外键字段的增删改查、多表查询(子查询和连表查询、正反向、聚合查询、 分组查询、 F与Q查询)、django中如何开启事务
一、 外键字段的增删改查
1.多对多的外键增删改查图书和作者是多对多,借助于第三张表实现的,如果想绑定图书和作者的关系,本质上就是在操作第三方表2.如何操作第三张表问题:让你给图书添加一个作者,他俩的关系可是多对多多对多的增删该查1.给图书id=2添加一个作者id=1book_obj = models.Book.objects.filter(pk=2).first()print(book_obj.authors) # app01.Author.None 这句话的意思就是跨到了第三张表借助于内置方法add()book_obj.authors.add(1) # 加一个作者book_obj.authors.add(2,3) # 一次性条件多个作者也支持写对象# author_obj1 = models.Author.objects.filter(pk=1).first()# author_obj2 = models.Author.objects.filter(pk=2).first()# author_obj3 = models.Author.objects.filter(pk=3).first()# book_obj.authors.add(author_obj1, author_obj2, author_obj3)2.删除# 也支持写对象book_obj.authors.remove(1)# book_obj.authors.remove(2,3)3.修改# book_obj.authors.set(1,3) # set() takes 2 positional arguments but 3 were givenbook_obj.authors.set([1,3]) # 注意修改的时候得加上中括号[]4.清空表book_obj.authors.clear() # 注意:这只能清空book_id=2的,若还有其他id数据,则还在总结:操作第三张表 通过外键字段点下面的方法add remove set clear # 四个方法二、 多表查询
1.子查询和连表查询
子查询:一个SQL语句的执行结果当成另一个SQL语句的执行条件,分步操作连表查询:把多个表关联在一起拼接成一个大的虚拟表,然后按照单表查询inner joinleft joinright joinunion
select * from course inner join teacher on course.id=teacher_course_id where id=1;select * from course as c inner join teacher as t on course.id=teacher_course_id left join class on class.id=c.class_id where c.id=12.正反向的概念
先判断是正向还是反向查询
1.正向外键字段在我手上,我查你就是正向查询# 图书查出版社:外键字段在图书表中,正向查询
2.反向外键字段在我手上,你查我就是反向查询# 出版社查图书,外键字段在图书表中,反向查询3.判断出来正向和反向之后有什么用正向查询按照字段查询(外键字段)反向查询按照表名小写或者表名小写_set
3. 子查询
# 1.查询书籍主键为1的出版社# 书籍查出版社----------->正向查询------------>按字段查询res = models.Book.objects.filter(pk=1).first()print(res.publish) # 人民出版社 publish_objprint(res.publish.name)print(res.publish.addr)# 2.查询书籍主键为2的作者# 书籍查作何------>正向查询------->按外键字段查询book_obj = models.Book.objects.filter(pk=2).first()print(book_obj) # Book object (2)# 一本书有多个作者,所以得点all()print(book_obj.authors.all()) # <QuerySet [<Author: Author object (1)>]>print(book_obj.authors.all()[0].name) # jerryprint(book_obj.authors.all()[0].age) # 18# for i in book_obj.authors.all():# print(i)# 3.查询作者jack的电话号码# 作者查作者详情------------->正向查询---------------->按字段查询author_obj = models.Author.objects.filter(name='jerry').first()print(author_obj.author_detail) # AuthorDetail object (1)print(author_obj.author_detail.phone)# 4.查询出版社是北京出版社出版的书# 出版社查书------>反向查询------>按照表名小写或者_setpublish_obj = models.Publish.objects.filter(name='北京出版社').first()print(publish_obj.book_set) # app01.Book.Noneprint(publish_obj.book_set.all()) # <QuerySet [<Book: Book object (2)>]>print(publish_obj.book_set.all()[0].title) # 水浒# 5.查询作者是jack写过的书# 作者查询书籍------------->反向查询------------>按照表名小写或者_setauthor_obj = models.Author.objects.filter(name='tom').first()print(author_obj.book_set) # app01.Book.Noneprint(author_obj.book_set.all()) # <QuerySet []># 6.查询手机号是110的作者姓名# 作者详细查询作者--------------->反向查询------------>按照表名小写或者_setauthor_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()print(author_detail_obj.author) # Author object (1)print(author_detail_obj.author.name) 总结:1. 什么时候加_Set2. 什么时候.all()结论:当查询的结果是有多个的时候,就需要以上两个操作4.多表查询之连表查询(基于双下划线的查询)
'''多表查询之连表查询(基于双下划线的查询)'''# 1.查询jerry的手机号和作者姓名# 作者查作者详情 ----->正向查询------->按字段res = models.Author.objects.filter(name='jerry').values('author_detail__phone', 'name')print(res) # <QuerySet [{'author_detail__phone': 110, 'name': 'jerry'}]># 作者详情查作者------>反向查询-------->表名小写res = models.AuthorDetail.objects.filter(author__name='jerry').values('phone', 'author__name')print(res) # <QuerySet [{'phone': 110, 'author__name': 'jerry'}]># 2.查询书籍主键为1的出版社名称和书的名称# 书籍查出版社 ----->正向查询------->按字段res = models.Book.objects.filter(pk=1).values('publish__name', 'title')print(res) # <QuerySet [{'publish__name': '人民出版社', 'title': '三国'}]># 出版社查询书籍---------->反向查询----------->按表名小写res = models.Publish.objects.filter(book__pk=1).values('name', 'book__title')print(res) # <QuerySet [{'name': '人民出版社', 'book__title': '三国'}]># 3.查询书籍主键为1的作者姓名# 书籍查询作者------------->正向查询------------>按字段res = models.Book.objects.filter(pk=1).values('authors__name')print(res)# 作者查询书籍-------------->反向查询----------->按表名小写res = models.Author.objects.filter(book__pk=1).values('name')print(res)# # 查询书籍主键是1的作者的手机号# 书籍---->作者----->作者详情# book 正向 author 正向 author_detailres = models.Book.objects.filter(pk=2).values('authors__author_detail__phone')print(res) # <QuerySet [{'authors__author_detail__phone': 110}]>5. 聚合查询(aggregate)
sum max min avg count# sql:
select sum(price) from table group by '';# 求书籍表中得书的平均价格
select avg(price) from book;
from django.db.models import Max, Min, Sum, Avg, Count注意:以后在导模块的时候,只要是跟数据库相关的一般都在
django.db
django.db.models# res = models.Book.objects.aggregate(Avg('price'))
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Avg('price'), Count('id'))print(res)6. 分组查询annotate
# 分组查询:group by
# 分组之后只能取到分组的依据,按照什么字段分组就只能取到这个字段的值,前提是严格模式# 非严格模式就可以取到所有字段的值
# 如何设置严格模式
1. 使用命令修改查看sql_modeshow variables like '%mode%';@@select sql_mode;# 设置严格模式set global sql_mode='ONLY_FULL_GROUP_BY'
2. 使用配置文件# 1.统计每一本书的作者个数# 按照书的id来分组# select * from table group by id# res = models.Book.objects.annotate() # annotate这个关键字它就是按照models后面的这个表分组# res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('author_num', 'title')res = models.Book.objects.annotate(author_num=Count('authors')).values('author_num', 'title')print(res)# 2.统计每个出版社卖的最便宜的书的价格# res = models.Publish.objects.annotate(min_price=Min('book__price')).values('min_price', 'name')# print(res)# 3.统计不止一个作者的图书# 先按照图书分组,求出每个图书的作者个数,包括了作者个数为0或者1的等,再次过滤做这个个数大于1的res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('author_num', 'title','id')print(res)# 4.查询每个作者出的书的总价格res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('sum_price', 'name')print(res)
7. F查询
# 1. 查询卖出数大于库存数的书籍# sql: select * from table where maichu > kucun;'''F查询'''from django.db.models import F# 1. 查询卖出数大于库存数的书籍res = models.Book.objects.filter(maichu__gt=F('kucun')).all()print(res[0].title)# 2.将所有书籍的价格提升500块sql: update book set price = price+500 ;res = models.Book.objects.update(price=F('price')+500)# 3.将所有书的名称后面加上爆款两个字# 如果是更新的字符串不能够这么来写,专业的语法来写# res = models.Book.objects.update(title=F('title')+'爆款')from django.db.models.functions import Concatfrom django.db.models import Valueres = models.Book.objects.update(title=Concat(F('title'), Value('爆款')))8. Q 查询
# 适用于或者的关系查询
'''Q查询'''from django.db.models import Q# 1.查询卖出数大于100或者价格小于600的书籍# select *from table where maichu>100 or price < 600;# res = models.Book.objects.filter(maichu__gt=100, price__lt=600).all() # and关系# res = models.Book.objects.filter(Q(maichu__gt=100), Q(price__lt=600)).all() # and关系 <QuerySet []># 或# res = models.Book.objects.filter(Q(maichu__gt=100)| Q(price__lt=600)).all() # OR关系 <QuerySet []># res = models.Book.objects.filter(~Q(maichu__gt=100)| Q(price__lt=600)).all() # OR关系 <QuerySet []># 非# res = models.Book.objects.filter(~Q(maichu__gt=100)| ~Q(price__lt=600)).all() # OR关系 <QuerySet []># res = models.Book.objects.filter(~(Q(maichu__gt=100)| Q(price__lt=600))).all() # OR关系 <QuerySet []># print(res)# Q的高阶用法q = Q()q.connector = 'or'# param = requests.GET.get("param")q.children.append(("maichu__gt", 600))# q.children.append((param +"__gt", 600))q.children.append(("price__lt", 100))res = models.Book.objects.filter(q)print(res)三、django中如何开启事务
1.事务的四大特性(ACID)事务的四大特性通常简称为 ACID 特性,它们是数据库管理系统(DBMS)中用于确保事务正确执行和数据的一致性的基本属性。ACID 是由以下四个特性组成:1. **原子性(Atomicity)**:原子性指的是事务是一个不可分割的单位,要么全部执行成功,要么全部执行失败,不存在中间状态。如果事务中的任何操作失败,整个事务会被回滚到初始状态,所有已经执行的操作都会撤销,保证数据库的一致性。2. **一致性(Consistency)**:一致性指的是事务使数据库从一个一致性状态转变为另一个一致性状态。这意味着事务的执行不会破坏数据库中定义的完整性约束和规则,保持数据库数据的正确性。3. **隔离性(Isolation)**:隔离性指的是并发执行的事务之间是相互隔离的,一个事务的执行不应该影响其他事务的执行。事务的隔离性确保了每个事务都感觉自己在独立地操作数据,避免了并发执行时的数据冲突和不一致问题。4. **持久性(Durability)**:持久性指的是一旦事务被提交,其对数据库的修改是永久性的,不会因为系统崩溃或断电而丢失。已提交的事务对数据库的修改会被持久化存储,保证数据的持久性。ACID 特性确保了数据库中的事务正确执行,即使在并发访问的情况下也能维护数据的完整性和一致性。这些特性是数据库管理系统设计的基本原则,用于保证事务的可靠性和数据的可控性。2.事务的隔离级别事务的隔离级别是数据库管理系统(DBMS)中用于控制并发事务之间相互影响的程度。不同的隔离级别提供了不同的数据一致性和并发性保证。常见的事务隔离级别包括:1. **读未提交(Read Uncommitted)**:最低的隔离级别,在该级别下,事务可以读取其他事务尚未提交的数据。这可能导致脏读、不可重复读和幻读问题。2. **读已提交(Read Committed)**:在该级别下,事务只能读取其他事务已经提交的数据。这可以避免脏读问题,但仍可能出现不可重复读和幻读问题。3. **可重复读(Repeatable Read)**:在该级别下,事务在读取数据时会对其进行加锁,确保其他事务无法修改这些数据。这可以避免脏读和不可重复读问题,但仍可能出现幻读问题。4. **序列化(Serializable)**:最高的隔离级别,在该级别下,事务会对读取的每一行数据都进行加锁,确保其他事务无法读取或修改这些数据。这可以避免脏读、不可重复读和幻读问题,但会降低并发性能。不同的数据库管理系统支持不同的隔离级别,并且默认隔离级别可能因数据库而异。在使用事务时,需要根据具体需求和业务逻辑来选择合适的隔离级别,以平衡数据的一致性和并发性。需要注意的是,较高的隔离级别可能会降低数据库的并发性能,因为它需要使用更多的锁来保证数据的一致性。3.事务的几个关键1.开启事务start transaction;2. 提交事务commit;3. 回滚事务rollback;4.事务的作用:保证安全,保证多个SQL语句要么同时执行成名, 要么同时失败'''Django中如何开启事务'''from django.db import transactiontry:with transaction.atomic():# sql1# sql2...models.Book.objects.filter(maichu__gt=100, price__lt=600).update()models.Book.objects.filter(maichu__gt=100, price__lt=600).create()except Exception as e:print(e)transaction.rollback()相关文章:
、django中如何开启事务)
外键字段的增删改查、多表查询(子查询和连表查询、正反向、聚合查询、 分组查询、 F与Q查询)、django中如何开启事务
一、 外键字段的增删改查 1.多对多的外键增删改查图书和作者是多对多,借助于第三张表实现的,如果想绑定图书和作者的关系,本质上就是在操作第三方表2.如何操作第三张表问题:让你给图书添加一个作者,他俩的关系可是多对…...
【学习笔记】生成式AI(ChatGPT原理,大型语言模型)
ChatGPT原理剖析 语言模型 文字接龙 ChatGPT在测试阶段是不联网的。 ChatGPT背后的关键技术:预训练(Pre-train) 又叫自监督式学习(Self-supervised Learning),得到的模型叫做基石模型(Founda…...

【Opencv入门到项目实战】(三):图像腐蚀与膨胀操作
文章目录 1.腐蚀操作2.膨胀操作3.开运算和闭运算4.礼帽与黑帽5.梯度运算 1.腐蚀操作 腐蚀操作是图像处理中常用的一种形态学操作,我们通常用于去除图像中的噪声、分割连通区域、减小目标物体的尺寸等。腐蚀操作的原理是,在给定的结构元素下,…...
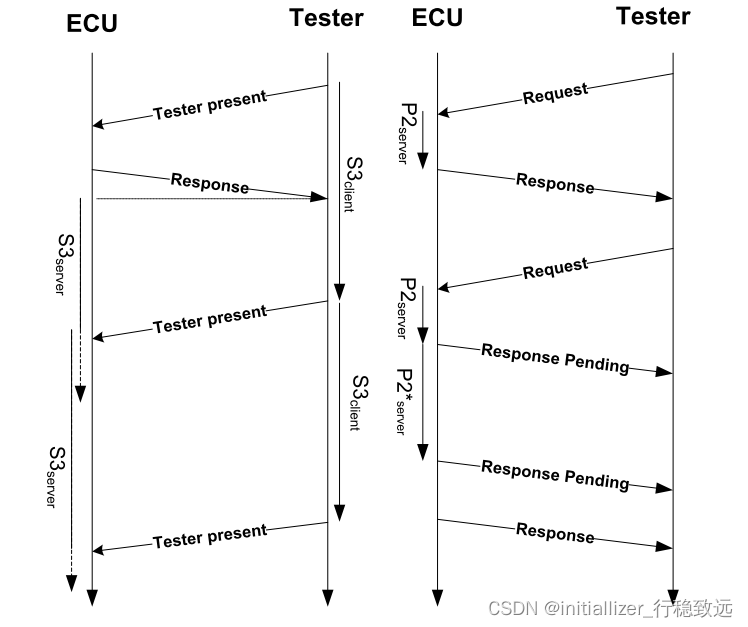
Autosar诊断系列介绍20 - UDS应用层P2Server/P2Client等时间参数解析
本文框架 1. 前言2.几个时间参数含义2.1 P2Client与P2Server2.2 P2*Client与P2*Server2.3 P3Client_Phys与P3Client_Func2.4 S3Client与S3Server 1. 前言 本系列Autosar 诊断入门介绍,会详细介绍诊断相关基础知识,如您对诊断实战有更高需求,…...
【iOS】json数据解析以及简单的网络数据请求
文章目录 前言一、json数据解析二、简单的网络数据请求三、实现访问API得到网络数据总结 前言 近期写完了暑假最后一个任务——天气预报,在里面用到了简单的网络数据请求以及json数据的解析,特此记录博客总结 一、json数据解析 JSON是一种轻量级的数据…...
Kubernetes客户端认证—— 基于ServiceAccount的JWTToken认证
1、概述 在 Kubernetes 官方手册中给出了 “用户” 的概念,Kubernetes 集群中存在的用户包括 “普通用户” 与 “ServiceAccount”, 但是 Kubernetes 没有普通用户的管理方式,通常只是将使用集群根证书签署的有效证书的用户都被视为合法用户。…...
45.ubuntu Linux系统安装教程
目录 一、安装Vmware 二、Linux系统的安装 今天开始了新的学习,Linux,下面是今天学习的内容。 一、安装Vmware 这里是在 Vmware 虚拟机中安装 linux 系统,所以需要先安装 vmware 软件,然 后再安装 Linux 系统。 所需安装文件:…...

Jmeter函数助手(一)随机字符串(RandomString)
一、目标 实现一个请求单次调用,请求体里多个集合中的相同参数(zxqs)值随机从序列{01、02、03、03、04、05、06、07、08}中取 若使用CSV数据文件、用户参数等参数化手段,单次执行请求,请求体里多个集合中的相同参数&a…...

SpringCloud之微服务API网关Gateway介绍
文章目录 1 微服务API网关Gateway1.1 网关简介1.2 Spring Cloud Gateway介绍1.3 Gateway特性1.4 Gateway核心概念1.4.1 路由1.4.1.1 定义1.4.1.2 动态路由 1.4.2 断言1.4.2.1 默认断言1.4.2.2 自定义Predicate 1.4.3 过滤器1.4.3.1 默认过滤器1.4.3.2 自定义Filter(…...

机器学习入门之 pandas
pandas 有三种数据结构 一种是 Series 一种是 Dataframe import pandas as pd import numpy as np score np.random.randint(0,100,[10,5])score[0,0] 100Datascore pd.DataFrame(score)subject ["语文","数学","英语","物理&quo…...
Django之JWT库与SimpleJWT库的使用
Django之JWT库与SimpleJWT库的使用 JWTJWT概述头部(header)载荷(payload)签名(signature) Django使用JWT说明jwt库的使用安装依赖库配置settings.py文件配置urls.py文件创建视图配置权限 SimpleJWT库的使用安装SimpleJWT库配置Django项目配置路由创建用户接口测试身份认证自定义…...
Jmeter远程服务模式运行时引用csv文件的路径配置
问题 在使用jmeter过程中,本机的内存等配置不足,启动较多的线程时,可以采用分布式运行。 在分布式运行的时候,jmeter会自动将脚本从master主机发送到remote主机上,所以不需要考虑将脚本拷贝到remote主机。但是jmeter…...

《OWASP代码审计》学习——注入漏洞审计
一、注入的概念 注入攻击允许恶意用户向应用程序添加或注入内容和命令,以修改其行为。这些类型的攻击是常见且广泛的,黑客很容易测试网站是否易受攻击,攻击者也很容易利用这些攻击。如今,它们在尚未更新的遗留应用程序中非常常见…...
Linux虚拟机中安装MySQL5.6.34
目录 第一章、xshell工具和xftp的使用1.1)xshell下载与安装1.2)xshell连接1.3)xftp下载安装和连接 第二章、安装MySQL5.6.34(不同版本安装方式不同)2.1)关闭防火墙,传输MySQL压缩包到Linux虚拟机2.2&#x…...
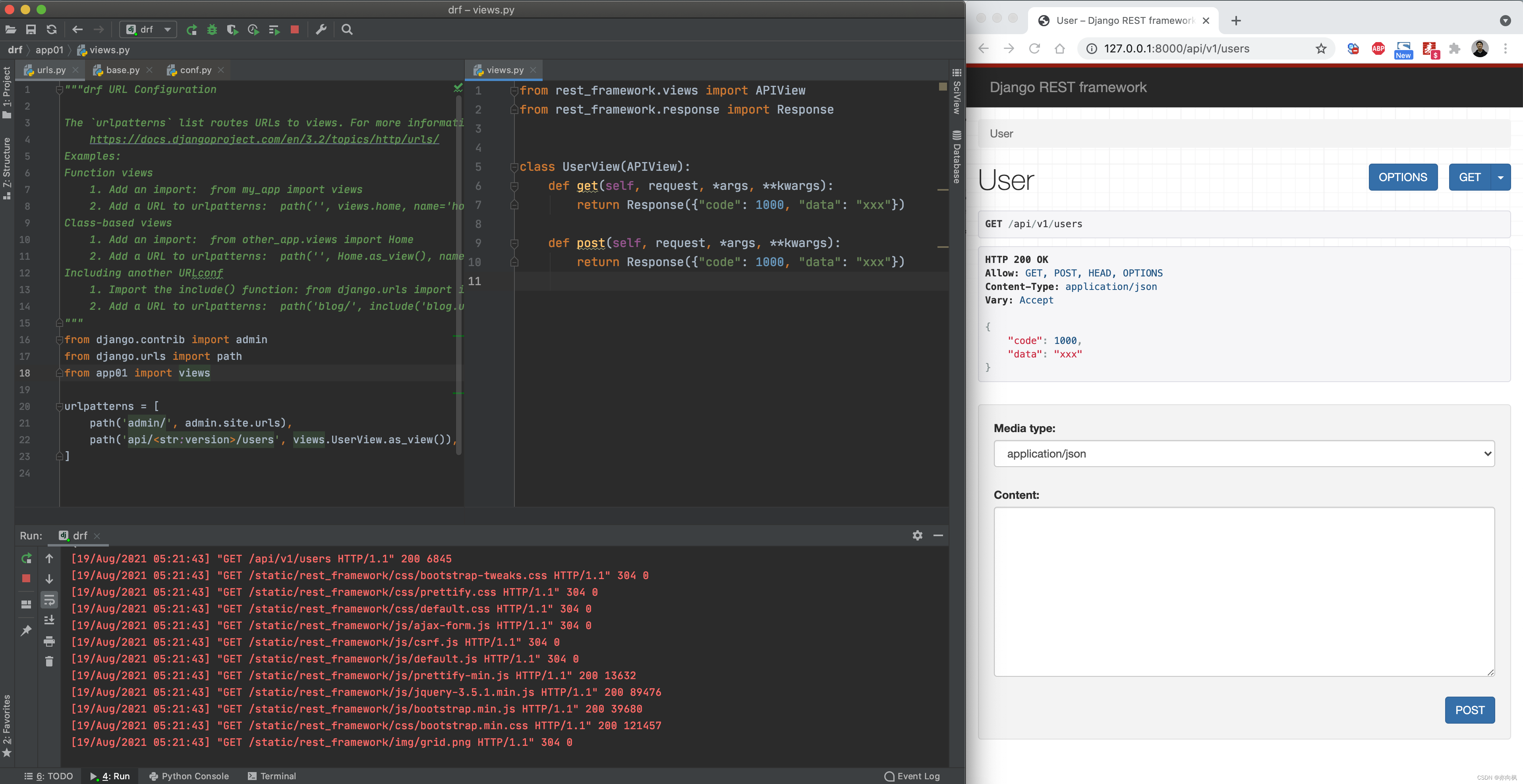
Django的FBV和CBV
Django的FBV和CBV 基于django开发项目时,对于视图可以使用 FBV 和 CBV 两种模式编写。 FBV,function base views,其实就是编写函数来处理业务请求。 from django.contrib import admin from django.urls import path from app01 import view…...

[每周一更]-(第57期):用Docker、Docker-compose部署一个完整的前后端go+vue分离项目
文章目录 1.参考项目2.技能点3.GO的Dockerfile配置后端的结构如图Dockerfile先手动docker调试服务是否可以启动报错 4.Vue的Dockerfile配置前端的结构如图nginx_docker.confDockerfile构建 5.docker-compose 整合前后端docker-compose.yml错误记录(1)ip端…...
springboot-mybatis的增删改查
目录 一、准备工作 二、常用配置 三、尝试 四、增删改查 1、增加 2、删除 3、修改 4、查询 五、XML的映射方法 一、准备工作 实施前的准备工作: 准备数据库表 创建一个新的springboot工程,选择引入对应的起步依赖(mybatis、mysql驱动…...

HTML5(H5)的前生今世
目录 概述HTML5与其他HTML的区别CSS3与其他CSS版本的区别总结 概述 HTML5是一种用于构建和呈现网页的最新标准。它是HTML(超文本标记语言)的第五个版本,于2014年由万维网联盟(W3C)正式推出。HTML5的前身可以追溯到互联…...
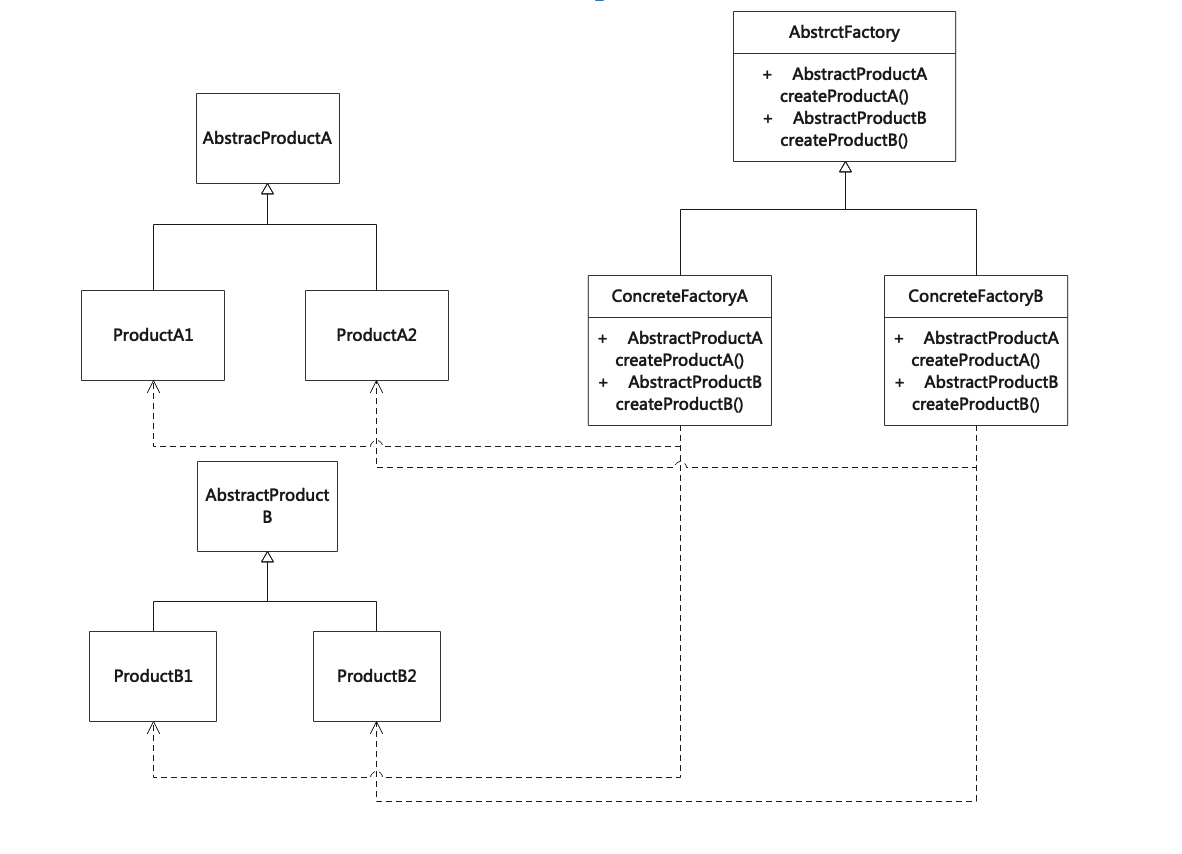
抽象工厂模式(Abstract Factory)
抽象工厂模式提供一个创建一组相关或相互依赖的对象的接口,而无须指定它们具体的类,每个子类可以生产一系列相关的产品。 The Abstract Factory Pattern is to provide an interface for creating families of related or dependent objects without s…...

Java 实现下载文件工具类
package com.liunian.utils;import lombok.SneakyThrows;import javax.servlet.ServletOutputStream; import javax.servlet.http.HttpServletResponse; import java.io.File; import java.io.FileInputStream;/*** ClassName DownloadFileUtils* Author liuyan 下载文件工具类…...

11鲲鹏系列总结篇:工程师读懂这套内容,解锁算力技术破局全能力
鲲鹏系列总结篇:工程师读懂这套内容,解锁算力技术破局全能力 一、写给每一位工程师:如何快速看懂这10篇硬核内容 作为常年和代码、架构、算力、落地项目打交道的工程师,不用被“架构师级”“顶层战略”的字眼劝退,这套…...

Ubuntu 24.04 + Wine 9.0 完美运行《文明5》中文版:DXVK配置全攻略
Ubuntu 24.04 Wine 9.0 完美运行《文明5》中文版:DXVK配置全攻略 当Linux游戏兼容性技术遇上经典策略游戏,会碰撞出怎样的火花?作为一款深度考验玩家战略思维的回合制游戏,《文明5》在Windows平台早已积累庞大粉丝群体。而如今&a…...

零基础上手Qwen-Image-2512-ComfyUI,从环境搭建到实际出图完整教程
零基础上手Qwen-Image-2512-ComfyUI,从环境搭建到实际出图完整教程 你是否曾经被AI绘画的高门槛劝退?复杂的安装流程、晦涩的参数设置、繁琐的模型下载...这些障碍让许多创意人士望而却步。今天,我们将彻底改变这一现状,带你从零…...

51单片机项目省电实战:除了掉电模式,你的STC89C52还能这样‘偷懒’降功耗
51单片机低功耗设计实战:从电路优化到代码框架的全方位策略 在电池供电的物联网设备中,51单片机因其高性价比依然占据重要地位。但许多开发者在使用STC89C52这类经典型号时,往往只关注了手册中提到的掉电模式,却忽略了系统级功耗优…...

前端开发环境搭建:Node.js, npm, VSCode
前端开发环境搭建:Node.js、npm与VSCode指南 在当今快速发展的前端开发领域,一个高效、稳定的开发环境是提升生产力的关键。Node.js、npm和VSCode作为现代前端开发的三大核心工具,能够帮助开发者轻松管理依赖、运行脚本以及编写高质量代码。…...
:3类高危组合+2种隐性技术债触发阈值)
【限时解密】某千亿级AI平台内部禁用的技术选型路径(附决策树红蓝对抗推演):3类高危组合+2种隐性技术债触发阈值
第一章:AI原生软件研发技术选型决策树的元模型构建 2026奇点智能技术大会(https://ml-summit.org) AI原生软件的研发已超越传统框架适配阶段,进入以语义驱动、能力可组合、生命周期自演进为特征的新范式。元模型作为该范式的技术选型中枢,需…...

终极指南:如何快速免费恢复加密压缩包密码
终极指南:如何快速免费恢复加密压缩包密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 您是否曾经遇到过这种情况࿱…...

C++ 右值引用与程序优化
一、左值与右值基础概念1. 左值(Lvalue)定义:能取地址、可被修改(除非用const修饰)的表达式,有持久的生命周期。示例:int a 10; // a是左值,&a合法 const int b 20; // b是con…...

3分钟从文档到演示文稿:PPTAgent智能生成完整指南
3分钟从文档到演示文稿:PPTAgent智能生成完整指南 【免费下载链接】PPTAgent An Agentic Framework for Reflective PowerPoint Generation 项目地址: https://gitcode.com/gh_mirrors/pp/PPTAgent 你是否还在为制作演示文稿而烦恼?PPTAgent是一款…...
)
告别复制粘贴!用Zotero+BibTeX一键搞定IEEE会议论文参考文献(Better BibTeX插件实战)
科研效率革命:ZoteroBibTeX全自动文献管理方案 在撰写学术论文时,参考文献管理往往是耗时又容易出错的一环。特别是对于需要频繁投稿IEEE会议的研究人员来说,手动复制粘贴bibtex条目、整理citation key的过程既枯燥又低效。想象一下ÿ…...