基于 Flink Paimon 实现 Streaming Warehouse 数据一致性管理
摘要:本文整理自字节跳动基础架构工程师李明,在 Apache Paimon Meetup 的分享。本篇内容主要分为四个部分:
背景
方案设计
当前进展
未来规划
点击查看原文视频 & 演讲PPT
一、背景
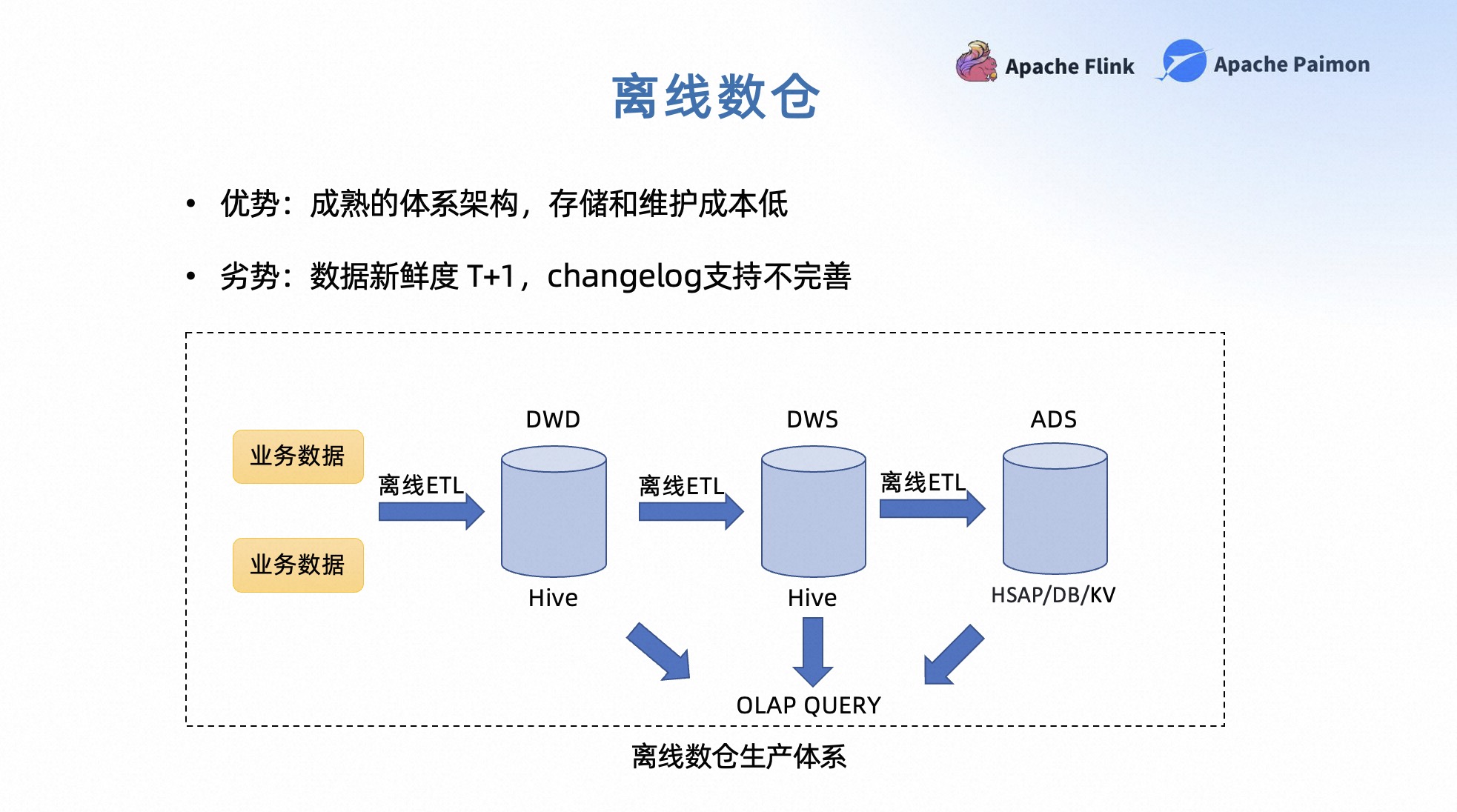
早期的数仓生产体系主要以离线数仓为主,业务按照自己的业务需求将数仓分为不同的层次,例如 DWD、DWS、ADS 等。在离线数仓中,业务数据会经过离线 ETL 加工进入数仓,层与层之间的数据转换也会使用离线 ETL 来进行处理。ADS 层可以直接对外提供 Serving 能力,中间层通常会使用 Hive 来存储中间数据。基于 Hive 也可以提供一些 OLAP QUERY 的能力。
在离线数仓生产体系下,优势是离线数仓的生产体系非常完整,工具链也比较成熟,存储和维护的成本比较低,对于用户的开发门槛相对也比较低。但劣势也非常明显,首先数据新鲜度非常低,通常是 T+1 级别,一般是小时级,甚至是天级。其次 changelog 支持不完善,虽然是面向Table开发,但中间存储 Hive 主要支持 append 类型的数据,同时离线 ETL 更适合处理全量数据,而不是增量更新。
随着数据量的增多,离线 ETL 的执行时间越来越长,同时业务对数据新鲜度的要求也越来越高。业务迫切的需要一种新的低延迟数仓生产体系。因此基于离线数仓进一步演进出了实时数仓生产体系。
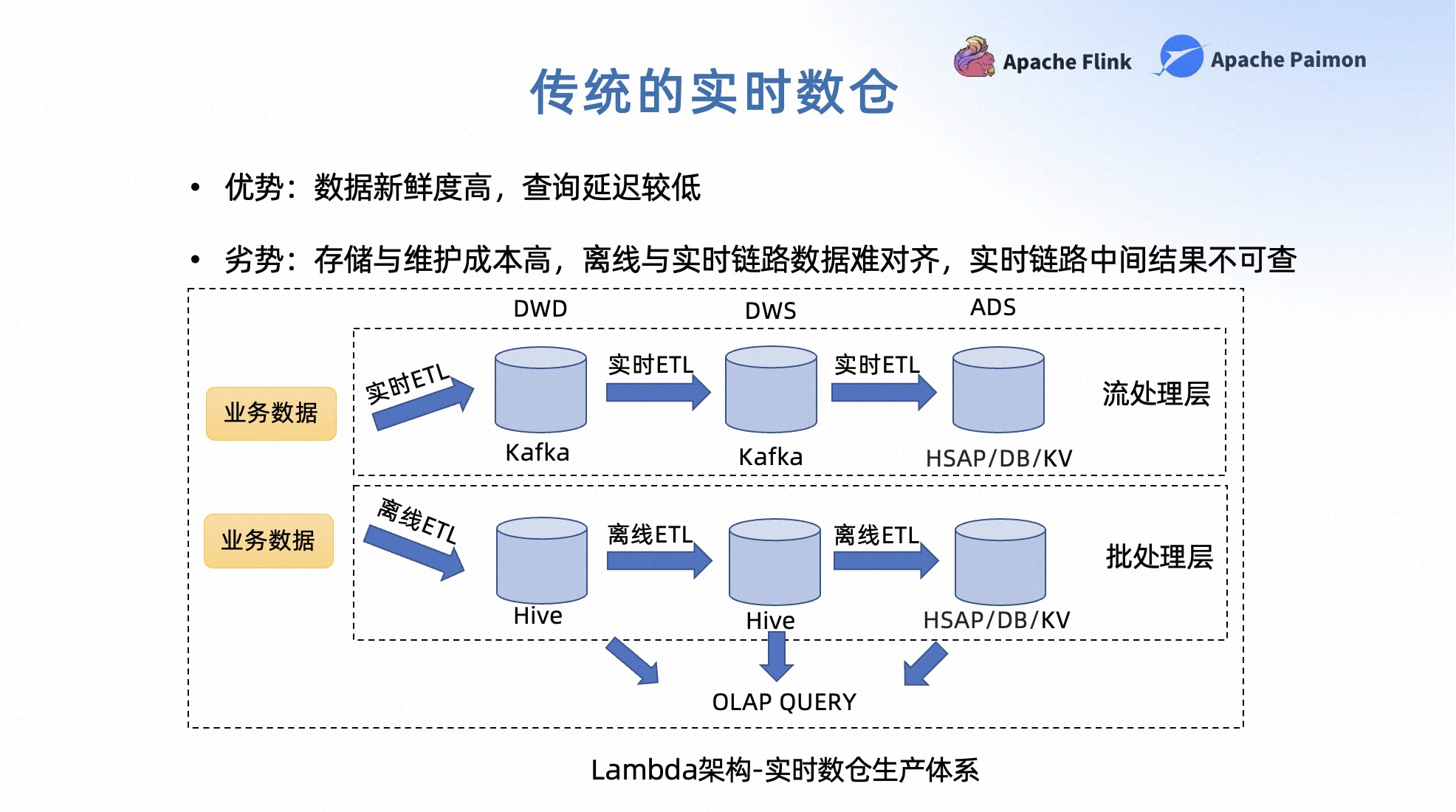
比较典型的是 Lambda 架构的实时数仓生产体系。在 Lambda 架构的实时数仓生产体系中,业务需要维护两条链路,将生产链路分为了流处理层和批处理层。流处理层主要用于实时处理增量数据,作为批处理层的加速层,这层通常会选用 Storm、Flink 等实时计算引擎来进行数据处理。而中间结果则采用 Kafka 进行存储,以提供低延迟的流式消费能力。
批处理层和离线数仓相同,完成 T+1 的数据结果产出。服务层则会综合流处理层和批处理层的结果对外提供服务。
随着流式计算引擎的不断发展,以 Flink 为例,已经实现了计算层的流批统一,在一些场景中可以完全移除掉批处理层,由流处理层来完成全量+增量的计算。为了提供中间关键数据的 OLAP 查询能力,仍然需要将 Kafka 的数据再 Dump 到 Hive 中一份。
在实时数仓生产体系中,优势是数据新鲜度非常高,同时基于流处理层也可以做很多的预计算,来降低查询的延迟。
劣势也比较明显:
- 第一,数仓的维护人员需要维护从计算到存储的两条技术栈完全不同的链路,开发和维护的成本都比较高。
- 第二,存储成本高。Kafka 为了提供低延迟的流式消费能力,相比于离线常用的 HDFS,S3 等离线存储,存储的成本会更高。同时,为了让中间数据能够提供离线查询的能力,还需要额外存储一份离线的全量数据。
- 第三,离线和实时链路的数据口径比较难对齐。这是因为采用了完全不同的两套技术栈在构建流处理层和批处理层。虽然逻辑抽象是相同的,但在具体实现上仍然有差别。并且流处理层的数据在不断地进行增量处理,和离线处理层很难基于固定的时间点进行结果对齐。
- 最后在流处理链路中的中间结果,它是不可以被查询的,因为 Kafka 只支持流式顺序消费,没有点查、batch 查询的能力。虽然可以通过将 Kafka 数据 Dump 到 Hive 中一份,但实时性比较差。

尽管计算引擎已经实现了流批统一,但实时数仓其他的痛点很大程度是由于存储功能存在一定的限制而导致的。随着数据湖技术的兴起,一种新的存储技术产生了,它能支持高效的数据流批读写、数据回溯以及数据更新。基于数据湖可以构建出新的数仓生产体系——Streaming Warehouse。
在 Streaming Warehouse 中,每个中间表都被抽象为 Dynamic Table,能够同时支持流式和批式访问,为用户提供了和离线数仓相同的生产体验。基于 Streaming Warehouse 可以带来以下收益。
首先,为用户提供了统一的Table抽象,用户只需要维护一套 Schema。同时也统一了技术栈,大幅降低了业务的开发和运维成本。
其次,它采用了流批一体的存储,支持流式消费和 OLAP 查询,可以随时查询实时计算的中间结果。
最后,在保证数据新鲜度的情况下,存储成本相比实时数仓会更低一些。中间存储可以选用相对廉价的 HDFS 和 S3 这样的存储。
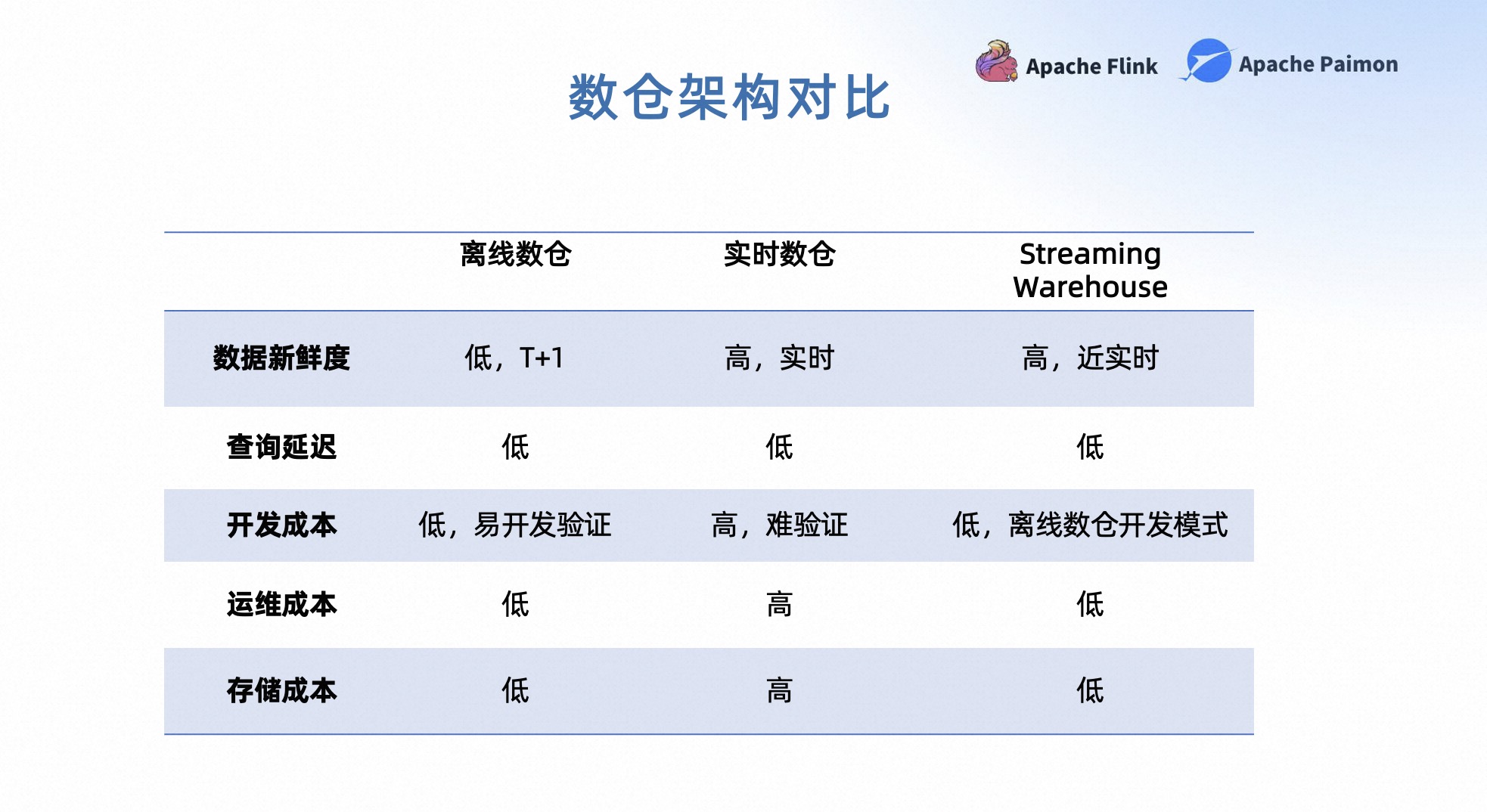
接下来我们对这三种数仓生产体系做一个整体的对比。
-
在数据新鲜度方面,实时数仓和 Streaming Warehouse 的数据新鲜度是比较接近的,都是近似于实时的生产体验。
-
在查询延迟方面,三种数仓生产体系的查询延迟都相对较低,但实时数仓的中间结果查询需要付出更多的成本,比如将中间结果需要导出到Hive等。
-
在开发成本方面,Streaming Warehouse 和离线数仓的开发成本比较接近,它们的开发模式类似,可以很容易的进行开发和数据验证,门槛较低。实时数仓由于中间结果不可查,想要做 debug 和数据验证的成本开销会比较高。
-
在运维成本方面,Streaming Warehouse 和离线数仓的运维成本也是比较接近的,因为它们的生产体系类似。对于运维人员,只需要维护一条链路,使用同一套技术栈。同时 Streaming Warehouse 和离线数仓都可以选择更廉价的离线存储,存储成本会更低一些。
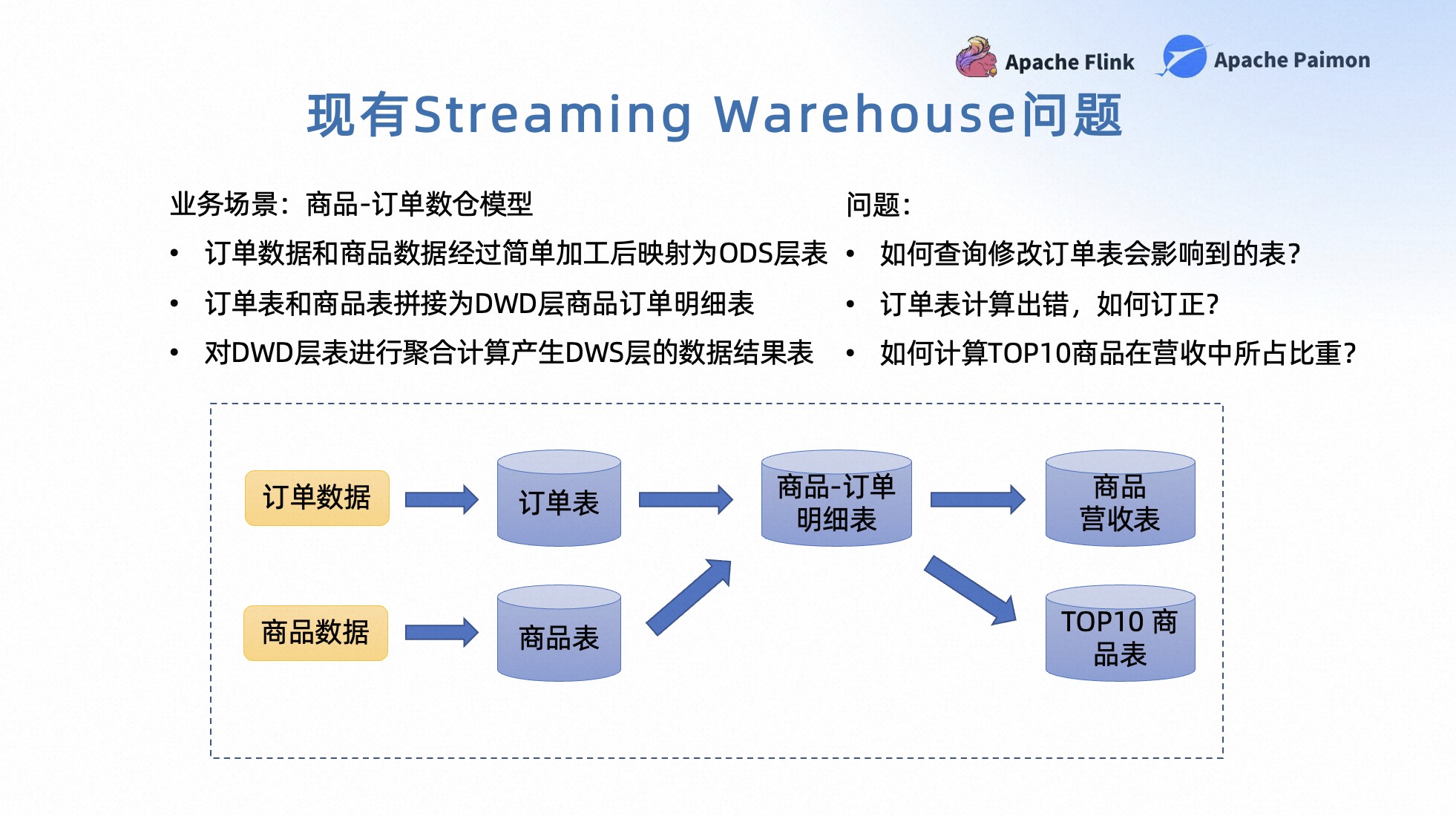
那么思考一下 Streaming Warehouse 是否真的完全覆盖了我们的需求?
先来看一个业务场景,这是一个比较典型的商品订单关联计算的业务场景。在这个场景中,订单数据和商品数据会经过一些简单的加工,导入到 Streaming Warehouse 中的 ODS 层的表,也就是订单表和商品表。
然后订单表和商品表会进一步拼接为 DWD 层的商品订单明细表。最后对 DWD 层的表做一些聚合计算,产生 DWS 层的数据结果表。例如统计今天所有商品的营收,统计今天销售量 Top 10 的商品信息等。
在这样一个业务场景中,业务在数仓中可能也会进行一些常见的操作,比如业务可能会去修改订单表的字段。那么如果修改了订单表的字段,怎么去判断这次修改可能会影响到下游的哪些表呢?这反映出目前 Streaming Warehouse 中缺乏一个血缘管理的业务能力。
另外如果订单表数据出错了,如何去做生产链路的数据订正呢?在离线数仓中,可以很方便的进行任务重跑、Overwrite 等操作。在 Streaming Warehouse 中目前也可以很方便的去做这样的操作吗?
由于 Streaming Warehouse 是基于实时生产链路,所以不仅需要对这个表进行订正,还需要对它下游的表同时进行处理。在整个订正的过程中,数据的中间变化不应该被服务层可见。比如聚合结果已经到了 10,在订正的过程中,这个结果可能会回退到1,然后再逐渐累加到 10。
除了上述两个问题外,在进行 OLAP 查询时,如果想要分析 Top 10 商品在整个营收中所占的比重如何进行呢?如果是离线数仓,我们可以在两个表就绪之后进行 batch 查询。而在 Streaming Warehouse 中并没有就绪的概念,这两张表又来源于两个不同的任务,任务之间并没有任何的数据对齐的操作。当我们进行多表关联查询的时候,它的计算结果并不是完全一致的,缺少一个一致性的保证。
下面我们来总结一下在 Streaming Warehouse 中存在的问题。
-
缺少血缘管理功能,包括表的血缘关系以及数据的血缘关系。表血缘关系是指这个表的上下游依赖,而数据血缘关系则是指这份数据来源于上游的哪些数据,同时下游基于这份数据生产出了哪些数据。
-
缺少统一的版本管理能力。在离线数仓中,我们可以按照小时、天来对数据进行对齐。而在 Streaming Warehouse 中,由于我们都是流式进行处理,没有数据对齐、版本划分的概念,就会导致进行多表关联查询的时候缺少一致性的保证。
-
数据订正困难。在进行订正的过程中,需要进行链路双跑、业务逻辑修正等大量的人工操作,运维成本较高。
基于以上的问题,我们提出了一个基于 Flink 和 Paimon 构建 Streaming Warehouse,并对外提供数据一致性管理的能力。
二、方案设计

下面我们介绍一下基于 Flink 和 Paimon 实现数据一致性管理方案的详细设计。
在一致性管理方案的整体设计中,主要包含两个部分。
-
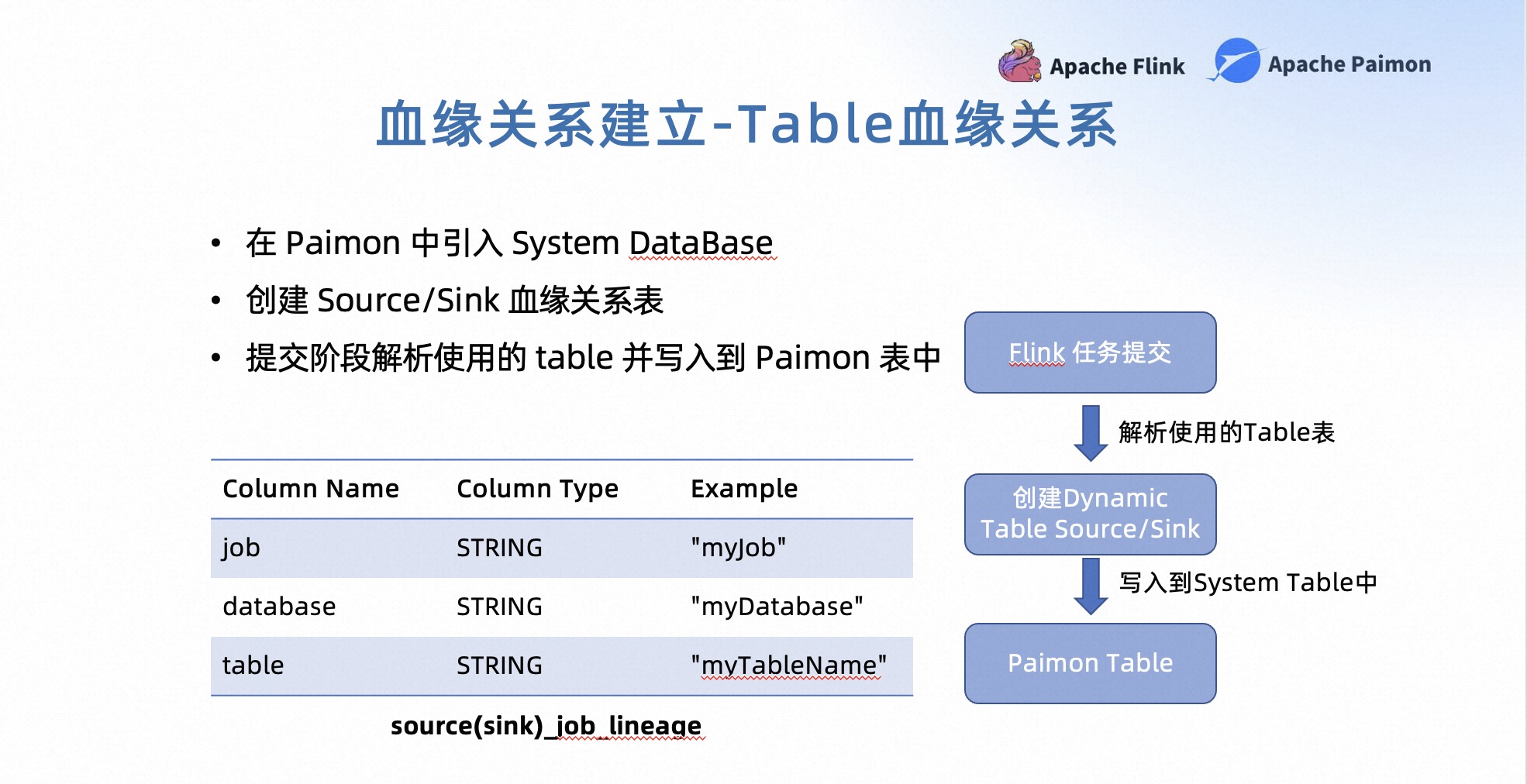
第一部分,建立上下游的血缘关系,我们会引入 System Database 来记录 Streaming Warehouse 中所有表和数据的血缘关系。同时,在任务提交以及数据生产的过程中,会自动的把表以及数据之间的血缘关系写入到血缘关系表中。
-
第二部分,我们会在 Streaming Warehouse 中引入数据版本控制的能力,数据会按照版本来保持可见性,并且协调多表数据版本处理的一致性。
下面我们详细介绍一下这两部分的方案设计。
首先是血缘关系中的Table血缘关系管理。我们在 Streaming Warehouse 中引入了 System Database,并在这个 System Database 中创建了 Source 和 Sink 的血缘关系表。在任务的提交阶段,会解析这个任务使用到的 Table 表,并将这些信息记录到 Paimon 的血缘关系表中。
上图是我们的一个表结构,主要用来记录表和任务之间的关联关系。基于这个关联关系,我们可以构建出表与表之间的数据血缘关系。
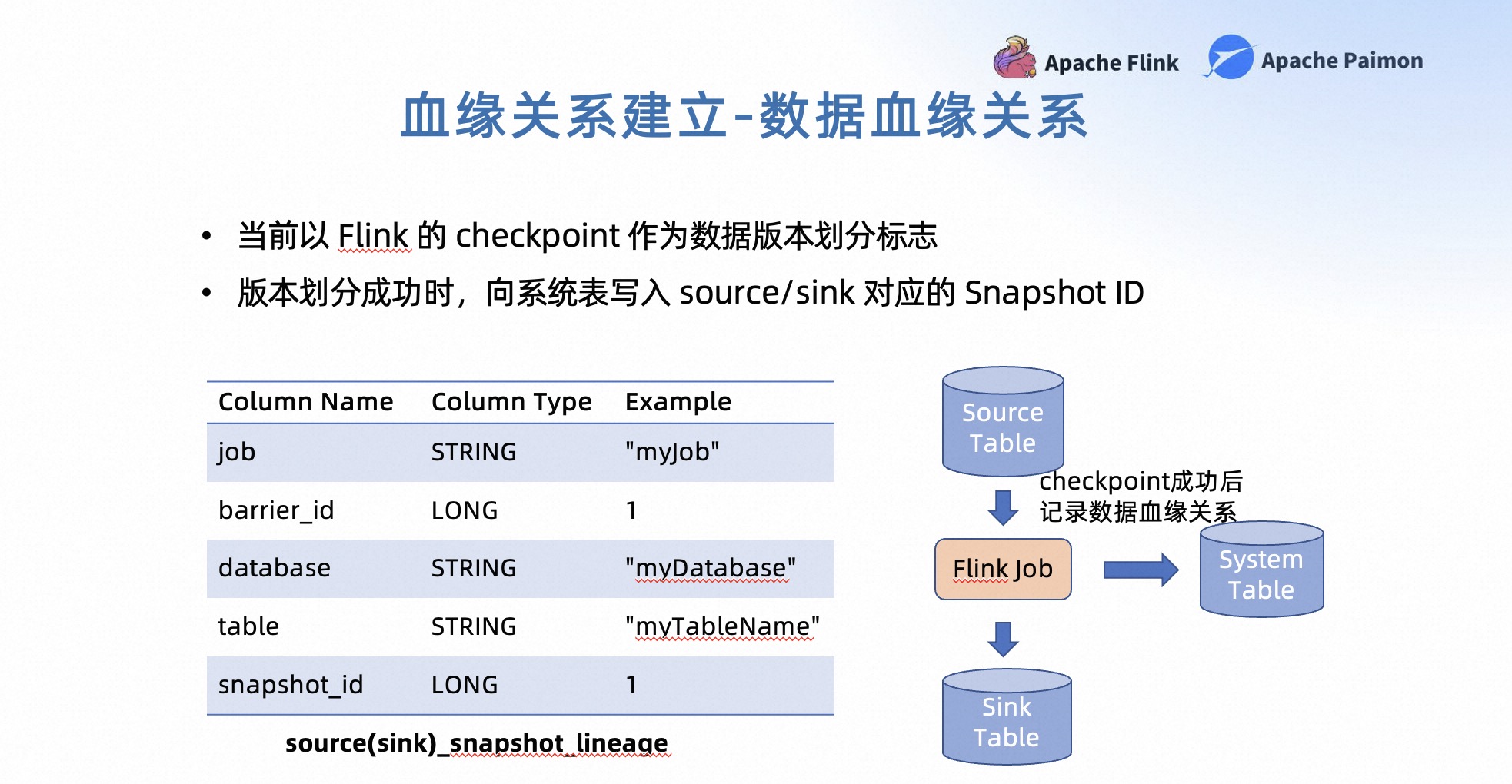
在数据血缘关系中会为数据划分一个版本,并将版本信息记录到数据血缘关系的表中。目前我们以 Flink 的 Checkpoint 作为数据版本的一个划分标志,这是因为在 Flink 中目前 Paimon 表是依赖 Checkpoint 来实现数据提交的。
在 Flink 的 Checkpoint 制作成功之后,这意味着一个新的版本的数据产生了,我们会自动记录消费与生产之间的 Snapshot 的关系。

接下来介绍数据版本控制的设计,首先介绍一下基本概念。
-
第一个概念是 Flink Checkpoint。这个是 Flink 定期用来持久化状态,制作快照的一个功能,主要用于容错、两阶段提交等。
-
第二个概念是 Paimon Snapshot。在 Flink 制作 Checkpoint 的时候 Paimon 会产生 1 个或 2 个Snapshot,这取决于 Paimon 在这个过程中是否有进行过 Compaction,但至少会产生一个 Snapshot 来作为新的数据版本。
-
第三个概念是 Data Version,也就是数据版本。计算引擎在计算的时候会按照数据的版本进行数据的对齐,然后进行处理,从而实现一个微批模式的处理。
目前,短期内我们是将 Paimon Snapshot 和 Data Version 两个概念进行了对齐,也就是说一个 Paimon Snapshot 就对应数据的一个版本。
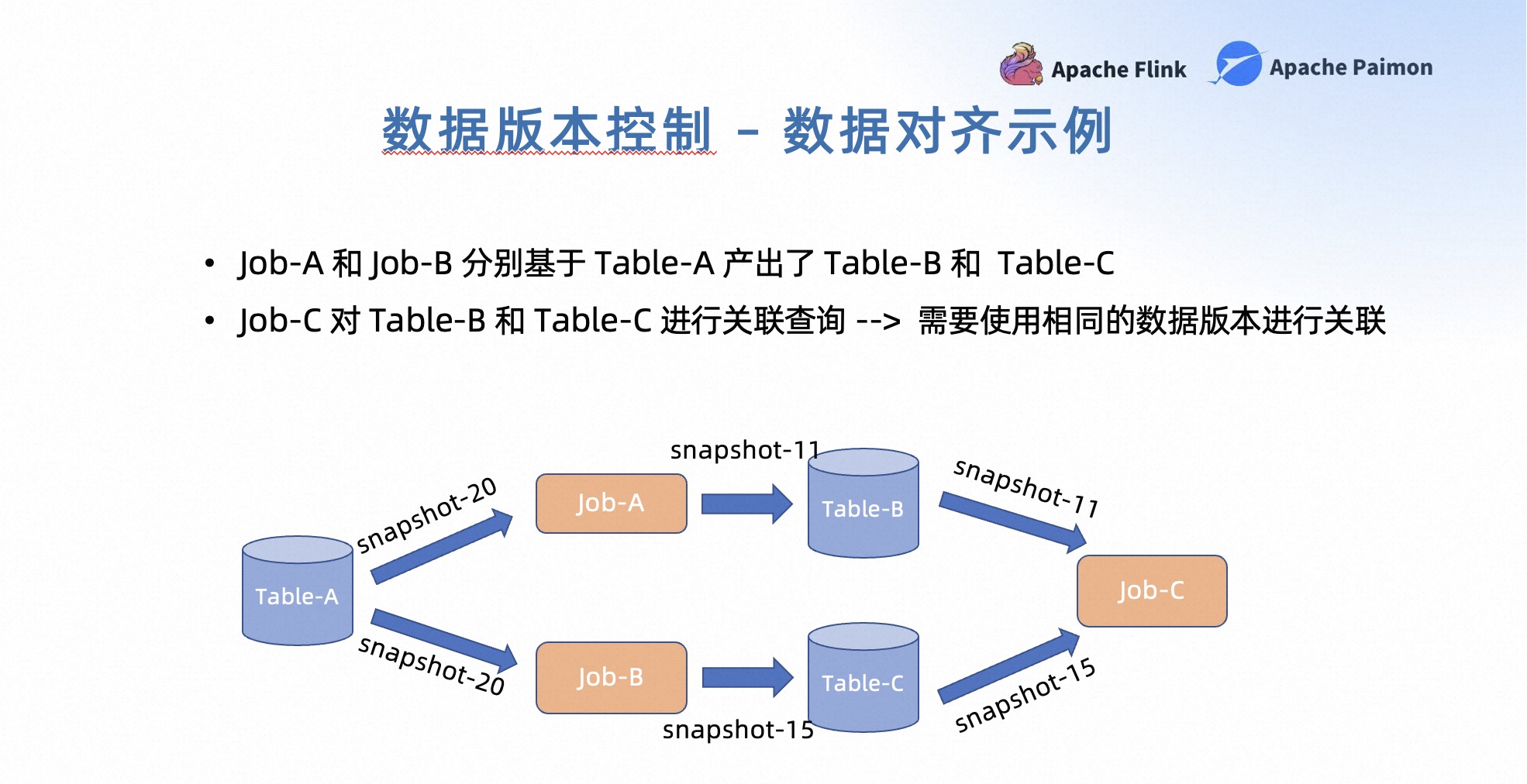
先简单看一个数据对齐的示例。假设我们有 Job-A 和 Job-B,他们分别基于 Table-A 产出了自己的下游表 Table-B 和 Table-C。当 Job-C 想要对 Table-B 和 Table-C 进行关联查询的时候,它就可以基于一致性的版本去做自己的 QUERY。
比如 Job-A 基于 Table-A 的 Snapshot-20 产出了 Table-B 的 Snapshot-11。Job-B 基于 Table-A 的Snapshot-20产出了 Table-C 的 Snapshot-15。那么 Job-C 的查询就应该基于 Table-B 的 Snapshot-11 和 Table-C 的 Snapshot-15 进行计算,从而实现计算的一致性。
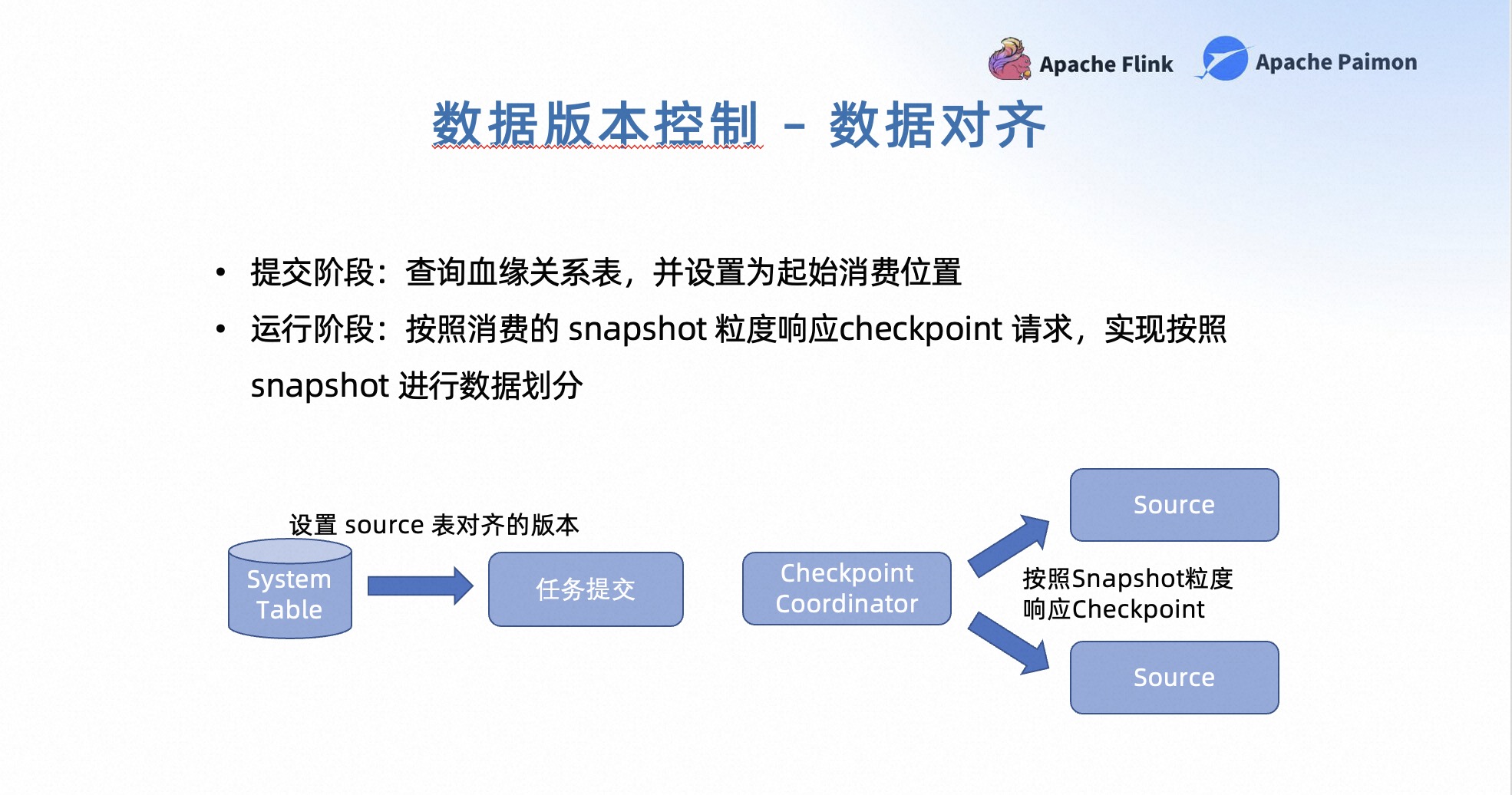
接下来介绍一下数据对齐的实现,它的实现分为两个部分。
- 在提交阶段,需要去血缘关系表中查询上下游表的一致性版本,并且基于查询结果给对应的上游表设置起始的消费位置。
-
在运行阶段,按照消费的 Snapshot 来协调 Checkpoint,在 Flink 的 Checkpoint Coordinator 向 Source 发出 Checkpoint 的请求时,会强制要求将 Checkpoint 插入到两个 Snapshot 的数据之间。如果当前的 Snapshot 还没有完全被消费,这个 Checkpoint 的触发会被推迟,从而实现按照 Snapshot 对数据进行划分和处理。
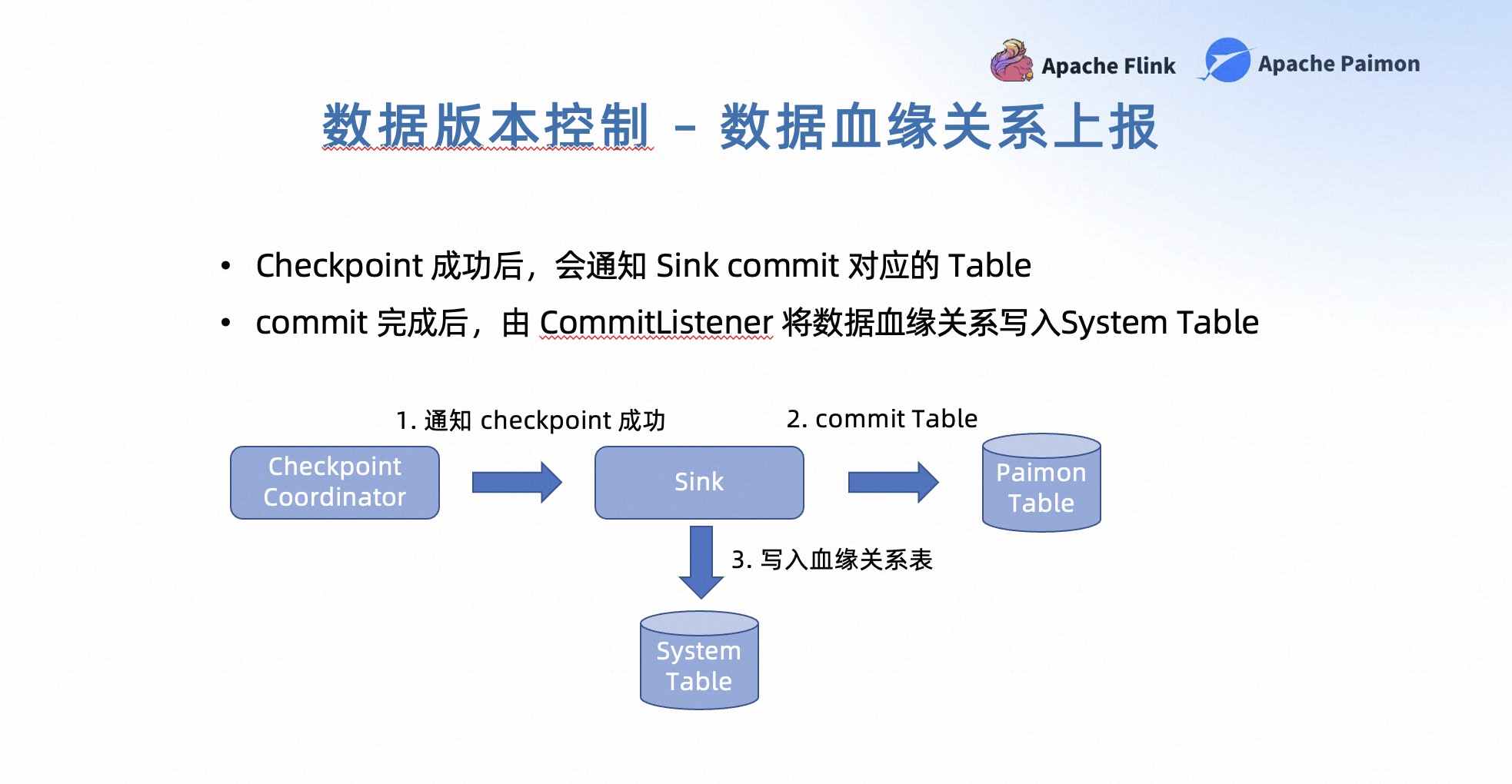
在 Flink 的 Checkpoint 成功之后,它会通知Sink的算子来进行 Table 的 commit。在 commit 完成之后,这份 Snapshot 的数据就可以被下游可见了。此时会由 Commit Listener 将数据的血缘关系写入到 System Table 中,用来记录这份血缘关系。

当我们实现上面两个功能之后,具体有哪些应用场景呢?
- 第一,数据血缘的自动化管理。数据血缘关系在整个数仓中是非常重要的一个部分。基于血缘关系我们可以快速的进行数据溯源,风险评估等。同时也可以基于血缘关系分析这些表的使用方、使用数量、数据走向,从而进行实际应用价值的评估。
- 第二,查询一致性的能力,我们可以为 OLAP 查询自动按照数据版本来做数据对齐,并且保证查询结果的一致性。同时基于一致性数据进行开发和 debug,可以降低开发和运维成本,不再需要业务方手动进行多表对齐的操作。
- 第三,数据订正。基于数据一致性管理以及数据血缘关系,可以简化数据订正的过程。首先按照血缘关系我们可以自动的创建下游需要订正的表的镜像表,然后再进行订正。可以提供两种订正方式,全量订正和增量订正。
- 全量订正,可以基于一致性版本的数据从上游进行全量消费,产生一个全链路的新数据。在整个数据生产追上延迟之后,可以对表进行一个自动切换。
- 增量订正,可以考虑和 Flink 的 Savepoint 机制相结合,从而不用再从零开始去初始化状态,减少需要回溯的数据量。
三、当前进展

下面我们介绍一下目前数据一致性管理的阶段性进展。
在社区里,目前我们发起了相关的 issue、PIP 以及邮件进行讨论,大家感兴趣的话可以关注一下相应的进展。如果有新的需求和想法的话,也欢迎大家一起来交流。
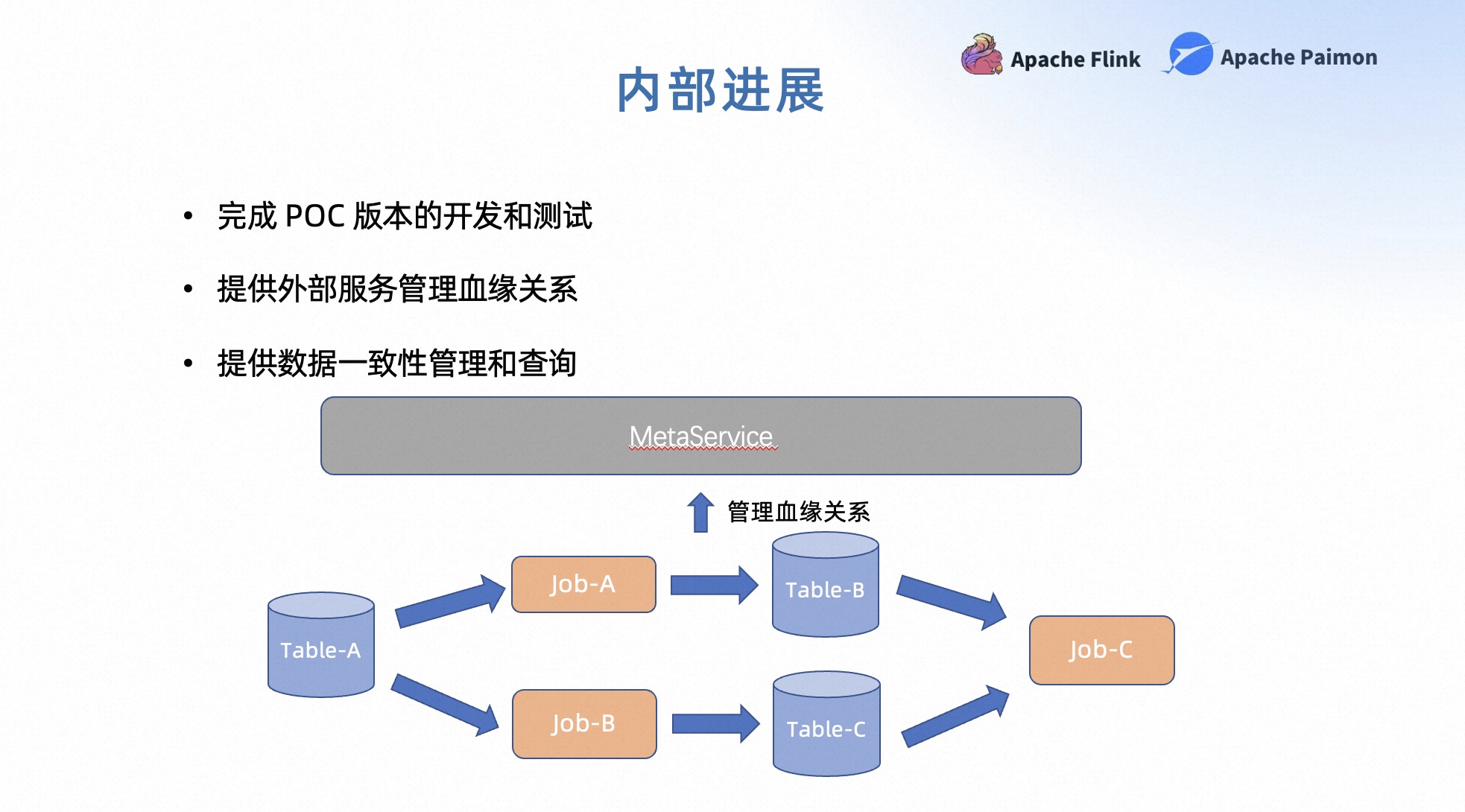
在字节内部,目前我们完成了一个 POC 版本的开发和测试。在这个版本中,我们提供了一个第三方的外部服务,用来管理血缘关系,协调数据版本等。
四、未来规划
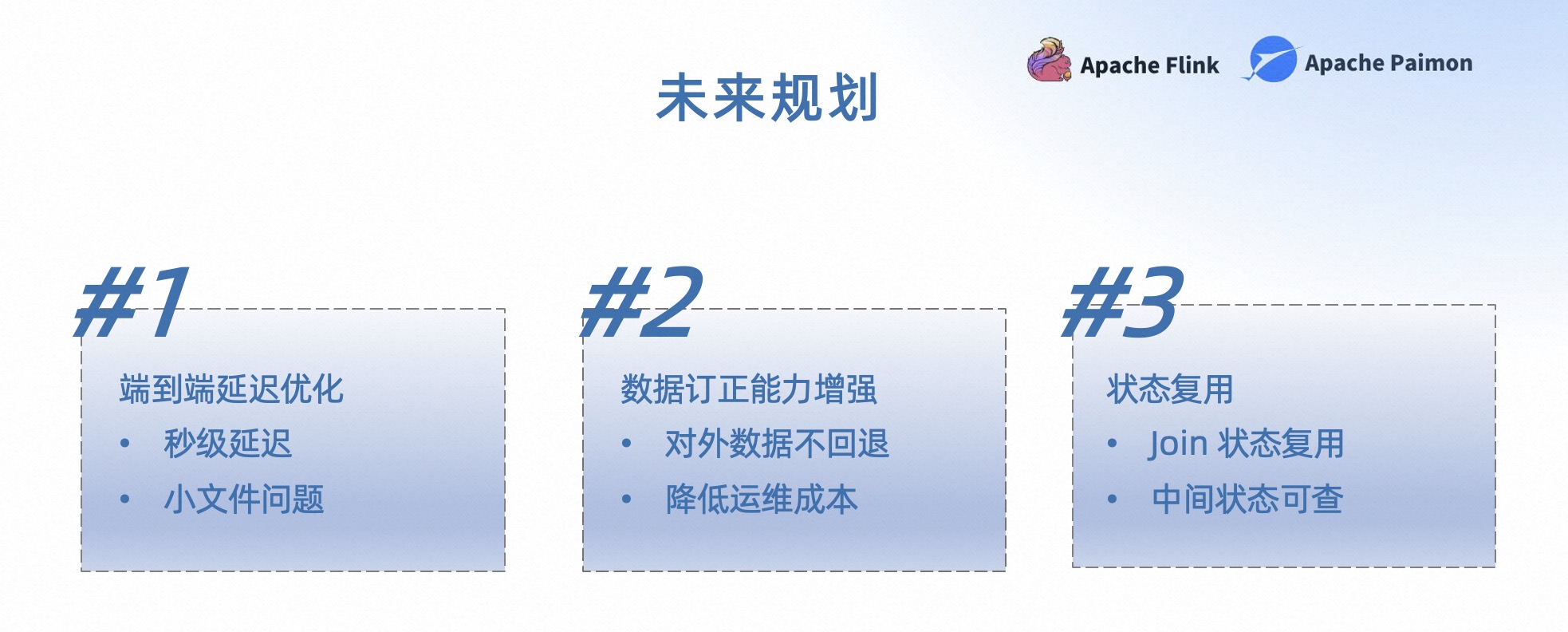
最后介绍一下在 Streaming Warehouse 上的未来规划。
- 第一,端到端延迟优化。在 POC 的过程中,我们发现端到端的延迟很大程度上取决于 Flink Checkpoint 的间隔,同时在内部收集一些业务需求的时候,业务对端到端延迟要求比较高。这样会带来一个问题,当我们降低 Checkpoint 的频率时,会导致比较多的小文件,这需要做一些权衡。下一阶段我们会着重解决端到端延迟的问题。
- 第二,数据订正能力增强。目前这个是业务在实时数仓生产中反馈比较多的痛点,业务希望数据订正的成本可以足够低,同时订正过程产生的中间结果对外不可见。
- 第三,状态复用。在数仓生产中有很多场景是多表关联。目前在 Flink 中,Join 算子会存储左右两条流的数据明细,在多表级联 Join 的场景下,每个 Join 算子都会存储之前的 Join 结果,相当于多存储了一次前面表的明细,会产生非常严重的状态膨胀的问题。业务希望这些状态可以被复用,也就是说相同表的数据只用被存储一份,这样的话可以大幅度的减少状态存储的开销。同时业务也希望这个中间状态是可以被查询的。假设这些状态可以被存储到 Paimon 的表中,采用 Lookup Join 的方式去访问。那么我们就可以使用 Flink 的 SQL 直接查询中间状态。
Q&A
问:血缘关系解析是基于 Flink 的 calcite 吗?
答:不是,是基于 FlinkTableFactory 进行实现,在创建 DynamicTableSource 和 DynamicTableSink 时,提取相关的 Table 信息和任务信息,然后写入到 Paimon 的血缘关系表中。
问:针对于任务出错,数据订正,具体是怎么操作的呢?也就是恢复正常的一个处理流程是怎么样的,大概需要多长时间能够恢复正常呢?
答:我们的目标是希望数据订正的流程可以在系统内自动完成,初期设想是在订正时,基于表的血缘关系对下游表产生相应的镜像表,然后将任务双跑在这条镜像链路上,基于数据血缘关系可以实现数据仍然按照相同的版本进行处理。在两条链路的延迟基本对齐时,进行任务以及表的切换。处理时间依赖处理的数据量,链路的复杂度等。
问:大佬有考虑在此基础上做一个统一的 Paimon 管理服务吗?例如 Paimon 的元数据管理,Compaction 管理,血缘管理等等
答:目前只考虑了实现元数据管理、血缘管理等,对于 Compaction 管理,可能更适合在 Table Service 这样的服务中进行。
问:业务周期跨度比较大,Flink Join 缓存全量的数据?
答:Flink 全量 Join 数据会在状态中存储 Table 的所有数据,同时对于级联 Join 会产生非常严重的状态膨胀问题。根据 Join 的原理,可以考虑将 Join 实现为 Lookup Join + Delta Join,对于历史数据,采用 Lookup join 去查历史表数据,而对于最近的增量数据,将其存储在状态中,通过状态查询进行 Join,这样可以将大量的全量数据存储在 Paimon 表中,状态里只缓存少部分数据。这依赖版本管理的能力来区分数据是 Join 历史数据还是增量数据。
问:字段血缘关系会做吗?要根据 SQL 语法解析的吧
答:暂时不考虑字段血缘关系的实现。
点击查看原文视频 & 演讲PPT
相关文章:
基于 Flink Paimon 实现 Streaming Warehouse 数据一致性管理
摘要:本文整理自字节跳动基础架构工程师李明,在 Apache Paimon Meetup 的分享。本篇内容主要分为四个部分: 背景 方案设计 当前进展 未来规划 点击查看原文视频 & 演讲PPT 一、背景 早期的数仓生产体系主要以离线数仓为主…...

云游戏App简记
注:在安卓手机端使用。其他端不做分析。 App手机游戏PC和主机游戏免费时长(手机游戏)是否排队备注咪咕快游支持。数量一般,和腾讯还有合作,有不少腾讯的游戏支持每日登录签到送30-60分钟,当天失效…...

ChatGPT已打破图灵测试,新的测试方法在路上
生信麻瓜的 ChatGPT 4.0 初体验 偷个懒,用ChatGPT 帮我写段生物信息代码 代码看不懂?ChatGPT 帮你解释,详细到爆! 如果 ChatGPT 给出的的代码不太完善,如何请他一步步改好? 全球最佳的人工智能系统可以通过…...
)
Flask学习笔记_异步CMS(五)
Flask学习笔记_异步CMS(五) 1.环境1.安装nvm2.安装node 2.使用vue-cli创建项目3.安装相关插件4.后台CMS开发1.页面结构1.app.vue搭建结构2.element-icon组件的使用3.iconfont组件的使用 2.使用[Vue-router](https://router.vuejs.org/installation.html)…...

争夺年度智能汽车「中间件」方案提供商TOP10,谁率先入围
进入2023年,整车电子架构升级进入新周期,无论是智能驾驶、智能座舱、车身控制还是信息网络安全,软件赋能仍是行业的主旋律。 作为智能汽车赛道的第三方研究咨询机构,高工智能汽车研究院持续帮助车企、投资机构挖掘具备核心竞争力…...

【Spring Cloud一】微服务基本知识
系列文章目录 微服务基本知识 系列文章目录前言一、系统架构的演变1.1单体架构1.2分层架构1.3分布式架构1.4微服务架构1.5分布式、SOA、微服务的异同点 二、CAP原则三、RESTfulRESTful的核心概念: 四、共识算法 前言 在实际项目开发过程中,目前负责开发…...

swift - 如何在数组大小更改后刷新 ForEach 显示元素的数量(SwiftUI、Xcode 11 Beta 5)
我正在尝试实现一个 View ,该 View 可以在内容数组的大小发生变化时更改显示项目的数量(由 ForEach 循环创建),就像购物应用程序可能会在用户下拉刷新后更改其可用项目的数量一样 这是我到目前为止尝试过的一些代码。如果我没记错的话,这些适…...

编程导航算法村第七关 |二叉树的遍历
编程导航算法村第七关 | 二叉树的遍历 前序遍历(递归) public List<Integer> preorderTraversal(TreeNode root) {ArrayList<Integer> result new ArrayList<Integer>();preorder(root, result);return result;}public void preorde…...

【docker】docker-compose安装带ui页面的kafka集群
docker-compose 安装带kafka-ui 的kafka集群 在日常的工作当中,kafka集群作为常用的中间件,其搭建过程略显繁琐,需要配置的文件颇多,为了方便各位初学者快速体验kafka的魅力,本文采取一键式安装kafka-3.3.1࿰…...

java实现多级菜单
/** * 查询所有菜单 */ public BaseWebResponse<Object> getAllMenus() { List<SystemMenuInfo> systemMenuInfoList menuInfoMapper.getAllMenus(); List<SystemMenuInfo> menuTree buildMenuTree(systemMenuInfoList); return setResultSuccess(&q…...

HTML中元素和标签有什么区别?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 标签(Tag)⭐元素(Element)⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅&a…...

android 如何分析应用的内存(十三)——perfetto
android 如何分析应用的内存(十三) 本篇文章是native内存的最后一篇文章——perfetto perfetto简介 从2018年始,android开发者峰会正式推出perfetto工具。从此perfetto成为安卓最重要的工具之一。在2018年以前,android使用syst…...
Chapter20 音乐
目录 音乐 琴键 哆来咪 振动与调式 利萨如曲线 和声与音调与和弦 音乐 在音乐理论中,一个八音度(octave)是一个频率范围相差二倍的区间。在大多数西洋乐器中,一个八音度被分为12个频率比相等的半音程(semitone&a…...

详解Nodejs中的模块化
Nodejs是一个基于Chrome V8引擎的JavaScript运行时环境,它允许开发者使用JavaScript在服务器端运行代码。在Nodejs中,模块化是一种组织和重用代码的重要方式。模块化允许我们将代码拆分成小块,使得代码结构更清晰、易于维护,并促进…...

debug思路 - maven构建报错
问题:maven面板中,进行compile、deploy操作时报错。 debug步骤: 1、鼠标右键选择“修改运行配置”。在运行命令中添加参数-X,用于产生执行调试输出。例如:compile -f -X pom.xml。 2、再次进行compile、deploy操作&…...
DSP学习笔记
间接寻址(通过放在辅助寄存器里面,可以对地址包括很多操作,1,-1,/-平移量,辅助寄存器内容的修改是在ARAU0和ARAU1中完成的。分为单操作数和双操作数,有很多模式在ARAU。单操作数间接寻址&#x…...

Java中的Apache Commons Math是什么?
Java中的Apache Commons Math是一个开源的数学库,它提供了许多常用的数学函数和算法,例如线性代数、微积分、统计、插值、拟合等。这个库对于需要处理大量数据的开发者来说非常有用,因为它可以大大简化代码并提高效率。 让我们从新手的角度来…...
规划路线(微信小程序、H5)
//地图getLocationDian(e1, e2) {console.log(e1, e2);let self this;self.xx1 [];self.xx2 [];self.points [];// self.markers[]console.log(self.markers, >marks);// self.$jsonp(url, data).then(re > {// var coors re.result.routes[0].polyline;// for (v…...

【CSS】视频文字特效
效果展示 index.html <!DOCTYPE html> <html><head><title> Document </title><link type"text/css" rel"styleSheet" href"index.css" /></head><body><div class"container"&g…...
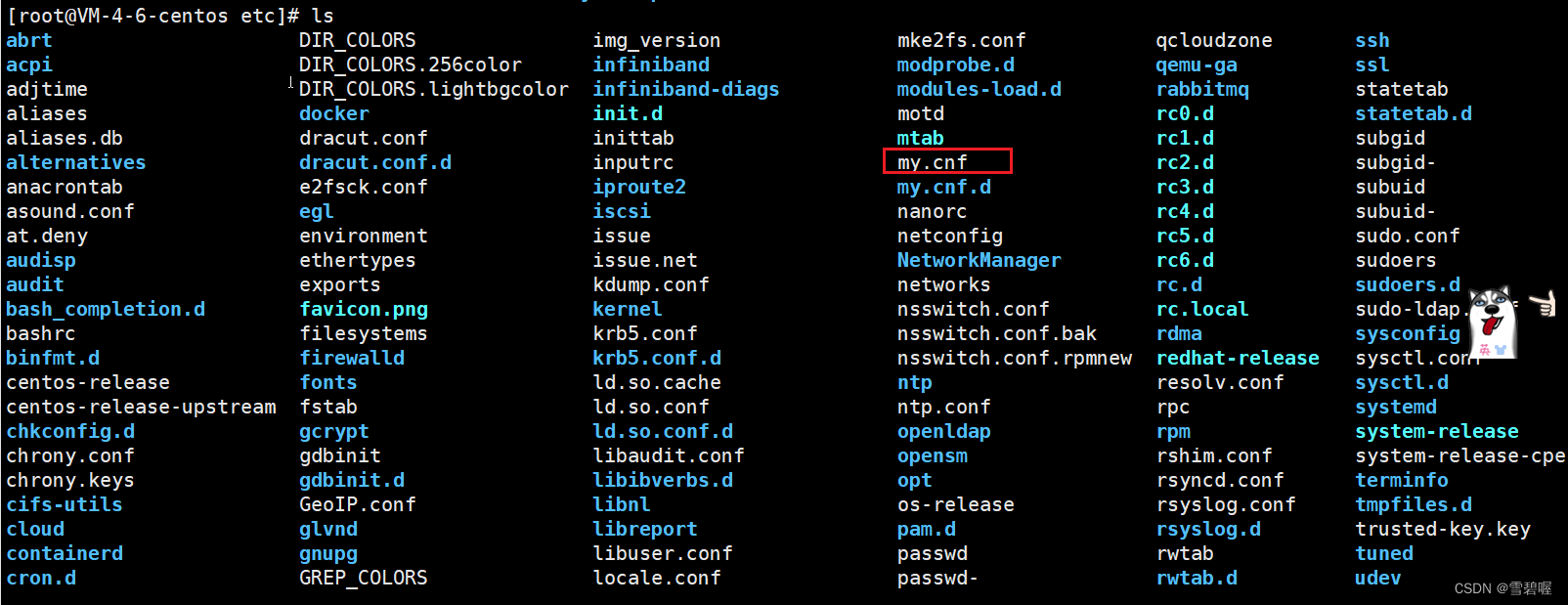
linux-MySQL的数据目录
总结: window中的my.ini linux 中 /etc/my.cnfwindow中的D:\soft\mysql-5.7.35-winx64\data linux 中 /var/lib/mysql 1.查找与mysql有关的目录 find / -name mysql [rootVM-4-6-centos etc]# find / -name mysql /opt/mysql /etc/selinux/targeted/tmp/modul…...

如何永久保存番茄小说?3个强力方案告别网络依赖
如何永久保存番茄小说?3个强力方案告别网络依赖 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更时突然断网?是否担心喜欢的小说某天会从平台消失…...

深夜告警炸裂?这份Linux故障排查“作战地图”请收好判
先唠两句:参数就像餐厅点单 把API想象成一家餐厅的“后厨系统”。 ? 路径参数/dishes/{dish_id} -> 好比你要点“宫保鸡丁”这道具体的菜,它是菜单(资源路径)的一部分。查询参数/dishes?spicytrue&typeSichuan -> 好比…...
 最管用的skills合集,建议是收藏!)
新的科研生产力:小龙虾(Claude Code) 最管用的skills合集,建议是收藏!
最近小龙虾火出了圈子。无论是做生物科研的老师同学,还是开发者,大家都想当第一个吃“龙虾”的人。但很多人用龙虾写论文的时候,首先卡在下载的这个问题上,其次是缺乏稳定性,输出的文章质量时好时坏。小编最近mark了一…...

探索Mesa:构建复杂系统仿真的Python框架
探索Mesa:构建复杂系统仿真的Python框架 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.com/gh_mirrors/me/mesa …...

Competitive Companion全链路解决方案:编程竞赛效率提升指南
Competitive Companion全链路解决方案:编程竞赛效率提升指南 【免费下载链接】competitive-companion Browser extension which parses competitive programming problems 项目地址: https://gitcode.com/gh_mirrors/co/competitive-companion 一、工具定位与…...

多语言提示词设计:中文语境下的提示工程终极指南
多语言提示词设计:中文语境下的提示工程终极指南 【免费下载链接】courses Anthropics educational courses 项目地址: https://gitcode.com/GitHub_Trending/cours/courses 在全球化AI应用时代,多语言提示词设计已成为开发者必备技能。GitHub推荐…...

百川2-13B中文优势:OpenClaw在古籍数字化中的实践案例
百川2-13B中文优势:OpenClaw在古籍数字化中的实践案例 1. 项目背景与需求 去年参与一个民间古籍保护项目时,遇到了一个棘手问题:团队收集了大量民国时期的线装书扫描件,但数字化过程异常艰难。这些古籍多为繁体竖排、无标点断句…...

破解网盘限速迷宫:技术侦探带你掌握高效直链解析方案
破解网盘限速迷宫:技术侦探带你掌握高效直链解析方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

FireRedASR-AED-L语音识别模型WebUI部署教程:Python环境快速配置指南
FireRedASR-AED-L语音识别模型WebUI部署教程:Python环境快速配置指南 想试试最新的语音识别模型,但被复杂的Python环境配置和依赖包冲突劝退?这感觉我太懂了。每次看到新模型发布,兴致勃勃地准备上手,结果第一步环境搭…...
AXI4-Stream视频数据流与FIFO深度优化)
Xilinx Video IP(二)AXI4-Stream视频数据流与FIFO深度优化
1. AXI4-Stream视频数据流基础 第一次接触Xilinx的Video IP时,很多人会被AXI4-Stream接口搞得一头雾水。其实把它想象成一条传送带就很好理解了——视频数据就像流水线上的包裹,按照固定节奏从源头运送到目的地。这条"传送带"有几个关键特性&a…...