【python】使用Selenium和Chrome WebDriver来获取 【腾讯云 Cloud Studio 实战训练营】中的文章信息
文章目录
- 前言
- 导入依赖库
- 设置ChromeDriver的路径
- 创建Chrome WebDriver对象
- 打开网页
- 找到结果元素
- 创建一个空列表用于存储数据
- 遍历结果元素并提取数据
- 提取标题、作者、发布时间等信息
- 判断是否为目标文章
- 提取目标文章的描述、阅读数量、点赞数量、评论数量等信息
- 将提取的数据存储为字典格式
- 将字典添加到数据列表中
- 保存数据为JSON文件
- 关闭WebDriver
- 完整代码
- 运行效果
- 结束语

前言
本文介绍了如何使用Selenium和Chrome WebDriver来获取 【腾讯云 Cloud Studio 实战训练营】中的文章信息。在这篇文章中,我们首先导入了需要使用的依赖库,然后设置了ChromeDriver的路径,并创建了Chrome WebDriver对象。接着,我们使用WebDriver打开了指定的网页,并等待页面加载完成。随后,通过定位元素的方式找到了搜索结果列表的父元素,并提取了每个搜索结果的标题、作者、发布时间等信息。最后,我们将提取到的数据存储为JSON文件,并关闭了WebDriver。
导入依赖库

from selenium import webdriver
import json
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import time
这段代码导入了需要使用的依赖库,包括selenium、json,以及一些常用模块。
设置ChromeDriver的路径

driver_path = ''
在这里,driver_path变量存储了ChromeDriver的路径,需要根据实际情况进行设置。
创建Chrome WebDriver对象
driver = webdriver.Chrome(driver_path)
通过webdriver.Chrome()方法创建了一个Chrome WebDriver对象,并将其赋值给变量driver。
打开网页

url = 'https://so.csdn.net/so/search?spm=1001.2100.3001.7499&q=%E8%85%BE%E8%AE%AF%E4%BA%91%20Cloud%20Studio%20%E5%AE%9E%E6%88%98%E8%AE%AD%E7%BB%83%E8%90%A5&t=blog&u=&utm_medium=distribute.pc_search_hot_word.none-task-hot_word-alirecmd-1-%E8%85%BE%E8%AE%AF%E4%BA%91%20Cloud%20Studio%20%E5%AE%9E%E6%88%98%E8%AE%AD%E7%BB%83%E8%90%A5-null-null.172%5Ev8%5Etag_flag&depth_1-utm_source=distribute.pc_search_hot_word.none-task-hot_word-alirecmd-1-%E8%85%BE%E8%AE%AF%E4%BA%91%20Cloud%20Studio%20%E5%AE%9E%E6%88%98%E8%AE%AD%E7%BB%83%E8%90%A5-null-null.172%5Ev8%5Etag_flag'
driver.get(url)
time.sleep(5)
使用driver.get()方法打开了指定的网页。这里的URL是搜索某个关键词的CSDN博客链接。然后通过time.sleep()方法等待页面加载完成。
找到结果元素
results = driver.find_element(By.CLASS_NAME, "so-result-list").find_elements(By.CLASS_NAME, "list-item")
使用driver.find_element()方法找到了搜索结果列表的父元素,再通过find_elements()方法找到所有的搜索结果元素,并将其赋值给变量results。
创建一个空列表用于存储数据
data = []
创建一个空列表data,用于存储提取出的数据。
遍历结果元素并提取数据
for result in results:...
遍历结果元素列表results,对每一个结果元素进行数据提取。
提取标题、作者、发布时间等信息
title = result.find_element(By.CLASS_NAME, "title").find_element(By.TAG_NAME, 'a').textauthor = result.find_element(By.CLASS_NAME, "item-ft").find_element(By.CLASS_NAME, 'name-text').textpushTime = result.find_element(By.CLASS_NAME, "item-ft").find_element(By.CLASS_NAME, 'time').text
通过find_element()方法找到标题、作者和发布时间等元素,并使用.text属性获取对应的文本内容。
判断是否为目标文章
if "实战训练营】" in title:...else:print(f'不是目标文章, 当前文章标题是:{title}')
通过判断标题中是否包含关键字"实战训练营】"来确定是否为目标文章。如果是目标文章,则进行下一步的数据提取;否则打印当前文章的标题。
提取目标文章的描述、阅读数量、点赞数量、评论数量等信息
description = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME, "row2").texttry:read = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,"item-ft").find_element(By.CLASS_NAME, "btm-view").find_element(By.CLASS_NAME, "num").textexcept NoSuchElementException:read = 0try:zan = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,"item-ft").find_element(By.CLASS_NAME, "btm-dig").find_element(By.CLASS_NAME, "num").textexcept NoSuchElementException:zan = 0try:comment = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,"item-ft").find_element(By.CLASS_NAME, "btm-comment").find_element(By.CLASS_NAME, "num").textexcept NoSuchElementException:comment = 0
使用find_element()方法逐层查找目标文章的描述、阅读数量、点赞数量、评论数量等元素,并通过.text属性获取对应的文本内容。如果某个元素不存在,则将对应的变量赋值为0。
将提取的数据存储为字典格式
item = {'title': title, # 标题'description': description, # 描述'read': read, # 阅读数量'zan': zan, # 点赞数量'comment': comment, # 评论数量'author': author, # 作者'pushTime': pushTime # 发布时间}
将提取到的标题、描述、阅读数量等信息存储为一个字典item。
将字典添加到数据列表中
data.append(item)
将提取到的字典item添加到数据列表data中。
保存数据为JSON文件
with open('data.json', 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)
使用json.dump()方法将数据列表data以JSON格式保存到文件"data.json"中。
关闭WebDriver
driver.quit()
关闭Chrome WebDriver。
完整代码
from selenium import webdriver
import json
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import time# 设置ChromeDriver的路径
driver_path = ''# 创建Chrome WebDriver对象
driver = webdriver.Chrome(driver_path)# 打开网页
url = 'https://so.csdn.net/so/search?spm=1001.2100.3001.7499&q=%E8%85%BE%E8%AE%AF%E4%BA%91%20Cloud%20Studio%20%E5%AE%9E%E6%88%98%E8%AE%AD%E7%BB%83%E8%90%A5&t=blog&u=&utm_medium=distribute.pc_search_hot_word.none-task-hot_word-alirecmd-1-%E8%85%BE%E8%AE%AF%E4%BA%91%20Cloud%20Studio%20%E5%AE%9E%E6%88%98%E8%AE%AD%E7%BB%83%E8%90%A5-null-null.172%5Ev8%5Etag_flag&depth_1-utm_source=distribute.pc_search_hot_word.none-task-hot_word-alirecmd-1-%E8%85%BE%E8%AE%AF%E4%BA%91%20Cloud%20Studio%20%E5%AE%9E%E6%88%98%E8%AE%AD%E7%BB%83%E8%90%A5-null-null.172%5Ev8%5Etag_flag'
driver.get(url)
time.sleep(5)# 找到结果元素
results = driver.find_element(By.CLASS_NAME, "so-result-list").find_elements(By.CLASS_NAME, "list-item")# 创建一个空列表用于存储数据
data = []# 遍历结果元素并提取数据
for result in results:time.sleep(5)title = result.find_element(By.CLASS_NAME, "title").find_element(By.TAG_NAME, 'a').textauthor = result.find_element(By.CLASS_NAME, "item-ft").find_element(By.CLASS_NAME, 'name-text').textpushTime = result.find_element(By.CLASS_NAME, "item-ft").find_element(By.CLASS_NAME, 'time').textif "实战训练营】" in title:description = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME, "row2").text# readEle = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME, "item-ft").find_element(# By.CLASS_NAME, "btm-view")# zanEle = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME, "item-ft").find_element(# By.CLASS_NAME, "btm-dig")# print(zanEle)# commentEle = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,# "item-ft").find_element(# By.CLASS_NAME, "btm-comment")try:read = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,"item-ft").find_element(By.CLASS_NAME, "btm-view").find_element(By.CLASS_NAME, "num").text# read = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,# "item-ft").find_element(# By.CLASS_NAME, "btm-view").find_element(By.CLASS_NAME, "num").textexcept NoSuchElementException:read = 0try:zan = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,"item-ft").find_element(By.CLASS_NAME, "btm-dig").find_element(By.CLASS_NAME, "num").textexcept NoSuchElementException:zan = 0try:comment = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME,"item-ft").find_element(By.CLASS_NAME, "btm-comment").find_element(By.CLASS_NAME, "num").textexcept NoSuchElementException:comment = 0# read = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME, "item-ft").find_element(By.CLASS_NAME, "btm-view").find_element(By.CLASS_NAME, "num").text# zan = result.find_element(By.CLASS_NAME, "item-bd__cont").find_element(By.CLASS_NAME, "item-ft").find_element(By.CLASS_NAME, "btm-dig").find_element(By.CLASS_NAME, "num").text# comment = result.find_element(By.CLASS_NAME,"item-bd__cont").find_element(By.CLASS_NAME, "item-ft").find_element(By.CLASS_NAME, "btm-comment").find_element(By.CLASS_NAME, "num").textidx = result.get_attribute('i')# 将提取的数据存储为字典格式item = {'title': title, # 标题'description': description, # 描述'read': read, # 阅读数量'zan': zan, # 点赞数量'comment': comment, # 评论数量'author': author, # 作者'pushTime': pushTime # 发布时间}print(idx)# 将字典添加到数据列表中data.append(item)else:print(f'不是目标文章, 当前文章标题是:{title}')# 保存数据为JSON文件with open('data.json', 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)# 关闭WebDriver
driver.quit()运行效果
运行的数据会保存到json 中

结束语
通过本文的介绍,我们学习了如何使用Selenium和Chrome WebDriver进行网页数据爬取,掌握了定位元素、提取信息和数据存储的相关技巧。这些技术对于获取网页上的数据非常有用,可以帮助我们实现自动化的数据采集和处理。希望本文对您有所帮助!如果您对网页数据爬取和数据处理有更多兴趣和需求,可以继续深入学习和探索相关内容。祝您在数据领域取得更多的成果!
相关文章:
【python】使用Selenium和Chrome WebDriver来获取 【腾讯云 Cloud Studio 实战训练营】中的文章信息
文章目录 前言导入依赖库设置ChromeDriver的路径创建Chrome WebDriver对象打开网页找到结果元素创建一个空列表用于存储数据遍历结果元素并提取数据提取标题、作者、发布时间等信息判断是否为目标文章提取目标文章的描述、阅读数量、点赞数量、评论数量等信息将提取的数据存储为…...

使用Feign 的远程调用,把mysql数据导入es
要把数据库数据导入到elasticsearch中,包括下面几步: 1)将商品微服务中的分页查询商品接口定义为一个FeignClient,放到feign-api模块中 2)搜索服务编写一个测试业务,实现下面功能: 调用item-ser…...
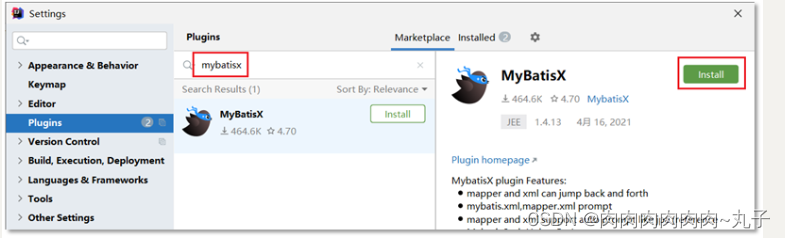
Java课题笔记~ MyBatis接口开发(代理开发)
使用XML文件进行开发,在调用SqlSession进行操作时,需要指定MyBatis映射文件中的方法,这种调用方式过于烦琐。为解决此问题,MyBatis提供了接口开发的方式。 接口开发的目的: 解决原生方式中的硬编码 简化后期执行SQL …...

从数学到深度学习的学习资料及教程合集
诸神缄默不语-个人CSDN博文目录 目前仅收集免费内容,最多需要买本纸质书。 付费的如果有免费版本我也会收录。 链接如失效请联系我。 这个笔记主要是为我自己准备的,算是一个可公开的to do list(其实做不完的我也知道)ÿ…...
报错)
nn.CrossEntropyLoss()报错
RuntimeError: “nll_loss_forward_reduce_cuda_kernel_2d_index” not implemented for ‘Float’ Traceback (most recent call last): File "<string>", line 1, in <module> File "/home/zz/anaconda3/envs/torch1.11/lib/python3.7/site-pack…...
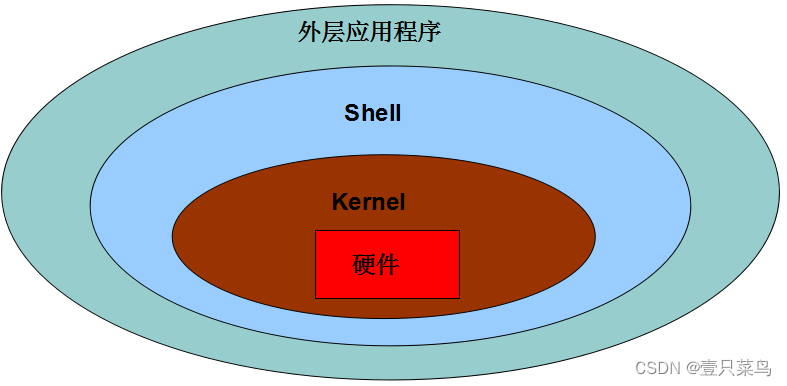
【BASH】回顾与知识点梳理(一)
【BASH】回顾与知识点梳理 一 前言一. 认识与学习 BASH1.1 硬件、核心与 Shell1.2 为何要学文字接口的 shell?1.3 系统的合法 shell 与 /etc/shells 功能1.4 Bash shell 的功能1.5 查询指令是否为 Bash shell 的内建命令: type1.6 指令的下达与快速编辑按…...
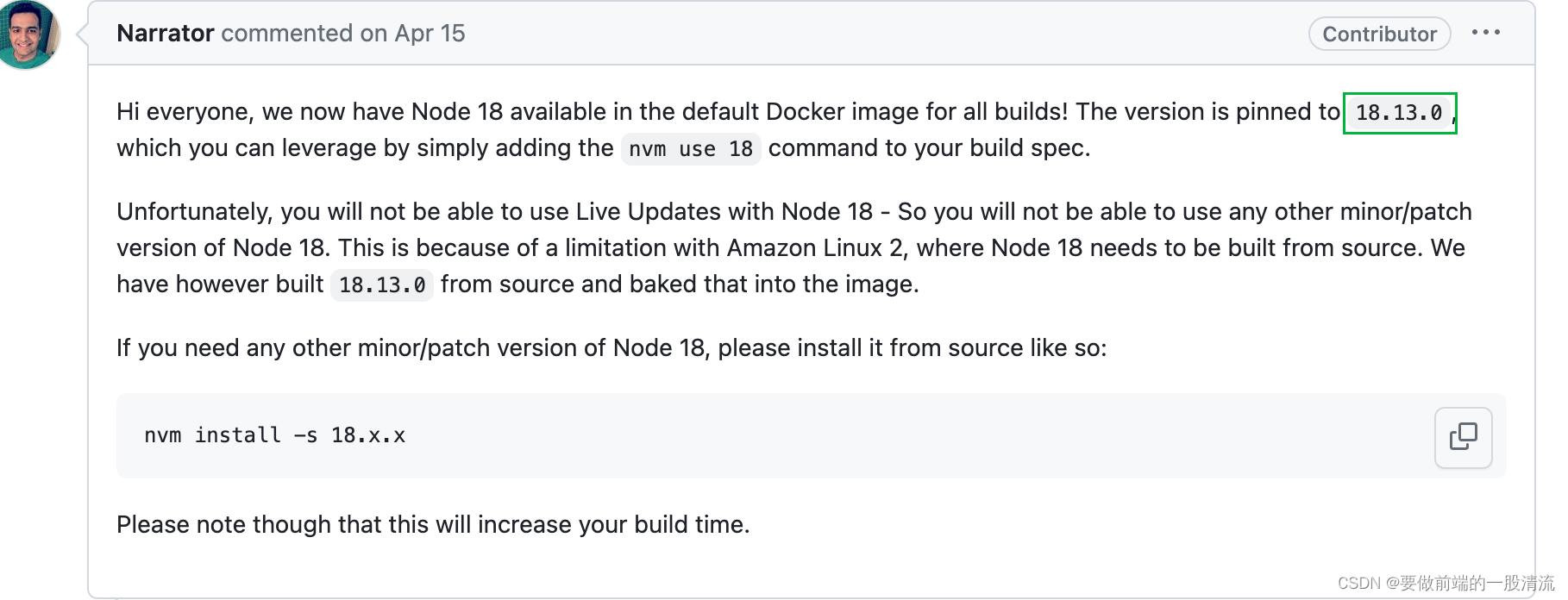
AWS Amplify 部署node版本18报错修复
Amplify env:Amazon Linux:2 Build Error : Specified Node 18 but GLIBC_2.27 or GLIBC_2.28 not found on build 一、原因 报错原因是因为默认情况下,AWS Amplify 使用 Amazon Linux:2 作为其构建镜像,并自带 GLIBC 2.26。不过,…...

K8S添加yum源并安装kubectl/kubeadm/kubelet组件
1.安装kubectl/kubeadm/kubelet ##添加yum 源 cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] nameKubernetes baseurlhttps://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled1 gpgcheck0 repo_gpgcheck0 gpgkeyhttps://mirr…...

kafka生产者指定ip
kafka生产者指定ip 最近工作中遇到一个问题,记录一下,需求中要求往kafka上推送信息。本来是个很简单的需求,但是踩了一个坑。 我通过spring boot集成了kafka写了一个生产者,客户那边给我三个节点的ip,然后我也没多想…...
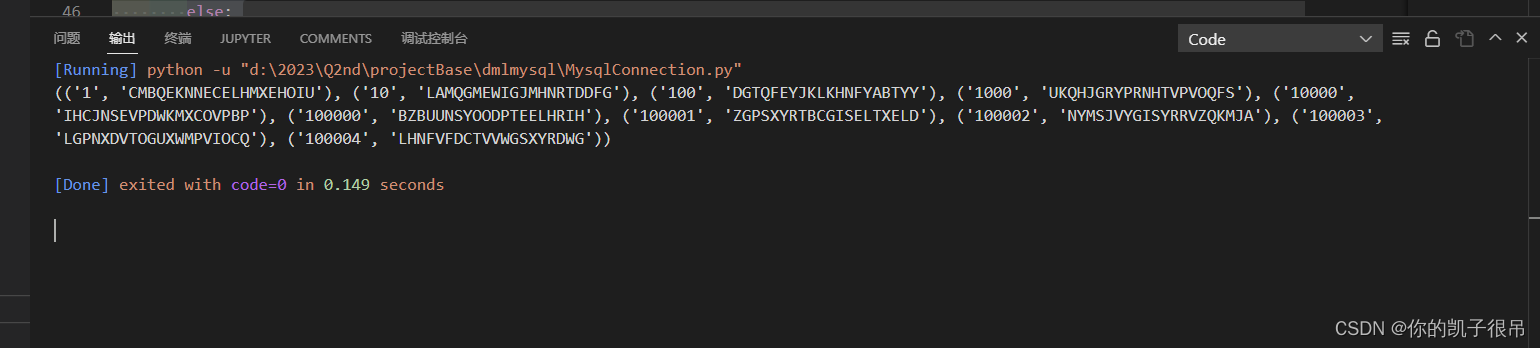
python 封装sql 增删改查连接MySQL
select * from Teacher limit 10 连接字符串配置MysqlConfig.py class MysqlConfig:HOST 192.168.56.210PORT 3306USER rootPASSWORD 1qaz0987654321DBStudentDBCHARSET utf8封装增删改查MysqlConnection.py Author: tkhywang 2810248865qq.com Date: 2023-06-19 15:44:48 Las…...
Flink正常消费一段时间后,大量反压,看着像卡住了,但又没有报错。
文章目录 前言一、原因分析二、解决方案 前言 前面我也有提到,发现flink运行一段时间后,不再继续消费的问题。这个问题困扰了我非常久,一开始也很迷茫。又因为比较忙,所以一直没有时间能够去寻找答案,只是通过每天重启…...
软件测试需求分析的常用方法
软件测试需求分析时,应要求产品人员对需求进行讲解,并使用相对应的方法进行科学分析,否则无法保障软件测试的完整性和科学性,从而造成在项目中后期Bug频出、风险增大等问题。 而常用的测试需求分析的方法: 1、功能分解…...
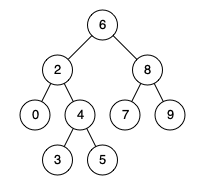
数据结构10 -查找_树表查找
创建二叉搜索树 二叉搜索树 二叉搜索树是有数值的了,二叉搜索树是一个有序树。 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它…...

第126天:内网安全-隧道技术SSHDNSICMPSMB上线通讯LinuxMac
知识点 #知识点: 1、入站规则不出网上线方案 2、出站规则不出网上线方案 3、隧道技术-SMB&ICMP&DNS&SSH 4、控制上线-Linux&Mac&IOS&Android-连接方向:正向&反向(基础课程有讲过) -内网穿透…...

开发一个饲料商城小程序需要多少钱
随着宠物行业的蓬勃发展,饲料商城小程序作为一个重要的销售渠道,吸引了越来越多的投资者。那么,开发一套饲料商城小程序需要多少钱呢?本文将为您详细解答。 首先,开发一套饲料商城小程序的价格受到多个因素的影响&…...

Emacs之set-face-attribute与font-lock-add-keywords用法区别(一百二十八)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

JavaScript高阶函数和闭包
在JavaScript编程中,高阶函数和闭包是两个重要而又常见的概念。它们是函数式编程的重要组成部分,可以让我们的代码更加灵活、简洁和高效。本文将详细解释高阶函数和闭包的概念、用法以及它们在JavaScript中的重要性。 高阶函数 1. 什么是高阶函数&…...

私有化部署企业IM即时通讯:提升效率、防止泄密、高效协同办公
随着科技的飞速发展和智能手机的普及,即时通讯(IM)应用在我们的生活和工作中变得越来越重要。在企业中,IM已成为员工之间交流沟通的主要方式之一。然而,对于大多数企业来说,选择私有化部署企业IM即时通讯软…...
react ant icon的简单使用
refer: 快速上手 - Ant Design 1.引入ant npm install antd --save 2.在页面引用: import { StarOutlined } from ant-design/icons; 如果想要引入多个icon,可以这样书写: import { UserOutlined, MailOutlined, PieChartOutlined } fr…...

用Rust实现23种设计模式之原型模式
在 Rust 中,原型模式可以通过实现 Clone trait 来实现。原型模式是一种创建型设计模式,它允许通过复制现有对象来创建新对象,而无需显式地使用构造函数。下面是一个使用 Rust 实现原型模式的示例,带有详细的代码注释和说明&#x…...

【声音克隆】Qwen3-TTS-12Hz-1.7B-Base零基础部署教程:5分钟搞定10国语言语音合成
Qwen3-TTS-12Hz-1.7B-Base零基础部署教程:5分钟搞定10国语言语音合成 声音克隆技术迎来重大突破!Qwen3-TTS-12Hz-1.7B-Base作为新一代语音合成模型,支持中文、英文、日文等10种主要语言和多种方言风格。本文将带你从零开始,只需5…...

mac上安装openclaw从入门到删除
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录安装拉取最新版本拉取对应版本卸载1、卸载openclaw2、卸载openclaw CLI3、确认是否删除参考来源保姆级!Mac 安装小龙虾 OpenClaw 全教程OpenClaw 卸载教程…...

Qwen3-Reranker完整指南:支持Markdown/HTML文档解析的增强版方案
Qwen3-Reranker完整指南:支持Markdown/HTML文档解析的增强版方案 1. 引言:重新定义文档检索的精准度 在日常工作中,你是否遇到过这样的困扰:用关键词搜索文档时,系统返回的结果看似相关,实际上却偏离了你…...

PyTorch 2.8深度学习镜像部署:RTX 4090D下NVIDIA Triton模型仓库构建
PyTorch 2.8深度学习镜像部署:RTX 4090D下NVIDIA Triton模型仓库构建 1. 镜像环境概述 PyTorch 2.8深度学习镜像为RTX 4090D显卡量身打造,基于CUDA 12.4深度优化,提供开箱即用的高性能计算环境。这个镜像特别适合需要大规模并行计算和高效内…...

Ollama小白入门:从零开始使用Yi-Coder-1.5B,体验AI写代码
Ollama小白入门:从零开始使用Yi-Coder-1.5B,体验AI写代码 1. 为什么你需要Yi-Coder-1.5B 作为一个开发者,你是否经常遇到这些情况: 知道要实现什么功能,但写不出具体代码需要快速生成一些模板代码来节省时间学习新编…...

科研助手实战:OpenClaw+Phi-3-vision自动整理文献图表数据
科研助手实战:OpenClawPhi-3-vision自动整理文献图表数据 1. 为什么需要自动化文献整理 作为一名经常需要阅读大量论文的研究者,我发现自己花费在整理文献数据上的时间越来越长。每次下载几十篇PDF,手动截图关键图表、复制数据表格、整理参…...
)
从沙漏到矿机:聊聊离散元法DEM是怎么‘算’出颗粒世界的(附Rocky/EDEM软件对比与学习资源)
从沙漏到矿机:离散元法DEM如何重构颗粒世界的数字镜像 沙漏里的细沙流淌时,每一粒沙子都在重力和碰撞中演绎着独特的运动轨迹。这种看似简单的物理现象背后,隐藏着一个复杂的多体动力学问题——如何精确描述成千上万颗粒之间的相互作用&#…...

七、桥接模式
目的 : 将抽象部分与其实现部分分离,使它们都可以独立地变化。核心 : 使用组合代替继承,抽象类包含一个实现接口的引用,将具体实现委托给该引用。场景 : 跨平台 UI 开发、数据库驱动、设备控制等。 首先是…...
)
ESP32S3变身HID设备:用esp-iot-solution实现USB键盘鼠标(附常见编译错误修复)
ESP32S3实战:基于esp-iot-solution打造高响应USB HID设备的全流程指南 当ESP32S3遇上USB HID协议,开发者手中的这块开发板瞬间化身为键盘鼠标模拟利器。不同于市面上简单的教程,本文将带您深入esp-iot-solution框架的核心,从环境搭…...

Nginx 正向代理与反向代理的区别
一:Nginx 正向代理与反向代理的区别 正向代理:替客户端出门办事 反向代理:替服务器接客办事生活化比喻(最容易理解) 1. 正向代理 你的代购 / 跑腿 你想买国外的东西,但你自己不方便/不能直接买。 你找一个…...