Hum Brain Mapp:用于功能连接体指纹识别和认知状态解码的高精度机器学习技术
摘要
人脑是一个复杂的网络,由功能和解剖上相互连接的脑区组成。越来越多的研究表明,对脑网络的实证估计可能有助于发现疾病和认知状态的生物标志物。然而,实现这一目标的先决条件是脑网络还必须是个体的可靠标记。在这里,本研究利用人类连接组项目数据,考察了被试的大脑指纹和认知状态。本研究的方法在识别fMRI扫描被试和对先前未见过的被试的认知状态进行分类方面实现了高达99%的准确率。更广泛地说,本研究使用大量被试(865名)在不同认知状态(8种)下的fMRI功能连接数据,探索了五种不同机器学习技术在个体指纹识别和认知状态解码目标上的准确性和可靠性。此外,本研究还比较了16种不同的功能连接体(FC)矩阵构建流程,以表征FC生成的不同方面对个体和任务分类准确性的影响,并确定可能存在的混淆因素。
前言
功能连接是一种衡量不同脑区活动之间的统计依赖性指标。实际上,它作为一种相关性度量,通常在所谓的“静息状态”下进行估计,也就是说,在没有明确任务指令的情况下进行估计。所有神经元素之间的全功能连接集定义了一个功能性脑网络,可以将其建模为节点(脑区)和边(功能连接权重)。大量研究表明,连接权重的变化可用于准确地预测个体的认知、临床和发育状态。
近年来,人们对基于网络的“指纹识别”产生了浓厚的兴趣。也就是说,使用统计分析来发现功能性大脑网络的特征,这些特征能够可靠地区分个体。先前的研究表明,功能连接体(FC)可以在fMRI扫描中提供一致的个体指纹,并以可识别的方式编码一般认知状态的各个方面。然而,目前仍存在一些关键的方法学问题。例如,大多数研究没有直接评估不同指纹识别算法的相对性能,也没有详尽地探讨FC矩阵构建流程对指纹识别的影响。
因此,本研究利用人类连接组项目(HCP)数据集的FCs,探索了五种不同机器学习技术在个体指纹识别和认知状态解码目标上的准确性和可靠性。此外,为了表征FC生成的不同方面对个体和任务分类准确性的影响,并识别可能存在的混淆因素,本研究还比较了16种不同的功能连接体(FC)矩阵构建流程。
实验结果表明,一些机器学习技术在对HCP数据集中的FCs进行个体指纹识别和任务解码方面具有近乎完美的能力,为FCs揭示了个体及其认知状态的重要特征这一观点提供了支持,并为未来的技术测量提供了基准。这些高精度分类器的另一个好处是能够识别FC的特征,以及大脑哪些区域之间的哪些连接是进一步研究认知状态的感兴趣区域。
方法
数据描述和分类目标
数据集:原始数据集由HCP发布的865名受试者的fMRI扫描数据组成。每名受试者在7项活动任务(情绪、赌博、语言、运动、关系、社会、工作记忆)中的每项都扫描2次,静息态任务(休息)扫描4次,共扫描18次。为了消除因休息扫描次数过多而造成的数据不平衡的影响,实验期间每位受试者仅使用2次休息扫描,共计每位受试者有16次扫描。数据集中不包含任何个人身份信息。此外,通过流程从个体fMRI扫描数据中生成功能连接矩阵,该流程包括脑区分割、混淆回归以及从fMRI时间序列框架中计算相关系数矩阵。
HCP功能预处理:HCP数据集中的图像进行了最小程度的预处理。简而言之,对每个图像的梯度失真和运动进行了校正,并通过样条插值步骤与相应的T1加权(T1w)图像对齐。进一步校正强度偏差,归一化为均值10000,投射到32k_fs_LR网格,排除异常值,并使用多模态表面配准对齐到公共空间。
分割预处理:设计一个由大脑皮层上200个区域组成的分区,以优化fMRI信号的局部梯度和全局相似性指标(Schaefer200)。将分割节点映射到Yeo典型功能网络。对于HCP数据集,Schaefer200是32k_fs_LR空间中的CIFTI文件。这些工具利用在recon-all管道中计算的表面配准,根据个体表面曲率和沟纹模式将组平均图谱转换到被试空间。这种方法为每个被试呈现了一个T1w空间体积。将分割重新采样到2mm T1w空间,以便与功能数据一起使用。相同的过程也可用于其他分辨率(例如Schaefer100)。
功能网络预处理:使用Nilearn的signal.clean对所有BOLD图像进行线性去趋势、带通滤波(0.008~0.08Hz)、混淆回归和标准化处理,去除与时间过滤器正交的混淆。所采用的混淆回归已被证明是减少运动相关伪影的一个相对有效的选择。经过预处理和扰动回归,得到各节点BOLD时间序列的残差均值。
分类目标:在每个实验中,训练一个机器学习分类器以完成以下两个目标之一:受试者识别(指纹识别)或任务识别(解码)。
(1)指纹识别。为了实现这一目标,分类器同时对所有受试者的扫描进行训练,每个受试者完成七项任务,共14次扫描。对于每个受试者,从八项任务(包含静息态任务)中随机选择一项,并保留该任务的两次扫描作为验证数据集。受试者指纹分类器的准确性是使用训练好的分类器正确预测受试者的验证扫描的百分比。
(2)任务解码。对于任务解码目标,分类器在来自受试者子集的扫描上进行训练,涉及八个任务,每个受试者总共扫描16次。验证数据集由所有任务中其余子集的扫描组成。任务解码分类器的准确性是使用训练好的分类器正确预测其任务的验证扫描的百分比。
分类器架构
针对两个目标测试了五种分类器架构:
1、根据Howland和Park(2004)提出的基于广义奇异值分解的LDA分类器,它避免了对维数远低于样本数量的需求。对于每个类别,LDA分类器的结果为输入向量提供了一组线性系数,可用于得出有关输入分量对于特定类别的相对重要性的结论(并生成可视化)。
2、多层感知器神经网络(NN)分类器,其训练可以建模高阶函数。
3、支持向量机(SVM)分类器,一种使用高维数据进行分类的常见机器学习方法。近年来,许多关于人脑功能连接组学的研究都将SVM作为预测工具。
4、最近质心(NC)分类器,其结果可用于对类之间的高维空间关系进行简单推断。
5、基于相关性(CORR)的分类器,这是在FCs上进行受试者指纹识别的经典方法,已知可以在类似的数据集上获得较高的准确率。
FC矩阵构建流程
在这里,本研究考虑了经过测试的四个矩阵构建流程变量,以确定结果对数据准备差异的稳健性,其中包括:
①有无全局信号回归:通过线性回归去除fMRI时间序列的平均信号强度。
②有无任务回归:去除任务诱发激活的一阶效应。
③Schaefer-Yeo 100与200分区:大脑图谱中产生FCs的区域数量。
④截断剩余扫描时间序列帧,以与较短的任务扫描长度保持一致。
整个流程如图1所示。

图1.功能连接体准备步骤的流程图。
结果
分类器精度
LDA分类器
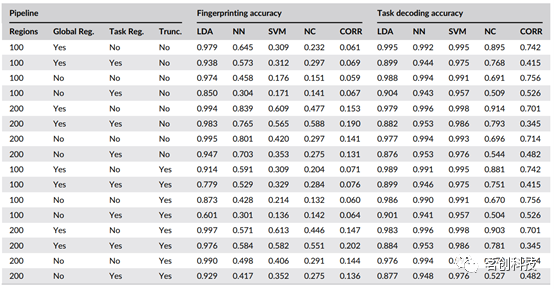
LDA分类器在两个目标和大多数矩阵构建流程中都获得了较高的准确率(见表1)。总体而言,它似乎比NN分类器对矩阵构建流程变化的影响更敏感。
表1.所有分类器架构和所有流程的验证精度得分。
从LDA分类器获得的系数(图3)通过对分类的输入特征重要性进行相对加权,为类区分的方法提供了一些验证。将输入特征映射到已知的大脑系统标签,可用于验证分类器是否“注意”与特定类别任务关联的脑区特征。
前馈神经网络(NN)分类器
表1还显示,在任务解码目标上,NN分类器比LDA分类器实现了更高和更一致的精度。然而,NN分类器在受试者指纹识别目标上的表现明显更差,这可以通过更好地选择NN超参数(更大或更多的隐藏层,不同的学习率,不同的激活函数等)、通过选择另一种NN架构或使用更大的数据集进行训练来改善。
例如,Wang等人(2019)使用DNN架构在七个任务中的类似任务解码目标上能够达到94%的准确率。他们的DNN是基于原始fMRI数据作为输入的卷积。本研究的简单三层神经网络能够在FCs输入维数显著降低的情况下获得更好的精度,这表明这种深度神经网络对于稳健的结果可能不是必要的。此外,虽然Wang等人的结果发现使用DNN的某些任务比其他任务更容易解码,但本研究的NN分类器在不同任务之间的分类精度基本上没有差异。
支持向量机(SVM)分类器
与LDA分类器和NN分类器相比,SVM分类器在任务解码目标上实现了所有架构中最高且最一致的精度分数(见图2),其结果比LDA分类器和NN分类器对矩阵构建流程的变化更稳健。
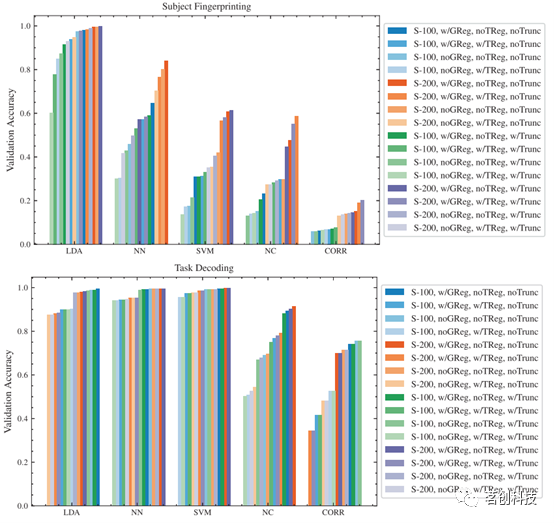
图2.受试者指纹分类器和任务解码分类器的验证精度分数比较。
在受试者指纹识别目标上,SVM分类器的精度明显低于LDA和NN分类器,并且对矩阵构建流程表现出显著的敏感性。
NC分类器
NC分类器在目标和所有矩阵构建流程上的性能都相对较差;然而,它仍然达到了足够高的精度水平,可以得出一些关于数据集性质的结论。在任务解码方面,一些矩阵构建流程的精度高达90%。鉴于NC分类器中两个连接组之间的相似性度量为L2范数,具有相对较高精度的结果表明该数据集在高维空间中表现出类的聚类特性。相对于其他分类器,NC分类器在个体指纹识别上的结果同样不理想;然而,能够在大约一半的时间内正确识别出865名受试者(仅使用L2范数),再次表明与个体受试者相关的扫描具有相对较强的空间聚类。
相关分类器
Finn等人(2015)通过计算目标扫描和测试矩阵数据库之间的Pearson相关系数,获得了较高的个体识别准确性。它们使用Shen 268个节点的功能分区,对来自HCP数据集中的126名受试者进行了测试,受试者识别目标限定在单一任务扫描的测试数据库。只有当目标矩阵和测试矩阵数据库均来自休息任务时(即rest→rest),才能达到最高准确率(93%),而其他任务组合的准确率较低(例如rest→other)。此外,他们指出识别准确性对分割的选择很敏感。例如,当使用68个节点的FreeSurfer-Yeo图谱时,他们在rest→rest受试者识别上达到了89%的准确率。为了重现他们的结果,使用来自本研究数据集的126名随机受试者,使用200个节点的Schaefer-Yeo图谱,在基于相关性的识别rest→rest扫描方面获得的最高准确率为81%。最后,为了充分比较CORR分类器与LDA分类器的结果,将该技术推广到本研究的完整数据集和与任务无关的识别。使用779名受试者和rest→rest任务目标,准确率降至73%。使用779名受试者和any→all任务目标,最高准确率降至20%(图1)。
LDA特征对认知状态解码的重要性
下列可视化图像(见图3)显示了个体连接组特征与特定认知状态之间的相关性,作为从LDA分类器获得的系数的函数。
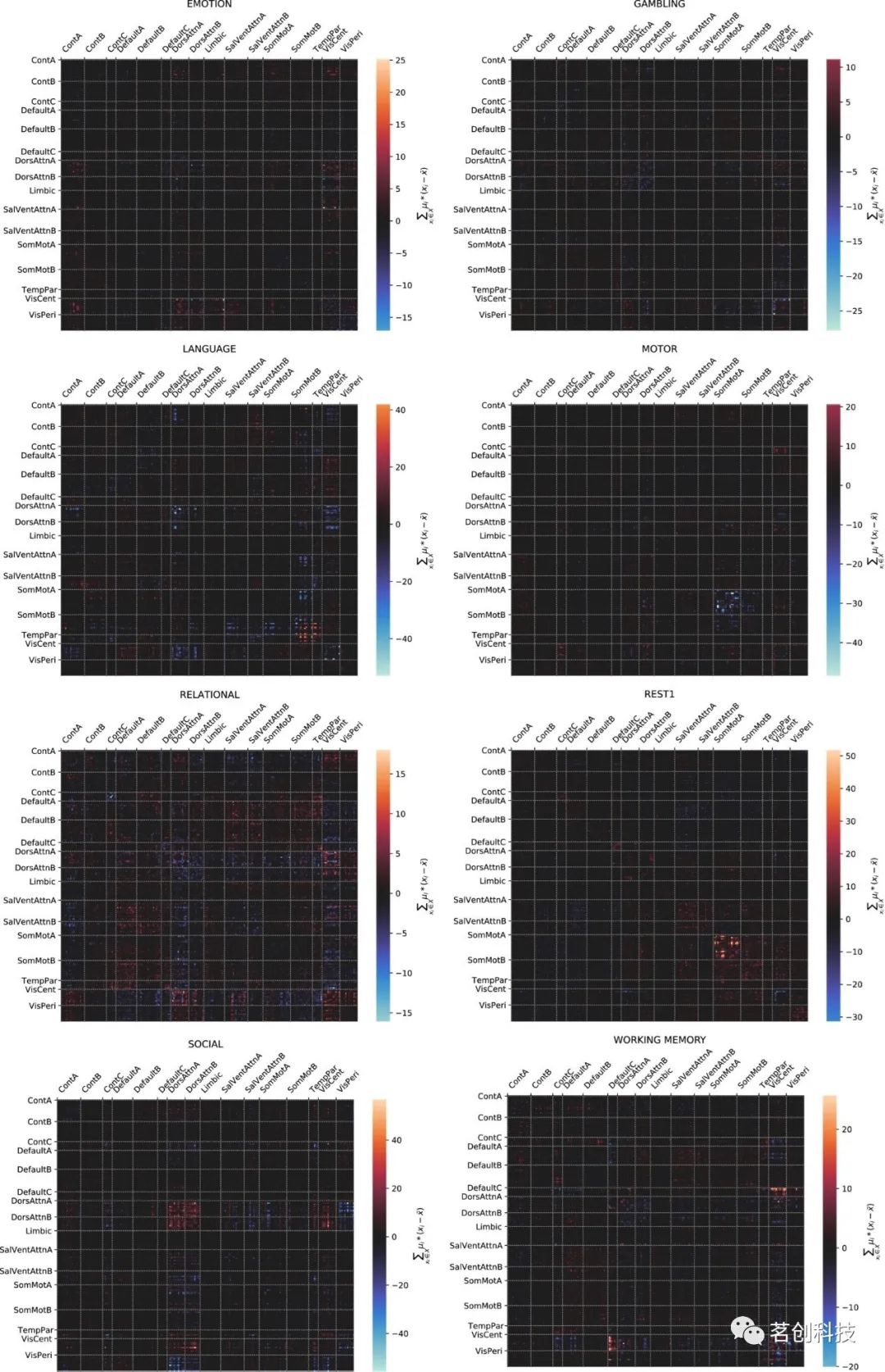
图3.可视化热图。
训练/验证分割对LDA分类器的影响
LDA分类器的精度对于训练集中合理减少的扫描次数似乎具有稳健性(见图4)。然而,任务解码分类器在仅对五名受试者(共80次扫描)进行训练后保持近80%的精度,而指纹分类器要达到约80%的类似精度需要至少两个任务的训练集(3460次扫描)。
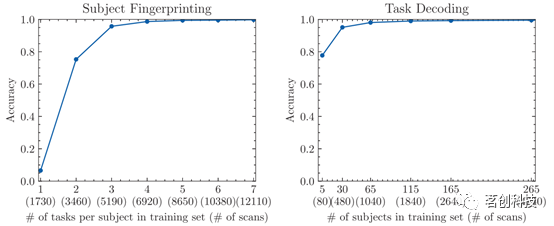
图4.训练/验证分割对LDA分类器精度的影响。
模块化和中心性
最近,人们对FC研究中纯图论指标的性能产生了浓厚的兴趣。作为比较,本研究考察了使用模块化和中心性指标(而不是连接组边权重)作为两项任务中性能最佳分类器架构的输入。从200个区域中,使用Louvain社区检测和不对称的负权重参数来计算社区结构。从该社区中,计算每个脑区的参与系数,并将正、负参与系数连接作为LDA或NN分类器的输入(n=400个特征)。图5显示了参与系数法和边权重法之间的比较。在个体指纹识别和任务分类目标中,使用连接体边权重作为输入比参与系数具有更好的准确率。
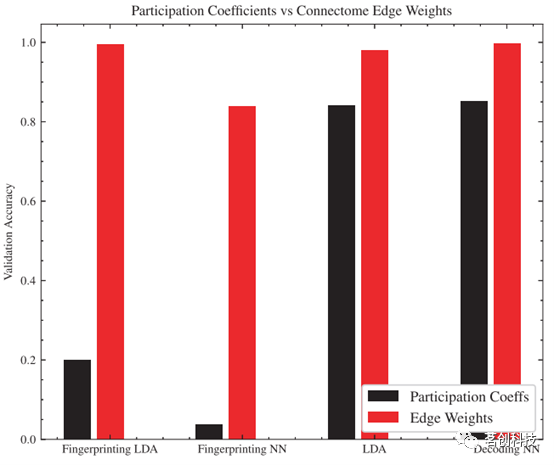
图5.比较LDA和NN在使用脑区参与系数vs连接体边权重作为输入时的分类精度。
FC矩阵构建流程
全局信号回归(GSR)
静息态功能连接MRI研究数量快速增长,数据处理的方法也在不断增加。其中一种处理方法是GSR,虽然有时存在争议,但它也有几个既定的好处。对于所有受试者,GSR的准确率分数要么非常类似于没有GSR的流线,要么分数略高,但有一个例外:在任务解码目标的NN分类器上,GSR的分数总体上明显更高(见图6)。
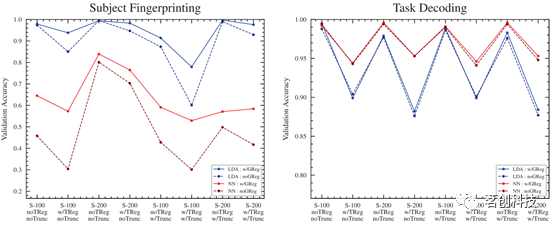
图6.有与没有全局信号回归。
分割大小
100个区域和200个区域的分割产生了相似的精度分数,100-区域在所有流程和架构中的精度分数略低,但有一个例外:对于任务解码目标的LDA分类器,100-区域的分割在所有流程中的精度略高(图7)。除此之外,由于200分区实际上包含了100分区作为其特征的“子集”,因此精度的略微下降并不奇怪。
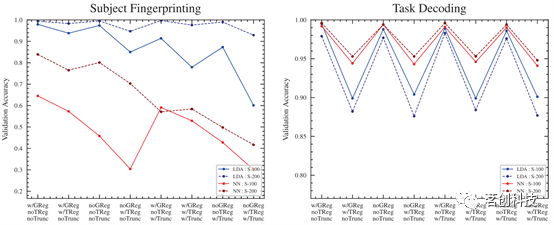
图7.100个区域与200个区域的分割。
时间序列截断
截断是一个重要的步骤,一般来说,较短的样本会导致连通性估计中的采样误差越大。为了确保样本数量具有可比性,本研究测试了时间序列的截断,以在所有样本中保持大致相同的帧数。总体而言,截断其余扫描时间序列以匹配任务扫描似乎会导致所有流程和分类器架构的精度略有下降(图8)。与200分区相比,100分区的不利影响要明显得多。
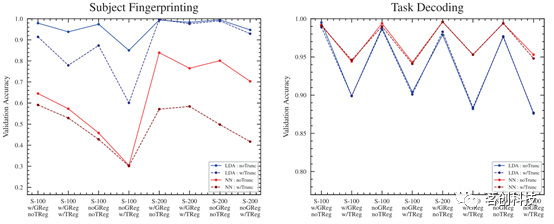
图8.使用与不使用时间序列截断。
任务回归
在所有测试中,使用任务回归的流程比不使用任务回归的流程分类精度更差(图9)。在任务分类目标中,回归旨在消除与每项任务相关但不是真正测量脑区活动的混淆因素。这些特定于任务的混淆的存在可能使任务区分更加容易,而去除它们可能会使任务解码变得更加困难。
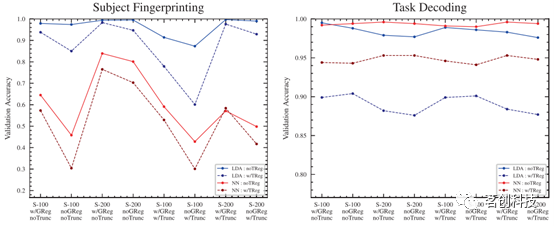
图9.有与没有任务回归。
特征选择
本研究考察了三种特征选择方法,以识别FC的边缘:
方差阈值:无监督方法,其中整个数据集中给定特征的方差用作其判别能力的度量,最重要的特征被认为是那些具有最高方差的特征。
SPEC:无监督方法,使用图谱分析来识别对维持数据集的空间聚类属性最重要的特征。
LDA系数:有监督方法,将一个给定特征在所有类别中的系数均值作为其判别能力的度量,最重要的特征被认为是那些系数均值最大的特征。
这三种特征选择方法都对输入特征进行了简单的优先级排序,除了确定要保留多少个“最重要”特征的阈值外,没有其他参数。将每种方法应用于整个数据集,然后使用最高精度矩阵构建流程(200个区域,w/GReg,noTReg)来测试特征缩减的FCs的准确性。特征选择实验的结果表明(图10),仅使用原始19900个特征(在200分区的情况下)中的几百个特征(即连接组的边),就可以在指纹识别和解码目标中保持高精度性能。
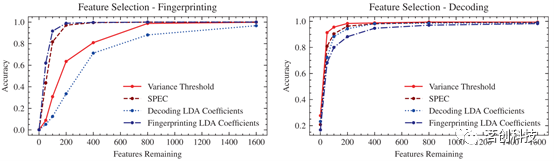
图10.使用四种特征选择方法选择的特征子集,在指纹或解码目标上训练LDA分类器的精度(200个区域,w/GReg,noTReg)。
特别是,对于任何单个特征选择方法,从SPEC中获得的特征排序似乎在指纹识别和解码目标之间提供了高精度的最佳平衡——仅用~200个特征就达到了90%的精度。
与从SPEC获得的最高排序特征相关的大脑系统(图11)似乎在某种程度上平衡了方差阈值(DorsAttnA、DorsAttnB、VisCent、VisPeri)的最高排序特征,方差阈值对解码具有最佳的整体性能,而LDA指纹识别系数(ContA、ContB、DefaultA、DefaultB)具有最佳的指纹识别整体性能。
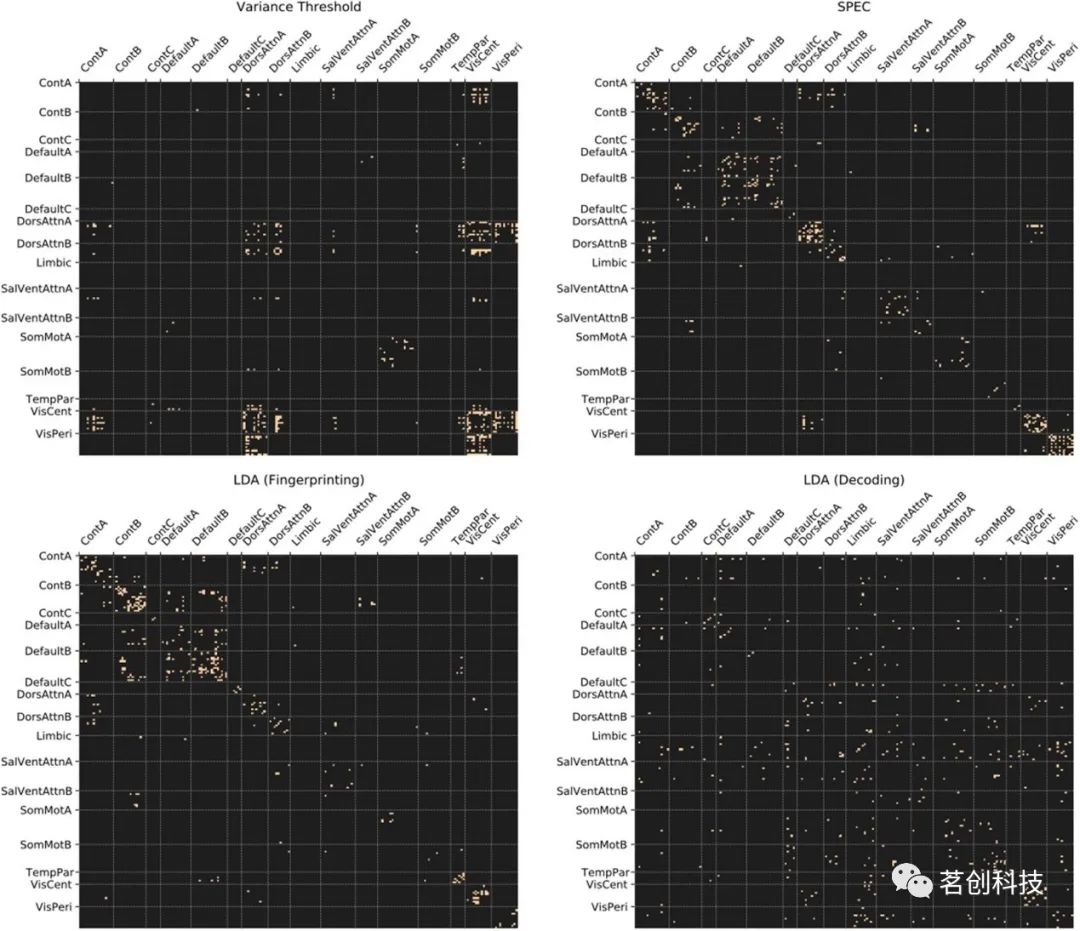
图11.使用每种特征选择方法选择的前200个最重要的连接体边,按大脑系统排序。
高维聚类
作为评估类别(单个受试者或任务)在高维空间中表现出聚类程度的另一种方法,本研究对数据集执行了PCA,将其降至50维,然后使用t-SNE进行二维可视化(图12)。
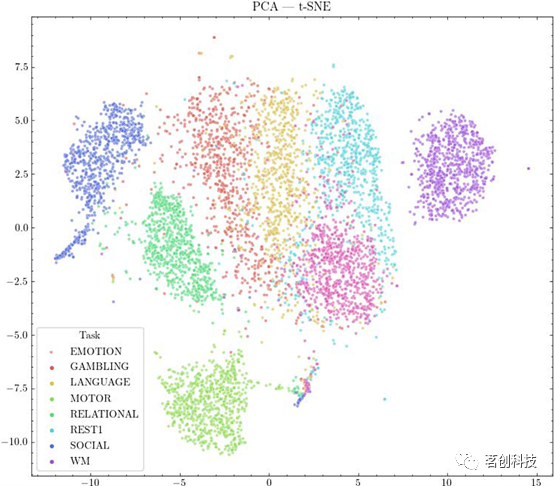
图12.利用PCA和t-SNE进行降维,以实现认知状态高维聚类的可视化。
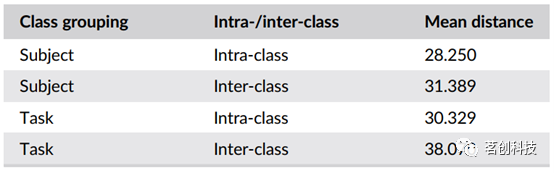
本研究还计算了所有样本对的平均类内(组内)和类间(组间)距离,扫描按受试者或任务分组,作为聚类的简单度量(表2)。结果表明,按任务或受试者分组扫描的平均类内距离小于类间距离。
表2.受试者和任务的平均类内和类间距离的度量。
结论
本研究结果表明,一些机器学习技术和矩阵构建流程可以从FCs实现高精度的个体指纹识别和任务解码。在大量受试者中进行个体指纹识别时,LDA分类器提供了最高和最一致的精度分数。在任务解码中,LDA、NN和SVM分类器的性能相似,但SVM在所有流程中略有优势。与较高的分类精度分数最一致的流程是:更精细的分区(更多的脑区)、使用GSR、无任务回归以及不使用时间序列截断。在未来的应用中,当决定使用哪种矩阵构建流程时,需要注意的是,虽然更精细的分区(更多的脑区)似乎能够提高精度,但给定扫描的特征数量会随着区域数量的平方而增加。这意味着更精细的分区虽然提高了精度,但可能会使分类器的训练成本显著增加。这里实现的高精度得益于HCP数据集,该数据集具有较高的一致性标准。未来的工作应该研究这些结果是否对来自其他数据集的扫描数据具有稳健性。
参考文献:Andrew Hannum, Mario A. Lopez. et al. High-accuracy machine learning techniques for functional connectome fingerprinting and cognitive state decoding. Hum Brain Mapp.2023;1-15.
相关文章:
Hum Brain Mapp:用于功能连接体指纹识别和认知状态解码的高精度机器学习技术
摘要 人脑是一个复杂的网络,由功能和解剖上相互连接的脑区组成。越来越多的研究表明,对脑网络的实证估计可能有助于发现疾病和认知状态的生物标志物。然而,实现这一目标的先决条件是脑网络还必须是个体的可靠标记。在这里,本研究…...

Ajax图书管理业务
图书管理业务 Ajax图书管理业务 需求: 对服务器的图书数据进行 增、删、改、查。功能的实现,同时实时动态的渲染刷新页面内容 根据功能模块分为四个业务模块,下面有各个业务的实现步骤 01_ 渲染图书列表业务 * 目标1:渲染图书列表 * 1.1 获…...

对于爬虫代码的优化,多个方向
对于优化爬虫,有许多可能的方法,这取决于你的具体需求和目标。以下是一些常见的优化策略: 1. **并发请求**:你可以使用多线程或异步IO来同时发送多个请求,这可以显著提高爬虫的速度。Python的concurrent.futures库或a…...

ffmpeg推流卡顿修复
1、使用命令如下: $"ffmpeg -i {this.IpAddress} -f flv {PushAddress}" 2、参考文章: ffmpeg 编码如何做带宽控制输出_ffmpeg bufsize_qianbo_insist的博客-CSDN博客...
Java02-迭代器,数据结构,List,Set ,TreeSet集合,Collections工具类
目录 什么是遍历? 一、Collection集合的遍历方式 1.迭代器遍历 方法 流程 案例 2. foreach(增强for循环)遍历 案例 3.Lamdba表达式遍历 案例 二、数据结构 数据结构介绍 常见数据结构 栈(Stack) 队列&a…...
离散 Hopfield 神经网络的分类与matlab实现
1 案例背景 1.1离散 Hopfield 神经网络学习规则 离散型 Hopfield神经网络的结构、工作方式,稳定性等问题在第9章中已经进行了详细的介绍,此处不再赘述。本节将详细介绍离散Hopfield神经网络权系数矩阵的设计方法。设计权系数矩阵的目的是: ①保证系统在异步工作时的稳…...
opencv 30 -图像平滑处理01-均值滤波 cv2.blur()
什么是图像平滑处理? 图像平滑处理(Image Smoothing)是一种图像处理技术,旨在减少图像中的噪声、去除细节并平滑图像的过渡部分。这种处理常用于预处理图像,以便在后续图像处理任务中获得更好的结果。 常用的图像平滑处理方法包括…...

中小企业的数字化营销应该如何着手?数字化营销到底要怎么做?
从侠义角度讲,数字化营销就是在数字化的媒体上做营销。传播本质上是一种营销的形式 从广义角度讲,我们不仅可以将营销数字化,也可以数字化很多事物,甚至行业,比如数字化制造业、数字化工厂、数字化商会等等 而这个…...
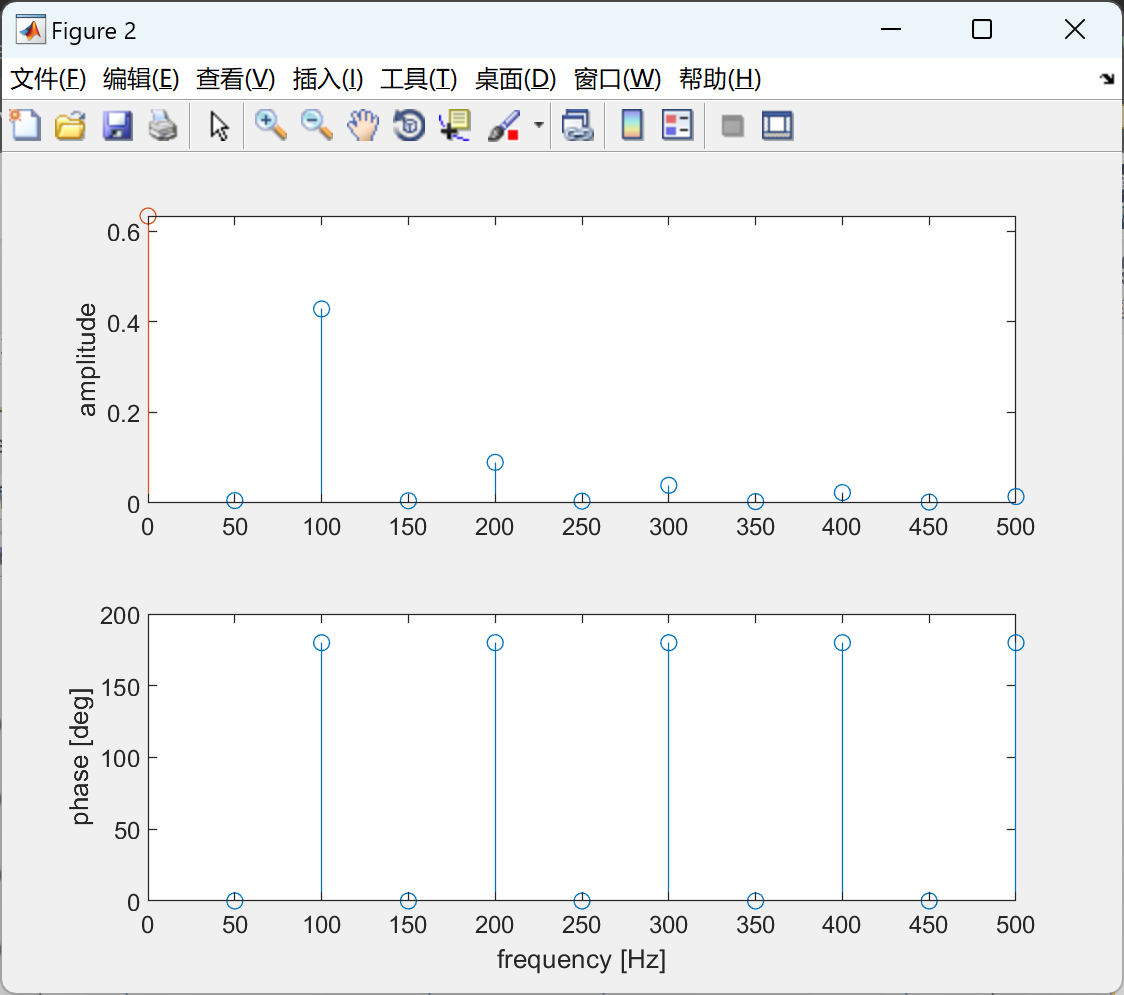
实数信号的傅里叶级数研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

oracle数据库巡检脚本
用于Oracle数据库巡检的示例脚本: #!/bin/bash# 设置数据库连接信息 DB_USER="your_db_username" DB_PASSWORD="your_db_password" DB_HOST="your_db_host" DB_PORT="your_db_port" DB_SID="your_db_sid" OUTPUT_FILE=&q…...
服务注册中心consul的服务健康监控及告警
一、背景 consul既可以作为服务注册中心,也可以作为分布式配置中心。当它作为服务注册中心的时候,java微服务之间的调用,会定期查询服务的实例列表,并且实例的状态是健康可用。 如果发现被调用的服务,注册到consul的…...

【算法第十四天7.28】二叉树的最大深度,二叉树的最小深度 ,完全二叉树的节点个数
链接力扣104-二叉树的最大深度 思路 class Solution {public int maxDepth(TreeNode root) {if(root null) return 0;if(root.left null) return maxDepth(root.right) 1;if(root.right null) return maxDepth(root.left) 1;int max Math.max(maxDepth(root.left),maxD…...

网络安全设备-等保一体机
本文为作者学习文章,按作者习惯写成,如有错误或需要追加内容请留言(不喜勿喷) 本文为追加文章,后期慢慢追加 等保一体机的功能 等保一体机产品主要依赖于其丰富的安全网元(安全网元包括:防火…...

Kafka的配置和使用
目录 1.服务器用docker安装kafka 2.springboot集成kafka实现生产者和消费者 1.服务器用docker安装kafka ①、安装docker(docker类似于linux的软件商店,下载所有应用都能从docker去下载) a、自动安装 curl -fsSL https://get.docker.com | b…...

【C++】unordered_map在Windows和Linux上的不同行为
我目前手头上的项目,需要编译在板端Linux上运行,但是日常daily调试多在Windows上开发。这就涉及到同一份代码在多平台上的编译个运行。有一次遇到了一个奇怪的现象:跑同样的一份代码,Windows和Linux出来的结果是不一致的。最终确定…...
Apipost三方消息通知,接口变更不用愁
Apipost致力于为开发者提供更全面的API管理功能。而最近,Apipost又新增了一个非常实用的功能:第三方消息推送。这个功能可以帮助开发人员及时了解API的变更情况,从而更好地管理和优化自己的API。 具体来说,Apipost的第三方消息推…...
C语言 用数组名作函数参数
当用数组名作函数参数时,如果形参数组中各元素的值发生变化,实参数组元素的值随之变化。 1.数组元素做实参的情况: 如果已经定义一个函数,其原型为 void swap(int x,int y);假设函数的作用是将两个形参(x,y…...
-回溯)
每日一题(980. 不同路径 III)-回溯
题目 980. 不同路径 III 题解思路 表格中值为1的为起始点值为0 的是可以经过的点,但是只能经过一次值为2 的是终点,计算从起点到终点一共有多少种路径 计算出值为0的方格个数,同时找到起点位置当位于终点时候且经过所有的方格为0的点 即为…...
, loads(), dump(), dumps())
【Python:json常用函数,用于加载和保存json文件】load(), loads(), dump(), dumps()
文章目录 1、load()2、loads()3、dump()4、dumps() json文件为javascript object Notation文件,属于轻量级的数据交换格式,可以用于存储和交换数据。json文件是由类似{ }的key-value映射组成。 1、load() 把json文件加载为Python的数据格式,…...

Flink State 和 Fault Tolerance详解
有状态操作或者操作算子在处理DataStream的元素或者事件的时候需要存储计算的中间状态,这就使得状态在整个Flink的精细化计算中有着非常重要的地位: 记录数据从某一个过去时间点到当前时间的状态信息。以每分钟/小时/天汇总事件时,状态将保留…...

如何通过开源硬件控制方案优化Dell游戏本散热性能
如何通过开源硬件控制方案优化Dell游戏本散热性能 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 在追求极致游戏体验的过程中,散热性能往往成为制…...

StructBERT-中文-large部署指南:开源镜像免配置运行详解
StructBERT-中文-large部署指南:开源镜像免配置运行详解 1. 快速了解StructBERT文本相似度模型 StructBERT中文文本相似度模型是一个专门用于中文文本相似度计算的高性能模型。这个模型基于structbert-large-chinese预训练模型,经过大规模中文相似度数…...

别再只盯着代码行数了!用Tessy实测圈复杂度,教你一眼看穿函数有多“绕”
别再只盯着代码行数了!用Tessy实测圈复杂度,教你一眼看穿函数有多“绕” 在代码评审会上,你是否遇到过这样的场景:有人指着一段200行的函数说"太长了需要拆分",而另一段50行的嵌套逻辑却被所有人忽略&#x…...

猫抓工具终极指南:如何快速捕获网页视频和音频资源
猫抓工具终极指南:如何快速捕获网页视频和音频资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为无法下载网页上的视频和音频而…...

FastAPI子应用挂载:别再让root_path坑你一夜久
Julia(julialang.org)由Stefan Karpinski、Jeff Bezanson等在2009年创建,目标是融合Python的易用性、C的高性能、R的统计能力、Matlab的科学计算生态。 其核心设计哲学是: 高性能:编译型语言(JIT࿰…...

Nucleus Co-Op:重新定义单机游戏的多人同屏革命
Nucleus Co-Op:重新定义单机游戏的多人同屏革命 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 想象一下这样的场景:你和朋…...

暗黑破坏神2存档编辑器:5分钟打造你的完美角色
暗黑破坏神2存档编辑器:5分钟打造你的完美角色 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为刷不到心仪的装备而烦恼吗?还在为角色build不够完美而反复重练吗?d2s-editor为你提供了一…...

ollama部署本地大模型|granite-4.0-h-350m在在线教育平台智能答疑中的应用
ollama部署本地大模型|granite-4.0-h-350m在在线教育平台智能答疑中的应用 1. 在线教育答疑的痛点与解决方案 在线教育平台最头疼的问题之一,就是学生随时提出的各种问题。传统的人工答疑方式存在明显瓶颈:老师回复不及时、夜间无人值守、重…...
工作原理系列(一))
AI智能体视觉检测系统(TVA)工作原理系列(一)
TVA初探——核心概念与应用场景解析作为企业初级技术人员,在接触AI智能体视觉检测系统(TVA)时,首先需要明确其核心定位、与传统机器视觉的区别,以及在工业场景中的实际应用价值。TVA全称为“Transformer-based Vision …...
)
从RTL到ATPG:手把手带你走一遍Tessent Shell的Flat Design DFT完整流程(含避坑点)
从RTL到ATPG:Tessent Shell Flat Design DFT全流程实战指南 在芯片设计领域,测试设计(DFT)正变得越来越关键。随着工艺节点不断演进,芯片复杂度呈指数级增长,传统的人工测试方法已无法满足现代SoC的测试需求。Mentor Graphics&…...