论文阅读-BotPercent: Estimating Twitter Bot Populations from Groups to Crowds
目录
摘要
引言
方法
数据集
BotPercent架构
实验结果
活跃用户中的Bot数量
Bot Population among Comment Sections
Bot Participation in Content Moderation Votes
Bot Population in Different Countries’ Politics
论文链接:https://arxiv.org/pdf/2302.00381.pdf
摘要
Twitter机器人检测在打击错误信息、识别恶意在线活动和保护社交媒体话语完整性方面变得越来越重要。虽然现有的机器人检测文献主要集中在识别单个机器人上,但如何估计特定社区和社交网络中机器人的比例仍未得到充分探讨,这对内容版主和日常用户都有很大的影响。
在这项工作中,我们提出了社区级机器人检测,这是一种通过估计机器人账户的百分比来估计在线社区恶意干扰数量的新方法。具体来说,我们引入了BotPercent,这是Twitter机器人检测数据集和基于特征、文本和图形的模型的融合,克服了现有个人级模型中的泛化问题,从而实现了更准确的社区级机器人估计。
实验表明,BotPercent在TwiBot-22基准测试上实现了最先进的社区级机器人检测性能,同时对特定用户特征的篡改表现出很强的鲁棒性。
借助BotPercent,我们以不同的方式分析在Twitter群组和社区的机器人率,例如所有活跃的Twitter用户,与党派新闻媒体互动的用户,参与Elon Musk内容审核投票的用户,以及不同国家和地区的政治社区。
我们的实验结果表明,Twitter机器人的存在并不是同质的,而是一种时空分布,其异质性应在内容审核、社交媒体政策制定等方面加以考虑。
引言
现有的Twitter机器人检测模型通常可以分为基于特征、基于文本和基于图形的方法;
尽管这些前沿的机器人检测方法取得了令人印象深刻的成果(Yang et al. 2020;Echeverrıa et al. 2018;Feng等2022a),他们只专注于个人层面的机器人检测,一次识别一个Twitter账户,而不考虑社区背景。
在这项工作中,我们提出了一个重要但尚未充分开发的社区级机器人检测设置,旨在估计社交网络社区内的机器人数量和百分比。
对于平台审核,社区级bot检测可以让决策者快速了解特定社区中bot的比例,并据此分配审核资源,同时告知社区成员不真实内容的风险。反过来,社交媒体用户可以对舆论操纵的企图更加警惕。
可以通过呈现集体统计数据而不是探查或跟踪单个用户来减轻隐私问题。这些以及其他商业和法律方面的考虑,使人们对了解总百分比的兴趣增加Twitter机器人(Varol 2022),这是我们工作的重点。
Botprecent:
训练数据和模型架构:对于训练数据,现有的个人级方法通常只利用一个数据集。由于公共可用数据集的领域和收集时间有限,单个方法只能捕获某些类型的Twitter机器人,并且难以泛化;因此,BotPercent合并了所有可用的Twitter机器人检测数据集,以增强泛化。
对于模型架构,个体级方法通常基于特征、文本或图形,并且只专注于检测传统机器人、社交机器人和高级机器人集群;由于不同类型的模型擅长处理不同的模态和检测不同类型的机器人,我们建议结合基于特征、文本和图形的方法来合并它们的归纳偏差,并增强BotPercent处理移动用户域的能力。BotPercent还对单个模型进行模型校准,并通过加权求和将它们的预测结合起来,从而得出从群组到人群的Twitter机器人数量的可靠估计。
实验:
我们首先在TwiBot-22机器人检测基准上评估BotPercent (Feng et al. 2022b)。大量的实验表明,BotPercent实现了社区级机器人检测的最先进性能,同时提高了对特定用户特征扰动的鲁棒性。
方法
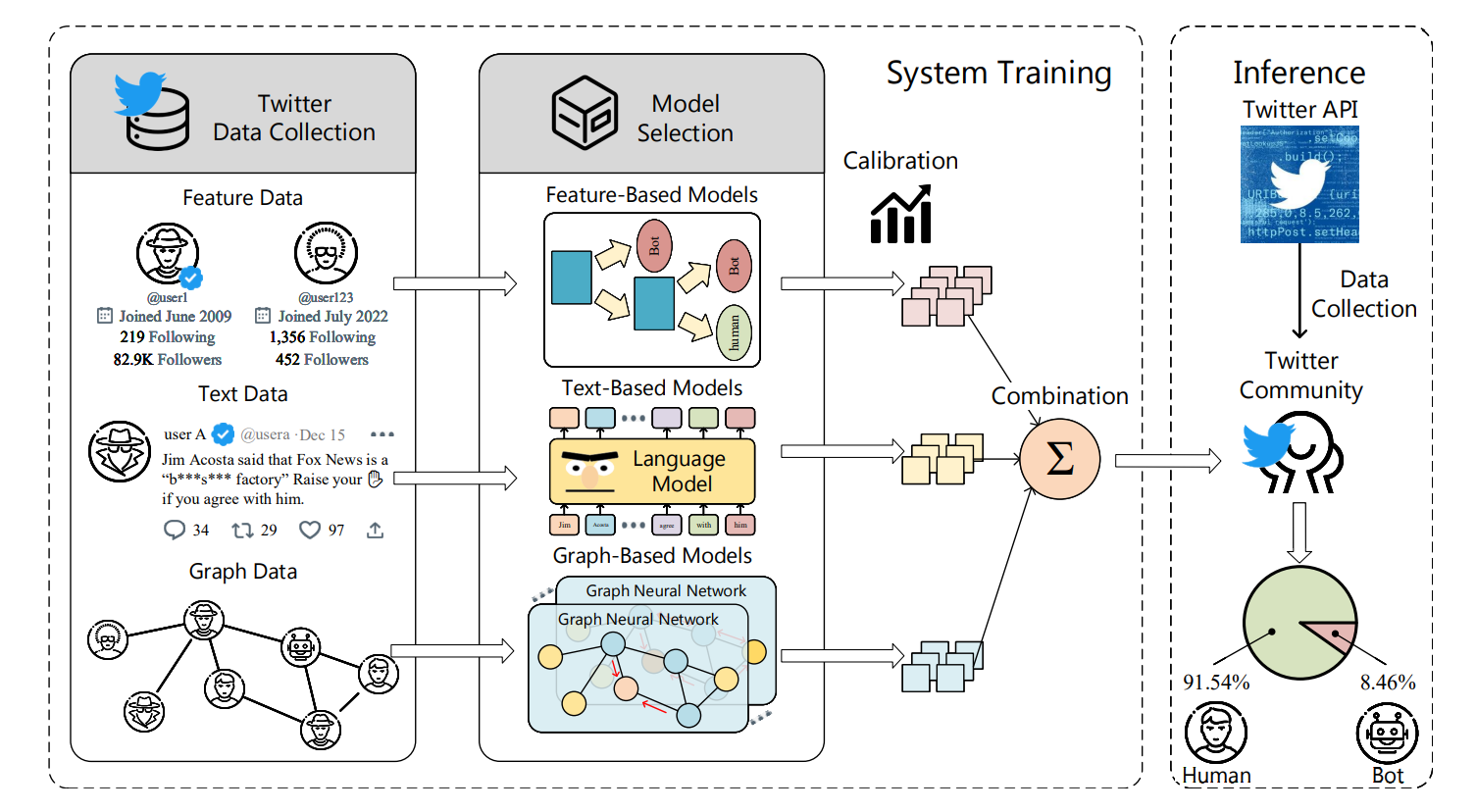
BotPercent采用多数据集多模型机器人检测管道,同时利用置信度校准和可学习权重来准确估计Twitter社区中的机器人数量。
数据集
现有的个人级方法通常只利用一个数据集。这些数据集主要集中在一个特定的领域,并在一个特定的时间段内收集,这使得个人层面的模型泛化能力有限;相反,社区级机器人检测处理多样化的Twitter机器人社区,应该在任何给定的时间段内工作。
具体来说,我们收集了所有公开可用的Twitter机器人检测数据集。
Cresci -15 (Cresci et al. 2015)数据集主要由从志愿者基地和活跃的意大利Twitter用户收集的帐户组成;
GILANI-17中的用户(Gilani et al. 2017)数据集是用Twitter流API收集的,并根据关注者的数量分为四类。
CRESCI-17具有三种类型的机器人:传统垃圾机器人,社交垃圾机器人和假追随者。
midterm -18 (Yang et al. 2020)数据集是根据2018年美国中期选举期间收集的政治推文和活跃用户进行过滤的;
对于CRESCI-STOCK-18(Cresci et al. 2018, 2019)数据集,通过在2017年的五个月内找到包含选定标签的推文中具有相似时间轴的帐户来识别bot用户。
CRESCI-RTBUST-19 (Mazza et al. 2019)数据集是从2018年6月17日至30日之间的意大利转发中抓取的。
Botometer - feedback -19 (Yang et al. 2019)数据集是通过手工标记Botometer用户反馈注释的帐户来构建的。
TWIBOT-20 (Feng et al. 2021b)由来自四个兴趣域的用户组成2020年7月至9月。
TWIBOT-22 (Feng et al. 2022b)使用多样性感知的BFS通过扩展关注关系来收集用户;
共同利用所有现有资源Twitter机器人检测数据集,BotPercent提出了一个机器人检测系统,旨在更好地进行领域泛化。
BotPercent架构
考虑到不同类型的模型在面对多样化的机器人时各有优缺点(Sayyadiharikandeh等人,2020),我们提出了一个统一的框架来结合这些模型的归纳偏差,提高BotPercent的性能和泛化性。
具体来说,我们首先在三类中选择一些有代表性的模型,并在组合数据集上对它们进行训练。BotPercent然后将个人水平方法的输出结合成一个可靠的预测。
基于特征的模型提取用户特征并采用传统分类器(Varol et al. 2017)。为了构建一个全面的基于特征的模型作为BotPercent的一部分,我们总结了现有基于特征的模型中引入的特征,并获得了一个更全面的特征集。继前人研究(Yang et al. 2020;Knauth 2019), BotPercent利用随机森林(Ho 1995)和AdaBoost (Freund and Schapire 1997)作为一个有效的基于特征的模块,并获得二元预测逻辑。
基于文本的机器人检测模型利用用户的推文和描述来识别Twitter机器人和恶意内容(Feng et al. 2022b)。BotPercent利用预训练RoBERTa (Liu et al. 2019a)和T5 (rafael et al. 2020)在使用线性层进行分类的同时提取用户推文和描述的嵌入:
基于图的机器人检测模型利用Twitter网络结构和图神经网络来分析用户交互(Ali Alhosseini et al. 2019;Feng et al. 2022a)。对于基于图的模型,我们在BotPercent中选择了四种最先进的方法:SimpleHGN (Lv等人,2021)、HGT (Hu等人,2020)、BotRGCN (Feng等人,2021c)和RGT (Feng等人,2022a),因为这些模型考虑了社交网络中固有的异质性,并且在Twibot22基准上显示出了很好的机器人检测性能(Feng等人,2022b)。这些模型的消息传递范式可以概括为:
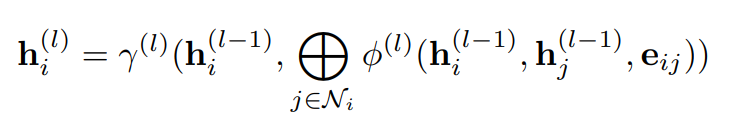
更具体地说,SimpleHGN采用了以边缘类型为读出函数γ的注意机制,HGT也采用了以边缘类型为不同投影矩阵的注意机制。BotRGCN以平均池化作为聚合函数,用不同的聚合矩阵对边缘类型进行处理,RGT利用关注机制在不同关系类型下传播消息,并通过不同关系类型的聚合表示进行传播。利用交叉熵损失对基于图的模型进行优化。
此外,由于数据依赖,BotPercent在分析大量Twitter社区时面临可扩展性问题:当BotPercent分析特定用户时,它会收集有关其多跳邻居的信息作为gnn的输入,这会导致指数级的数据收集成本。在Zhang等人(2021)的激励下,我们使用知识蒸馏(Hinton等人,2015)将基于图的检测器的知识转移到mlp。具体来说,蒸馏训练损失可表示为:
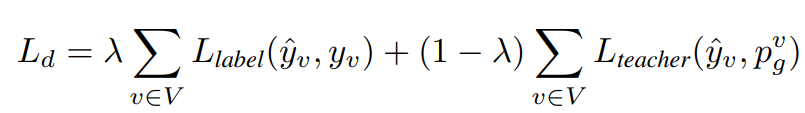
尽管二进制机器人探测器提供的分数表明每个帐户是机器人的可能性,但人们普遍认为,二进制分类器通常产生的置信度分数不能准确反映真实概率,模型经常被错误校准。由于社区级机器人检测依赖于对机器人概率的准确估计,原始模型得分需要进一步处理。BotPercent对所有子模型执行置信度校准,以确保估计概率和真实概率之间的一致性。具体来说,我们利用了温度缩放(Guo et al. 2017),这是一种后处理方法,通过在保留集上调整单个缩放参数来重新缩放置信度预测。
BotPercent在获得所有子模型的校准结果后,通过加权求和将预测结果进行组合:
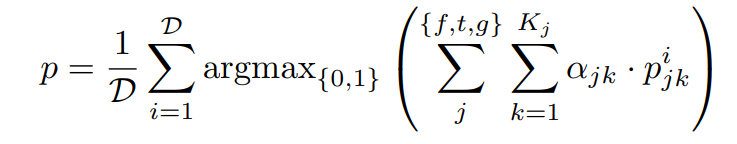
实验结果
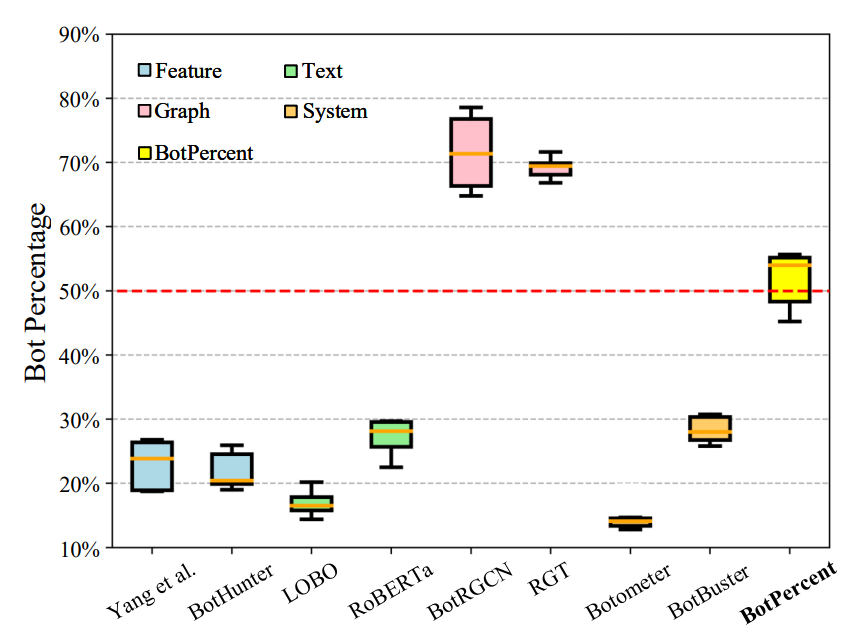
图3给出了BotPercent的估计和现有的方法。它表明BotPercent始终优于所有基线模型,包括最先进的个人机器人检测方法,如RGT。此外,基于特征和文本的方法通常低估了机器人的数量,而基于图形的方法通常高估了机器人的百分比。这些结果证明了BotPercent等多数据集多模型机器人检测框架对于提高泛化和估计精度的重要性。
除了在社区级机器人检测上实现最先进的性能外,我们还评估个人层面的百分比。我们利用TwiBot-22基准测试中的1000个专家注释账户,并将其降采样到一个包含150人的平衡测试集
150机器人。如表2所示,BotPercent以最先进的精度实现了同等水平的性能,甚至在f1得分方面优于所有基线。

埃隆·马斯克于2022年接管推特后,推特的验证政策发生了重大变化:现有的验证用户可能会失去其验证状态,而之前未验证的用户可以通过订阅Twitter blue获得蓝色复选标记。
这对Twitter机器人检测有很大的影响,因为验证是多种类型的机器人探测器广泛采用的基本功能。因此,一个理想的机器人检测系统应该是鲁棒的,并且在这种特征扰动下保持稳定的预测
(Ng, Robertson, and Carley 2022),特别是对于已验证的二进制特征。
A)所有用户为已验证用户,b)所有用户为未验证用户,c)用户验证状态随机分配。这是为了模拟用户验证不再可靠的场景,以及机器人探测器在这种情况下的表现。我们将结果列于表中
3,这表明禁用验证功能将严重削弱几个现有的机器人检测系统的性能。
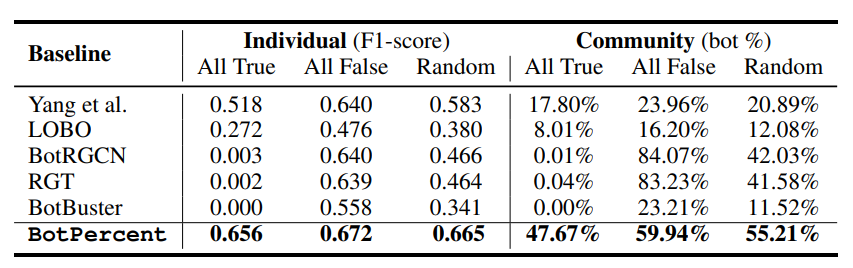
相反,由于其多模式和多模型管道,BotPercent在不同设置下保持稳定的性能,从而减少了对特定验证功能的过度依赖。
活跃用户中的Bot数量
我们首先用BotPercent来回答一个重要而又广受争议的问题:活跃Twitter用户中Twitter机器人的总体百分比。具体来说,我们使用Twitter API中的StreamClient函数对1%的实时tweet和相应的用户进行7天的采样1并采用对收集的105,614个用户进行分析。然后我们使用自举方法(Efron和Tibshirani)(1994)估计bot存在的抽样分布,并以95%的置信区间证明结果。
活跃用户中bot账户的百分比为8.46%,95%置信区间为(8.28%,8.64%)

值得注意的是,BotPercent的结论是8.46%大于Twitter(< 5%),显著小于Elon Musk (> 20%) (Porter 2022)。
Bot Population among Comment Sections
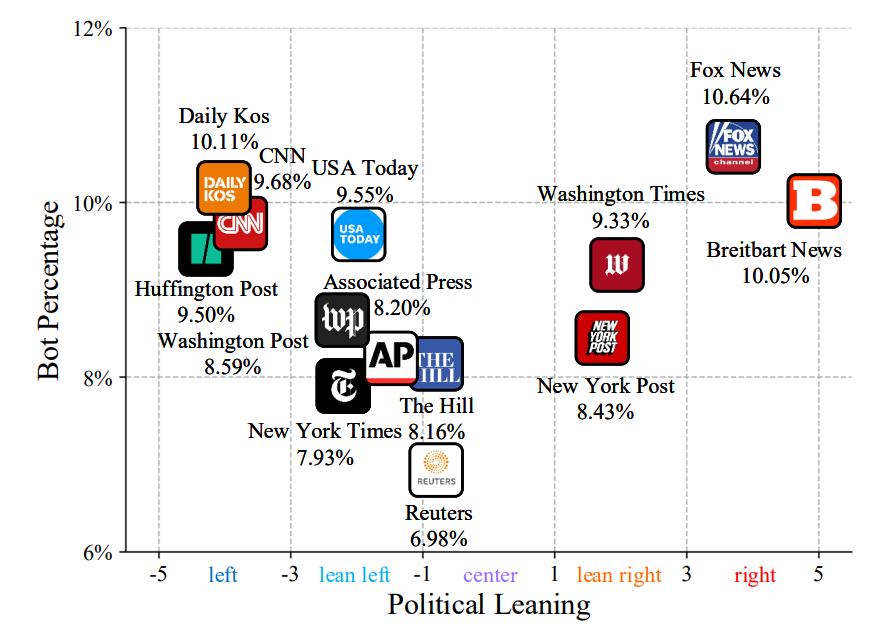
著名用户推文下的评论区是舆论的主战场(Weber 2014)。因此,我们调查了这些评论区的机器人百分比,并了解了以名人为中心和新闻分享组受到Twitter机器人攻击的程度。
我们收集了2022年12月23日至31日期间对这些用户发表评论的所有账号。
我们采用BotPercent对bot种群进行分析,结果如图所示4. 研究表明,加密货币名人评论区的bot百分比明显高于其他领域,技术领域的bot百分比也普遍高于平均水平,表明社交网络中bot的空间分布不均匀。

虽然之前的作品主要集中在政治领域的Twitter机器人(Woolley 2016;Forelle et al. 2015),我们的研究结果表明,Twitter机器人在多个领域都很活跃,尤其是加密货币和技术,而且机器人在政治之外的影响也值得研究,它对金融欺诈、市场操纵等方面的影响。
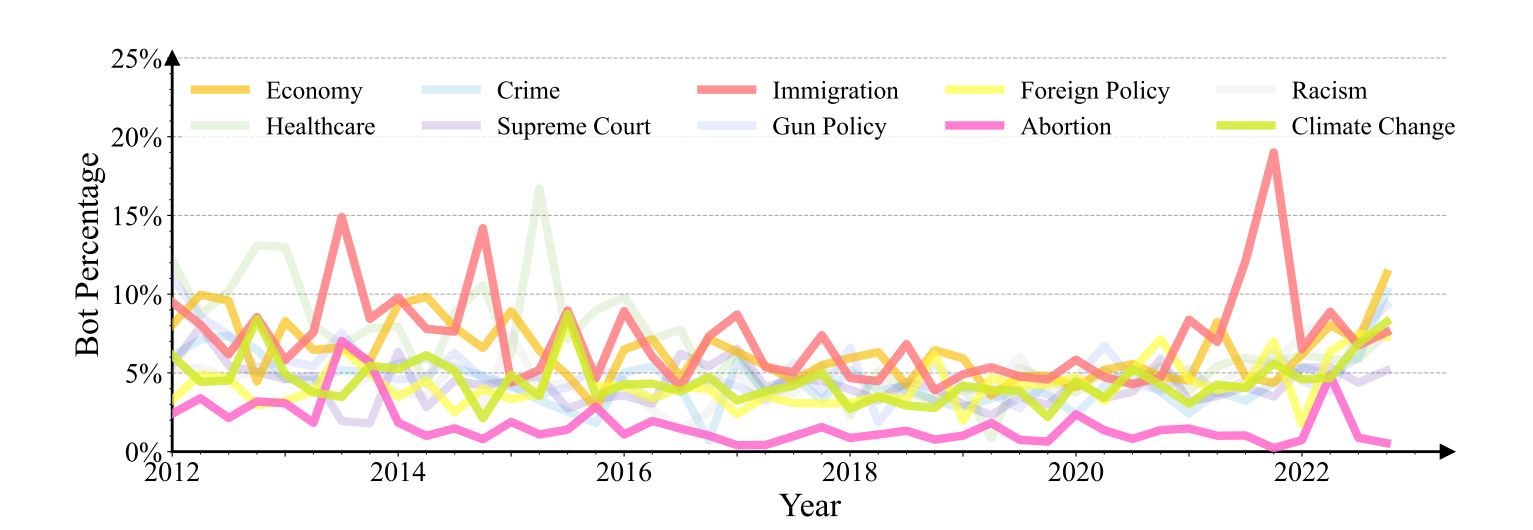
总的来说,Twitter和社交媒体已经成为政治话语的重要媒介,而Twitter机器人则被恶意行为者操纵,以干扰政治讨论(Caldarelli et al. 2020)。
为了更好地理解Twitter机器人的政治干预模式,我们调查了11个政治话题,并使用Flores-Saviaga、Feng和Savage(2022)中提出的政治关键词来搜索不同时间段发布的推文,并分析相应的Twitter用户。对于每个政治话题,我们每季度收集1000个用户在过去十年中的推文2012年1月至2022年12月。如图6所示,bot账户的比例随着现实世界中的重大社会政治事件而变化。
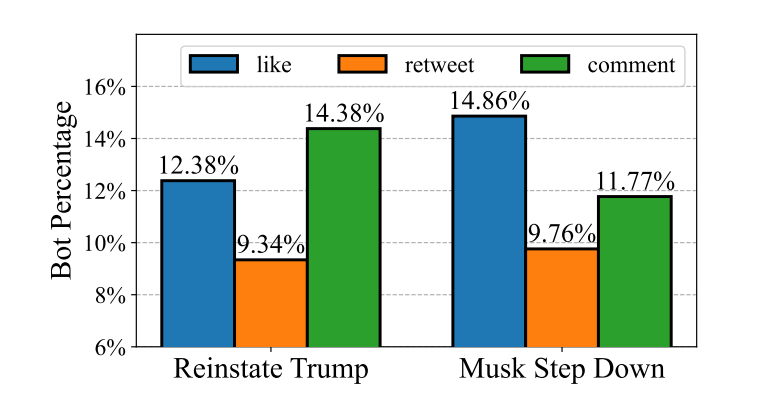
Bot Participation in Content Moderation Votes
自2022年埃隆·马斯克(Elon Musk)收购Twitter以来,他对自己的个人账户进行了多次投票,其中两次投票产生了相应的内容审核结果:一次决定是否恢复唐纳德·特朗普在推特上的职位,另一次决定马斯克是否应该辞去推特首席执行官一职。
虽然内容审核的直接民主政策看起来直截了当,但它有许多问题,其中之一是恶意行为者通过Twitter机器人进行干预。为此,我们利用BotPercent用于调查转发、评论或喜欢这两次的用户中的bot数量,而具体的投票数据无法通过Twitter API获得
图9显示,在与两种内容审核投票进行交互的用户中,约有8%到14%是机器人。考虑到两党支持率接近(51.8%对48.2%),(57.5% vs . 42.5%),以至于机器人可能改变了结果,我们的分析对结果的有效性提出了质疑“大众之声,上帝之声”的社交媒体节制原则。
Bot Population in Different Countries’ Politics
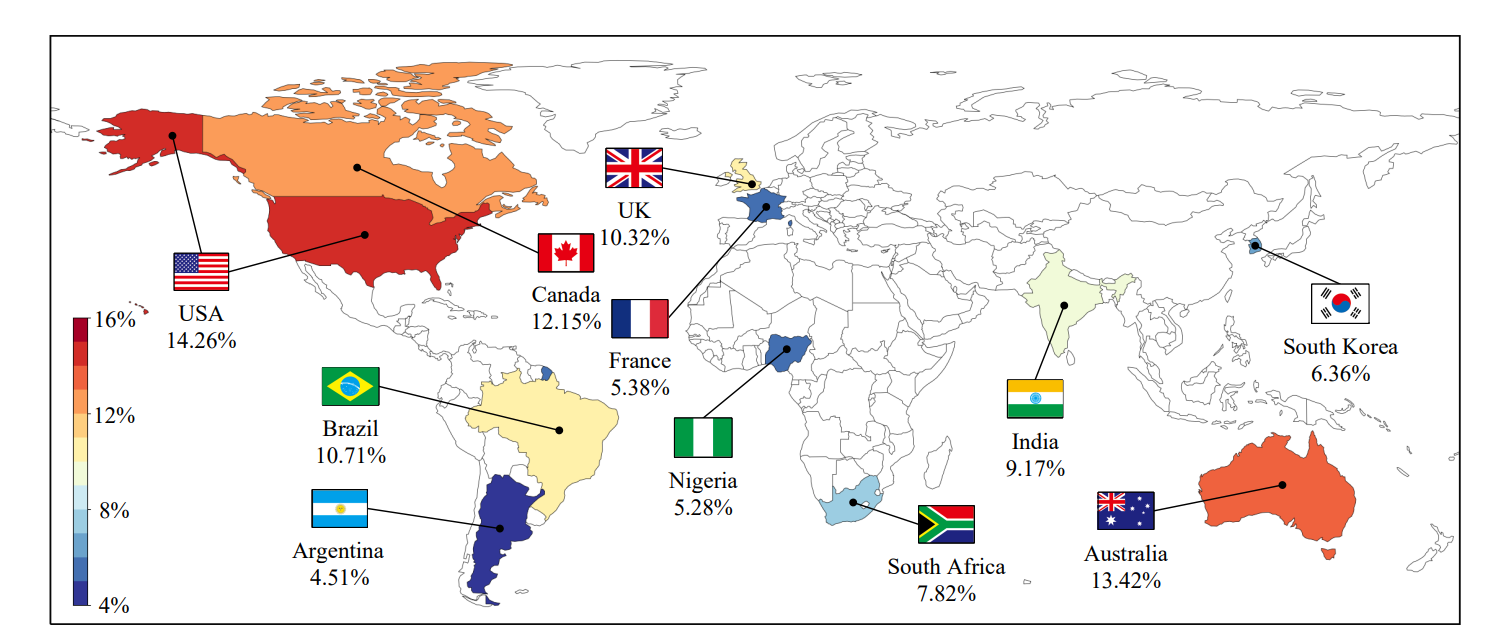
现有的关于推特机器人人口的研究主要集中在美国政治中的机器人(Bessi和Ferrara 2016;Yang et al. 2020),而忽视了可能存在类似问题的其他国家的政治格局。
我们通过调查不同国家政治社区的bot人口来补充稀缺的文献。具体来说,我们以总统或总理的Twitter账户为起点,抽样他们的追随者,作为不同国家政治参与社区的代理。图8显示,美国政治中机器人的比例最高,而其他英语国家也见证了更高水平的机器人干预。此外,阿根廷、法国和尼日利亚的政治社区中机器人的比例最低,这表明他们的政治话语更真实、更真实。这些结果再次证实,推特机器人在整个推特网络中具有空间模式,而恶意推特机器人在美国以外的国家的影响值得进一步研究。
相关文章:
论文阅读-BotPercent: Estimating Twitter Bot Populations from Groups to Crowds
目录 摘要 引言 方法 数据集 BotPercent架构 实验结果 活跃用户中的Bot数量 Bot Population among Comment Sections Bot Participation in Content Moderation Votes Bot Population in Different Countries’ Politics 论文链接:https://arxiv.org/pdf/23…...
用于永磁同步电机驱动器的自适应SDRE非线性无传感器速度控制(MatlabSimulink实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
Spring Cloud+Spring Boot+Mybatis+uniapp+前后端分离实现知识付费平台免费搭建 qt
Java版知识付费源码 Spring CloudSpring BootMybatisuniapp前后端分离实现知识付费平台 提供职业教育、企业培训、知识付费系统搭建服务。系统功能包含:录播课、直播课、题库、营销、公司组织架构、员工入职培训等。 提供私有化部署,免费售…...
删除注释(力扣)
删除注释 题目 给一个 C 程序,删除程序中的注释。这个程序source是一个数组,其中source[i]表示第 i 行源码。 这表示每行源码由 ‘\n’ 分隔。 在 C 中有两种注释风格,行内注释和块注释。 字符串// 表示行注释,表示//和其右侧…...

阿里云AK创建
要在阿里云上创建 Access Key(AK),您需要按照以下步骤进行操作: 登录到阿里云控制台([https://www.aliyun.com/?utm_contentse_1014243503))。 点击右上方的主账号,点击“AccessKey管理”。 …...

OC与Swift的相互调用
OC调用Swift方法 1、在 Build Settings 搜索 Packaging ,设置 Defines Module 为 YES 2、新建 LottieBridge.swift 文件,自动生成桥 ProductName-Bridging-Header.h 3、在 LottieBridge.swift 中,定义Swift类继承于OC类,声明 obj…...

某银行软件测试笔试题
(时间90分钟,满分100分) 考试要求:计算机相关专业试题 一、填空题(每空1分,共10分) 1. ______验证___是保证软件正确实现特定功能的一系列活动和过程。 2. 按开发阶段分,软件测试可…...

SpringMVC概述、SpringMVC的工作流程、创建SpringMVC的项目
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaweb 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Spring MVC入门 一、Spring MVC概述二、入门案例2.1导入Sp…...

一文说清楚支付架构
作者:陈斌 支付的技术架构是为了保障能够顺利处理支付请求而设计的结构体系。从系统的角度看,它包括了计算机系统的软件、硬件、网络和数据等。从参与的主体角度来看,它涉及交易的付款方、收款方、支付机构、银行、卡组织和金融监管机构等。要…...

【Golang 接口自动化00】为什么要用Golang做自动化?
目录 为什么使用Golang做自动化 最终想实现的效果 怎么做? 写在后面 资料获取方法 为什么使用Golang做自动化 顺应公司的趋势学习了Golang之后,因为没有太多时间和项目来实践,怕止步于此、步Java缺少练习遗忘殆尽的后尘,决定…...
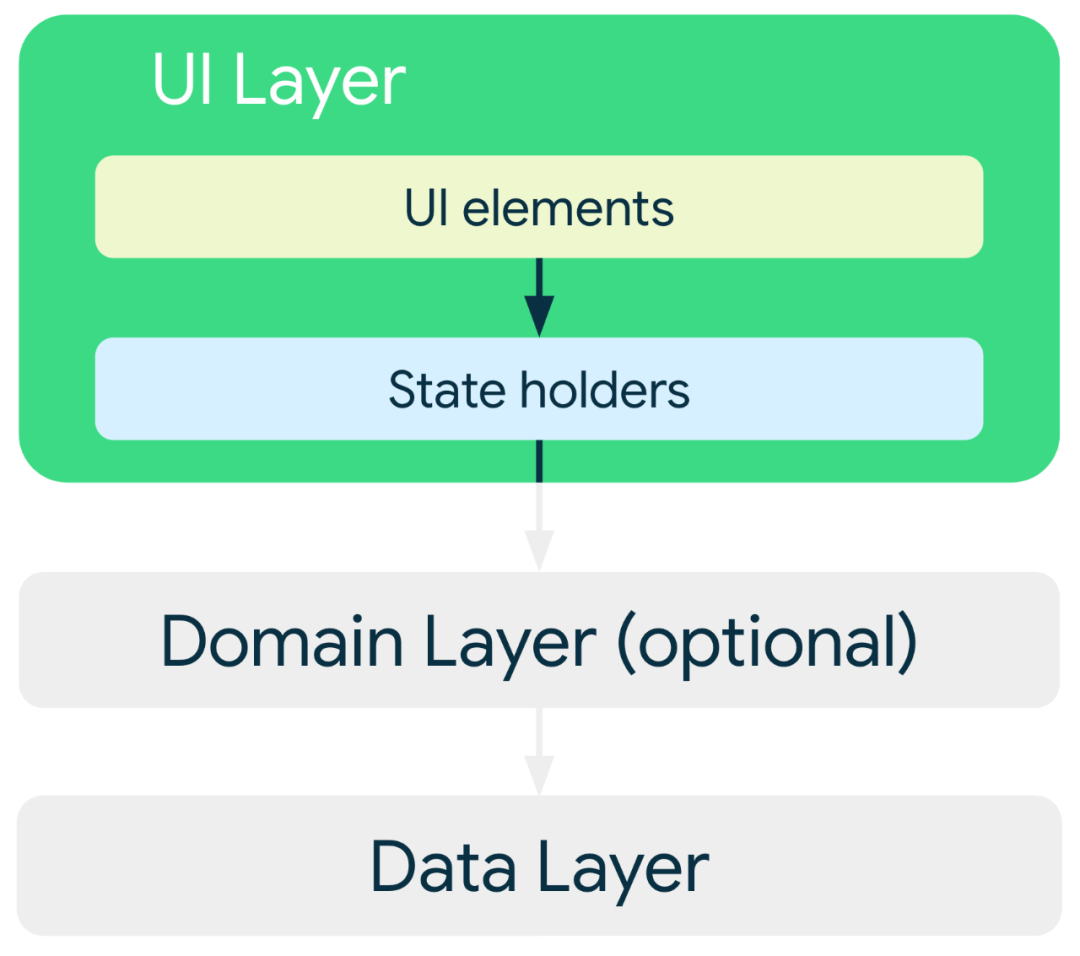
Android 架构模式如何选择
作者:vivo 互联网客户端团队-Xu Jie Android架构模式飞速演进,目前已经有MVC、MVP、MVVM、MVI。到底哪一个才是自己业务场景最需要的,不深入理解的话是无法进行选择的。这篇文章就针对这些架构模式逐一解读。重点会介绍Compose为什么要结合MV…...

深入了解 LoRaWAN® B 类设备
介绍 在 LoRaWAN 网络中,终端设备以三种模式之一运行:LoRaWAN A 类、B 类和 C 类。网络只能将消息(下行链路)发送到终端设备在两个短接收窗口之一期间处于 A 类模式,该接收窗口在设备向网络发送消息(上行链路)后立即打开。然而,这些上行链路不是预先安排的,并且可以由…...
KK集团再闯港交所:引领潮流零售市场,2023年一季度业绩增势显著
撰稿|行星 来源|贝多财经 7月31日,KK Group Company Holdings Limited(下称“KK集团”)在港交所更新招股书,补充了截至2023年3月31日的财务数据等信息,继续推进上市事宜,摩根士丹利和瑞信为其联席保荐人。…...

Vue中的组件渲染
在Vue中,组件的被渲染意味着将组件的内容转换为真实的DOM元素并添加到页面上。当Vue应用启动时,根组件会被渲染,并递归地渲染其子组件。 当组件被渲染时,Vue会将组件的模板解析成虚拟DOM(Virtual DOM)的形…...
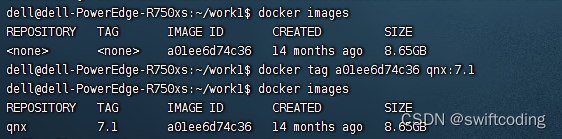
docker 保存和载入镜像
查看本机docker镜像 docker images保存镜像 docker save -o /home/space/work1/docker_qnx7.1.tar.gz a01ee6d74c36复制镜像到其他服务器 scp /home/space/work1/docker_qnx7.1.tar.gz XXXIP:/home/dell/work1/登录新 服务器操作 docker load -i docker_qnx7.1.tar.gz载入后…...
Java框架(九)--Spring Boot入门(1)
SpringBoot 2.x入门简介 学前基础 Maven Spring MVC理念 开发环境 Spring Boot官网版本介绍 https://spring.io/projects/spring-boot#learn 我们点击 Reference Doc. ,再点击Getting Started,就可以看到官网系统环境说明了 官网系统环境说明 Sp…...

2023年第四届“华数杯”数学建模思路 - 案例:随机森林
## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 什么是随机森林? 随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。如果用图来表示他们之…...

Redis中缓存穿透、击穿、雪崩以及解决方案
Redis中缓存穿透、击穿、雪崩以及解决方案 Redis作为一个高效的内存数据库,提供了缓存能力使得我们能够快速访问数据。然而,在使用Redis作为缓存时,我们可能会面临缓存穿透、缓存击穿和缓存雪崩的问题。接下来,我将详细解释这些现…...
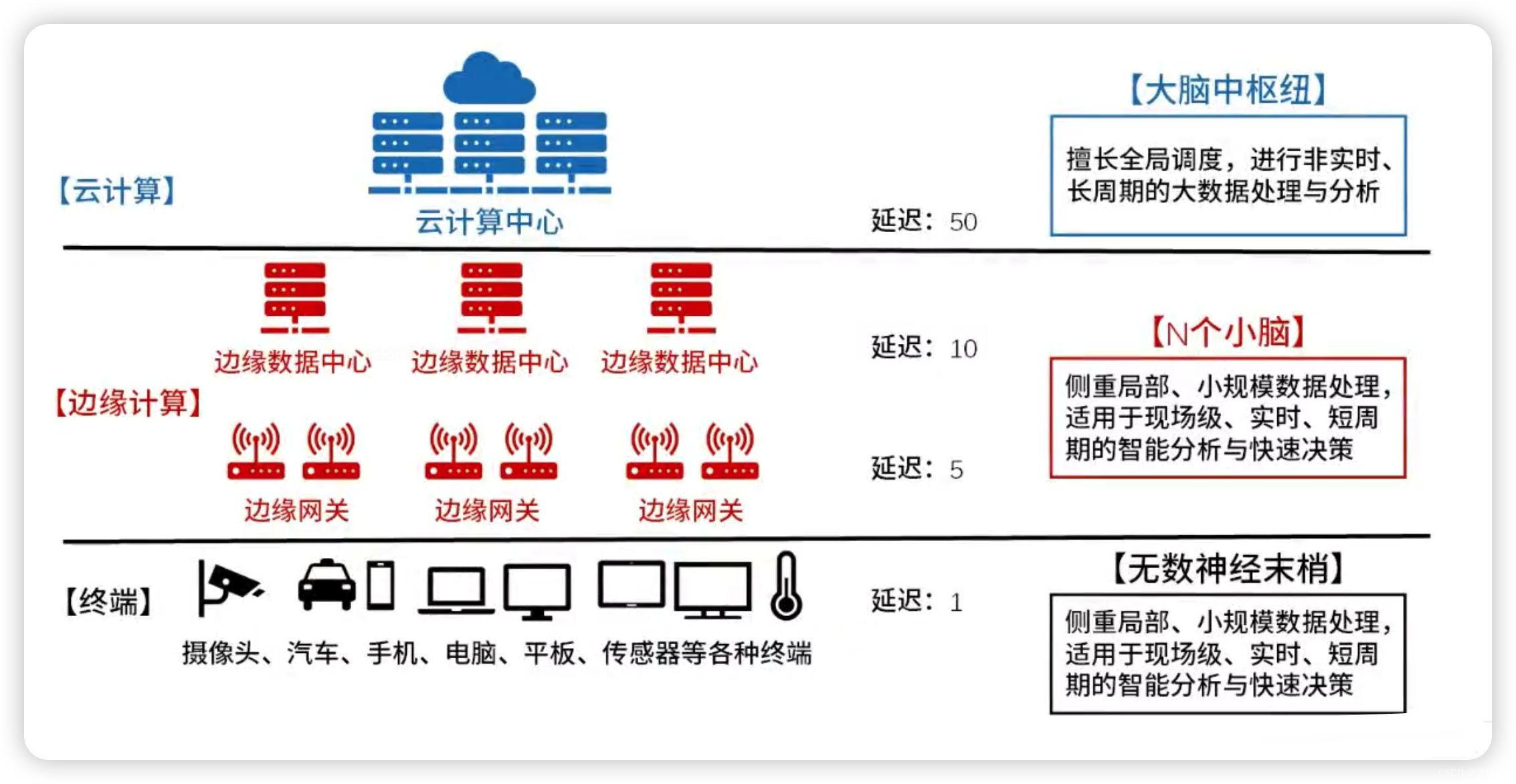
系统架构设计师-软件架构设计(6)
目录 一、物联网分层架构 二、大数据分层架构 三、基于服务的架构(SOA) 1、SOA的特征 2、服务构件与传统构件的区别 四、Web Service(WEB服务) 1、Web Services 和 SOA的关系 五、REST(表述性状态转移) 六、ESB(…...
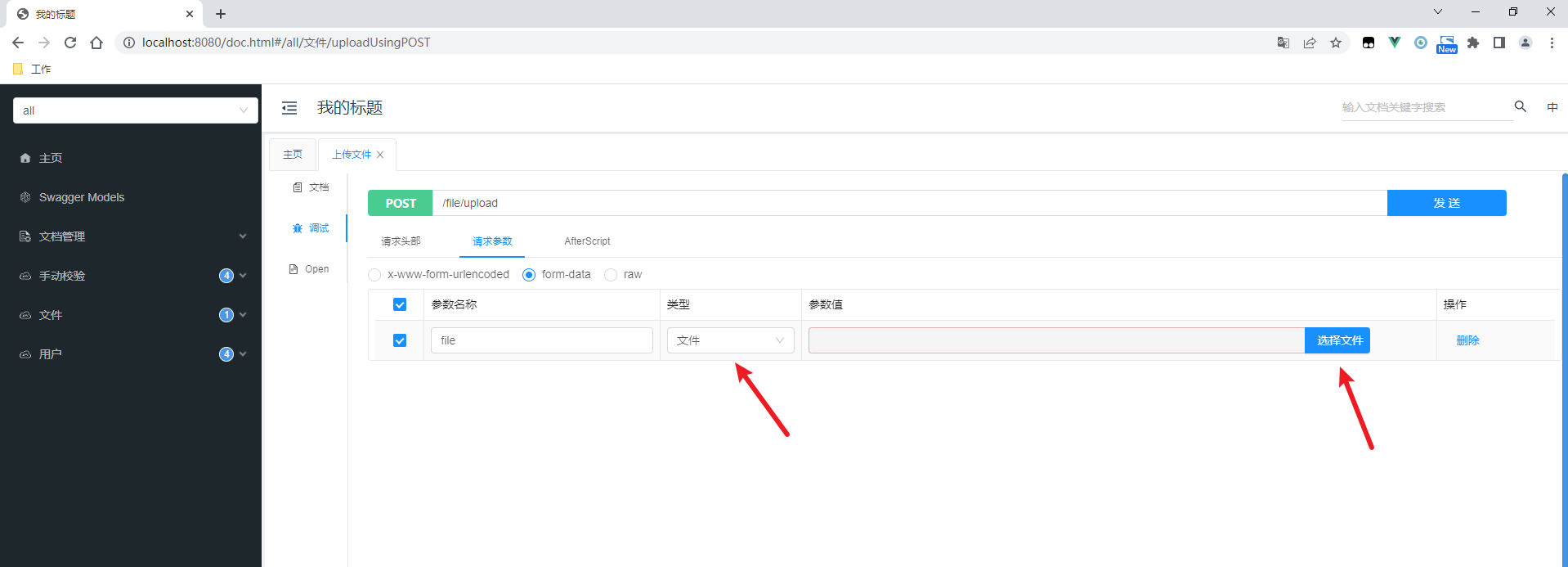
Knife4j系列--解决不显示文件上传的问题
原文网址:Knife4j系列--解决不显示文件上传的问题_IT利刃出鞘的博客-CSDN博客 简介 本文介绍使用Knife4j时无法上传文件的问题。 问题复现 依赖 <dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-…...
)
别再手动改代码了!用Postman汉化插件5分钟搞定中文界面(附最新版下载)
5分钟解锁Postman中文界面:零代码汉化全攻略 第一次打开Postman时,满屏的英文术语是否让你望而却步?作为国内开发者,我们常常需要在这款强大的API测试工具和中文思维之间来回切换。其实,只需一个浏览器插件࿰…...
Hunyuan-MT-7B开源镜像:Pixel Language Portal与LangChain集成构建翻译Agent
Hunyuan-MT-7B开源镜像:Pixel Language Portal与LangChain集成构建翻译Agent 1. 项目概览 Pixel Language Portal(像素语言跨维传送门)是一款基于腾讯Hunyuan-MT-7B大模型构建的创新翻译工具。不同于传统翻译软件的呆板界面,它采…...

SuperMap iClient3D for WebGL 倾斜摄影压平与批量模型自动化布设
1. 倾斜摄影压平技术入门指南 第一次接触倾斜摄影压平技术时,我也被这个专业名词唬住了。其实说白了,就是把倾斜摄影模型中的某个区域"拍平",就像用熨斗把衣服熨平一样简单。在城市规划项目中,这个功能特别实用…...

终极指南:使用Jsxer快速解密Adobe JSXBIN二进制脚本文件
终极指南:使用Jsxer快速解密Adobe JSXBIN二进制脚本文件 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer 你是否曾经遇到过以JSXBIN开头的Adobe ExtendScript二进制文件?这些…...

生成式推荐算法合规性悬崖:GDPR/《生成式AI服务管理暂行办法》双约束下,如何重构用户意图建模链路?
第一章:生成式推荐算法合规性悬崖:GDPR/《生成式AI服务管理暂行办法》双约束下,如何重构用户意图建模链路? 2026奇点智能技术大会(https://ml-summit.org) 在生成式推荐系统中,用户意图建模正面临前所未有的合规性临界…...

ESP32驱动0.96寸OLED屏,从C51代码移植到ESP-IDF的保姆级避坑指南
ESP32驱动0.96寸OLED屏:从C51到ESP-IDF的完整移植指南 当我们需要在ESP32项目中使用0.96寸OLED显示屏时,往往会遇到一个常见问题:手头只有基于C51单片机的驱动代码(比如淘宝卖家提供的例程),如何将其移植到…...

如何获取并定制化订货系统源码以适应企业需求?
在数字化转型的浪潮中,构建自主可控的 B2B 业务平台已成为众多企业的核心战略。对于希望深度掌控业务流程、实现数据私有化部署的企业而言,直接获取并二次开发订货系统源码是最高效的路径。这不仅意味着拥有系统的完全所有权,更代表了能够根据…...

面试官:堆外内存爆了,Dump 文件没用,你怎么定位?3招定位线上“幽灵内存泄漏”
如果是堆外内存(Direct Memory)溢出怎么办?我看监控面板,Heap用得很少,但机器的内存RSS一直在飙升,最后进程直接被Linux的OOM Killer杀掉了。用MAT打开Dump文件,里面啥也没有,这咋整…...

如何解决ScriptCat中GM.xmlHttpRequest异步兼容性问题:完整指南
如何解决ScriptCat中GM.xmlHttpRequest异步兼容性问题:完整指南 【免费下载链接】scriptcat ScriptCat, a browser extension that can execute userscript; 脚本猫,一个可以执行用户脚本的浏览器扩展 项目地址: https://gitcode.com/gh_mirrors/sc/sc…...
从录制到执行:利用Scripting Tracker与Python实现SAP GUI自动化操作
1. 为什么需要SAP GUI自动化? 每天重复点击几十次相同的按钮,填写上百个雷同的表单——这是很多SAP用户的真实工作状态。作为企业级ERP系统,SAP的操作往往需要大量人工交互,效率低下且容易出错。我曾在某制造业客户现场见过这样的…...