如何在pytest接口自动化框架中扩展JSON数据解析功能?
开篇
上期内容简单说到了。params类类型参数的解析方法。相较于简单。本期内容就json格式的数据解析,来进行阐述。
在MeterSphere中,有两种方式可以进行json格式的数据维护。一种是使用他们自带的JsonSchema来填写key-value表单。另一种就是手写json。
手写json在日常工作中效率较低,原因有二,一是手写太麻烦,占据大量个工作时间,影响效率。二是对正确性以及层级结构无法保证准确性。两者相比较,故选择JsonSchema的方式来维护json格式的数据。
json格式数据模型如下
"jsonSchema": {"properties": {"字段1": {"mock": {"mock": ""},"type": "string","description": "字段描述。。。"},"字段2": {"type": "number","mock": {"mock": ""},"minLength":50,"maxLength":100},"字段3": {"type": "integer","mock": {"mock": ""},"description": "字段描述"}},"type": "object","mock": {"mock": ""},"required": ["字段1","字段2",]}
使用JsonSchema作为最外层节点,第二层节点包含了类型、字段属性、必填字段列表等参数信息。第三层节点就是字段的一些属性,包含了字段长度、字段名称、字段类型、字段描述等
特别需要说明的是,MeterSphere的字段类型有很多,其中包含了object以及array这两种类型的数据
- object:如果字段类型是object,那么该字段节点下会嵌套另外一些字段,这些字段也是json格式的
- array:同理,如果字段类型是array,那么该字段下面会嵌套一个列表,列表中的每一个元素,都是json格式,不可以手动设置key,是从0递增自动命名。
这两种类型是可以无限重复套娃下去。只要你需要。
所以在解析这类数据时,我们就需要先解决这种层层嵌套的问题。
思路梳理
- 首先判断一下数据类型是否为上述这种套娃格式
- 判断字段类型是object还是array
- 利用python的递归,调用自身。并将字段属性作为参数传给这个函数
- 然后提取字段中的最大值,最小值,以及参数名称、类型
- 判断当前字段是否在必填列表中,如果在,则将这个字段设置为必填
如上是大概的解题思路,抛开拆解套娃,代码相对简单。如下是源码展示
# 解析json请求的参数
def post_arguments(data, required_list=None):field = {}if not isinstance(data, dict):raise TypeError("'data' is not dict")for key, value in data.items():if value["type"] == "object" and "properties" in value:# 递归调用,实现多层嵌套解析if "required" in value:recursion_par = post_arguments(value["properties"], value["required"])par = {key:{"type": value["type"],"description": value["description"] if "description" in value else "",**recursion_par}}field.update(par)else:recursion_par = post_arguments(value["properties"])par = {key: {"type": value["type"],"description": value["description"] if "description" in value else "",**recursion_par}}field.update(par)elif value["type"] == "array" and "items" in value:for l, i in enumerate(value["items"]):for arr_key, arr_value in i.items():if arr_value == "object" and "properties" in arr_value:# 递归调用,实现多层嵌套解析if "required" in arr_value:recursion_par = post_arguments(arr_value["properties"], value["required"])par = {l: {"type": value["type"],"description": value["description"] if "description" in value else "",**recursion_par}}field.update(par)else:recursion_par = post_arguments(arr_value["properties"])par = {l: {"type": value["type"],"description": value["description"] if "description" in value else "",**recursion_par}}field.update(par)elif arr_value == "array" and "items" in arr_value:if "required" in arr_value:recursion_par = post_arguments(arr_value["properties"], arr_value["required"])par = {l: {"type": value["type"],"description": value["description"] if "description" in value else "",**recursion_par}}field.update(par)else:recursion_par = post_arguments(arr_value["properties"])par = {l: {"type": value["type"],"description": value["description"] if "description" in value else "",**recursion_par}}field.update(par)else:maxLength = MAX_LENGTHminLength = MIN_LENGTHrequired = "false"if "maxLength" in arr_key:maxLength = i["maxLength"]elif "maxLength" in arr_key:minLength = i["minLength"]if required_list:if l in required_list:required = "true"items_par = {key:{"type": value["type"],"description": value["description"] if "description" in value else "",l: {"type": i["type"],"required": required,"max": maxLength,"min": minLength}}}field.update(items_par)else:maxLength = MAX_LENGTHminLength = MIN_LENGTHrequired = "false"if "maxLength" in value:maxLength = value["maxLength"]elif "minLength" in value:minLength = value["minLength"]if required_list:if key in required_list:required = "true"else:required = "false"par = {key: {"type": value["type"],"description": value["description"] if "description" in value else "","required": required,"max": maxLength,"min": minLength,}}field.update(par)return field可以看到,思路不是很难,但是代码还是比较臃肿的,其中有很多的代码是冗余的,在后期优化中,将考虑这块重构一下。大家在写的时候将思路缕清,别写出我这么烂的代码。。。。引以为戒~
结语
总结一下这个函数
- 首先在写的时候,多重嵌套是个难题,可以通过递归的方式解决
- 另外一定在思路缕清的前提下,再开始写代码,我就是在边写边思考,一个for循环一个for循环的嵌套。导致代码极其臃肿。执行效率有一定程度的降低,且代码可读性不好
- 公共代码提取:像一些数据结构模板,这些都可以提取成一个公共变量,然后调用即可。在函数中反复写着相类似的模板,是一种很愚蠢的行为。。。
【整整200集】超超超详细的python自动化测试进阶教程合集,真实模拟企业项目实战
相关文章:

如何在pytest接口自动化框架中扩展JSON数据解析功能?
开篇 上期内容简单说到了。params类类型参数的解析方法。相较于简单。本期内容就json格式的数据解析,来进行阐述。 在MeterSphere中,有两种方式可以进行json格式的数据维护。一种是使用他们自带的JsonSchema来填写key-value表单。另一种就是手写json。…...

哪些年,我们编程四处找的环境依赖
基于Maven,快速构建SSM项目 <properties><!-- 将spring和有关的升级版本,设置为5.0.5--><spring.version>5.0.5.RELEASE</spring.version><!-- 将mybatis和有关的升级版本,设置为3.1.1--><my…...
物联网工程开发实施,应该怎么做?
我这里刚好有嵌入式、单片机、plc的资料需要可以私我或在评论区扣个6 物联网工程的概念 物联网工程是研究物联网系统的规划、设计、实施、管理与维护的工程科学,要求物联网工程技术人员根 据既定的目标,依照国家、行业或企业规范,制定物联网…...

mysql使用SUBSTRING_INDEX拆分字符串,获取省、市、县和详细现住址
mysql使用SUBSTRING_INDEX拆分字符串,获取省、市、县和详细现住址 一、如何把"江西-上饶市-广丰县-大南镇古村村张家82号"拆分为省、市、县和详细现住址二、mysql的解决办法 一、如何把"江西-上饶市-广丰县-大南镇古村村张家82号"拆分为省、市、…...
和存活(livenessProbe)探针)
Kubernetes中的就绪(readinessProbe)和存活(livenessProbe)探针
目录 案例一 案例二 readinessProbe就绪探针 readinessProbe就绪探针的作用 livenessProbe存活探针 livenessProbe存活探针的作用 探针的几种类型 探针的几个参数...
docker端口映射详解(随机端口、指定IP端口、随意ip指定端口、指定ip随机端口)
目录 docker端口映射详解 一、端口映射概述: 二、案例实验: 1、-P选项,随机端口 2、使用-p可以指定要映射到的本地端口。 Local_Port:Container_Port,任意地址的指定端口 Local_IP:Local_Port:Container_Port 映射到指定地…...

俄罗斯方块
俄罗斯方块简单实现 使用 pygame 模块实现俄罗斯方块的简单实现,这里没有使用pygame 自带的碰撞检测,而是自定义的方法实现边界碰撞和方块间碰撞检测。 代码实现 import random import pygame import time # 初始化游戏 pygame.init()# 设置游戏窗口大…...

web服务
静态网页与动态网页的区别 在网站设计中,静态网页是网站建设的基础,纯粹 HTML 格式的网页通常被称为“静态网页”,静态网页是标准的 HTML 文件,它的文件扩展名是 .htm、.html,可以包含文本、图像、声音、FLASH 动画、…...

【Rust 基础篇】Rust类型别名:为类型赋予新的名字
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。在Rust中,类型别名是一种常见的编程特性,它允许为现有类型赋予新的名字,从而提高代码的可读…...
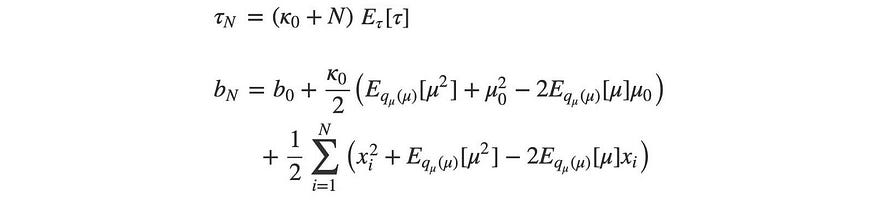
【机器学习】 贝叶斯理论的变分推理
许志永 一、说明 贝叶斯原理,站在概率角度上似乎容易解释,但站在函数立场上就不那么容易了;然而,在高端数学模型中,必须要在函数和集合立场上有一套完整的概念,其迭代和运算才能有坚定的理论基础。 二、贝叶…...
Flink之RedisSink
在Flink开发中经常会有将数据写入到redis的需求,但是Flink官方并没有对应的扩展包,这个时候需要我们自己编译对应的jar资源,这个时候就用到了bahir,barhir是apahce的开源项目,是专门给spark和flink提供扩展包使用的,bahir官网,这篇文章就介绍下如何自己编译RedisSink扩展包. 下…...

STM32CubeMx学习与K210串口通信+识别橘色色块——点亮小灯
K210模块的串口发送代码 引入模块 import sensor, image,time,lcd,utime import KPU as kpu import gc, sys from fpioa_manager import fm from machine import UART 锁定引脚 和 申明串口 fm.register(9, fm.fpioa.UART1_TX, forceTrue) fm.register(10, fm.fpioa.UART1_R…...

睿讯微带你深度了解汽车交流充电桩
这几年随着新能源汽车的普及,充电桩也越来越多的出现在我们的视野中。新能源纯电汽车就好比一种大号的电子产品,而充电桩则是它不可缺少的子系统,是新能源车主们的必要选择。 汽车充电桩分为直流和交流两种,2022年底全国公共充电桩…...

word怎么压缩到10m以下?文件压缩很简单
Word文档是我们工作和学习中一直需要用到的,但有时候Word文档体积过大,给存储和传输带来了不便,这时候我们可以做的就压缩Word。 通常情况下,影响Word文档过大的主要因素主要是图片过多、音视频插入、格式的设置、文字内容的增多以…...

I.MX6ULL_Linux_驱动篇(43)linux通用LED驱动
前面我们都是自己编写 LED 灯驱动,其实像 LED 灯这样非常基础的设备驱动, Linux 内核已经集成了。 Linux 内核的 LED 灯驱动采用 platform 框架,因此我们只需要按照要求在设备树文件中添加相应的 LED 节点即可,本章我们就来学习如…...

OPTEE之sonarlint静态代码分析实战二——optee_client
ATF(TF-A)/OPTEE之静态代码分析汇总 目录 一、optee_client源码下载及分析 二、扫描类型归类...

c++调用ffmpeg api将视频文件内容进行udp推流
代码及工程见https://download.csdn.net/download/daqinzl/88156926 开发工具:visual studio 2019 播放,采用ffmpeg工具集里的ffplay.exe, 执行命令 ffplay udp://238.1.1.10:6016 主要代码如下: #include "pch.h" #include <iostream&g…...
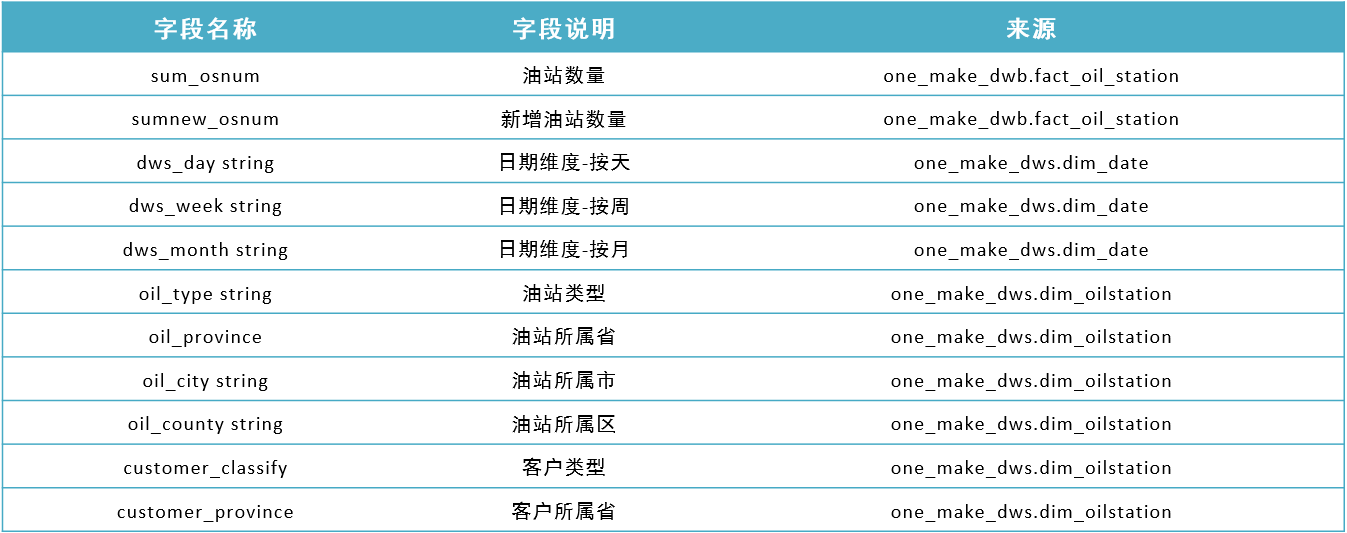
助力工业物联网,工业大数据之服务域:油站主题分析【二十六】
文章目录 07:服务域:油站主题分析08:服务域:油站主题实现 07:服务域:油站主题分析 目标:掌握油站主题的需求分析 路径 step1:需求step2:分析 实施 需求:统计…...
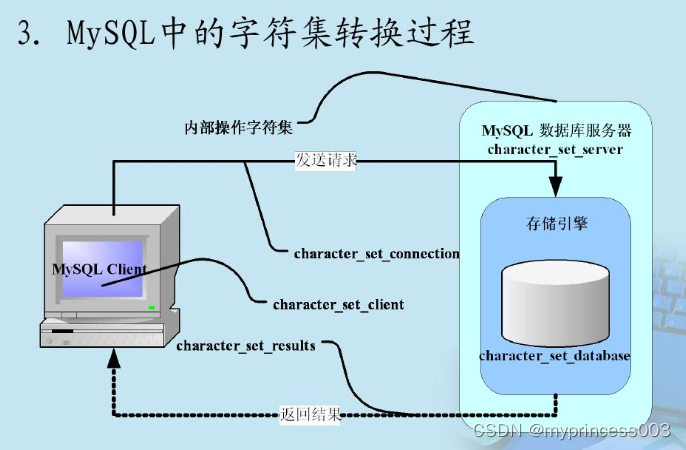
MySql之索引
MySql之索引 1.索引概述 MySql官方对索引的定义为:索引是帮助MySql高效获取数据的数据结构。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找…...

adb调试
连不上 adb 如果还遇到5037端口被占用的问题,就找出进程号用taskkill命令杀死该进程即可 1、查找5037端口对应的进程:netstat -ano|findstr 5037 2、杀死该进程:taskkill /F /PID pid 连接unity profiler 打开发包,并安装在手机…...
)
告别虚拟机!在Windows 11上零配置搭建Masm汇编实验环境(附保姆级图文教程)
在Windows 11上零配置搭建Masm汇编实验环境的完整指南 对于计算机专业的学生和汇编语言初学者来说,搭建一个可用的实验环境往往是第一道门槛。传统方法要么需要配置复杂的虚拟机,要么依赖过时的DOS模拟器,这些方案不仅占用系统资源࿰…...

银河麒麟V10 SP1安全基线配置踩坑记:为什么pam_wheel.so的group=wheel参数不生效?
银河麒麟V10 SP1安全基线配置实战:pam_wheel.so参数差异深度解析 第一次在银河麒麟V10 SP1服务器上配置安全基线时,我遇到了一个令人费解的问题。按照行业标准做法,我在/etc/pam.d/su文件中添加了auth required pam_wheel.so groupwheel配置&…...

【PZ-ZU47DR-KFB】璞致FPGA ZYNQ UltraScalePlus RFSOC QSPI Flash 固化实战指南与疑难解析
1. 认识璞致PZ-ZU47DR-KFB开发板与QSPI Flash固化 第一次拿到璞致PZ-ZU47DR-KFB开发板时,我就被它的硬件配置震撼到了。这块板子搭载的是Xilinx ZYNQ UltraScale RFSoC XCZU47DR芯片,集成了4核Cortex-A53处理器和FPGA可编程逻辑,还自带8通道5…...

Python小白也能学会!3个月蜕变AI开发高手,收藏这份超全路线图!
本文针对程序员学习大模型提供实用路线,强调Python基础即可入门。文章分阶段介绍12步学习计划,从基础理论到应用开发,再到高阶进阶,并给出3个月时间规划与关键提醒。核心观点是:掌握大模型开发并不难,关键在…...

三步掌握FullCalendar Vue3组件:从入门到场景化落地
三步掌握FullCalendar Vue3组件:从入门到场景化落地 【免费下载链接】fullcalendar-vue The official Vue 3 component for FullCalendar 项目地址: https://gitcode.com/gh_mirrors/fu/fullcalendar-vue 📌 适用人群:前端开发者/全栈…...

ANIMATEDIFF PRO企业级部署:API服务化与WebUI双模式运行指南
ANIMATEDIFF PRO企业级部署:API服务化与WebUI双模式运行指南 1. 项目概述与核心价值 ANIMATEDIFF PRO是一个基于先进AnimateDiff架构的专业级文生视频渲染平台,专为追求电影级视觉效果的内容创作者和AI艺术家设计。这个平台集成了Realistic Vision V5.…...

langchain学习--提示词
langchain提示词学习要点提示词(Prompt)在LangChain中扮演着核心角色,直接影响模型输出的质量和准确性。以下是关键学习方向和实践方法:基础结构设计明确指令:直接说明任务要求,例如"生成一份关于气候…...

元域的演进式架构:从“大而全”陷阱到“城市扩展”式敏捷构建
摘要 很多企业在构建数字化平台时,陷入“大而全”的陷阱:试图一次性设计所有功能,结果项目周期漫长、成本高昂、上线即落后。元域的建设同样面临这一风险。本文提出元域的演进式架构,以模块化、插件化、事件驱动、配置驱动四大设…...

别再乱用List了!Unity中Queue的5个高效应用场景对比
Unity中Queue的5个高效应用场景:性能对比与实战指南 在Unity开发中,数据结构的选择往往决定了游戏性能的上限。很多开发者习惯性地使用List来解决所有问题,却忽视了Queue在特定场景下的性能优势。本文将深入分析Queue的底层原理,并…...

4种突破数字内容壁垒的技术方案:面向研究者与创作者的开源工具指南
4种突破数字内容壁垒的技术方案:面向研究者与创作者的开源工具指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fa…...