pytorch学习——正则化技术——权重衰减
一、概念介绍
权重衰减(Weight Decay)是一种常用的正则化技术,它通过在损失函数中添加一个惩罚项来限制模型的复杂度,从而防止过拟合。
在训练参数化机器学习模型时, 权重衰减(weight decay)是最广泛使用的正则化的技术之一, 它通常也被称为L2正则化。
1.1理解:
权重衰减(weight_decay)本质上是一个L2正则化系数
那什么是参数的正则化?从我的理解上,就是让参数限定在一定范围,目的是为了不让模型对训练集过拟合。
注:应对过拟合最好的方法还是扩大有效样本(但成本过高)
1.2如何控制模型容量?
1.将模型变得比较小,减少里面参数的数量
2.缩小参数的取值范围
注:权重衰退就是通过限制参数的取值来实现
1.3硬性限制

即使得w的每个项的平方都小于θ这个值,最强情况下就是θ等于0,即所有w都等于0
1.4柔性限制

即损失函数后面加了一个非负项,为了使损失函数最小化,就得使得后面项足够小——起到限制w的作用,相比于硬性限制,柔性限制并没有将w的值限制在一个固定范围内。
1.5图解对最优解的影响


上式为不加限制条件的最优解,即图中的绿色中心点,但该点会使得||w||^2这一项较大,其和并不是最优解。
而加上限制的最优点即为图中两曲线的交叉点
1.6更新参数法则


1.7总结
~权重衰减是通过L2正则项使得模型参数不会过大,从而控制复杂度
~正则项权重是控制模型复杂度的超参数
二、示例演示
2.1模型构造
生成公式如下:

# 导入需要的库
import torch
from torch import nn
from d2l import torch as d2l# 定义训练和测试数据集的大小,输入特征的维度和批次大小
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5# 定义真实的权重true_w和偏差true_b,并将其初始化为0.01和0.05
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05# 使用d2l.synthetic_data函数生成训练数据train_data和测试数据test_data
# 生成的数据是通过真实的权重和偏差加上一些噪声生成的
train_data = d2l.synthetic_data(true_w, true_b, n_train)
test_data = d2l.synthetic_data(true_w, true_b, n_test)# 使用d2l.load_array函数将训练数据train_data和测试数据test_data
# 转换为数据迭代器train_iter和test_iter
train_iter = d2l.load_array(train_data, batch_size)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)2.2初始化模型参数
def init_params():w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)b = torch.zeros(1, requires_grad=True)return [w, b]
# 初始化模型参数w和b
# w的形状为(num_inputs, 1),从正态分布中随机生成
# b初始化为0
# 参数需要计算梯度,requires_grad参数被设置为True
# 返回一个包含w和b的列表2.3定义L2范数
def l2_penalty(w):return torch.sum(w.pow(2)) / 22.4定义训练代码实现
下面的代码将模型拟合训练数据集,并在测试数据集上进行评估。
函数的具体实现如下:
-
首先通过init_params()函数初始化模型参数w和b。
-
定义net函数为线性回归模型,loss为平方损失函数。
-
设置训练的轮数num_epochs和学习率lr,同时创建一个可视化工具animator,用于可视化训练过程中的损失值。
-
在每个epoch中,遍历训练数据集train_iter,对每个小批量数据(X, y)进行如下操作:
-
计算模型的输出net(X),并计算损失函数loss(net(X), y)。
-
加上L2范数惩罚项lambd * l2_penalty(w),其中l2_penalty(w)为权重w的L2范数。
-
对损失函数进行反向传播,并使用SGD来更新模型参数w和b。
-
-
每5个epoch,计算训练集和测试集上的损失值,并使用animator将损失值可视化。
-
训练结束后,输出模型参数w的L2范数。
# 带有L2正则化的线性回归训练过程
# lambd表示L2正则化的强度# 初始化模型参数w和b
w, b = init_params()# 定义线性回归模型net和平方损失函数loss
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss# 设置训练的轮数num_epochs和学习率lr
# 创建一个可视化工具animator,用于可视化训练过程中的损失值
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',xlim=[5, num_epochs], legend=['train', 'test'])# 在每个epoch中,遍历训练数据集train_iter,对每个小批量数据(X, y)进行如下操作:
for epoch in range(num_epochs):for X, y in train_iter:# 计算模型的输出net(X),并计算损失函数loss(net(X), y)# 加上L2范数惩罚项lambd * l2_penalty(w),其中l2_penalty(w)为权重w的L2范数# 对损失函数进行反向传播,并使用SGD来更新模型参数w和bl = loss(net(X), y) + lambd * l2_penalty(w)l.sum().backward()d2l.sgd([w, b], lr, batch_size)# 每5个epoch,计算训练集和测试集上的损失值,并使用animator将损失值可视化if (epoch + 1) % 5 == 0:animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),d2l.evaluate_loss(net, test_iter, loss)))# 训练结束后,输出模型参数w的L2范数
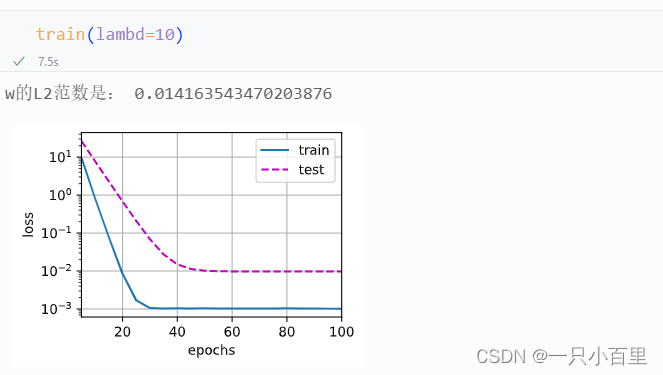
print('w的L2范数是:', torch.norm(w).item())2.5训练结果展示
在这段代码中,lambd是一个超参数,表示L2正则化的强度。在每个小批量数据的损失函数中,会加上L2范数惩罚项,以控制模型的复杂度和防止过拟合。L2正则化的强度由超参数lambd控制,lambd越大,模型的复杂度就越小,对训练数据的拟合程度就越差,但是可以更好地控制过拟合。反之,lambd越小,模型的复杂度就越大,对训练数据的拟合程度就越好,但是可能会过拟合。在模型训练过程中,我们通常会使用交叉验证等技术来选择最优的超参数lambd。
2.5.1忽略正则化直接训练
其中用lambd = 0禁用权重衰减后运行这个代码。 注意,虽然训练误差有了减少,但测试误差没有减少, 这意味着出现了严重的过拟合。

2.5.2使用权重衰减
下面,我们使用权重衰减来运行代码。 注意,在这里训练误差增大,但测试误差减小。 得到预期效果。
三.简洁实现代码
# 导入需要的库
import torch
from torch import nn
from d2l import torch as d2ldef train_concise(wd):# 定义训练和测试数据集的大小,输入特征的维度和批次大小n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5# 使用nn.Sequential定义了一个单层全连接神经网络net# 并将其参数使用param.data.normal_()方法初始化为随机值net = nn.Sequential(nn.Linear(num_inputs, 1))for param in net.parameters():param.data.normal_()# 使用nn.MSELoss定义平方损失函数loss# 该损失函数的reduction参数设置为'none',表示不对损失值进行降维loss = nn.MSELoss(reduction='none')# 设置训练的轮数num_epochs和学习率lr# 使用torch.optim.SGD定义一个优化器trainer,该优化器的参数包括网络的权重和偏差,以及权重衰减系数wdnum_epochs, lr = 100, 0.003trainer = torch.optim.SGD([{"params":net[0].weight,'weight_decay': wd},{"params":net[0].bias}], lr=lr)# 创建一个可视化工具animator,用于可视化训练过程中的损失值animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',xlim=[5, num_epochs], legend=['train', 'test'])# 在每个epoch中,遍历训练数据集train_iter,对每个小批量数据(X, y)进行如下操作:for epoch in range(num_epochs):for X, y in train_iter:# 将优化器trainer的梯度清零# 计算模型的输出net(X),并计算损失函数loss(net(X), y)# 对损失函数进行反向传播,并使用优化器trainer来更新模型参数trainer.zero_grad()l = loss(net(X), y)l.mean().backward()trainer.step()# 每5个epoch,计算训练集和测试集上的损失值,并使用animator将损失值可视化。if (epoch + 1) % 5 == 0:animator.add(epoch + 1,(d2l.evaluate_loss(net, train_iter, loss),d2l.evaluate_loss(net, test_iter, loss)))print('w的L2范数:', net[0].weight.norm().item())
train_concise(0) #lambd设置为0相关文章:
pytorch学习——正则化技术——权重衰减
一、概念介绍 权重衰减(Weight Decay)是一种常用的正则化技术,它通过在损失函数中添加一个惩罚项来限制模型的复杂度,从而防止过拟合。 在训练参数化机器学习模型时, 权重衰减(weight decay)是…...
iTOP-RK3588开发板Ubuntu 系统交叉编译 Qt 工程-命令行交叉编译
使用源码 rk3588_linux/buildroot/output/rockchip_rk3588/host/bin/qmake 交叉编译 QT 工程。 最后烧写编译好的 buildroot 镜像,将编译好的 QT 工程可执行程序在 buildroot 系统上运行。 交叉编译 QT 工程如下所示,首先进入 QLed 的工程目录下。 然后…...
Java进阶——数据结构与算法之哈希表与树的入门小结(四)
文章大纲 引言一、哈希表1、哈希表概述2、哈希表的基本设计思想3、JDK中的哈希表的设计思想概述 二、树1、树的概述2、树的特点3、树的相关术语4、树的存储结构4.1、双亲表示法4.2、孩子兄弟表示法:4.3、孩子表示法:4.4、双亲孩子表示法 三、二叉树1、二…...

DataFrame中按某字段分类并且取该分类随机数量的数据
最近有个需求,把某个df中的数据,按照特定字段分类,并且每个分类只取随机数量数据,这个随机数量需要有范围限制。写出来记录下。 def randomCutData(self, df, startNum):grouped df.groupby(classify_label)df_sampled pd.Data…...
【c++】rand()随机函数的应用(一)——rand()函数详解和实例
c语言中可以用rand()函数生成随机数,今天来探讨一下rand()函数的基本用法和实际应用。 本系列文章共分两讲,今天主要介绍一下伪随机数生成的原理,以及在伪随机数生成的基础上,生成随机数的技巧,下一讲主要介绍无重复随…...
iOS——Block回调
先跟着我实现最简单的 Block 回调传参的使用,如果你能举一反三,基本上可以满足了 OC 中的开发需求。已经实现的同学可以跳到下一节。 首先解释一下我们例子要实现什么功能(其实是烂大街又最形象的例子): 有两个视图控…...
)
html学习6(xhtml)
1、xhtml是以xml格式编写的html。 2、xhtml与html的文档结构区别: DOCTYPE是强制性的<html>、<head>、<title>、<body>也是强制性的<html>中xmlns属性是强制性的 3、 元素语法区别: xhtml元素必须正确嵌套xhtml元素必…...
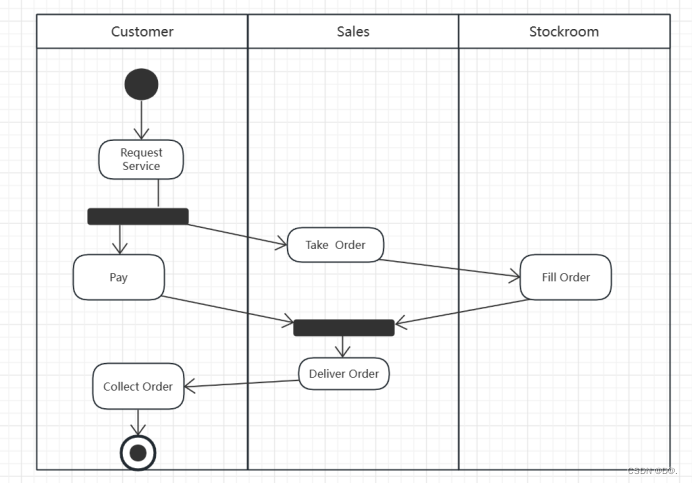
UML-活动图
目录 一.活动图概述: 1.活动图的作用: 2.以下场合不使用活动图: 3.活动图的基本要素: 4.活动图的图符 4.1起始状态 4.2终止状态 4.3状态迁移 4.4决策点 4.5同步条:表示活动之间的不同 5.活动图: 二.泳道: 1.泳道图&a…...

跨境电商怎么做?Live Market教你创业及做大生意
随着全球化的不断深入和互联网技术的迅猛发展,跨境电商成为了一个蓬勃发展的行业。根据eMarketer的数据,2021年全球跨境电商销售额将达到4.5万亿美元,预计到2025年将增长至6.3万亿美元。这表明,跨境电商行业将继续保持强劲增长的趋…...

Linux 4.19 和Linux 5.10 的区别
Linux 4.19和Linux 5.10是Linux内核的两个不同版本。它们之间有一些重要的区别,包括功能、性能和支持方面的改进。以下是一些常见的区别: 功能增强:Linux 5.10相对于4.19引入了许多新功能和增强。例如,Linux 5.10引入了BPF&#x…...
学习单片机的秘诀:实践与坚持
在学习单片机时,将实践与学习结合起来是一个很好的方法。不要一上来就死磕指令和名词,而是边学边做实验,循序渐进地理解和应用指令。通过实验,你能亲身感受到指令的控制效果,增强对单片机的理解和兴趣。 学习单片机不…...
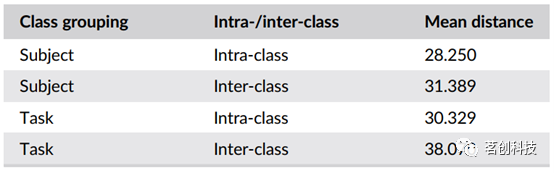
Hum Brain Mapp:用于功能连接体指纹识别和认知状态解码的高精度机器学习技术
摘要 人脑是一个复杂的网络,由功能和解剖上相互连接的脑区组成。越来越多的研究表明,对脑网络的实证估计可能有助于发现疾病和认知状态的生物标志物。然而,实现这一目标的先决条件是脑网络还必须是个体的可靠标记。在这里,本研究…...

Ajax图书管理业务
图书管理业务 Ajax图书管理业务 需求: 对服务器的图书数据进行 增、删、改、查。功能的实现,同时实时动态的渲染刷新页面内容 根据功能模块分为四个业务模块,下面有各个业务的实现步骤 01_ 渲染图书列表业务 * 目标1:渲染图书列表 * 1.1 获…...

对于爬虫代码的优化,多个方向
对于优化爬虫,有许多可能的方法,这取决于你的具体需求和目标。以下是一些常见的优化策略: 1. **并发请求**:你可以使用多线程或异步IO来同时发送多个请求,这可以显著提高爬虫的速度。Python的concurrent.futures库或a…...

ffmpeg推流卡顿修复
1、使用命令如下: $"ffmpeg -i {this.IpAddress} -f flv {PushAddress}" 2、参考文章: ffmpeg 编码如何做带宽控制输出_ffmpeg bufsize_qianbo_insist的博客-CSDN博客...
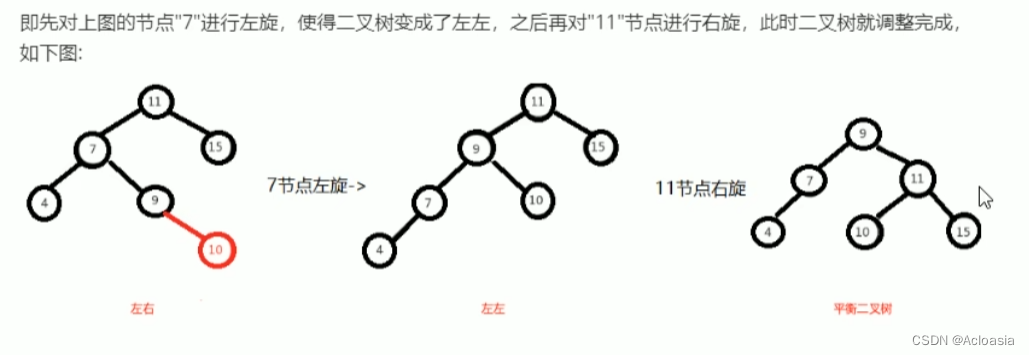
Java02-迭代器,数据结构,List,Set ,TreeSet集合,Collections工具类
目录 什么是遍历? 一、Collection集合的遍历方式 1.迭代器遍历 方法 流程 案例 2. foreach(增强for循环)遍历 案例 3.Lamdba表达式遍历 案例 二、数据结构 数据结构介绍 常见数据结构 栈(Stack) 队列&a…...
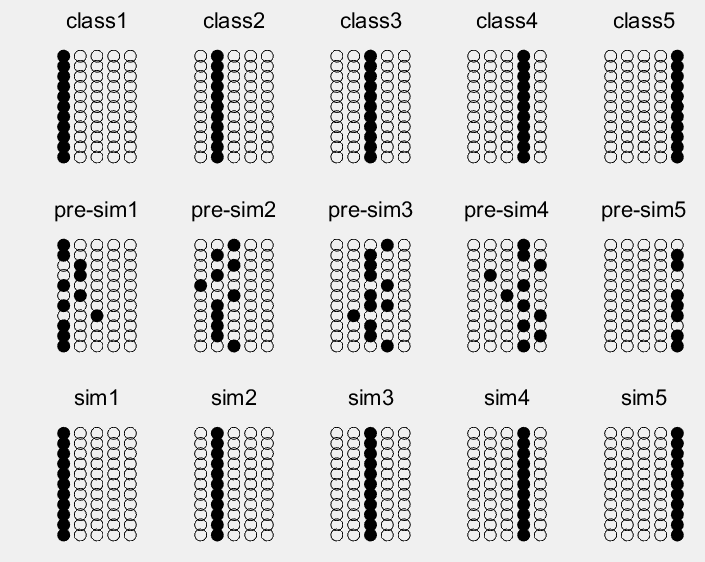
离散 Hopfield 神经网络的分类与matlab实现
1 案例背景 1.1离散 Hopfield 神经网络学习规则 离散型 Hopfield神经网络的结构、工作方式,稳定性等问题在第9章中已经进行了详细的介绍,此处不再赘述。本节将详细介绍离散Hopfield神经网络权系数矩阵的设计方法。设计权系数矩阵的目的是: ①保证系统在异步工作时的稳…...
opencv 30 -图像平滑处理01-均值滤波 cv2.blur()
什么是图像平滑处理? 图像平滑处理(Image Smoothing)是一种图像处理技术,旨在减少图像中的噪声、去除细节并平滑图像的过渡部分。这种处理常用于预处理图像,以便在后续图像处理任务中获得更好的结果。 常用的图像平滑处理方法包括…...

中小企业的数字化营销应该如何着手?数字化营销到底要怎么做?
从侠义角度讲,数字化营销就是在数字化的媒体上做营销。传播本质上是一种营销的形式 从广义角度讲,我们不仅可以将营销数字化,也可以数字化很多事物,甚至行业,比如数字化制造业、数字化工厂、数字化商会等等 而这个…...
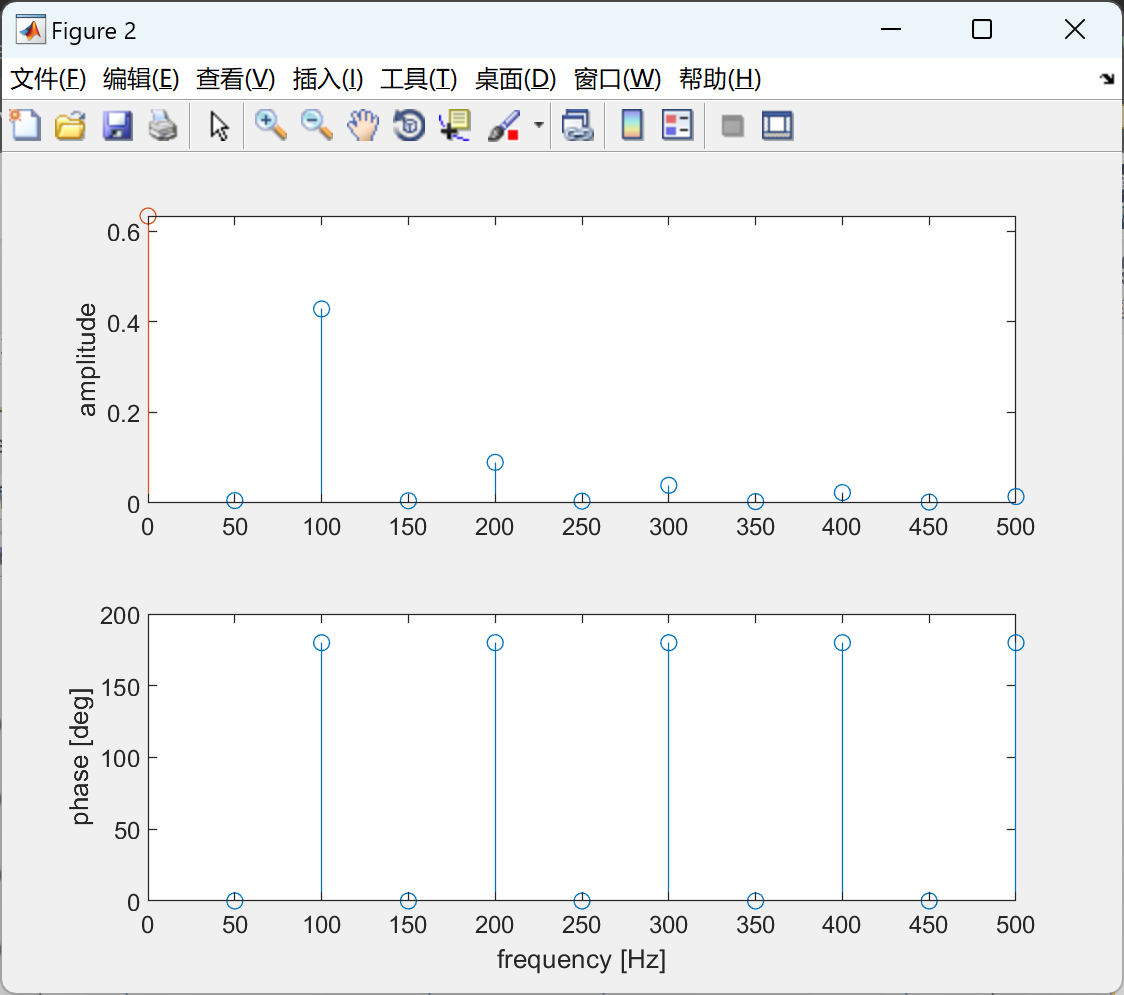
实数信号的傅里叶级数研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

解决Python虚拟环境激活脚本PowerShell执行权限问题
1. 为什么你的Python虚拟环境激活脚本无法运行? 最近在Windows上使用Python虚拟环境时,是不是经常遇到这样的错误提示:"无法加载文件...\Activate.ps1,因为在此系统上禁止运行脚本"?这个问题困扰过不少Pytho…...

cv_unet_image-colorization效果展示:黑白漫画分镜图AI上色后出版物适配性验证
cv_unet_image-colorization效果展示:黑白漫画分镜图AI上色后出版物适配性验证 1. 项目背景与技术特点 黑白漫画分镜图的上色工作一直是漫画制作中的耗时环节,传统手工上色需要专业画师投入大量时间。基于深度学习的图像上色技术为这一流程带来了革命性…...

5步掌握MRIcroGL医学影像可视化的核心用法
5步掌握MRIcroGL医学影像可视化的核心用法 【免费下载链接】MRIcroGL v1.2 GLSL volume rendering. Able to view NIfTI, DICOM, MGH, MHD, NRRD, AFNI format images. 项目地址: https://gitcode.com/gh_mirrors/mr/MRIcroGL MRIcroGL是一款专业的医学影像可视化工具&a…...

OWL ADVENTURE企业级部署架构:高可用与负载均衡配置指南
OWL ADVENTURE企业级部署架构:高可用与负载均衡配置指南 如果你正在考虑把OWL ADVENTURE这样的AI模型引入到公司的核心业务流程里,比如智能客服、内容审核或者数据分析,那你肯定不止关心模型效果好不好,更会担心它“稳不稳”。想…...

DVWA实战:文件包含漏洞的攻防博弈与场景化利用
1. 文件包含漏洞初探:从原理到危害 第一次接触文件包含漏洞时,我正调试一个简单的PHP网站。当时发现修改URL参数就能读取服务器上的任意文件,那种"原来系统这么脆弱"的震惊感至今难忘。文件包含漏洞本质上是一种代码注入技术&#…...

Blender终极重网格插件:一键生成高质量四边形拓扑的完整指南
Blender终极重网格插件:一键生成高质量四边形拓扑的完整指南 【免费下载链接】QRemeshify A Blender extension for an easy-to-use remesher that outputs good-quality quad topology 项目地址: https://gitcode.com/gh_mirrors/qr/QRemeshify 在3D建模工作…...

Mos技术深度解析:重新定义macOS鼠标滚轮体验的开源方案
Mos技术深度解析:重新定义macOS鼠标滚轮体验的开源方案 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independently …...

Nanbeige 4.1-3B极简界面效果:超长对话历史滚动+性能优化实测
Nanbeige 4.1-3B极简界面效果:超长对话历史滚动性能优化实测 如果你厌倦了传统大模型Web界面那种拥挤的侧边栏、死板的方形头像和卡顿的对话体验,那么今天分享的这个项目可能会让你眼前一亮。这是一个专为南北阁(Nanbeige)4.1-3B…...

OpenCode实战案例:用AI编程助手快速开发项目,提升10倍编码效率
OpenCode实战案例:用AI编程助手快速开发项目,提升10倍编码效率 1. 为什么选择OpenCode作为AI编程助手 作为一名长期奋战在代码一线的开发者,我一直在寻找能够真正提升开发效率的工具。当我第一次接触OpenCode时,就被它的设计理念…...

Go语言的runtime.MemProfile
Go语言作为一门高效、简洁的编程语言,其内存管理机制一直是开发者关注的焦点。runtime.MemProfile作为Go运行时提供的强大工具,能够帮助开发者深入分析程序的内存使用情况,从而优化性能、排查内存泄漏等问题。本文将围绕runtime.MemProfile展…...