pytorch实战-图像分类(二)(模型训练及验证)(基于迁移学习(理解+代码))
目录
1.迁移学习概念
2.数据预处理
3.训练模型(基于迁移学习)
3.1选择网络,这里用resnet
3.2如果用GPU训练,需要加入以下代码
3.3卷积层冻结模块
3.4加载resnet152模
3.5解释initialize_model函数
3.6迁移学习网络搭建
3.7优化器
3.8训练模块(可以理解为主函数)
3.9开始训练
3.10微调
4.测试模型
4.1加载训练好的模型
4.2测试数据预处理
4.3数据展示
4.4提取测试数据集
4.5计算提取数据集的预测结果
4.6展示预测结果
参考文献
1.迁移学习概念
先说一下深度学习常见的问题:
1.数据集不够,通常用数据增强解决。
2.参数难以确定,训练时间长,这就需要用迁移学习来解决
什么叫迁移学习呢:比方说有一个对100w的自行车数据集,并用VGG模型训练好的网络,而此时你想训练一个1w自行车数据集(虽然对象一样,但采集的数据会不同),也用VGG模型进行训练,你发现,你们数据集的对象一样,选用的网络模型一样,此时在初始化自己模型权重(就是卷积层,池化层和全连接层的参数)时,可以用人家训练好的模型参数(如果不这样就需要随机初始化模型权重),这样做可以节省大量寻找最优参数的时间,又可以保证参数的准确。
总结:迁移学习就是用别人的东西训练自己的东西,但要注意,为了使用别人的模型参数,要保证自己的数据对象、网络结构、输入和输出数据的结构和别人相同。比方说,别人识别狗,你不能识别 猫,别人用VGG你不能用resnet,别人输入和输入图像大小是224×224.你不能是256×256。
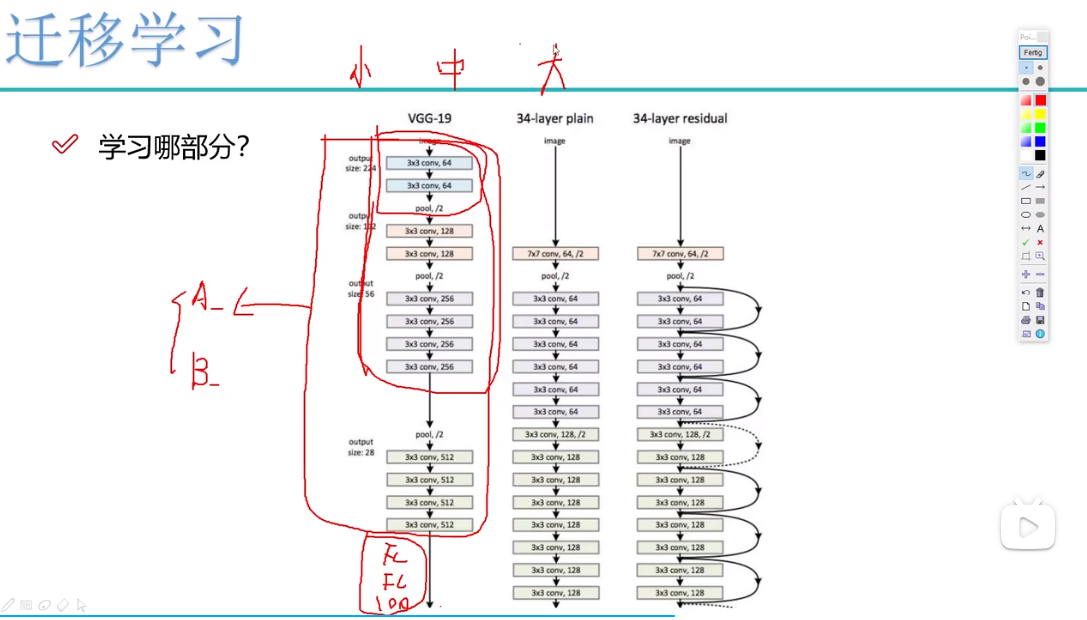
进一步理解迁移学习的使用1:看下图最大的红框,表示卷积层,当用别人的模型时,对卷积层的两种处理方式。
A:作为自己模型权重的初始化参数。
B:冻结卷积层网络,意思是直接用别人的参数,不再更新。冻结卷积层网络又分几种情况。
B1:当数据量小时,冻结第二大红框表示的卷积层,剩下卷积层进行更新。因为数据量小时,容易过拟合,直接用别人呢参数最好。
B2:当数据量中等时冻结最小红框表示的卷积层,剩下的卷积层进行更行。
B3:当数据量足够大时,不冻结卷积层,用A的方法,只作为自己模型权重的初始化参数。数据量大时,虽然对象一样,但毕竟数据不同,会有一定差异,更新参数是最优选择。
进一步理解迁移学习的使用2:说完卷积层,在说一下全连接层,必须要注意不管卷积层选A还是B,全连接层都是要更新的,原因在于,别人模型进行图像分类可能是进行1000个分类,而你只进行100或者999个分类,那么全连接层的参数肯定是不同的。
2.数据预处理
上接该文:pytorch实战-图像分类(一)(数据预处理)
3.训练模型(基于迁移学习)
3.1选择网络,这里用resnet
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
#是否用人家训练好的特征来做
feature_extract = True 3.2如果用GPU训练,需要加入以下代码
# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()if not train_on_gpu:print('CUDA is not available. Training on CPU ...')
else:print('CUDA is available! Training on GPU ...')device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")3.3卷积层冻结模块
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:for param in model.parameters():param.requires_grad = False3.4加载resnet152模
注意:resnet152模型就是别人的模型。
model_ft = models.resnet152()
model_ft3.5解释initialize_model函数
本小节只是截取pytorch官网的一个例子,用initialize_model说明在pytoch中迁移学习怎么使用,不属于本文代码
具体操作如下:
1.下载别人的模型参数,这里下载restnet152模型
2.选择需要冻结的卷积层
3.改变全连接层的输出个数,这里将1000改为102
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):# 选择合适的模型,不同模型的初始化方法稍微有点区别model_ft = Noneinput_size = 0if model_name == "resnet":""" Resnet152"""model_ft = models.resnet152(pretrained=use_pretrained) #下载resnet152模型set_parameter_requires_grad(model_ft, feature_extract) #选择冻结哪部分卷积层num_ftrs = model_ft.fc.in_features #全连接层的输入比方说全连接层是2048×1000,这就是2048.model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102),nn.LogSoftmax(dim=1)) #原resnet152的全连接层输出是1000,自己模型需要的输出是102,进行改动。input_size = 224return model_ft, input_size3.6迁移学习网络搭建
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)#GPU计算
model_ft = model_ft.to(device)# 模型保存
filename='checkpoint.pth'# 是否训练所有层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:params_to_update = []for name,param in model_ft.named_parameters():if param.requires_grad == True:params_to_update.append(param)print("\t",name)
else:for name,param in model_ft.named_parameters():if param.requires_grad == True:print("\t",name)3.7优化器
就是用该方法更新模型参数
# 优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#学习率每7个epoch衰减成原来的1/10
#最后一层已经LogSoftmax()了,所以不能nn.CrossEntropyLoss()来计算了,nn.CrossEntropyLoss()相当于logSoftmax()和nn.NLLLoss()整合
criterion = nn.NLLLoss()3.8训练模块(可以理解为主函数)
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename):since = time.time() #best_acc = 0"""checkpoint = torch.load(filename)best_acc = checkpoint['best_acc']model.load_state_dict(checkpoint['state_dict'])optimizer.load_state_dict(checkpoint['optimizer'])model.class_to_idx = checkpoint['mapping']"""model.to(device)val_acc_history = []train_acc_history = []train_losses = []valid_losses = []LRs = [optimizer.param_groups[0]['lr']]best_model_wts = copy.deepcopy(model.state_dict())for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 训练和验证for phase in ['train', 'valid']:if phase == 'train':model.train() # 训练else:model.eval() # 验证running_loss = 0.0running_corrects = 0# 把数据都取个遍for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 清零optimizer.zero_grad()# 只有训练的时候计算和更新梯度with torch.set_grad_enabled(phase == 'train'):if is_inception and phase == 'train':outputs, aux_outputs = model(inputs)loss1 = criterion(outputs, labels)loss2 = criterion(aux_outputs, labels)loss = loss1 + 0.4*loss2else:#resnet执行的是这里outputs = model(inputs)loss = criterion(outputs, labels)_, preds = torch.max(outputs, 1)# 训练阶段更新权重if phase == 'train':loss.backward()optimizer.step()# 计算损失running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / len(dataloaders[phase].dataset)epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)time_elapsed = time.time() - sinceprint('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# 得到最好那次的模型if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())state = {'state_dict': model.state_dict(),'best_acc': best_acc,'optimizer' : optimizer.state_dict(),}torch.save(state, filename)if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)scheduler.step(epoch_loss)if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))LRs.append(optimizer.param_groups[0]['lr'])print()time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))# 训练完后用最好的一次当做模型最终的结果model.load_state_dict(best_model_wts)return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs 3.9开始训练
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))3.10微调
在2.9中得到的模型,是冻结了卷积层,只训练了全连接层,所以此时希望在此基础上再对卷积层进行训练。
for param in model_ft.parameters():param.requires_grad = True# 再继续训练所有的参数,学习率调小一点
optimizer = optim.Adam(params_to_update, lr=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)# 损失函数
criterion = nn.NLLLoss()# Load the checkpoint,加载自己的模型checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
#model_ft.class_to_idx = checkpoint['mapping']model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer, num_epochs=10, is_inception=(model_name=="inception"))4.测试模型
4.1加载训练好的模型
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)# GPU模式
model_ft = model_ft.to(device)# 保存文件的名字
filename='seriouscheckpoint.pth'# 加载模型
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])4.2测试数据预处理
1.测试数据处理方法需要跟训练时一直才可以
2.crop操作的目的是保证输入的大小是一致的
3.标准化操作也是必须的,用跟训练数据相同的mean和std,但是需要注意一点训练数据是在0-1上进行标准化,所以测试数据也需要先归一化
4.PyTorch中颜色通道是第一个维度,跟很多工具包都不一样,需要转换
def process_image(image_path):# 读取测试数据img = Image.open(image_path)# Resize,thumbnail方法只能进行缩小,所以进行了判断if img.size[0] > img.size[1]:img.thumbnail((10000, 256))else:img.thumbnail((256, 10000))# Crop操作left_margin = (img.width-224)/2bottom_margin = (img.height-224)/2right_margin = left_margin + 224top_margin = bottom_margin + 224img = img.crop((left_margin, bottom_margin, right_margin, top_margin))# 相同的预处理方法img = np.array(img)/255mean = np.array([0.485, 0.456, 0.406]) #provided meanstd = np.array([0.229, 0.224, 0.225]) #provided stdimg = (img - mean)/std# 注意颜色通道应该放在第一个位置img = img.transpose((2, 0, 1))return img4.3数据展示
def imshow(image, ax=None, title=None):"""展示数据"""if ax is None:fig, ax = plt.subplots()# 颜色通道还原image = np.array(image).transpose((1, 2, 0))# 预处理还原mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])image = std * image + meanimage = np.clip(image, 0, 1)ax.imshow(image)ax.set_title(title)return ax4.4提取测试数据集
# 得到一个batch的测试数据
dataiter = iter(dataloaders['valid'])
images, labels = dataiter.next()model_ft.eval()if train_on_gpu:output = model_ft(images.cuda())
else:output = model_ft(images)4.5计算提取数据集的预测结果
_, preds_tensor = torch.max(output, 1)preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())
preds4.6展示预测结果
fig=plt.figure(figsize=(20, 20))
columns =4
rows = 2for idx in range (columns*rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])plt.imshow(im_convert(images[idx]))ax.set_title("{} ({})".format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),color=("green" if cat_to_name[str(preds[idx])]==cat_to_name[str(labels[idx].item())] else "red"))
plt.show()参考文献
1.6-训练结果与模型保存_哔哩哔哩_bilibili
相关文章:
pytorch实战-图像分类(二)(模型训练及验证)(基于迁移学习(理解+代码))
目录 1.迁移学习概念 2.数据预处理 3.训练模型(基于迁移学习) 3.1选择网络,这里用resnet 3.2如果用GPU训练,需要加入以下代码 3.3卷积层冻结模块 3.4加载resnet152模 3.5解释initialize_model函数 3.6迁移学习网络搭建 3.…...
b 树和 b+树的理解
项目场景: 图灵奖获得者(Niklaus Wirth )说过: 程序 数据结构 算法, 也就说我们无时无刻 都在和数据结构打交道。 只是作为 Java 开发,由于技术体系的成熟度较高,使得大部分人认为࿱…...

正则表达式 —— Awk
Awk awk:文本三剑客之一,是功能最强大的文本工具 awk也是按行来进行操作,对行操作完之后,可以根据指定命令来对行取列 awk的分隔符,默认分隔符是空格或tab键,多个空格会压缩成一个 awk的用法 awk的格式…...

国芯新作 | 四核Cortex-A53@1.4GHz,仅168元起?含税?哇!!!
创龙科技SOM-TLT507是一款基于全志科技T507-H处理器设计的4核ARM Cortex-A53全国产工业核心板,主频高达1.416GHz。核心板CPU、ROM、RAM、电源、晶振等所有元器件均采用国产工业级方案,国产化率100%。 核心板通过邮票孔连接方式引出MIPI CSI、HDMI OUT、…...
【MyBatis】 框架原理
目录 10.3【MyBatis】 框架原理 10.3.1 【MyBatis】 整体架构 10.3.2 【MyBatis】 运行原理 10.4 【MyBatis】 核心组件的生命周期 10.4.1 SqlSessionFactoryBuilder 10.4.2 SqlSessionFactory 10.4.3 SqlSession 10.4.4 Mapper Instances 与 Hibernate 框架相比&#…...

三、线性工作流
再生产的各个环节,正确使用gamma编码及gamma解码,使得最终得到的颜色数据与最初输入的物理数据一致。如果使用gamma空间的贴图,在传给着色器前需要从gamma空间转到线性空间。 如果不在线性空间下进行渲染,会产生的问题:…...

2023华数杯数学建模A题思路 - 隔热材料的结构优化控制研究
# 1 赛题 A 题 隔热材料的结构优化控制研究 新型隔热材料 A 具有优良的隔热特性,在航天、军工、石化、建筑、交通等 高科技领域中有着广泛的应用。 目前,由单根隔热材料 A 纤维编织成的织物,其热导率可以直接测出;但是 单根隔热…...
Zabbix分布式监控Web监控
目录 1 概述2 配置 Web 场景2.1 配置步骤2.2 显示 3 Web 场景步骤3.1 创建新的 Web 场景。3.2 定义场景的步骤3.3 保存配置完成的Web 监控场景。 4 Zabbix-Get的使用 1 概述 您可以使用 Zabbix 对多个网站进行可用性方面监控: 要使用 Web 监控,您需要定…...

PHP从入门到精通—PHP开发入门-PHP概述、PHP开发环境搭建、PHP开发环境搭建、第一个PHP程序、PHP开发流程
每开始学习一门语言,都要了解这门语言和进行开发环境的搭建。同样,学生开始PHP学习之前,首先要了解这门语言的历史、语言优势等内容以及了解开发环境的搭建。 PHP概述 认识PHP PHP最初是由Rasmus Lerdorf于1994年为了维护个人网页而编写的一…...

【LeetCode-中等】722. 删除注释
题目链接 722. 删除注释 标签 字符串 步骤 Step1. 先将source合并为一个字符串进行处理,中间补上’\n’,方便后续确定注释开始、结束位置。 string combined; for (auto str : source) {combined str "\n"; }Step2. 定义数组 toDel&am…...

rust里如何判断字符串是否相等呢?
在 Rust 中,有几种方法可以判断字符串是否相等。下面是其中几种常见的方法: 使用 运算符:可以直接使用 运算符比较两个字符串是否相等。例如: fn main() {let str1 "hello";let str2 "world";if str1 …...

python基本知识学习
一、输出语句 在控制台输出Hello,World! print("Hello,World!") 二、注释 单行注释:以#开头 # print("你好") 多行注释: 选中要注释的代码Ctrl/三单引号三双引号 # print("你好") # a1 # a2 print("Hello,World!&…...
vue3和typescript_组件
1 components下新建myComponent.vue 2 页面中引入组件,传入值,并且绑定事件函数。 3...

Qt+联想电脑管家
1.自定义按钮类 效果: (1)仅当未选中,未悬浮时 (2)其他三种情况,均如图 #ifndef BTN_H #define BTN_H#include <QPushButton> class btn : public QPushButton {Q_OBJECT public:btn(QWidget * parent nullptr);void set_normal_icon(…...
论文阅读-BotPercent: Estimating Twitter Bot Populations from Groups to Crowds
目录 摘要 引言 方法 数据集 BotPercent架构 实验结果 活跃用户中的Bot数量 Bot Population among Comment Sections Bot Participation in Content Moderation Votes Bot Population in Different Countries’ Politics 论文链接:https://arxiv.org/pdf/23…...
用于永磁同步电机驱动器的自适应SDRE非线性无传感器速度控制(MatlabSimulink实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
Spring Cloud+Spring Boot+Mybatis+uniapp+前后端分离实现知识付费平台免费搭建 qt
Java版知识付费源码 Spring CloudSpring BootMybatisuniapp前后端分离实现知识付费平台 提供职业教育、企业培训、知识付费系统搭建服务。系统功能包含:录播课、直播课、题库、营销、公司组织架构、员工入职培训等。 提供私有化部署,免费售…...
删除注释(力扣)
删除注释 题目 给一个 C 程序,删除程序中的注释。这个程序source是一个数组,其中source[i]表示第 i 行源码。 这表示每行源码由 ‘\n’ 分隔。 在 C 中有两种注释风格,行内注释和块注释。 字符串// 表示行注释,表示//和其右侧…...

阿里云AK创建
要在阿里云上创建 Access Key(AK),您需要按照以下步骤进行操作: 登录到阿里云控制台([https://www.aliyun.com/?utm_contentse_1014243503))。 点击右上方的主账号,点击“AccessKey管理”。 …...

OC与Swift的相互调用
OC调用Swift方法 1、在 Build Settings 搜索 Packaging ,设置 Defines Module 为 YES 2、新建 LottieBridge.swift 文件,自动生成桥 ProductName-Bridging-Header.h 3、在 LottieBridge.swift 中,定义Swift类继承于OC类,声明 obj…...
到HAL层回调的完整消息传递链路)
图解Android蓝牙启动:从App调用enable()到HAL层回调的完整消息传递链路
Android蓝牙启动流程深度解析:从应用层到HAL层的完整链路 在车载系统、智能家居等场景中,蓝牙作为核心无线通信协议,其启动过程的稳定性直接影响用户体验。本文将深入剖析Android蓝牙子系统从应用层调用enable()到HAL层回调的完整消息传递链路…...

幻境·流金入门必看:DiffSynth-Studio+玄金美学环境搭建详解
幻境流金入门必看:DiffSynth-Studio玄金美学环境搭建详解 “流光瞬息,影画幻成。” 你是否曾幻想过,只需输入一段文字描述,就能在十几秒内获得一张细节丰富、质感堪比电影画面的高清图像?这听起来像是科幻电影里的场景…...

Excalidraw虚拟白板工具:如何用5分钟开启你的手绘图表创作之旅?
Excalidraw虚拟白板工具:如何用5分钟开启你的手绘图表创作之旅? 【免费下载链接】excalidraw Virtual whiteboard for sketching hand-drawn like diagrams 项目地址: https://gitcode.com/GitHub_Trending/ex/excalidraw 你是否厌倦了传统图表工…...

网盘直链下载助手:八大平台高速下载解决方案
网盘直链下载助手:八大平台高速下载解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

应对2026检测新规:论文如何优化?实测10款降低AI率工具,SCI/工科适用
现在写论文最怕的,已经不是查重了。怕什么?怕那个AIGC率太高。 真的,越来越多学校开始抓AIGC检测报告了,重复率放一边,就看你AI痕迹多不多。我自己就是刚爬出坑的25届学姐,这坑我踩得死死的。怎么说呢&…...
- 田忌赛马(Java JS Python C))
(200分)- 田忌赛马(Java JS Python C)
(200分)- 田忌赛马(Java & JS & Python & C)题目描述给定两个只包含数字的数组a,b,调整数组 a 里面的数字的顺序,使得尽可能多的a[i] > b[i]。数组a和b中的数字各不相同。输出所有可以达到最优结果的a数…...
)
Mac上告别命令行!用SmartSVN图形化搞定SVN版本控制(附目录结构最佳实践)
Mac上告别命令行!用SmartSVN图形化搞定SVN版本控制(附目录结构最佳实践) 作为一名长期与代码打交道的开发者,我深知版本控制工具的重要性。但每次打开终端输入那些晦涩的SVN命令时,总有种穿越回2005年的错觉。直到发现…...

别再折腾编译了!用Qt和VLC 2.2.4 SDK在Windows上快速打造自己的视频播放器
用Qt和VLC SDK在Windows上快速构建视频播放器的完整指南 每次看到开发者为了一个简单的视频播放功能而陷入VLC编译的泥潭,我都忍不住想——其实有更优雅的解决方案。本文将带你绕过复杂的编译过程,直接使用预编译的VLC 2.2.4 SDK和Qt框架,在W…...

突破性AI技术:3大维度深度解析Zero123++图像生成新范式
突破性AI技术:3大维度深度解析Zero123图像生成新范式 【免费下载链接】zero123plus Code repository for Zero123: a Single Image to Consistent Multi-view Diffusion Base Model. 项目地址: https://gitcode.com/gh_mirrors/ze/zero123plus Zero123是一项…...
集成实战:从环境配置到核心功能实现(含源码解析))
VS2019 MFC CEF(Chrome)集成实战:从环境配置到核心功能实现(含源码解析)
1. 为什么要在MFC中集成CEF? 十年前我刚接触MFC开发时,最头疼的就是界面美化问题。传统的GDI绘图方式要实现一个圆角按钮都得折腾半天,更别说复杂的动态效果了。直到发现CEF(Chromium Embedded Framework)这个神器&…...