Sklearn-使用SVC对iris数据集进行分类
Sklearn-使用SVC对iris数据集进行分类
- iris数据集的加载
- 训练svc模型
- 输出混淆矩阵和分类报告
- 使用Pipeline管道完成固定操作
- 不使用Pipeline
- 使用Pipeline
使用SVC对iris数据集进行分类预测
涉及内容包含:
- 数据集的加载,训练集和测试集的划分
- 训练svc模型,对测试集的预测
- 输出混淆矩阵和分类报告
- 使用Pipeline执行操作
iris数据集的加载
加载数据集
用DataFrame展示数据
划分训练集和测试集合
from sklearn.datasets import load_iris
iris = load_iris()
iris.keys()
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
data = iris['data']
target = iris['target']# 以DataFrame显示所有的数据
import pandas as pd
df = pd.DataFrame(data,columns=iris['feature_names'])
df['target'] = target # 添加target列
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | 2 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | 2 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | 2 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | 2 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | 2 |
150 rows × 5 columns
# 划分数据集:训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.3) # 测试集占30%。训练集70%
训练svc模型
- 导入库文件
- 初始化svc
- 训练svc
from sklearn.svm import SVC
# 初始化SVC
svc = SVC()
# 训练
svc.fit(x_train,y_train)
# 查看训练效果
print("训练集的精度",svc.score(x_train,y_train))
# 对测试集预测的精度
print("对测试集的预测效果:",svc.score(x_test,y_test))# 对测试集进行预测
y_pre = svc.predict(x_test)
# 表格对比预测与实际结果
df2 = pd.DataFrame(data = {'predict':y_pre,'true':y_test
})
训练集的精度 0.9714285714285714
对测试集的预测效果: 0.9555555555555556
输出混淆矩阵和分类报告
- 输出混淆矩阵:查看每个类预测的成功与失败的情况
- 输出分类报告:查看分类的性能
from sklearn.metrics import confusion_matrix# 输出混淆矩阵
con_matrix = confusion_matrix(y_test,y_pre)
print(con_matrix)
[[12 0 0][ 0 15 1][ 0 1 16]]
from sklearn.metrics import classification_report
# 输出分类报告
report = classification_report(y_test,y_pre,target_names=iris['target_names'])
print(report)
precision recall f1-score supportsetosa 1.00 1.00 1.00 12versicolor 0.94 0.94 0.94 16virginica 0.94 0.94 0.94 17accuracy 0.96 45macro avg 0.96 0.96 0.96 45
weighted avg 0.96 0.96 0.96 45
使用Pipeline管道完成固定操作
- 增加对数据的归一化处理
- 将对数据的归一化处理和训练处理放在pipeline中完成
不使用Pipeline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler iris = load_iris()
data = iris['data']
target = iris['target']# 划分数据集:训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.3,random_state=42,stratify=target) # 测试集占30%。训练集70%# 特征变量标准化
# 由于支持向量机可能受特征变量取值范围影响,训练集与测试集的特征变量标准化
scaler = StandardScaler().fit(x_train)
x_train_s = scaler.transform(x_train)
x_test_s = scaler.transform(x_test)# 训练模型
svm = SVC()
svm.fit(x_train_s, y_train)
print("精确度:",svm.score(x_test_s, y_test))
精确度: 0.9333333333333333
使用Pipeline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVCfrom sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# from sklearn.pipeline import make_pipelineiris = load_iris()
data = iris['data']
target = iris['target']# 划分数据集:训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.3,random_state=42,stratify=target) # 测试集占30%。训练集70%# 构造管道
pipe = Pipeline([('std_scaler',StandardScaler()),('svc',SVC())]
)
# 使用管道
pipe.fit(x_train,y_train)
# 预测
print("精度为:",pipe.score(x_test,y_test))
精度为: 0.9333333333333333
相关文章:

Sklearn-使用SVC对iris数据集进行分类
Sklearn-使用SVC对iris数据集进行分类 iris数据集的加载训练svc模型输出混淆矩阵和分类报告使用Pipeline管道完成固定操作不使用Pipeline使用Pipeline 使用SVC对iris数据集进行分类预测 涉及内容包含: 数据集的加载,训练集和测试集的划分训练svc模型,对测试集的预测…...

项目经理必读:领导风格对项目成功的关键影响
引言 项目经理作为一个领导者的角色,他们需要协调各方资源,管理团队,推动项目的进行。为了完成这些任务,项目经理必须具备各种领导风格的灵活性,以应对项目中的各种变数和挑战。在这篇文章中,我们将讨论领…...
行业追踪,2023-08-04
自动复盘 2023-08-04 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
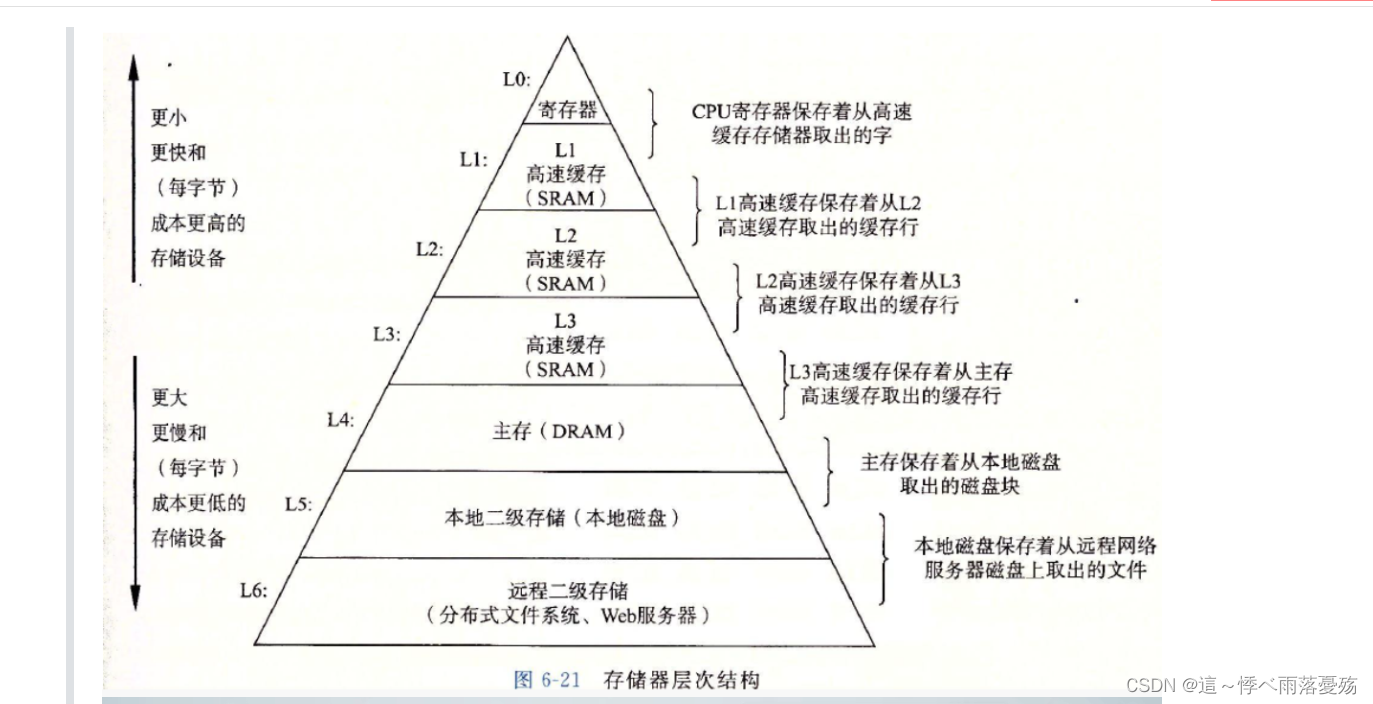
双链表(带哨兵位头节点)
目录 编辑 双链表的初始化: 双链表的打印: 双链表的尾插: 双链表的头插: 双链表的尾删: 双链表的头删: 双链表pos位置之前的插入: 双链表pos位置的删除: 关于顺序表和链表…...
)
MySQL - LOAD DATA LOCAL INFILE将数据导入表中和 INTO OUTFILE (速度快)
文章目录 一、语法介绍二、数据分隔符介绍 :换行符说明: 三、示例LOAD DATA LOCAL INFILEINTO OUTFILE 总结 一、语法介绍 LOAD DATA[LOW_PRIORITY | CONCURRENT] [LOCAL]INFILE file_name[REPLACE | IGNORE]INTO TABLE tbl_name[PARTITION (partition_name [, par…...

String ,StringBulider ,StringBuffer
面试指北149 知乎 StringBuffer和StringBuilder区别详解(Java面试)_stringbuffer和stringbuilder的区别_辰兮要努力的博客-CSDN博客...

阶段总结(linux基础)
目录 一、初始linux系统 二、基本操作命令 三、目录结构 四、文件及目录管理命令 查看文件内容 创建文件 五、用户与组管理 六、文件权限与压缩管理 七、磁盘管理 八、系统程序与进程管理 管理机制 文件系统损坏 grub引导故障 磁盘资源耗尽 程序与进程的区别 查…...
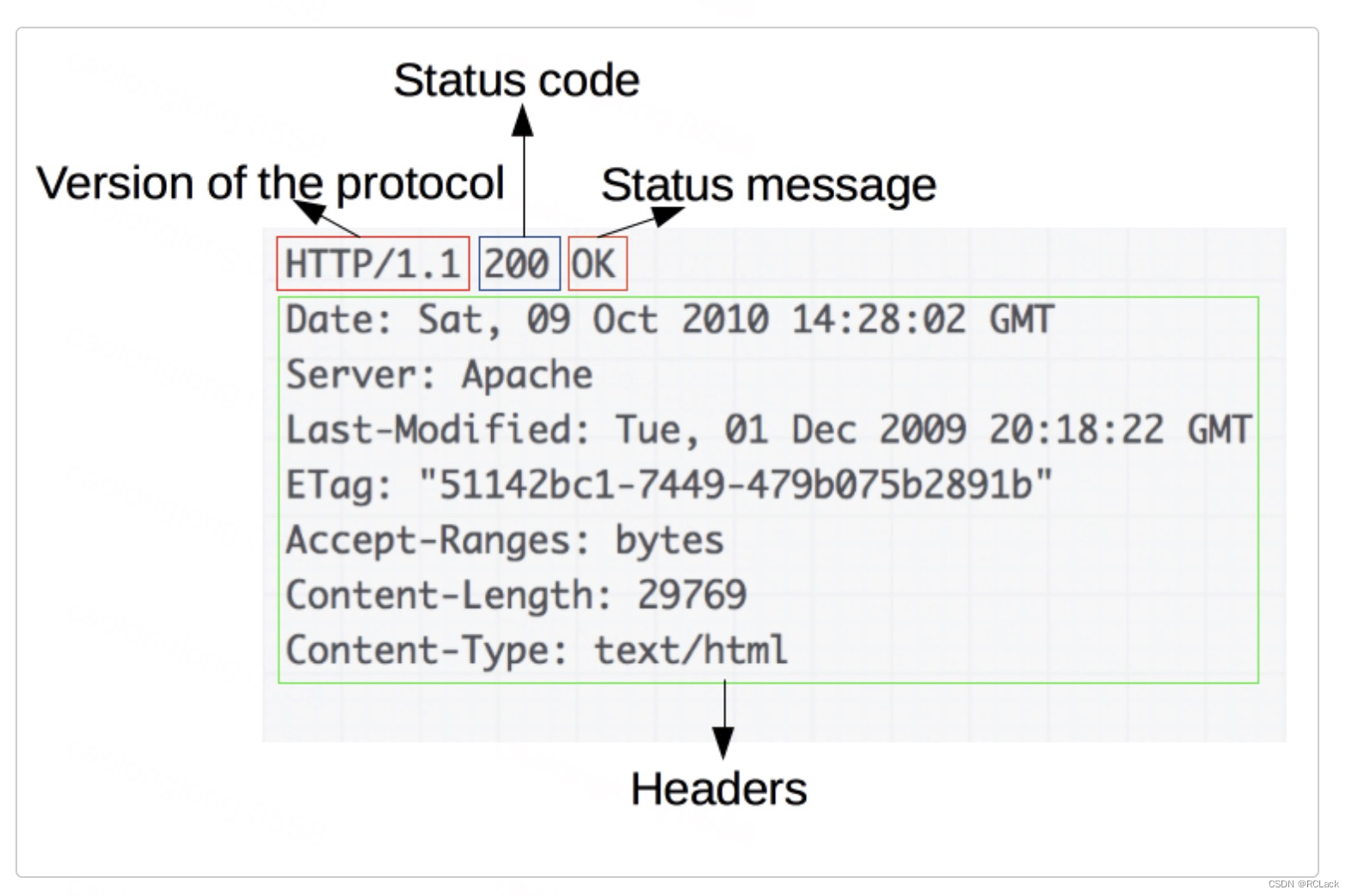
HTTP(超文本传输协议)学习
关于HTTP补学 一、HTTP能干什么 通过下图能够直观的看出:“交换数据 ” 二、HTTP请求例子 一个 HTTP 方法,通常是由一个动词,像 GET、POST 等,或者一个名词,像 OPTIONS、HEAD 等,来定义客户端执行的动作。…...
)
23年7月工作笔记整理(前端)
目录 一、js相关二、业务场景学习 一、js相关 1.js中Number类型的最大值常量:Number.MAX_VALUE,最小值常量:Number.MIN_VALUE 2.巩固一下reduce语法:reduce(function(初始值或方法的返回值,当前值,当前值的索引,要累加的初始值))…...
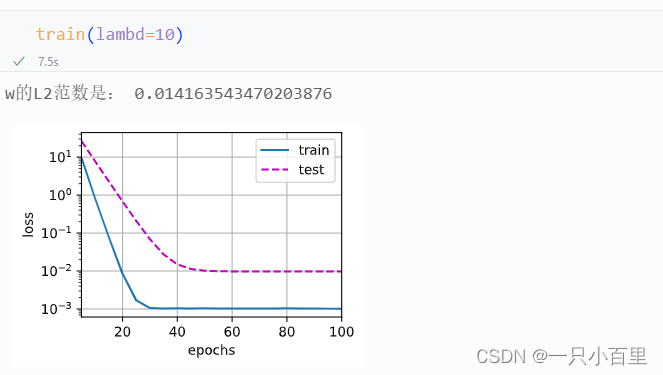
pytorch学习——正则化技术——权重衰减
一、概念介绍 权重衰减(Weight Decay)是一种常用的正则化技术,它通过在损失函数中添加一个惩罚项来限制模型的复杂度,从而防止过拟合。 在训练参数化机器学习模型时, 权重衰减(weight decay)是…...
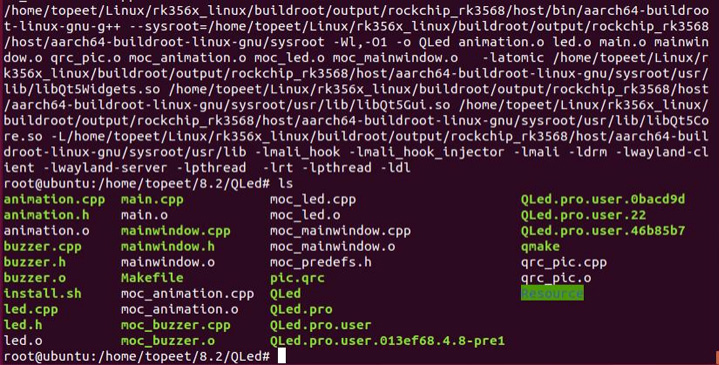
iTOP-RK3588开发板Ubuntu 系统交叉编译 Qt 工程-命令行交叉编译
使用源码 rk3588_linux/buildroot/output/rockchip_rk3588/host/bin/qmake 交叉编译 QT 工程。 最后烧写编译好的 buildroot 镜像,将编译好的 QT 工程可执行程序在 buildroot 系统上运行。 交叉编译 QT 工程如下所示,首先进入 QLed 的工程目录下。 然后…...
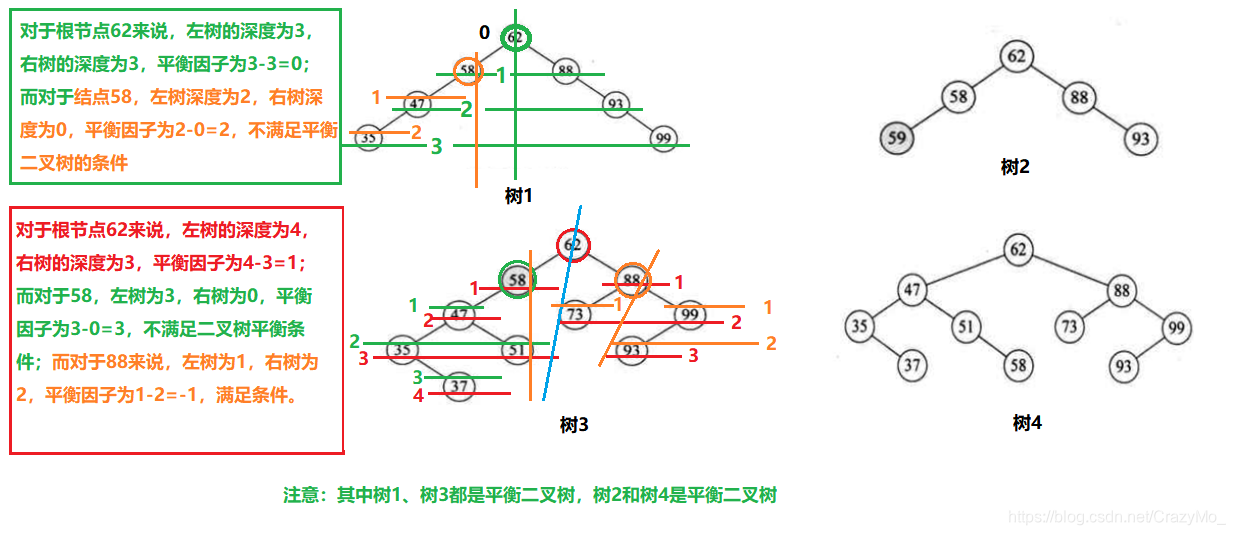
Java进阶——数据结构与算法之哈希表与树的入门小结(四)
文章大纲 引言一、哈希表1、哈希表概述2、哈希表的基本设计思想3、JDK中的哈希表的设计思想概述 二、树1、树的概述2、树的特点3、树的相关术语4、树的存储结构4.1、双亲表示法4.2、孩子兄弟表示法:4.3、孩子表示法:4.4、双亲孩子表示法 三、二叉树1、二…...

DataFrame中按某字段分类并且取该分类随机数量的数据
最近有个需求,把某个df中的数据,按照特定字段分类,并且每个分类只取随机数量数据,这个随机数量需要有范围限制。写出来记录下。 def randomCutData(self, df, startNum):grouped df.groupby(classify_label)df_sampled pd.Data…...
【c++】rand()随机函数的应用(一)——rand()函数详解和实例
c语言中可以用rand()函数生成随机数,今天来探讨一下rand()函数的基本用法和实际应用。 本系列文章共分两讲,今天主要介绍一下伪随机数生成的原理,以及在伪随机数生成的基础上,生成随机数的技巧,下一讲主要介绍无重复随…...
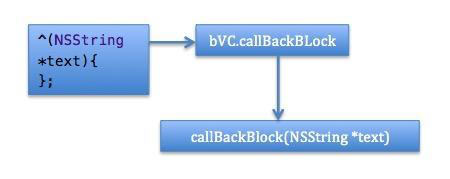
iOS——Block回调
先跟着我实现最简单的 Block 回调传参的使用,如果你能举一反三,基本上可以满足了 OC 中的开发需求。已经实现的同学可以跳到下一节。 首先解释一下我们例子要实现什么功能(其实是烂大街又最形象的例子): 有两个视图控…...
)
html学习6(xhtml)
1、xhtml是以xml格式编写的html。 2、xhtml与html的文档结构区别: DOCTYPE是强制性的<html>、<head>、<title>、<body>也是强制性的<html>中xmlns属性是强制性的 3、 元素语法区别: xhtml元素必须正确嵌套xhtml元素必…...
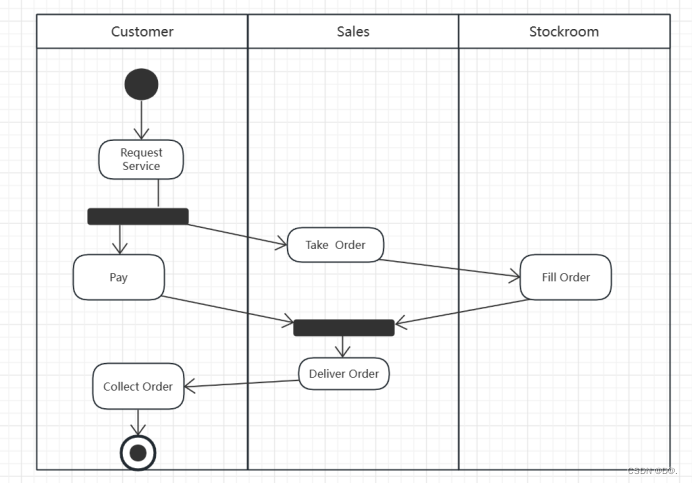
UML-活动图
目录 一.活动图概述: 1.活动图的作用: 2.以下场合不使用活动图: 3.活动图的基本要素: 4.活动图的图符 4.1起始状态 4.2终止状态 4.3状态迁移 4.4决策点 4.5同步条:表示活动之间的不同 5.活动图: 二.泳道: 1.泳道图&a…...

跨境电商怎么做?Live Market教你创业及做大生意
随着全球化的不断深入和互联网技术的迅猛发展,跨境电商成为了一个蓬勃发展的行业。根据eMarketer的数据,2021年全球跨境电商销售额将达到4.5万亿美元,预计到2025年将增长至6.3万亿美元。这表明,跨境电商行业将继续保持强劲增长的趋…...

Linux 4.19 和Linux 5.10 的区别
Linux 4.19和Linux 5.10是Linux内核的两个不同版本。它们之间有一些重要的区别,包括功能、性能和支持方面的改进。以下是一些常见的区别: 功能增强:Linux 5.10相对于4.19引入了许多新功能和增强。例如,Linux 5.10引入了BPF&#x…...
学习单片机的秘诀:实践与坚持
在学习单片机时,将实践与学习结合起来是一个很好的方法。不要一上来就死磕指令和名词,而是边学边做实验,循序渐进地理解和应用指令。通过实验,你能亲身感受到指令的控制效果,增强对单片机的理解和兴趣。 学习单片机不…...

终极指南:EuroSAT数据集深度解析与遥感图像分类性能优化
终极指南:EuroSAT数据集深度解析与遥感图像分类性能优化 【免费下载链接】EuroSAT EuroSAT: Land Use and Land Cover Classification with Sentinel-2 项目地址: https://gitcode.com/gh_mirrors/eu/EuroSAT EuroSAT数据集是遥感图像分类领域的重要基准&…...

3步解密Navicat密码:技术原理与实战应用完整指南
3步解密Navicat密码:技术原理与实战应用完整指南 【免费下载链接】navicat_password_decrypt 忘记navicat密码时,此工具可以帮您查看密码 项目地址: https://gitcode.com/gh_mirrors/na/navicat_password_decrypt 作为数据库开发者和管理员,你是否…...

Qwen3-VL-4B Pro多场景落地:盲人辅助APP中实时图像语音描述服务
Qwen3-VL-4B Pro多场景落地:盲人辅助APP中实时图像语音描述服务 1. 项目背景与意义 对于视力障碍人群来说,日常生活中最大的挑战之一就是无法获取视觉信息。传统的辅助手段如盲杖、导盲犬等虽然有用,但无法提供丰富的环境感知能力。随着人工…...
栽)
归并排序力扣题(leetcode)栽
1.概述在人工智能快速发展的今天,AI不再仅仅是回答问题的聊天机器人,而是正在演变为能够主动完成复杂任务的智能代理。OpenAI的Codex CLI就是这一趋势的典型代表——一个跨平台的本地软件代理,能够在用户的机器上安全高效地生成高质量的软件变…...

DotNetPy:现代.NET 与 Python 互操作 实战指南概
我为什么会发出这个疑问呢?是因为我研究Web开发中的一个问题时,HTTP请求体在 Filter(过滤器)处被读取了之后,在 Controller(控制层)就读不到值了,使用 RequestBody 的时候。 无论是字…...
5分钟掌握Translumo:实时屏幕翻译神器,打破游戏视频语言壁垒
5分钟掌握Translumo:实时屏幕翻译神器,打破游戏视频语言壁垒 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Trans…...

单片机驱动直流电机,除了PWM调速,你还需要注意这个‘隐形杀手’——续流二极管
单片机驱动直流电机:PWM调速之外的续流二极管实战指南 当你在深夜调试电机驱动电路,突然闻到一股焦糊味,发现MOS管又烧毁了——这种场景对许多单片机开发者来说并不陌生。PWM调速是控制直流电机的常见手段,但很少有人告诉你&…...
)
Ansys Maxwell实战:3D涡流分析从入门到精通(附线圈与圆盘案例)
Ansys Maxwell实战:3D涡流分析从入门到精通(附线圈与圆盘案例) 电磁仿真在现代工程设计中扮演着越来越重要的角色,而Ansys Maxwell作为行业标杆工具,其3D涡流分析功能尤其适用于电机、变压器、感应加热等场景。本文将从…...

LangChain教程-、Langchain基础严
简介 AI Agent 不仅仅是一个能聊天的机器人(如普通的 ChatGPT),而是一个能够感知环境、进行推理、自主决策并调用工具来完成特定任务的智能系统,更够完成更为复杂的AI场景需求。 AI Agent 功能 根据查阅的资料,agent的…...

Phi-3 Forest Lab应用场景:技术布道师内容生成器——将复杂概念转化为森林隐喻文案
Phi-3 Forest Lab应用场景:技术布道师内容生成器——将复杂概念转化为森林隐喻文案 1. 项目背景与核心价值 在技术传播领域,如何将复杂的AI概念转化为大众易于理解的内容,一直是技术布道师面临的挑战。Phi-3 Forest Lab通过创新的自然隐喻系…...