双链表(带哨兵位头节点)
目录
编辑
双链表的初始化:
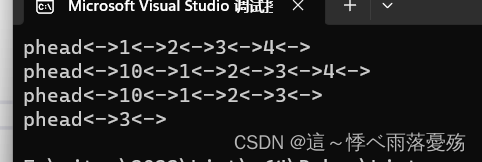
双链表的打印:
双链表的尾插:
双链表的头插:
双链表的尾删:
双链表的头删:
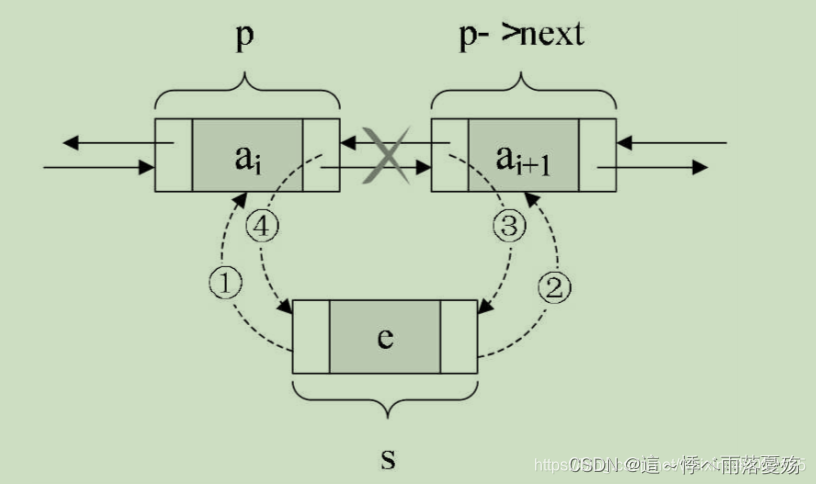
双链表pos位置之前的插入:
双链表pos位置的删除:
关于顺序表和链表的区别:
- 上篇文章给大家讲解了无头单向循环链表,它的特点:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构子结构,如哈希桶、图的邻接表等等。但是呢,单链表在笔试中还是很常见的。
- 今天我给大家讲解一下带头双向链表,它的特点:结构复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然复杂,但是使用代码实现以后会发现结构会带来很多优势。
如图,这就是今天我为大家讲解的双链表结构了。下面跟随我的思路走下去,希望让你对链表有新的理解。

双链表的初始化:
- 今天我给大家带来另一种方式改变链表的结构,如果想了解双指针来改变链表的结构,可以参考参考我的上一篇单链表的博客。
- 思路:我创建了一个节点,然后把节点赋给了phead,再让它的上一个位置和下一个位置分别指向它自己,最后返回phead就是我们要的哨兵位的头节点了。
ListNode* ListCreate(ListDateType x) {ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->val = x;newnode->next = NULL;newnode->prev = NULL;return newnode; }ListNode* ListInit() {ListNode* phead = ListCreate(0);phead->next = phead;phead->prev = phead;return phead; }
双链表的打印:
- 因为要让终端出现下面的样子,我就用到了打印的函数。
- 首先,还是老套路,我先断言了一下,防止传的参数有问题。
- 因为这里的phead是一个哨兵位,存放着无效的数据,所以,我就定义了一个cur的节点,用循环打印链表中的所有值,并标明他们的方向。
void ListPrint(ListNode* phead) {assert(phead);printf("phead<->");ListNode* cur = phead->next;while (cur != phead){printf("%d<->", cur->val);cur = cur->next;}printf("\n"); }
双链表的尾插:
- 在双链表尾插的时候,它的优势就体现出来了,如果是单链表,要尾插的话,是只有遍历找尾节点的,但是呢,如果是双向链表,phead的前一个节点就是尾节点,它就不用找尾,也不需要遍历了。这也是双链表的优势之一。
- 尾插思路:先断言一下,然后用tail保存尾节点,创建一个新节点,然后改变尾节点和头节点链接关系,让newnode为新的尾节点。
void ListPushBack(ListNode* phead,ListDateType x) {assert(phead);ListNode* tail = phead->prev;ListNode* newnode = ListCreate(x);tail->next = newnode;newnode->prev = tail;newnode->next = phead;phead->prev = newnode;}
双链表的头插:
- 思路:头插的话,就是先保存一下头节点的位置,然后创建一个新节点,然后改变他们的链接关系就可以了。因为我是先保存了它们的位置,所以谁先链接先都可以,如果没有保存的话,要向好逻辑,不要出现找不到头节点的位置了。
void ListPushFront(ListNode* phead, ListDateType x) {assert(phead);ListNode* newnode = ListCreate(x);ListNode* first = phead->next;phead->next = newnode;newnode->prev = phead;newnode->next = first;first->prev = newnode;}
双链表的尾删:
- 思路:尾删的话,就要记录一下尾节点的前一个节点了,然后去改变一下phead和尾节点前一个节点的链接关系。
void ListPopBack(ListNode* phead) {assert(phead);assert(phead->next != phead);ListNode* tail = phead->prev;ListNode* tailprev = phead->prev->prev;tailprev->next = phead;phead->prev = tailprev;free(tail);}
双链表的头删:
- 思路:头删的思路,其实和尾删的思路差不多,只不过这里保存的是phead之后的第二个节点了。然后就是改变链接关系。
void ListPopFront(ListNode* phead) {assert(phead);assert(phead != phead->next);ListNode* first = phead->next;ListNode* second = first->next;phead->next = second;second->prev = phead;free(first);}
双链表pos位置之前的插入:
- 思路:如果是插入的话,是不是和尾插和头插差不多呢,我在这里是保存的pos之前的节点,然后创建一个新的节点,让pos之前的节点指向新节点,让新节点和pos再建立连接关系。
void ListInsert(ListNode* pos, ListDateType x) {assert(pos);ListNode* posprev = pos->prev;ListNode* newnode = ListCreate(x);posprev->next = newnode;newnode->prev = posprev;newnode->next = pos;pos->prev = newnode; }
双链表pos位置的删除:
- 思路:pos位置要删除的话,保存pos上一个节点和pos下一个节点,然后free掉pos位置,再改变他们的链接关系。
void ListErase(ListNode* pos) {assert(pos);ListNode* posprev = pos->prev;ListNode* posnext = pos->next;posprev->next = posnext;posnext->prev = posprev;free(pos); }
大家看了pos位置的删除和pos之前的插入,是不是感觉和前面的尾插尾删和头插头删差不多呢,其实呢,最后的两个函数是可以进行对函数的复用的。
- 尾插:其实就是在ListInsert函数传phead就可以了,这样就实现了尾插。
ListInsert(phead, x);
- 头插:头插是改变phead之后的位置,所以直接传phead->next就可以了。
ListInsert(phead->next, x);
- 头删和尾删:因为我写的删除的函数是删除pos位置,所以传要删除的位置就可以了。
ListErase(phead->prev);ListErase(phead->next);
关于顺序表和链表的区别:
- 存储空间上:顺序表在物理上是连续的,而链表逻辑上是连续的,而物理上是不一定连续的。
- 随机访问上:顺序表是支持随机访问的,而链表是不支持的,向要访问链表中的节点,是需要遍历的。
- 任意位置的插入和删除:在这里链表就有很大的优势了,链表只需要改变指向就可以实现对任意位置的插入和删除。但是对于顺序表,它可能需要搬运元素,效率太低了。
- 插入:顺序表因为是连续的,所以在插入的上面,可能会有malloc扩容,但是呢malloc是有消耗的,如果一次扩二倍,但是用的不多,就会造成对空间的浪费,如果一次扩的空间是+1,可能局面临着多次扩容,而malloc的消耗并不低,所以这是不可取的。而链表并没有容器的概念,在这方面有优势。
- 缓存利用率:顺序表的缓存命中率高,而链表低。
#define _CRT_SECURE_NO_WARNINGS 1 #include "DoubleList.h"ListNode* ListCreate(ListDateType x) {ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->val = x;newnode->next = NULL;newnode->prev = NULL;return newnode; }ListNode* ListInit() {ListNode* phead = ListCreate(0);phead->next = phead;phead->prev = phead;return phead; }void ListPrint(ListNode* phead) {assert(phead);printf("phead<->");ListNode* cur = phead->next;while (cur != phead){printf("%d<->", cur->val);cur = cur->next;}printf("\n"); }void ListPushBack(ListNode* phead,ListDateType x) {assert(phead);//ListNode* tail = phead->prev;//ListNode* newnode = ListCreate(x);//tail->next = newnode;//newnode->prev = tail;//newnode->next = phead;//phead->prev = newnode;ListInsert(phead, x);}void ListPushFront(ListNode* phead, ListDateType x) {assert(phead);//ListNode* newnode = ListCreate(x);//ListNode* first = phead->next;//phead->next = newnode;//newnode->prev = phead;//newnode->next = first;//first->prev = newnode;ListInsert(phead->next, x); }void ListPopBack(ListNode* phead) {assert(phead);assert(phead->next != phead);//ListNode* tail = phead->prev;//ListNode* tailprev = phead->prev->prev;//tailprev->next = phead;//phead->prev = tailprev;//free(tail);ListErase(phead->prev); }void ListPopFront(ListNode* phead) {assert(phead);assert(phead != phead->next);//ListNode* first = phead->next;//ListNode* second = first->next;//phead->next = second;//second->prev = phead;//free(first);ListErase(phead->next); }int ListSize(ListNode* phead) {assert(phead);int size = 0;ListNode* cur = phead->next;while (cur != phead){++size;cur = cur->next;}return size; }void ListInsert(ListNode* pos, ListDateType x) {assert(pos);ListNode* posprev = pos->prev;ListNode* newnode = ListCreate(x);posprev->next = newnode;newnode->prev = posprev;newnode->next = pos;pos->prev = newnode; }void ListErase(ListNode* pos) {assert(pos);ListNode* posprev = pos->prev;ListNode* posnext = pos->next;posprev->next = posnext;posnext->prev = posprev;free(pos); }
什么是缓存利用率:
关于“Cache Line” ,缓存是把数据加载到离自己进的位置,对于CPU来说,CPU是一块一块存储的。而这就叫“Chche Line”。
我们所写的程序,其实都是会形成不同的指令,然后让CPU执行,但是呢,CPU执行速度快,内存跟不上,所以CPU一般都是把数据放到缓存中,对于小的字节来说,直接由寄存器来读取,大的字节会用到三级缓存。
简而言之,数据先被读取,然后运算,最后放到主存中,如果没有命令,就继续。
而顺序表呢,它的物理结构是连续的,它可能一开始没有命中,但是一旦缓存命中了,它可能就会被连续命中,所以这也是顺序表缓存利用率高的原因,而链表也是因为他的物理结构,导致缓存利用率低。
下面是双链表的源码:
#define _CRT_SECURE_NO_WARNINGS 1 #include "DoubleList.h"ListNode* ListCreate(ListDateType x) {ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->val = x;newnode->next = NULL;newnode->prev = NULL;return newnode; }ListNode* ListInit() {ListNode* phead = ListCreate(0);phead->next = phead;phead->prev = phead;return phead; }void ListPrint(ListNode* phead) {assert(phead);printf("phead<->");ListNode* cur = phead->next;while (cur != phead){printf("%d<->", cur->val);cur = cur->next;}printf("\n"); }void ListPushBack(ListNode* phead,ListDateType x) {assert(phead);//ListNode* tail = phead->prev;//ListNode* newnode = ListCreate(x);//tail->next = newnode;//newnode->prev = tail;//newnode->next = phead;//phead->prev = newnode;ListInsert(phead, x);}void ListPushFront(ListNode* phead, ListDateType x) {assert(phead);//ListNode* newnode = ListCreate(x);//ListNode* first = phead->next;//phead->next = newnode;//newnode->prev = phead;//newnode->next = first;//first->prev = newnode;ListInsert(phead->next, x); }void ListPopBack(ListNode* phead) {assert(phead);assert(phead->next != phead);//ListNode* tail = phead->prev;//ListNode* tailprev = phead->prev->prev;//tailprev->next = phead;//phead->prev = tailprev;//free(tail);ListErase(phead->prev); }void ListPopFront(ListNode* phead) {assert(phead);assert(phead != phead->next);//ListNode* first = phead->next;//ListNode* second = first->next;//phead->next = second;//second->prev = phead;//free(first);ListErase(phead->next); }int ListSize(ListNode* phead) {assert(phead);int size = 0;ListNode* cur = phead->next;while (cur != phead){++size;cur = cur->next;}return size; }void ListInsert(ListNode* pos, ListDateType x) {assert(pos);ListNode* posprev = pos->prev;ListNode* newnode = ListCreate(x);posprev->next = newnode;newnode->prev = posprev;newnode->next = pos;pos->prev = newnode; }void ListErase(ListNode* pos) {assert(pos);ListNode* posprev = pos->prev;ListNode* posnext = pos->next;posprev->next = posnext;posnext->prev = posprev;free(pos); }#pragma once #include <stdio.h> #include <assert.h> #include <stdlib.h>typedef int ListDateType;typedef struct ListNode {ListDateType val;struct ListNode* next;struct ListNode* prev; }ListNode;ListNode* ListCreate(ListDateType x); void ListPrint(ListNode* phead); ListNode* ListInit(); void ListPushBack(ListNode* phead,ListDateType x); void ListPushFront(ListNode* phead, ListDateType x); void ListPopBack(ListNode* phead); void ListPopFront(ListNode* phead); int ListSize(ListNode* phead); void ListInsert(ListNode* pos, ListDateType x); void ListErase(ListNode* pos);
相关文章:
双链表(带哨兵位头节点)
目录 编辑 双链表的初始化: 双链表的打印: 双链表的尾插: 双链表的头插: 双链表的尾删: 双链表的头删: 双链表pos位置之前的插入: 双链表pos位置的删除: 关于顺序表和链表…...
)
MySQL - LOAD DATA LOCAL INFILE将数据导入表中和 INTO OUTFILE (速度快)
文章目录 一、语法介绍二、数据分隔符介绍 :换行符说明: 三、示例LOAD DATA LOCAL INFILEINTO OUTFILE 总结 一、语法介绍 LOAD DATA[LOW_PRIORITY | CONCURRENT] [LOCAL]INFILE file_name[REPLACE | IGNORE]INTO TABLE tbl_name[PARTITION (partition_name [, par…...

String ,StringBulider ,StringBuffer
面试指北149 知乎 StringBuffer和StringBuilder区别详解(Java面试)_stringbuffer和stringbuilder的区别_辰兮要努力的博客-CSDN博客...

阶段总结(linux基础)
目录 一、初始linux系统 二、基本操作命令 三、目录结构 四、文件及目录管理命令 查看文件内容 创建文件 五、用户与组管理 六、文件权限与压缩管理 七、磁盘管理 八、系统程序与进程管理 管理机制 文件系统损坏 grub引导故障 磁盘资源耗尽 程序与进程的区别 查…...
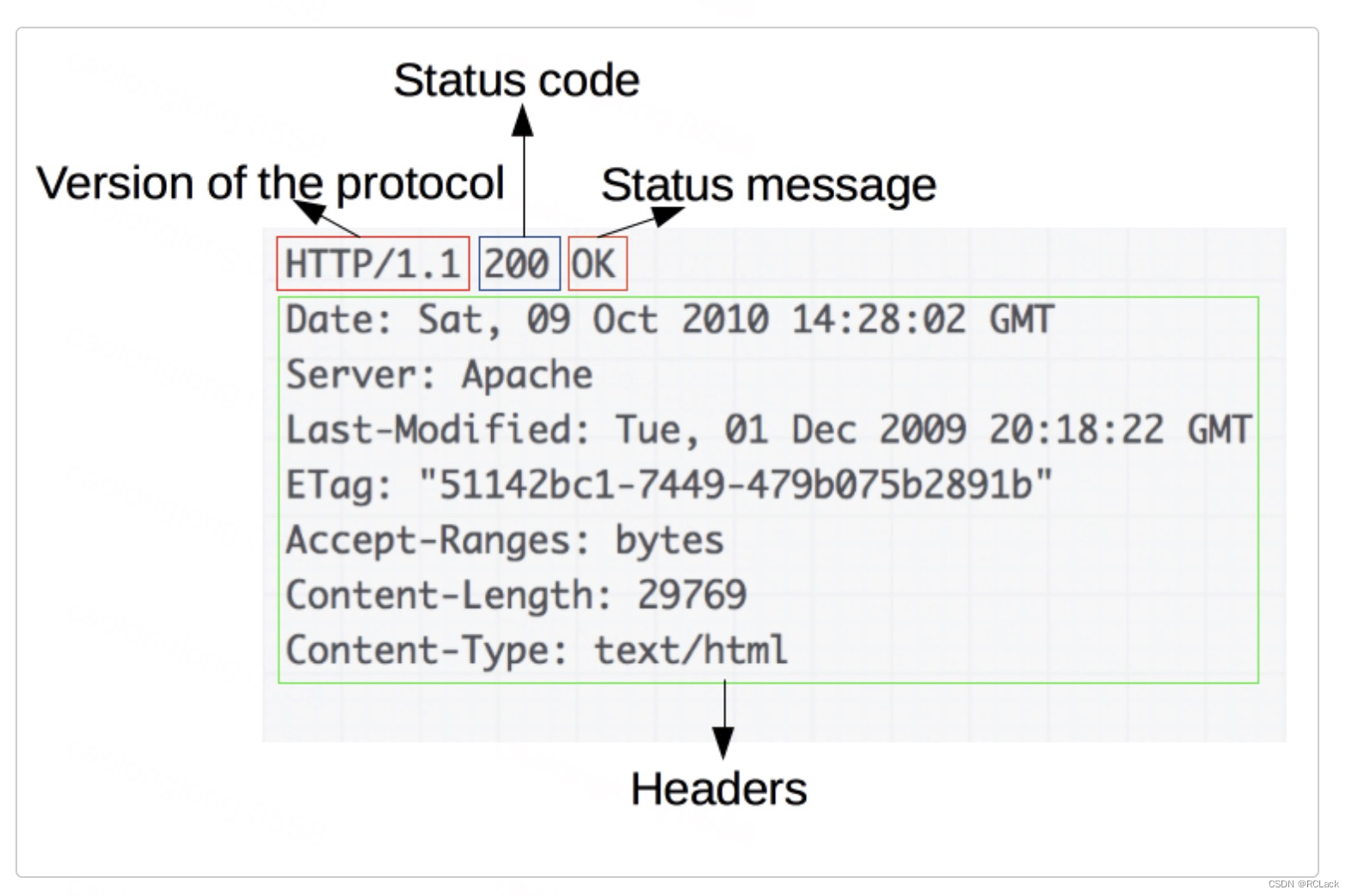
HTTP(超文本传输协议)学习
关于HTTP补学 一、HTTP能干什么 通过下图能够直观的看出:“交换数据 ” 二、HTTP请求例子 一个 HTTP 方法,通常是由一个动词,像 GET、POST 等,或者一个名词,像 OPTIONS、HEAD 等,来定义客户端执行的动作。…...
)
23年7月工作笔记整理(前端)
目录 一、js相关二、业务场景学习 一、js相关 1.js中Number类型的最大值常量:Number.MAX_VALUE,最小值常量:Number.MIN_VALUE 2.巩固一下reduce语法:reduce(function(初始值或方法的返回值,当前值,当前值的索引,要累加的初始值))…...
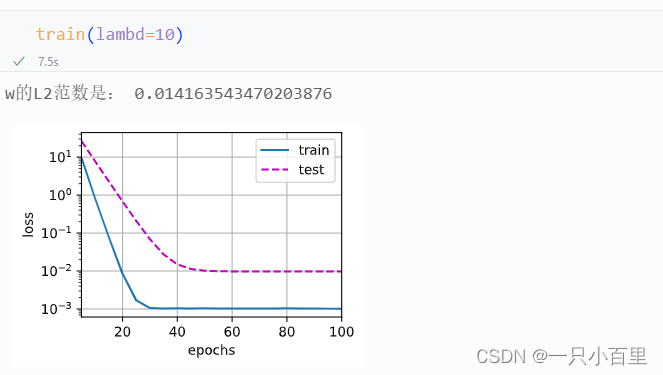
pytorch学习——正则化技术——权重衰减
一、概念介绍 权重衰减(Weight Decay)是一种常用的正则化技术,它通过在损失函数中添加一个惩罚项来限制模型的复杂度,从而防止过拟合。 在训练参数化机器学习模型时, 权重衰减(weight decay)是…...
iTOP-RK3588开发板Ubuntu 系统交叉编译 Qt 工程-命令行交叉编译
使用源码 rk3588_linux/buildroot/output/rockchip_rk3588/host/bin/qmake 交叉编译 QT 工程。 最后烧写编译好的 buildroot 镜像,将编译好的 QT 工程可执行程序在 buildroot 系统上运行。 交叉编译 QT 工程如下所示,首先进入 QLed 的工程目录下。 然后…...
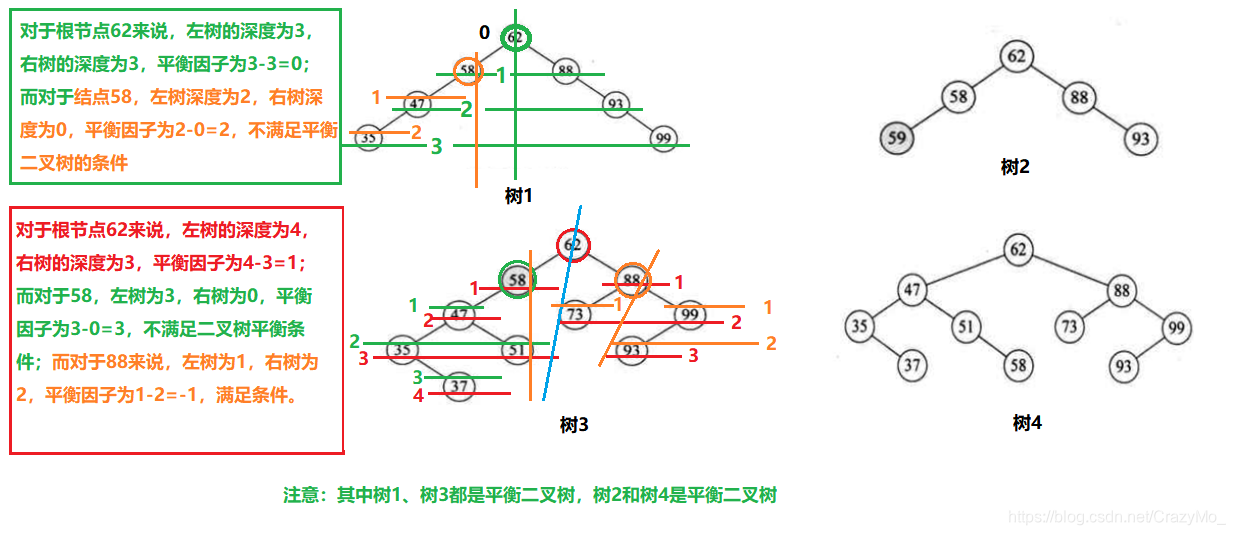
Java进阶——数据结构与算法之哈希表与树的入门小结(四)
文章大纲 引言一、哈希表1、哈希表概述2、哈希表的基本设计思想3、JDK中的哈希表的设计思想概述 二、树1、树的概述2、树的特点3、树的相关术语4、树的存储结构4.1、双亲表示法4.2、孩子兄弟表示法:4.3、孩子表示法:4.4、双亲孩子表示法 三、二叉树1、二…...

DataFrame中按某字段分类并且取该分类随机数量的数据
最近有个需求,把某个df中的数据,按照特定字段分类,并且每个分类只取随机数量数据,这个随机数量需要有范围限制。写出来记录下。 def randomCutData(self, df, startNum):grouped df.groupby(classify_label)df_sampled pd.Data…...
【c++】rand()随机函数的应用(一)——rand()函数详解和实例
c语言中可以用rand()函数生成随机数,今天来探讨一下rand()函数的基本用法和实际应用。 本系列文章共分两讲,今天主要介绍一下伪随机数生成的原理,以及在伪随机数生成的基础上,生成随机数的技巧,下一讲主要介绍无重复随…...
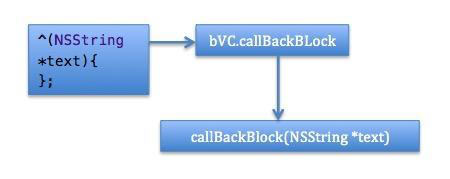
iOS——Block回调
先跟着我实现最简单的 Block 回调传参的使用,如果你能举一反三,基本上可以满足了 OC 中的开发需求。已经实现的同学可以跳到下一节。 首先解释一下我们例子要实现什么功能(其实是烂大街又最形象的例子): 有两个视图控…...
)
html学习6(xhtml)
1、xhtml是以xml格式编写的html。 2、xhtml与html的文档结构区别: DOCTYPE是强制性的<html>、<head>、<title>、<body>也是强制性的<html>中xmlns属性是强制性的 3、 元素语法区别: xhtml元素必须正确嵌套xhtml元素必…...
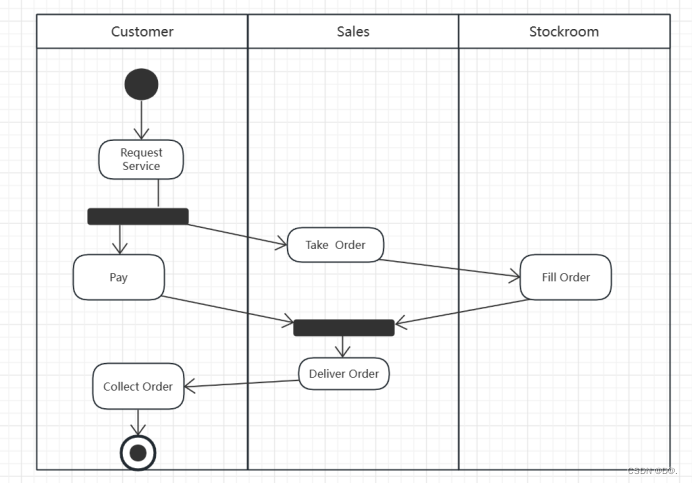
UML-活动图
目录 一.活动图概述: 1.活动图的作用: 2.以下场合不使用活动图: 3.活动图的基本要素: 4.活动图的图符 4.1起始状态 4.2终止状态 4.3状态迁移 4.4决策点 4.5同步条:表示活动之间的不同 5.活动图: 二.泳道: 1.泳道图&a…...

跨境电商怎么做?Live Market教你创业及做大生意
随着全球化的不断深入和互联网技术的迅猛发展,跨境电商成为了一个蓬勃发展的行业。根据eMarketer的数据,2021年全球跨境电商销售额将达到4.5万亿美元,预计到2025年将增长至6.3万亿美元。这表明,跨境电商行业将继续保持强劲增长的趋…...

Linux 4.19 和Linux 5.10 的区别
Linux 4.19和Linux 5.10是Linux内核的两个不同版本。它们之间有一些重要的区别,包括功能、性能和支持方面的改进。以下是一些常见的区别: 功能增强:Linux 5.10相对于4.19引入了许多新功能和增强。例如,Linux 5.10引入了BPF&#x…...
学习单片机的秘诀:实践与坚持
在学习单片机时,将实践与学习结合起来是一个很好的方法。不要一上来就死磕指令和名词,而是边学边做实验,循序渐进地理解和应用指令。通过实验,你能亲身感受到指令的控制效果,增强对单片机的理解和兴趣。 学习单片机不…...
Hum Brain Mapp:用于功能连接体指纹识别和认知状态解码的高精度机器学习技术
摘要 人脑是一个复杂的网络,由功能和解剖上相互连接的脑区组成。越来越多的研究表明,对脑网络的实证估计可能有助于发现疾病和认知状态的生物标志物。然而,实现这一目标的先决条件是脑网络还必须是个体的可靠标记。在这里,本研究…...

Ajax图书管理业务
图书管理业务 Ajax图书管理业务 需求: 对服务器的图书数据进行 增、删、改、查。功能的实现,同时实时动态的渲染刷新页面内容 根据功能模块分为四个业务模块,下面有各个业务的实现步骤 01_ 渲染图书列表业务 * 目标1:渲染图书列表 * 1.1 获…...

对于爬虫代码的优化,多个方向
对于优化爬虫,有许多可能的方法,这取决于你的具体需求和目标。以下是一些常见的优化策略: 1. **并发请求**:你可以使用多线程或异步IO来同时发送多个请求,这可以显著提高爬虫的速度。Python的concurrent.futures库或a…...

老马失前蹄,竟然在数据库外键上翻车了,重温外键级联浩
AI Agent 时代的沙箱需求 从 Copilot 到 Agent:执行能力的质变 在生成式 AI 的早期阶段,应用主要以“Copilot”形式存在,AI 仅作为辅助生成建议。然而,随着 AutoGPT、BabyAGI 以及 OpenAI Code Interpreter(现为 Advan…...
)
【稀缺首发】金融级大模型上线前必过测试关:自动生成符合ISO/IEC 25010标准的137条可执行用例(含合规性断言模板)
第一章:大模型工程化测试用例自动生成 2026奇点智能技术大会(https://ml-summit.org) 大模型工程化落地的核心挑战之一,在于测试覆盖难以随模型迭代速度同步演进。传统手工编写测试用例的方式在面对动态 Prompt、多轮对话、上下文敏感输出等场景时&…...

【CW32实战】从零到一:MDK环境配置与固件库点亮LED
1. 开发环境准备:MDK安装与固件库获取 第一次接触CW32系列单片机时,环境搭建往往是最让人头疼的环节。我刚开始用CW32F030的时候,光是安装软件就折腾了大半天。下面就把我踩过的坑和验证过的正确方法分享给大家。 首先需要下载MDK开发环境&am…...
)
Zynq UltraScale实战:Linux A53与裸机R5共享内存的5个关键步骤(附代码)
Zynq UltraScale实战:Linux A53与裸机R5共享内存的5个关键步骤(附代码) 在异构计算架构中,Zynq UltraScale MPSoC凭借其独特的双核Cortex-A53与实时核Cortex-R5组合,成为工业控制、自动驾驶等领域的理想选择。但如何让…...
)
告别龟速下载!用阿里云镜像源5分钟搞定YOLOv8到v11的完整环境(Windows保姆级教程)
5分钟极速部署YOLO全系列:阿里云镜像源加速Windows环境配置指南 刚接触目标检测的新手们,往往在第一步环境配置就卡壳数小时——PyTorch下载进度条纹丝不动、CUDA版本匹配报错、依赖冲突导致安装失败… 这些坑我三年前第一次跑YOLOv3时全踩过。现在教你用…...

三步搞定iOS激活锁绕过:applera1n工具使用全指南
三步搞定iOS激活锁绕过:applera1n工具使用全指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾经因为忘记Apple ID密码而无法使用自己的iPhone?或者购买的二手设备被…...

3步轻松掌握:no-defender实用指南,安全关闭Windows Defender防火墙
3步轻松掌握:no-defender实用指南,安全关闭Windows Defender防火墙 【免费下载链接】no-defender A slightly more fun way to disable windows defender firewall. (through the WSC api) 项目地址: https://gitcode.com/GitHub_Trending/no/no-defe…...

AWPortrait-Z功能体验:批量生成、历史记录恢复等实用功能详解
AWPortrait-Z功能体验:批量生成、历史记录恢复等实用功能详解 1. 从安装到启动:快速上手指南 如果你刚接触AI图像生成,可能会觉得部署一个模型很复杂。但AWPortrait-Z在这方面做得相当友好,它把复杂的模型封装成了一个开箱即用的…...

终极指南:如何免费解锁Cursor AI Pro功能,告别试用限制
终极指南:如何免费解锁Cursor AI Pro功能,告别试用限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reac…...

LiuJuan20260223Zimage与MySQL数据库交互:安装配置与数据管理
LiuJuan20260223Zimage与MySQL数据库交互:安装配置与数据管理 为AI模型数据提供稳定可靠的数据存储方案 1. 前言:为什么需要数据库支持 在实际的AI应用开发中,我们经常遇到一个痛点:模型生成的数据如何持久化保存?比如…...