python机器学习(七)决策树(下) 特征工程、字典特征、文本特征、决策树算法API、可视化、解决回归问题
决策树算法
特征工程-特征提取
特征提取就是将任意数据转换为可用于机器学习的数字特征。计算机无法直接识别字符串,将字符串转换为机器可以读懂的数字特征,才能让计算机理解该字符串(特征)表达的意义。
主要分为:字典特征提取(特征离散化)、文本特征提取(文章中特征词汇出现的频次)。
字典特征提取
对类别数据进行转换。
计算机不能够识别直接传入的城市、温度数据,需要转换为0,1的编码才能够被计算机所识别。
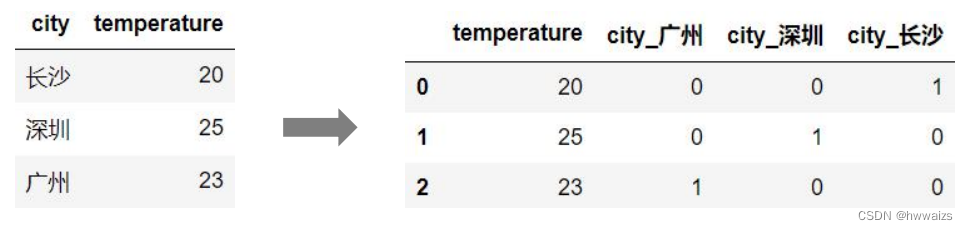
用代码实现就为:
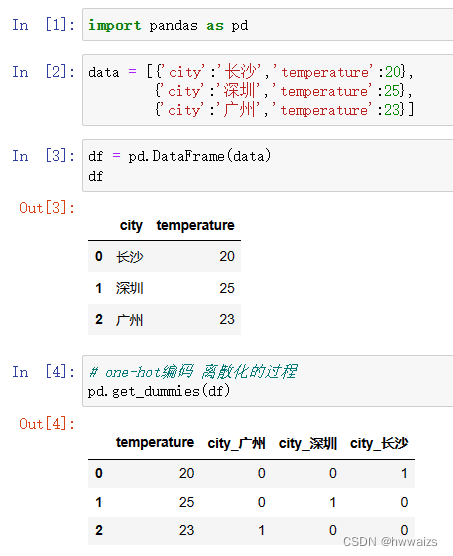
字典特征提取API
sklearn.feature_extraction.DictVectorizer(sparse=Ture,...)
DictVectorizer.fit_transform(X),X:字典或者包含字典的迭代器返回值,返回sparse矩阵
DictVectorizer.get_feature_names()返回类别名称

当数据量比较大的时候,使用sparse矩阵能更好的显示特征数据,更加的直观,没有显示0数据,更加节省内存。
文本特征提取
对文本数据进行特征值化,一篇文章中每个词语出现的频次。
文本特征提取API
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
返回词频矩阵。
CountVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
CountVectorizer.get_feature_names()返回值:单词列表
英文文本特征提取实现
需求:体现以下段落的词汇出现的频次
[“Life is a never - ending road”,“I walk,walk,keep walking.”]
注意:
1.文本特征提取没有sparse参数,只能以默认的sparse矩阵接收
2.单个的字母,如I,a都不会统计
3.通过stop_words指定停用词
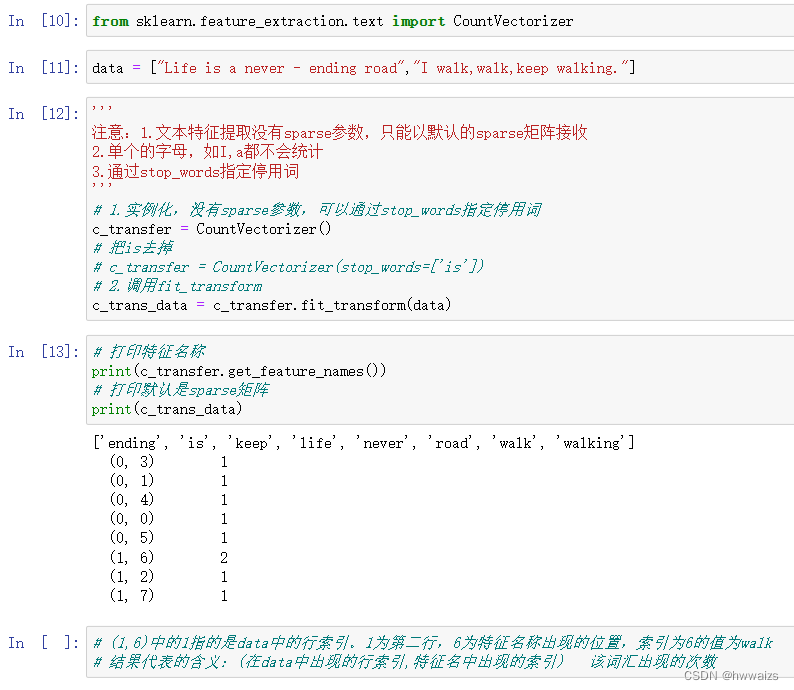
中文文本特征提取实现
需求:体现以下段落的词汇出现的频次
data = [‘这一次相遇’,‘美得彻骨,美得震颤,美得孤绝,美得惊艳。’]

需求:体现以下文本的词汇出现的频次
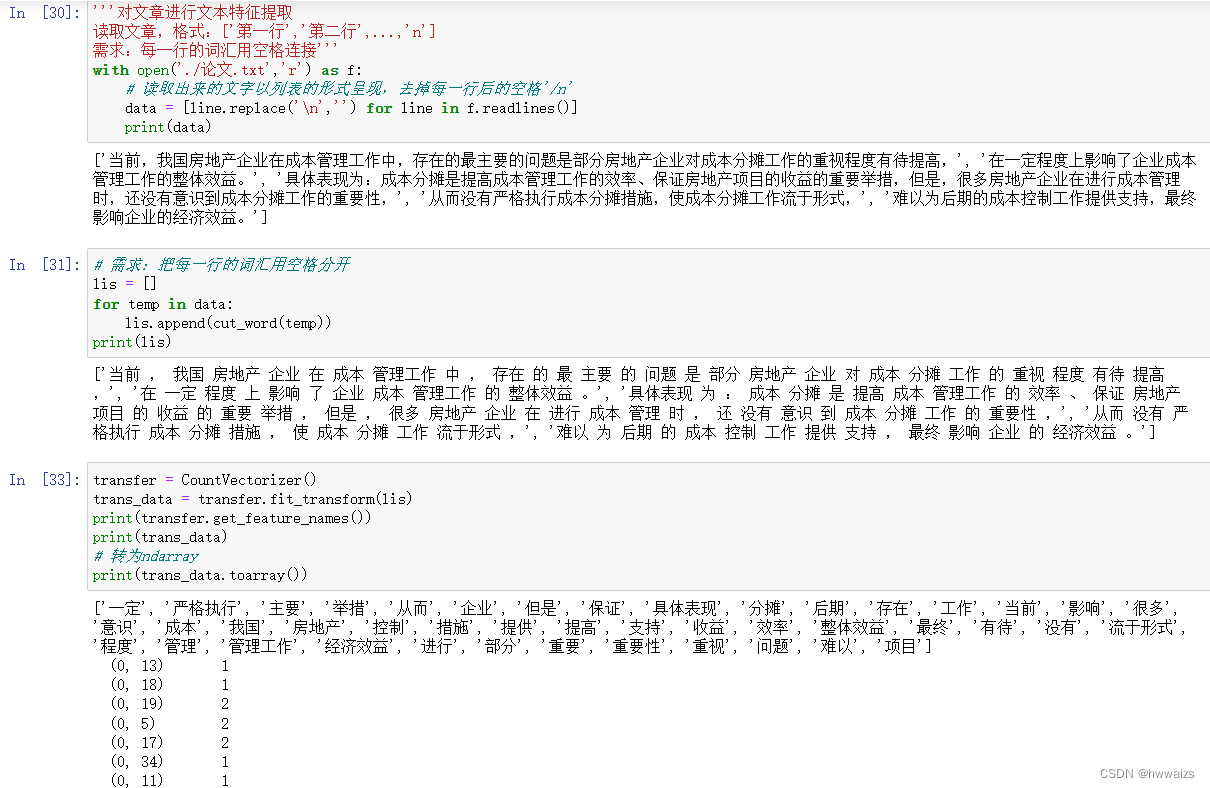
把文章中的词汇统一提取出来,去掉重复值后放到一个列表里,矩阵里显示的是每个词汇在每一行中出现的次数。根据词汇出现的多少可以把 文章归纳为跟词汇相关的文章。
Tf-idf文本特征提取
TF-IDF的主要思想是:如果某个词语或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类。
TF-IDF的作用:用于评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
Tf-idf文本特征提取公式: t f i d f i , j = t f i , j ∗ i d f i tfidf_{i,j}=tf_{i,j}*idf_i tfidfi,j=tfi,j∗idfi
词频(term frequency ,tf):指的是某一个给定的词语在该文件中出现的频率
逆向文档频率(inverse document frequency ,idf):是一个词语普遍重要性的度量。某一个特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到。
比如一篇文章由1000个字,而房地产出现了500次,房地产在该文章中出现的频率tf为:500/1000=0.5;房地产在1000份文件中出现过,文件的总数量为1000000,idf: l o g 1000000 / 1000 = 3 log1000000/1000=3 log1000000/1000=3;tf-idf就为0.5*3=1.5。
不单单看某个词汇在某一篇文章中出现的次数(频率),还需要看它在整个文件集中出现的次数。
Tf-idf文本特征提取api
sklearn.feature_extraction.text.TfidfVectorizer
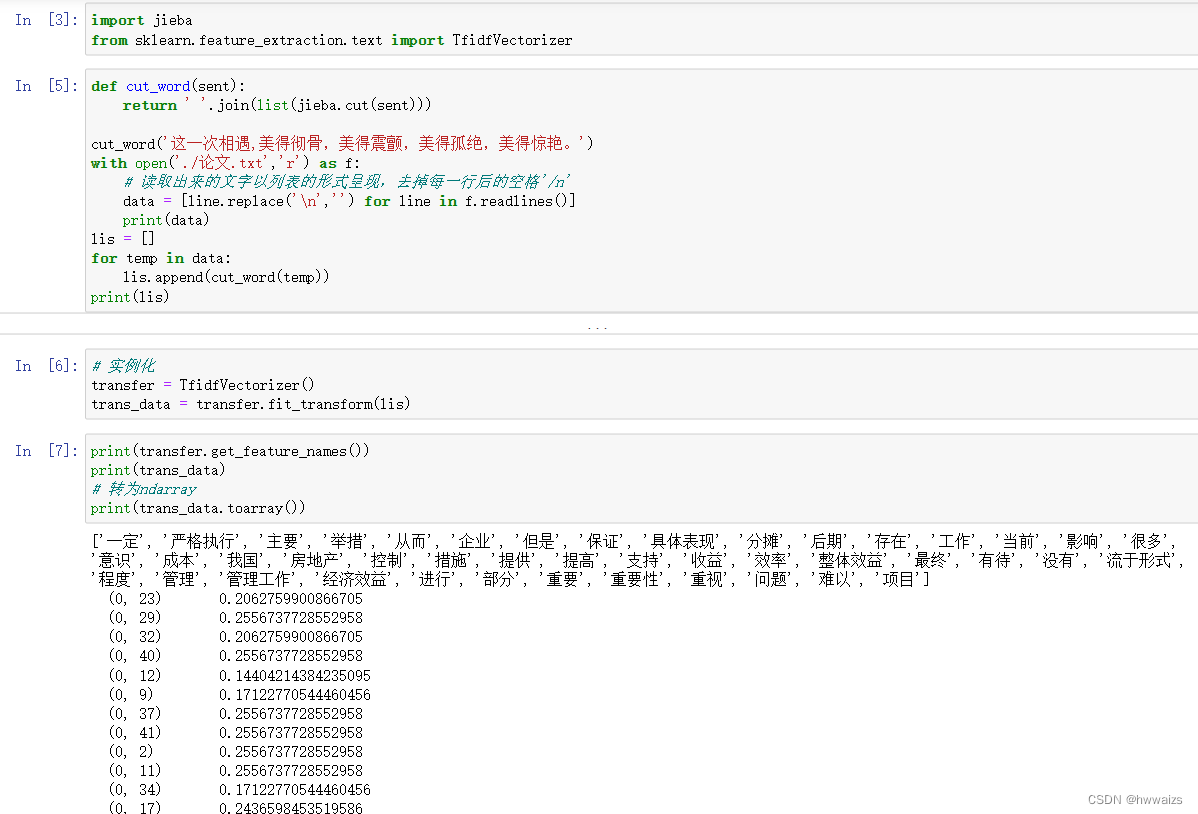

得到的是计算之后的tfidf的结果,没有文件集就是以行来进行分割的,以列表作为文件集,把每一行作为一个文件来进行处理。通过判断tfidf的大小来将某个词汇作为分割的重要词汇。
决策树算法API
分类API
sklearn.tree.DecisionTreeClassifier 决策树的分类算法器- criterion:设置树的类型- entropy:基于信息熵,也就是ID3算法,实际结果与C4.5相差不大- gini:默认参数,相当于基尼系数。CART算法是基于基尼系数做属性划分的,
所以criterion=gini时,实际上执行的是CART算法。- splitter:在构造树时,选择属性特征的原则,可以是best或random。默认是best,- best代表在所有的特征中选择最好的,random代表在部分特征中选择最好的。- max_depth:决策树的最大深度,可以控制决策树的深度来防止决策树过拟合。- min_samples_split:当节点的样本数小于min_samples_split时,不再继续分裂,默认值为2- min_samples_leaf:叶子节点需要的最小样本数。如果某叶子节点的数目小于这个阈值,则会和
兄弟节点一起被剪枝。可以为int、float类型。- min_leaf_nodes:最大叶子节点数。int类型,默认情况下无需设置,特征不多时,无需设置。
特征比较多时,可以通过该属性防止过拟合。
案例:泰坦尼克号乘客生存预测
需求:读取以下数据,预测生存率
train.csv 是训练数据集,包含特征信息和存活与否的标签;
test.csv 是测试数据集,只包含特征信息。
PassengerId:乘客编号;Survived:是否幸存;Pclass:船票等级;Name:姓名;Sex:性别;Age:年龄;
SibSp:亲戚数量(兄妹 配偶);Parch:亲戚数量(父母 子女);Ticket:船票号码;Fare:船票价格;Cabin:船舱;
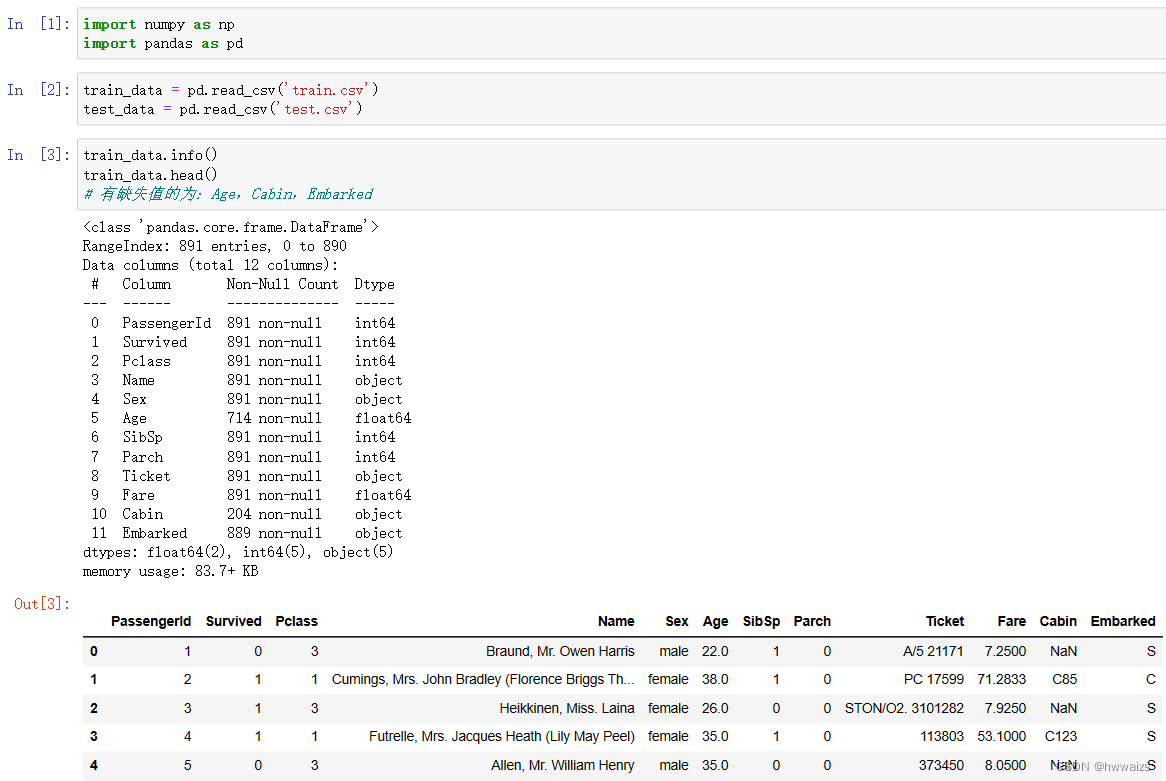


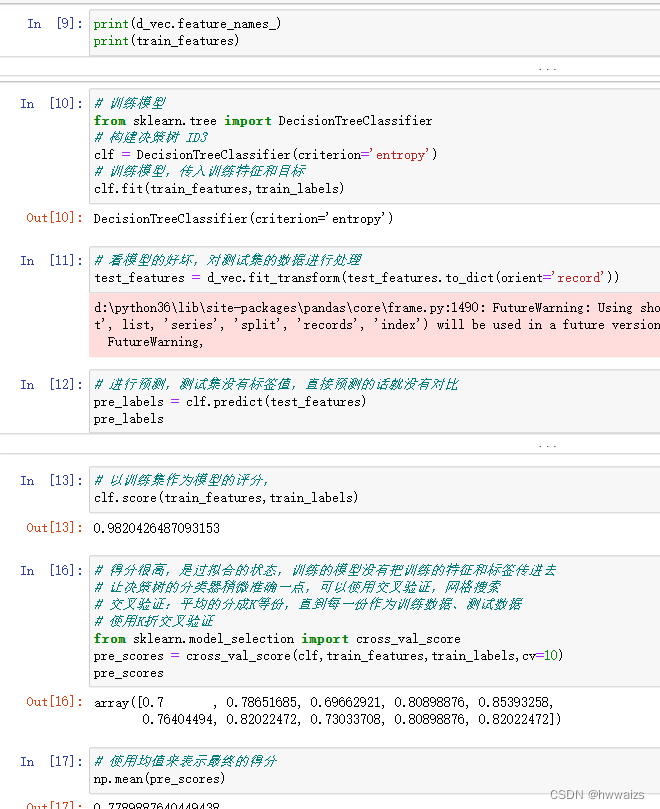
通过对字段的分析进行处理,注意纯数字类型可以以均值进行替换,字符串类型的缺失值太大就直接删掉,缺失值比较少的话就用占比比较多的来填充,特征选择尽量与标签有关系的特征,将特征中的文本转换为对应的数值,最终进行训练模型,然后进行K折交叉验证。
决策树可视化
安装graphviz工具,下载地址:http://www.graphviz.org/download/
将graphviz添加到环境变量PATH中,然后通过pip install graphviz 安装graphviz库
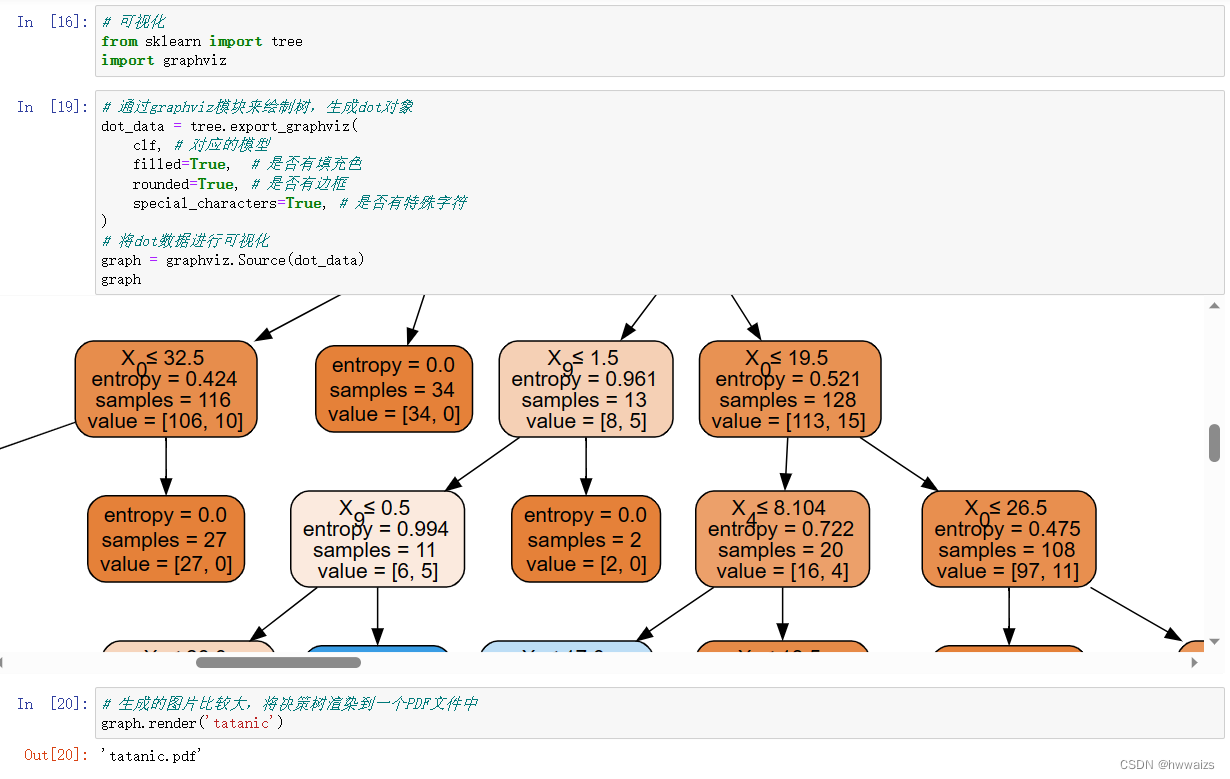
生成的图片比较大,可以保存为pdf文件,效果如下
决策树解决回归问题
决策树基于ID3、C4.5、CART算法,回归问题是基于CART算法实现的,基尼系数。
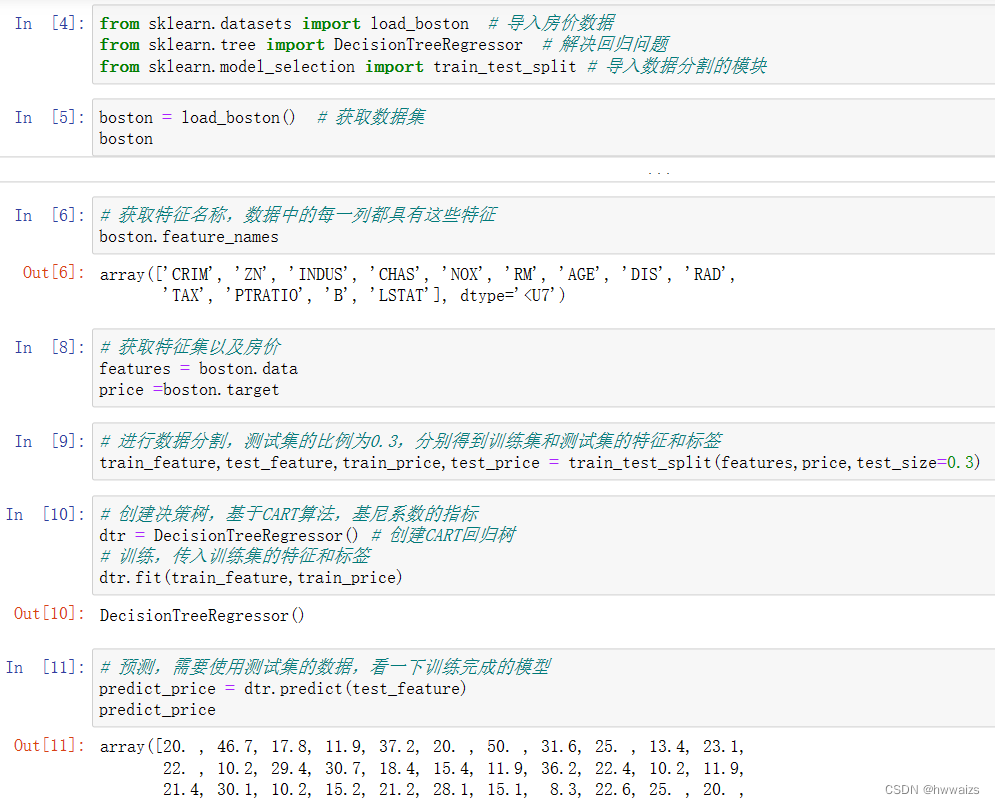
导入boston房价的数据,以及决策树的回归问题接口,接下来要调用数据接口,获取数据集,然后获取特征名称、特征集、得到训练集和测试集的特征和标签,然后进行训练和预测。
相关文章:
python机器学习(七)决策树(下) 特征工程、字典特征、文本特征、决策树算法API、可视化、解决回归问题
决策树算法 特征工程-特征提取 特征提取就是将任意数据转换为可用于机器学习的数字特征。计算机无法直接识别字符串,将字符串转换为机器可以读懂的数字特征,才能让计算机理解该字符串(特征)表达的意义。 主要分为:字典特征提取(特征离散化)…...
数据结构与算法中的双向链表
链表概念在现实世界中使用得很普遍。当我们使用 Spotify 播放队列中的下一首歌曲时,我们学到的单链表的概念就开始发挥作用。但是要播放队列中的上一首歌曲到底可以做什么呢? 在这篇博客中,我们将了解与数据结构相关的另一个概念,…...
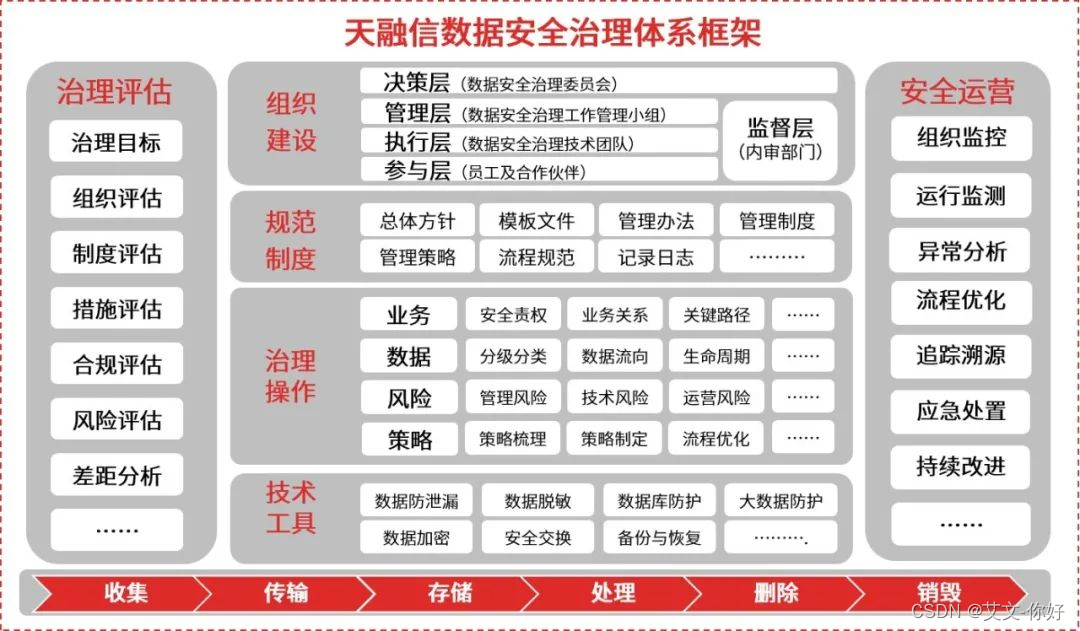
数据安全治理的关键-数据分类分级工具
强大的资产发现能力 多种资产发现方式的组合应用,能够最大程度地提高资产发现能力。 灵活的敏感数据分类分级规则 内置丰富的敏感数据分类分级规则,支持正则表达式、关键词组、非结构化指纹、结构化指纹、机器聚类等多种匹配方式,并且规则…...
Spring集成Junit
目录 1、简介 2、Junit存在的问题 3、回顾Junit注解 4、集成步骤 4.1、导入坐标 4.2、Runwith 4.3、ContextConfiguration 4.4、Autowired 4.5、Test 4.6、代码 5、补充说明 5.1、Runwith 5.2、BlockJUnit4ClassRunner 5.3、没有配置Runwith ⭐作者介绍࿱…...
Java正则校验密码至少包含:字母数字特殊符号中的2种
一、语法 字符说明\将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如, n匹配字符 n。\n 匹配换行符。序列 \\\\ 匹配 \\ ,\\( 匹配 (。^匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n…...
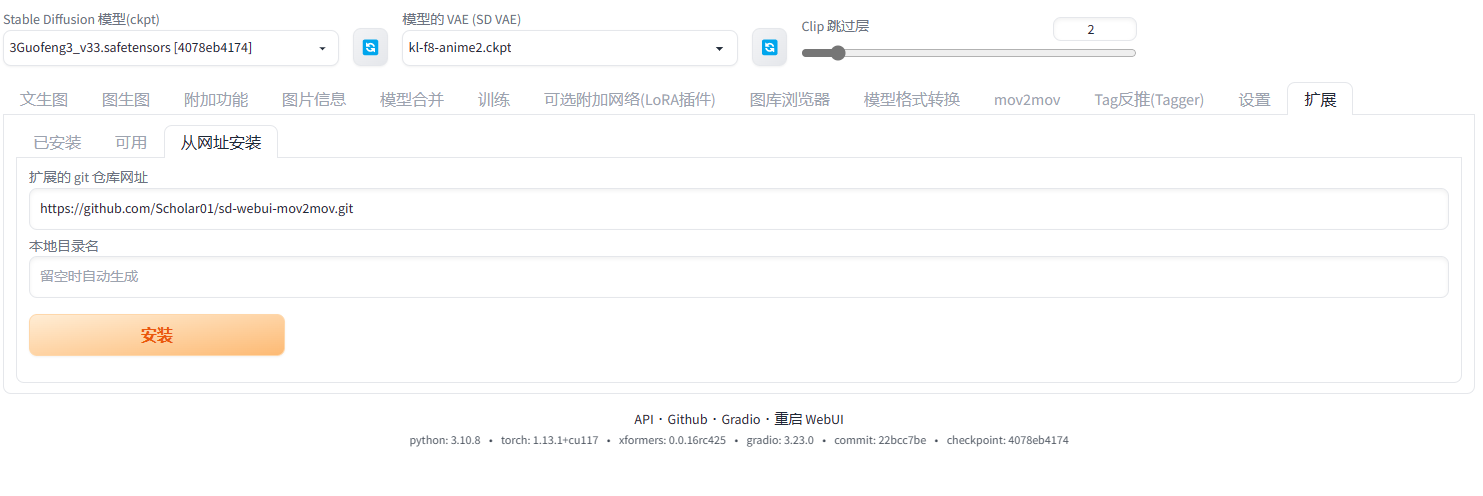
Stable Diffusion教程(6) - 扩展安装
打开stable diffusion webUI界面 加载插件列表 依次点击扩展->可用->加载自 搜索插件 首先在搜索框输入你要安装的插件,然后点击插件后面的安装按钮 如果你需要的插件这里面没有找到,可通过通网址安装的方式安装。 在git仓库网址输入框输入的你插件…...

Jenkins通过OpenSSH发布WinServer2016
上一篇文章> Jenkins集成SonarQube代码质量检测 一、实验环境 jenkins环境 jenkins入门与安装 容器为docker 主机IP系统版本jenkins10.10.10.10rhel7.5 二、OpenSSH安装 1、下载 官网地址:https://learn.microsoft.com/zh-cn/windows-server/administration/op…...

字母异位词分组 LeetCode热题100
题目 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 思路 将字符串按字符升序排列后作为key,原字符串作为value存储到map上。 代码 class Solution…...

使用angular和electron 构建桌面应用
使用angular和electron 构建桌面应用 初始设置 新建一个angular app npm install -g @angular/cli ng new angular-electron cd angular-electron修改src/index.html文件内容 将绝对路径改为相对路径,加个点,使electron可以访问到angular文件资源 <base href=".…...

安达发制造工业迈向智能化:APS高级计划排程助力提升生产效率
随着市场竞争的加剧,制造企业纷纷寻求提高生产效率和降低成本的方法。近年来,越来越多的制造企业开始采用APS(高级计划与排程)系统,以优化生产计划和排程,提高生产效率,并在竞争中取得优势。 现代制造业通常面临复杂的…...

Flink - sink算子
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 1. Kafka_Sink 2. Kafka_Sink - 自定义序列化器 3. Redis_Sink_String 4. Redis_Sink_list 5. Redis_Sink_set 6. Redis_Sink_hash 7. 有界流数据写入到ES 8. 无界流数据写入到ES 9. 自定…...

【项目 线程2】3.5 线程的分离 3.6线程取消 3.7线程属性
3.5 线程的分离 #include <stdio.h> #include <pthread.h> #include <string.h> #include <unistd.h>void * callback(void * arg) {printf("chid thread id : %ld\n", pthread_self());return NULL; }int main() {// 创建一个子线程pthread…...
Filebeat+ELK 部署
目录 //在 Node1 节点上操作 1.安装 Filebeat 2.设置 filebeat 的主配置文件 3.在 Logstash 组件所在节点上新建一个 Logstash 配置文件 4.浏览器访问 http://192.168.193.40:5601 登录 Kibana,单击“Create In…...
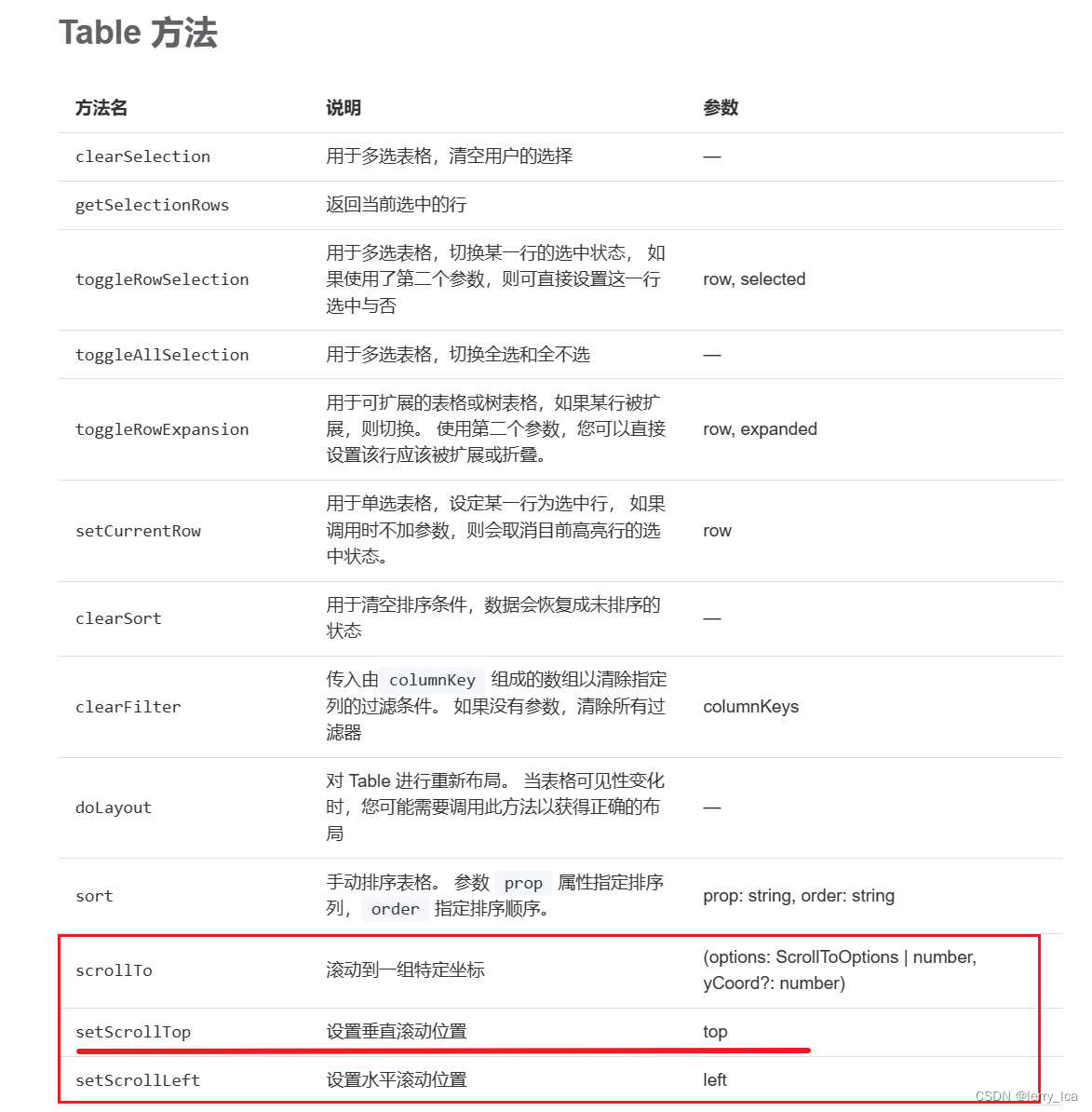
el-table点击表格某一行添加到URL参数,访问带参URL加载表格内容并滚动到选中行位置 [Vue3] [Element-plus 2.3]
写在最前 需求:有个表格列出了一些行数据,每个行数据点击后会加载出对应的详细数据,想要在点击了某一行后,能够将该点击反应到URL中,这样我复制这个URL发给其他人,他们打开时也能看到同样的行数据。 url会根…...
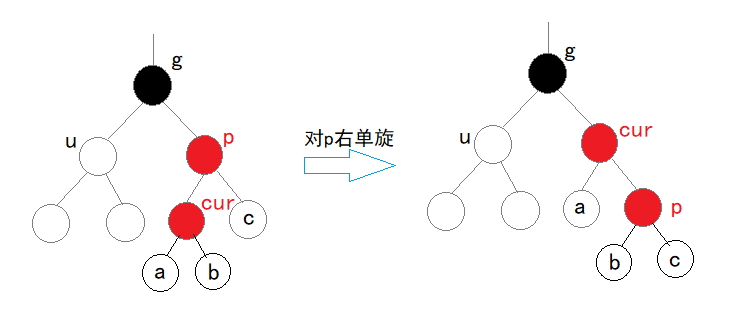
【树】 二叉树 堆与堆排序 平衡(AVL)树 红黑(RB)树
目录 1 树1.1 认识树1.2 树的相关概念1.3 树的表示孩子兄弟表示法 2 二叉树2.1 概念2. 2 特殊二叉树2.3 二叉树的性质2.4 二叉树的存储结构 3 堆 — 完全二叉树的顺序结构实现3.1 堆的概念3.2 核心代码3.3 堆应用1 堆排序2 TOP-K问题 4 二叉树的链式存储4.1 二叉链结构与初始化…...
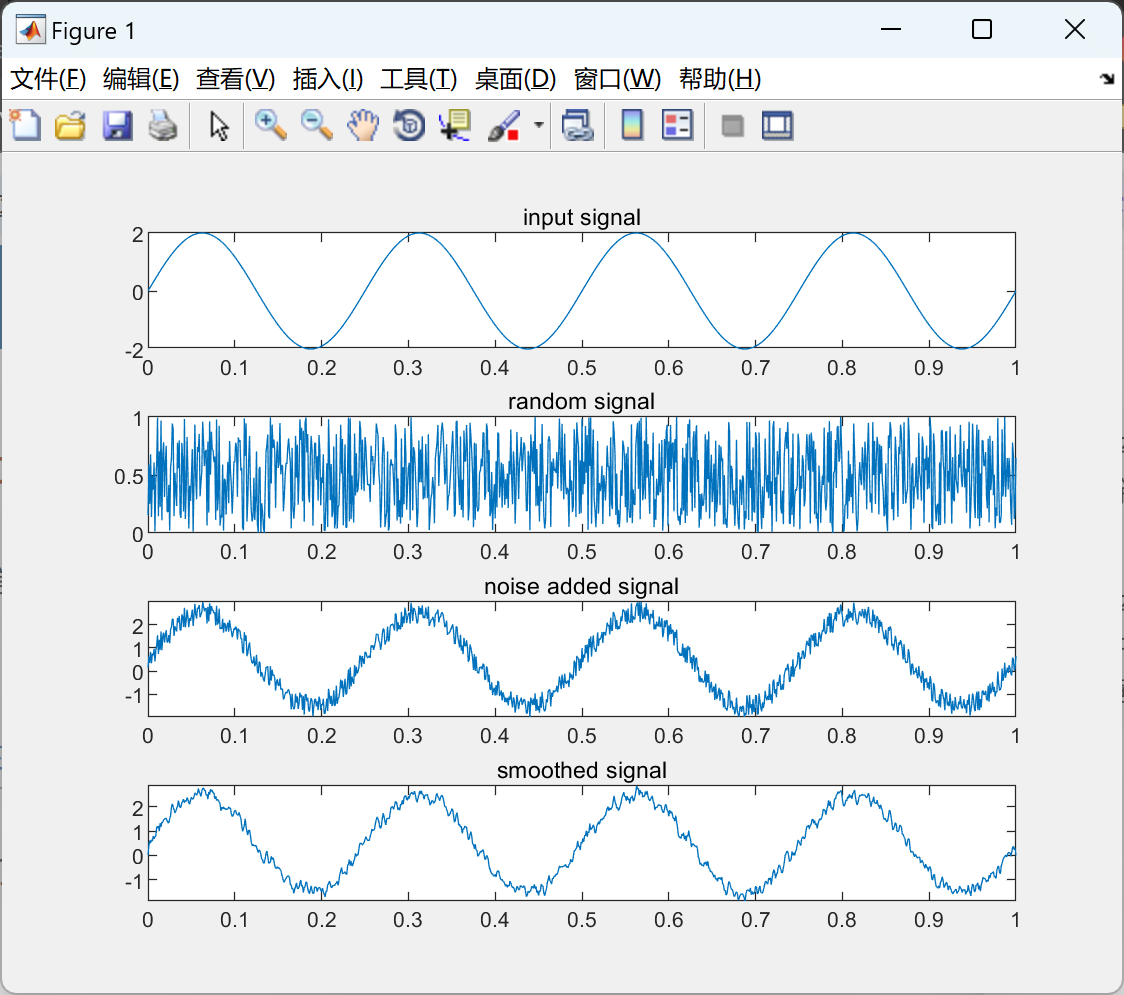
信号平滑或移动平均滤波研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
黑客技术(网络安全)自学
一、黑客是什么 原是指热心于计算机技术,水平高超的电脑专家,尤其是程序设计人员。但后来,黑客一词已被用于泛指那些专门利用电脑网络搞破坏或者恶作剧的家伙。 二、学习黑客技术的原因 其实,网络信息空间安全已经成为海陆空之…...

使用七牛云、阿里云、腾讯云的对象存储上传文件
说明:存在部分步骤省略的情况,请根据具体文档进行操作 下载相关sdk composer require qiniu/php-sdkcomposer require aliyuncs/oss-sdk-php composer require alibabacloud/sts-20150401composer require qcloud/cos-sdk-v5 composer require qcloud_s…...
使用阿里云DataX完成数据同步
DataX DataX 是阿里云 DataWorks 数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, datab…...
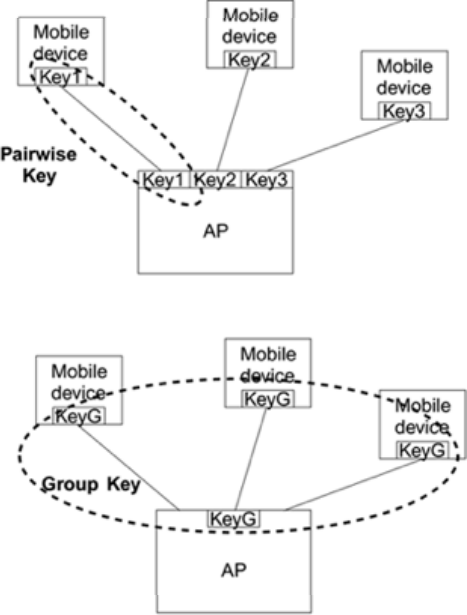
《Kali渗透基础》13. 无线渗透(三)
kali渗透 1:无线通信过程1.1:Open 认证1.2:PSK 认证1.3:关联请求 2:加密2.1:Open 无加密网络2.2:WEP 加密系统2.3:WPA 安全系统2.3.1:WPA12.3.2:WPA2 3&#…...

筑牢代码安全基石:GB/T 34943/34944 标准详解与库博静态分析工具的全面支持
一、标准概述:GB/T 34943 与 GB/T 34944 国家标准在软件安全日益成为国家信息化战略核心的背景下,GB/T 34943-2017《C/C 语言源代码漏洞测试规范》与 GB/T 34944-2017《Java 语言源代码漏洞测试规范》两项国家标准应运而生国家标准化管理委员会。由全国信…...

坐标系工艺参数的设定
在一台专机机床上模拟圆弧程序时,发现G2和G3的方向是反的,G2轴按逆时针方向运行,G3轴按顺时针方向运行。测试程序如下:G19G0 G90 Y0 Z0G2 Y100 Z100 CR100 F500M30G2指令时,圆弧为逆时针方向G3指令时,圆弧为…...

嵌入式贝叶斯优化:Arduino/ESP32轻量级1D黑箱调参库
1. 项目概述Bayesian Optimization(贝叶斯优化)Arduino 库是一个面向资源受限嵌入式平台的轻量级、确定性、单输入维度(1D)黑箱函数优化器。它并非通用数值计算库,而是专为微控制器场景深度定制的实时决策引擎——当目…...
)
PaddlePaddle-GPU环境配置:为什么你的显卡总是被识别成CPU?(附解决方案)
PaddlePaddle-GPU环境配置:为什么你的显卡总是被识别成CPU?(附解决方案) 刚拿到新显卡准备大展拳脚,却发现PaddlePaddle死活不认GPU,这种挫败感我太懂了。明明花大价钱买的显卡,结果深度学习训…...

IndexTTS-2-LLM功能全解析:不仅能用,还这么好用!
IndexTTS-2-LLM功能全解析:不仅能用,还这么好用! 1. 引言:为什么选择IndexTTS-2-LLM? 想象一下,你正在制作一个有声读物,需要把大量文字转换成自然流畅的语音。传统语音合成工具生成的机械音让…...

微信聊天记录导出终极指南:如何快速安全备份你的珍贵回忆
微信聊天记录导出终极指南:如何快速安全备份你的珍贵回忆 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经因为手机丢失或系统升级,担心…...

HagiCode 为什么选择 Hermes 作为综合 Agent 核心一
1. 哑铃图是什么? 哑铃图(Dumbbell Plot),有时也称为DNA图或杠铃图,是一种用于比较两个相关数据点的可视化图表。 它源于人们对更有效数据比较方式的持续探索。 在传统的时间序列比较中,我们通常使用两条折…...

ZYNQ PS端FFT加速实战:在Xilinx SDK中集成CMSIS-DSP库
1. 为什么要在ZYNQ PS端实现FFT加速? 在嵌入式信号处理领域,快速傅里叶变换(FFT)是最基础也是最关键的算法之一。很多工程师第一次接触ZYNQ平台时,往往会优先考虑使用PL端的FFT IP核来实现加速。但实际项目中ÿ…...
)
Python 3.14 JIT性能调优黄金三角:类型特化×循环展开×GC协同策略(附真实Web服务QPS从1.8K→3.4K压测报告)
第一章:Python 3.14 JIT编译器演进与性能调优全景图Python 3.14 引入了实验性但高度可配置的内置 JIT 编译器(代号“Torchlight”),标志着 CPython 首次在标准发行版中集成轻量级、函数粒度的即时编译能力。该 JIT 并非替代解释器…...

C#的[DoesNotReturn]和[DoesNotReturnIf]:帮助流分析的特性
C#的[DoesNotReturn]和[DoesNotReturnIf]特性是编译器流分析的重要工具,它们通过显式标记方法或代码块的终止行为,帮助开发者编写更安全、更高效的代码。这些特性在异常处理、条件终止等场景中尤为实用,能够显著提升代码的可读性和静态分析的…...