Spark知识点总结
1. Spark支持哪几种运行模式?
-
本地模式(Local Mode):在这种模式下,Spark在单个机器上运行。所有的Spark操作都在一个单独的JVM进程中进行。这种模式适合开发和测试,但不适合处理大规模的数据。
-
集群模式(Cluster Mode):在集群模式下,Spark可以分布在多个机器上运行,从而处理大规模的数据。集群模式包括:
-
Standalone Mode:这是Spark自带的集群管理系统。在Standalone模式下,你需要手动启动Spark主节点和工作节点。
-
YARN (Yet Another Resource Negotiator):YARN是Hadoop的资源管理系统。如果你已经有一个运行Hadoop的集群,你可以在YARN上运行Spark,这样可以让Spark和其他Hadoop应用共享集群资源。
-
Apache Mesos:Mesos是一个更通用的集群管理系统,可以运行各种应用,包括Spark。使用Mesos,你可以在同一个集群上运行Spark和其他应用。
-
Kubernetes (K8s):Kubernetes是一个开源的容器编排系统,可以用来管理和部署应用。从Spark 2.3版本开始,Spark也可以在Kubernetes上运行。
-
2. Spark的Standalone集群架构有哪些角色及功能?
-
Master:也被称为主节点,它负责管理整个Spark集群。Master的主要任务包括:
-
负责管理从节点
-
接收客户端请求
-
资源管理:Master需要跟踪集群中每个Worker的状态,包括它们的CPU和内存使用情况。当接收到新的Spark应用请求时,Master需要决定如何分配资源给这个应用。
-
任务调度:当Spark应用提交作业时,Master需要将作业划分为多个任务,并将这些任务分配给不同的Worker。
-
-
Worker:也被称为从节点,它们执行由Master分配的计算任务。Worker的主要任务包括:
-
利用自己节点的资源运行主节点分配的计算任务
-
3. Spark支持哪些开发语言?
Python、Java、Scala、SQL、R
4. RDD是什么?
- 定义:弹性分布式数据集
- 理解:高度类似于列表,区别在于RDD是分布式的,RDD的数据可以存储多个节点上
5. RDD的五大特性是什么?
-
分区(Partitioned):每个RDD都由多个分区构成。分区是数据的基本单位,每个分区都可以在集群的不同节点上并行处理。
-
并行操作(Parallel Operation):对RDD的转换操作实质上是对RDD所有分区的并行操作。Spark会尽量在所有可用的节点上并行执行任务。
-
依赖关系(Dependencies):每个RDD都会保留与其他RDD之间的依赖关系,这些依赖关系被称为血统(Lineage)。血统信息使得Spark可以在数据丢失时重新计算丢失的部分。
-
(可选择)持久化(Persistence):RDD可以被持久化到内存中,以便在多个并行操作中复用。持久化的级别可以是内存存储,磁盘存储,或者两者的混合。
-
(可选择)任务调度(Task Scheduling):Spark在分配任务给Executor运行的时候,会尽量选择数据局部性较好的节点进行计算,也就是优先在数据所在节点进行计算,这样可以减少数据的网络传输,提高计算效率。
6. RDD的弹性是什么意思?
- RDD的弹性主要体现的是数据安全和性能的灵活性
- 安全:血脉机制,Task自动恢复
- 性能:Persist持久化机制和Checkpoint检查点机制
- 开发者可以自由的在安全和性能之间做选择
-
容错性(Fault-tolerance):这是通过RDD的血统(Lineage)机制实现的。每个RDD都会记住它是如何从其他RDD转换过来的。这意味着,如果某个分区的数据丢失(例如,因为节点失败),Spark可以使用血统信息重新计算这个分区的数据,而不是从其他节点复制数据。这种自动恢复的能力增加了Spark的弹性。
-
可伸缩性(Scalability):RDD的弹性也体现在它可以很容易地在更大或更小的集群上运行。如果你增加了更多的节点,Spark会自动将数据和计算任务分配给这些新的节点。同样,如果你减少了节点,Spark也能够处理这种情况。
-
持久化(Persistence):RDD支持多种持久化级别,允许用户根据需要将数据存储在内存中、磁盘上,或者以序列化的形式存储。这种灵活性可以帮助你根据你的应用的需求和资源限制来平衡存储和计算的开销。
-
检查点(Checkpointing):RDD还支持检查点机制,这可以将RDD的某个状态保存到磁盘(通常是分布式文件系统如HDFS),以减少在失败恢复时的计算量。这是一种弹性的体现,因为它允许你在数据安全性和计算效率之间做出权衡。
7. Spark的算子分为几类?
-
转换(Transformation):这些操作会产生一个新的RDD。例如,
map函数会对RDD中的每个元素应用一个函数,并返回一个包含结果的新RDD。转换操作是惰性的,也就是说,它们不会立即执行,而是在动作操作被调用时才执行。这样可以让Spark更有效地计划整个数据处理流程。转换操作在Spark中是非常重要的概念,因为它们允许我们构建一个处理流程,然后一次性地在数据上执行这个流程。 -
动作(Action):这些操作会触发实际的计算,并返回一个值给Driver程序,或者将数据写入外部系统(例如,文件系统或数据库)。例如,
count函数会返回RDD中的元素数量,saveAsTextFile函数会将RDD的内容写入一个文本文件。当动作操作被调用时,Spark会开始实际的计算,包括执行所有的转换操作。
转换一般不会触发job构建task,返回值一定是一个RDD
动作一定会触发job构建task,返回值一定不是一个RDD
8. Spark的常用算子有哪些?
转换算子(Transformation):
map(func):返回一个新的RDD,由每一个输入元素经过func函数转换后组成。flatMap(func):类似于map,但是每一个输入元素可以被映射为零个或多个输出元素(所以func应该返回一个序列,而不是单一元素)。filter(func):返回一个新的RDD,只包含满足func的元素。reduceByKey(func):在(K,V)对的RDD上调用,返回一个(K,V)对的RDD,其中每个key的值都是通过func函数聚合所有同样key的值得到的。join(otherDataset):在两个键值对的RDD上调用,返回一个相同key对应的所有元素联接在一起的RDD。distinct([numTasks])):返回一个包含源RDD中不同元素的新RDD。union(dataset):返回一个新的RDD,包含源RDD和指定RDD的所有元素。keys():返回一个仅包含键值对RDD中的key的RDD。values():返回一个仅包含键值对RDD中的value的RDD。mapValues(func):在键值对RDD上调用,应用函数func到每个value,生成一个新的键值对RDD。
动作算子(Action):
foreach(func):应用函数func到RDD的每个元素。take(n):返回RDD的前n个元素。first():返回RDD的第一个元素。count():返回RDD的元素个数。collect():返回RDD中的所有元素。collectAsMap():将结果以Map的形式返回,以便查找。saveAsTextFile(path):将数据集的元素以textfile的形式保存到本地文件系统,HDFS或者其他Hadoop支持的文件系统。top(n):返回RDD的前n个元素,按照自然结果排序。takeOrdered(n, [ordering]):返回该RDD排序后的前n个元素。
9. persist、cache、checkpoint之间的区别
-
cache():这是一种特殊的持久化操作,其实就是
persist(MEMORY_ONLY),也就是说,它会将RDD的数据存到内存中。如果内存不够,那么没有存到内存中的分区就会在需要的时候重新计算。 -
persist():这是一个更一般的持久化操作,可以让你自己选择存储级别。例如,你可以选择将数据存到磁盘上,或者以序列化的方式存到内存中,或者将数据复制到多个节点等等。
-
checkpoint():这是一种特殊的持久化操作,它会将RDD的数据保存到一个可靠的文件系统(如HDFS)中。这个操作会切断RDD的血脉(Lineage)信息,也就是说,一旦数据被checkpoint了,它的父RDD就可以被丢弃了,因为如果需要的话,我们可以总是从checkpoint的数据重新计算出这个RDD的数据。
- 存储位置
- persist:将RDD缓存在内存或者磁盘中,可以自己指定
- checkpoint:将RDD的数据存储在磁盘中 - 生命周期
- persist:当遇到了unpersist或者程序结束,缓存的数据会被自动释放
- checkpoint:不会被自动释放,只能手动删除 - 存储内容
- persist:将整个RDD的对象缓存,保留RDD的血脉关系
- checkpoint:只存储了RDD的数据,不会保留RDD的血脉关系
10. reduceByKey和groupByKey的区别
reduceByKey(func)
reduceByKey操作可以在每个分区内部先对输出进行本地的reduce,因此需要发送到不同节点上进行全局reduce的数据量就会大大减小。这就使得reduceByKey比groupByKey具有更低的网络传输开销和更好的性能。
groupByKey()
groupByKey操作将会根据键值对的键进行分组。在这个过程中,同一个键的所有值都会被拉取到一个节点上然后进行reduce操作。这就意味着,对于大数据量的应用,groupByKey可能会导致大量的数据在节点间进行传输,从而导致较大的性能开销。
因此,一般来说,我们推荐在可能的情况下,尽量使用reduceByKey或者其他能够减少数据传输的操作(如aggregateByKey或foldByKey),而尽量避免使用groupByKey。
11. repartition和coalesce的区别
repartition(numPartitions)
repartition操作将通过网络shuffle重新分配数据,从而创建出新的分区集合。你可以使用这个操作来增加或减少RDD的分区数。由于需要通过网络shuffle数据,所以repartition操作的开销比较大。
coalesce(numPartitions, shuffle = False)
coalesce操作用于减少RDD的分区数,以减少数据在不同分区间的传输。在默认情况下,coalesce不会进行shuffle操作,所以比repartition更高效。但如果你设置shuffle = True,那么coalesce就会和repartition一样,通过网络shuffle来重新分配数据。
12. map和mapPartitions的区别
map(func)
map操作是一种对元素级别的转换,它会对RDD的每一个元素应用一个函数,然后返回一个新的RDD。
mapPartitions(func)
mapPartitions操作是一种对分区级别的转换,它会对RDD的每一个分区应用一个函数,然后返回一个新的RDD。
在性能和资源使用上,map和mapPartitions有以下的差异:
map操作会对每一个元素都调用一次函数,这可能会带来一些额外的开销,特别是当函数调用开销较大的时候。mapPartitions操作只会对每个分区调用一次函数,所以它可以有效地利用资源,减少函数调用的开销。但是,因为它需要在内存中处理整个分区的数据,所以如果一个分区的数据量很大,mapPartitions可能会占用大量的内存。
13. top和sortByKey的区别?
top(n)
top操作将从RDD中返回前n个元素,元素按照自然顺序排序。这个操作不需要对整个数据进行shuffle,但是需要将所有数据加载到驱动程序的内存中,所以它只适合于数据量较小的情况。
sortByKey(ascending=True)
sortByKey操作将RDD中的数据按照键进行排序。你可以选择升序或降序排序。这个操作需要对数据进行shuffle,所以它的开销相对较大,但是它可以处理大数据量,因为它不需要将所有数据都加载到内存中。
top:Action操作,不经过Shuffle,只能降序排序,适合于小数据量
sortByKey:Transformation操作,经过Shuffle,可以降序或者升序,适合于大数据量
14. Spark的程序由几个部分组成及每个部分的功能是什么?
- 在集群模式下,每个Spark程序都由两种进程构成
- Driver:驱动进程,先启动,只有1个
- 负责申请资源启动Executor
- Driver负责解析代码构建Task
- 负责将Task调度分配给Executor运行,并监控Task运行
- Executor:计算进程,后启动,可能有多个
- Executor启动运行在从节点上
- 负责运行Task
15. Spark程序的运行流程是什么?
-
客户端提交Spark应用:首先,用户会使用
spark-submit命令(或者其他方式)提交Spark应用。这个命令可以指定应用的代码、类和任意的命令行参数。 -
启动Driver:一旦Spark应用被提交,Driver程序就会启动。Driver程序可以在用户的本地机器上运行,也可以在集群的主节点上运行,这取决于用户提交应用时的配置。
-
Driver请求资源:Driver程序会通过集群管理器(如YARN、Mesos或Standalone)请求启动Executor的资源。
-
启动Executor:集群管理器会在集群的Worker节点上启动Executor进程。每个Executor进程都有一定数量的核和内存。
-
Executor注册:一旦Executor进程启动,它们会向Driver程序注册。这样,Driver程序就知道了有哪些Executor可以用于运行任务。
-
Driver解析代码:Driver程序会解析用户代码,生成一系列的Task。这些Task是由Transformation和Action操作生成的。
-
构建DAG和Stage:Driver程序会使用DAGScheduler组件将这些Task组织成一个DAG,并且根据数据的依赖关系将DAG划分为多个Stage。
-
划分TaskSet:每个Stage会被进一步划分为一个TaskSet,TaskSet中的每个Task都是可以并行执行的。
-
调度Task:最后,Driver程序会使用TaskScheduler组件将Task调度到Executor上执行。
16. Spark为什么比MR要快?
-
内存计算和DAG执行模型:Spark允许用户将数据保存在内存中,从而避免了频繁的磁盘I/O操作,这使得Spark比MapReduce更快。此外,Spark使用DAG(有向无环图)执行模型,可以在一个阶段(stage)中执行多个操作,而不需要像MapReduce那样在每个操作之后都将结果写入磁盘。
-
智能Shuffle:Spark的Shuffle过程比MapReduce更加智能。在MapReduce中,Shuffle包括排序和合并等操作,这些操作通常会消耗大量的计算资源。而在Spark中,Shuffle过程可以根据数据量和计算需求进行优化,例如,对于reduce类的操作,Spark可以避免不必要的排序。
-
任务调度:在MapReduce中,每个任务都是一个单独的JVM进程,这意味着任务的启动和结束都需要消耗资源。而在Spark中,所有任务都运行在同一个Executor进程的不同线程中,这减少了任务启动和结束的开销。
17. Spark支持哪些模块?
-
Spark Core:这是Spark的基础模块,提供了Spark的基本功能,包括任务调度、内存管理、错误恢复、与存储系统的交互等。此外,Spark Core还提供了Resilient Distributed Dataset (RDD) API,这是Spark的基本数据结构。
-
Spark SQL:这个模块提供了处理结构化和半结构化数据的接口。用户可以使用SQL查询数据,也可以使用Dataset或DataFrame API进行编程。Spark SQL模块还包括一个强大的查询优化器,叫做Catalyst。
-
Spark Streaming:这个模块允许用户处理实时数据流。它使用了Spark Core中的RDD模型,并提供了一个高级API,用于处理数据流。
-
Struct Streaming:这是一个基于Spark SQL引擎的流处理框架。它提供了一种处理无限数据流的新方法,用户可以像处理批数据一样处理流数据。
-
MLlib (Machine Learning Library):这个模块是Spark的机器学习库,提供了常见的机器学习算法,包括分类、回归、聚类、协同过滤等。此外,MLlib还提供了一些机器学习的工具,如特征提取、转换、降维等。
-
GraphX:这是Spark的图计算库,用于处理图形数据和计算。它包括一系列图形算法,如PageRank和Connected Components。
18. DataFrame、DataSet是什么,与RDD比较有什么区别?
- RDD:分布式集合,类似于列表,支持泛型,但没有Schema
- DataFrame:分布式表,类似于数据表,不支持泛型,拥有Schema
- DataSet:分布式表 ,类似于数据表,支持泛型,拥有Schema
19. 为什么要用Spark on YARN?
- 资源统一化管理,YARN是公共的资源管理平台,可以运行各种分布式程序:MR、Tez、Spark、Flink
- YARN的资源和任务调度机制更加成熟完善
20. Spark on YARN的不同deploymode的区别?
- deploy-mode:决定Driver进程运行位置
- client:Driver运行在客户端节点
- cluster:Driver运行在从节点
- 问题:只要是Spark程序就一定有Driver,只要运行在YARN就有AppMaster
- client模式:两者共存
- Driver运行在客户端节点,负责解析代码构建Task、分配Task运行
- AppMaster运行从节点上,负责申请资源启动Executor
- cluster模拟:两者合并
- Driver以子进程方式运行在AppMaster内部,实现整体功能
21. 什么是宽依赖和窄依赖?
- 宽依赖:父RDD的一个分区的数据给了子RDD多个分区,一对多
- 宽依赖会导致Shuffle产生,Spark程序中会按照宽依赖划分Stage
- 窄依赖:父RDD的一个分区的数据只给了子RDD的一个分区,一对一,多对一
- 窄依赖可以直接在内存中完成,Spark程序中一个Stage内部全部是窄依赖过程
22. Spark的Shuffle过程和MRShuffle有什么区别?
- 从整体的角度来看,两者并没有大的差别。
- 都是将 mapper(Spark 里是 ShuffleMapTask)的输出先进行分区
- 不同的 分区的数据最终送到不同的 reducer(Spark 里是 ShuffleReadTask)。
- Reducer 以内存作缓冲区,对数据进行聚合或者排序等操作
- 从细节的角度来看,两者有一些重要差别。
- MapReduce 是 sort-based,所有数据不论怎么样经过shuffle都会被排序,对大量数据的处理计算比较友好,但灵活性较差
- Spark中的Shuffle有多种方案可以选择排序或者不排序,并且实现了基于内存和网络传输的优化方案,提升了性能
- 从实现角度来看,两者也有一些差别。
- MapReduce 将处理流程划分出明显的几个阶段:map, spill, merge, shuffle, sort, reduce 等。
- 在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蕴含在 transformation 中。
相关文章:

Spark知识点总结
1. Spark支持哪几种运行模式? 本地模式(Local Mode):在这种模式下,Spark在单个机器上运行。所有的Spark操作都在一个单独的JVM进程中进行。这种模式适合开发和测试,但不适合处理大规模的数据。 集群模式&a…...
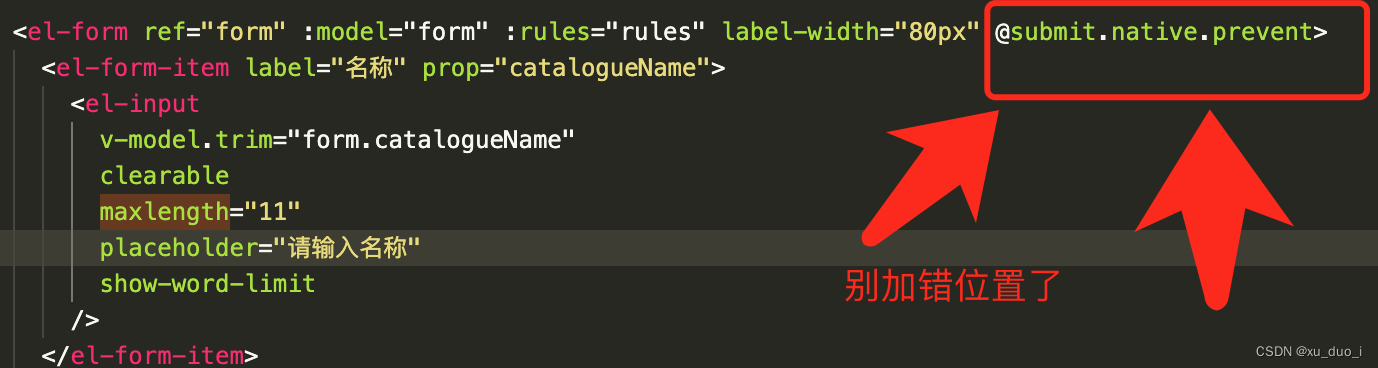
vue el-input 使用 回车键会刷新页面的问题
场景: vue项目中 在输入框输入字符并按下回车键搜索时,不会进行搜索, 而是会刷新页面 原因: 当form表单中只有一个input时,按下回车建会自动触发页面的提交功能, 产生刷新页面的行为 解决: 在…...

【ARM64 常见汇编指令学习 12 -- ARM 汇编函数 的学习】
文章目录 1.1 ARM 汇编函数简介1.1.1 ARM 汇编标签 Label1.1.2 ARM 汇编函数属性指令1.1.3 UEFI 中的函数宏:ASM_FUNC1.1.3.1 UEFI ASM_FUNC 实现汇编函数 1.1.4 UEFI 预编译前缀宏 ASM_PFX 上篇文章:ARM64 常见汇编指令学习 11 – ARM 汇编宏 .macro 的…...

linux下软件安装 - 与GPT对话
1 cmake 没有uninstall 你是对的,CMake 默认情况下并没有提供 make uninstall 目标。这是因为 make install 操作是在特定的目录下进行安装的,CMake 不知道安装到了哪里以及哪些文件被安装了。因此,没有直接支持的 make uninstall 目标来进行卸载。 如果你想要卸载通过 mak…...
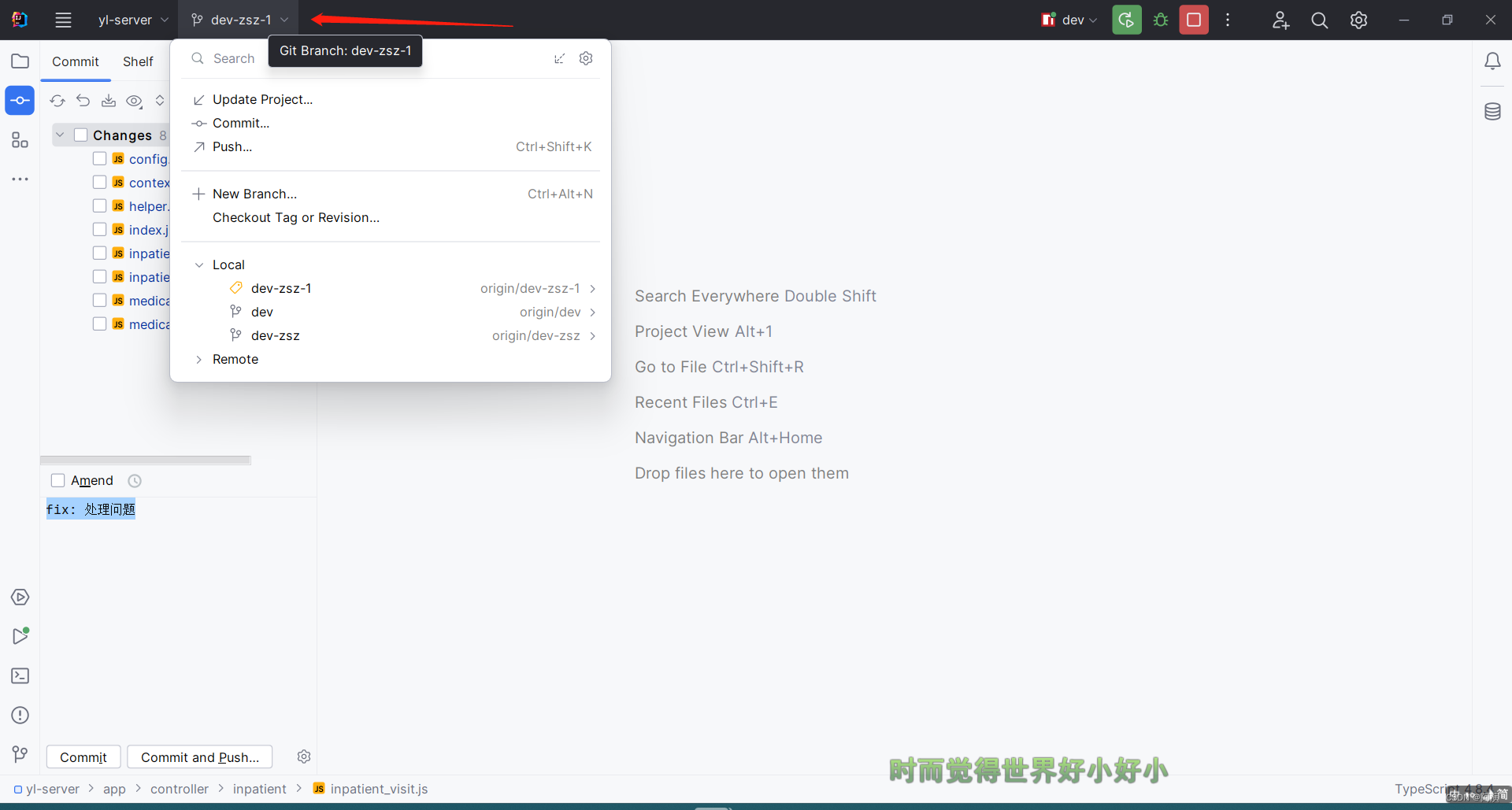
idea 2023 新版ui中git的相关操作
前两个月换了新电脑,下了最新版的idea发现可以切换一套新的ui了 切换新ui肯定不太习惯,很多操作都得重新摸索一下 在这里记录几个git相关的操作 忽略我下面截图中当前项目是js的后端项目…… 切换ui 首先说一下怎么切换新旧版ui,我这里就…...

vue3—SCSS的安装、配置与使用
SCSS 安装 使用npm安装scss: npm install sass sass-loader --save-dev 配置 配置到全局 🌟附赠代码🌟 css: {preprocessorOptions: {scss: {additionalData:import "./src/Function/Easy_I_Function/Echarts/ToSeeEcharts/utill.…...

Godot 4 源码分析 - Path2D与PathFollow2D
学习演示项目dodge_the_creeps,发现里面多了一个Path2D与PathFollow2D 研究GDScript代码发现,它主要用于随机生成Mob var mob_spawn_location get_node(^"MobPath/MobSpawnLocation")mob_spawn_location.progress randi()# Set the mobs dir…...
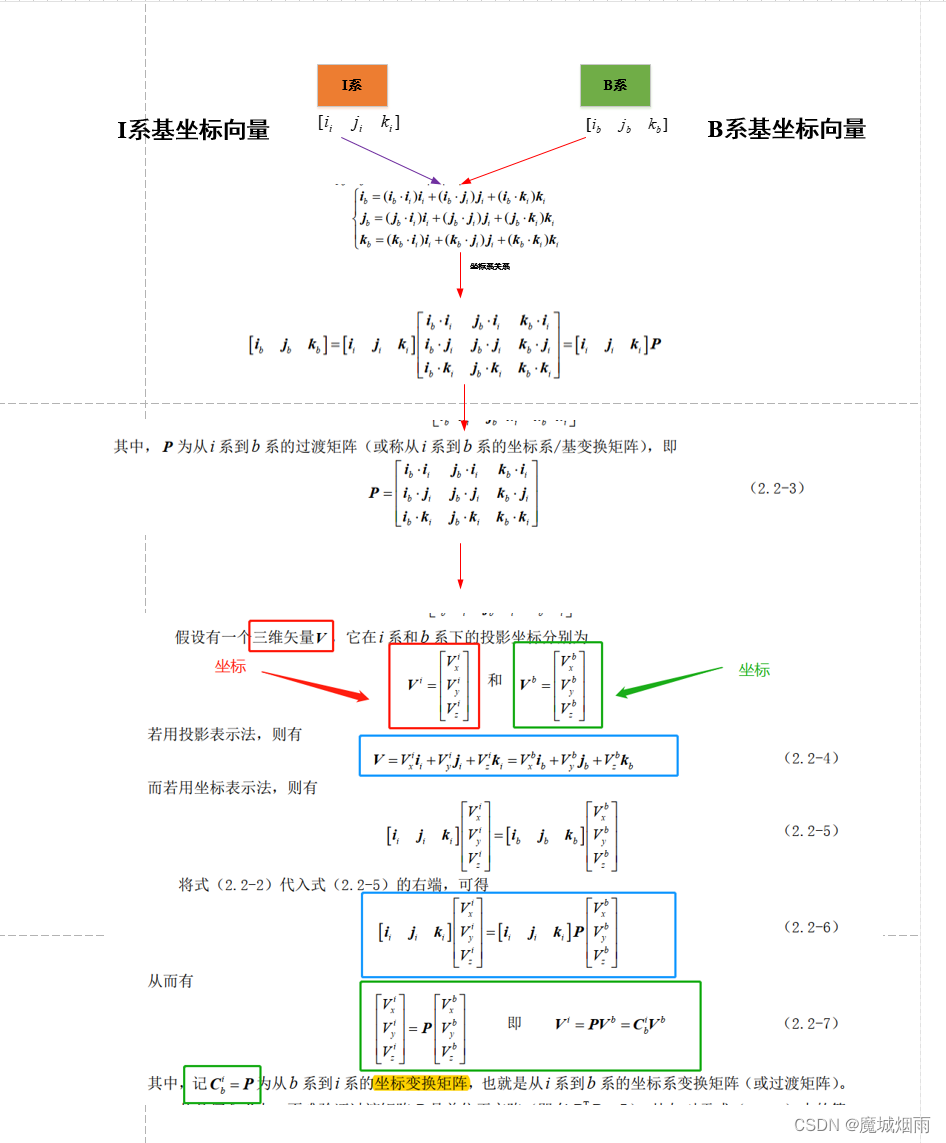
ardupilot 中坐标变换矩阵和坐标系变换矩阵区别
目录 文章目录 目录摘要1.坐标变换矩阵与坐标系变换矩阵摘要 本节主要记录ardupilot 中坐标变换矩阵和坐标系变换矩阵的区别,这里非常重要,特别是进行姿态误差计算时,如果理解错误,很难搞明白后面算法。 1.坐标变换矩阵与坐标系变换矩阵 坐标变换矩阵的本质含义:是可以把…...

VR内容研发公司 | VR流感病毒实验虚拟现实课件
由广州华锐互动开发的《VR流感病毒实验虚拟现实课件》是一种新型的教学模式,可以为学生提供更加真实和直观的流感病毒分离鉴定实验操作体验,从而提高学生的实验技能和工作效率。 《VR流感病毒实验虚拟现实课件》涉及了生物安全二级实验室(BSL-2)和流感病…...

python——案例10:认识if、elif、else
案例10:认识if、elif、elsenumfloat(input("输入数值:")) #用户输入数字if num>0:print("正数")elif num0:print("零") else:print("负数")#输出结果如下:输入数值:-1 负数 输入数值…...

Hadoop中命令检查hdfs的文件是否存在
Hadoop中命令检查hdfs的文件是否存在 在Hadoop中,可以使用以下命令检查HDFS文件是否存在: hadoop fs -test -e 其中,是要检查的HDFS文件的路径。 如果文件存在,命令返回0;如果文件不存在,命令返回非0值…...

计算机网络用户接入层设计
用户接入层为用户提供访问核心网络的能力, 为用户提供共享/交换的带宽分配,按照业主要求,并考虑到端口密度的要求以及 设备的性能价格比,建议选用 Catalyst 3524XL和 Catalyst 3548XL 工作组交换 机,分别放置于配线间中。如同一配线间需两台以…...

全志F1C200S嵌入式驱动开发(应用程序开发)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 我们在开发soc驱动的时候,很多情况下也要验证下当前的驱动功能是否正确。当然除了验证驱动功能之外,我们还要编写业务代码和流程代码。这中间就和各行各业有关了,有的是算法,有…...

人工智能学习07--pytorch23--目标检测:Deformable-DETR训练自己的数据集
参考 https://blog.csdn.net/qq_44808827/article/details/125326909https://blog.csdn.net/dystsp/article/details/125949720?utm_mediumdistribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-125949720-blog-125326909.235^v38^pc_releva…...

Statefulset 实战 1
上一部分与大家分享到 Statefulset 与 RplicaSet 的区别,以及 Statefulset 的特点,能做的一些事情及一些注意事项 现在我们来尝试使用 Statefulset 来部署我们的应用,我们可以需要有应用程序,然后有持久化卷 开始使用 Statefuls…...

没有jodatime,rust怎么方便高效的操作时间呢?
关注我,学习Rust不迷路!! 当使用Rust进行日期操作时,可以使用 chrono 库。下面给出了二十个常见的日期操作的例子: 1. 获取当前日期和时间: use chrono::prelude::*;let current_datetime Local::now()…...
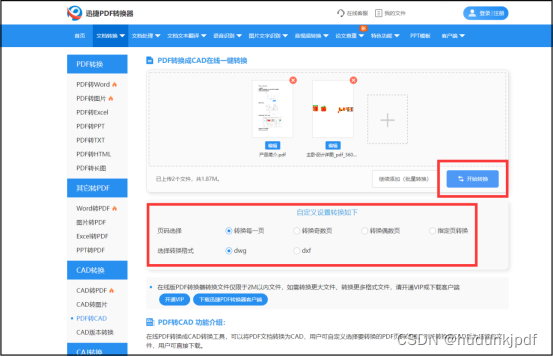
如何把pdf转成cad版本?这种转换方法非常简单
将PDF转换成CAD格式的优势在于,CAD格式通常是用于工程设计和绘图的标准格式。这种格式的文件可以在计算机上进行编辑和修改,而不需要纸质副本。此外,CAD文件通常可以与其他CAD软件进行交互,从而使得工程设计和绘图过程更加高效和精…...

MySQL常用函数方法
字符串函数 函数描述举例left(str, length)从左开始截取字符串,截取length个left(2023-08-04, 7) 2023-08right(str, length)从右开始截取字符串,截取length个 right(2023-08-04, 5) 08-04 substring(str, pos, length) substring(被截取字…...

Linux命令200例专栏导读:实用指南助你成为Linux大师
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。 🏆本文已…...

ICN6202 MIPIDSI转LVDS桥接芯片的功能及特征 调试文档资料
产品特征功能: 输入:MIPI DSI 支持MIPI D-PHY Version 1.00.00 和 MIPI DSI Version 1.02.00. 可接收MIPI DSI 18bpp RGB666 and 24bpp RGB888 packets 4 lane data1 lane clock 4对数据线可以选择1、2、3、4lane data 每对差分数据传输线最大可…...

Coze 智能体开发标准流程
在 Coze(扣子)平台上开发 AI 智能体(Agent)的流程可以概括为 “创建 - 编排 - 调试 - 发布” 四个核心阶段。无论你是使用国内版 (coze.cn) 还是国际版 (coze.com),其逻辑架构基本一致。1. 创建智能体 (Create)这是项目…...

3个步骤轻松解决B站缓存视频无法播放问题:m4s格式转换完全指南
3个步骤轻松解决B站缓存视频无法播放问题:m4s格式转换完全指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾遇到这样的情…...

PythonOcc实战避坑指南:处理复杂STEP装配体时,如何准确识别零件并计算几何属性?
PythonOcc工业级STEP装配体处理实战:从零件识别到爆炸图生成的全流程避坑指南 在工业设计和机械工程领域,处理复杂装配体模型是日常工作中的重要环节。当我们需要对阀门、齿轮箱等工业设备进行数字化分析时,准确识别零件并计算几何属性是后续…...

3步完成Windows系统净化:轻量优化工具Win11Debloat使用指南
3步完成Windows系统净化:轻量优化工具Win11Debloat使用指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter a…...

如何高效捕获网页资源?这款浏览器扩展让下载效率提升300%
如何高效捕获网页资源?这款浏览器扩展让下载效率提升300% 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字化时代,网页…...
)
手把手教你调用MiniMax API:快速集成聊天、语音合成到你的应用(Python示例)
手把手教你调用MiniMax API:快速集成聊天、语音合成到你的应用(Python示例) 在AI技术快速落地的今天,将大模型能力集成到自己的应用中已成为开发者的刚需。MiniMax作为国内领先的大模型服务提供商,其API平台提供了对话…...

测试工程师的悲哀:我们正在成为“人肉脚本”
曾几何时,“点点点”是外界贴在测试工程师身上最刺眼的标签,我们奋力撕下它,向世界证明测试是一个需要深度技术、系统思维和工程能力的专业领域。我们学会了编程,构建了自动化框架,掌握了性能压测与安全渗透。然而&…...

像素史诗·智识终端Claude Code实践:自动化代码生成与审查
像素史诗智识终端Claude Code实践:自动化代码生成与审查 1. 开发者的新助手 最近在开发圈里,一个叫"像素史诗智识终端"的工具开始引起关注。它集成了类似Claude Code的智能代码能力,正在改变开发者们日常工作的方式。想象一下&am…...

Music Tag Web:3大核心能力重塑你的音乐库管理体验
Music Tag Web:3大核心能力重塑你的音乐库管理体验 【免费下载链接】music-tag-web 音乐标签编辑器,可编辑本地音乐文件的元数据(Editable local music file metadata.) 项目地址: https://gitcode.com/gh_mirrors/mu/music-tag…...

新手福音:用快马AI生成你的第一个简易网页网盘项目
作为一个刚接触编程的新手,想要快速上手一个实际项目确实容易感到无从下手。最近我在学习网页开发时,尝试用InsCode(快马)平台做了一个简易网页网盘,整个过程意外地顺利。这个项目虽然功能简单,但涵盖了前端开发的几个核心概念&am…...