大数据课程G1——Hbase的概述
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解HIve的概念;
⚪ 了解HIve与数据库的区别;
⚪ 了解HIve的特点;
一、简介
1. 概述
1. HBase原本是由Yahoo!公司开发后来贡献给了Apache的一套开源的、基于Hadoop的、分布式的、可扩展的、非关系型数据库。
2. 如果需要对大量数据进行随机且实时读写,那么可以考虑使用HBase。
3. HBase能够管理非常大的表:billions of rows * millions of columns。
4. HBase是仿照Google的Big Table来进行实现的,因此,HBase和BigTable的原理几乎一致,只有实现语言不同。HBase是使用Java语言实现的,BigTable使用的是C语言实现的 - HBase最终将数据落地到HDFS上。
5. HBase提供了2个大版本,并且2个版本都在同时更新。其中,Hadoop3.1.3版本支持的是HBase2.2.X及以上版本。
6. HBase作为非关系型数据库,不支持标准的SQL语法,提供了一套全新的命令。
7. HBase能够存储稀疏类型的数据,也因此HBase能够存储结构化(数据本身有结构,经过解析之后,能够用传统数据库中的一个或者几个表来存储)和半结构化数据(数据本身有结构,但是解析之后无法用传统数据库中的表来存储)。
8. HBase本身作为数据库,提供了完整的增删改查的功能。HBase基于HDFS来进行存储,HDFS的特点是允许一次写入多次读取,不允许修改而允许追加写入,但是HBase提供了"改"功能,HBase如何实现"改"功能的?- HBase实际上并没有去修改写入的数据,而是在文件末尾去追加数据。HBase会对写入的每条数据自动添加一个时间戳,当用户获取数据的时候,HBase自动返回最新的数据,那么从用户角度来看,就是发生了数据的修改。
9. 在HBase中,数据的每一个时间戳称之为是一个版本。
10. 如果要锁定唯一的一条数据,那么需要通过行键+列族+列+时间戳这四个维度来锁定,这种结构称之为是一个Cell(单元格)。
11. HBase中的表在创建的时候,如果不指定,那么只对外提供一个版本的数据。
12. 如果建好表之后再修改可以获取的版本,那么已经添加的数据不起作用。
13. 即使表允许对外获取多个版本的数据,在获取的时候如果不指定,依然只获取一个版本的数据。
2. 基本概念
1. Rowkey:行键
a. 在HBase中没有主键的概念,取而代之的是行键。
b. 不同于传统的关系型数据库,在HBase中,定义表的时候不需要指定行键列,而是在添加数据的时候来手动添加行键。
c. HBase默认会对行键来进行排序,按照字典序排序。
2. Column Family:列族/列簇
a. 在HBase中,没有表关联的概念,取而代之的是用列族来进行设计。
b. 在HBase中,一个表中至少要包含1个列族,可以包含多个列族,理论上不限制列族的数量。
c. 在HBase中强调列族,但是不强调列 - 在定义表的时候必须定义列族,但是列可以动态增删,一个列族中可以包含0到多个列。
3. namespace:名称空间
a. 在HBase中没有database的概念,取而代之的是namespace。
b. 在HBase启动的时候,自带了两个空间:default和hbase。hbase空间下放的是HBase的基本信息;在建表的时候如果不指定,则表默认是放在default空间下。
3. 基本命令
| 命令 | 解释 |
| processlist | 查看当前HBase在执行的任务 |
| status | 查看HBase的运行状态 |
| version | 查看HBase的版本 |
| whoami | 查看HBase的当前用户 |
| create 'person', {NAME => 'basic'}, {NAME => 'info'}, {NAME => 'other'} 或者 create 'person', 'basic', 'info', 'other' | 建立一个person表,包含3个列族:basic,info,other |
| append 'person', 'p1', 'basic:name', 'Bob' | 在person表中添加一个行键为p1的数据,向basic列族的name列中添加数据 |
| get 'person', 'p1' | 获取指定行键的数据 |
| get 'person', 'p1', {COLUMN => 'basic'} 或者 get 'person', 'p1', 'basic' | 获取指定行键指定列族的数据 |
| get 'person', 'p1', {COLUMN => ['basic', 'info']} 或者 get 'person', 'p1', 'basic', 'info' | 获取指定行键多列族的数据 |
| get 'person', 'p1', {COLUMN => 'basic:name'} 或者 get 'person', 'p1', 'basic:name' | 获取指定行键指定列的数据 |
| scan 'person' | 扫描整表 |
| scan 'person', {COLUMNS => 'basic'} | 获取指定列族的数据 |
| scan 'person', {COLUMNS => ['basic', 'info']} | 获取多列族的数据 |
| scan 'person', {COLUMNS => ['basic:name', 'other:address']} | 获取多个列的数据 |
| put 'person', 'p1', 'basic:age', 20 | 修改数据 |
| delete 'person', 'p1', 'other:adderss' 或者 deleteall 'person', 'pb', 'basic:name' | 删除指定行键指定列族的指定列 |
| deleteall 'person', 'p1' | 删除指定行键的所有数据 |
| create 'students', {NAME => 'basic', VERSIONS => 3}, {NAME => 'info', VERSIONS => 4} | 指定每一个列族允许对外获取的版本数量 |
| desc 'students' 或者 describe 'students' | 描述表 |
| get 'students', 's1', {COLUMN => 'basic:age', VERSIONS => 3} | 获取指定行键指定列的指定数量版本的数据 |
| scan 'students', {COLUMNS => 'basic:age', VERSIONS => 3} | 获取指定列的指定数量版本的数据 |
| count 'person' | 统计person表中行键的个数 |
| get_splits 'person' | 获取person表对应的HRegion的个数 |
| truncate 'person' | 摧毁重建person表 |
| list_namespace | 查看所有的空间 |
| create_namespace 'demo' | 创建demo空间 |
| create 'demo:users', 'basic' | 在demo空间下创建users表 |
| list_namespace_tables 'demo' | 获取demo空间下的所有表 |
| describe_namespace 'demo' | 描述demo空间 |
| drop_namespace 'demo' | 删除demo空间,要求这个空间为空 |
| disable 'demo:users' | 禁用表 |
| drop 'demo:users' | 删除表 |
| enable 'person' | 启用表 |
| exists 'users' | 判断表是否存在 |
| is_disabled 'person' | 判断person表是否被禁用 |
| is_enabled 'person' | 判断person表是否被启用 |
| list | 查看所有空间下的所有的表 |
| locate_region 'person', 'p1' | 定位p1行键所在的HRegion的位置 |
| show_filters | 展现所有的过滤器 |
| disable_all 'demo:.*' | 禁用demo空间下的所有的表 |
| drop_all 'demo.*' | 删除demo空间下的所有的表 |
| enable_all 'demo:.*' | 启用demo空间下的所有的表 |
4. Hive和HBase的比较
1. Hive本质上是一个用于进行数据仓库管理的工具,在实际过程中经常用于对数据进行分析和清洗,提供了相对标准的SQL结构,底层会将SQL转化为MapReduce来执行,因此Hive的效率相对较低,更适合于离线开发的场景。Hive一般针对历史数据进行分析,一般只提供增加和查询的能力,一般不会提供修改和删除的功能。
2. HBase本质上是一个非关系型数据库,在实际过程中,用于存储数据。因为HBase的读写效率较高,吞吐量较大,因此一般使用HBase来存储实时的数据,最终数据会落地到HDFS上。HBase作为数据库,提供了完整的增删改查的能力,但是相对而言,HBase的事务能力较弱。HBase不支持SQL,提供了一套完整的命令。
3. 总结:Hive强调的是分析能力,但是HBase强调的是存储能力,相同的地方在于两者都是利用HDFS来存储数据。
二、安装
1. 硬件环境:至少需要3台虚拟机或者云主机,Centos7.5及以上版本,至少需要双核,至少4G内存+20G磁盘。
2. 软件环境:JDK1.8+Zookeeper3.5.7+Hadoop3.1.3。
3. 进入/home/software目录下。
cd /home/software
4. 上传或者下载HBase的安装包,云主机的下载地址。
wget http://bj-yzjd.ufile.cn-north-02.ucloud.cn/hbase-2.4.2-bin.tar.gz
5. 解压。
tar -xvf hbase-2.4.2-bin.tar.gz
6. 进入HBase的配置目录
cd hbase-2.4.2/conf
7. 编辑文件。
vim hbase-env.sh
#添加如下属性
export JAVA_HOME=/home/software/jdk1.8
export HBASE_MANAGES_ZK=false
#保存退出,重新生效
source hbase-env.sh
8. 编辑文件。
vim hbase-site.xml
#添加如下内容
<!--指定HBase在HDFS上的数据存储目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:9000/hbase</value>
</property>
<!--开启HBase的分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--配置Zookeeper的连接地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
9. 编辑文件。
vim regionservers
#添加当前的三台主机的主机名
10. 需要将Hadoop的核心配置文件拷贝到当前的HBase的配置目录下。
cp /home/software/hadoop-3.1.3/etc/hadoop/core-site.xml ./
11. 回到software目录下,远程拷贝给另外两台云主机。
cd /home/software/
scp -r hbase-2.4.2 root@hadoop02:$PWD
scp -r hbase-2.4.2 root@hadoop03:$PWD
12. 配置三台主机的环境变量。
vim /etc/profile
#在文件末尾添加
export HBASE_HOME=/home/software/hbase-2.4.2
export PATH=$PATH:$HBASE_HOME/bin
#保存退出,重新生效
source /etc/profile
13. 启动Zookeeper。
cd /home/software/apache-zookeeper-3.5.7-bin/bin
sh zkServer.sh start
sh zkServer.sh status
14. 在第一台主机上启动Hadoop的HDFS。
start-dfs.sh
15. 在第一台主机上启动HBase。
start-hbase.sh
16. 可以通过IP:16010来访问HBase的界面。
相关文章:

大数据课程G1——Hbase的概述
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解HIve的概念; ⚪ 了解HIve与数据库的区别; ⚪ 了解HIve的特点; 一、简介 1. 概述 1. HBase原本是由Yahoo!公司开发后来贡献给了…...

第三章 图论 No.2单源最短路之虚拟源点,状压最短路与最短路次短路条数
文章目录 1137. 选择最佳线路1131. 拯救大兵瑞恩1134. 最短路计数383. 观光 dp是特殊的最短路,是无环图(拓扑图)上的最短路问题 1137. 选择最佳线路 1137. 选择最佳线路 - AcWing题库 // 反向建图就行 #include <iostream> #include…...

汉诺塔问题
一本通1205:汉诺塔问题 【题目描述】 约19世纪末,在欧州的商店中出售一种智力玩具,在一块铜板上有三根杆,最左边的杆上自上而下、由小到大顺序串着由64个圆盘构成的塔。目的是将最左边杆上的盘全部移到中间的杆上,条件…...
Java on Azure Tooling 6月更新|标准消费和专用计划及本地存储账户(Azurite)支持
作者:Jialuo Gan - Program Manager, Developer Division at Microsoft 排版:Alan Wang 大家好,欢迎阅读 Java on Azure 工具的六月更新。在本次更新中,我们将介绍 Azure Spring Apps 标准消费和专用计划支持以及本地存储账户&…...
-网络嗅探-黑盒监控)
Prometheus(八)-网络嗅探-黑盒监控
介绍 Blackbox Exporter是Prometheus社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP以及ICMP的方式对网络进行探测。用户可以直接使用go get命令获取Blackbox Exporter源码并生成本地可执行文件: go get prometheus…...

modbus TCP 通信测试
modbus TCP 通信测试 读取单个或多个线圈 发送指令:00 00 00 00 00 06 00 01 03 10 00 08 00 00 00 00 00 06 00 01 03 10 00 08 事务 处理 标识 协议 标识 长度 单元 标识 功能码 起始 线圈 地址 线圈 个数 06:后面的字节长度。 01&am…...

GDB Debug
使用gdb带着参数启动程序 在gdb中启动程序并传递命令行参数: gdb ./my_program (gdb) run arg1 arg2 arg3 这将在gdb中启动程序"my_program",并将参数"arg1"、"arg2"和"arg3"传递给程序。 在启动gdb之前&…...

【项目流程】前端项目的开发流程
1. 项目中涉及的所有角色及其职责 - PM 产品经理 产品经理(Product Manager,简称PM)负责明确和定义产品的愿景和战略,与客户、用户、业务部门和其他利益相关者进行沟通,收集并分析他们的需求和期望。负责制定产品的详…...

JS监听浏览器关闭、刷新及切换标签页触发事件
蛮简单的东西,知道就会,不知道就不会,没什么逻辑可言。简单记录一下,只为加深点儿印象。 visibilitychange visibilitychange可以监听到浏览器的切换标签页。 直接上代码: <script>document.addEventListe…...

Unity 引擎做残影效果——3、顶点偏移方式
Unity实现残影效果 大家好,我是阿赵。 继续讲Unity引擎的残影做法。这次的残影效果和之前两种不太一样,是通过顶点偏移来实现的。 具体的效果是这样: 与其说是残影,这种效果更像是移动速度很快时造成的速度线,所以在移…...

【Linux】权限
1、shell命令以及运行原理 Linux 严格意义上说的是一个操作系统,我们称之为“核心(kernel)“ ,但我们一般用户,不能直接使用 kernel。而是通过 kernel 的“外壳”程序,也就是所谓的shell,来与 k…...

Excel导入日期格式时自动转为五位数文本
问题描述:Excel导入数据时,当数据是日期可能会存在问题,日期格式转为文本了,例如“2023-07-31”接收时变为“45138”,导致后端解析日期出错,无法导入。 解决方法: 方法一:将Excel日…...

Mac使用brew安装软件报错
在使用brew安装软件时报错Failed to upgrade Homebrew Portable Ruby! brew install --cask --appdir/Applications docker> Downloading https://ghcr.io/v2/homebrew/portable-ruby/portable-ruby/blobs/sha256:0cb1cc7af109437fe0e020c9f3b7b95c3c709b140bde9f991ad2c143…...

Android 实现MQTT客户端,用于门禁消息推送
添加MQTT依赖 implementation ‘org.eclipse.paho:org.eclipse.paho.client.mqttv3:1.2.2’ implementation ‘org.eclipse.paho:org.eclipse.paho.android.service:1.1.1’ 在Manifest清单文件中添加服务 <service android:name"org.eclipse.paho.android.service.Mq…...

跨境电商的广告推广怎么做?7个方法
在跨境电商竞争日趋激烈的市场环境下,跨境电商店铺引流成了制胜关键点。这里给大家分享一套引流推广的方法。 一、搜索引擎营销推广 搜索引擎有两个最大的优点是更灵活、更准确。搜索引擎营销的目标定位更精确,且不受时间和地理位置上的限制࿰…...

《Java-SE-第二十八章》之CAS
前言 在你立足处深挖下去,就会有泉水涌出!别管蒙昧者们叫嚷:“下边永远是地狱!” 博客主页:KC老衲爱尼姑的博客主页 博主的github,平常所写代码皆在于此 共勉:talk is cheap, show me the code 作者是爪哇岛的新手,水平很有限&…...

git之reflog分析
写在前面 本文一起看下reflog命令。 1:场景描述 在开发的过程中,因为修改错误,想要通过git reset命令恢复到之前的某个版本,但是选择提交ID错误,导致多恢复了一个版本,假定,该版本对应的内容…...
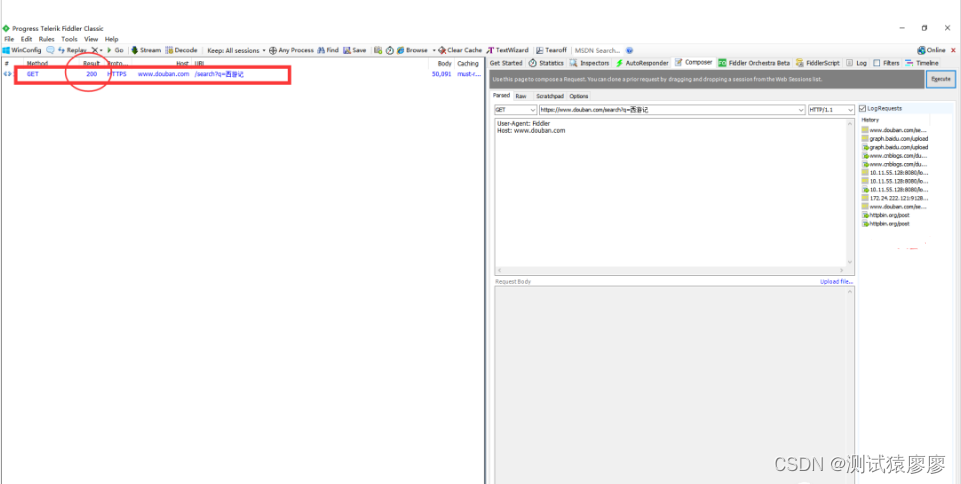
《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(18)-Fiddler如何接口测试,妈妈再也不担心我不会接口测试了
1.简介 Fiddler最大的优势在于抓包,我们大部分使用的功能也在抓包的功能上,fiddler做接口测试也是非常方便的。 领导或者开发给你安排接口测试的工作任务,但是没有给你接口文档(由于开发周期没有时间出接口文档)&…...

Oracle open JDK和 Amazon Corretto JDK的区别
Oracle OpenJDK和Amazon Corretto JDK都是基于Java开放源代码项目的发行版,它们之间有一些区别。 1. 来源:Oracle OpenJDK是由Oracle公司领导和支持的,它是Java的官方参考实现之一。而Amazon Corretto JDK是由亚马逊公司开发和支持的…...
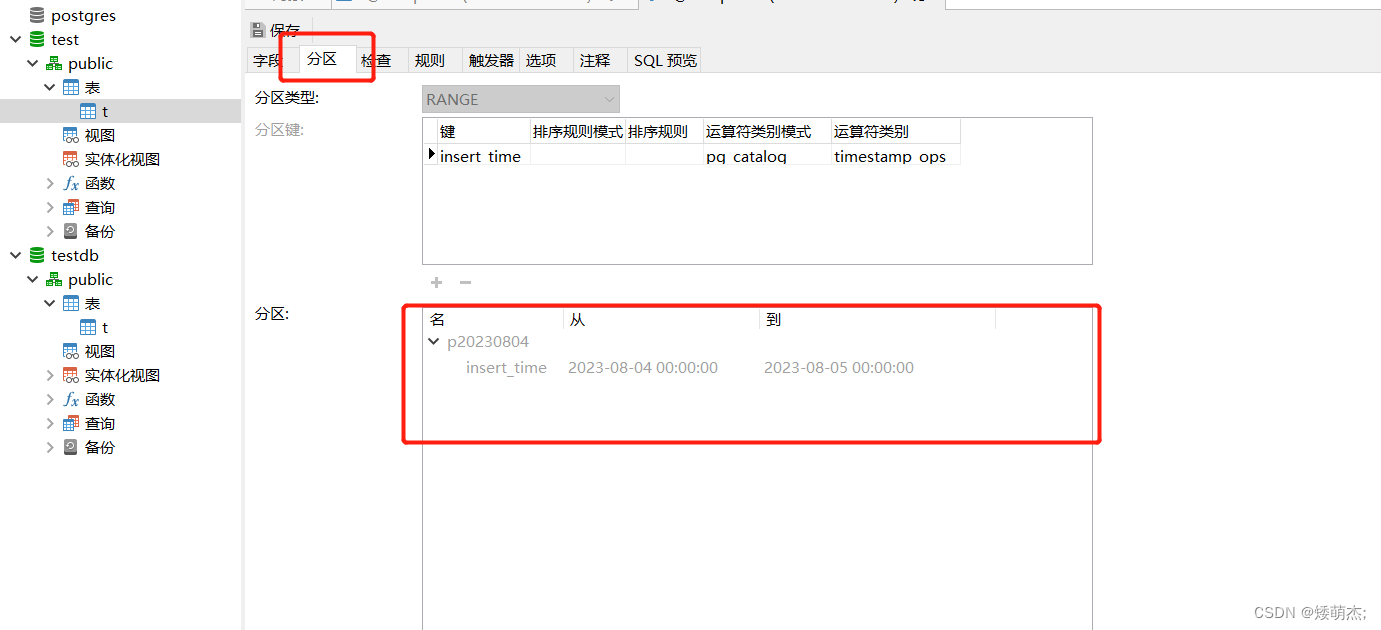
Spark写PGSQL分区表
这里写目录标题 需求碰到的问题格式问题分区问题(重点) 解决完整代码效果 需求 spark程序计算后的数据需要往PGSQL中的分区表进行写入。 碰到的问题 格式问题 使用了字符串格式,导致插入报错。 val frame df.withColumn("insert_t…...

deepin系统更换镜像源
deepin更换镜像源的操作 392 cd /etc/393 ls394 ls395 cd apt/396 ls397 cp sources.list sources.list_backup398 vim sources.list399 apt-get clean400 apt-get update401 apt-get upgrade402 history 20 rootZZM-PC:/etc/apt# 对应上面的vim操作 rootZZM-PC:/et…...

Qwen3-VL-4B Pro应用场景:电商商品识别、学习资料解读,真实案例分享
Qwen3-VL-4B Pro应用场景:电商商品识别、学习资料解读,真实案例分享 1. 项目简介与核心能力 Qwen3-VL-4B Pro是基于阿里通义千问Qwen3-VL-4B-Instruct模型构建的高性能视觉语言模型服务。相比轻量版2B模型,4B版本在视觉语义理解和逻辑推理能…...

如何在不安装Steam的情况下获取创意工坊模组
如何在不安装Steam的情况下获取创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 对于许多游戏爱好者来说,Steam创意工坊是一个宝库,里面充满…...

告别杂音!利用ES7210阵列麦克风提升RK3288设备录音质量的实战优化
智能硬件音频革命:ES7210阵列麦克风在RK3288平台的高清降噪实战 当会议室里的空调嗡嗡作响,当孩子在隔壁房间嬉戏打闹,当窗外的汽车鸣笛此起彼伏——这些日常环境噪音是否总让你的语音交互设备"听不清"用户指令?传统单…...

如何快速掌握Node.js MySQL驱动:纯JavaScript实现的终极指南
如何快速掌握Node.js MySQL驱动:纯JavaScript实现的终极指南 【免费下载链接】mysql A pure node.js JavaScript Client implementing the MySQL protocol. 项目地址: https://gitcode.com/gh_mirrors/my/mysql 前言 在Node.js生态中,数据库连接…...

DeepSeek-OCR-2参数详解:--max_pages --batch_size --conf_threshold 高级调优指南
DeepSeek-OCR-2参数详解:--max_pages --batch_size --conf_threshold 高级调优指南 1. 引言:为什么需要调优参数? 如果你用过DeepSeek-OCR-2,可能已经体验过它强大的文档解析能力。但你是否遇到过这样的情况:处理多页…...

Qwen3-ASR-1.7B在Windows下的WSL2部署教程
Qwen3-ASR-1.7B在Windows下的WSL2部署教程 1. 开篇:语音识别新选择 如果你正在Windows上寻找一个好用的语音识别工具,Qwen3-ASR-1.7B可能是个不错的选择。这个模型支持30种语言和22种中文方言的识别,效果相当不错。最重要的是,它…...

告别复杂配置:用Chainlit前端5分钟体验Qwen3-14B文本生成
告别复杂配置:用Chainlit前端5分钟体验Qwen3-14B文本生成 1. 为什么选择Qwen3-14B_int4_awq 如果你正在寻找一个既强大又易于部署的文本生成模型,Qwen3-14B_int4_awq绝对值得考虑。这个模型基于Qwen3-14B进行int4的awq量化,通过AngelSlim技…...

告别代码移植烦恼:STM32CubeMX 6.4.0 + STM32F407ZGT6 + YT8512C PHY芯片的LWIP网络配置全攻略
STM32F407ZGT6与YT8512C PHY芯片的LWIP网络适配实战指南 当硬件工程师将开发板上的PHY芯片从常见型号更换为YT8512C时,许多基于标准模板的LWIP网络代码会突然失效。这不是代码本身的问题,而是PHY芯片差异导致的底层驱动不匹配现象。本文将深入剖析YT8512…...

Emscripten构建优化指南:针对不同目标平台的终极优化策略
Emscripten构建优化指南:针对不同目标平台的终极优化策略 【免费下载链接】emscripten Emscripten: An LLVM-to-WebAssembly Compiler 项目地址: https://gitcode.com/gh_mirrors/em/emscripten Emscripten是一个强大的LLVM到WebAssembly编译器,它…...