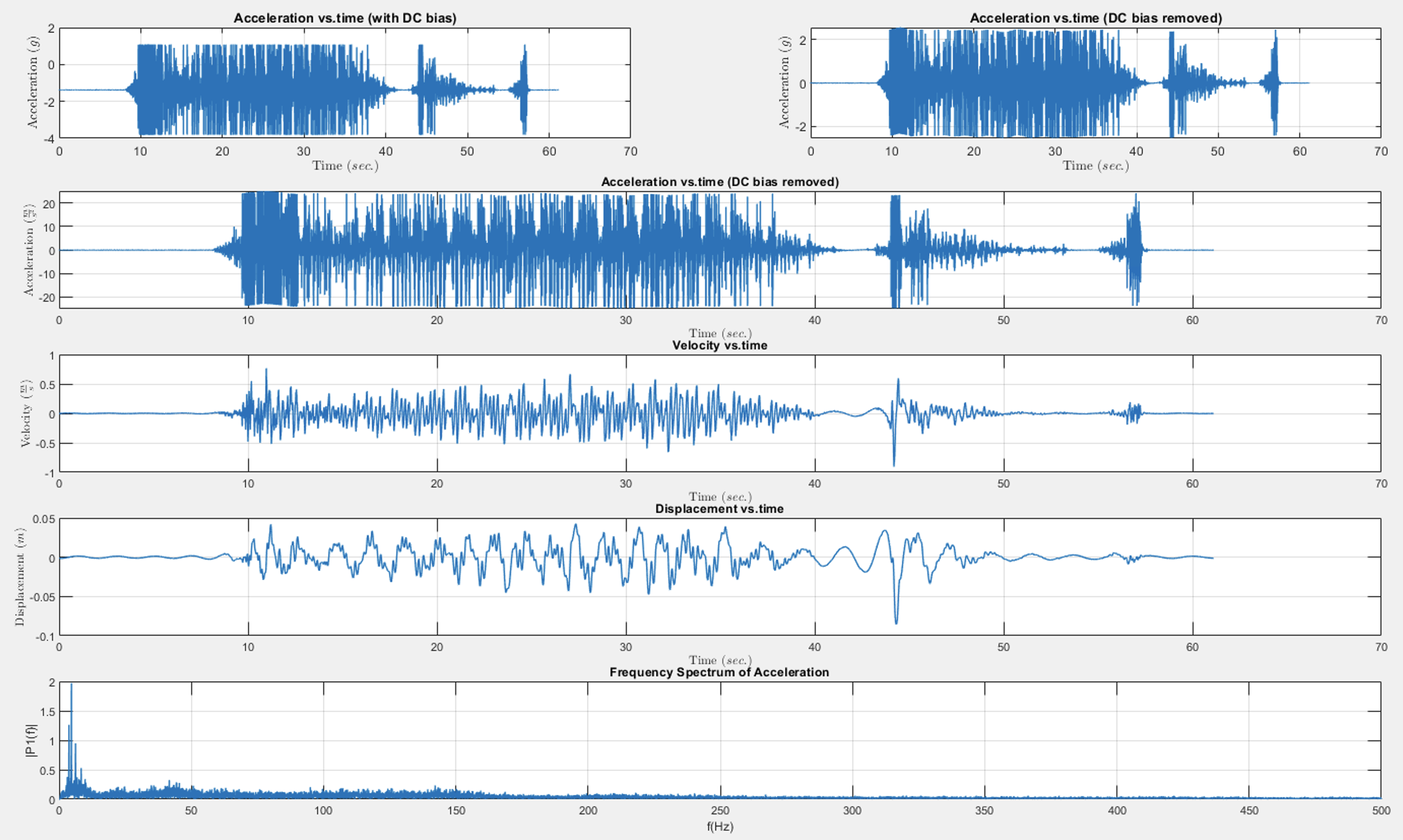
【使用 DSP 滤波器加速速度和位移】使用信号处理算法过滤加速度数据并将其转换为速度和位移研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
家居行业解决方案 | 君子签电子签约助力家居企业减负增效
过去,家居行业因供需两端碎片化、服务链条较长等因素,导致线上发展较为缓慢,近年来,互联网的发展推动直播电商、兴趣电商兴起,促使家居行业数字化建设需求越来越为迫切。 合同管理作为家居行业企业经营的一项重要管理…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...