vue-router 源码解析(二)-创建路由匹配对象
文章目录
- 基本使用
- 导语
- createRouterMatcher 创建匹配路由记录
- addRoute 递归添加matcher
- createRouteRecordMatcher 创建matcher
- tokenizePath 解析path
- tokensToParser 记录打分
- insertMatcher 将matcher排序
- 总结
基本使用
const routes = [{path:"/",component: Demo2,name:'root',beforeEnter: (to, from) => {console.log('ddd')return true;},beforeLeave:(to, from) => {console.log('aa')return true;},},{ path: '/d0/d01?p0=jeff', component: App,name:'n0',alias:'/a0',beforeEnter: (to, from) => {return true;},},{ path: '/d1/:d11', component: Demo1 ,name:'n1',beforeEnter:[ (to, from) => {return true;},(to, from) => {return true;}],},{ path: '/d2/d21', component: Demo2,name:'n2',redirect:'/r2'},{path: '/d3',name: 'n3',component: Demo1,children: [{ path: 'd31', name: 'n31', component: Demo2,alias:'a31' }],},]const router = VueRouter.createRouter({history: VueRouter.createWebHashHistory(), // 创建对应的路由对象routes,
})导语
- 在上文中介绍了三种模式下路由对象的创建,而本文将深入createRouter,解析如何将传入的routes配置,转换成未来进行导航时对应的一个个matcher,当开发者通过push 等API进行导航时,会查找到对应path|name 的matcher记录,进而拿到需要的路由记录信息
- matcher的创建过程,会根据routes中的信息,转换出一条条具有分数(或者理解为权重)的matcher,匹配时会根据分数优先匹配
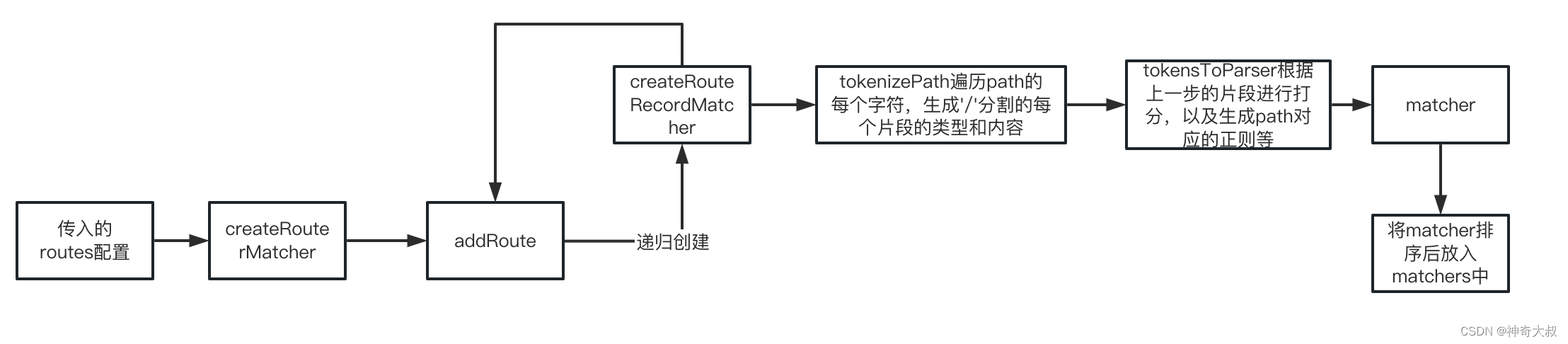
createRouterMatcher 创建匹配路由记录
//router.ts
export function createRouter(options: RouterOptions): Router { //options就为传入的配置// 这里返回的matcher是操作路由记录的API,非路由记录对应的匹配matcherconst matcher = createRouterMatcher(options.routes, options)// ...
}
- 会递归调用addRoutes方法,将配置的routes全部转换成matcher
export function createRouterMatcher(routes: Readonly<RouteRecordRaw[]>,globalOptions: PathParserOptions
): RouterMatcher {// 存储所有routes配置转换而成的路由记录const matchers: RouteRecordMatcher[] = []// 存储原始路由记录(非原始记录:设置了alias的别名路由会再创建一条记录,但该记录不会加入matcherMap中)const matcherMap = new Map<RouteRecordName, RouteRecordMatcher>()// 合并开发者传递的strict、end和sensitive这些约定路由匹配模式的属性globalOptions = mergeOptions({ strict: false, end: true, sensitive: false } as PathParserOptions,globalOptions)function addRoute(route){ //将routes配置转换成matcher,过程会递归调用创建子路由matcher// ...} // 创建一级路由记录routes.forEach(route => addRoute(route));return { addRoute, resolve, removeRoute, getRoutes, getRecordMatcher };
}
addRoute 递归添加matcher
- 普通路由:
- 会为每一个route创建一个matcher
- 别名路由:
- 如果存在别名路由时,会再创建一条matcher,matcher.path为别名设置的名称
- 别名路由的matcher.aliasOf会指向原始路由记录的matcher
- 原始路由的matcher.alias[],会存放对应的所有别名路由记录matcher
- 子路由:
- 当存在子路由时,会递归创建
- 子路由matcher.path会拼接上父路由的路径
- 子路由matcher.parent属性会指向父路由matcher
- 最终所有的matcher会存入matchers,整个创建出来的matchers是一个平级结构(一维数组)
function addRoute(record: RouteRecordRaw, // 原始的route记录(开发者传入的)parent?: RouteRecordMatcher,// 当存在子路由时,parent才会有,第一次因为是创建一级路由,所以为空originalRecord?: RouteRecordMatcher // alais别名路由对应的原始记录) {// 首次添加originalRecord为空,表明是添加第一层根路由const isRootAdd = !originalRecord// 将单个路由配置转换成规定格式,格式如下/**{path: record.path,redirect: record.redirect,name: record.name,meta: record.meta || {},aliasOf: undefined, // 别名记录才会有值,执行原始记录beforeEnter: record.beforeEnter,props: normalizeRecordProps(record),children: record.children || [],instances: {},//路由组件实例,复用时使用leaveGuards: new Set(), // setup中使用的守卫updateGuards: new Set(),// setup中使用的守卫enterCallbacks: {},components:'components' in record? record.components || null: record.component && { default: record.component },}*/const mainNormalizedRecord = normalizeRouteRecord(record)// 让个是别名路由,originalRecord会指向原始路由,为别名路由添加引用mainNormalizedRecord.aliasOf = originalRecord && originalRecord.record// 合并route记录中存在的strict、end和sensitive这些约定路由匹配模式的属性const options: PathParserOptions = mergeOptions(globalOptions, record)// 将转换后的路由变成数组格式,因为可能存在别名,将别名记录添加进去const normalizedRecords: typeof mainNormalizedRecord[] = [mainNormalizedRecord,]// 处理别名情况if ('alias' in record) {// 别名可以是一个字符串或数组,统一变成数组格式const aliases =typeof record.alias === 'string' ? [record.alias] : record.alias!// 将alias变成path,有多少个alias就会添加多少条记录for (const alias of aliases) {normalizedRecords.push(assign({}, mainNormalizedRecord, {components: originalRecord? originalRecord.record.components: mainNormalizedRecord.components,// 别名作为pathpath: alias,// 别名路由指向的原始路由记录aliasOf: originalRecord? originalRecord.record: mainNormalizedRecord,// the aliases are always of the same kind as the original since they// are defined on the same record}) as typeof mainNormalizedRecord)}}// route对应的matcherlet matcher: RouteRecordMatcher// 别名对应的原始matcherlet originalMatcher: RouteRecordMatcher | undefinedfor (const normalizedRecord of normalizedRecords) {const { path } = normalizedRecord// 当存在parent时,说明正在处理子路由// 添加子路由:处理alias没有加'/',且父路由没有以'/'结尾的情况,会拼接父路由路径作为pathif (parent && path[0] !== '/') {const parentPath = parent.record.pathconst connectingSlash =parentPath[parentPath.length - 1] === '/' ? '' : '/'normalizedRecord.path =parent.record.path + (path && connectingSlash + path)}// 现在的版本必须用正则代替'*'匹配所有路由if (__DEV__ && normalizedRecord.path === '*') {throw new Error('Catch all routes ("*") must now be defined using a param with a custom regexp.\n' +'See more at https://next.router.vuejs.org/guide/migration/#removed-star-or-catch-all-routes.')}// 创建出matchermatcher = createRouteRecordMatcher(normalizedRecord, parent, options)if (__DEV__ && parent && path[0] === '/')checkMissingParamsInAbsolutePath(matcher, parent)// 当设置了别名alias,会再次生成一条别名对路由记录// 当第一次遍历原始路由记录后,originalRecord为上次原始记录,将别名路由记录放进原始记录的alias中if (originalRecord) {// 原始记录中添加别名记录originalRecord.alias.push(matcher)if (__DEV__) {checkSameParams(originalRecord, matcher)}} else {// 没有originalMatcher说明没有设置alias别名,或者正在处理原始路由记录originalMatcher = originalMatcher || matcher// 处理别名路由中,往alias中添加别名路由if (originalMatcher !== matcher) originalMatcher.alias.push(matcher)// 检查删除掉之前添加的相同name路由if (isRootAdd && record.name && !isAliasRecord(matcher))removeRoute(record.name)}// 如果存在子路由if (mainNormalizedRecord.children) {const children = mainNormalizedRecord.childrenfor (let i = 0; i < children.length; i++) {addRoute(children[i],matcher,originalRecord && originalRecord.children[i])}}originalRecord = originalRecord || matcherif ((matcher.record.components &&Object.keys(matcher.record.components).length) ||matcher.record.name ||matcher.record.redirect) {// 将matcher根据分数排序,添加进matchers中insertMatcher(matcher)}}// 最终返回删除当前matcher的方法return originalMatcher? () => {// since other matchers are aliases, they should be removed by the original matcherremoveRoute(originalMatcher!)}: noop
}
createRouteRecordMatcher 创建matcher
最主要的是tokenizePath和tokensToParser两个方法
- tokenizePath:解析每一个片段(指按照’/'分割的路径)的类型和内容
- tokensToParser:根据上一步结果进行打分和生成正则等
export function createRouteRecordMatcher(record: Readonly<RouteRecord>, // 路由记录parent: RouteRecordMatcher | undefined, // 父路由记录options?: PathParserOptions // strict、end和sensitive这些约定路由匹配模式的属性
): RouteRecordMatcher {// 通过tokenizePath解析每一个片段(指按照'/'分割的路径)类型和内容,tokensToParser根据上一步结果进行打分和生成正则等const parser = tokensToParser(tokenizePath(record.path), options)const matcher: RouteRecordMatcher = assign(parser, {record,parent,// these needs to be populated by the parentchildren: [],alias: [],})if (parent) {if (!matcher.record.aliasOf === !parent.record.aliasOf)parent.children.push(matcher)}return matcher}
tokenizePath 解析path
- 会遍历path的每一个字符,根据path中的‘/’进行分割,返回[[{type: 0, value: ‘’}],[{type: 0, value: ‘d01?p0=jeff’}]]类似结果
const enum TokenizerState {Static, // 静态路径Param, // 动态路径,比如:idParamRegExp, // custom re for a paramParamRegExpEnd, // check if there is any ? + *EscapeNext,
}
export function tokenizePath(path: string): Array<Token[]> {//...while (i < path.length) {char = path[i++]if (char === '\\' && state !== TokenizerState.ParamRegExp) {previousState = statestate = TokenizerState.EscapeNextcontinue}switch (state) {case TokenizerState.Static: //如果匹配到的是静态路径if (char === '/') {if (buffer) {consumeBuffer()}finalizeSegment()} else if (char === ':') { // 解析到':',说明遇到了动态路径,走动态路径的解析分支consumeBuffer()state = TokenizerState.Param} else {addCharToBuffer()}breakcase TokenizerState.Param: // 动态路径的解析if (char === '(') {state = TokenizerState.ParamRegExp} else if (VALID_PARAM_RE.test(char)) { // 字母或数字addCharToBuffer()} else {consumeBuffer()state = TokenizerState.Static// go back one character if we were not modifyingif (char !== '*' && char !== '?' && char !== '+') i--}break//...
}
- 如果路径为:‘/d0/d01?p0=jeff’,那么将会返回 [ [ {type: 0, value: ‘d0’} ], [ { type: 0, value: ‘d01?p0=jeff’ } ]]
- 如果路径为:‘/d1/:d11’,那么将会返回 [ [ {type: 0, value: ‘d1’} ], [ { type: 1, value: ‘d11’} ] ]
tokensToParser 记录打分
- 根据上一步分割的片段,进行打分以及生成正则
// 打分规则
const enum PathScore {_multiplier = 10,Root = 9 * _multiplier, // just /Segment = 4 * _multiplier, // /a-segmentSubSegment = 3 * _multiplier, // /multiple-:things-in-one-:segmentStatic = 4 * _multiplier, // /staticDynamic = 2 * _multiplier, // /:someIdBonusCustomRegExp = 1 * _multiplier, // /:someId(\\d+)BonusWildcard = -4 * _multiplier - BonusCustomRegExp, // /:namedWildcard(.*) we remove the bonus added by the custom regexpBonusRepeatable = -2 * _multiplier, // /:w+ or /:w*BonusOptional = -0.8 * _multiplier, // /:w? or /:w*// these two have to be under 0.1 so a strict /:page is still lower than /:a-:bBonusStrict = 0.07 * _multiplier, // when options strict: true is passed, as the regex omits \/?BonusCaseSensitive = 0.025 * _multiplier, // when options strict: true is passed, as the regex omits \/?
}
export function tokensToParser(segments: Array<Token[]>,extraOptions?: _PathParserOptions
): PathParser {const score: Array<number[]> = []// 针对动态path等会抽取出来,用于后续判断是否重复出现相同的path,开发环境会提示const keys: PathParserParamKey[] = []for (const segment of segments) {// ...// 如果配置了sensitive的分数let subSegmentScore: number =PathScore.Segment +(options.sensitive ? PathScore.BonusCaseSensitive : 0)// 如果是静态路径的分数 if (token.type === TokenType.Static) {// prepend the slash if we are starting a new segmentif (!tokenIndex) pattern += '/'pattern += token.value.replace(REGEX_CHARS_RE, '\\$&')subSegmentScore += PathScore.Static} // ...}
}
- 如果路径为’/d1/:d11’,最终会返回这样的结果
{"re": {},"score": [[80],[60]],"keys": [{"name": "d11","repeatable": false,"optional": false}],"record": {// ...},"children": [],"alias": []
}
insertMatcher 将matcher排序
function addRoute(record: RouteRecordRaw, // 原始的route记录(开发者传入的)parent?: RouteRecordMatcher,// 当存在子路由时,parent才会有,第一次因为是创建一级路由,所以为空originalRecord?: RouteRecordMatcher // alais别名路由对应的原始记录) {// ...matcher = createRouteRecordMatcher(normalizedRecord, parent, options)// ...if ((matcher.record.components &&Object.keys(matcher.record.components).length) ||matcher.record.name ||matcher.record.redirect) {insertMatcher(matcher)}
}
insertMatcher
function insertMatcher(matcher: RouteRecordMatcher) {let i = 0// 对路由记录根据score进行排序,i代表该路由记录排序后的位置while (i < matchers.length &&comparePathParserScore(matcher, matchers[i]) >= 0 && // comparePathParserScore 是个比较器// 子路由为空路径时,排序应该在父路由前面(matcher.record.path !== matchers[i].record.path ||!isRecordChildOf(matcher, matchers[i])))i++// 将路由记录插入matchers中matchers.splice(i, 0, matcher)// matcherMap 中只存放原始记录if (matcher.record.name && !isAliasRecord(matcher))matcherMap.set(matcher.record.name, matcher)}
总结
- vue-router会将开发者传入的routes配置转换成一条条matcher,而matcher会根据你path的类型进行打分排序,后续匹配时会优先匹配分数高的
相关文章:
vue-router 源码解析(二)-创建路由匹配对象
文章目录基本使用导语createRouterMatcher 创建匹配路由记录addRoute 递归添加matchercreateRouteRecordMatcher 创建matchertokenizePath 解析pathtokensToParser 记录打分insertMatcher 将matcher排序总结基本使用 const routes [{path:"/",component: Demo2,nam…...

分布式新闻项目实战 - 10.Long类型精度丢失问题
怒发冲冠,凭阑处、潇潇雨歇。抬望眼,仰天长啸,壮怀激烈。三十功名尘与土,八千里路云和月。莫等闲、白了少年头,空悲切。 靖康耻,犹未雪。臣子恨,何时灭。驾长车,踏破贺兰山缺。壮志饥…...

如何将本地jar包安装到maven仓库
mvn install:install-file:主要是将本地自定义jar安装到maven仓库,然后在pom中可以直接通过dependency的方式来引用。 此命令有如参数: 命令说明-DgroupId自定义groupId设置groupId 名-DartifactId自定义artifactId设置该包artifactId名-Dversion自定义…...
C++:map和set的认识和简单使用/关联式容器
关联式容器 关联式容器即是用来存储数据的,并且存储的是<Key,Value>结构的键值对,在数据检索时效率比序列式容器高。 序列式容器也就是vector、list、queue等容器,因为其底层为线性序列的数据结构,里面存储的是…...

网络工程师一定要学会的知识点:OSPF,今天给大家详细介绍
1. OSPF 概念OSPF(Open Shortest Path First 开放式最短路径优先)是一种动态路由协议,属于内部网关协议(Interior Gateway Protocol,简称 IGP),是基于链路状态算法的路由协议。2. OSPF 的运行原理(1)OSPF 的…...
企业管理的三大基石及其关系
企业管理的三大基石三大基石是什么三大基石的关系制度:管理:文化:三大基石是什么 一个企业,不管它是属于哪种类型,影响员工行为的都有三种力量——制度、管理和文化,这是管理的三大基石。 三大基石的关系 …...

6个月软件测试培训出来后的感悟 —— 写给正在迷茫是否要转行或去学软件测试的学弟们
本人刚从某培训机构学习结束,现在已经上班一个月了。这篇文章我不会说太多的知识点,或噱人去培训机构学习的话语,仅作为一个普通打工者的身份,来写给那些对于软件测试未来发展、薪资待遇等不清楚的正在为家庭,解决信用…...

IoU Loss综述(IOU,GIOU,CIOU,EIOU,SIOU,WIOU)
边界框回归(BBR)的损失函数对于目标检测至关重要。它的良好定义将为模型带来显著的性能改进。大多数现有的工作假设训练数据中的样本是高质量的,并侧重于增强BBR损失的拟合能力。 一、L2-norm 最初的基于回归的BBR损失定义为L2-norm…...
Node=>Express中间件 学习3
1.概念: 例:在处理污水的时候,一般都要经过三个处理环节,从而保证处理过后的废水,达到排放标准 处理污水的这三个中间处理环节,就可以叫中间件 2.中间件调用流程 当一个请求到达Express的服务器之后&#x…...
【STM32笔记】HAL库UART串口配置及重定向(解决接收中断与scanf不能同时工作的问题)
【STM32笔记】HAL库UART串口配置及重定向(解决接收中断与scanf不能同时工作的问题) 首先 要使用printf和scanf 必不可少的就是 #include <stdio.h>这里需要做的就是配置单片机的UART 并且使其能够被printf和scanf调用 打开异步工作模式 并且选择…...

【前端CSS面试题】2023前端最新版css模块,高频15问
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的CSS面试题 目录 一、CSS必备面试题 1.CSS3新特性 2.CSS实现元素两个盒子垂…...

Linux命令大全,赶紧收藏!
新的一年 新的征程 新的课程开班 等你来学! 本文为Linux命令大全,从A到Z都有总结,建议大家收藏以便查用,或者查漏补缺! A 命令 描述 access 用于检查调用程序是否可以访问指定的文件,用于检查文件…...

大数据入门怎么学习
大数据学习不能停留在理论的层面上,大数据方向切入应是全方位的,基础语言的学习只是很小的一个方面,编程落实到最后到编程思想。学习前一定要对大数据有一个整体的认识。 大数据是数据量多吗?其实并不是,通过Hadoop其…...
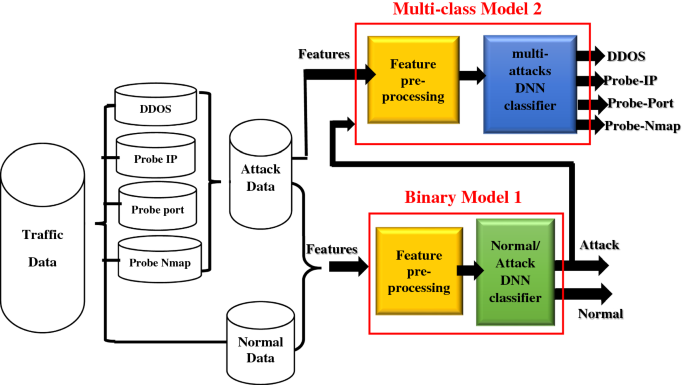
用于异常检测的深度神经网络模型融合
用于异常检测的深度神经网络模型融合 在当今的数字时代,网络安全至关重要,因为全球数十亿台计算机通过网络连接。近年来,网络攻击的数量大幅增加。因此,网络威胁检测旨在通过观察一段时间内的流量数据来检测这些攻击,…...

游戏服务器如何选择合适的服务器配置
游戏服务器如何选择合适的服务器配置 大家好,今天给大家分享一下游戏服务器配置的选择,为什么特别的说明一下服务器呢?服务器是决定服稳定性和安全性最重要的一个程序,如果是服务器配置不够,可能会导致服掉线、卡顿的…...
01-幂等性解释,问题及常用解决方案
目录 1. 幂等性简介 2. 后端如何解决幂等性问题 2.1 数据库层面 -> 2.1.1 防重表 -> 2.1.2 数据库悲观锁(不建议,容易出现死锁情况) -> 2.1.3 数据库乐观锁 -> 2.1.4 乐观锁CAS算法原理 2.2 锁层面 2.3 幂等性token层面 -> 2.3.1 简介文字描述: …...

SpringBoot配置文件
配置文件有两种格式: .properties .yml .properties是老版配置文件,.yml是新版配置文件 一、properties详解 IDEA社区版不支持 properties格式的日志的提示,需要安装相应插件。 3.1properties 基本语法 (ps:小技巧࿰…...

基于蜣螂算法改进的DELM分类-附代码
蜣螂算法改进的深度极限学习机DELM的分类 文章目录蜣螂算法改进的深度极限学习机DELM的分类1.ELM原理2.深度极限学习机(DELM)原理3.蜣螂算法4.蜣螂算法改进DELM5.实验结果6.参考文献7.Matlab代码1.ELM原理 ELM基础原理请参考:https://blog.c…...
FPGA纯verilog代码实现图像对数变换,提供工程源码和技术支持
目录1、图像对数变换理论2、log系数的matlab生成3、FPGA实现图像对数变换4、vivado与matlab联合仿真5、vivado工程介绍6、上板调试验证并演示7、福利:工程代码的获取1、图像对数变换理论 对数变换可以将图像的低灰度值部分扩展,显示出低灰度部分更多的细…...

【Python百日进阶-Web开发-Vue3】Day516 - Vue+ts后台项目3:首页
文章目录 一、首页头部1.1 element-plus中找到适合的Container布局容器1.2 头部容器Layout 布局1.3 src/views/HomeView.vue二、侧边菜单栏2.1 element-plus中找到适合的Menu侧栏2.2 src/views/HomeView.vue三、侧边栏的动态路由3.1 src/views/HomeView.vue3.2 src/views/Goods…...

Visual C++ 运行库全家桶:一键解决Windows软件运行问题的终极方案
Visual C 运行库全家桶:一键解决Windows软件运行问题的终极方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为"应用程序无法启动"…...

2026年5月11日|60秒读懂世界:国乒双冠、微信组合支付、公积金新政与科技突破速览
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

ClawX:桌面化AI Agent编排平台,降低OpenClaw使用门槛
1. 项目概述:ClawX,为OpenClaw AI Agent打造的桌面门户如果你和我一样,对AI Agent(智能体)的潜力感到兴奋,但又对在终端里敲命令、编辑YAML配置文件、管理进程这些繁琐操作感到头疼,那么ClawX的…...

支付钱包启动器:架构设计与工程实践全解析
1. 项目概述:一个面向开发者的支付钱包启动器 最近在和一些做独立开发的朋友聊天,发现大家在做项目时,但凡涉及到支付、钱包这类功能,都挺头疼的。不是对接流程繁琐,就是安全风险高,要么就是代码耦合度太强…...

AI绘画工作流自动化:从NovelAI到Pixiv的Semi-Auto工具实战
1. 项目概述:从手动到自动,解放AI绘画生产力的桌面利器如果你和我一样,是个深度沉迷于AI绘画的创作者,那你一定经历过这样的痛苦:在NovelAI的WebUI里,吭哧吭哧地调好一组参数,生成一张图&#x…...

3步快速部署GitHub中文化插件:告别英文界面的烦恼
3步快速部署GitHub中文化插件:告别英文界面的烦恼 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经因为GitHub的…...

备战蓝桥杯国赛【Day 8】
例题 1:数字统计(蓝桥杯基础题)项目内容类型暴力枚举 / 数学核心遍历区间,统计数字出现次数题目描述 统计范围 [L, R] 的所有整数中,数字 2 出现的次数。 输入格式 L R输出格式 数字 2 出现的次数。 题解 直接遍历每个…...

上午题_结构化开发
耦合基础知识...

视频技术演进:从模拟到数字的革命与压缩技术解析
1. 视频技术演进:从模拟到数字的革命上世纪30年代末,当第一套视频标准在美国诞生时,谁也没想到这个被称为RS-170的技术会成为现代视频技术的基石。作为最早的模拟视频标准,RS-170定义了525线(其中480线为有效视频内容&…...

基于Godot引擎的模块化RTS游戏框架开发实战指南
1. 项目概述:当开放世界RTS遇上Godot引擎如果你和我一样,是个对即时战略游戏(RTS)有情怀,同时又对Godot引擎的轻量与高效念念不忘的开发者,那么看到“lampe-games/godot-open-rts”这个项目标题时ÿ…...