SpringBoot整合Caffeine
一、Caffeine介绍
1、缓存介绍
缓存(Cache)在代码世界中无处不在。从底层的CPU多级缓存,到客户端的页面缓存,处处都存在着缓存的身影。缓存从本质上来说,是一种空间换时间的手段,通过对数据进行一定的空间安排,使得下次进行数据访问时起到加速的效果。
就Java而言,其常用的缓存解决方案有很多,例如数据库缓存框架EhCache,分布式缓存Memcached等,这些缓存方案实际上都是为了提升吞吐效率,避免持久层压力过大。
对于常见缓存类型而言,可以分为本地缓存以及分布式缓存两种,Caffeine就是一种优秀的本地缓存,而Redis可以用来做分布式缓存
2、Caffeine介绍
Caffeine官方:
https://github.com/ben-manes/caffeine
Caffeine是基于Java 1.8的高性能本地缓存库,由Guava改进而来,而且在Spring5开始的默认缓存实现就将Caffeine代替原来的Google Guava,官方说明指出,其缓存命中率已经接近最优值。实际上Caffeine这样的本地缓存和ConcurrentMap很像,即支持并发,并且支持O(1)时间复杂度的数据存取。二者的主要区别在于:
-
ConcurrentMap将存储所有存入的数据,直到你显式将其移除;
-
Caffeine将通过给定的配置,自动移除“不常用”的数据,以保持内存的合理占用。
因此,一种更好的理解方式是:Cache是一种带有存储和移除策略的Map。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
二、Caffeine基础
使用Caffeine,需要在工程中引入如下依赖
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><!--https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeinez找最新版--><version>3.0.5</version>
</dependency>
1、缓存加载策略
1.1 Cache手动创建
最普通的一种缓存,无需指定加载方式,需要手动调用put()进行加载。需要注意的是put()方法对于已存在的key将进行覆盖,这点和Map的表现是一致的。在获取缓存值时,如果想要在缓存值不存在时,原子地将值写入缓存,则可以调用get(key, k -> value)方法,该方法将避免写入竞争。调用invalidate()方法,将手动移除缓存。
在多线程情况下,当使用get(key, k -> value)时,如果有另一个线程同时调用本方法进行竞争,则后一线程会被阻塞,直到前一线程更新缓存完成;而若另一线程调用getIfPresent()方法,则会立即返回null,不会被阻塞。
Cache<Object, Object> cache = Caffeine.newBuilder()//初始数量.initialCapacity(10)//最大条数.maximumSize(10)//expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准//最后一次写操作后经过指定时间过期.expireAfterWrite(1, TimeUnit.SECONDS)//最后一次读或写操作后经过指定时间过期.expireAfterAccess(1, TimeUnit.SECONDS)//监听缓存被移除.removalListener((key, val, removalCause) -> { })//记录命中.recordStats().build();cache.put("1","张三");//张三System.out.println(cache.getIfPresent("1"));//存储的是默认值System.out.println(cache.get("2",o -> "默认值"));
1.2 Loading Cache自动创建
LoadingCache是一种自动加载的缓存。其和普通缓存不同的地方在于,当缓存不存在/缓存已过期时,若调用get()方法,则会自动调用CacheLoader.load()方法加载最新值。调用getAll()方法将遍历所有的key调用get(),除非实现了CacheLoader.loadAll()方法。使用LoadingCache时,需要指定CacheLoader,并实现其中的load()方法供缓存缺失时自动加载。
在多线程情况下,当两个线程同时调用get(),则后一线程将被阻塞,直至前一线程更新缓存完成。
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()//创建缓存或者最近一次更新缓存后经过指定时间间隔,刷新缓存;refreshAfterWrite仅支持LoadingCache.refreshAfterWrite(10, TimeUnit.SECONDS).expireAfterWrite(10, TimeUnit.SECONDS).expireAfterAccess(10, TimeUnit.SECONDS).maximumSize(10)//根据key查询数据库里面的值,这里是个lamba表达式.build(key -> new Date().toString());
1.3 Async Cache异步获取
AsyncCache是Cache的一个变体,其响应结果均为CompletableFuture,通过这种方式,AsyncCache对异步编程模式进行了适配。默认情况下,缓存计算使用ForkJoinPool.commonPool()作为线程池,如果想要指定线程池,则可以覆盖并实现Caffeine.executor(Executor)方法。synchronous()提供了阻塞直到异步缓存生成完毕的能力,它将以Cache进行返回。
在多线程情况下,当两个线程同时调用get(key, k -> value),则会返回同一个CompletableFuture对象。由于返回结果本身不进行阻塞,可以根据业务设计自行选择阻塞等待或者非阻塞。
AsyncLoadingCache<String, String> asyncLoadingCache = Caffeine.newBuilder()//创建缓存或者最近一次更新缓存后经过指定时间间隔刷新缓存;仅支持LoadingCache.refreshAfterWrite(1, TimeUnit.SECONDS).expireAfterWrite(1, TimeUnit.SECONDS).expireAfterAccess(1, TimeUnit.SECONDS).maximumSize(10)//根据key查询数据库里面的值.buildAsync(key -> {Thread.sleep(1000);return new Date().toString();});//异步缓存返回的是CompletableFuture
CompletableFuture<String> future = asyncLoadingCache.get("1");
future.thenAccept(System.out::println);
2、驱逐策略
驱逐策略在创建缓存的时候进行指定。常用的有基于容量的驱逐和基于时间的驱逐。
基于容量的驱逐需要指定缓存容量的最大值,当缓存容量达到最大时,Caffeine将使用LRU策略对缓存进行淘汰;基于时间的驱逐策略如字面意思,可以设置在最后访问/写入一个缓存经过指定时间后,自动进行淘汰。
驱逐策略可以组合使用,任意驱逐策略生效后,该缓存条目即被驱逐。
-
LRU 最近最少使用,淘汰最长时间没有被使用的页面。
-
LFU 最不经常使用,淘汰一段时间内使用次数最少的页面
-
FIFO 先进先出
Caffeine有4种缓存淘汰设置
-
大小 (LFU算法进行淘汰)
-
权重 (大小与权重 只能二选一)
-
时间
-
引用 (不常用,本文不介绍)
@Slf4j
public class CacheTest {/*** 缓存大小淘汰*/@Testpublic void maximumSizeTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder()//超过10个后会使用W-TinyLFU算法进行淘汰.maximumSize(10).evictionListener((key, val, removalCause) -> {log.info("淘汰缓存:key:{} val:{}", key, val);}).build();for (int i = 1; i < 20; i++) {cache.put(i, i);}Thread.sleep(500);//缓存淘汰是异步的// 打印还没被淘汰的缓存System.out.println(cache.asMap());}/*** 权重淘汰*/@Testpublic void maximumWeightTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder()//限制总权重,若所有缓存的权重加起来>总权重就会淘汰权重小的缓存.maximumWeight(100).weigher((Weigher<Integer, Integer>) (key, value) -> key).evictionListener((key, val, removalCause) -> {log.info("淘汰缓存:key:{} val:{}", key, val);}).build();//总权重其实是=所有缓存的权重加起来int maximumWeight = 0;for (int i = 1; i < 20; i++) {cache.put(i, i);maximumWeight += i;}System.out.println("总权重=" + maximumWeight);Thread.sleep(500);//缓存淘汰是异步的// 打印还没被淘汰的缓存System.out.println(cache.asMap());}/*** 访问后到期(每次访问都会重置时间,也就是说如果一直被访问就不会被淘汰)*/@Testpublic void expireAfterAccessTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder().expireAfterAccess(1, TimeUnit.SECONDS)//可以指定调度程序来及时删除过期缓存项,而不是等待Caffeine触发定期维护//若不设置scheduler,则缓存会在下一次调用get的时候才会被动删除.scheduler(Scheduler.systemScheduler()).evictionListener((key, val, removalCause) -> {log.info("淘汰缓存:key:{} val:{}", key, val);}).build();cache.put(1, 2);System.out.println(cache.getIfPresent(1));Thread.sleep(3000);System.out.println(cache.getIfPresent(1));//null}/*** 写入后到期*/@Testpublic void expireAfterWriteTest() throws InterruptedException {Cache<Integer, Integer> cache = Caffeine.newBuilder().expireAfterWrite(1, TimeUnit.SECONDS)//可以指定调度程序来及时删除过期缓存项,而不是等待Caffeine触发定期维护//若不设置scheduler,则缓存会在下一次调用get的时候才会被动删除.scheduler(Scheduler.systemScheduler()).evictionListener((key, val, removalCause) -> {log.info("淘汰缓存:key:{} val:{}", key, val);}).build();cache.put(1, 2);Thread.sleep(3000);System.out.println(cache.getIfPresent(1));//null}
}
3、刷新机制
refreshAfterWrite()表示x秒后自动刷新缓存的策略可以配合淘汰策略使用,注意的是刷新机制只支持LoadingCache和AsyncLoadingCache
private static int NUM = 0;@Test
public void refreshAfterWriteTest() throws InterruptedException {LoadingCache<Integer, Integer> cache = Caffeine.newBuilder().refreshAfterWrite(1, TimeUnit.SECONDS)//模拟获取数据,每次获取就自增1.build(integer -> ++NUM);//获取ID=1的值,由于缓存里还没有,所以会自动放入缓存System.out.println(cache.get(1));// 1// 延迟2秒后,理论上自动刷新缓存后取到的值是2// 但其实不是,值还是1,因为refreshAfterWrite并不是设置了n秒后重新获取就会自动刷新// 而是x秒后&&第二次调用getIfPresent的时候才会被动刷新Thread.sleep(2000);System.out.println(cache.getIfPresent(1));// 1//此时才会刷新缓存,而第一次拿到的还是旧值System.out.println(cache.getIfPresent(1));// 2
}
4、统计
LoadingCache<String, String> cache = Caffeine.newBuilder()//创建缓存或者最近一次更新缓存后经过指定时间间隔,刷新缓存;refreshAfterWrite仅支持LoadingCache.refreshAfterWrite(1, TimeUnit.SECONDS).expireAfterWrite(1, TimeUnit.SECONDS).expireAfterAccess(1, TimeUnit.SECONDS).maximumSize(10)//开启记录缓存命中率等信息.recordStats()//根据key查询数据库里面的值.build(key -> {Thread.sleep(1000);return new Date().toString();});cache.put("1", "shawn");
cache.get("1");/** hitCount :命中的次数* missCount:未命中次数* requestCount:请求次数* hitRate:命中率* missRate:丢失率* loadSuccessCount:成功加载新值的次数* loadExceptionCount:失败加载新值的次数* totalLoadCount:总条数* loadExceptionRate:失败加载新值的比率* totalLoadTime:全部加载时间* evictionCount:丢失的条数*/
System.out.println(cache.stats());
5、总结
上述一些策略在创建时都可以进行自由组合,一般情况下有两种方法
-
设置
maxSize、refreshAfterWrite,不设置expireAfterWrite/expireAfterAccess,设置expireAfterWrite当缓存过期时会同步加锁获取缓存,所以设置expireAfterWrite时性能较好,但是某些时候会取旧数据,适合允许取到旧数据的场景 -
设置
maxSize、expireAfterWrite/expireAfterAccess,不设置 refreshAfterWrite 数据一致性好,不会获取到旧数据,但是性能没那么好(对比起来),适合获取数据时不耗时的场景
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
三、SpringBoot整合Caffeine
1、@Cacheable相关注解
1.1 相关依赖
如果要使用@Cacheable注解,需要引入相关依赖,并在任一配置类文件上添加@EnableCaching注解
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency>
1.2 常用注解
-
@Cacheable :表示该方法支持缓存。当调用被注解的方法时,如果对应的键已经存在缓存,则不再执行方法体,而从缓存中直接返回。当方法返回null时,将不进行缓存操作。
-
@CachePut :表示执行该方法后,其值将作为最新结果更新到缓存中,每次都会执行该方法。
-
@CacheEvict :表示执行该方法后,将触发缓存清除操作。
-
@Caching :用于组合前三个注解,例如:
@Caching(cacheable = @Cacheable("CacheConstants.GET_USER"),evict = {@CacheEvict("CacheConstants.GET_DYNAMIC",allEntries = true)}
public User find(Integer id) {return null;
}
1.3 常用注解属性
-
cacheNames/value :缓存组件的名字,即cacheManager中缓存的名称。
-
key :缓存数据时使用的key。默认使用方法参数值,也可以使用SpEL表达式进行编写。
-
keyGenerator :和key二选一使用。
-
cacheManager :指定使用的缓存管理器。
-
condition :在方法执行开始前检查,在符合condition的情况下,进行缓存
-
unless :在方法执行完成后检查,在符合unless的情况下,不进行缓存
-
sync :是否使用同步模式。若使用同步模式,在多个线程同时对一个key进行load时,其他线程将被阻塞。
1.4 缓存同步模式
sync开启或关闭,在Cache和LoadingCache中的表现是不一致的:
-
Cache中,sync表示是否需要所有线程同步等待
-
LoadingCache中,sync表示在读取不存在/已驱逐的key时,是否执行被注解方法
2、实战
2.1 引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency><dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId>
</dependency>
2.2 缓存常量CacheConstants
创建缓存常量类,把公共的常量提取一层,复用,这里也可以通过配置文件加载这些数据,例如@ConfigurationProperties和@Value
public class CacheConstants {/*** 默认过期时间(配置类中我使用的时间单位是秒,所以这里如 3*60 为3分钟)*/public static final int DEFAULT_EXPIRES = 3 * 60;public static final int EXPIRES_5_MIN = 5 * 60;public static final int EXPIRES_10_MIN = 10 * 60;public static final String GET_USER = "GET:USER";public static final String GET_DYNAMIC = "GET:DYNAMIC";}
2.3 缓存配置类CacheConfig
@Configuration
@EnableCaching
public class CacheConfig {/*** Caffeine配置说明:* initialCapacity=[integer]: 初始的缓存空间大小* maximumSize=[long]: 缓存的最大条数* maximumWeight=[long]: 缓存的最大权重* expireAfterAccess=[duration]: 最后一次写入或访问后经过固定时间过期* expireAfterWrite=[duration]: 最后一次写入后经过固定时间过期* refreshAfterWrite=[duration]: 创建缓存或者最近一次更新缓存后经过固定的时间间隔,刷新缓存* weakKeys: 打开key的弱引用* weakValues:打开value的弱引用* softValues:打开value的软引用* recordStats:开发统计功能* 注意:* expireAfterWrite和expireAfterAccess同事存在时,以expireAfterWrite为准。* maximumSize和maximumWeight不可以同时使用* weakValues和softValues不可以同时使用*/@Beanpublic CacheManager cacheManager() {SimpleCacheManager cacheManager = new SimpleCacheManager();List<CaffeineCache> list = new ArrayList<>();//循环添加枚举类中自定义的缓存,可以自定义for (CacheEnum cacheEnum : CacheEnum.values()) {list.add(new CaffeineCache(cacheEnum.getName(),Caffeine.newBuilder().initialCapacity(50).maximumSize(1000).expireAfterAccess(cacheEnum.getExpires(), TimeUnit.SECONDS).build()));}cacheManager.setCaches(list);return cacheManager;}
}
2.4 调用缓存
这里要注意的是Cache和@Transactional一样也使用了代理,类内调用将失效
/*** value:缓存key的前缀。* key:缓存key的后缀。* sync:设置如果缓存过期是不是只放一个请求去请求数据库,其他请求阻塞,默认是false(根据个人需求)。* unless:不缓存空值,这里不使用,会报错* 查询用户信息类* 如果需要加自定义字符串,需要用单引号* 如果查询为null,也会被缓存*/
@Cacheable(value = CacheConstants.GET_USER,key = "'user'+#userId",sync = true)
@CacheEvict
public UserEntity getUserByUserId(Integer userId){UserEntity userEntity = userMapper.findById(userId);System.out.println("查询了数据库");return userEntity;
}
相关文章:
SpringBoot整合Caffeine
一、Caffeine介绍 1、缓存介绍 缓存(Cache)在代码世界中无处不在。从底层的CPU多级缓存,到客户端的页面缓存,处处都存在着缓存的身影。缓存从本质上来说,是一种空间换时间的手段,通过对数据进行一定的空间安排,使得下…...

元宇宙虚拟展厅的特点是什么呢?优势有哪些?
元宇宙是一个很广阔的虚拟世界,它可以创造出更为丰富、沉浸式的体验,这种全新的体验为展览和艺术领域带来了更多的可能性,元宇宙虚拟展厅以其多样化、互动性、沉浸式展示的特点,带领大家进入一个虚拟现实的全新世界。 元宇宙虚拟展…...

Day11-Webpack前端工程化开发
Webpack 一 webpack基本概念 遇到问题 开发中希望将文件分开来编写,比如CSS代码,可以分为头部尾部内容,公共的样式。 JS代码也希望拆分为多个文件,分别引入,以后代码比较好维护。 本地图片,希望可以实现小图片不用访问后端,保存在前端代码中就可以了 运行程序时我…...

什么是函数式编程,应用场景是什么
什么是函数式编程,应用场景是什么 函数式编程和面向对象编程一样,是一种编程规范。强调执行的过程而非结果,通过一系列的嵌套的函数调用,完成一个运算过程。它主要有以下几个特点: 1.函数是"一等公民"&…...

Vue3之路由认识
回顾: 原来的vue2路由是通过this. r o u t e 和 t h i s . route和this. route和this.router来控制的。现在vue3有所变化,useRoute相当于以前的this. r o u t e ,而 u s e R o u t e r 相当于 t h i s . route,而useRouter相当于t…...

P1775 石子合并(弱化版)(内附封面)
石子合并(弱化版) 题目描述 设有 N ( N ≤ 300 ) N(N \le 300) N(N≤300) 堆石子排成一排,其编号为 1 , 2 , 3 , ⋯ , N 1,2,3,\cdots,N 1,2,3,⋯,N。每堆石子有一定的质量 m i ( m i ≤ 1000 ) m_i\ (m_i \le 1000) mi (mi≤1000)。…...

jmeter之接口测试(http接口测试)
基础知识储备 一、了解jmeter接口测试请求接口的原理 客户端--发送一个请求动作--服务器响应--返回客户端 客户端--发送一个请求动作--jmeter代理服务器---服务器--jmeter代理服务器--服务器 二、了解基础接口知识: 1、什么是接口:前端与后台之间的…...
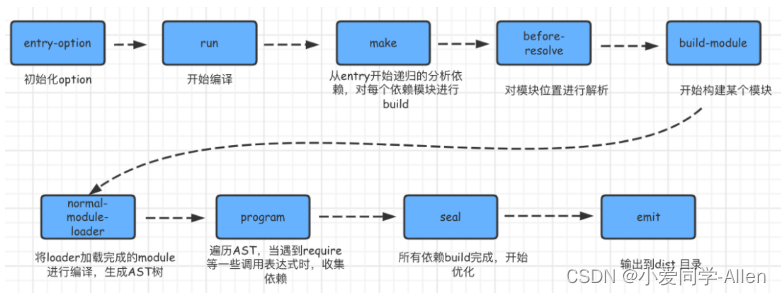
webpack基础知识二:说说webpack的构建流程?
一、运行流程 webpack 的运行流程是一个串行的过程,它的工作流程就是将各个插件串联起来 在运行过程中会广播事件,插件只需要监听它所关心的事件,就能加入到这条webpack机制中,去改变webpack的运作,使得整个系统扩展…...

PHP使用PhpSpreadsheet实现导出Excel时带下拉框列表 (可支持三级联动)
因项目需要导出Excel表 需要支持下拉 且 还需要支持三级联动功能 目前应为PHPExcel 不在维护,固采用 PhpSpreadsheet 效果如图: 第一步:首先 使用composer 获取PhpSpreadsheet 我这里PHP 版本 7.4 命令如下: composer r…...

Openssh高危漏洞CVE-2023-38408修复方案
0x01 漏洞简述 2023年07月21日,360CERT监测发现OpenSSH发布了OpenSSH的风险通告,漏洞编号为CVE-2023-38408,漏洞等级:高危,漏洞评分:8.1。 OpenSSH 是 Secure Shell (SSH) 协议的开源实现,提供…...

Android中的ContentProvider
Android中的ContentProvider 在Android中,ContentProvider是四大组件之一,用于在不同应用程序之间共享和管理数据。它提供了一种标准化的方式来访问和管理应用程序的数据,使得多个应用程序可以安全地共享数据,而无需直接访问彼此…...
:的含义?)
if device is None and isinstance(net, torch.nn.Module):的含义?
这段代码的含义是,如果变量 device 为 None 并且 net 是 torch.nn.Module 的实例,那么执行后续的代码块。 解释一下其中的几个部分: device:这是一个代表设备的变量,通常用于指定在哪个设备上执行模型的计算ÿ…...

C++如何用OpenCV中实现图像的边缘检测和轮廓提取?
最近有个项目需要做细孔定位和孔距测量,需要做边缘检测和轮廓提取,先看初步效果图: 主要实现代码: int MainWindow::Test() {// 2.9 单个像素长度um 5倍double dbUnit 2.9/(1000*5);// 定义显示窗口namedWindow("src"…...
智慧水务和物联网智能水表在农村供水工程中的应用
摘 要:随着社会的进步和各项事业的飞速发展,人民生活水平的逐步提升,国家对农村饮水安全有了更高的要求,为了进一步提升农村供水服务的质量,利用现代化、信息化科学技术提升农村供水服务质量,提高用水管理效…...

机器学习笔记 - 了解 GitHub Copilot 如何通过提供自动完成式建议来帮助您编码
一、GitHub Copilot介绍 GitHub Copilot 是世界上第一个大规模 AI 开发人员工具,可以帮助您以更少的工作更快地编写代码。GitHub Copilot 从注释和代码中提取上下文,以立即建议单独的行和整个函数。 研究发现 GitHub Copilot 可以帮助开发人员更快地编码、专注于解决更大的问…...

《数据同步-NIFI系列》Nifi配置DBCPConnectionPool连接SQL Server数据库
Nifi配置DBCPConnectionPool连接SQL Server数据库 一、新增DBCPConnectionPool 在配置中新增DBCPConnectionPool,然后配置数据库相关信息 二、配置DBCPConnectionPool 2.1 DBCPConnectionPool介绍 主要介绍以下五个必填参数 Database Connection URL࿱…...

HarmonyOS/OpenHarmony元服务开发-卡片使用自定义绘制能力
ArkTS卡片开放了自定义绘制的能力,在卡片上可以通过Canvas组件创建一块画布,然后通过CanvasRenderingContext2D对象在画布上进行自定义图形的绘制,如下示例代码实现了在画布的中心绘制了一个笑脸。 Entry Component struct Card { private c…...
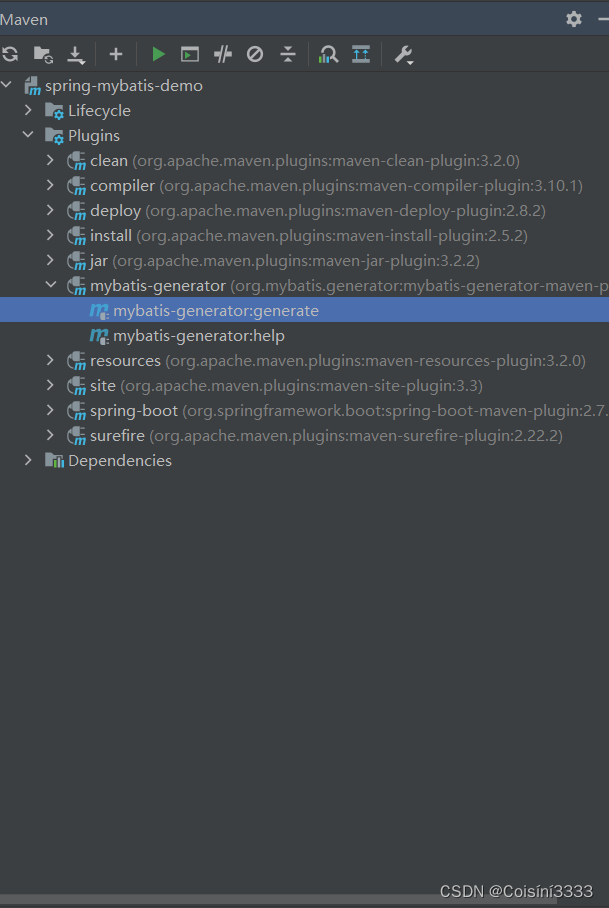
SpringBoot引入MyBatisGenerator
1.引入插件 <plugin><groupId>org.mybatis.generator</groupId><artifactId>mybatis-generator-maven-plugin</artifactId><version>1.3.5</version><configuration><!--generator配置文件所在位置--><configuratio…...

JVM面试题--实践
目录 JVM 调优的参数可以在哪里设置参数值 war包部署在tomcat中设置 jar包部署在启动参数设置 JVM 调优的参数都有哪些? 设置堆空间大小 虚拟机栈的设置 年轻代中Eden区和两个Survivor区的大小比例 年轻代晋升老年代阈值 设置垃圾回收收集器 JVM 调优的工…...

神经网络的搭建与各层分析
为什么去西藏的人都会感觉很治愈 拉萨的老中医是这么说的 缺氧脑子短路,很多事想不起来,就会感觉很幸福 一、卷积层 解释:卷积层通过卷积操作对输入数据进行处理。它使用一组可学习的滤波器(也称为卷积核或特征检测器)…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...