【大模型】开源且可商用的大模型通义千问-7B(Qwen-7B)来了
【大模型】开源且可商用的大模型通义千问-7B(Qwen-7B)来了
- 新闻
- 通义千问 - 7B 介绍
- 评测表现
- 快速使用
- 环境要求
- 安装相关的依赖库
- 推荐安装flash-attention来提高你的运行效率以及降低显存占用
- 使用 Transformers 运行模型
- 使用 ModelScope 运行模型
- 量化
- 长文本理解
- 参考
新闻
2023年8月3日 在魔搭社区(ModelScope)和Hugging Face同步推出Qwen-7B和Qwen-7B-Chat模型。
通义千问 - 7B 介绍
通义千问-7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。Qwen-7B系列模型的特点包括:
- 大规模高质量预训练数据:我们使用了超过2.2万亿token的自建大规模预训练数据集进行语言模型的预训练。数据集包括文本和代码等多种数据类型,覆盖通用领域和专业领域。
- 优秀的模型性能:相比同规模的开源模型,Qwen-7B在多个评测数据集上具有显著优势,甚至超出12-13B等更大规模的模型。评测评估的能力范围包括自然语言理解与生成、数学运算解题、代码生成等。
- 更好地支持多语言:基于更大词表的分词器在分词上更高效,同时它对其他语言表现更加友好。用户可以在Qwen-7B的基础上更方便地训练特定语言的7B语言模型。
- 8K的上下文长度:Qwen-7B及Qwen-7B-Chat均能支持8K的上下文长度, 允许用户输入更长的prompt。
- 支持插件调用:Qwen-7B-Chat针对插件调用相关的对齐数据做了特定优化,当前模型能有效调用插件以及升级为Agent。
- GitHub 地址
https://github.com/QwenLM/Qwen-7B - huggingface 地址
https://huggingface.co/Qwen/Qwen-7B-Chat
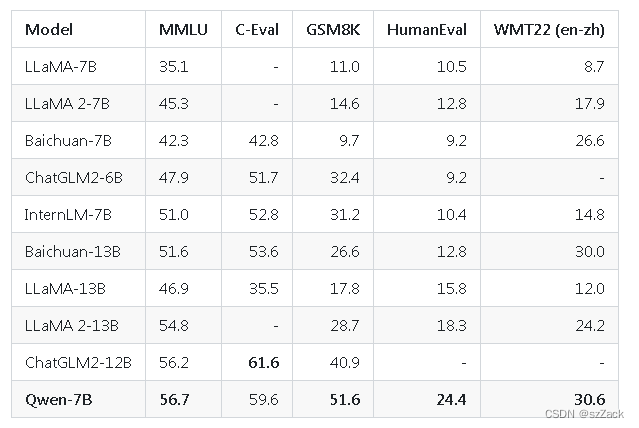
评测表现
Qwen-7B在多个全面评估自然语言理解与生成、数学运算解题、代码生成等能力的评测数据集上,包括MMLU、C-Eval、GSM8K、HumanEval、WMT22等,均超出了同规模大语言模型的表现,甚至超出了如12-13B参数等更大规模的语言模型。
快速使用
环境要求
pytorch>=1.12transformers==4.31.0
安装相关的依赖库
pip install transformers==4.31.0 accelerate tiktoken einops
推荐安装flash-attention来提高你的运行效率以及降低显存占用
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
pip install csrc/layer_norm
pip install csrc/rotary
使用 Transformers 运行模型
先判断当前机器是否支持BF16,命令如下所示:
import torch
torch.cuda.is_bf16_supported()
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
再进行测试:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig# 请注意:我们的分词器做了对特殊token攻击的特殊处理。因此,你不能输入诸如<|endoftext|>这样的token,会出现报错。
# 如需移除此策略,你可以加入这个参数`allowed_special`,可以接收"all"这个字符串或者一个特殊tokens的`set`。
# 举例: tokens = tokenizer(text, allowed_special="all")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# 默认使用fp32精度
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参# 第一轮对话 1st dialogue turn
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。# 第二轮对话 2nd dialogue turn
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。# 第三轮对话 3rd dialogue turn
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
使用 ModelScope 运行模型
魔搭(ModelScope)是开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品。使用ModelScope同样非常简单,代码如下所示:
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope import snapshot_downloadmodel_id = 'QWen/qwen-7b-chat'
revision = 'v1.0.0'model_dir = snapshot_download(model_id, revision)pipe = pipeline(
task=Tasks.chat, model=model_dir, device_map='auto')
history = Nonetext = '浙江的省会在哪里?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
text = '它有什么好玩的地方呢?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
量化
还支持量化,详情查看:【https://github.com/QwenLM/Qwen-7B/blob/main/README_CN.md】
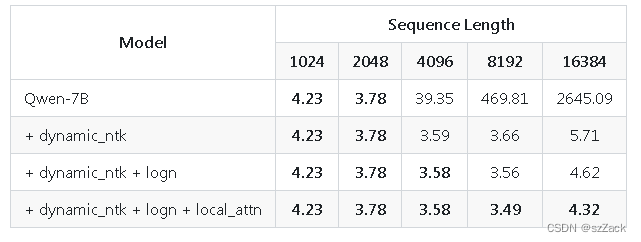
长文本理解
我们引入了NTK插值、窗口注意力、LogN注意力缩放等技术来提升模型的上下文长度并突破训练序列长度的限制。我们的模型已经突破8K的序列长度。通过arXiv数据集上的语言模型实验,我们发现Qwen-7B能够在长序列的设置下取得不错的表现。
参考
- https://github.com/QwenLM/Qwen-7B
- https://huggingface.co/Qwen/Qwen-7B-Chat
相关文章:
【大模型】开源且可商用的大模型通义千问-7B(Qwen-7B)来了
【大模型】开源且可商用的大模型通义千问-7B(Qwen-7B)来了 新闻通义千问 - 7B 介绍评测表现快速使用环境要求安装相关的依赖库推荐安装flash-attention来提高你的运行效率以及降低显存占用使用 Transformers 运行模型使用 ModelScope 运行模型 量化长文本…...

SQL分类及通用语法数据类型
一、SQL分类 DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML: 数据操作语言,用来对数据库表中的数据进行增删改DQL: 数据查询语言,用来查询数据库中表的记录DCL: 数据控制语言,用来创建数据库…...

亿欧智库:2023中国功效型护肤产品成分解析研究报告(附下载
关于报告的所有内容,公众【营销人星球】获取下载查看 核心观点 消费端:“纯净美妆〞概念火热,消费驱动因素向成分来源硬核转变 新冠疫情过后,消费者对于生活健康:自然,可持续的关注度持续上升。在消费者…...
主机准备和负载均衡器安装)
Kubernetes高可用集群二进制部署(一)主机准备和负载均衡器安装
Kubernetes概述 使用kubeadm快速部署一个k8s集群 Kubernetes高可用集群二进制部署(一)主机准备和负载均衡器安装 Kubernetes高可用集群二进制部署(二)ETCD集群部署 Kubernetes高可用集群二进制部署(三)部署…...

python与深度学习(十二):CNN和猫狗大战二
目录 1. 说明2. 猫狗大战的CNN模型测试2.1 导入相关库2.2 加载模型2.3 设置保存图片的路径2.4 加载图片2.5 图片预处理2.6 对图片进行预测2.7 显示图片 3. 完整代码和显示结果4. 多张图片进行测试的完整代码以及结果 1. 说明 本篇文章是对上篇文章猫狗大战训练的模型进行测试。…...

React(1)——快速入门
目录 一、React背景简介 ❤️ 官网和资料 📚 介绍描述 🐧 React的特点 🔨 React高效的原因 🙏🏻 二、React的基本使用 💻 三、React JSX(JSX:JavaScript XML)📦 …...
【论文】【生成对抗网络五】Wasserstein GAN (WGAN)
【题目、作者】: 紫色:要解决的问题或发现的问题 红色:重点内容 棕色:关联知识,名称 绿色:了解内容,说明内容 论文地址: 论文下载 本篇文章仅为原文翻译,仅作参考。…...
)
学习率Learn_rate是什么(深度学习)
学习率是指在训练神经网络时用于调整参数的步进大小,它决定了每次梯度更新时参数的调整程度。学习率的选择直接关系到模型的性能和训练过程的效果。 学习率变化可能带来的影响: 收敛速度:较高的学习率可以加快模型的收敛速度,因为…...
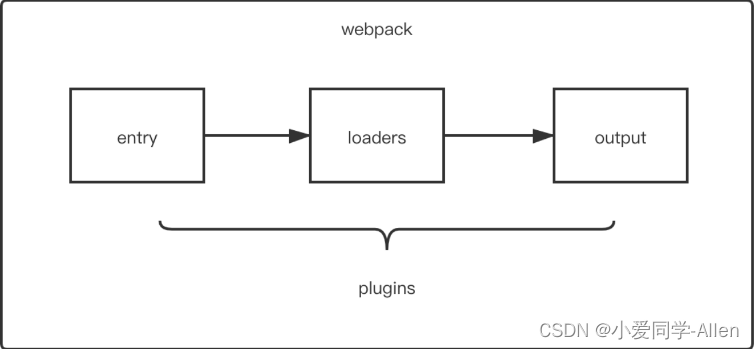
webpack基础知识五:说说Loader和Plugin的区别?编写Loader,Plugin的思路?
一、区别 前面两节我们有提到Loader与Plugin对应的概念,先来回顾下 loader 是文件加载器,能够加载资源文件,并对这些文件进行一些处理,诸如编译、压缩等,最终一起打包到指定的文件中plugin 赋予了 webpack 各种灵活的…...
AI大模型之花,绽放在鸿蒙沃土
随着生成式AI日益火爆,大语言模型能力引发了越来越多对于智慧语音助手的期待。 我们相信,AI大模型能力加持下的智慧语音助手一定会很快落地,这个预判不仅来自对AI大模型的观察,更来自对鸿蒙的了解。鸿蒙一定会很快升级大模型能力&…...
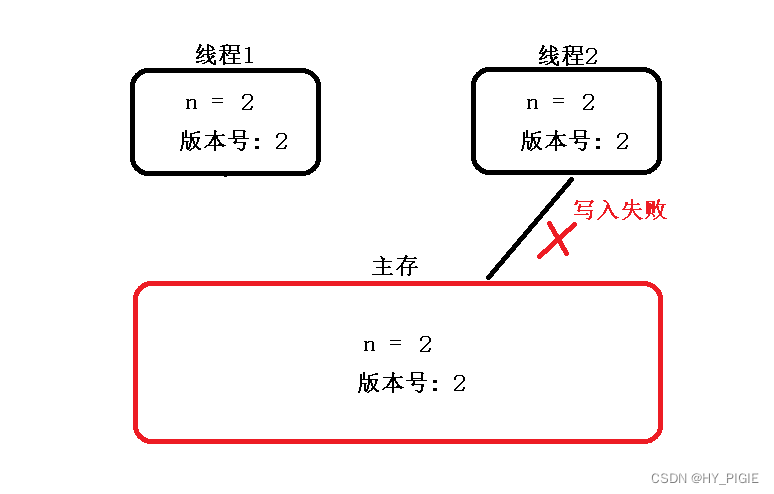
[JAVAee]锁策略
目录 乐观锁与悲观锁 乐观锁 乐观锁的冲突检测 悲观锁 读锁与写锁 重量级锁与轻量级锁 重量级锁 轻量级锁 自旋锁 公平锁与非公平锁 可重入锁与不可重入锁 乐观锁与悲观锁 乐观锁 在乐观锁中,假设数据并不会发生冲突,在正式提交数据时会对数据进行冲突检测,如果发…...

uni-app-使用tkiTree组件实现树形结构选择
前言 在实际开发中我们经常遇见树结构-比如楼层区域-组织架构-部门岗位-系统类型等情况 往往需要把这个树结构当成条件来查询数据,在PC端可以使用Tree,table,Treeselect等组件展示 在uni-app的内置组件中似乎没有提供这样组件来展示&#x…...
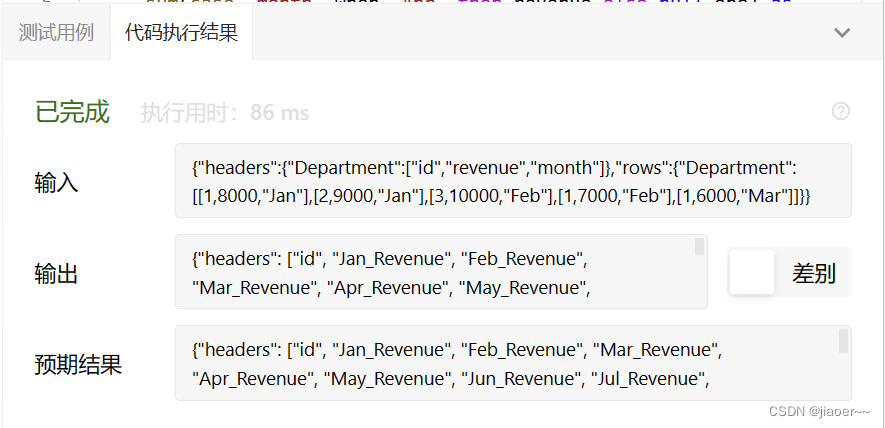
SQL-每日一题【1179. 重新格式化部门表】
题目 部门表 Department: 编写一个 SQL 查询来重新格式化表,使得新的表中有一个部门 id 列和一些对应 每个月 的收入(revenue)列。 查询结果格式如下面的示例所示: 解题思路 1.题目要求我们重新格式化表,…...

GO语言语法结构
GO语言结构 包声明引入包函数变量语句 && 表达式注释 package main import "fmt" func main() {fmt.Println("Hello,World!") } 如这段代码块根据上面的语法结构进行逐行解释 第一行的 package main 是定义一个包名,必须在源文件…...
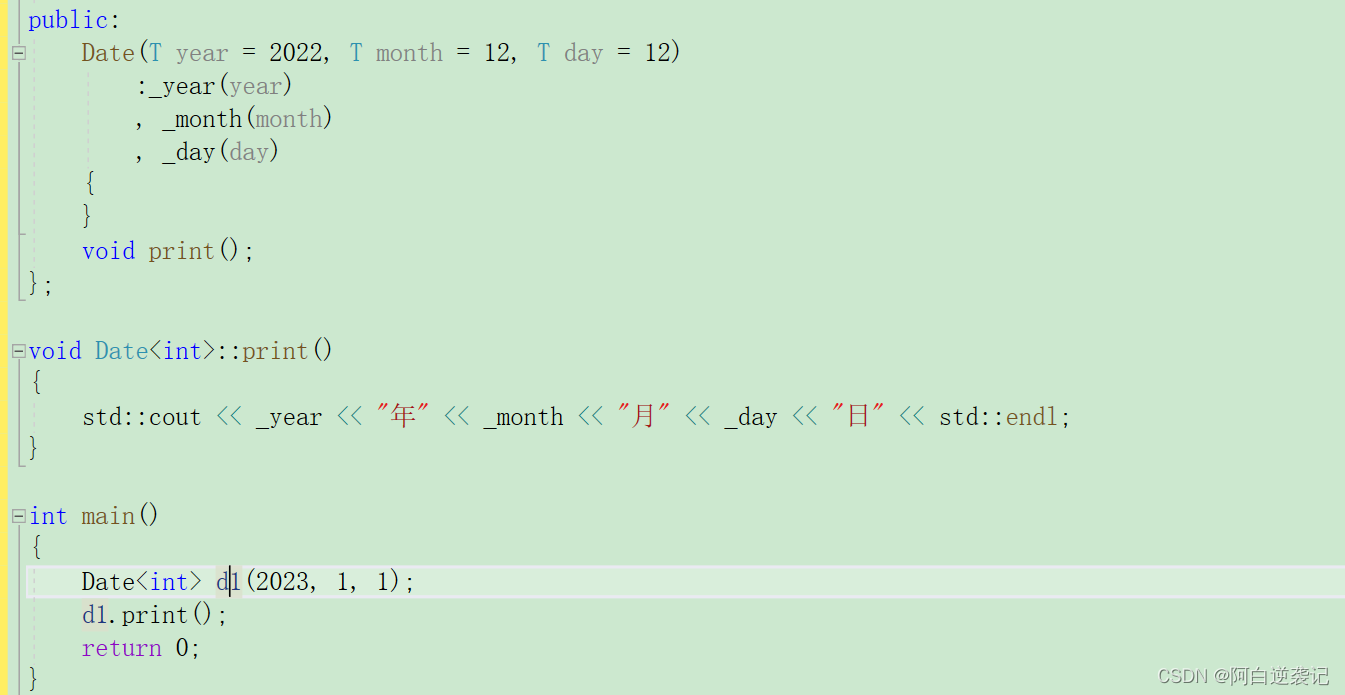
C++学习——模板
目录 🍉一:什么是模板 🍎二:普通模板的定义 🍍三:类模板的定义 🍌四:模板的实例化 🍇1.当普通模板定义存在可修改返回值产生的分歧 🍈2:类模板实例…...
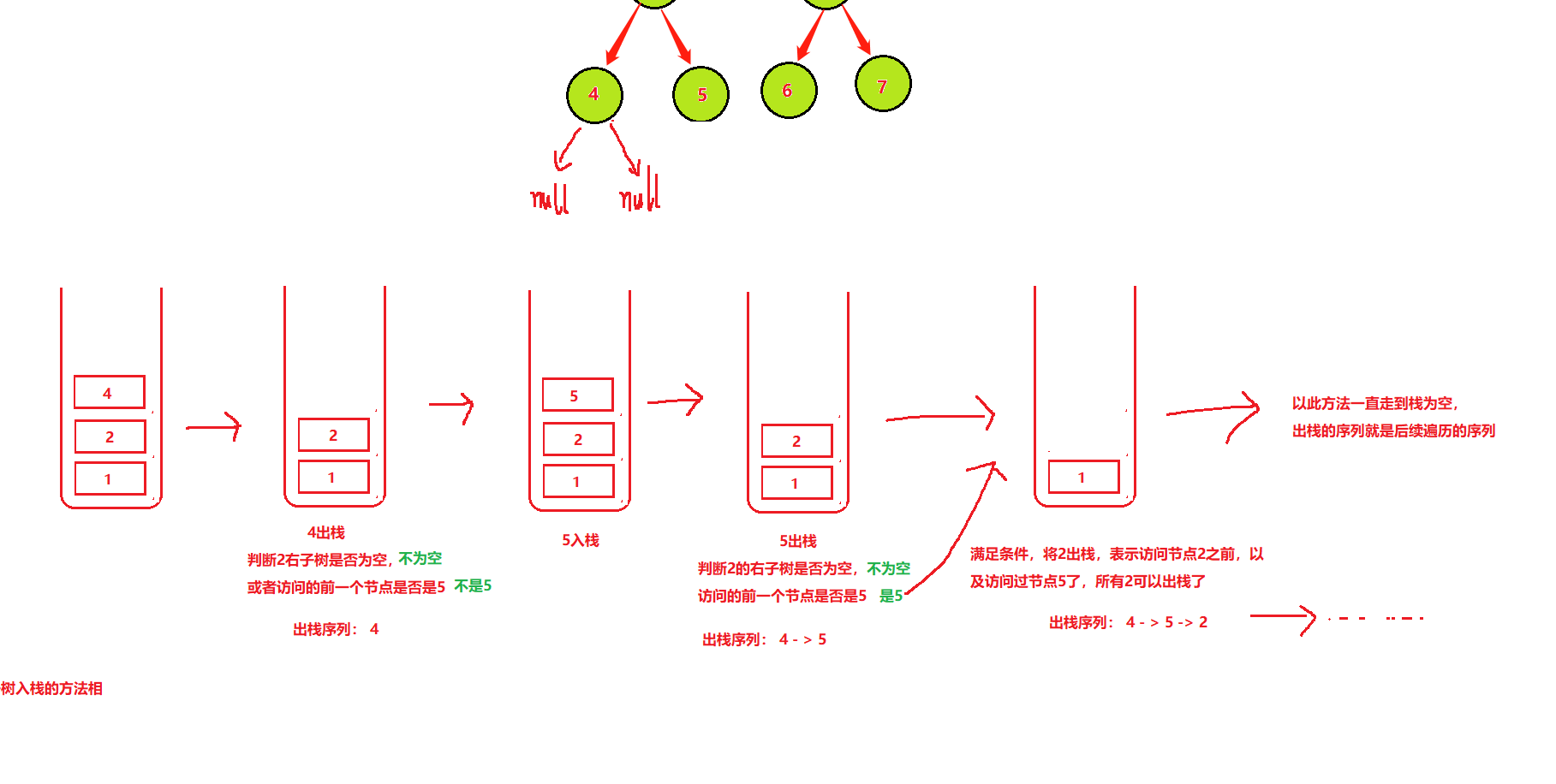
二叉树的遍历(先序遍历,中序遍历,后序遍历)递归与非递归算法
目录 一、先序遍历题目链接1.递归2.非递归 二、中序遍历题目链接1.递归2.非递归 三、后序遍历题目链接1.递归2.非递归 一、先序遍历 先序遍历:先遍历一颗树的根节点,后遍历左子树,最后遍历右子树 先序遍历序列: 1 -> 2 -> 4…...
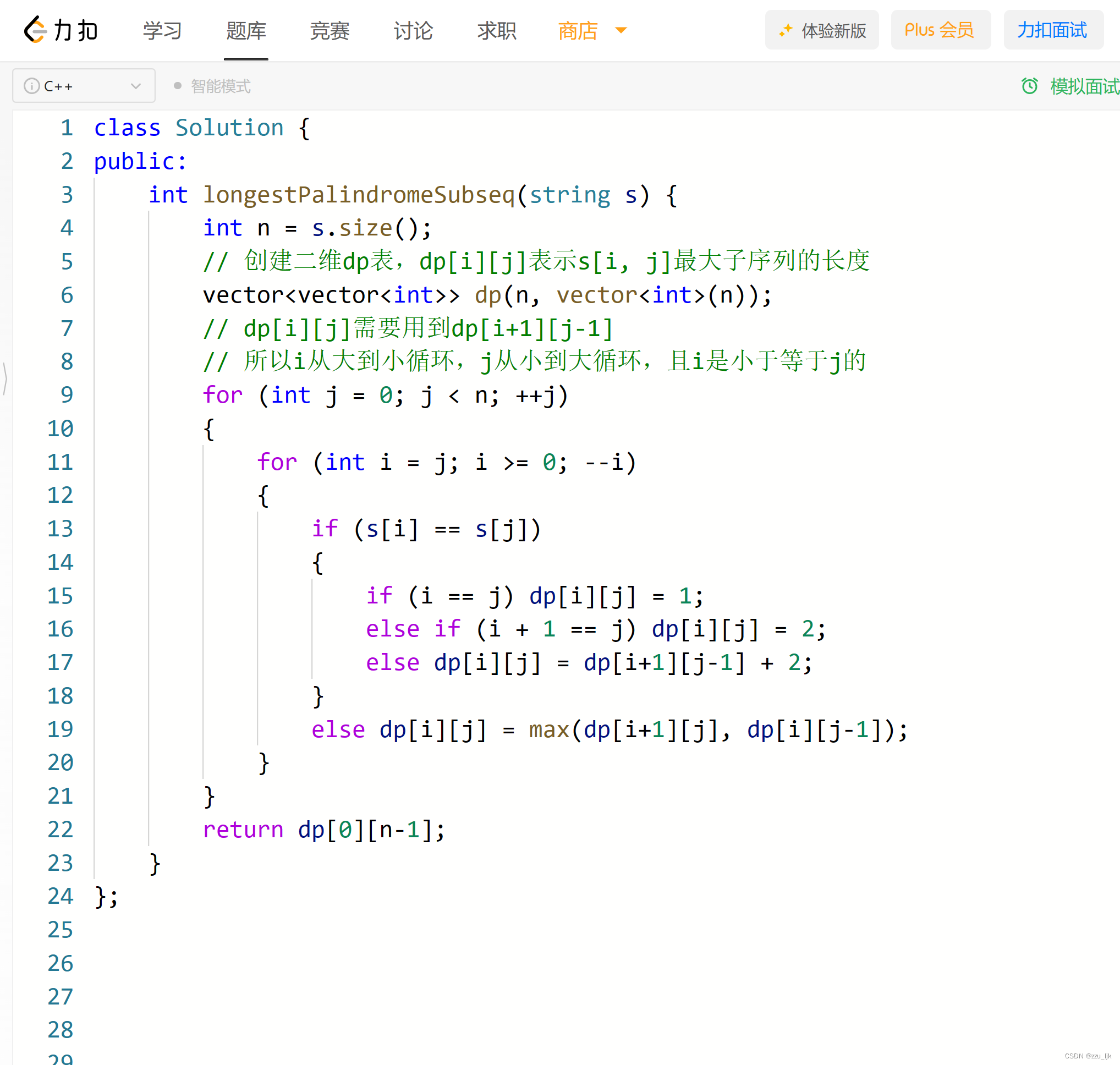
【LeetCode】516. 最长回文子序列
文章目录 1. 思路讲解1.1 创建dp表1.2 状态转移方程1.3 不需考虑边界问题 2. 整体代码 1. 思路讲解 1.1 创建dp表 此题采用动态规划的方法,创建一个二维dp表,dp[i][j]表示s[i, j]中最大回文子序列的长度。且我们人为规定 i 是一定小于等于 j 的。 1.2…...
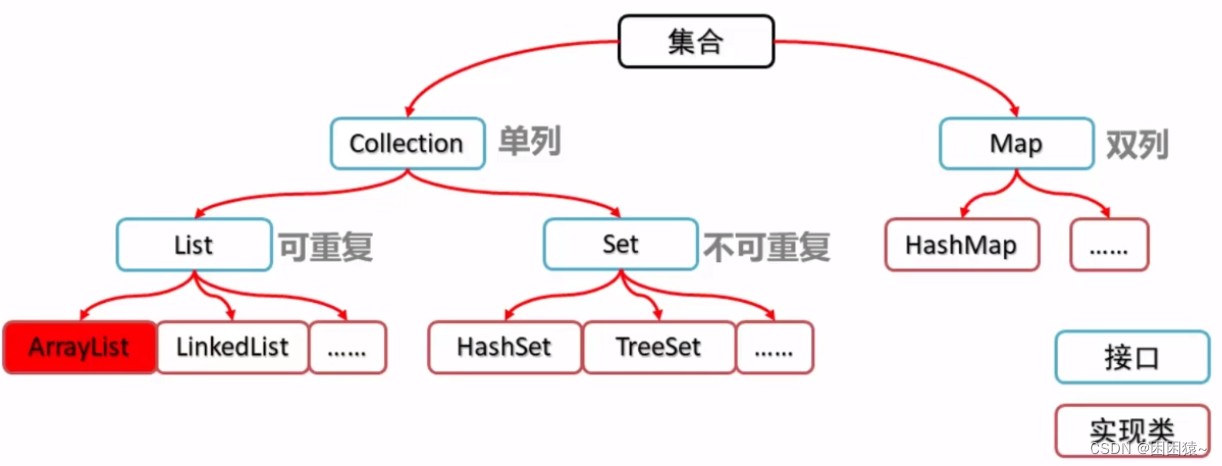
Java 集合框架
Java 集合框架提供了一组接口和类,以实现各种数据结构和算法。 集合框架满足以下几个要求。 该框架必须是高性能的。基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。 该框架允许不同类型的集合…...
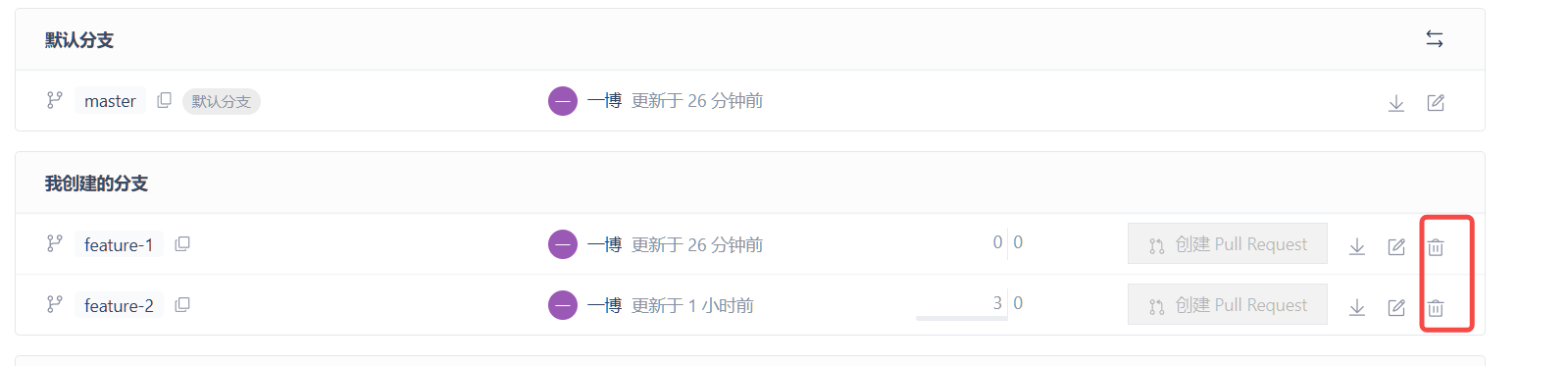
遇到多人协作,我们该用git如何应对?(版本二)
一、多人协作二 1.1多人协作 一般情况下,如果有多需求需要多人同时进行开发,是不会在一个分支上进行多人开发,而是一个需求或一个功能点就要创建一个feature 分支。 现在同时有两个需求需要你和你的小伙伴进行开发,那么你们俩便…...

Flutter iOS 集成使用 fluter boost
在 Flutter项目中集成完 flutter boost,并且已经使用了 flutter boost进行了路由管理,这时如果需要和iOS混合开发,这时就要到 原生端进行集成。 注意:之前建的项目必须是 Flutter module项目,并且原生项目和flutter m…...
驱动应用程序设计)
基于STM32LXXX的数字电位器(AD5290YRMZ10)驱动应用程序设计
一、简介: AD5290是一款支持15V高压的数字电位器,采用SPI接口控制。相比普通数字电位器,它最大的优势是支持30V单电源或15V双电源供电,适合工业控制、可编程电源等需要高压调节的应用场景。 二、主要技术特性: 参数 值 说明 抽头数 256 8位分辨率,0~255可编程 端到端电阻…...
数据库事务的坑:@Transactional注解的隐藏陷阱
一、问题现场还原 那是一个月黑风高的夜晚,小王正准备下班,突然运营群里炸了: 【运营】重大bug!用户下单成功了,但没扣库存! 【运营】已有多名用户反馈... 【运维】涉及金额已达¥12,580... 小…...

从LSB到MSB:位平面分割在图像隐写与压缩中的实战解析
1. 什么是位平面分割? 第一次听说"位平面分割"这个词时,我也是一头雾水。直到有一天我在处理一张老照片时,发现即使删除了某些数据,照片看起来依然清晰,这才恍然大悟。位平面分割(Bit-Plane Sli…...

探索6种突破信息壁垒的创新方案
探索6种突破信息壁垒的创新方案 你是否曾因遇到付费墙而无法获取急需的信息?当知识被一道道"数字门锁"隔离,我们该如何智慧地开启信息之门?本文将带你探索突破信息壁垒的创新方案,让有价值的内容触手可及。 问题解析&am…...

XXMI启动器:一站式二次元游戏模组管理平台的终极解决方案
XXMI启动器:一站式二次元游戏模组管理平台的终极解决方案 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款革命性的开源模组管理平台,专为…...

D3KeyHelper终极指南:5步轻松掌握暗黑3智能按键操作
D3KeyHelper终极指南:5步轻松掌握暗黑3智能按键操作 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否在暗黑破坏神3的高强度战斗中感…...
保姆级教程:用两张RTX 4090本地搭建企业级TranslateGemma翻译引擎
保姆级教程:用两张RTX 4090本地搭建企业级TranslateGemma翻译引擎 1. 为什么选择本地化翻译系统? 在当今全球化的工作环境中,高效准确的翻译工具已成为刚需。但常见的在线翻译服务存在几个痛点: 数据隐私风险:敏感技…...
Pixel Dimension Fissioner 环境部署详解:在Ubuntu服务器上从零开始配置
Pixel Dimension Fissioner 环境部署详解:在Ubuntu服务器上从零开始配置 1. 准备工作:系统与硬件要求 在开始部署Pixel Dimension Fissioner之前,我们需要确保服务器满足基本要求。根据官方文档和实际测试经验,以下是推荐配置&a…...

3步完整指南:使用OpenCore Legacy Patcher让老旧Mac焕发新生
3步完整指南:使用OpenCore Legacy Patcher让老旧Mac焕发新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹果官方抛弃的老款Ma…...

开源中国教育战略升级:构建AI时代全链条人才培养生态
在数字化转型浪潮席卷全球教育的当下,开源中国以一场战略升级宣告其从工具服务商向AI教育基础设施提供者的身份转变。4月8日至10日在北京展览馆举办的第35届北京教育装备展示会上,这家国内领先的开源技术平台展示了其覆盖K12至高等教育的完整解决方案&am…...